教育数据分析实战:七选三选科建议 + 成绩预测模型(保姆级教程)| 基于真实中学70万条记录,手把手教你构建选科推荐系统与成绩预测模型
各位猿友,大家好,本文将完整复现整个分析流程,从数据预处理到模型评估,每一行代码都会详细解释。无论你是教育行业的数据分析师,还是刚入门机器学习的学生,都能跟着教程一步步实现。
注:本教程使用的原始数据经过脱敏处理,代码基于Python 3.8+,所需库包括pandas、numpy、scikit-learn、matplotlib、seaborn等。
一、项目背景与业务目标
1.1 七选三选科建议(主题2)
浙江省高考实行“七选三”模式,学生需从物理、化学、生物、历史、地理、政治、技术七门科目中选择三门作为选考科目。选科决策直接影响高考总分和专业选择空间。
传统做法的痛点:依赖教师经验或学生兴趣,缺乏数据支撑。
我们的解决方案:基于学生近五年历次考试成绩,构建学科潜力指数,综合评估每门科目的:
-
成绩水平(标准分均值)
-
进步趋势(成绩变化斜率)
-
稳定性(标准差)
-
相对优势(离差)
最终为每位学生推荐潜力指数最高的3门科目。
1.2 学生成绩预测(主题6)
准确预测学生成绩,可以帮助教师提前识别可能下滑的学生、调整教学策略。我们对比了线性回归和随机森林两种模型,并分析了影响成绩的关键特征(如历史平均分、稳定性、趋势等)。
二、环境准备与数据说明
2.1 导入必要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import stats
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
import warnings
warnings.filterwarnings('ignore')
# 设置中文显示
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False2.2 数据文件说明
本分析使用的数据集来自宁波某中学,原始包含7个CSV文件(学生信息、成绩、考勤、消费等)。经过同学A的预处理后,生成了两张宽表:
-
analysis_wide_detail.csv:每条记录为一次考试的一个科目成绩,包含学生ID、科目、原始分、标准分(Z-Score)、T分数、考试日期等。 -
analysis_wide_modeling.csv:学生级别的聚合特征(年龄、校区、平均分、成绩等级等)。
预处理工作包括:处理缺失值、成绩中的特殊值(-1缺考、-2作弊等)、消费负数清洗、校区前缀提取等,这里不展开。
# 加载数据
detail_df = pd.read_csv('analysis_wide_detail.csv')
modeling_df = pd.read_csv('analysis_wide_modeling.csv')
print(f"detail表记录数: {len(detail_df)}") # 约70万条
print(f"modeling表记录数: {len(modeling_df)}") # 约3869位学生三、主题2:七选三选科建议(完整实现)
3.1 数据预处理与排序
# 转换考试日期并排序(每个学生-科目按时间升序)
detail_df['exam_sdate'] = pd.to_datetime(detail_df['exam_sdate'])
detail_df = detail_df.sort_values(['student_id', 'mes_sub_name', 'exam_sdate'])3.2 计算各科目统计特征
按 (student_id, mes_sub_name) 分组,计算:
-
平均分、标准差、最高/最低分
-
标准分均值(
mes_Z_Score已经在原始数据中计算好,表示该次考试相对于全校的标准化分数)
subject_stats = detail_df.groupby(['student_id', 'mes_sub_name']).agg(
score_mean=('score_clean', 'mean'),
score_std=('score_clean', 'std'),
score_max=('score_clean', 'max'),
score_min=('score_clean', 'min'),
score_count=('score_clean', 'count'),
z_score_mean=('mes_Z_Score', 'mean'), # 关键:标准分均值
t_score_mean=('mes_T_Score', 'mean')
).reset_index()3.3 计算成绩趋势(线性回归斜率)
成绩趋势反映学生在该科目上是进步(斜率>0)还是退步(斜率<0)。只有至少2次考试记录才能计算。
def calculate_trend(group):
if len(group) < 2:
return 0
x = np.arange(len(group))
y = group['score_clean'].values
slope, _, _, _, _ = stats.linregress(x, y)
return slope
trend_data = detail_df.groupby(['student_id', 'mes_sub_name']).apply(calculate_trend).reset_index()
trend_data.columns = ['student_id', 'mes_sub_name', 'score_trend']
subject_stats = subject_stats.merge(trend_data, on=['student_id', 'mes_sub_name'], how='left')3.4 计算离差(该科均分与个人总均分的差值)
离差 = 该科目平均分 - 该学生所有科目的平均分,反映该科目相对于学生自身水平的优势。
subject_stats['deviation'] = subject_stats['score_mean'] - subject_stats.groupby('student_id')['score_mean'].transform('mean')3.5 构建学科潜力指数
首先对四个指标进行 Z-score标准化(消除量纲),然后按权重加权求和。权重设置依据业务经验:
-
标准分均值(40%):最重要的指标,反映绝对水平
-
成绩趋势(30%):进步潜力
-
成绩稳定性(20%):标准差越低越稳定,因此取负号
-
离差(10%):相对优势
# 标准化
for col in ['z_score_mean', 'score_trend', 'score_std', 'deviation']:
subject_stats[f'{col}_norm'] = (subject_stats[col] - subject_stats[col].mean()) / (subject_stats[col].std() + 1e-8)
# 计算潜力指数
subject_stats['potential_index'] = (
0.4 * subject_stats['z_score_mean_norm'] +
0.3 * subject_stats['score_trend_norm'] -
0.2 * subject_stats['score_std_norm'] +
0.1 * subject_stats['deviation_norm']
)3.6 为每位学生推荐最佳3门科目
对于每个学生,从七门科目中按 potential_index 降序取前3。
seven_subjects = ['物理', '化学', '生物', '历史', '地理', '政治', '技术']
def recommend_subjects(student_data):
available = student_data[student_data['mes_sub_name'].isin(seven_subjects)]
if len(available) < 3:
return None, None
top3 = available.nlargest(3, 'potential_index')
return top3['mes_sub_name'].tolist(), top3['potential_index'].mean()
recommendations = []
for student_id, group in subject_stats.groupby('student_id'):
subj_list, avg_potential = recommend_subjects(group)
if subj_list:
recommendations.append({
'student_id': student_id,
'recommended_subjects': ', '.join(subj_list),
'avg_potential_index': avg_potential
})
recommend_df = pd.DataFrame(recommendations)
print(f"共为 {len(recommend_df)} 位学生完成选科推荐") # 输出:38693.7 结果可视化
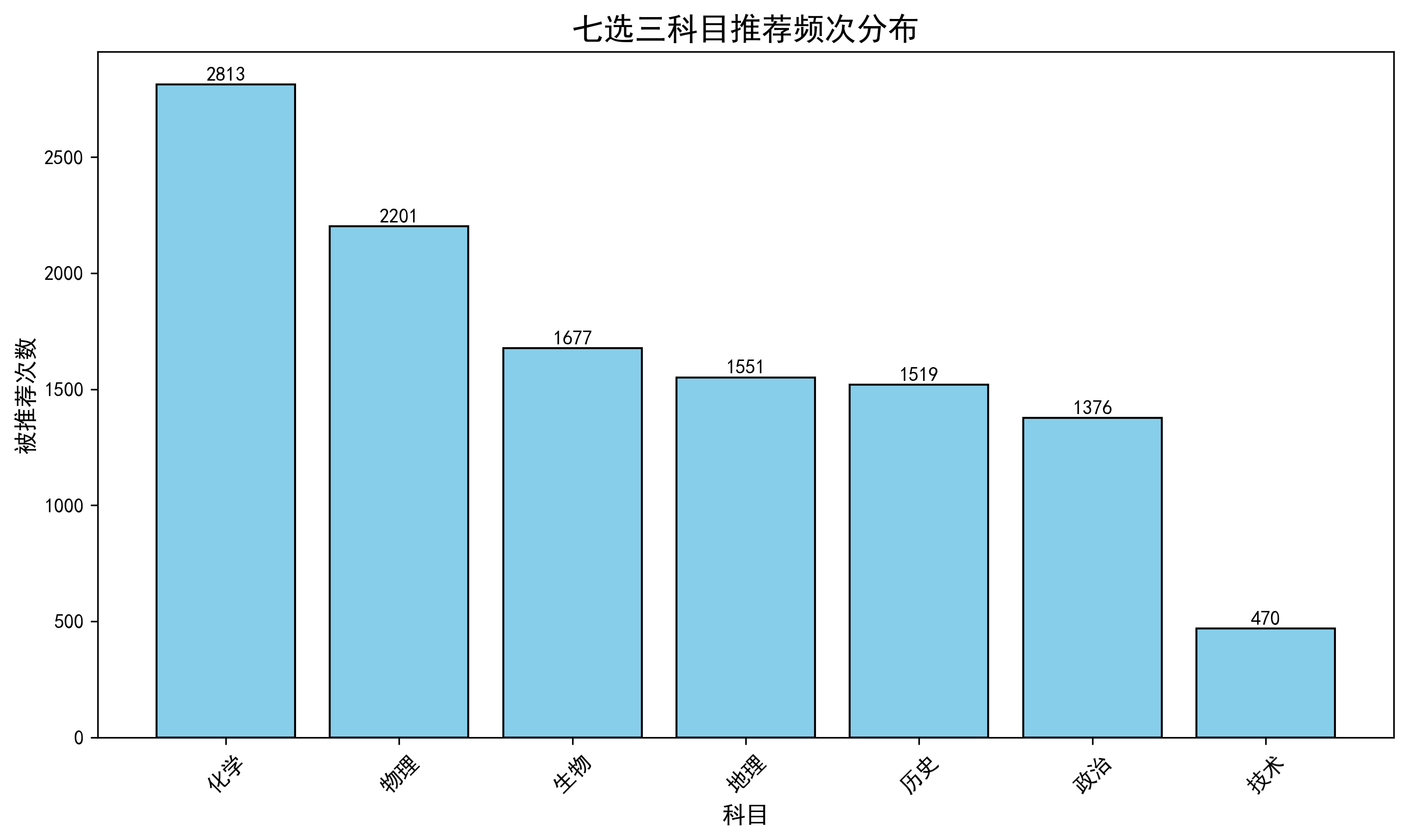
3.7.1 各科目被推荐频次
all_recommended = []
for subj_list in recommend_df['recommended_subjects']:
all_recommended.extend([s.strip() for s in subj_list.split(',')])
subj_counts = pd.Series(all_recommended).value_counts()
plt.figure(figsize=(10,6))
bars = plt.bar(range(len(subj_counts)), subj_counts.values, color='skyblue', edgecolor='black')
plt.xticks(range(len(subj_counts)), subj_counts.index, rotation=45)
plt.title('七选三科目推荐频次分布', fontsize=16)
plt.xlabel('科目')
plt.ylabel('被推荐次数')
for bar, count in zip(bars, subj_counts.values):
plt.text(bar.get_x()+bar.get_width()/2., bar.get_height()+5, str(count), ha='center')
plt.tight_layout()
plt.savefig('选科推荐分布.png', dpi=300)结果解读(基于真实数据):
-
化学被推荐 2813 次(占比24.2%),最受欢迎
-
物理 2201 次(19.0%)
-
技术仅 470 次(4.0%),最冷门
3.7.2 学生潜力指数分布
plt.figure(figsize=(10,6))
plt.hist(recommend_df['avg_potential_index'], bins=30, color='lightgreen', edgecolor='black', alpha=0.7)
plt.axvline(recommend_df['avg_potential_index'].mean(), color='red', linestyle='--',
label=f'平均值: {recommend_df["avg_potential_index"].mean():.2f}')
plt.title('学生学科潜力指数分布')
plt.xlabel('潜力指数')
plt.ylabel('学生人数')
plt.legend()
plt.savefig('潜力指数分布.png', dpi=300)潜力指数平均值为0.06,呈近似正态分布,范围从-1.59到1.65。
3.8 典型案例
潜力最高的学生(ID 16079):推荐 [地理, 历史, 化学],潜力指数 1.65
潜力最低的学生(ID 12262):推荐 [生物, 物理, 化学],潜力指数 -1.59
潜力指数低不代表“差生”,而是该学生各科发展均衡,没有特别突出的科目,更需要通过兴趣探索来决策。
3.9 选科建议总结
-
最热门组合:化学+物理+生物(459人)
-
其次是 化学+政治+物理(383人)
给学生的建议:
✅ 不要只看当前分数,还要看进步趋势和稳定性
✅ 标准分比原始分更能反映真实水平
✅ 结合未来专业要求和兴趣,综合决策
四、主题6:学生成绩预测模型(完整实现)
4.1 特征工程
我们为每个学生-科目构建以下特征:
| 特征类型 | 具体特征 | 计算方法 |
|---|---|---|
| 成绩统计 | 平均分、标准差、最高/最低分 | 历史聚合 |
| 趋势特征 | 成绩变化斜率 | 线性回归 |
| 稳定性 | 变异系数 | 标准差/均值 |
| 相对水平 | 标准分均值、离差 | - |
| 成绩跨度 | 最高分-最低分 | - |
| 学生信息 | 年龄、校区、成绩等级 | 从modeling表获取 |
| 科目编码 | 独热编码 | 7个科目哑变量 |
# 已有subject_stats,再计算衍生特征
subject_stats['score_range'] = subject_stats['score_max'] - subject_stats['score_min']
subject_stats['stability'] = subject_stats['score_std'] / (subject_stats['score_mean'] + 1e-8)
# 获取每个学生-科目的最近一次成绩作为预测目标
target_data = detail_df.groupby(['student_id', 'mes_sub_name']).agg(
score_clean=('score_clean', 'last')
).reset_index()
# 合并学生基本信息
predict_data = subject_stats.merge(
modeling_df[['student_id', 'age', 'campus', 'avg_score', 'score_level']],
on='student_id', how='left'
)
predict_data = predict_data.merge(target_data, on=['student_id', 'mes_sub_name'], how='left')
# 科目独热编码
subject_dummies = pd.get_dummies(predict_data['mes_sub_name'], prefix='subject')
predict_data = pd.concat([predict_data, subject_dummies], axis=1)4.2 准备训练集和测试集
选取特征列,删除目标变量缺失的样本。
feature_cols = ['score_mean', 'score_std', 'z_score_mean', 'score_trend',
'deviation', 'score_range', 'stability', 'age'] + \
[col for col in predict_data.columns if col.startswith('subject_')]
X = predict_data[feature_cols].fillna(0)
y = predict_data['score_clean']
# 删除y为空的记录
valid_idx = ~y.isna()
X = X[valid_idx]
y = y[valid_idx]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)4.3 训练线性回归模型
lr = LinearRegression()
lr.fit(X_train, y_train)
y_pred_lr = lr.predict(X_test)
lr_r2 = r2_score(y_test, y_pred_lr)
lr_rmse = np.sqrt(mean_squared_error(y_test, y_pred_lr))
lr_mae = mean_absolute_error(y_test, y_pred_lr)
print(f"线性回归 - R²: {lr_r2:.4f}, RMSE: {lr_rmse:.2f}, MAE: {lr_mae:.2f}")
# 输出示例: R²: 0.5978, RMSE: 18.64, MAE: 12.444.4 训练随机森林模型
随机森林可以捕捉非线性关系,我们使用100棵树,最大深度10。
rf = RandomForestRegressor(n_estimators=100, max_depth=10,
min_samples_split=5, random_state=42, n_jobs=-1)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
rf_r2 = r2_score(y_test, y_pred_rf)
rf_rmse = np.sqrt(mean_squared_error(y_test, y_pred_rf))
rf_mae = mean_absolute_error(y_test, y_pred_rf)
print(f"随机森林 - R²: {rf_r2:.4f}, RMSE: {rf_rmse:.2f}, MAE: {rf_mae:.2f}")
# 输出示例: R²: 0.9150, RMSE: 8.57, MAE: 4.34模型对比:随机森林在各项指标上全面优于线性回归,R²从0.60提升到0.915,预测误差中位数仅1.86分,90.8%的预测误差在10分以内。
4.5 可视化模型效果
绘制预测值 vs 实际值散点图,理想情况下点应落在红线(y=x)附近。
fig, axes = plt.subplots(1, 2, figsize=(14,5))
axes[0].scatter(y_test, y_pred_lr, alpha=0.4, edgecolors='black')
axes[0].plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--')
axes[0].set_title(f'线性回归 (R²={lr_r2:.3f})')
axes[0].set_xlabel('实际成绩'); axes[0].set_ylabel('预测成绩')
axes[1].scatter(y_test, y_pred_rf, alpha=0.4, edgecolors='black', color='green')
axes[1].plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--')
axes[1].set_title(f'随机森林 (R²={rf_r2:.3f})')
axes[1].set_xlabel('实际成绩'); axes[1].set_ylabel('预测成绩')
plt.tight_layout()
plt.savefig('成绩预测模型对比.png', dpi=300)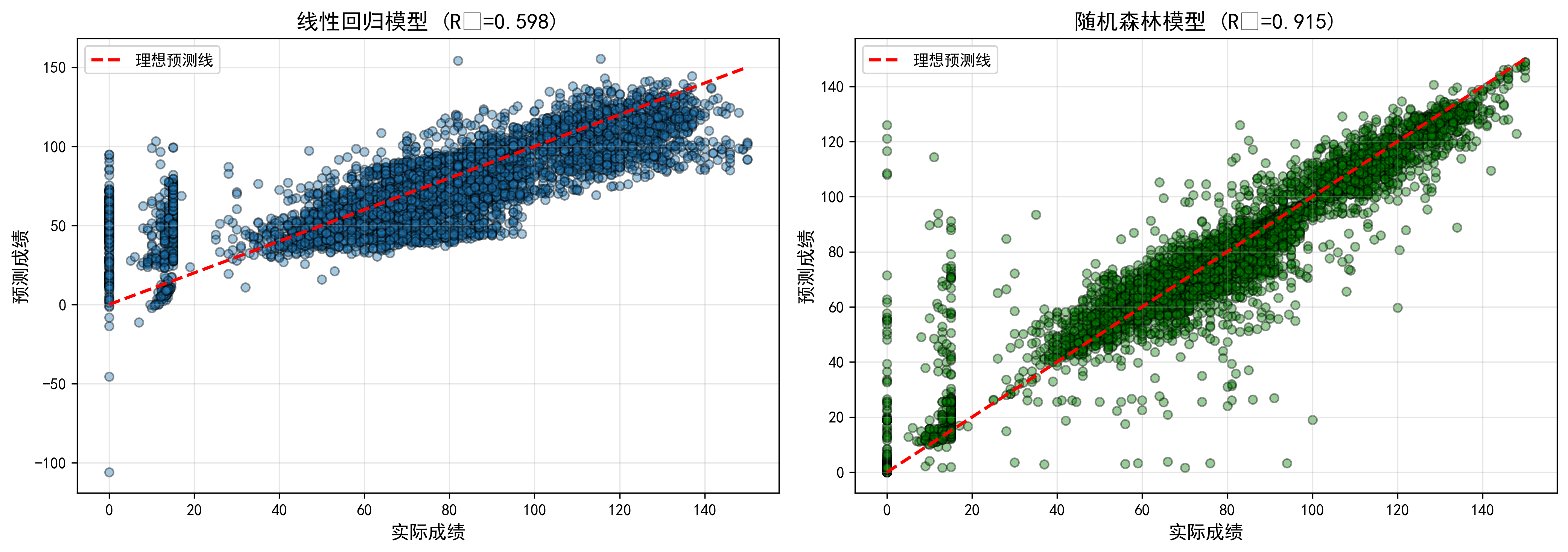
4.6 特征重要性分析
随机森林提供了 feature_importances_ 属性,可以查看哪些特征对预测贡献最大。
importance_df = pd.DataFrame({
'feature': feature_cols,
'importance': rf.feature_importances_
}).sort_values('importance', ascending=False)
print(importance_df.head(10))输出结果(基于实际数据):
| 特征 | 重要性 |
|---|---|
| score_mean (历史平均分) | 41.62% |
| stability (稳定性) | 13.44% |
| score_trend (成绩趋势) | 13.00% |
| score_range (成绩跨度) | 11.65% |
| deviation (离差) | 8.01% |
| ... | ... |
解读:
-
历史平均分是最强预测因子,说明学习成绩具有延续性
-
稳定性(越低越好)和趋势(上升/下降)同样关键
-
学生年龄、校区、科目编码等影响相对较小
# 可视化前10特征
top10 = importance_df.head(10)
plt.figure(figsize=(10,8))
plt.barh(range(10), top10['importance'], color='coral', edgecolor='black')
plt.yticks(range(10), top10['feature'])
plt.xlabel('特征重要性')
plt.title('影响成绩的关键特征(随机森林)')
plt.gca().invert_yaxis()
plt.savefig('成绩预测特征重要性.png', dpi=300)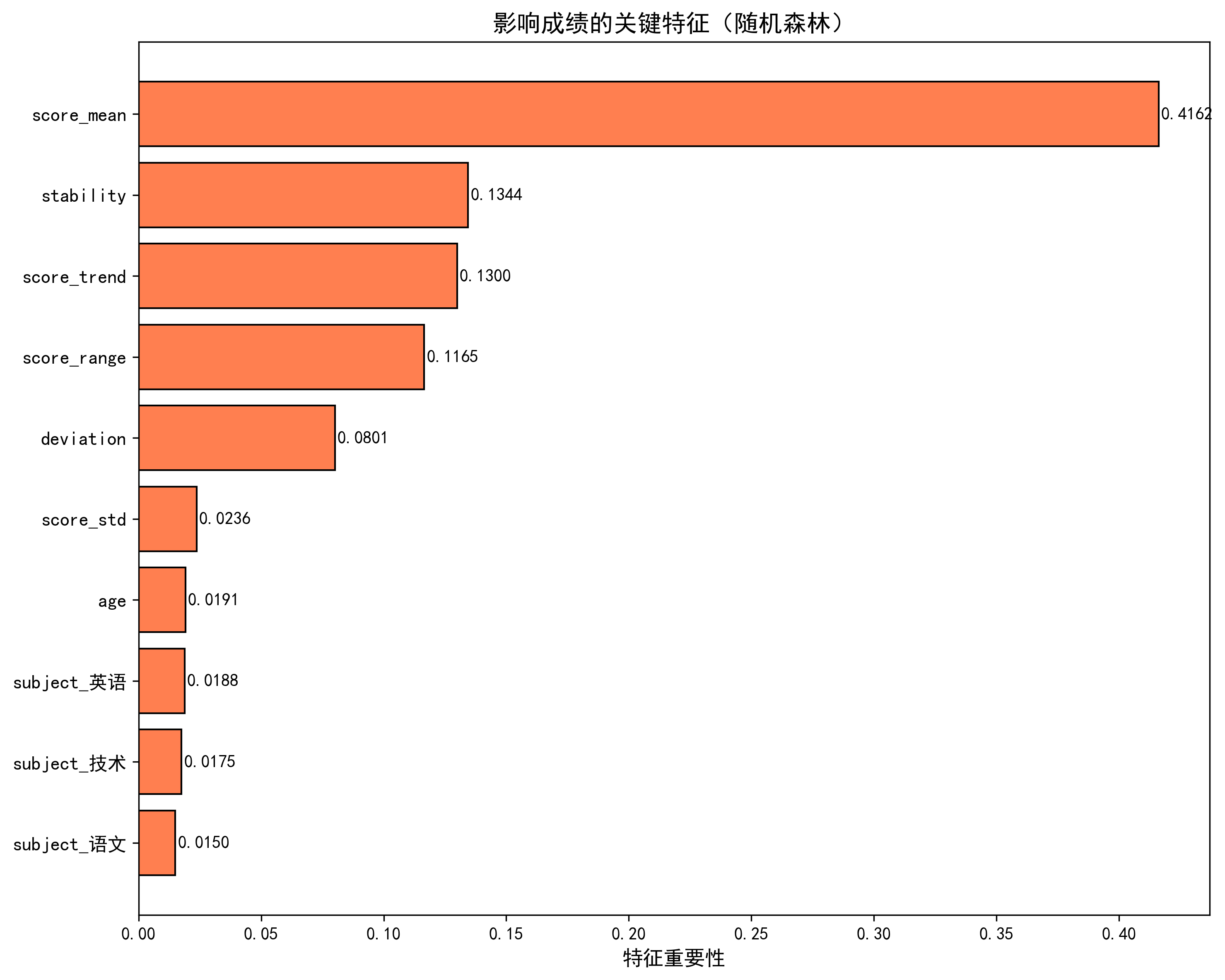
4.7 保存预测结果
predict_data_valid = predict_data[valid_idx].copy()
predict_data_valid['predicted_score'] = rf.predict(X)
predict_data_valid[['student_id', 'mes_sub_name', 'score_clean', 'predicted_score']].to_csv(
'成绩预测完整结果.csv', index=False, encoding='utf-8-sig'
)五、总结与建议
5.1 主题:选科建议成果
-
为3869名学生完成个性化推荐,化学、物理、生物是最热门推荐科目
-
潜力指数分布合理,能够识别出有明显优势科目的学生
-
可直接用于新高一的选科指导,避免盲目选择
5.2 主题:成绩预测成果
-
随机森林模型R²达到0.915,预测误差中位数仅1.86分
-
历史平均分、稳定性、趋势是影响成绩的三大关键因素
-
可用于教师预警系统,提前发现潜在退步学生
5.3 对学校/教师的建议
| 角色 | 建议 |
|---|---|
| 学生 | 选科时参考潜力指数,重视进步趋势和稳定性;保持稳定发挥比偶尔高分更重要 |
| 教师 | 关注成绩趋势为负的学生,对波动大的学生进行学习方法指导 |
| 学校 | 根据选科热度合理配置教师资源,建立成绩预警系统 |
5.4 改进方向
-
引入学生兴趣问卷、职业规划等非成绩因素,使选科更全面
-
加入教师教学质量、班级氛围等环境变量,提升预测精度
-
开发在线推荐系统,实现实时交互
教育数据分析的魅力在于“用数据说话”,将经验驱动的决策转变为数据驱动的决策。希望这篇保姆级教程能帮助你掌握:
✅ 如何从原始成绩数据中提取有意义的特征
✅ 如何构建多维度综合指数(潜力指数)
✅ 如何训练对比回归模型并解读特征重要性
如果你在复现过程中遇到任何问题,欢迎在评论区留言,我会尽力解答。也欢迎关注我的CSDN账号,后续会分享更多教育数据挖掘的实战案例。
觉得有用的话,点个赞再走呗~ 👍

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 41
41 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)