基于 vLLM Sleep 技术的多模共算实战教程
一、技术背景与痛点
1.1 传统多模型部署的困境
在大模型应用落地过程中,我们经常面临这样的场景:
- 智能体工作流:需要顺次调用多个不同能力的模型(代码模型、对话模型、多模态模型)
- 一体机/边缘设备:算力有限,无法为每个模型单独分配 GPU
- vGPU :模型通过多实例共存,但模型之间存在算力抢占,且部署数量有限
1.2 vLLM Sleep 模式
vLLM 作为高性能大模型推理引擎,从 v0.6.0 版本开始引入了 Sleep mode。其核心原理:
│ 活跃模型 ──→ 占用显存进行推理计算 │
│ ↓ │
│ Sleep ────→ 将 KV Cache 卸载到 CPU 内存(保留激活在显存),释放 GPU 显存 │
│ ↓ │
│ Wake Up ──→ 从 CPU 内存恢复 KV Cache 到 GPU,快速恢复服务 │
关键优势:
- 睡眠中的模型几乎不占用 GPU 显存(仅保留极小激活值)
- 唤醒速度快(秒级),用户感知不明显
- 单卡可同时部署多个大参数模型,按需唤醒使用
二、核心技术亮点
2.1 多模型快速切换架构
通过模型睡眠/唤醒机制,实现同设备多模型快速切换:
# 核心切换逻辑示意
class MultiModelCoordinator:
def switch_model(self, target_model_port: int):
# 1. 当前模型暂停(Pause)
self.pause_current_model()
# 2. 当前模型睡眠(Sleep)
self.sleep_current_model()
# 3. 目标模型唤醒(Wake Up)
self.wake_target_model(target_model_port)
# 4. 恢复服务
return self.get_model_response()适用场景:
- 🤖 智能体链式调度:规划 Agent → 代码 Agent → 总结 Agent 无缝切换
- 🖥️ 一体机部署:单台设备提供多模型能力
- 💰 经济型算力:最大化利用有限 GPU 资源
2.2 与 vGPU/卡级部署的对比
|
vGPU/卡级隔离 |
vLLM Sleep 多模共算 |
|
|
部署数量 |
受限于虚拟化分区 |
单机能部署的都能部署 |
|
显存占用 |
每个模型独占分区 |
仅活跃模型占用显存 |
|
算力利用 |
存在抢占和闲置 |
100% 利用,无抢占 |
|
模型大小 |
受分区限制 |
正常单机可部署即可 |
|
切换延迟 |
无需切换(并行) |
秒级唤醒(可接受) |
单机能部署下的大模型,多模共算场景也基本可以部署,只需预留一点点其他模型的激活值显存。
2.3 华为昇腾生态适配
在910系列在执行跨卡任务时经常会出现HCCL复用报错,导致很多场景无法实现(例如:1、2/2、3同时起;1、2、3、4/1、2同时起等)。CANN官方给了以下两个环境变量,可以在同卡跨卡任务时,避免重复HCCL端口:
export HCCL_HOST_SOCKET_PORT_RANGE="auto"
export HCCL_NPU_SOCKET_PORT_RANGE="auto"2.4 鲁棒性、稳定性增强:Pause/Resume 机制
直接使用 vLLM 的 Sleep/Wake Up 接口存在稳定性风险:
- 模型正在处理请求时直接 Sleep 可能导致状态异常
- 昇腾处理器可能出现指令冲突导致服务崩溃
因此引入了开发者模式下的模型服务暂停机制,用于保证模型切换前模型无在途请求。
# 910B 解决pause打断不生效需要配置如下变量
export COMPILE_CUSTOM_KERNELS=1
# pause相关指令
curl -X POST 'http://0.0.0.0:8000/pause'
curl -X POST 'http://0.0.0.0:8000/pause?wait_for_inflight_requests=True'
curl -X POST 'http://0.0.0.0:8000/resume'*鲁棒性测试记录:
1)模型处于sleeping状态,向该模型发送问题;导致睡眠服务端报错,进程中断❌
2)模型处于sleeping状态,该模型所在节点剩余显存不足(其他任务),向该模型发送唤醒命令;导致睡眠服务端报错,进程中断❌
3)模型处于wakeup状态,正在处理请求,向模型发送睡眠命令;模型服务端报错,进程中断❌
4)模型处于wakeup状态,正在处理请求,向模型发送pause请求(不等当前请求完成),请求侧返回报错(请求提前终止),模型侧正常暂停;再次发送resume后,模型恢复正常,可以对话✅
5)模型处于wakeup状态,正在处理请求,向模型发送pause请求(等当前请求完成),请求侧正常回答完,模型侧正常暂停;再次发送resume后,模型侧恢复正常,可以对话✅
6)模型处于paused状态,向该模型发送睡眠请求,可以睡眠,但再次发送唤醒请求,模型服务端报错,进程中断❌
7)模型处于paused状态,向模型发送resume请求,请求成功后再向该模型发送睡眠请求,可以睡眠,再次发送唤醒请求,模型服务成功拉起✅
三、性能表现
3.1 项目整体流程
服务端流程图
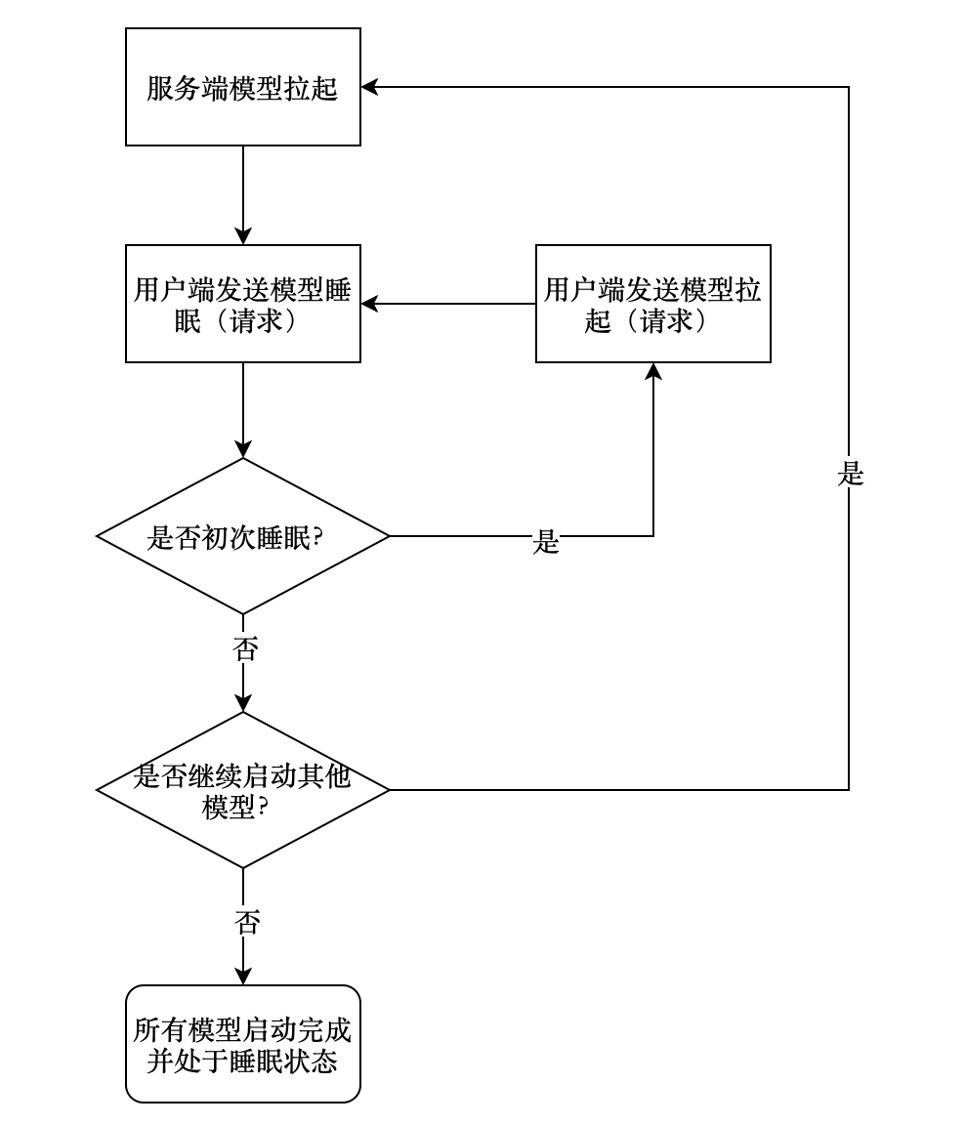
客户端流程图
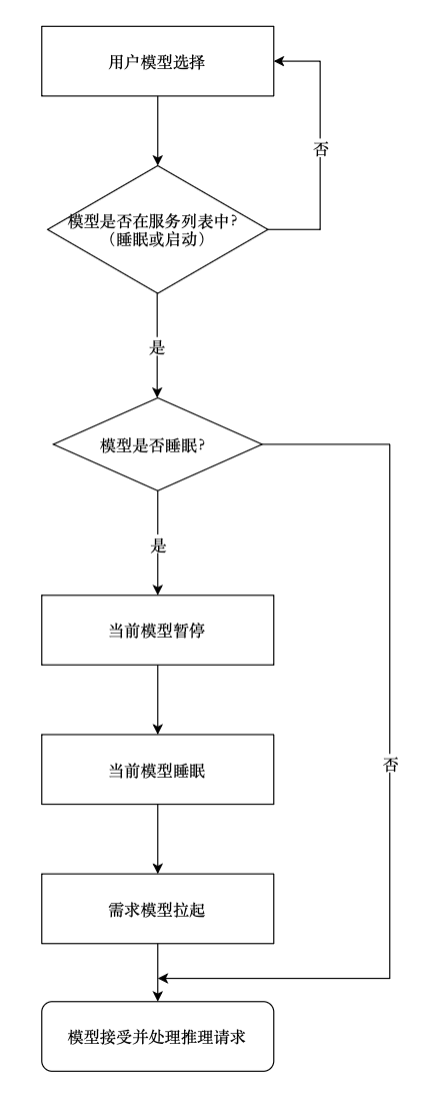
3.2 测试数据
|
模型 |
卡数 |
睡眠时间(非首轮) (s) |
唤醒时间(非首轮) (s) |
正常拉起用时(s) |
|
Qwen3-0.8B |
1 |
0.2 |
0.05 |
/ |
|
Qwen3-4B |
1 |
0.2 |
0.1 |
/ |
|
Qwen3-14B |
1 |
4.47 |
1.47 |
127 |
|
Qwen3-14B |
2 |
3.75 |
0.82 |
117 |
|
Qwen3-14B |
4 |
3.46 |
0.49 |
111 |
|
Qwen2.5-72B |
4 |
3.17 |
0.89 |
217 |
|
Qwen2.5-72B |
8 |
3.01 |
0.62 |
209 |
总结
在算力资源有限,且模型支持链式调用或不严格并发要求时,基于模型睡眠进行快速切换收益还是可观的。但是因为启动服务时增加了export VLLM_SERVER_DEV_MODE="1",vllm暴露的接口非常多,建议正式服务化前再惊醒一次封装。
相关链接:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)