AI人工智能 机器学习概述
机器学习概述——从核心概念到工程实践
本文系统梳理机器学习的核心知识体系:从人工智能的基本概念出发,深入探讨机器学习的算法分类、建模流程、特征工程以及模型调优等关键环节,帮助初学者建立完整的机器学习知识框架。
文章目录
一、人工智能三大概念
1.1 什么是人工智能(AI)
人工智能(Artificial Intelligence,AI) 是让机器模仿人类智能的技术。其核心目标是通过模拟人的大脑,让计算机能像人一样思考、学习、决策和解决问题。
AI 的四个期望方向:
- 让系统像人一样思考
- 让系统理性地思考
- 让系统像人一样行动
- 让系统理性地行动
1.2 什么是机器学习(ML)
机器学习(Machine Learning,ML) 让计算机拥有自动学习的能力,无需经过人的显式编程。传统的编程是人写规则 → 机器执行,而机器学习是人提供数据 → 机器自己找出规律。
1.3 什么是深度学习(DL)
深度学习(Deep Learning,DL) 也叫深度神经网络,通过大脑仿生的方式,设计一层一层的神经元来模拟万事万物。它是从机器学习发展而来的一个重要分支。
1.4 三者关系全景图
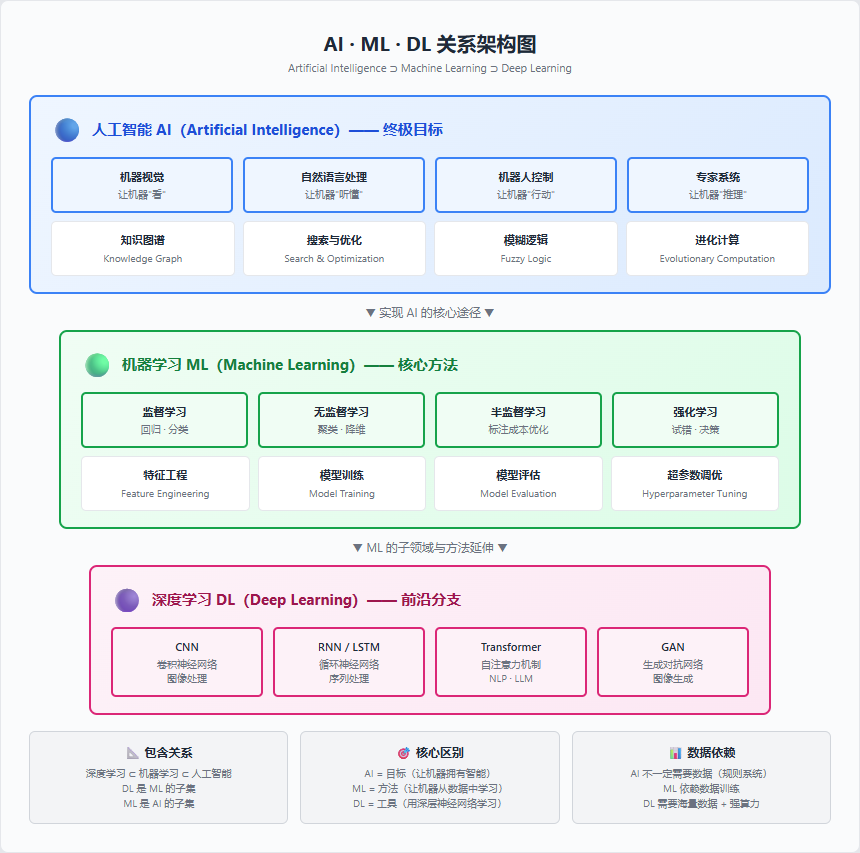
三者关系:人工智能(AI)是终极目标,机器学习(ML)是实现 AI 的一条重要途径,而深度学习(DL)是机器学习的一个子领域和方法。简单说:AI ⊃ ML ⊃ DL。
二、两种学习方式:规则 vs 模型
2.1 基于规则的学习
程序员根据经验,利用手工 if-else 的方式进行预测。例如:
# 基于规则的房价预测
def predict_price(area):
if area > 100:
return "高价"
elif area > 60:
return "中等"
else:
return "低价"
局限性:很多问题无法明确写出规则,比如图像识别、语音识别和自然语言处理——规则根本写不完。
2.2 基于模型的学习
从数据中自动学出规律,让数据"说话"。以房价预测为例:
利用线性关系来拟合"面积"与"房价"之间的关系——让直线尽可能多地经过数据点,不能经过的尽量均匀分布在直线两侧。
模型可表示为: y = a x + b y = ax + b y=ax+b,其中 a a a 和 b b b 就是要训练的模型参数(Model Parameters)。
基于模型的学习是现代机器学习的核心理念:让数据决定规则,而非人工编写规则。
三、机器学习的应用领域
机器学习已渗透到各行各业,以下是三大核心应用方向:
| 领域 | 英文缩写 | 核心任务 | 典型应用 |
|---|---|---|---|
| 计算机视觉 | CV | 对人看到的东西进行理解 | 人脸识别、自动驾驶、医学影像诊断 |
| 自然语言处理 | NLP | 对人交流的东西进行理解 | 机器翻译、智能客服、ChatGPT |
| 数据挖掘与分析 | DM/DA | 从数据中发现规律和模式 | 用户画像、推荐系统、风险控制 |
四、人工智能发展史与三要素
4.1 发展历程时间线
4.2 AI 发展三要素
AI 的蓬勃发展离不开三个核心要素的相互作用:
数据、算法、算力三者相互促进、缺一不可。大数据的积累为算法提供了"燃料",算力的提升让复杂模型训练成为可能,而算法的突破又反过来刺激了对数据与算力的需求。
五、机器学习常用术语
5.1 核心概念
以下面这个"黑马程序员就业薪资表"为例:
| 编号 | 培训学科 | 作业考试 | 学历 | 工作经验 | 工作地点 | 就业薪资 |
|---|---|---|---|---|---|---|
| 1 | Java | 90 | 本科 | 1 | 北京 | 14k |
| 2 | Java | 80 | 本科 | 1 | 武汉 | 10k |
| 3 | AI | 90 | 本科 | 0 | 北京 | 15k |
| 4 | AI | 92 | 研究生 | 2 | 上海 | 25k |
| 5 | 测试 | 95 | 本科 | 0 | 上海 | 11k |
| 6 | 测试 | 80 | 专科 | 0 | 武汉 | 7k |
| n | AI | 91 | 本科 | 1 | 上海 | ? |
- 样本(Sample):一行数据就是一个样本,多个样本组成数据集(Dataset)
- 特征(Feature):一列数据一个特征,也称为属性。特征是从数据中抽取出来的、对预测有用的信息
- 标签/目标(Label/Target):模型要预测的那一列数据。上表中的"就业薪资"就是标签
一句话理解:特征就是"已知信息",标签就是"想预测的结果"。比如预测房价——面积、楼层、地段是特征,房价是标签。
5.2 数据集划分
数据集通常划分为两部分:
变量命名约定:
# 标准的数据集划分
X_train, X_test # 训练集的特征和测试集的特征
y_train, y_test # 训练集的标签和测试集的标签
# 划分比例一般 7:3 到 8:2
核心原则:测试集在训练过程中绝对不能使用,它只用于最终评估模型的泛化能力。就像考试前不能提前看卷子一样。
六、机器学习算法分类全景
机器学习算法按学习方式可分为四大类:

6.1 监督学习(Supervised Learning)
定义:输入数据由**特征值 + 目标值(标签)**组成,训练数据有标签。
| 子类型 | 目标值特点 | 举例 | 常用算法 |
|---|---|---|---|
| 回归 | 连续值 | 房价预测、股票预测 | 线性回归、决策树、GBDT |
| 分类 | 离散值 | 垃圾邮件识别(二分类)、手写数字识别(多分类) | 逻辑回归、SVM、随机森林 |
# 监督学习示例:sklearn 房价预测
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 特征:面积、楼层、朝向等;标签:房价
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = LinearRegression()
model.fit(X_train, y_train) # 训练:学习特征与房价的关系
predictions = model.predict(X_test) # 预测:对新数据预测房价
6.2 无监督学习(Unsupervised Learning)
定义:输入数据没有被标记,样本类别未知,没有标签。根据样本间的相似性进行聚类,发现数据内在结构。
典型应用:用户分群、异常检测、文档主题归类、图像分割。
6.3 半监督学习(Semi-Supervised Learning)
核心思路——用少量标注数据撬动大量未标注数据:
- 让专家标注少量数据,训练出一个初始模型
- 用该模型去预测大量未标记数据
- 将模型预测结果与专家判断对比,迭代改善模型
最大价值:大幅降低数据标注成本。在医疗影像、工业质检等标注成本极高的领域应用广泛。
6.4 强化学习(Reinforcement Learning)
强化学习通过试错来学习最佳策略。其核心包含四个要素:
| 要素 | 英文 | 含义 |
|---|---|---|
| 智能体 | Agent | 做出决策的主体(如游戏玩家) |
| 环境 | Environment | 智能体所处的世界(如游戏场景) |
| 行动 | Action | 智能体可执行的操作 |
| 奖励 | Reward | 环境对行动的反馈信号 |
里程碑应用:AlphaGo 战胜围棋冠军、DeepMind 星际争霸 AI、自动驾驶决策系统。
七、机器学习建模五步流程
一个完整的机器学习项目遵循标准化的五步流程: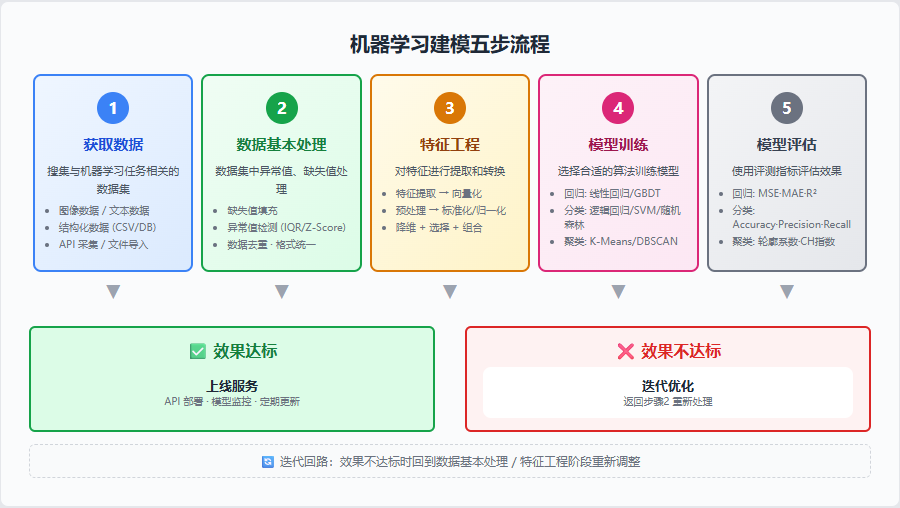
各步骤详解
| 步骤 | 核心任务 | 关键问题 |
|---|---|---|
| 1. 获取数据 | 搜集与任务相关的数据集 | 数据量够不够?质量如何?来源可信吗? |
| 2. 数据基本处理 | 缺失值填充、异常值处理 | 哪些数据有问题?怎么处理最合理? |
| 3. 特征工程 | 特征提取、预处理、降维等 | 哪些特征有用?如何转换让模型更好学习?(最耗时) |
| 4. 模型训练 | 选择算法进行训练 | 用什么算法?参数如何调优? |
| 5. 模型评估 | 用测试集评估 | 模型泛化能力够吗?是否需要回头调整? |
在整个建模流程中,数据基本处理和特征工程往往是最耗时、耗精力的环节,也是决定模型效果上限的关键。
八、特征工程:机器学习的核心
8.1 什么是特征工程
特征工程(Feature Engineering) 是利用专业背景知识和技巧处理数据,让机器学习算法效果最好的过程。
经典名言:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。”
—— “Applied machine learning is basically feature engineering.”
8.2 特征工程五大子领域
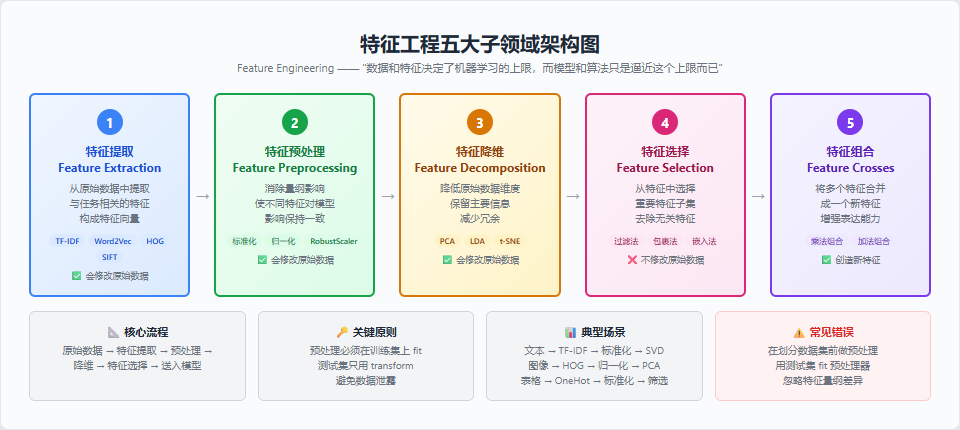
8.3 各子领域详解
| 领域 | 核心问题 | 常用方法 | 是否修改原数据 |
|---|---|---|---|
| 特征提取 | 如何从原始数据获取特征? | 文本→TF-IDF、图像→HOG/SIFT | ✅ |
| 特征预处理 | 不同特征量纲不一致怎么办? | 归一化、标准化、RobustScaler | ✅ |
| 特征降维 | 特征太多/冗余怎么办? | PCA、LDA、t-SNE | ✅ |
| 特征选择 | 哪些特征最重要? | 过滤法、包裹法、嵌入法 | ❌ |
| 特征组合 | 如何创造更有表达力的特征? | 乘法组合、加法组合 | ✅ |
8.4 特征预处理代码示例
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 标准化(Z-Score):均值为0,标准差为1
scaler = StandardScaler()
X_standardized = scaler.fit_transform(X)
# 归一化(Min-Max):缩放到 [0, 1]
normalizer = MinMaxScaler()
X_normalized = normalizer.fit_transform(X)
小贴士:当特征量纲差异很大时(如"年龄"0-100 vs "收入"0-100000),距离相关的算法(KNN、SVM、神经网络)必须先做预处理,否则数值大的特征会主导结果。
九、模型拟合问题:过拟合与欠拟合
9.1 三种拟合状态
拟合(Fitting) 用来描述模型对样本分布点的模拟程度:

9.2 形象理解
用一个故事来理解三个概念:
- 欠拟合:机器"看"天鹅太少,连基本特征(白色、长脖子)都没学全——识别标准太粗糙
- 良好拟合:机器基本能区别天鹅和其他动物,在见过的和没见过的图片上都表现不错
- 过拟合:训练数据碰巧全是白天鹅,机器以为"白色"是天鹅的必备特征——遇到黑天鹅直接不认识
9.3 泛化与奥卡姆剃刀
泛化(Generalization):模型在新数据(非训练数据)上表现好坏的能力。这是机器学习追求的终极目标。
奥卡姆剃刀原则:给定两个具有相同泛化误差的模型,较简单的模型比较复杂的模型更可取。即——如无必要,勿增实体。
9.4 解决方案一览
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 欠拟合 | 模型过于简单 | 增加特征数量、提高模型复杂度(如线性→多项式) |
| 过拟合 | 模型过于复杂、数据不纯、训练数据太少 | 正则化(L1/L2)、数据增强、特征降维、早停(Early Stopping)、Dropout |
# 使用正则化防止过拟合(以逻辑回归为例)
from sklearn.linear_model import LogisticRegression
# L2 正则化(默认),C 越小正则化强度越大
model = LogisticRegression(penalty='l2', C=0.1)
model.fit(X_train, y_train)
十、scikit-learn 开发环境搭建
10.1 工具简介
scikit-learn 是基于 Python 的机器学习库,特点:
- 简单高效的数据挖掘和数据分析工具
- 建立在 NumPy、SciPy 和 matplotlib 之上
- 开源,BSD 许可证,可商业使用
- 提供统一的 API 接口,各类算法调用方式一致
10.2 安装与验证
# 安装 scikit-learn
pip install scikit-learn
# 验证安装
python -c "import sklearn; print(sklearn.__version__)"
10.3 快速上手模板
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 1. 获取数据
iris = load_iris()
X, y = iris.data, iris.target
# 2. 数据集划分
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# 3. 特征预处理(标准化)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test) # 注意:测试集用 train 的参数
# 4. 模型训练
model = LogisticRegression()
model.fit(X_train, y_train)
# 5. 模型评估
y_pred = model.predict(X_test)
print(f"准确率: {accuracy_score(y_test, y_pred):.2%}")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
关键细节:测试集的预处理用的是训练集上 fit 得到的参数(如均值、方差),不能用测试集自己 fit!否则会造成数据泄露。
总结与知识体系总览
本文覆盖了机器学习入门必须掌握的六大模块:
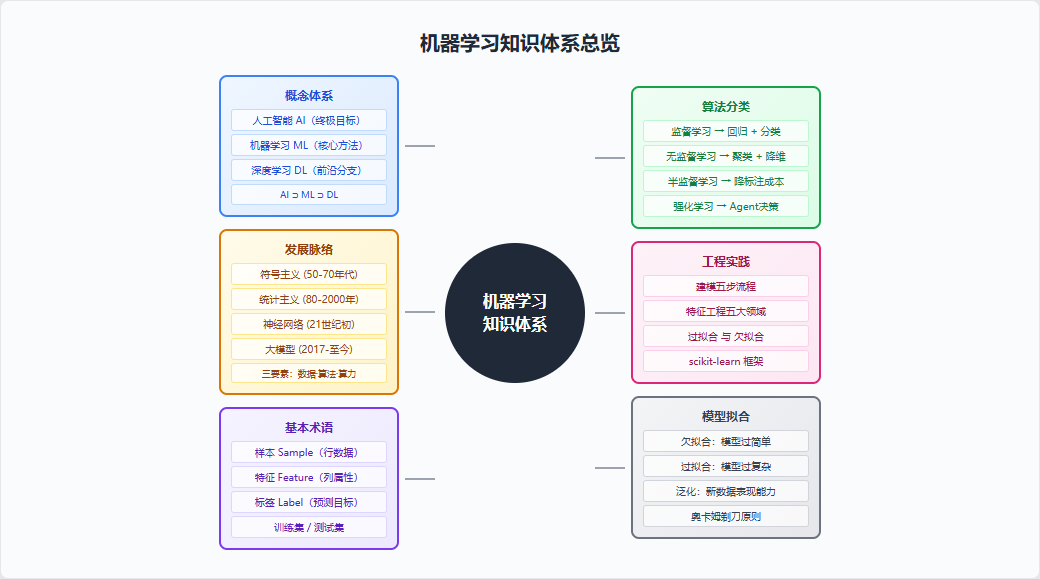
核心要点回顾
| 模块 | 核心要点 |
|---|---|
| 概念关系 | AI ⊃ ML ⊃ DL,三者是包含与被包含的关系 |
| 学习方式 | 规则学习(人工 if-else)→ 模型学习(数据驱动) |
| 发展三要素 | 数据(燃料)+ 算法(引擎)+ 算力(加速器) |
| 算法分类 | 监督 / 无监督 / 半监督 / 强化学习,按"标签有无"区分 |
| 建模流程 | 获取数据 → 数据处理 → 特征工程 → 模型训练 → 模型评估 |
| 特征工程 | 决定模型上限的核心环节,包含提取/预处理/降维/选择/组合 |
| 模型拟合 | 欠拟合(太简单)vs 过拟合(太复杂),追求泛化能力 |
| 开发工具 | scikit-learn:简单高效、API 统一、生态完善 |
参考资料:scikit-learn 官方文档 https://scikit-learn.org/stable/

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)