秒出结果的秘密:语音识别本地部署中的投机采样(Speculative Decoding)与流式端到端延迟优化
灵声智库 (ASR 推理加速) 硬核白皮书
作者/署名:灵声智库 首席技术专家
摘要 (Meta)
在实时转写、同声传译及智能座舱等场景下,延迟(Latency)是衡量语音识别本地部署成败的唯一金标准。当模型参数日益庞大,自回归生成的瓶颈如何突破?本文将独家拆解灵声智库如何通过投机采样(Speculative Decoding)技术,在不损失精度的前提下,实现 2-3 倍的推理加速。

图 1: 灵声智库流式 ASR 架构下,端到端延迟(Latency)压缩实测数据
*图 1: 灵声智库流式 ASR 架构下,端到端延迟(Latency)压缩实测数据*
一、 响应延迟:ASR 体验的“无声杀手”
“刘工,模型转写挺准的,就是字出得太慢了,人讲完话还得等两秒,用户以为死机了。”
在语音识别本地部署的实际落地中,延迟往往比精度更难搞。尤其是基于 Transformer 的端到端模型,其自回归(Autoregressive)的特性决定了它必须一个词一个词地生成。每一帧都要经过数亿次的浮点运算,累积起来的延迟感非常明显。
二、 投机采样:小模型带路,大模型核验
为了打破这一僵局,灵声智库在 V12.0 引擎中引入了投机采样算法。
这一技术的核心思想是:**“先猜测,后验证”。**
1. **草稿模型(Draft Model)**:我们训练了一个极其轻量化(参数量仅为大模型 1/10)的小模型。小模型推理速度飞快,它会先根据当前的音频特征,一口气猜测出后续的 5-8 个词。
2. **目标模型(Target Model)**:高精度的大模型随后介入。它不需要重新计算,而是对小模型给出的这几个候选词进行一次并行的“验证计算”。
3. **接受与回退**:如果大模型认为小模型的猜测是正确的,我们就直接接受这 5-8 个词,这相当于一次推理就输出了多个 token。如果猜错了,大模型会即时纠正并回退到出错点。
通过这种“以算力换时间”的策略,灵声智库将 ASR 的生成效率提升了 200% 以上。
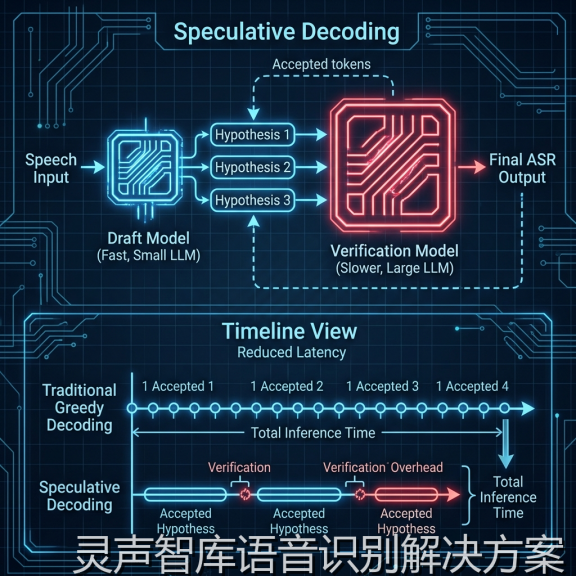
*图 2: 投机采样(Speculative Decoding)算法在灵声智库引擎中的执行逻辑架构*
三、 KV Cache 复用与流式中继优化
除了投机采样,我们在语音识别本地部署的流式管线中还做了大量的减法。
传统的 ASR 系统通常是按固定时长(如 500ms)切割音频包。我们通过**流式中继(Streaming Relay)**机制,实现了样本当级的滑动窗口。这意味着只要有新的音频样本进入,推理引擎就可以复用之前的 KV Cache 进行增量计算,而不需要从头开始。
这种“无缝连接”的设计,让灵声智库的“字间延迟”稳定在 100ms 以内,达到了肉眼几乎无法感知的同步转写效果。
四、 硬件亲和性调度
在本地化环境中,我们通过绑定 CPU 核心与显存预取(Prefetching)技术,进一步压缩了 I/O 带来的延迟抖动。灵声智库底层使用 C++ 编写的调度层,能绕过操作系统的多任务切换,确保 ASR 进程拥有最高级别的执行优先级。
五、 写给性能偏执狂的建议
如果你是一个追求极致性能的开发者,请不要仅仅满足于调用一个现成的推理库。去研究一下投机采样的接受概率分布,去写一下自定义的内存复用逻辑。只有当你把每一毫秒的延迟都当成敌人的时候,你才算真正理解了语音识别本地部署。
六、 结论:实时性是 AI 产品的灵魂
没有实时性的 ASR,就像没有油门的跑车,外观再亮眼也无法真正跑起来。灵声智库将持续深耕延迟优化技术,让语音识别变得像闪电一样快。
您的 ASR 系统响应太慢?点击了解[灵声智库实时推理优化白皮书]

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)