STARK(31.7FPS) < SeqTrack(40FPS) < AQATrack(67.6FPS)模型的比较分析
模型介绍:
AQATrack架构
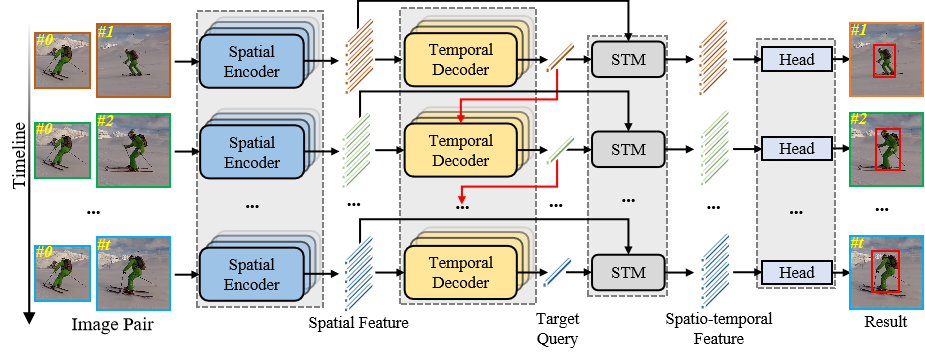
STARK架构:
输入三元组:初始模板 + 动态模板 + 当前搜索区域 → ResNet 提取特征 → 展平拼接 → Transformer 编码器(时空注意力)→ Transformer 解码器(单目标查询)→ 角点预测头 + 分数头 → 输出边界框与置信度。
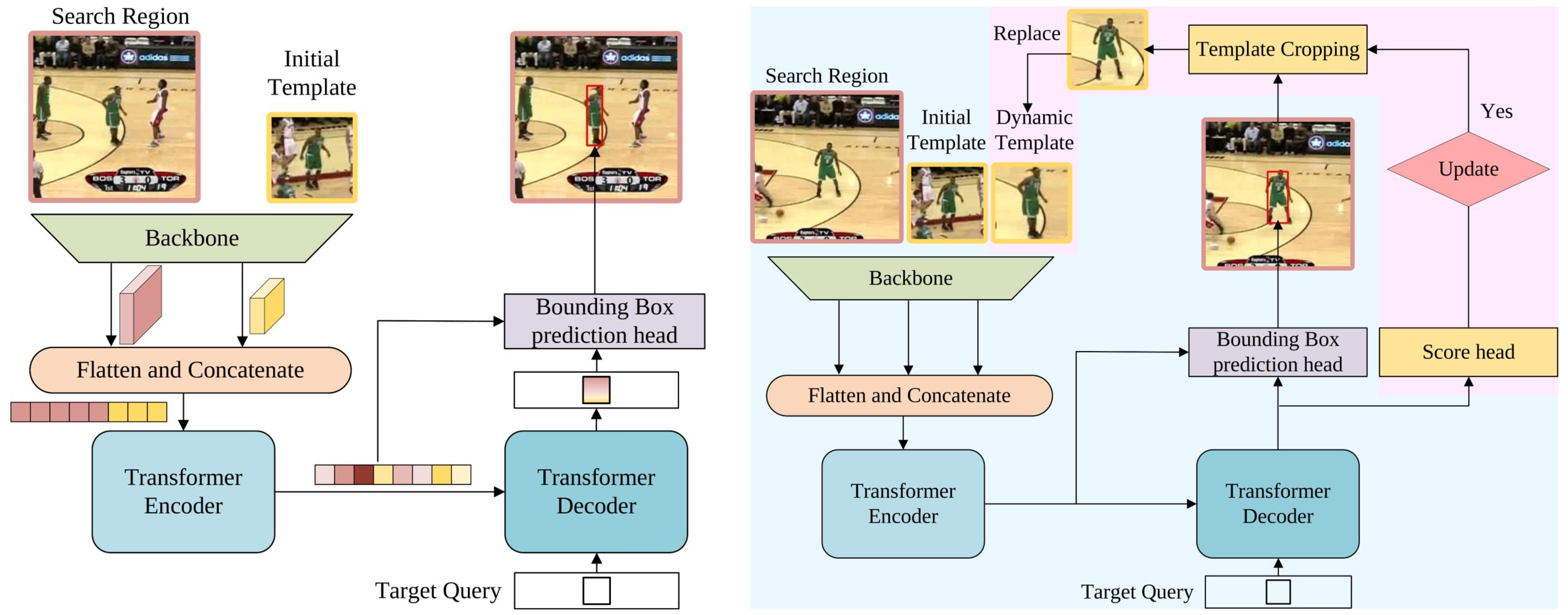
- 首次将编码器 - 解码器 Transformer用于单目标跟踪,建模全局时空特征依赖。
- 提出动态模板 + 分数头,融合空间信息与时序变化,无需梯度更新。
- 端到端、无锚点、无候选框、无后处理,用角点预测头直接输出边界框。
- 构建新基准NOTU,解决小数据集过拟合问题。
SeqTrack
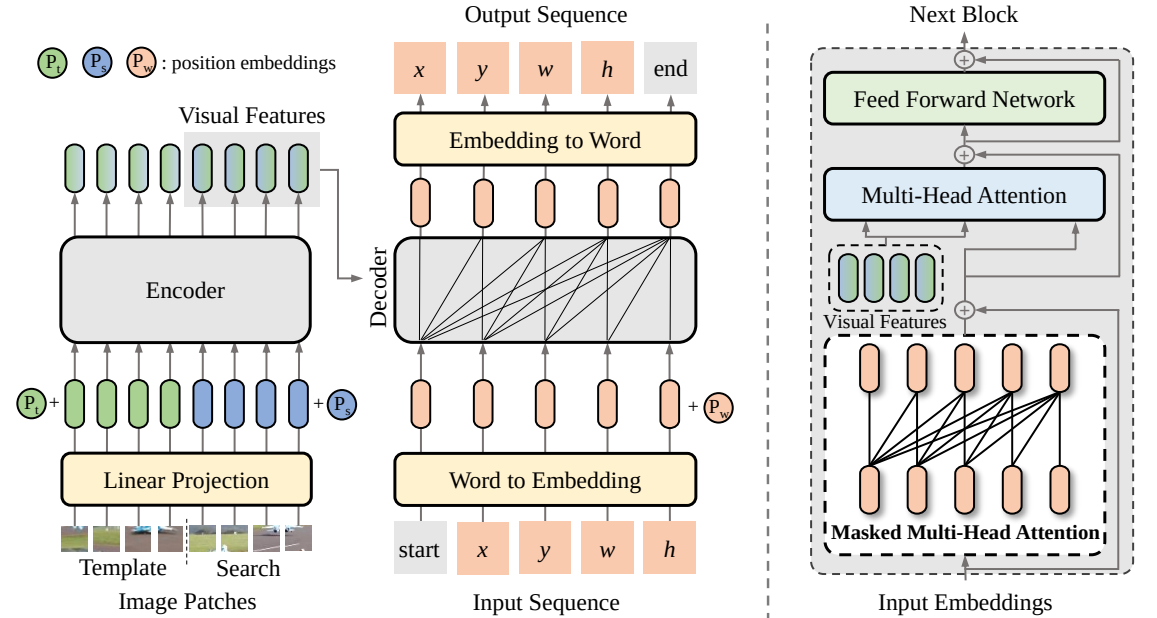
性能指标对比
计算效率
- 参数量:STARK(43.4M) < AQATrack(72M) < SeqTrack(89M)
- 推理速度:STARK(31.7FPS) < SeqTrack(40FPS) < AQATrack(67.6FPS)
- 训练速度:SeqTrack < AQATrack < STARK
跟踪精度:在LaSOT基准测试中:
- STARK达到67.1% AUC
- SeqTrack达到69.9% AUC
- AQATrack达到71.4% AUC
目标跟踪领域利用 Transformer 挖掘时空信息的演进趋势:
-
STARK 是早期的开拓者,验证了用 Transformer 编码器结合动态模板来建模时空特征的可行性。
-
SeqTrack 迈出了大胆的一步,通过序列生成彻底简化了跟踪框架,将坐标预测变成了“语言翻译”。
-
AQATrack 在 STARK 的基础上进一步优化,引入了更优雅的“自回归查询向量”来学习时序变化,相比 STARK 的手动规则和 SeqTrack 的序列生成,它在不显著增加复杂度的前提下,更精细地建模了目标的运动状态。
三者都在追求以更简洁、更高效的方式,让模型自动从视频流中学习到鲁棒的时空表征。
| 架构组件 | AQATrack (CVPR 2024) | STARK (ICCV 2021) | SeqTrack (CVPR 2023) |
|---|---|---|---|
| 整体架构 | 编码器-解码器 | 仅编码器 | 编码器-解码器 |
| 编码器 | HiViT (层次化 ViT,渐进式下采样) | ResNet (CNN主干) + Transformer 编码器 | ViT (标准 ViT,MAE 预训练) |
| 解码器 | 时序解码器,核心是时序注意力 (TA) 和自回归查询 | 无 (仅用编码器融合特征) | 因果解码器,核心是掩码自注意力 |
| 时序建模 | 学习一组自回归的目标查询向量 QallQall,在滑动窗口中传递 | 动态更新模板图像,将其作为第三路输入 | 序列生成,将历史坐标作为序列输入;或在线更新模板 |
| 预测头 | 传统的中心点预测头 (分类+回归) | 角点预测头 (预测概率分布的期望) | 序列生成头 (MLP + Softmax),直接输出单词 |
1. SeqTrack —— 舰船/大型飞机跟踪
适用卫星视频场景: 港口舰船编队航行、机场滑行中的客机、云层间歇遮挡目标。
| 适配卫星视频的理由 | 在卫星视频中的局限 |
|---|---|
| ViT 的全局感受野非常适合区分外形相似的密集目标(如并排停靠的军舰),能利用船体间距和编队队形作为上下文线索。 | 256x256 大模板在卫星视频中意义不大,目标只有 10-20 像素,外扩 4 倍后大量背景噪声被编码,反而干扰匹配。 |
| 序列自回归解码能较好处理云层短暂遮挡(目标消失 3-5 帧)后的重捕获,利用目标消失前的运动向量推断重现位置。 | 序列生成速度慢,而卫星视频通常需要事后快速处理长时序数据,推理效率成瓶颈。 |
| MAE 预训练对阴影、光照变化鲁棒性高,能应对卫星过顶时太阳高度角变化带来的目标亮度改变。 | 4000 bins 的坐标量化在亚像素精度要求下显得过于粗糙(1 bin ≈ 0.08 px 误差),不利于精确的中心定位。 |
2. AQATrack —— 密集车辆/小目标群(最推荐)
适用卫星视频场景: 城市交通流中的车辆计数与跟踪、停车场车辆出入监控、农田农机作业。
| 适配卫星视频的理由 | 在卫星视频中的局限 |
|---|---|
128x128 紧凑模板恰好契合卫星目标尺寸。对于 10 px 左右的车辆,FACTOR=2.0 裁剪出约 20x20 区域,无冗余背景干扰。 |
HiViT 是为高分辨率图像设计的,在卫星视频的极小目标上,16x16 的 Patch 粒度过粗,可能无法捕捉车辆内部的细微差异(如轿车与 SUV 仅差 1-2 px 轮廓)。 |
| 中心点检测(CENTER Head)天然适配卫星目标定位。热力图峰值可直接映射为亚像素级坐标,比序列生成更精确。 | 对完全静止后重新启动的目标(如等红灯车辆)可能产生 ID Switch,因为紧凑模板缺乏周围环境的长期锚定信息。 |
| 推理速度极快,适合处理卫星视频的大覆盖范围、多目标同时跟踪任务(一块区域可能有上百辆车)。 | 对云层厚遮挡(连续 10 帧以上)较敏感,中心点热力图在无目标时会产生杂乱的伪峰。 |
卫星视频使用建议
-
所有模型均需调整模板外扩系数:建议将
TEMPLATE.FACTOR从 2.0 或 4.0 降至 1.5,避免引入过多无关背景像素。 -
AQATrack 可关闭部分数据增强:卫星视频无运动模糊和尺度剧变,可适当减小
CENTER_JITTER和SCALE_JITTER。 -
考虑预处理超分:若原始目标小于 8x8 像素,建议先用轻量超分网络将 ROI 放大 2 倍再送入跟踪器,否则特征图经 stride=16 下采样后会彻底消失。
| 架构选择 | 性能/效果影响 | 来源 |
|---|---|---|
| HiViT 编码器 (AQATrack) | 提升空间特征质量 (+0.8% AUC) | 优于标准 ViT 的一次性下采样 |
| 时序注意力 (AQATrack) | 更精准地捕获运动趋势 (+0.9% AUC) | 优于普通的自注意力机制 |
| 自回归查询 (AQATrack) | 无需手动规则,端到端学习时序 | 避免了 STARK 中错误更新模板带来的性能下降 |
| 角点预测头 (STARK) | 提升定位精度 (+2.7% 成功率) | 优于直接回归坐标的 MLP 头 |
| 动态模板更新 (STARK) | 挖掘时序信息,但需小心 | 正确更新能大幅提升性能,错误更新则有害 |
| 自回归序列生成 (SeqTrack) | 简化框架,学习因果依赖 (+1.3% AUC) | 优于双向并行预测,符合人类先验 |
| 因果解码器 (SeqTrack) | 统一预测与解码,框架极简 | 移除了所有定制的跟踪头,仅用交叉熵损失 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)