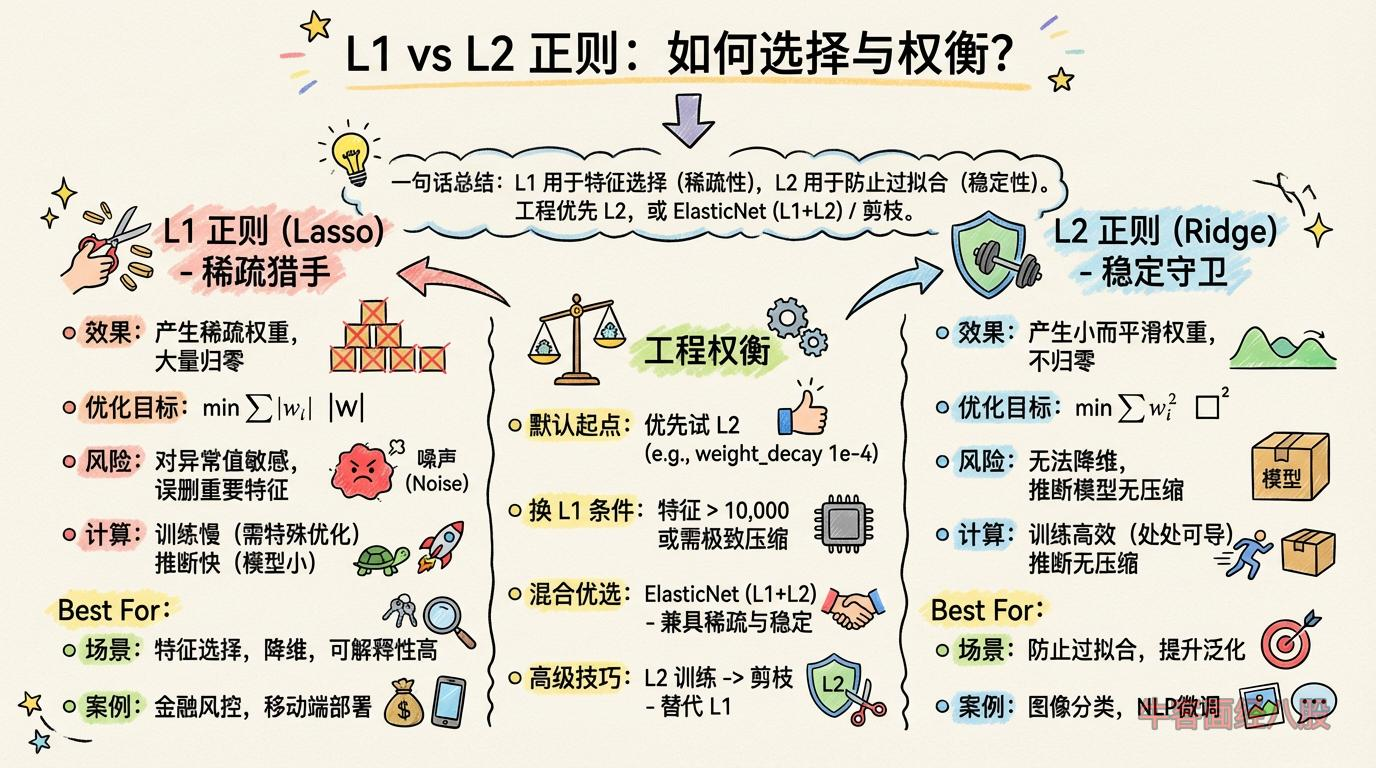
L1正则化 vs L2正则化
正则化
1. 欠拟合、正常情况、过拟合
模型的训练在训练集上表现很好,但是在测试集上效果不佳,这就是模型过拟合
(1)一起回顾一些知识点:
- 欠拟合:则是指模型过于简单,无法捕捉数据中的主要模式,导致训练集和测试集上的表现都很差。例如,用线性回归拟合非线性数据时,模型可能无法反映数据的复杂关系。
- 过拟合:这通常是因为模型过于复杂,记住了训练数据中的噪声或细节,导致泛化能力不足。例如,在房价预测中,过拟合的模型可能记住了某些特定房屋的价格,而忽略了特征间的普遍关系。
具体情况如图所示:
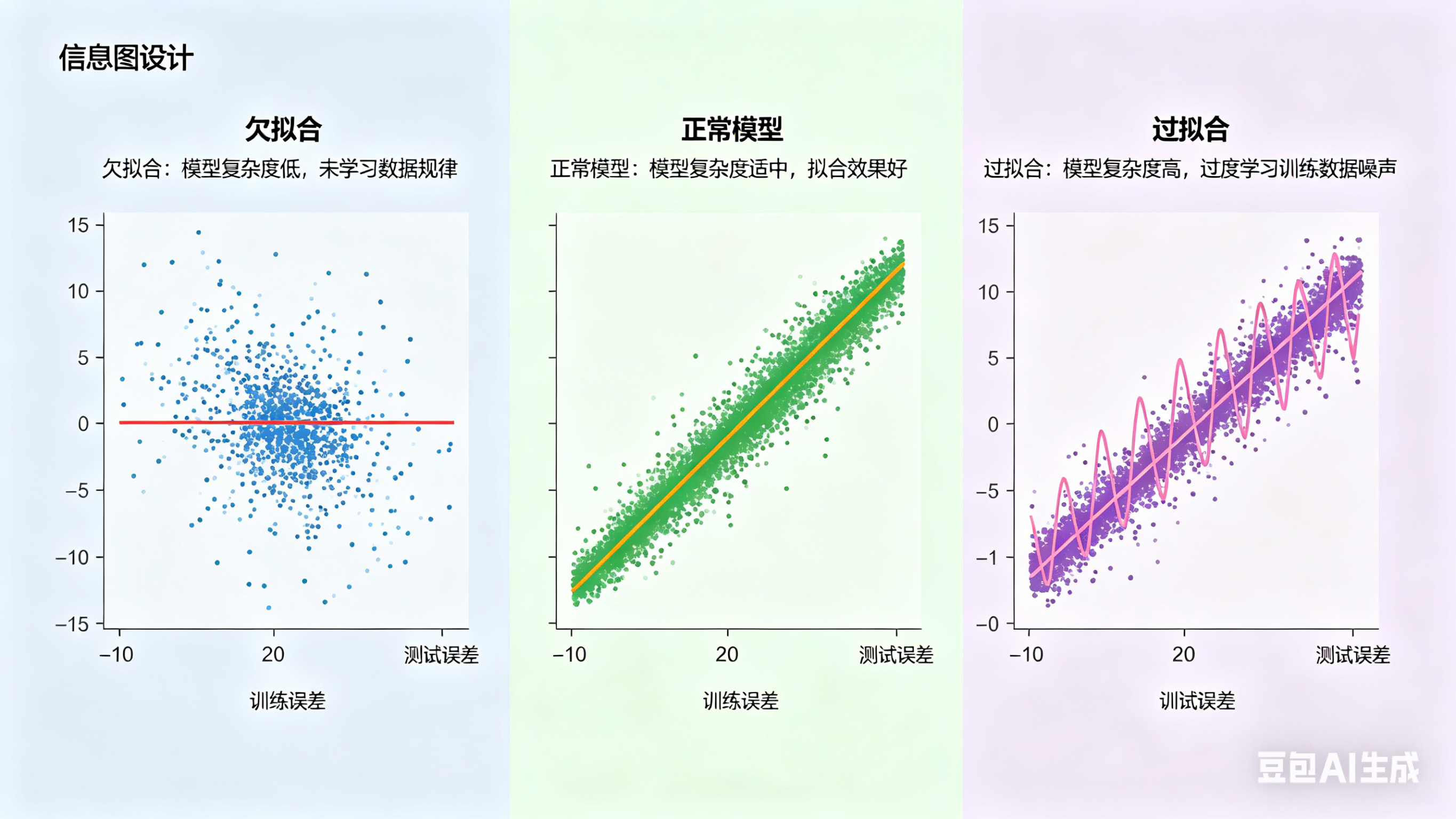
(有其他博客发过的图可能更好理解这里引用一下,如下图,原博客来源:)【机器学习】一文彻底搞懂正则化(Regularization)-CSDN博客![]() https://blog.csdn.net/Zlyzjiabjw547479/article/details/149189783
https://blog.csdn.net/Zlyzjiabjw547479/article/details/149189783
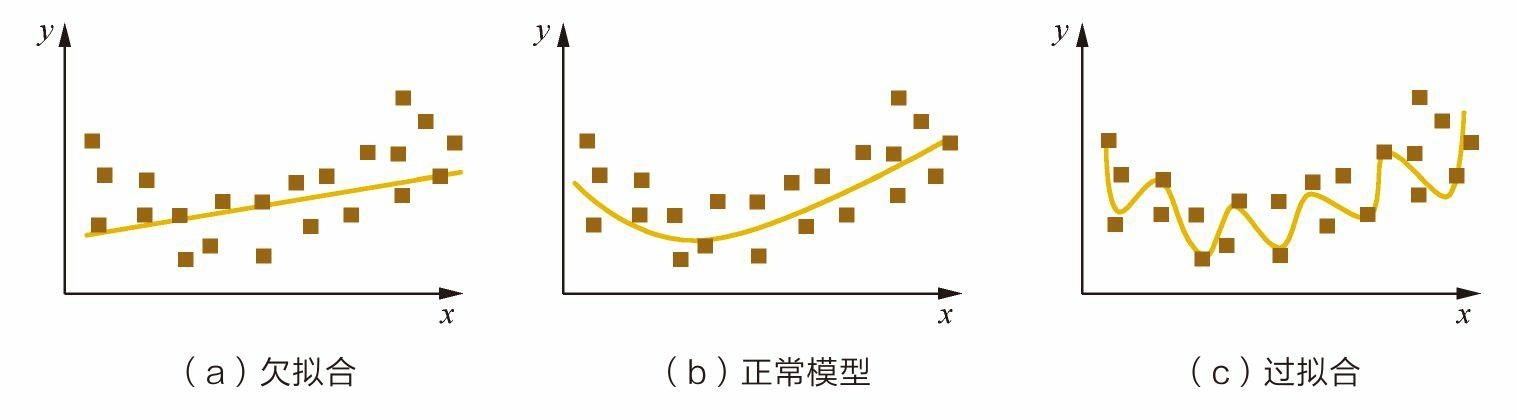
(2)面对这两种情况应对方案如下:
| 欠拟合 |
1. 增加模型复杂度(如增加层数或神经元数量) 2. 提供更多有意义的特征 3. 减少正则化力度 4. 延长训练时间或调整学习率 |
| 过拟合 |
1. 增加训练数据 2. 使用正则化(如L1或L2正则化) 3. 减少模型复杂度(降低参数数量或深度) 4. 使用Dropout层随机丢弃部分神经元 5. 数据增强(如图像旋转、缩放等) |
2. 正则化
因为训练时会学习到其他噪声导致过拟合,所以就要给模型加 “约束惩罚”,不让参数变得过大、不让模型太复杂,强迫模型学习通用规律,而不是死记噪声。这就是正则化。
正则化公式:
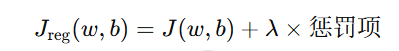
(J(w,b)是拟合误差)
L1、L2对比
1. L1、L2性能对比
| 方面 | L1(Lasso) | L2(Ridge) |
|
效果本质 |
产生稀疏权重(大量权重归零) | 产生小而平滑的权重(权重接近零但不归零) |
| 公式 | 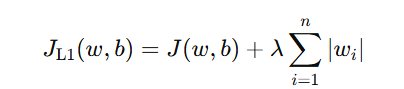 |
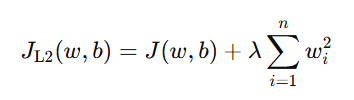 |
| 梯度特性 | 在0处不可导(次梯度下降),优化更复杂 | 处处可导,梯度下降稳定 |
| 抗噪声能力 | 弱(对异常值敏感,可能错误删除重要特征) | 强(对异常值鲁棒,权重均匀缩小) |
| 计算效率 | 高稀疏模型推断快,但训练可能慢(需特殊优化器) | 训练高效(兼容所有优化器),推断时模型无压缩 |
| 优化目标 |
min( s.t. |
min( s.t. |
|
示意图 约束域 |
(L1 约束是有棱角菱形:损失等高线优先卡在棱角,直接把部分权重压为 0,实现稀疏。) |
(L2 约束是光滑圆:切点一般不在坐标轴,所有权重都不为 0,只变小。) |
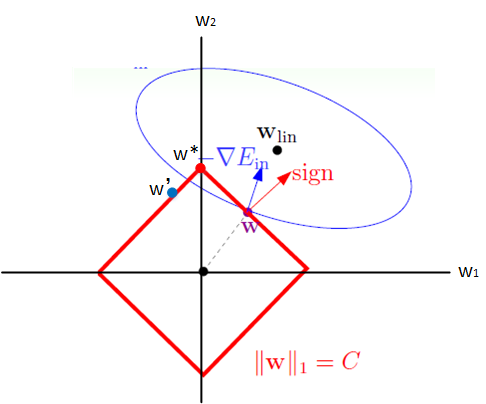
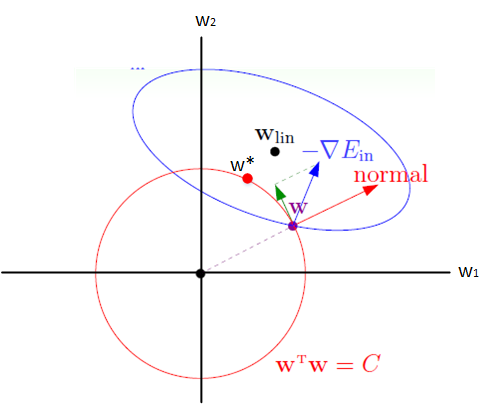
补充:结合 L1 稀疏 + L2 平滑的优点得到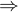 L1+L2 弹性网 Elastic Net
L1+L2 弹性网 Elastic Net
公式:
2.选择策略
(1)提升泛化能力,防止过拟合,且所有特征都可能有用。————————————首选L2
①案例:
- 图像分类(ResNet)、NLP 预训练模型(BERT)的微调。
- 数据维度不高(特征数 < 1000)的回归任务。
②收益:验证集误差降低 5%~10%,训练曲线更平滑。
③实现代码:
# PyTorch 示例(直接在优化器权重衰减项实现 L2)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-5)(2)特征选择(降维)、模型压缩或可解释性要求高。———————————————首选L1
①案例:
- 金融风控(需明确哪些特征决策)、高维基因数据筛选关键特征。
- 移动端部署需减少模型参数量的场景。
②收益:特征数量减少 80%+,模型尺寸缩小 50% 但精度仅损失 1%~2%。
③实现代码:
# 手动添加 L1 损失(注意:优化器需支持,或自己实现近端梯度)
l1_loss = lambda * torch.norm(weight, 1)
total_loss = ce_loss + 0.01 * l1_loss(3)兼具特征选择与稳定性的需求,且数据强相关。—————混合使用 ElasticNet(L1+L2)
①案例:广告 CTR 预估中,特征存在多重共线性(如用户年龄与收入段)。
②收益:比纯 L1 更稳定,比纯 L2 更稀疏。
③实现代码:
# sklearn 示例(线性模型)
from sklearn.linear_model import ElasticNet
model = ElasticNet(alpha=0.1, l1_ratio=0.5) # l1_ratio 控制 L1/L2 混合比例3.工程中的权衡经验
- 默认起点:
优先试 L2(weight_decay 设 1e-4 到 1e-2),因其稳定且易调参,大多数深度学习任务有效。 - 换 L1 的条件:
- 特征数 > 10,000(如文本 TF-IDF 特征),且怀疑大量特征无关。
- 模型部署需极致压缩(如嵌入式设备)。
- 避坑指南:
- L1 的风险:可能因噪声删错特征,需交叉验证确认稳定性。
- L2 的风险:无法降维,推断时模型体积无变化。
- 高级技巧:
用 L2 训练后,对权重剪枝(pruning)替代 L1——同样达到稀疏性,且训练更稳。
总结
- L1 用于特征选择(要稀疏性),L2 用于防止过拟合(要稳定性)
- 工程中常优先 L2,仅当特征维度高且需压缩模型时才加入 L1,最优解常用 ElasticNet(L1+L2)或直接试 L2 剪枝。
说明:该内容用于学习,部分内容来源链接:2025年-京东-算法/AI岗高频面试题 (nowcoder.com)![]() https://www.nowcoder.com/exam/interview/96648758/test?paperId=63848762&order=0
https://www.nowcoder.com/exam/interview/96648758/test?paperId=63848762&order=0

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)