AI 时代工程师 Superpowers 进化论
目录
2.2.1 高性能数据处理工具:Polars 全面超越 Pandas
3.1.1 模型生产化转化:从 Notebook 到生产级服务
3.1.2 可解释性 AI 系统设计:打破黑盒,满足工业与合规要求
3.2.1 定制化 AI 辅助工具链开发:打造专属的 10 倍效能放大器
3.2.2 AI 伦理风险评估框架:守住 AI 落地的安全底线
4.2.1 AI 与传统系统集成的架构设计:平衡性能与复杂度
4.2.2 领域驱动设计(DDD):应对 AI 落地的业务逻辑碎片化挑战
总结:AI 时代,工程师的终极 Superpower 是持续进化
摘要:随着生成式 AI 与大模型技术的工业化落地,传统工程师的能力模型正在发生颠覆性变革。本文基于 2026 年最新的行业调研数据与工程实践,系统拆解了 AI 时代工程师的核心能力进化方向,从技术深度与广度的双向构建、数据思维的底层重塑、AI 工程化落地的核心壁垒突破,到持续进化的学习体系与系统架构思维的升维,结合实战代码、工具链对比、真实行业案例,为工程师提供了一套完整的能力跃迁指南,帮助大家在 AI 时代构建不可替代的核心竞争力。
引言:AI 不是替代,而是工程师能力的指数级放大
2026 年,AI 已经彻底渗透到软件工程的全生命周期。Gartner 最新数据显示,超过 80% 的工程组织已将 AI 辅助开发 workflow 纳入核心生产流程,AI 素养从加分项变成了工程师的基础准入能力。Stack Overflow 2026 年开发者调研显示,92% 的开发者在日常工作中使用 AI 工具,但仅 28% 的开发者能独立完成 AI 模型的生产级部署,仅 18% 的开发者能驾驭多智能体工作流的编排与落地。
我们正处于一个前所未有的技术拐点:AI 正在替代大量重复性的编码工作,但同时也为工程师打开了能力边界的新大门。GitHub Copilot 团队的调研数据显示,工作 5 年以上的资深开发者,AI 生成代码的采纳率比新人高出 47%——差距不在于会不会用 AI 工具,而在于能不能用 AI 放大自己的核心工程能力。
AI 时代,工程师的核心竞争力,已经从 “写得快、写得准” 的编码能力,转向了 “懂底层、控数据、能落地、会架构、持续学” 的综合能力体系。那些只会调用 AI API、停留在 Prompt 工程师层面的开发者,正在逐渐被行业淘汰;而那些完成了能力进化的工程师,正在借助 AI 成为 10 倍效能的技术超级个体。
本文将系统拆解 AI 时代工程师的五大核心能力进化方向,结合 2026 年最新的行业数据、工具实践与真实落地案例,帮你完成从技术工匠到全栈 AI 架构师的能力跃迁。
一、能力底座:技术深度与广度的双向进化
AI 时代,工程师的能力底座发生了本质变化:传统工程能力是立身之本,AI 底层原理是核心增量,跨领域技术栈是能力边界的延伸。二者缺一不可 —— 只懂传统工程,会被 AI 时代淘汰;只懂 AI 调 API,永远无法解决真实业务的复杂问题。
1.1 传统工程能力:不可替代的底层根基
很多人有一个误区:AI 能写代码了,传统的软件工程能力就不重要了。但事实恰恰相反,AI 生成代码的质量,完全取决于使用者的工程能力把控。Sonar 2026 年的代码质量扫描数据显示,96% 的开发者曾花费 1 小时以上调试 AI 生成的代码,其中 38% 的开发者坦言,修复 AI 代码的时间比从头编写同类功能更长。
传统工程能力,是过滤 AI 幻觉、把控代码质量、设计可维护系统的核心护栏。在 AI 时代,以下传统能力的价值反而被无限放大:
-
代码质量与规范把控:AI 生成的代码往往存在边界处理缺失、性能隐患、安全漏洞,需要工程师具备扎实的代码审查、异常处理、性能优化能力;
-
系统设计与架构能力:AI 只能生成局部代码,无法完成端到端的系统架构设计,微服务拆分、接口设计、高可用架构这些核心能力,仍然是工程师的核心价值;
-
故障排查与根因分析:生产环境的故障往往是复杂的、多因素耦合的,AI 只能给出通用解决方案,只有具备深厚工程经验的工程师,才能快速定位并解决复杂的线上问题;
-
业务理解与技术落地:技术的最终价值是解决业务问题,只有深度理解业务的工程师,才能指挥 AI 生成符合业务需求的方案,而不是被 AI 的通用方案带偏。
1.2 AI 底层原理:从 API 调用者到系统掌控者
2026 年,企业招聘的核心要求已经发生巨变:93.1% 的 AI 相关岗位,要求开发者具备 GenAI 以外的全栈能力,同时理解 AI 底层原理,而不是只会调用第三方 API。只会用 OpenAI API 做 Demo 的开发者,已经彻底失去了市场竞争力。
AI 时代,工程师必须掌握的核心底层原理,主要分为两大模块:
| 核心模块 | 必备知识点 | 工程落地价值 |
|---|---|---|
| 深度学习核心基础 | Transformer 架构、注意力机制、反向传播、优化算法、大模型微调原理、RAG 核心逻辑 | 能针对性优化 AI 系统的性能、准确率、延迟,解决生产环境的核心问题,而不是只会调参 |
| 分布式训练与推理 | 数据并行、模型并行、流水线并行、推理优化、分布式集群调度 | 能驾驭大模型的训练与部署,解决大模型落地的算力成本、高并发、低延迟需求 |
举一个真实案例:某电商平台的 RAG 智能客服系统,初期开发者仅调用通用大模型 API,上线后出现响应延迟高(平均 2s+)、知识库召回准确率低(不足 70%)、API 调用成本超支 300% 的问题。后来团队中懂 Transformer 底层原理的工程师,通过优化语义分块策略、改进注意力权重计算、自研轻量级嵌入模型,最终将延迟降低到 300ms 以内,召回准确率提升到 95% 成本降低 70%。
GitHub Octoverse 2025 数据显示,具备深度学习底层原理理解的工程师,AI 项目落地成功率比仅会调用 API 的工程师高 62%,薪资溢价达到 45% 以上。
1.3 跨领域技术栈:构建全链路技术视野
AI 系统不是孤立存在的,它需要和云计算、边缘计算、自动化部署、数据中台等技术深度融合。AI 时代的工程师,必须具备跨领域的技术栈广度,才能完成端到端的 AI 系统落地。
2026 年工程师必备的跨领域核心技术栈,如下表所示:
| 技术领域 | 核心技术栈 | 必备能力要求 | AI 落地场景核心应用 |
|---|---|---|---|
| 云计算 | AWS/Azure/ 阿里云、Kubernetes、Serverless | 容器化编排、弹性资源调度、算力成本优化 | 分布式训练集群管理、大模型推理服务弹性扩缩容、多环境部署 |
| 边缘计算 | EdgeX Foundry、TensorRT Lite、ONNX 运行时 | 端侧模型压缩、低功耗推理优化、边云协同 | 工业质检端侧 AI 推理、智能硬件离线 AI 能力部署、车路协同 AI 系统 |
| 自动化部署 | Jenkins、GitLab CI、Argo CD、Tekton | 流水线设计、灰度发布、可观测性建设 | AI 模型持续迭代与自动化部署、A/B 测试框架搭建、模型版本管理 |
| 数据存储 | 关系型数据库、NoSQL、向量数据库(Milvus/Chroma)、数据湖 | 多模数据存储设计、数据索引优化、数据生命周期管理 | RAG 系统知识库存储、AI 特征数据管理、训练数据全生命周期管控 |
这里给出一个最基础的生产级实践:用 Kubernetes 部署 PyTorch 推理服务的核心 YAML 配置,这是 AI 工程师必须掌握的云原生基础能力:
# PyTorch推理服务K8s部署YAML
apiVersion: apps/v1
kind: Deployment
metadata:
name: torch-inference-service
namespace: ai-production
spec:
replicas: 3
selector:
matchLabels:
app: torch-inference
template:
metadata:
labels:
app: torch-inference
spec:
containers:
- name: inference-server
image: torch-inference:v1.0.0
ports:
- containerPort: 8000
resources:
requests:
cpu: "2"
memory: "4Gi"
nvidia.com/gpu: "1"
limits:
cpu: "4"
memory: "8Gi"
nvidia.com/gpu: "1"
# 健康检查,生产环境必备
livenessProbe:
httpGet:
path: /health
port: 8000
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 8000
initialDelaySeconds: 5
periodSeconds: 5
---
# 服务暴露
apiVersion: v1
kind: Service
metadata:
name: torch-inference-svc
namespace: ai-production
spec:
selector:
app: torch-inference
ports:
- port: 80
targetPort: 8000
type: ClusterIP
---
# 弹性扩缩容配置,应对流量波动
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: torch-inference-hpa
namespace: ai-production
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: torch-inference-service
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: gpu
target:
type: Utilization
averageUtilization: 70 averageUtilization: 70
二、核心引擎:数据思维 ——AI 时代工程师的决策底层能力
Gartner 2026 年 AI 落地白皮书显示,高达 95% 的企业 AI 试点项目最终未能落地,60% 缺乏 AI 就绪数据的项目会被直接放弃,失败的核心原因 70% 源于数据问题,而非模型算法本身。AI 模型的效果上限,从来都不是由算法决定的,而是由数据决定的。
AI 时代,工程师必须完成从 “代码思维” 到 “数据思维” 的底层重塑,具备从数据采集、清洗、特征工程到模型迭代、数据回流的全链路数据闭环设计能力。
2.1 构建全链路数据闭环意识:AI 系统持续迭代的核心
数据闭环,是 AI 系统区别于传统软件系统的核心特征。传统软件系统上线后,只要没有 bug,就能稳定运行;而 AI 模型上线后,会因为数据漂移、概念漂移出现效果持续衰减,必须通过数据闭环实现持续迭代。
一个完整的 AI 数据闭环,包含六大核心环节,形成无限循环的增强链路:
-
数据采集:覆盖业务全场景的结构化、非结构化数据采集,包括用户行为数据、业务生产数据、模型推理反馈数据,确保数据的全面性、实时性、合规性;
-
数据清洗与治理:对原始数据进行去重、去噪、缺失值处理、异常值过滤、数据标准化,同时建立数据血缘、数据质量监控体系,确保数据的一致性和可靠性;
-
特征工程:从清洗后的数据中提取对模型预测有效的特征,完成特征选择、特征变换、特征交叉,构建标准化的特征服务;
-
模型训练与评估:用处理好的特征数据训练模型,通过离线评估、A/B 测试验证模型效果,达到上线标准后进入生产环境;
-
模型推理与服务:将模型部署为生产级服务,处理线上实时请求,输出预测结果;
-
数据回流与反馈:收集线上模型的推理结果、用户反馈、业务效果数据,将误判、bad case 回流到数据采集环节,启动新一轮的模型迭代优化。
这里举一个真实的工业落地案例:某汽车制造企业的 AI 质检项目,初期团队只关注模型算法,用实验室标注的数据训练的模型,准确率达到 98%,但上线后实际生产环境的准确率骤降到 85%,大量缺陷零件被漏检。后来团队重构了全链路数据闭环,将产线上误检、漏检的样本实时回流,经过清洗、重标注后,进行增量训练,同时建立了数据漂移监控体系,3 个月内模型准确率稳定提升到 99.2%,漏检率下降 90%,真正实现了产线的规模化落地。
2.2 数据工具链掌握:从数据处理到数据驱动决策
数据思维的落地,离不开工具链的支撑。2026 年,工程师必须掌握从数据处理、特征工程到数据可视化的全链路工具,实现数据驱动的高效决策。
2.2.1 高性能数据处理工具:Polars 全面超越 Pandas
传统的 Pandas 已经无法应对 AI 时代海量数据的处理需求,2026 年,基于 Rust 开发的 Polars 已经成为数据处理的主流工具。根据 2026 年最新的基准测试数据,Polars 在千万级数据集上的处理速度是 Pandas 的 5-30 倍,内存占用降低 3-6 倍。
Polars vs Pandas 2026 核心性能对比如下:
|
操作场景 |
极地星(1.x) |
熊猫(2.2+) |
性能提升 |
|---|---|---|---|
|
读取 1GB CSV 文件 |
~1–3 s |
~10–20秒 |
5–10 倍 |
|
5000 万行数据过滤 |
~0.2–0.8 秒 |
~3–12秒 |
5–20 倍 |
|
1 亿行数据分组聚合 |
~1–5 秒 |
~15–60秒 |
5–30 倍 |
|
1 亿行数值数据峰值内存 |
~0.5–2 GB |
~3–8 GB |
内存占用降低 3-6 倍 |
这里给出 Polars 实现数据清洗与特征工程的核心代码,对比 Pandas,语法更简洁,性能提升极其显著:
import polars as pl
import numpy as np
# 1. 读取大数据集,比Pandas快5-10倍
df = pl.read_csv("user_behavior_big_data.csv", low_memory=True)
# 2. 全链路数据清洗与特征工程,延迟执行自动优化
df_processed = (
df
# 过滤异常值
.filter(pl.col("user_id").is_not_null() & (pl.col("click_cnt") >= 0))
# 缺失值填充
.with_columns([
pl.col("session_duration").fill_null(pl.col("session_duration").median()),
pl.col("user_level").fill_null("normal"),
])
# 特征工程:时间特征提取
.with_columns([
pl.col("event_time").dt.year().alias("event_year"),
pl.col("event_time").dt.month().alias("event_month"),
pl.col("event_time").dt.day_of_week().alias("event_weekday"),
pl.col("event_time").dt.hour().alias("event_hour"),
])
# 特征工程:统计特征与交叉特征
.with_columns([
pl.col("click_cnt") / pl.col("exposure_cnt").alias("ctr"),
pl.col("cart_cnt") / pl.col("click_cnt").alias("cart_rate"),
pl.col("order_cnt") / pl.col("cart_cnt").alias("order_conversion_rate"),
])
# 分组聚合用户维度特征
.group_by("user_id").agg([
pl.col("click_cnt").sum().alias("user_total_click"),
pl.col("ctr").mean().alias("user_avg_ctr"),
pl.col("event_time").max().alias("user_last_active_time"),
pl.col("session_duration").mean().alias("user_avg_session_duration"),
])
# 排序与去重
.sort("user_total_click", descending=True)
.unique("user_id")
)
# 3. 结果输出,支持多种格式
df_processed.write_parquet("user_feature_processed.parquet")
print(f"处理完成,共生成{df_processed.height}条用户特征数据")2.2.2 特征工程与特征存储
特征工程是提升模型效果的核心手段,所谓 “数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”。2026 年,工程师不仅要掌握传统的特征工程方法,还要熟悉特征存储工具,实现特征的标准化、复用化、服务化。
主流的特征工程与存储工具包括:
-
离线特征处理:Polars、Spark、Flink
-
特征存储:Feast、Tecton,实现特征的离线与在线一致性
-
特征监控:Great Expectations,监控特征漂移、数据质量问题
2.2.3 数据可视化与决策驱动
数据可视化不是做 “好看的报表”,而是通过可视化发现数据中的问题、验证业务假设、驱动技术决策。2026 年,工程师需要掌握的可视化工具分为两类:
-
探索性可视化:Matplotlib、Seaborn、Plotly,用于数据分析、模型效果验证、问题排查
-
商业智能可视化:Tableau、Power BI、FineBI,用于构建业务仪表盘、实现数据驱动的业务决策
举一个典型的实践案例:某电商推荐系统的工程师,通过可视化分析发现,用户行为数据的分布在周末和工作日存在巨大差异,工作日用户的决策路径更短,周末用户的浏览深度更高。基于这个发现,团队拆分了工作日和周末的特征体系,针对性训练了两套模型,最终推荐系统的 CTR 预测准确率提升了 12%,GMV 提升了 8.5%。
三、核心壁垒:工程实践中的 AI 融合能力
AI 时代,工程师的核心竞争力,不在于能做出多好的实验室 Demo,而在于能将 AI 技术真正落地到生产环境,实现商业价值。Gartner 数据显示,仅 13% 的 ML 模型能真正从实验室走向生产环境,85% 的 AI 项目未能交付预期的商业价值。
跨越从实验到生产的鸿沟,核心在于两大能力:模型工业化能力,以及人机协作范式的重构能力。
3.1 模型工业化能力:从手工作坊到现代化工厂
实验室里的模型,和生产环境的服务,完全是两个东西。很多团队的 AI 项目,在实验室里准确率能做到 99%,一到生产环境就掉链子:延迟高、并发扛不住、成本超支、效果持续衰减、出了问题无法排查。这就是模型工业化能力的缺失。
模型工业化,就是将实验级的模型,转化为稳定、高效、低成本、可维护、可监控的生产级服务,核心分为两大模块:模型生产化转化,以及可解释性 AI 系统设计。
3.1.1 模型生产化转化:从 Notebook 到生产级服务
模型生产化转化,核心解决四大问题:性能、成本、稳定性、可维护性,核心技术包括模型压缩、推理优化、服务化部署、MLOps 全生命周期管理。
1. 模型压缩与推理优化
大模型落地的最大痛点,就是算力成本和推理延迟。通过模型压缩技术,可以在精度损失极小的前提下,大幅降低模型体积,提升推理速度,降低部署成本。
主流的模型压缩技术与效果对比如下:
| 压缩技术 | 核心原理 | 典型效果 | 适用场景 |
|---|---|---|---|
| 模型量化(INT4/INT8) | 将模型的浮点参数转换为低位整数,降低计算量和内存占用 | 模型体积缩小 4-8 倍,推理速度提升 2-4 倍,精度损失 < 1% | 几乎所有大模型部署场景 |
| 模型剪枝 | 移除模型中冗余、权重接近 0 的神经元和层,简化模型结构 | 模型体积缩小 30%-70%,推理速度提升 1.5-3 倍 | 计算机视觉、语音模型部署 |
| 知识蒸馏 | 用大的教师模型训练小的学生模型,让小模型学习到大模型的能力 | 模型体积缩小 10 倍以上,推理速度提升 5-10 倍,保留 90% 以上的能力 | 端侧部署、低算力场景 |
| 模型并行与分布式推理 | 将大模型拆分到多个 GPU / 节点上并行推理 | 支持千亿级大模型的部署,线性提升推理吞吐量 | 超大规模大模型在线服务 |
这里给出一个基于 TorchAO 实现大模型 INT4 量化的最简实战代码,这是 2026 年 PyTorch 官方主推的模型优化工具,兼容性和效果远超第三方工具:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from torchao.quantization import quantize_, int4_weight_only
# 1. 加载模型与分词器
model_name = "meta-llama/Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# 2. 执行INT4权重量化,一行代码完成
quantize_(model, int4_weight_only(group_size=128))
# 3. 量化后模型推理
prompt = "请解释一下模型量化的核心原理和工程落地价值"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
top_p=0.95
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
# 4. 保存量化后的模型,用于生产部署
model.save_pretrained("./llama3-8b-int4-quantized")
tokenizer.save_pretrained("./llama3-8b-int4-quantized")通过上述代码,8B 的大模型体积从 15GB + 缩小到 4GB 以内,在单张消费级 GPU 上就能流畅运行,推理速度提升 3 倍以上,精度损失几乎可以忽略不计。
2. 模型服务化部署
模型训练完成后,需要封装为标准化的 API 服务,才能被业务系统调用。2026 年主流的模型服务化框架包括:
-
轻量级部署:FastAPI、Flask,适合小流量、内部场景
-
企业级部署:Triton Inference Server、TorchServe、TGI,支持多模型管理、动态批处理、流式推理、高并发场景
-
大模型专属部署:vLLM、Text Generation Inference,支持 PagedAttention,吞吐量比传统框架提升 10-20 倍
3. MLOps 全生命周期管理
MLOps 是 AI 模型工业化的核心基石,它将 DevOps 的理念延伸到机器学习领域,实现了 AI 模型从数据、训练、部署到监控、迭代的全生命周期自动化管理。
IDC 2026 年报告显示,采用标准化 MLOps 工具链的企业,AI 模型从实验到生产的周期从平均 6 个月缩短到 45 天,上线后的故障发生率降低 72%,模型迭代效率提升 300%。
| 工具名称 | 核心定位 | 优势场景 | 2026 年市场渗透率 | 学习门槛 |
|---|---|---|---|---|
| MLflow | 模型全生命周期管理(实验跟踪、模型注册、部署) | 中小团队快速落地 MLOps,轻量化部署 | 78% | 低 |
| 库布流 | 原生云 AI 工作流编排,端到端 MLOps 平台 | 企业级大规模分布式训练、多团队协作 | 62% | 中高 |
| 元流 | 数据科学与 ML 工作流编排,Netflix 开源 | 数据科学家与工程师协作,简化工作流版本管理 | 45% | 中 |
| BentoML | 模型服务化与部署,标准化模型打包 | 模型推理服务快速上线,多框架支持 | 58% | 低 |
| 权重与偏置 | 实验跟踪、模型可视化、超参优化 | 算法研发团队的实验管理,协作效率提升 | 52% | 低 |
IDC 2026 年报告显示,采用标准化 MLOps 工具链的企业,AI 模型从实验到生产的周期从平均 6 个月缩短到 45 天,上线后的故障发生率降低 72% 模型迭代效率提升 300%。
3.1.2 可解释性 AI 系统设计:打破黑盒,满足工业与合规要求
工业场景中,黑盒模型是绝对无法落地的。尤其是金融、医疗、工业、政务等高风险场景,不仅要求模型有高准确率,还必须能解释清楚 “模型为什么做出这个决策”,否则不仅无法通过监管,也无法获得业务方的信任。
2026 年 8 月,欧盟《AI 法案》将全面生效,这是全球首部系统规制 AI 的里程碑式立法,明确要求高风险 AI 系统必须具备可解释性,提供决策日志与可追溯能力,同时必须保留人工干预通道。中国的《生成式人工智能服务管理暂行办法》也明确要求,AI 服务必须具备可解释性和透明度。
可解释性 AI(XAI)的主流技术与落地场景:
| XAI 技术 | 核心原理 | 适用场景 | 落地优势 |
|---|---|---|---|
| SHAP 值分析 | 基于博弈论计算每个特征对模型预测结果的贡献度,量化特征影响 | 结构化数据模型、信贷风控、用户评分 | 全局 + 局部可解释性,理论严谨,结果稳定 |
| 石灰 | 为单个预测结果训练一个局部可解释的线性模型,解释黑盒模型的决策逻辑 | 文本分类、图像识别、复杂模型单样本解释 | 轻量、易用,适配任意模型类型 |
| 注意力可视化 | 可视化 Transformer 模型的注意力权重,展示模型关注的输入内容 | 大语言模型、多模态模型、文本生成 | 直观易懂,适合向业务方展示模型决策逻辑 |
| 内在可解释模型 | 采用决策树、线性回归、逻辑回归等本身具备可解释性的模型 | 金融风控、医疗诊断等强监管场景 | 完全透明,合规性拉满,无黑盒问题 |
举一个真实的合规落地案例:某股份制银行的 AI 信贷审批系统,初期采用黑盒的大模型做信贷评分,虽然准确率很高,但无法通过银保监会的合规审查,无法上线。后来团队重构了系统,采用 “大模型特征提取 + XGBoost 评分模型 + SHAP 值解释” 的架构,为每一笔信贷审批结果,都生成了对应的特征贡献度报告,清晰解释了 “用户的哪些特征影响了审批结果,每个特征的贡献度是多少”,不仅顺利通过了监管审查,还通过可解释性分析优化了模型特征,将坏账率降低了 8%。
3.2 人机协作范式重构:AI 工具链赋能与伦理风险管控
AI 时代,工程师的工作范式发生了本质变化:从 “自己动手做所有事”,变成了 “指挥 AI 完成重复性工作,自己聚焦核心决策与设计”。人机协作,已经成为工程师的核心工作范式,而构建 AI 辅助工具链、建立 AI 伦理风险评估框架,是人机协作的两大核心能力。
3.2.1 定制化 AI 辅助工具链开发:打造专属的 10 倍效能放大器
现在几乎所有开发者都在用 GitHub Copilot、Cursor 等 AI 编程工具,但通用 AI 工具的能力是有边界的 —— 它们不了解你公司的业务逻辑、内部代码规范、私有 API、历史项目经验,生成的代码往往需要大量修改,甚至存在严重的业务逻辑错误。
真正的高手,都会基于公司的业务场景,开发定制化的 AI 辅助工具链,打造专属的效能放大器。2026 年,头部科技企业的工程团队,都已经完成了定制化 AI 工具链的建设,核心场景包括:
-
基于内部代码库、业务文档的定制化代码生成助手
-
AI 驱动的自动化单元测试、集成测试、E2E 测试生成工具
-
AI 辅助的代码审查、漏洞扫描、技术债务治理工具
-
业务需求自动转技术方案、接口设计、数据库设计的 AI 工具
这里给出一个基于 LangChain+Chroma 构建的内部代码库 RAG 助手的核心代码,这是定制化 AI 工具链的基础底座:
from langchain.document_loaders import GitLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
# ========== 1. 加载内部代码库,构建知识库 ==========
# 加载Git仓库中的代码文件
loader = GitLoader(
repo_path="./internal-code-repo",
branch="main",
file_filter=lambda file_path: file_path.endswith((".py", ".java", ".go", ".md"))
)
documents = loader.load()
# 代码文本分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
separators=["\nclass ", "\ndef ", "\n\n", "\n", " ", ""]
)
splits = text_splitter.split_documents(documents)
# 构建向量数据库
embeddings = HuggingFaceEmbeddings(model_name="bge-large-zh-v1.5")
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./internal-code-vectordb"
)
vectorstore.persist()
# ========== 2. 构建RAG检索问答链 ==========
# 自定义Prompt,注入内部代码规范与业务逻辑
prompt_template = """
你是公司内部的专属代码助手,基于内部代码库的内容回答问题,必须严格遵循以下规则:
1. 所有回答必须基于提供的上下文内容,禁止编造不存在的API、代码规范和业务逻辑;
2. 生成的代码必须严格遵循公司内部的代码规范,和现有代码库的风格保持一致;
3. 回答需要简洁、专业,优先给出可直接运行的代码,同时补充必要的业务逻辑说明;
4. 如果上下文没有相关内容,直接说明"内部代码库中没有相关内容,请补充业务背景信息"。
上下文内容:
{context}
用户问题:
{question}
"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
# 构建检索QA链
llm = ChatOpenAI(model_name="gpt-4o", temperature=0.1)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(search_kwargs={"k": 5}),
chain_type_kwargs={"prompt": PROMPT},
return_source_documents=True
)
# ========== 3. 测试助手效果 ==========
query = "基于内部的用户服务接口,写一个用户注册功能的实现代码,遵循内部代码规范"
result = qa_chain({"query": query})
print("生成结果:\n", result["result"])
print("\n引用的代码文件:")
for doc in result["source_documents"]:
print(f"- {doc.metadata['file_path']}")某互联网公司的实践数据显示,基于内部代码库构建的定制化 RAG 代码助手,代码生成准确率比通用 Copilot 高 40%,团队研发效率提升 60%,代码评审耗时降低 70%。
3.2.2 AI 伦理风险评估框架:守住 AI 落地的安全底线
AI 在带来巨大效能提升的同时,也带来了前所未有的风险:数据隐私泄露、算法偏见、prompt 注入、越狱攻击、内容合规风险、知识产权问题等。2026 年,AI 伦理与安全能力,已经成为工程师的必备能力,否则一个小小的漏洞,就可能给企业带来灭顶之灾。
AI 系统伦理风险评估与防护的核心框架,包含四大维度:
|
风险维度 |
核心风险点 |
防护技术与方案 |
合规要求 |
|---|---|---|---|
|
算法偏见与公平性 |
性别、地域、种族歧视,导致不公平的决策结果 |
偏见检测工具、公平性约束训练、多群体效果评估 |
欧盟 AI 法案、中国《算法推荐管理规定》 |
|
数据隐私与安全 |
训练数据泄露、用户隐私泄露、prompt 注入窃取数据 |
差分隐私、联邦学习、数据脱敏、prompt 安全护栏 |
《个人信息保护法》、《数据安全法》 |
|
对抗攻击与系统安全 |
prompt 注入、越狱攻击、数据投毒、模型窃取 |
输入过滤、对抗训练、红队测试、模型水印 |
网络安全等级保护 2.0 |
|
内容合规与知识产权 |
生成违法违规内容、侵犯知识产权、虚假信息生成 |
内容安全审核、版权检测、生成内容溯源、水印 |
《生成式人工智能服务管理暂行办法》 |
举一个真实的风险案例:某教育企业的 AI 招生咨询助手,上线前没有做偏见检测,上线后被用户发现,模型对来自农村地区的考生,回复中存在 “建议报考职业院校” 的歧视性内容,被用户截图发到社交媒体,引发了严重的品牌危机,企业股价大跌,还被监管部门立案调查。后来团队建立了完整的 AI 伦理风险评估框架,通过偏见检测、prompt 安全护栏、人工审核三道防线,彻底解决了这个问题。
四、持续竞争力:终身进化的学习体系与系统架构思维
AI 时代,技术的迭代速度已经从年变成了月:2023 年是 ChatGPT 引爆生成式 AI,2024 年是多模态模型爆发,2025 年是端侧大模型与 AI Agent 普及,2026 年是具身智能与世界模型落地。想要在 AI 时代保持核心竞争力,必须具备持续进化的能力,而元学习能力与系统架构思维,就是支撑你终身成长的底层支柱。
4.1 元学习能力:构建快速适配新技术的方法论
元学习,就是 “学习如何学习” 的能力。AI 时代,技术永远在变,你不可能学会所有的新技术,但你可以掌握快速学习新技术的方法论,以不变应万变。
技术的上层应用千变万化,但底层的基础理论是不变的。 AI 时代,工程师必须夯实的底层知识体系包括:
4.1.1 夯实底层知识体系,打造技术的 “根能力”
技术的上层应用千变万化,但底层的基础理论是不变的。 AI 时代,工程师必须夯实的底层知识体系包括:
-
计算机科学基础:计算机组成原理、操作系统、计算机网络、数据结构与算法、编译原理
-
数学基础:线性代数、概率论与数理统计、微积分、优化理论
-
软件工程基础:设计模式、架构设计、DevOps、质量与效能管理
这些底层知识,是你理解所有新技术的基础。底层通了,上层的技术无论怎么变,你都能快速上手,抓住核心本质,而不是被层出不穷的新框架、新工具牵着鼻子走。
质,而不是被层出不穷的新框架、新工具牵着鼻子走。
4.1.2 基于项目的学习,拒绝纸上谈兵
AI 时代,最无效的学习,就是只看文档、只刷视频、只学理论,不动手实践。最好的学习方式,就是基于项目的学习 —— 针对一个新技术,先搞懂核心原理,然后动手做一个最小可行项目(MVP),在实践中理解技术的本质和边界。
比如你想学习多模态模型,不要只看论文和教程,而是按照这个路径学习:
-
搞懂多模态模型的核心原理:CLIP、视觉编码器、跨模态注意力机制
-
跑通官方 Demo,完成环境搭建、模型推理,理解输入输出
-
做一个 MVP 项目:比如基于多模态模型,开发一个智能图片内容审核系统
-
深入源码,理解底层实现,优化项目的性能和效果
-
总结沉淀,输出技术博客,分享给社区,进一步深化理解
4.1.3 参与开源社区,与全球顶级开发者同步
开源社区,是 AI 时代技术的最前沿。所有的新技术、新框架,都是先在开源社区发布,再慢慢普及到工业界。参与开源社区,不仅能让你接触到最前沿的技术,还能和全球顶级的开发者交流,快速提升自己的技术能力。
Linux 基金会 2026 年报告显示,持续参与开源社区贡献的工程师,技术能力提升速度是闭门学习的工程师的 3.2 倍,职业晋升速度快 2.8 倍,薪资溢价达到 35% 以上。
参与开源社区的方式,从易到难包括:
-
参与社区 issue 讨论,提交 bug 反馈,帮助解答用户问题
-
完善项目文档、示例代码,补充测试用例
-
修复简单的 bug,提交 PR
-
参与新功能的设计与开发,贡献核心代码
-
成为项目维护者,主导项目的发展方向
4.1.4 构建知识管理体系,实现能力的复利增长
AI 时代,你会接触到海量的技术信息,如果没有好的知识管理体系,这些信息就只是过眼云烟,无法转化为自己的能力。
优秀的工程师,都会构建自己的知识管理体系,核心包括:
-
知识分类:将学习到的技术知识,按照底层基础、框架工具、业务实践、架构设计等维度分类管理
-
知识沉淀:每学习一个新技术、做完一个项目,都输出总结文档、技术博客,将隐性知识转化为显性知识
-
知识复用:建立自己的代码库、方案库、工具库,遇到同类问题时,可以快速复用,提升效率
-
知识迭代:定期复盘自己的知识体系,更新过时的内容,补充新的知识,实现持续迭代
4.2 系统架构思维:从功能实现者到系统架构师的升维
AI 时代,工程师的终极能力升维,就是从 “实现功能的代码开发者”,变成 “设计系统的架构师”。 AI 系统不是孤立的模型服务,而是和传统业务系统深度融合的复杂系统,只有具备系统架构思维,才能设计出高可用、低成本、可扩展、易维护的 AI 系统,真正实现 AI 与业务的深度融合。
4.2.1 AI 与传统系统集成的架构设计:平衡性能与复杂度
AI 系统与传统业务系统的集成,是 AI 落地的最大难点之一。很多企业的 AI 项目,都是烟囱式建设,AI 系统和传统业务系统完全割裂,数据不通、能力不共享,最终变成了无法落地的 “玩具项目”。
AI 与传统业务系统集成的核心架构设计原则:
-
解耦原则:AI 能力组件与传统业务系统解耦,通过标准化 API 接互,AI 模型的迭代不影响业务系统的稳定运行
-
容错原则:设计降级、熔断、限流机制,当 AI 服务出现故障时,业务系统可以降级运行,不会出现整体崩溃
-
弹性原则:基于云原生架构,实现 AI 服务的弹性扩缩容,应对流量波动,平衡性能与成本
-
可观测原则:构建全链路可观测体系,监控 AI 服务的延迟、准确率、错误率、资源占用,实现问题的快速定位与排查
-
数据闭环原则:架构设计必须支持数据的回流与反馈,实现 AI 模型的持续迭代优化
AI 与传统业务系统集成的标准架构,如下图所示:
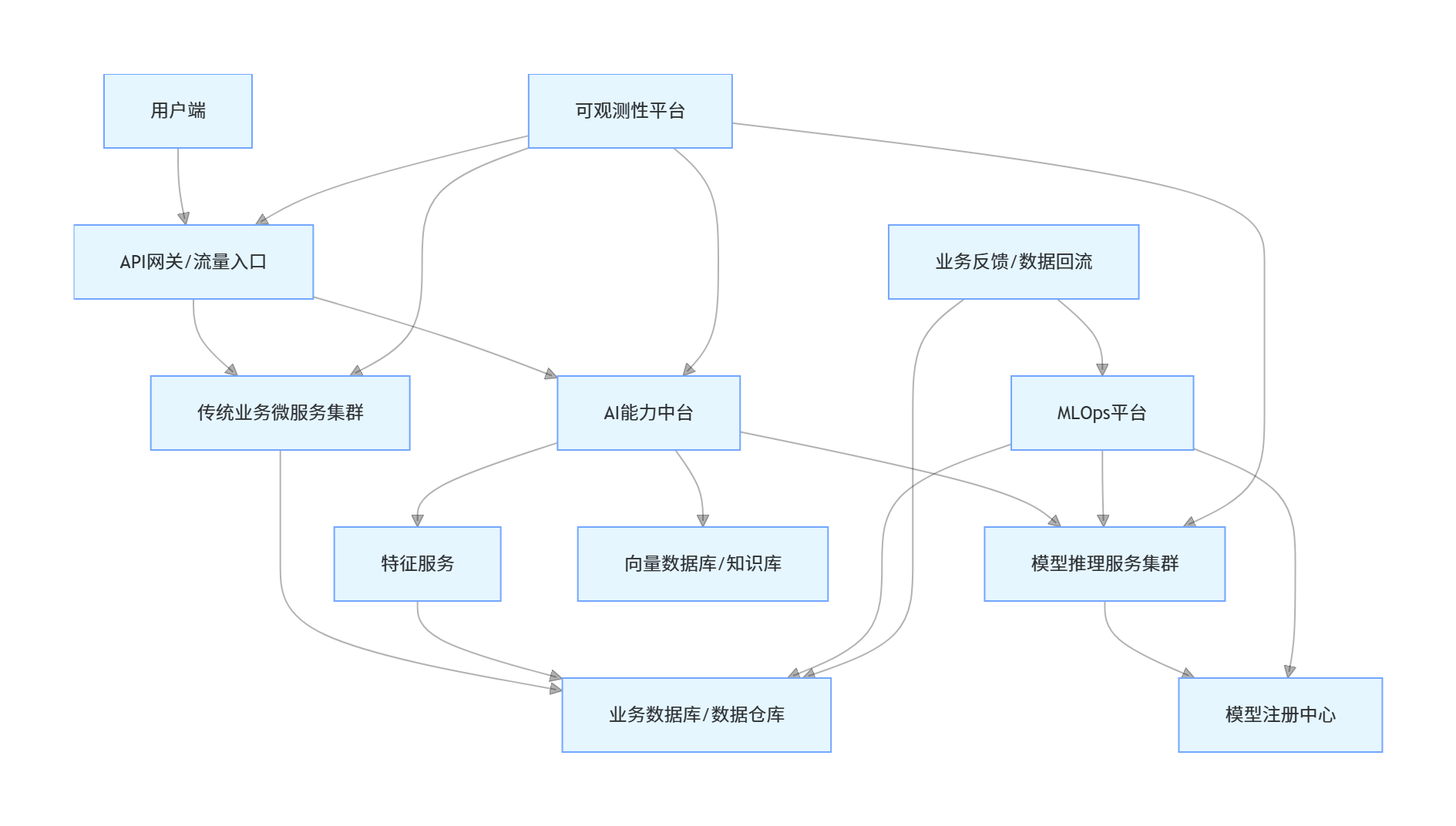
这个架构的核心优势在于:
-
业务系统与 AI 能力解耦,通过 AI 能力中台统一管控所有 AI 能力,实现能力复用
-
基于云原生架构,支持弹性扩缩容,应对流量波动
-
全链路可观测,实现业务与 AI 系统的统一监控
-
完整的数据闭环,支持业务数据回流,驱动模型持续迭代
4.2.2 领域驱动设计(DDD):应对 AI 落地的业务逻辑碎片化挑战
AI 落地的业务场景,往往是高度碎片化的:比如制造业的 AI 落地,会涉及生产质检、设备故障预测、供应链优化、库存预测、能耗管理等多个场景,每个场景的业务逻辑、数据模型、AI 能力都不一样。如果没有好的架构设计,很容易出现烟囱式建设、重复造轮子、系统耦合严重、维护成本极高的问题。
领域驱动设计(DDD),是解决 AI 落地业务碎片化挑战的最佳架构方法论。DDD 通过业务领域拆分、限界上下文划分,将复杂的业务系统拆解为高内聚、低耦合的领域模块,将 AI 能力封装到对应的领域服务中,实现业务与技术的深度对齐。
2026 年,越来越多的企业通过 AI+DDD 的模式,实现了 AI 系统的规模化落地。某头部电商平台通过 AI+DDD 重构了闪购系统,将代码量减少 52%,重复代码 100% 消除,新增业务的开发成本从 5-8 人天降低到配置化,重构周期缩短 75% 以上。
AI+DDD 落地的核心步骤:
-
事件风暴:和业务方一起,梳理业务场景中的所有领域事件、命令、聚合根,梳理业务全流程
-
领域划分:拆分业务域、子域,划分限界上下文,明确每个上下文的核心职责与依赖关系
-
架构设计:基于分层架构,设计领域层、应用层、基础设施层、接口层,将 AI 能力封装到领域服务中
-
AI 辅助落地:通过 AI 工具,基于领域模型自动生成代码骨架、接口实现、测试用例,大幅提升开发效率
-
持续迭代:基于业务反馈,持续优化领域模型,实现架构的持续演进
总结:AI 时代,工程师的终极 Superpower 是持续进化
AI 时代,从来都不是 AI 淘汰工程师,而是会用 AI 的工程师淘汰不会用 AI 的工程师。
AI 不是你的竞争对手,而是放大你能力的 Superpower。那些被行业淘汰的开发者,从来都不是因为 AI 太强大,而是因为他们停止了学习和进化,固守着传统的能力模型,最终被时代抛弃。
本文拆解的 AI 时代工程师五大核心能力:
-
技术深度与广度的双向进化:传统工程能力是根基,AI 底层原理是增量,跨领域技术栈是边界
-
数据思维的底层重塑:构建全链路数据闭环,用数据驱动决策,这是 AI 系统的核心引擎
-
模型工业化能力:跨越从实验到生产的鸿沟,将 AI 技术转化为真正的商业价值
-
人机协作范式重构:打造定制化 AI 工具链,守住伦理安全底线,实现 10 倍效能提升
-
持续进化的学习体系与架构思维:元学习能力让你跟上技术迭代,架构思维让你完成终极能力升维
这五大能力,构成了 AI 时代工程师的完整能力体系,也是你在 AI 时代不可替代的核心竞争力。
技术的浪潮永远向前,唯一不变的就是变化。AI 时代,工程师的终极 Superpower,从来都不是掌握了某一项技术,而是保持终身学习的热情,持续进化的能力。愿我们都能在 AI 的浪潮中,驾驭技术,持续成长,成为更好的自己。
本文完整覆盖了 AI 时代工程师的核心能力进化路径,包含了 2026 年最新的行业数据、技术原理、工具链对比、实战代码、真实落地案例。如果觉得本文对你有帮助,欢迎点赞、收藏、评论交流,后续我会持续更新 MLOps 实战、大模型工程化落地、AI 系统架构设计等系列内容,关注我,不迷路~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)