LangChain 核心组件 [ 1 ]

核心组件(Components)
前置说明,从这一小节开始,我们将会学习大量的概念、术语,及其具体用法和对应的接口方法。但不用担心,它们本质上都是围绕大模型调用衍生出来额的一系列功能扩展,因为大模型也不是随随便便就能被很好的调用起来。因此,为了让整个交互流程更规范、更高效,LangChain 定义了一系列的组件使我们与大模型的交互更规范。
因此在学习过程中,有几点要提前强调:
- 理解每个组件的作用和适用场景是最重要的,不需要死记硬背接口和参数;
- 如何查阅官方文档,掌握自主查询的方法才是关键;
- 但前期我们仍会详细讲解常用接口和参数,随着内容深入,将更侧重核心功能与查询思路的培养。重要的内容我们都会覆盖到,大家可以放心。
消息(Messages)
消息是聊天模型中的通信单位,用于表示聊天模型的输入和输出,以及可能与对话关联的任何其他上下文或元数据。
LLM 消息结构
每条消息都有一个角色和内容,以及因 LLM 的不同而不同的附加元数据。
消息角色 (Role):用来区分对话中不同类型的消息,并帮助聊天模型了解如何响应给定的消息序列。
| 角色 | 描述 |
|---|---|
system(系统角色) |
用于告诉聊天模型如何行为并提供额外的上下文。并非所有聊天模型提供商都支持。 |
user(用户角色) |
表示用户与模型交互的输入,通常以文本或其他交互式输入的形式。 |
assistant(助理角色) |
表示来自模型的响应,其中可以包括文本或调用工具的请求。 |
tool(工具角色) |
用于在检索外部数据或将工具调用的结果传递回模型的消息。与支持工具调用的聊天模型一起使用。 |
消息内容 (Content):表示多模态数据(例如,图像、音频、视频)的消息文本或字典列表的内容。内容的具体格式可能因底层不同的 LLM 而异。目前,大多数模型都支持文本作为主要内容类型,对多模态数据的支持仍然有限。
消息其他元数据 (Additional metadata)
| 元数据 | 描述 |
|---|---|
ID |
消息标识符。 |
Name |
名称允许区分具有相同角色的不同实体。并非所有型号都支持此功能! |
Metadata |
有关消息的其他信息,例如时间戳、令牌使用情况等。 |
Tool Calls |
模型发出的一个或多个工具的调用请求 |
下面展示一个 OpenAI 的格式消息列表:
[
{
"role": "user",
"content": "Hello, how are you?"
},
{
"role": "assistant",
"content": "I'm doing well, thank you for asking."
},
{
"role": "user",
"content": "Can you tell me a joke?",
}
]
LangChain 接受下面的格式作为聊天模型的输入:
chat_model.invoke([
{
"role": "user",
"content": "Hello, how are you?",
},
{
"role": "assistant",
"content": "I'm doing well, thank you for asking.",
},
{
"role": "user",
"content": "Can you tell me a joke?",
}
])
LangChain 消息
LangChain 提供了一种统一的消息格式,可以跨聊天模型使用,允许用户使用不同的聊天模型,而无需担心每个模型提供商使用的消息格式的具体细节。例如:
openai_model = init_chat_model("gpt-4o-mini", model_provider="openai")
anthropic_model = init_chat_model("claude-3-5-sonnet-latest", model_provider="anthropic")
deepseek_model = init_chat_model("deepseek-chat", model_provider="deepseek")
google_genai_model = init_chat_model("gemini-2.5-flash", model_provider="google_genai")
model = init_chat_model(...)
这些模型提供商不同,但对于其输入和输出,统一使用 LangChain 的消息格式。LangChain 消息格式主要分为五种,分别是:
| 消息类型 | 对应角色 | 描述 |
|---|---|---|
SystemMessage |
对应 system 系统角色 |
用于启动 AI 模型的行为并提供额外的上下文,例如指示模型采用特定角色或设定对话的基调(例如,“你是一个端庄开发的专家”)。 |
HumanMessage |
对应 user 用户角色 |
人类端消息表示用户与模型交互的输入。大多数聊天模型都希望用户输入采用文本形式。 |
AIMessage |
对应 assistant 助理角色 |
这是来自模型的响应,其中可以包括文本或调用工具的请求。它还可能包括其他媒体类型,如图像、音频或视频 —— 尽管目前仍然不常见。 |
AIMessageChunk |
对应 assistant 助理角色,用于流式响应 |
通常在生成聊天模型时流式传输响应,因此用户可以实时看到响应,而不是等待生成整个响应后再显示。 |
ToolMessage |
对应 tool 工具角色 |
这表示一条角色为 "tool" 的消息,其中包含调用工具的结果。 |
这几个消息类型,我们之前已经全部见过!它们都是 LangChain BaseMessage 的子类,全部是作为 LangChain 聊天模型的输入和输出!
BaseMessage 抽象消息类
class langchain_core.messages.base.BaseMessage 是作为 LangChain 聊天模型的输入和输出!
参数如下:
content:消息的字符串内容。
additional_kwargs:与消息关联的其他有效负载数据。对于来自 AI 的消息,可能包括模型提供的工具调用。
response_metadata:响应元数据。例如:响应标头、logprobs、令牌计数、模型名称。
type:消息的类型。必须是消息类型唯一的字符串。此字段的目的是在对消息进行反序列化时方便地识别消息类型。
name:消息名称,为消息提供一个人类可读的名称。该字段的使用是可选的,是否使用它取决于模型实现。
id:消息的可选唯一标识符。理想情况下,这应该由创建消息的提供者 / 模型提供。
内置方法:
pretty_print() -> None:打印消息的漂亮表示。
pretty_repr(html: bool = False) -> str:获得消息的漂亮 HTML 表示。
-
请求为 False 将消息格式化为 HTML。如果为 True,则消息将使用 HTML 标记进行格式化。默认值为 False。
-
响应:这是消息的漂亮表示。
text() -> str:获取消息的文本内容。
对话模式
大多数对话都以设置对话上下文的系统消息开始。 接下来是包含用户输入的用户消息,然后是包含模型响应的助手消息。如下图所示:
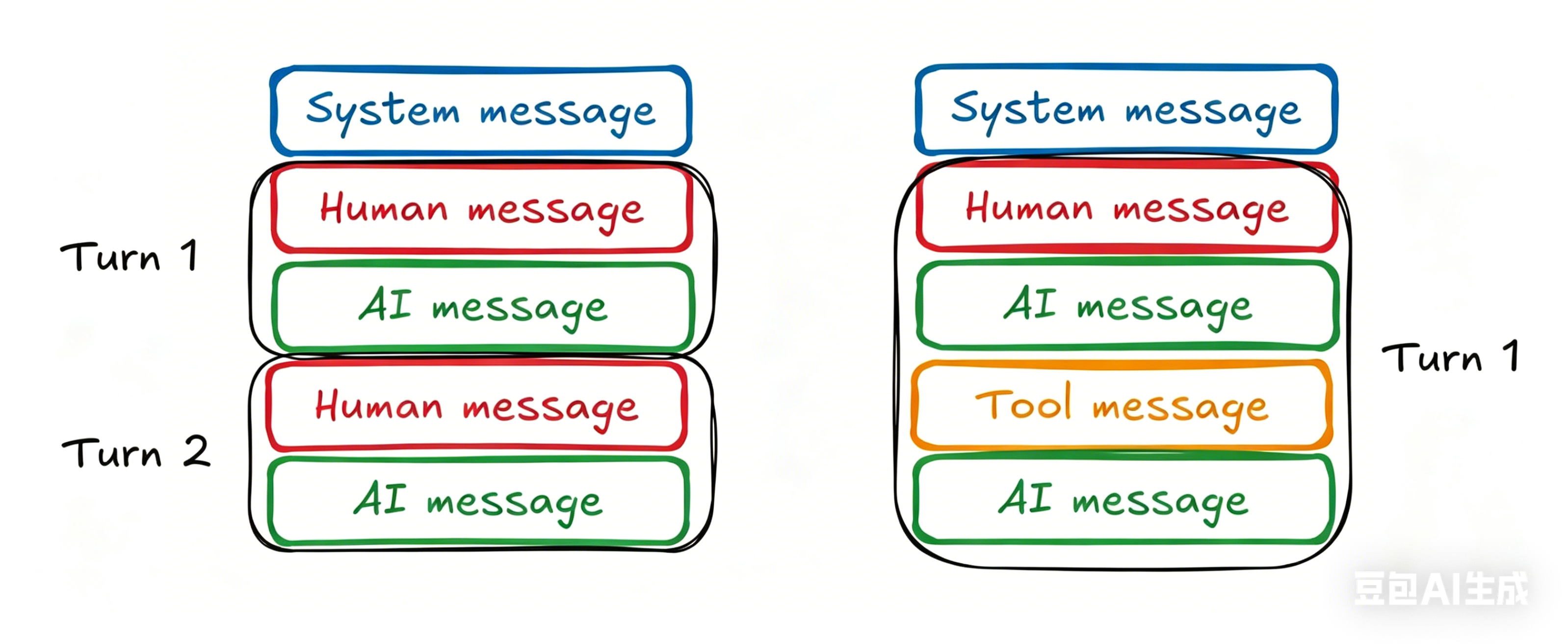
缓存历史消息
多轮对话
在与大型语言模型交互的过程中,我们常常体验到与智能助手进行连贯多轮对话的便利性。但目前我们的系统还未支持此功能,代码如下:
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 第一次对话
result = model.invoke([HumanMessage(content="Hi! I'm Bob")])
result.pretty_print()
# 第二次对话
result = model.invoke([HumanMessage(content="What's my name?")])
result.pretty_print()
================================ Ai Message =================================
Hi Bob! How can I assist you today?
================================ Ai Message =================================
I'm sorry, but I don't have access to personal information about you unless you share it with me. What would you like me to call you?
可以发现,聊天模型并不认识我们,更别说支持更多轮的对话了~【LLM 没有记忆 】
稍作修改,让我们将 AI 回复给我们的响应跟着新的用户消息一起发给聊天模型试试。代码如下:
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 记录消息
messages = [
HumanMessage(content="Hi! I'm Bob"),
AIMessage(content="Hello Bob! How can I assist you today?"),
HumanMessage(content="What's my name?"),
]
model.invoke(messages).pretty_print()
打印结果:
================================ Ai Message =================================
Your name is Bob! How can I help you today, Bob?
从结果可知,只要将历史消息,重新发送给聊天模型,那么就可以实现多轮对话的功能。
内存缓存
那么对于历史消息的管理就显得尤为重要。在 LangChain 老版本中,可以使用 RunnableWithMessageHistory 来管理聊天消息历史记录。它将你的输入和输出,将其存储在某个数据存储中。未来的交互将这些消息作为其输入的一部分传递给链。代码如下:
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
store = {}
# 接受一个 session id 并返回一个消息历史对象。
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 包装模型,管理聊天消息历史记录
with_message_history = RunnableWithMessageHistory(model, get_session_history)
config = {"configurable": {"session_id": "1"}}
with_message_history.invoke(
[HumanMessage(content="Hi! I'm Bob")],
config=config,
).pretty_print()
with_message_history.invoke(
[HumanMessage(content="What's my name?")],
config=config,
).pretty_print()
class langchain_core.runnables.history.RunnableWithMessageHistory 类初始化参数说明:
runnable:被包装Runnable实例,这里就是我们定义的聊天模型get_session_history:返回类型为BaseChatMessageHistory的消息记录历史回调函数。此函数接受一个session_id字符串类型,并返回相应的ChatHistory实例。
class langchain_core.runnables.history.RunnableWithMessageHistory 类方法说明:
invoke()方法:此方法与其他Runnable实例的.invoke()方法相同。只不过注意其config中需要配置configurable中的session_id:RunnableWithMessageHistory可以读取到config["configurable"]["session_id"],进而调用get_session_history获取对应的会话历史。
最终打印结果:
================================ Ai Message =================================
Hi Bob! How can I assist you today?
================================ Ai Message =================================
Your name is Bob! How can I help you today?
记忆功能已经实现!
说明:从 LangChain 的 v0.3 版本开始,官方建议 LangChain 用户不要使用 RunnableWithMessageHistory,而是利用 LangGraph 持久性来完成(见 LangGraph 章节)。原因是它们的功能有限,不太适合现实世界的对话式应用程序。这些内存抽象缺乏对多用户、多对话的支持,而这对于大型或活跃的用户群的对话系统是很重要的。
LangChain 0.3 中,RunnableWithMessageHistory 被正式弃用,取而代之的是 LangGraph 持久性。这些 LangGraph 持久性非常灵活,可以支持比 RunnableWithMessageHistory 接口更广泛的用例。我们会在 LangGraph 篇章中学习它!
因此,RunnableWithMessageHistory 这部分我们讲解并不深入。在之前,对于生产环境我们还需要使用聊天消息的持久化实现,例如 RedisChatMessageHistory 等,而不只是 InMemoryChatMessageHistory(),但现在也不推荐新应用使用它们了。
管理历史消息
前置概念
上下文窗口
管理历史消息,无非就是理解如何 “管理”,“管理” 无非也就是一些 “CRUD”。那么在了解如何管理消息之前,需要先了解下多轮对话的核心概念:上下文窗口。上下文窗口可以理解为模型的 “短期记忆区”,即 LLM 在一次处理请求时,所能查看和处理的最大 Token 数量,它包含了:
-
用户的输入
-
大模型的输出
-
有时还包括系统指令(
SystemMessage)和对话历史。
不同 OpenAI 下的模型上下文窗口不同为:
-
GPT-4o 模型上下文窗口为
400000(最大 Token 数量) -
GPT-4.1 模型上下文窗口为
1047576(最大 Token 数量) -
其他模型上下文窗口可参考对应模型官网说明,如 OpenAI 下模型可以参考这里。
Token
在自然语言处理(NLP)中,Token 是文本的基本单位。它不是完全等同于一个单词或一个汉字,而是一个更细粒度的划分。计算机无法直接理解文字,需要将文本转换为数字(向量)。Tokenization(令牌化)就是这个转换过程的第一步,将句子分解成模型可以理解和处理的碎片。
对于英文:1 个 Token ≈ 4 个字符或 0.75 个单词,1000 个 Tokens 约等于 750 个英文单词。一个 Token 可以是一个单词(如 apple)、一个词根(如 un 在 unlikely 中),或者一个标点符号(如 .)。例如,"ChatGPT is great!" 可能会被分成 ["Chat", "GPT", " is ", " great", "!"] 这 6 个 Token。
对于中文:1 个汉字 ≈ 1.5 - 2 个 Token,1000 个 Token 大约相当于 500-700 个汉字。常见的例子,上下文窗口就像一个固定大小的工作台,再把 Token 比作一个个积木零件,把大模型比作一个工匠。工匠需要拼接的部分(输出的 Token)也放在工作台上。整个过程(输入 + 输出)中,工作台上的所有积木(Tokens)总数都不能超过工作台的最大容量(上下文窗口大小)。
如果最初的零件太多,占满了工作台,工匠就没有空间进行拼装了。这时你就需要减少零件(精简输入)。
也就是说:AI 上下文窗口的计量单位,就是 Token!
消息裁剪
有了上下文窗口和 Token 的认知,再来看多轮对话的实现原理,其实就是:
输入 = 系统消息 + 对话历史 + 最新用户问题
对于模型来说,并不真正 “记忆”,而是每次都将完整的上下文重新输入。由于所有模型的上下文窗口大小都是有限的,这意味着作为输入的 Token 也是有限的。如果累积了很长的消息历史,则需要管理传递给模型的消息的长度。
trim_messages 可用于将聊天历史记录的大小减小为指定的令牌数或指定的消息计数。
本质原理是: trim_messages 在裁剪聊天历史时,默认会保留最顶部的系统消息绝不删除,只会从系统消息之后最早的用户与助手历史消息开始,从头依次移除老旧对话,直到整体总 Token 数量或消息条数压缩到设定上限为止,始终保护 AI 人设、规则类的系统提示不被裁剪,只舍弃过时的聊天上下文,既控制住上下文窗口大小,又不破坏模型基础设定和最新对话逻辑。
基于输入 Token 数的修剪
下面演示一个通过 trim_messages 裁剪消息的示例(基于输入 Token 数的修剪)。
先来看不做任何输入限制的聊天:
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain.messages import trim_messages
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 历史消息记录
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="what's my name"),
]
print(model.invoke(messages))
打印结果:
content="Your name is Bob."
additional_kwargs={}
response_metadata={
'token_usage': {
'completion_tokens': 5,
'prompt_tokens': 88,
'total_tokens': 93,
'completion_tokens_details': {'accepted_prediction_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0},
'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}
},
'model_name': 'gpt-4o-mini-2024-07-18',
'system_fingerprint': 'fp_51db2b04af',
'finish_reason': 'stop',
'logprobs': None
}
id='run-6f8eb5dc-69dc-4dbe-8109-d0e9991f9fe-0'
usage_metadata={
'input_tokens': 88,
'output_tokens': 5,
'total_tokens': 93,
'input_token_details': {'audio': 0, 'cache_read': 0},
'output_token_details': {'audio': 0, 'reasoning': 0}
}
从打印结果看来,LLM 还认识我们,且共输入了 88 个 tokens。接下来让我们对消息进行裁剪,我们只希望将来输入时,最多输入 65 个 tokens,超出的需要按照一定的 “规则” 进行裁剪,代码如下:
# 导入OpenAI聊天模型(对接GPT-4o-mini)
from langchain_openai import ChatOpenAI
# 导入三种消息类型:系统消息、人类消息、AI消息
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# 导入消息裁剪工具(核心:裁剪聊天历史)
from langchain.messages import trim_messages
# --------------------------
# 1. 定义大模型
# --------------------------
model = ChatOpenAI(model="gpt-4o-mini")
# --------------------------
# 2. 完整的历史对话记录
# --------------------------
messages = [
# 系统消息:设定AI的角色/规则(最重要,不会被随便删掉)
SystemMessage(content="you're a good assistant"),
# 一轮轮对话:用户说 → AI回复
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
# 最后用户提问:我的名字是什么?(需要靠历史记忆回答)
HumanMessage(content="what's my name?"),
]
# --------------------------
# 3. 创建消息裁剪器(核心!)
# --------------------------
trimmer = trim_messages(
max_tokens=65, # 限制总token不超过65(超过就裁剪)
strategy="last", # 裁剪策略:保留【最近】的消息,删掉【最早】的
token_counter=model, # 用模型自带的分词器算token(最准确)
include_system=True, # ✅ 关键:保留系统消息,不裁剪系统提示
allow_partial=False, # 不允许截断单条消息,要么整条保留,要么整条删掉
start_on="human", # 保证裁剪后的消息列表,以【用户消息】开头(符合对话格式)
)
# --------------------------
# 4. 构造执行链:裁剪 → 送给模型
# --------------------------
chain = trimmer | model
# --------------------------
# 5. 执行:自动裁剪历史 → 发送给AI → 输出结果
# --------------------------
print(chain.invoke(messages))打印结果:
content="I don't know your name. Would you like to share it with me?"
additional_kwargs={}
response_metadata={
'token_usage': {
'completion_tokens': 16,
'prompt_tokens': 60,
'total_tokens': 76,
'completion_tokens_details': {'accepted_prediction_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0},
'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}
},
'model_name': 'gpt-4o-mini-2024-07-18',
'system_fingerprint': 'fp_880a1f5gpzyKPrvwvecXJniM',
'finish_reason': 'stop',
'logprobs': None
}
id='run-f0e007b7-54b5-4910-bb45-4a725a633c77-0'
usage_metadata={
'input_tokens': 60,
'output_tokens': 16,
'total_tokens': 76,
'input_token_details': {'audio': 0, 'cache_read': 0},
'output_token_details': {'audio': 0, 'reasoning': 0}
}
可以看见,此时我们的输入 message 已经被修剪了。被修剪了哪些消息呢?来看下:
trimmer = trim_messages(
max_tokens=65,
strategy="last",
token_counter=model,
include_system=True,
allow_partial=False,
start_on="human",
)
# 打印经过裁剪器裁剪后的结果
print(trimmer.invoke(messages))
结果如下:
[
SystemMessage(content="you're a good assistant", additional_kwargs={}, response_metadata={}),
HumanMessage(content="whats 2 + 2", additional_kwargs={}, response_metadata={}),
AIMessage(content="4", additional_kwargs={}, response_metadata={}),
HumanMessage(content="thanks", additional_kwargs={}, response_metadata={}),
AIMessage(content="no problem!", additional_kwargs={}, response_metadata={}),
HumanMessage(content="having fun?", additional_kwargs={}, response_metadata={}),
AIMessage(content="yes!", additional_kwargs={}, response_metadata={}),
HumanMessage(content="what's my name?", additional_kwargs={}, response_metadata={})
]
从结果来看,确实是按照我们设定的裁剪 “规则” 来完成的。修剪聊天记录后,生成的聊天记录(输入)应该有效,需要遵循对话模式原则:
-
聊天记录以
HumanMessage或SystemMessage开头,后跟HumanMessage。这可以通过设置start_on="human"来实现。 -
聊天记录以
HumanMessage或ToolMessage结尾。这可以通过设置ends_on="human"、"ai"、"tool"来实现。 -
ToolMessage只能出现在涉及工具调用的AIMessage之后。 -
如果原始聊天记录中存在
SystemMessage,则新聊天历史记录应包括SystemMessage总是历史记录中的第一条消息(如果存在)。这可以通过设置include_system=True。
基于消息数的修剪
除了基于 Token 的修剪,还可以通过设置 token_counter=len 根据消息数修剪聊天记录。在这种情况下,max_tokens 将控制最大消息数。示例如下:
# 导入对接 OpenAI GPT 的聊天模型
from langchain_openai import ChatOpenAI
# 导入 LangChain 内置的三种消息类型:系统消息、用户消息、AI 消息
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# 导入消息裁剪工具 trim_messages(核心:自动裁剪超长对话历史)
from langchain.messages import trim_messages
# 1. 初始化大模型(这里只是用来演示,实际裁剪不一定需要模型运行)
model = ChatOpenAI(model="gpt-4o-mini")
# 2. 构造一段完整的对话历史
# 结构:系统提示 + 多轮用户与AI对话 + 最后一个问题
messages = [
# 系统消息:设定 AI 角色(会被保护)
SystemMessage(content="you're a good assistant"),
# 历史对话 1
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
# 历史对话 2
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
# 历史对话 3
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
# 历史对话 4
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
# 历史对话 5
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
# 最后一轮用户提问(最新消息)
HumanMessage(content="what's my name?"),
]
# 3. 创建消息裁剪器(核心配置)
trimmer = trim_messages(
max_tokens=6, # 限制总长度不超过 6 个单位
strategy="last", # 保留【最近】的消息,删掉【最早】的
token_counter=len, # 用【字符串长度】来计算长度(不是真实token,只是简单计数)
include_system=True, # 保留系统消息,不删除系统提示
allow_partial=False, # 不允许把一条消息截断,必须整条保留或整条删除
start_on="human", # 裁剪后的消息列表必须以【用户消息 HumanMessage】开头
)
# 4. 执行裁剪,输出结果
print(trimmer.invoke(messages))结果如下:
[
SystemMessage(content="you're a good assistant", additional_kwargs={}, response_metadata={}),
HumanMessage(content="I like vanilla ice cream", additional_kwargs={}, response_metadata={}),
AIMessage(content="nice", additional_kwargs={}, response_metadata={}),
HumanMessage(content="whats 2 + 2", additional_kwargs={}, response_metadata={}),
AIMessage(content="4", additional_kwargs={}, response_metadata={}),
HumanMessage(content="thanks", additional_kwargs={}, response_metadata={}),
AIMessage(content="no problem!", additional_kwargs={}, response_metadata={}),
HumanMessage(content="having fun?", additional_kwargs={}, response_metadata={}),
AIMessage(content="yes!", additional_kwargs={}, response_metadata={}),
HumanMessage(content="what's my name?", additional_kwargs={}, response_metadata={})
]
消息过滤
在复杂的场景下,我们可能会使用历史记录来跟踪状态,例如我们可能只想将整个消息列表的子集传递给模型,而不是所有的历史记录。
filter_messages 支持过滤消息。下面演示支持的过滤方法,首先准备消息列表:
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# 历史消息记录
messages = [
SystemMessage(content="你是一个聊天助手", id="1"),
HumanMessage(content="真实输入", id="2"),
AIMessage(content="真实输出", id="3"),
HumanMessage(content="测试输入", id="4"),
AIMessage(content="测试输出", id="5"),
]
- 按类型进行筛选
print(filter_messages(messages, include_types="human"))
结果如下:
# 注:该写法等价于
# filter_messages(messages, include_types=["human"]).invoke(messages)
[
HumanMessage(content='真实输入', additional_kwargs={}, response_metadata={}, id='2'),
HumanMessage(content='测试输入', additional_kwargs={}, response_metadata={}, id='4')
]
- 按类型 ID 进行筛选
print(filter_messages(messages, include_types=[HumanMessage, AIMessage], exclude_ids=["3"]))
结果如下:
[
HumanMessage(content='真实输入', additional_kwargs={}, response_metadata={}, id='2'),
HumanMessage(content='测试输入', additional_kwargs={}, response_metadata={}, id='4'),
AIMessage(content='测试输出', additional_kwargs={}, response_metadata={}, id='5')
]
消息合并
若我们的消息列表中连续两次使用相同的消息,但实际上模型并不支持合并相同类型的连续消息。因此为了改变情况,我们可以使用 merge_message_runs 来合并相同类型的连续消息。示例如下:
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain.messages import merge_message_runs
# 定义大模型
model = ChatOpenAI(model="gpt-4o-mini")
# 历史消息记录
messages = [
SystemMessage(content="你是一个聊天助手。"),
HumanMessage(content="你什么时候使用 LangChain?"),
HumanMessage(content="为什么我要使用 LangGraph?"),
AIMessage(content="因为当你做你的代码更有条理时,LangChain 会让你做到"),
AIMessage(content="这时候使用 LangGraph 时,LangGraph 会让你做到节点是个好主意!"),
HumanMessage(content="不过,它会分散你的注意力!"),
]
merged = merge_message_runs(messages)
print("合并后" + "\n".join([repr(x) for x in merged]))
合并结果:
[
SystemMessage(content='你是一个聊天助手。', additional_kwargs={}, response_metadata={}),
HumanMessage(content='你什么时候使用 LangChain?为什么我要使用 LangGraph?', additional_kwargs={}, response_metadata={}),
AIMessage(content='因为当你做你的代码更有条理时,LangChain 会让你做到节点是个好主意!这时候使用 LangGraph 时,LangGraph 会让你做到节点是个好主意!', additional_kwargs={}, response_metadata={}),
HumanMessage(content='不过,它会分散你的注意力!', additional_kwargs={}, response_metadata={})
]
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)