CCCaption: Dual-Reward Reinforcement Learning for Complete and Correct Image Captioning(CVPR 2026)
研究方向:Image Captioning
1.方法介绍
本文提出字幕质量应该通过两个客观方面来评估:
1)完整性(字幕是否涵盖了所有显著的可视事实?)
2)正确性(描述与图像是否相符?)
本文提出CCCaption:一个双重奖励强化学习框架,并配备了一个专门的微调语料库,明确优化这些属性以生成完整且正确的字幕。
1)为确保完整性,使用多样的大型语言模型来区分图像中的不同可视查询,并对回答更多查询的字幕给予奖励,采用动态查询采样策略以提高训练效率。
2)为确保准确性,通过验证从标题分解中得出的子标题查询的真实性来惩罚包含幻觉的标题。
对称双奖励优化联合最大化了完整性和准确性,引导模型生成更好地满足这些客观标准的标题。
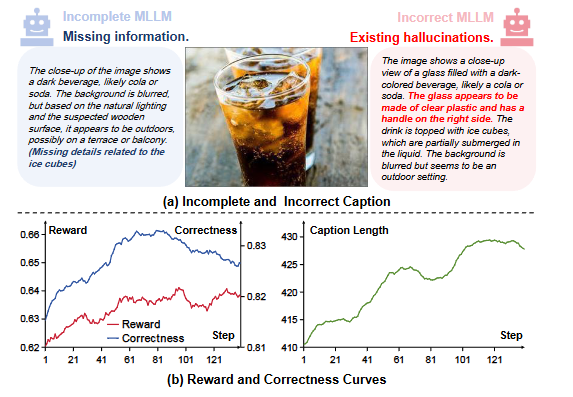
如图(a)所示,完整性要求涵盖显著的视觉事实(例如,左边的字幕不完整因为它省略了冰块)。正确性要求具有基于图像的事实性(例如,右边的字幕提到了关键内容但错误地将容器识别为有把手的塑料杯,从而违反了正确性)。
如图(b)所示,即使在奖励持续增加的情况下,标题的正确性在后期训练阶段显著下降。这种差异表明,标题学会在回答查询的同时幻想出查询未约束的细节,从而夸大了奖励但降低了事实性。
2.论文介绍
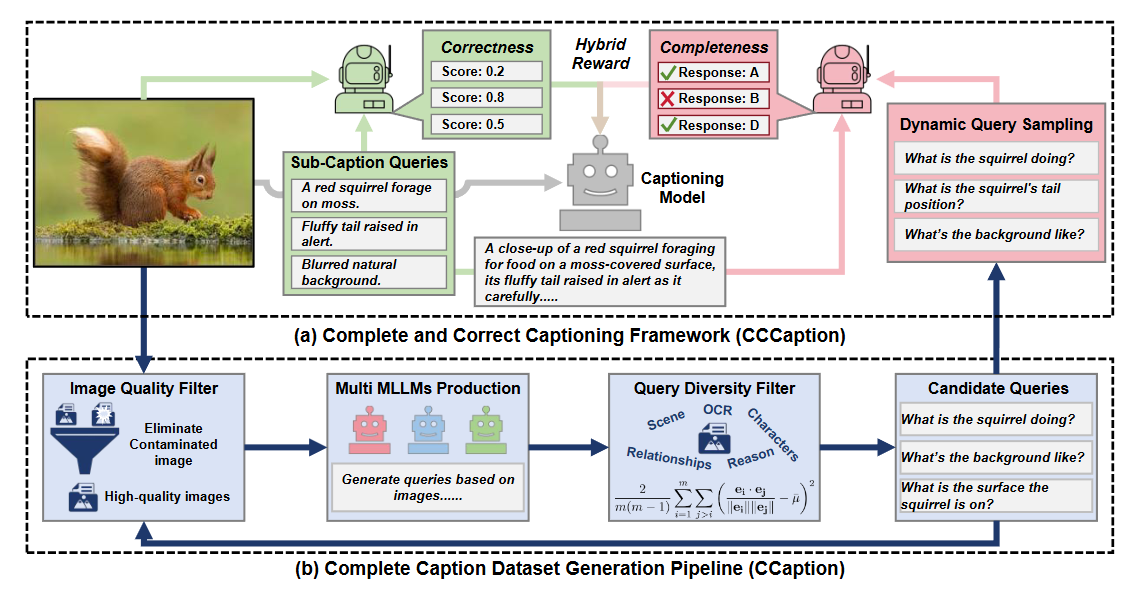
(1) 首先,我们使用多样的MLLMs将图像分解为一系列视觉查询。通过引入多样性度量(即查询的方差越大,查询的多样性越大)以及附加规则(例如,查询的有效性和相关性),我们过滤掉低质量查询。经过反复迭代,获得完全捕捉图像信息的完整查询。最后,构建了包含44k样本的完整标题训练数据集,命名为CCaption-44k。此外,我们在训练过程中设计了一种动态查询采样策略,提高了多样查询(即优势较高的查询)的采样概率,以提高训练效率。
(2)就正确性而言,我们对包含幻觉的标题进行惩罚。在先前的工作的基础上,我们将长标题分解成子标题查询,这些查询包括标题的基本信息。然后,将原子查询与原始图像一起输入到MLLM中,使模型能够对原子查询中的幻觉进行评分,从而为标题提供正确性奖励。
2.1 预备知识与概念定义
传统方法的局限性:传统的图像描述模型通常使用最大似然估计(MLE)来进行监督学习,从而学习条件分布 。但是,当作为参考的人类标注存在偏差或不完整时,模型就无法生成理想的描述 。
强迫模型去最大化生成人类参考答案 的概率。但问题在于,如果人类标注不完整或有偏差,模型也只会照单全收 。
强化学习的引入:为了摆脱对参考文本的单纯模仿,作者引入了强化学习来最大化期望奖励 。
强化学习的标准公式。它的目标是调整模型参数 ,使得模型在看到图像
时,倾向于生成那些能获得高奖励分数
的描述
。
完整性与正确性的数学定义: 作者将图像的真实信息定义为集合,将模型生成的描述包含的信息定义为集合
。
完整性得分 ():衡量生成的描述覆盖了多少图像真实信息,即
。
正确性得分 ():衡量生成的描述中有多少是真实存在于图像中的(没有幻觉),即
。
核心痛点:在实际操作中,真实的“基础信息集合”是无法直接观测和计算的 。因此,作者在 2.2 节提出了可计算的近似方案 。
2.2 CCCaption 框架核心机制
为了在训练中实际应用这两个指标,作者设计了双重奖励机制,并引入了动态查询采样策略。
1. 完整性奖励 (Completeness Reward)
为了近似代表图像的全部信息 Bx,作者使用了一组视觉查询问题(Visual Queries)集合 Qx 。
奖励计算:如果第三方裁判模型(Judge Model)能根据生成的描述正确回答出这些查询问题,模型就会获得奖励 。公式如下:
-
: 针对图像
生成的问题集合(比如“图里有几只猫?”)。
-
: 冻结的第三方裁判模型(Judge Model)。它负责只看生成的描述
来回答问题
。
-
: 指示函数。如果裁判模型根据 $\hat{y}$ 成功答对了
-
含义:如果你生成的描述写得足够详尽,裁判模型光看你的描述就能回答出关于图片的各种问题。答对的问题越多,你的完整性奖励
就越高 。
多模型生成与多样性过滤 (Multi-MLLMs & Diversity):CCCaption 引入了基于 embedding 向量的多样性指标 V 。他们使用多个大型多模态模型(MLLMs)生成问题,并过滤掉低质量或重复的问题,最终构建了包含 4.4 万样本的训练集 CCaption-44k 。
如果提问集合 里的问题全是同质化的(比如一直问猫的颜色),那完整性奖励就失去了意义 。因此需要衡量提问的多样性:
-
: 问题
和
的文本嵌入向量(Embedding vector)。
-
: 两个问题向量之间的余弦相似度(Cosine Similarity),用来衡量两个问题有多相似 。
-
: 所有问题对(Pairs)之间余弦相似度的平均值 。
-
含义:这个公式本质上是在计算问题相似度的方差。方差越大,说明问题之间差异越大,覆盖的面越广(即多样性好)。如果方差低于设定阈值,算法就会剔除冗余问题 。
2. 正确性奖励 (Correctness Reward)
为了惩罚幻觉(Hallucinations),作者通过将生成的描述 拆解为多个子查询问题(Sub-caption queries)集合
,以此来近似表示生成的描述信息
。
奖励计算:让裁判模型直接看着原图,来评估这些由生成的描述转化而来的“子问是否在图像中真实存在(Grounding)。得分越高,说明幻觉越少 。公式如下:
-
: 由生成的描述
-
: 裁判模型直接看着原图
之间的软评分。
-
含义:模型吹的牛越多(产生幻觉),裁判模型在原图中找不到对应证据的概率就越大,正确性奖励
就会越低 。
3. 动态查询采样策略 (Dynamic Query Sampling)
在强化学习(特别是 GRPO 框架)中,如果每次都用所有的问题进行训练,效率会很低 。
原因:有些问题太简单,模型每次都能答对,这些问题提供的梯度非常微小,对训练没有帮助 。
解决方案:引入基于伯努利分布的动态采样公式 。随着训练的进行,那些信息量低(总是答对或总是答错)的问题被采样的概率会逐渐降低 。这样不仅增加了有价值样本的权重,还显著提升了训练效率 。
-
: 候选问题集合 。
-
: 对问题
。
-
-
含义:动态过滤掉那些对模型提升没有帮助的“废话问题”,增加那些模型偶尔答对偶尔答错的“争议性问题”的采样率,以此提高训练效率 。
4. 总体目标 (Overall Objective)
最后,模型将上述两种奖励通过权重参数 (
)进行线性组合,形成最终的混合强化学习奖励 :
这个综合奖励会被代入到强化学习的目标函数中,用于不断优化模型生成既全面又准确的图像描述 。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)