Java多线程
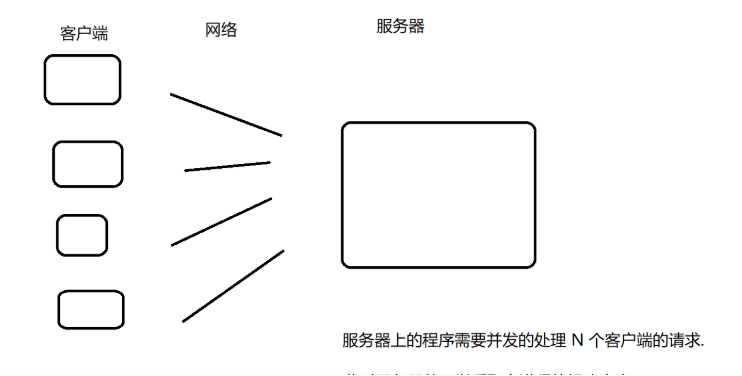
对于日常开发中,一个公司越做越大,业务也就越来越多,服务器需要处理的任务也就越来越多,在一个服务器资源有限的情况下,我们为了能提高处理任务的效率,那我们该怎么办呢?
目前常见的办法就是“并发编程”,也就是上一篇文章提到的“一个CPU在不同的阶段处理不同的任务,因为执行速度很快,所以看起来像是CPU同时处理多个任务”。对于“并发编程”的实现,在本文我们将介绍“并发编程”的实现基础和最终如何实现。让大家对这种方式有更深的理解。
为什么是线程?
什么是线程?
进程:进程是操作系统进行资源分配和调度的一个独立单位
线程:线程是进程中的一个单独的顺序控制流,是处理器调度和执行的基本单位
线程和进程的关系:
- “线程”可以称呼为“轻量级进程”,一个“进程”是由多个“线程”组成的(一个进程中至少有一个线程)。
- 一个“进程”中的多个“线程”是共用这个“进程”的资源的(内存,文件描述符表……也就是PCB),但是每个“线程”有属于自己的状态,上下文,记账信息和优先级
承接回上面服务器的例子
一般大家处理这个情况都是使用“并发编程”,而“并发编程”的基础便是“多线程”。
为什么是多线程?
之前不是说我们计算机一般都是按照“进程”在分配资源吗?那么肯定是“多进程”作为大任务的执行处理方式啊,怎么又变成了“多线程”。
首先,我们先说线程相较于进程的优势在哪,再详细剖析:
- 线程的创建,销毁,执行调度速度很快(相较于进程)
- 线程使用占用的资源更少(相比多个进程使用的资源来说)
对于剖析以上的原因,我们就需要来解释“进程”和“线程”的区别。
“进程”和“线程”的区别:
- 每个进程都有属于独立的被分配的资源,不会互相占用;而线程,属于同一个“进程”里的多个“线程”是共用这个“进程”的资源的
- 对于进程,进程是相互独立的,一个进程出现问题,其他进程不会受到影响;对于线程,同一个“进程”里的多个“线程”,有一个出现问题(挂掉)也会影响到其他的“线程”
- 对于进程,不同的进程通常不会有资源访问冲突;对于线程,同一个“进程”里的多个“线程”对于同一个资源使用经常出现冲突。
- “进程”是操作系统分配资源的基本单位;“线程”是操作系统调度执行的基本单位
创建自己的线程
一.继承Thread类创建,重写run方法
//通过继承Thread类的方法创建线程
class MyThread extends Thread {
@Override
public void run() {
while (true) {
System.out.println("Hello Thread");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class demo1 {
public static void main(String[] args) {
Thread t=new MyThread();
t.start();
while (true){
System.out.println("Hello Main");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
注:MyThread类里重写的函数run是一个“回调函数”,我们只负责重写,之后在start线程之后,run方法会自己启动。这类“回调函数”类似于“锦囊妙计”,我们只负责写出来,交给别人来执行(线程开始后会自己调度),可以得到下面这样的运行结果

二.实现Runnable接口,重写run方法,使用Runnable对象创建线程
//使用Runnable接口进行创建线程
class MyRun implements Runnable{
@Override
public void run() {
while (true){
System.out.println("实现Runnable接口的线程");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class demo2{
public static void main(String[] args) {
Runnable r=new MyRun();
Thread t=new Thread(r);
t.start();
while (true) {
System.out.println("hello main");
try {
Thread.sleep(1000);
} catch (InterruptedException e){
throw new RuntimeException(e);
}
}
}
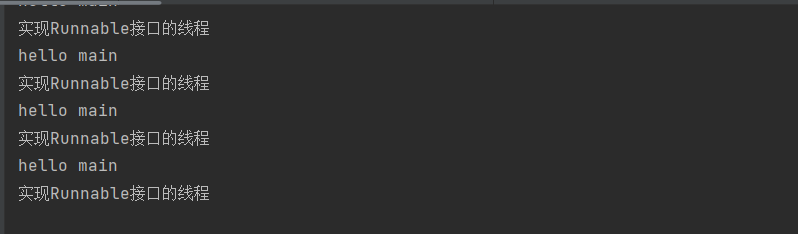
}最终我们执行就可以看到下面这样的情况:
三.Thread匿名内部类创建线程(一次性操作)
//继承Thread使用匿名内部类来创建线程
public class demo3 {
public static void main(String[] args) {
Thread t=new Thread(){
@Override
public void run() {
while (true){
try {
System.out.println("继承Thread类的匿名内部类的线程");
Thread.sleep(1000);
}catch (InterruptedException e){
throw new RuntimeException(e);
}
}
}
};
t.start();
while (true){
try {
System.out.println("Here is main");
Thread.sleep(1000);
}catch (InterruptedException e){
throw new RuntimeException(e);
}
}
}
}使用匿名内部类创造Thread对象时,可以不用继承Thread直接创造。最终执行代码我们可以得到下面的结果:

四.Runnable匿名内部类对象创建线程
//使用Runnable创建匿名内部类创造线程
public class demo4 {
public static void main(String[] args) {
Runnable r=new Runnable() {
@Override
public void run() {
while (true){
try {
System.out.println("Runnable匿名内部类的线程");
Thread.sleep(1000);
}catch (InterruptedException e){
throw new RuntimeException(e);
}
}
}
};
Thread t=new Thread(r);
t.start();
while (true){
try {
System.out.println("Here is main");
Thread.sleep(1000);
}catch (InterruptedException e){
throw new RuntimeException(e);
}
}
}
}这里我们同样可以不用实现Runnable接口创建对象,再使用Runnable对象来创建线程.
最终我们执行代码可以得到下列的结果:

五.使用lambda表达式创建线程
//使用lambda表达式的形式,创建线程
public class demo5 {
public static void main(String[] args) {
Thread t=new Thread(()->{
while (true){
try {
System.out.println("lambda表达式的线程");
Thread.sleep(1000);
}catch (InterruptedException e){
throw new RuntimeException(e);
}
}
});
t.start();
while (true){
try {
System.out.println("Here is main");
Thread.sleep(1000);
}catch (InterruptedException e){
throw new RuntimeException(e);
}
}
}
}这种方法是我们最推荐的方法,简单快捷。
执行代码后我们可以得到下面的结果:

Thread类及常见方法
我们线程相当于一个执行流,JVM一般对线程的管理是通过Thread类的对象管理,也就是说我们一个线程就对应一个Thread类的对象。因此线程的一些属性和对线程的操作都在Thread类中,我们来介绍了解这些。
Thread常见的构造方法以及属性
Thread类常见的构造方法:
方法 说明 Thread() 创建线程对象 Thread(Runnable target) 使用Runnable对象创建线程对象 Thread(String name) 创建线程对象,并命名 Thread(Runnable target,String name) 使用Runnable对象创建线程对象,并命名 Thread(ThreadGroup group,Runnable target) 线程可以被用来分组管理,分好的组即为线 注:这里线程名字我们可以后续使用获取当前线程名字的方法获得,也可以去Java中的去获取
Thread常见的属性以及获取方法
下表为Thread类中常用到的属性以及可以使用到的取到属性的方法,这些一一对应,大家自行了解即可
属性 获取方法 ID getId() 名称 getName() 状态 getState() 优先级 getPriority() 是否后台线程 isDaemon() 是否存活 isAlive() 是否被中断 isInterrupted() 注意事项:
1.ID是线程的唯一标识,不同线程不会重复
2.名称是各种调试工具用到
3.状态表示线程当前所处的一个情况
4.优先级高的线程理论上更容易被调度到
5.对于是否是后台线程,我们需要对此进行补充:
前台线程:一般main方法执行的线程和自己手动创造的线程是“前台线程”。前台线程有以下的特殊要求:
(1):前台线程可以有多个
(2):前台线程只要全部结束,进程就会直接结束(无论后台线程执行完毕没)
后台线程:也叫做“守护线程”,一般可以手动设置为后台线程,它结束与否并不会影响当前进程的结束
我们可以通过下面的一些案例来深入理解:
两个前台线程,一个结束,一个没有
public static void main(String[] args) { //创建一个线程,验证创建的线程是前台线程 Thread t1=new Thread(()->{ while (true){ try { System.out.println("线程1正在执行"); Thread.sleep(1000); }catch (InterruptedException e){ throw new RuntimeException(e); } } }); t1.start(); System.out.println("main线程正在执行"); //强制结束系统执行 // System.exit(1); }
由于t1也是前台线程,所有前台线程没有都结束,因此程序不会结束。
后台线程结束不影响整个进程的结束
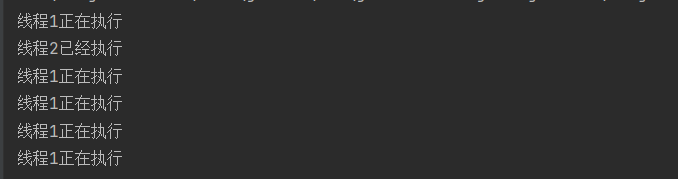
public static void main(String[] args) { //创建一个线程,验证创建的线程是前台线程 Thread t1=new Thread(()->{ while (true){ try { System.out.println("线程1正在执行"); Thread.sleep(1000); }catch (InterruptedException e){ throw new RuntimeException(e); } } }); t1.start(); //创建一个线程2,设置成后台线程 Thread t2=new Thread(()->{ System.out.println("线程2已经执行"); }); t2.setDaemon(true); t2.start(); }
t2被设置为了后台线程,可以看到前台线程t1没有结束,即使t2结束了,也不会影响到程序的进行。
后台程序未结束,前台线程已结束
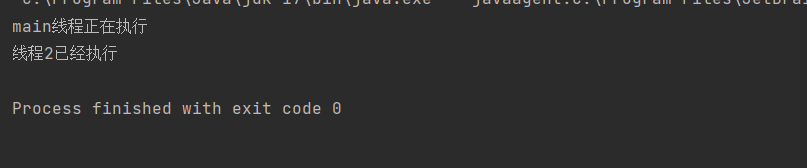
public static void main(String[] args) { //创建一个线程2,设置成后台线程 Thread t2=new Thread(()->{ while (true){ try { System.out.println("线程2已经执行"); Thread.sleep(1000); }catch (InterruptedException e){ throw new RuntimeException(e); } } }); t2.setDaemon(true); t2.start(); //main中前台线程 System.out.println("main线程正在执行"); //强制结束系统执行 // System.exit(1); }
可以看到,即使后台线程还未执行完,但是由于前台线程main执行完了,整个进程就此结束!!!
6.是否存活,即简单的理解成,run方法是否运行结束了

启动一个线程
我们编写了创建Thread对象线程的代码这并不代表我们已经开启了一个线程,我们需要使用start方法才算真正意义上开启一个线程(一般写在创建好的线程的后面)
//线程对象名.start();注:一个线程只能调用一次start()方法
中断一个线程
一般情况下,我们并不会主动强制中断一个线程,这可能导致线程A对我们数据库值进行修改时,修改到一半被强制终止,这样容易造成“脏读”类似的效果。但是如果线程可能造成严重的问题时,我们必须进行中断止损,一般来说,我们有两种中断线程的办法:
1.使用公共的自定义标识符来中断线程
2.使用Thread类中的Interrupt()方法来终止
我们接下来介绍这两种办法详细细节。
使用公共的自定义标识符来中断线程
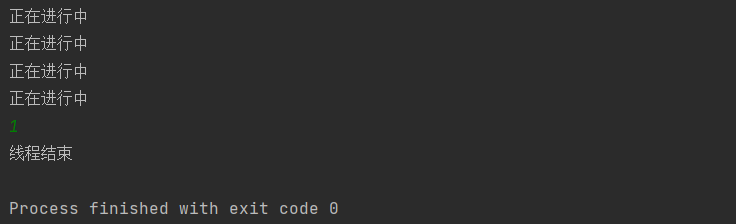
public class demo9 { //通过设定变量来控制线程的中断 public static boolean running=true; public static void main(String[] args) { Thread t1=new Thread(()->{ while (running){ try { System.out.println("正在进行中"); Thread.sleep(1000); }catch (InterruptedException e){ throw new RuntimeException(e); } } System.out.println("线程结束"); }); t1.start(); Scanner sc=new Scanner(System.in); int i= sc.nextInt(); if(i==1){ running=false; } }
这里我们使用全局变量running来控制了lambda表达式中的线程的进行中断。
值得注意的一点是,由于类和lambda表达式的特殊原因,我们这里只能使用全局变量(类似于变量要归属于类),这样我们running才能正常被创建线程的lambda表达式捕获。
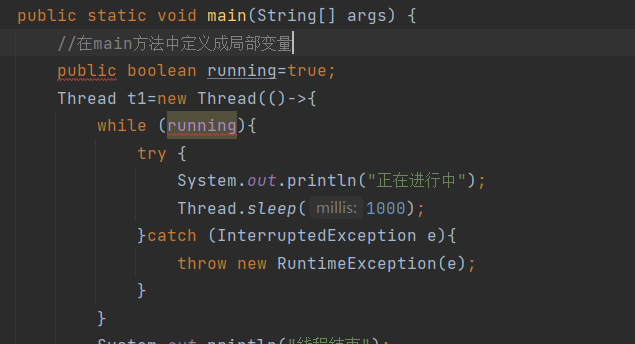
如果在main方法中定义成局部变量会出现这样的情况:
写成局部变量之后,直接出现了编译报错。
原因:对于lambda表达式/匿名内部类的变量捕获,只能捕获final修饰的变量/事实final变量(赋值完后续不会被更改值,编译器会认为成事实final变量)。
定义成局部变量,由于后续修改值,因此不能算作事实final变量,不能被捕获,也就出现编译报错。
定义成全局变量,虽然全局变量并不算是事实final,但由于全局变量的生命周期与外部类对象一样,因此可以被捕获
使用Thread类中的Interrupt()方法中断
Thread类中有关中断线程的方法如下表:
方法 说明 public void interrupt() 中断对象关联的线程,如果线程正在阻塞,则以异常方式通知,否则设置标志位 public static boolean interrupted() 判断当前线程的中断标志位是否设置,调用后青醋标志位 public boolean isInterrupted() 判断对象关联的线程的标志位是否设置,调用后不清楚标志位
Interrupt的使用
(1):直接中断运行中的线程
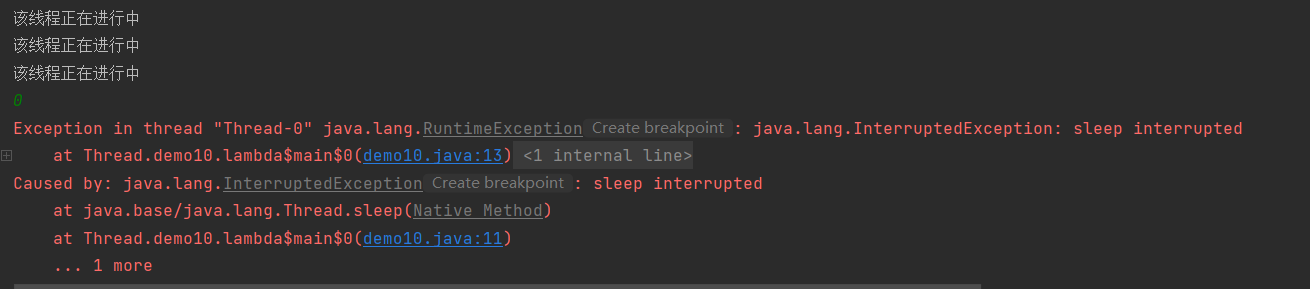
public class demo10 { public static void main(String[] args) { Thread t=new Thread(()->{ while (true){ try { System.out.println("该线程正在进行中"); Thread.sleep(1000); }catch (InterruptedException e){ throw new RuntimeException(e); } } }); t.start(); Scanner sc=new Scanner(System.in); int n=sc.nextInt(); if (n==0){ t.interrupt(); } }
可以看到我们输入0,从而调用Interrupt方法之后,编译器抛出异常直接中断了线程。
(2):中断正在阻塞中的线程
有时候,我们会因为线程一直阻塞无法结束而烦恼,可以使用Interrupt方法直接让阻塞中的线程结束:
//使用Thread类自带的Interrupt方法中断正在阻塞中的线程 public static void main(String[] args) { Thread t2=new Thread(()->{ System.out.println("线程执行中"); try { Thread.sleep(100_000); }catch (InterruptedException e){ throw new RuntimeException(e); } System.out.println("线程执行完毕"); }); t2.start(); Scanner sc=new Scanner(System.in); int n= sc.nextInt(); if(n==0){ t2.interrupt(); } }正常情况下(没有输入n调用方法的那串代码)由于我们要等待sleep对线程的阻塞时间到了才能结束。如下:
但是我们可以使用Interrupt方法:
原理是:Interrupt方法可以唤醒阻塞情况(将sleep唤醒,不用等时间到,类似阻塞有wait/join/sleep)直接接受线程。
使用Thread类中的isInterrupted方法
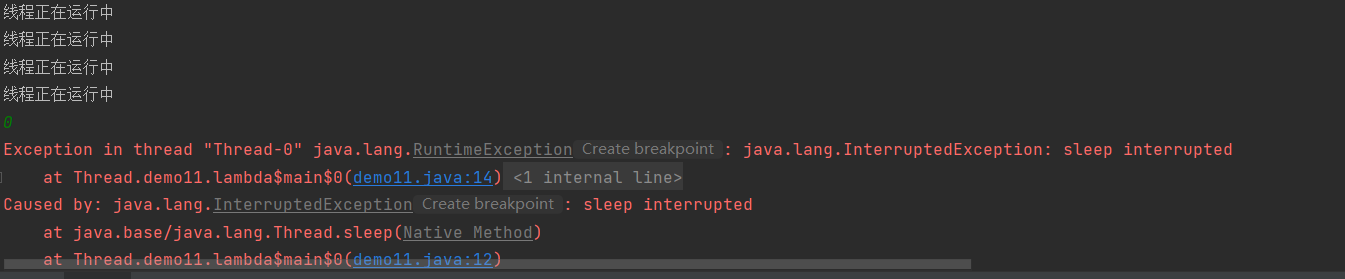
public class demo11 { public static void main(String[] args) { Thread t=new Thread(()->{ Thread cur=Thread.currentThread(); while (!cur.isInterrupted()){ System.out.println("线程正在运行中"); try { Thread.sleep(1000); }catch (InterruptedException e){ throw new RuntimeException(e); } } }); t.start(); Scanner sc=new Scanner(System.in); int n= sc.nextInt(); if(n==0){ t.interrupt(); } } }
这里这个方法起到了类似于先前的标识符的作用

等待一个线程
一般来说,如果两个线程结果互相相关有影响,那么我们肯定是最好等待其中一个线程执行完毕,这样才不会造成线程不安全的问题。但是我们又知道--操作系统调动线程执行是完全随机的(一般情况下),因此我们需要方法操纵线程主动等待,这样才能够保证我们线程执行的安全。
Thread类给我们提供了几个线程等待的方法,如下表所示:
方法 说明 public void join() 等待线程结束 public void join(long millis) 等待线程结束,最多等millis毫秒 public void join(long millis,intnanos) 同理,但可以更高精度 那么我们用实例代码来帮助大家理解,
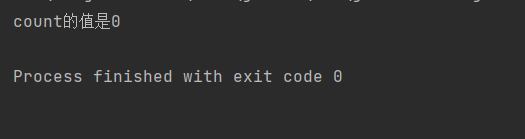
public class demo12 { public static int count=0; //join等待方法的使用 public static void main(String[] args) throws InterruptedException { Thread t=new Thread(()->{ for (int i = 0; i <1000; i++) { count+=i; } }); t.start(); //t.join(); System.out.println("count的值是"+count); } }观察这串代码,我们代码目的是“t线程负责相加,main线程输出count值,count是0-999数之和”,那么我们预期结果就是打印出相加之和?(真的如此吗?)
但实际上,这串代码输出的结果是这样的:
可以看到count居然没有进行相加操作就结束了,这是为什么呢?
注意了!!!t线程和main线程同样是前台线程(可以理解成是同一级别的),但是“操作系统对线程的调度是随机的!!!”,因此可能出现以下情况:
- main线程先打印,t线程再进行相加(就是图中所示的情况)
- t线程相加好了,main线程打印出最终结果
但是我们又要的是count相加完成之后的值,因此我们需要让main线程等待t线程执行完毕后再打印,那么我们就可以加上一行代码后,如下:
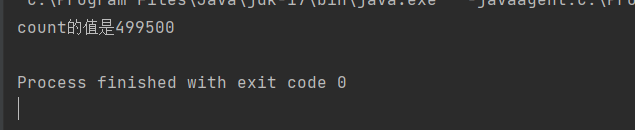
public class demo12 { public static int count=0; //join等待方法的使用->正常输出count相加后的值,而不是先执行main线程的打印 public static void main(String[] args) throws InterruptedException { Thread t=new Thread(()->{ for (int i = 0; i <1000; i++) { count+=i; } }); t.start(); t.join(); System.out.println("count的值是"+count); } }
这次我们输出的值就是t线程相加完毕的值!!!
PS:t.join()指的是等待t线程执行完毕后,main线程再执行(谁调用,等待谁执行完毕)
特别补充:
1.join方法我们也可以加上参数(作为等待线程执行的最大等待时间),这样能够提升效率,避免某个线程执行不完的“死等”现象。
2.使用join方法后,其他线程会进入“阻塞”状态,比如上述代码,t线程执行,main线程进入“阻塞”状态,直至t线程执行完毕后,才解除“阻塞”状态
3.如果在“规定时间内”指定线程仍然没有执行完毕,那么其他线程就会变成“就绪”状态;同理如果指定线程先执行完毕了,等到时间结束,其他线程就会变成“就绪”状态。
获取当前线程的引用
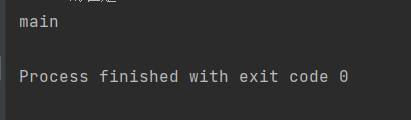
方法 说明 public static Thread currentThread() 返回当前线程对象的引用 这里的当前线程,指的是“正在被调度的线程”,是由操作系统来决定的(毕竟线程调度是完全随机的)。我们可以用下面代码来简单了解一下使用即可:
Thread t1=new Thread(()->{ }); Thread cur=Thread.currentThread(); System.out.println(cur.getName());
特别注意!!!Runnable是调用不了这个方法的
休眠当前线程
线程的执行是很快的,如果我们要放缓线程的执行速度,或者想让某线程先停下一段时间,在执行(一般是用于减轻某段时间CPU的负担),我们就会使用使线程休眠的方法
Thread类提供的休眠线程的方法如下表:
方法 说明 public static void sleep(long millis) throws InterruptedException 休眠当前线程millis毫秒 public static void sleep(long millis,int nanos) throws InterruptedException 可以更高精度的休眠
public class demo5 { public static void main(String[] args) { Thread t=new Thread(()->{ while (true){ try { System.out.println("lambda表达式的线程"); Thread.sleep(1000); }catch (InterruptedException e){ throw new RuntimeException(e); } } }); t.start(); while (true){ try { System.out.println("Here is main"); Thread.sleep(1000); }catch (InterruptedException e){ throw new RuntimeException(e); } } } }比如像这串代码,sleep休眠1秒线程中的打印操作,这样更方便我们观察数据,并且CPU的负担会轻一些。
注意!!!补充事项:
1.使用sleep方法,需要我们使用throw/try catch来处理Interrupt异常
2.sleep方法本质是阻塞当前线程(在某段时间内),这样的实现有赖于Thread类中“计时器”
3.有时在CPU资源紧张的时候,某些线程会使用sleep(0)的方法,主动放弃自己执行对CPU的占用,“放权”自己的一部分给其他重要或者资源量大的线程使用,这样有助于延缓CPU的资源紧张情况
线程的状态
一般来说每个线程都有自己的状态,这样操作系统才好有条理的去调度管理线程
观察线程的状态
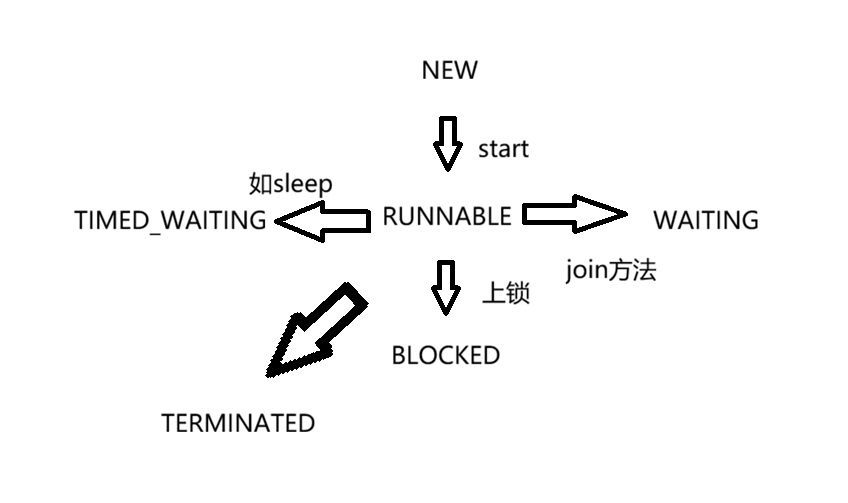
“线程的状态”是一个枚举类型的组(Thread.State)
这里我们使用一串代码来观察线程的状态:
public class demo13 { //观察当前线程的状态 public static void main(String[] args) { for (Thread.State state:Thread.State.values()){ System.out.println(state); } } }
我们可以看到有这几种“线程状态”
- NEW:创建了这个线程,但没有使用start开启线程
- RUNNABLE:可以工作调度的线程,分成正在工作中和即将开始工作
- BLOCKED:被锁锁定的线程(需要等待另一把锁执行完毕解锁,才能执行)
- WAITING:被join方法阻塞的线程
- TIMED_WAITING:带有超时阻塞的线程
- TERMINATED:已经执行完毕的线程,线程已被销毁,但Thread类的对象还存在
一般情况下,我们使用这张流程图来帮助理解这几种“线程状态”

多线程的线程安全问题
根据我们的介绍我们知道“线程的调度是完全随机的”,那么会不会有两个线程交叉一起执行的时候,互相干扰造成结果错误呢?这显然是可能的,接下来我们使用一个例子来向大家引入线程安全问题:
public class demo14 {
//线程不安全的例子
public static int count=0;
public static void main(String[] args) throws InterruptedException {
Thread t1=new Thread(()->{
for (int i = 0; i <50000; i++) {
count++;
}
});
Thread t2=new Thread(()->{
for (int i = 0; i <50000; i++) {
count++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("count的值是"+count);
}
}正常情况下,这串代码的执行结果是10w(两个线程分别让count自增5w次),但是结果是这样的:
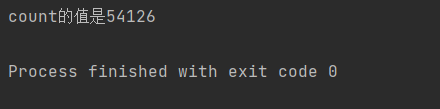
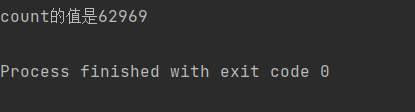
可以明显看到每一次执行的结果都不一样,而且都不是我们的预期结果。那么我们就能正式依靠这个例子引入我们线程安全问题的介绍。
线程安全问题以及线程不安全的原因
线程安全问题:
如果多线程环境下代码运⾏的结果是符合我们预期的,即在单线程环境应该的结果,则说这个程序是线程安全的。即:在单线程情况下,刚才的例子应该是两个循环结果是10w,但是在多线程的情况下,例子结果不仅不是最终正确结果,还是完全随机的数(一般大于5w)。这就是出现了线程不安全问题。
线程不安全的原因:
1.(根本原因)操作系统对于线程的调度是随机的(并不能真正意义上指定线程的先后)
2.两个线程针对“同一个变量”进行修改操作
3.修改操作不是“原子的”->例如,上面的例子,count++对应的指令操作就是三步执行
4.内存可见性
5.指令重排序
线程不安全原因的具体体现
1,2,3原因的体现:
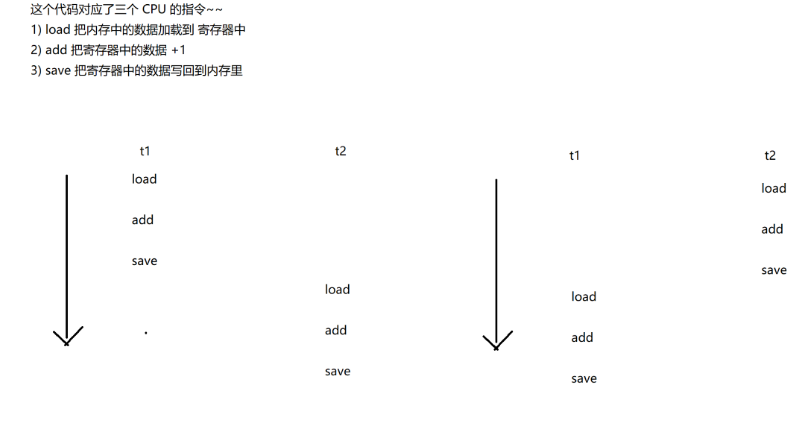
public class demo14 { //线程不安全的例子 public static int count=0; public static void main(String[] args) throws InterruptedException { Thread t1=new Thread(()->{ for (int i = 0; i <50000; i++) { count++; } }); Thread t2=new Thread(()->{ for (int i = 0; i <50000; i++) { count++; } }); t1.start(); t2.start(); t1.join(); t2.join(); System.out.println("count的值是"+count); } }上面代码的一个线程中count++一行的操作,其实对应了在CPU中执行的三步指令。
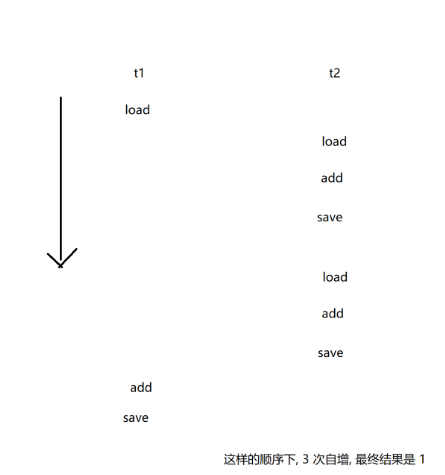
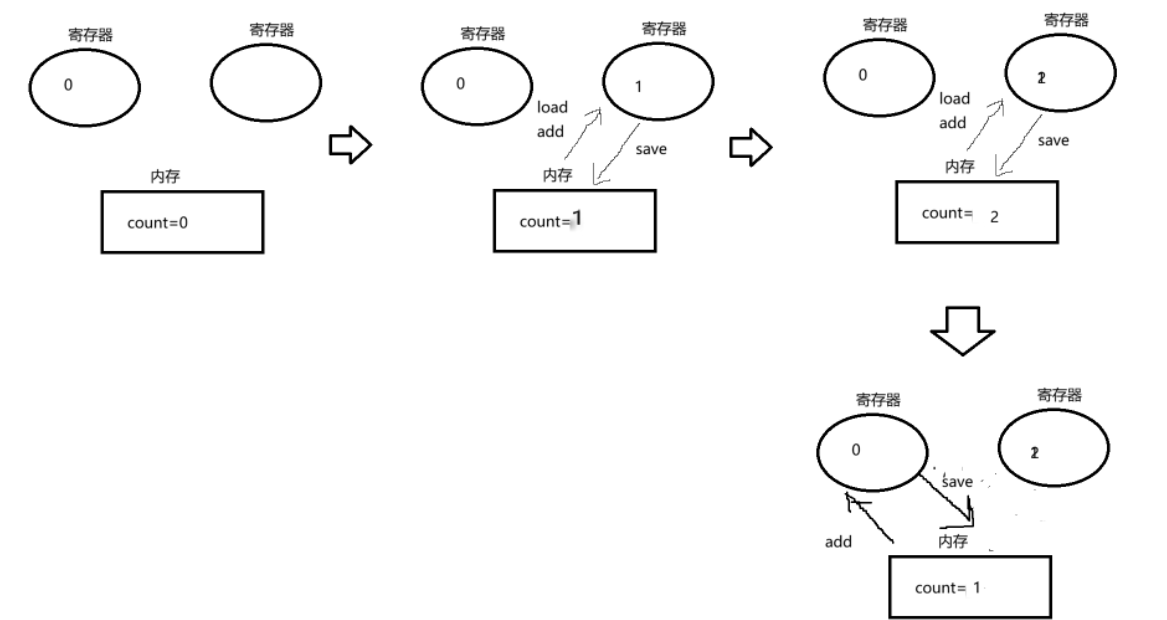
可以看到如果按照我们图中这样的执行,在两个寄存器上单独更新count值,不互相干扰,肯定不会造成问题。但是由于我们的原因1(线程调度完全随机),原因2(对同一值进行修改),原因3(修改操作不是原子操作)就会造成接下来的问题:
由于不是原子操作,且随机调度使得CPU的指令执行也变得混乱随机,从而造成了如此效果。这种杂乱的情况不止这一种,多种综合下来就造成了我们例子那样的随机数值现象。
这种线程不安全问题,是由原子性造成的。
可见性造成的多线程不安全:
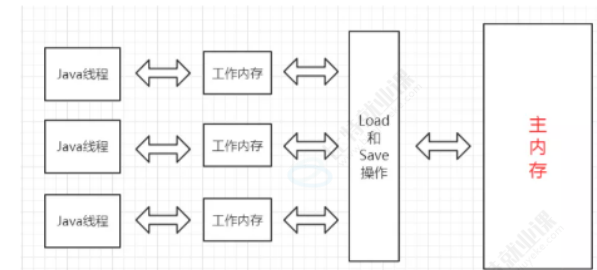
可见性:可见性指的是,“一个线程”修改“共享变量”的数值,“另一个线程”中能及时知道“共享变量”的值已经被修改了。
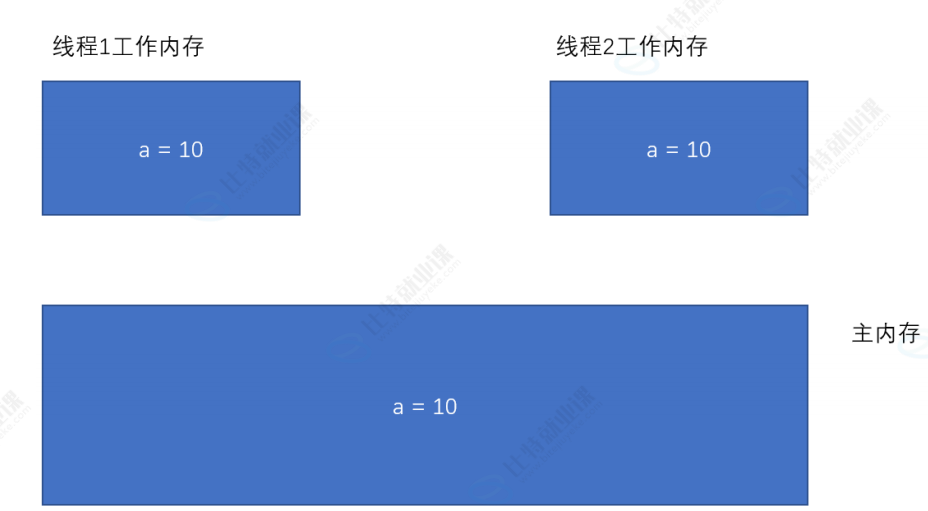
如上图所示,一般情况,我们每个Java线程都有属于自己的“工作内存”(一般指CPU中的寄存器或者缓存区),一般线程共享变量是存储在主内存(一般就是内存)中。
这里我们还要补充两个操作:
- 线程读取共享变量时,先拷贝共享变量值到自己的“工作内存”中
- 线程修改共享变量时,对拷贝在“工作内存”中的值进行修改,再传递回主内存中
有了这些基本概念我们就能介绍“可见性”带来的线程不安全问题
我们先读取共享变量到两个线程的工作内存区中
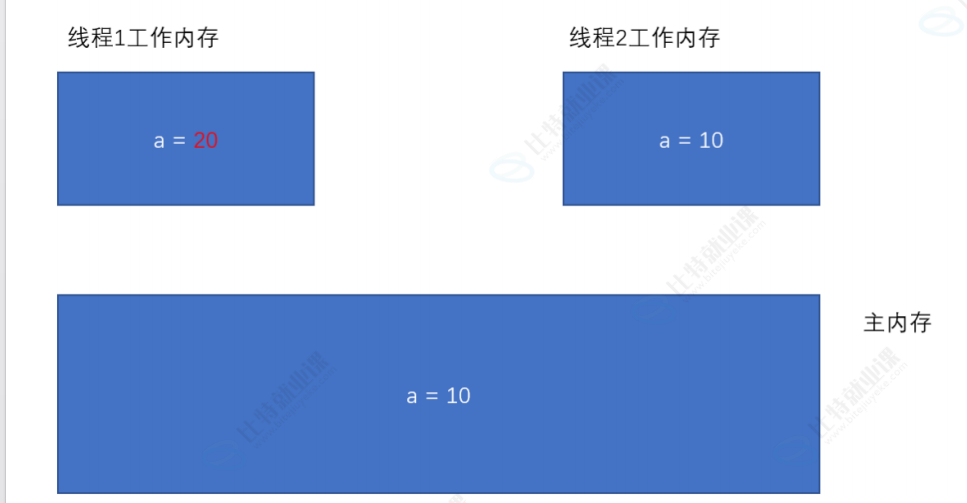
接下来,在线程1中修改变量值,这样的情况下,如果线程2要使用共享变量,会因为主内存值没有及时修改,导致线程不安全(类似于脏读,使用了错误的数据),如下图:
指令重排序造成的线程不安全问题:
1
多线程安全问题的解决
Synchronized锁解决原子性问题
我们知道由于“随机调度”,“多线程对同一变量修改”,“操作不是原子的”等原因造成了,我们先前例子的结果问题,我们思考如何解决这个问题?
只要我们让两个线程“互斥”各干各的,有原子性不就行了吗?
于是我们只要引入“锁”就能完美解决这个问题
引入锁后的代码以及运行结果:
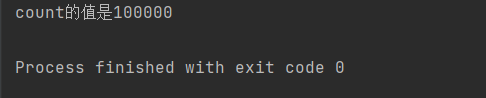
public class demo15 { public static int count=0; //解决多线程安全问题(锁) public static void main(String[] args) throws InterruptedException { Object locker=new Object(); Thread t1=new Thread(()->{ for (int i = 0; i <50000; i++) { synchronized (locker) { count++; } } }); Thread t2=new Thread(()->{ for (int i = 0; i <50000; i++) { synchronized (locker) { count++; } } }); t1.start(); t2.start(); t1.join(); t2.join(); System.out.println("count的值是"+count); } }运行结果:
可以看到就此我们成功使得两线程相加的结果得到了正确的结果。这样的结果依赖于Synchronized的锁特性。那么我们接下来介绍一下Sychronized
Synchronized的特性以及例子解析
Synchronized这把锁能够起效,主要时因为它的特性“互斥”
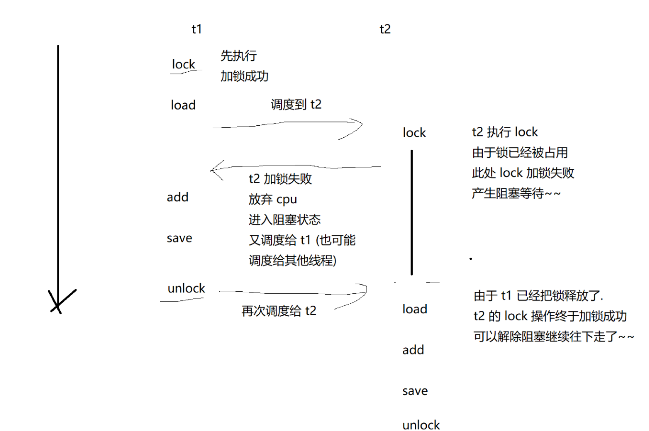
什么是“互斥”?相当于我们对两个线程(针对同一变量进行修改)进行Sychronized加锁。
其中某个线程执行到了某对象的synchronized中,其他线程也执行到童话一个对象的synchronized中就会“阻塞等待”(等第一个线程执行完解锁,才会执行,相当于真正意义上一个执行完才会执行另一个,不会造成执行时互相的指令插队)。
- 进入synchronized修饰代码块,相当于“加锁”
- 退出synchronized修饰的代码块,相当于“解锁”
这里我们需要明确一个最核心的理念,也是synchronized能发挥效果的原因:
理念:是对多个线程上同一把锁(同一个对象),这样才能造成互斥(“阻塞”),核心!!!“阻塞等待”!!!不会造成插队效果
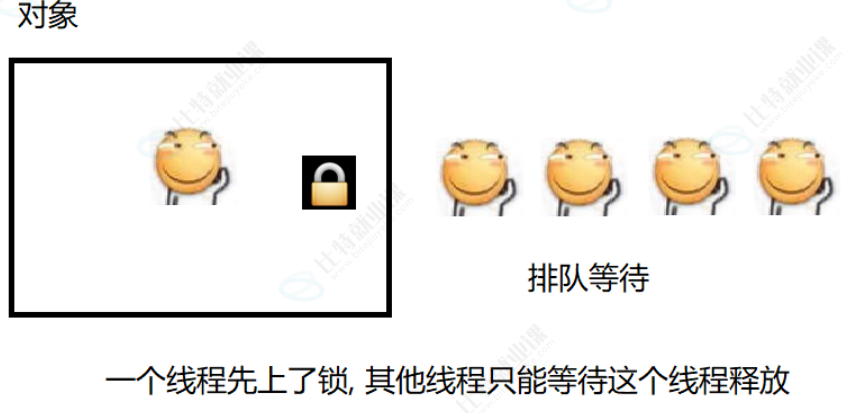
这里我们可以使用这样的一个例子来帮助大家解析:
多个人(多个线程)都想进入厕所(对象),但是由于某个人(其中一个线程)上锁了(synchronized),其他人(线程)只能排队等待锁释放(阻塞等待)。
那么我们就可以解析,为什么使用synchronized锁能够解决上面例子的问题了:
正是因为加锁阻塞,导致t2线程无法进行“插队”执行,因此能够两个独立执行。
Synchronized的使用
synchronized的使用需要我们指定具体的对象,才能直接使用,因此我们使用时要特别注意这个点
修饰代码块:锁任意对象
public class SynchronizedDemo { private Object locker = new Object(); public void method() { synchronized (locker) { } } }注意!!!locker对象是Object类型的
修饰代码块:锁当前对象
public class SynchronizedDemo { public void method() { synchronized (this) { } } }
直接修饰普通方法:锁的是“当前类对象”
public class SynchronizedDemo { public synchronized void methond() { } }
修饰静态方法:锁的是“当前类的对象”
public class SynchronizedDemo { public synchronized static void method() { } }
总而言之,synchronized对什么对象加锁并不重要,重要的是两个线程是否对同一个对象进行加锁,这样才能真正产生“阻塞等待”的效果
Synchronized使用可能产生的问题
Synchronized的特性补充--可重入性
不管是对于哪种语言,一般来说使用锁都会产生一个问题,我们使用下面的案例作为引子,来引出我们要介绍的问题以及解决方法。
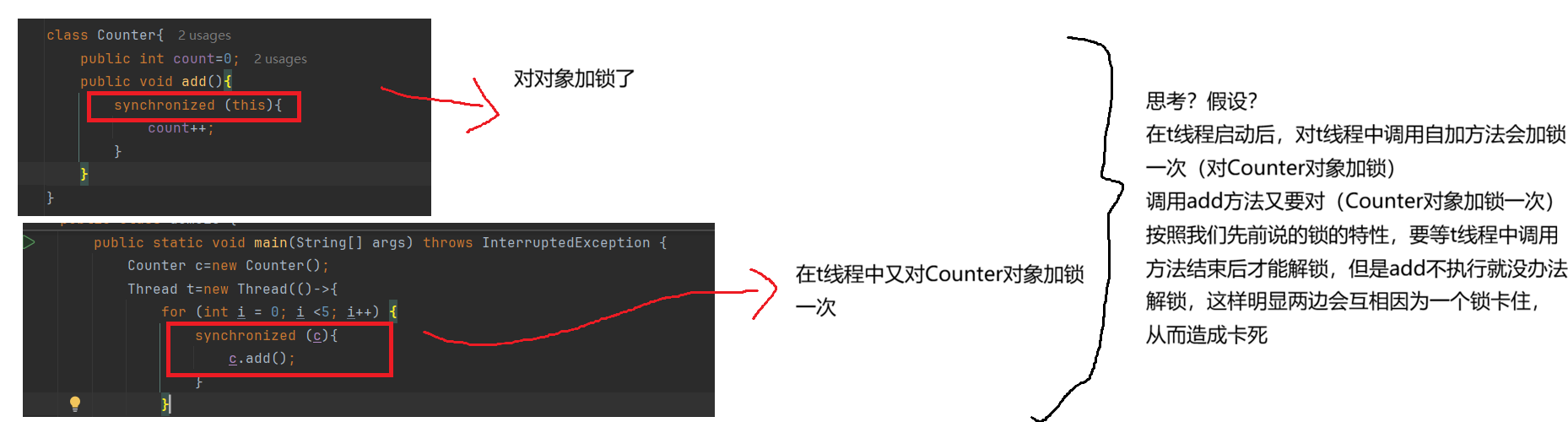

可以看到我们程序最后执行出来的结果并不是我们所假设的那样,而是能正常进行自加的操作,并没有因为两个线程的加锁而造成卡死,这是为什么呢?
这是因为synchronized的特性“可重入性”。
可重入性:
简单来说,synchronized在第一次加锁之后,会记录下加锁的线程,在第二次对线程进行加锁时(必须是同一把锁加锁两次)就会对第二次加锁的线程进行判断:
- 如果是同一个线程,就会直接跳过第二次加锁这个操作(同一个线程不用管)
- 如果不是同一个线程,就会产生阻塞效果
值得一提的是,“可重入性”一般是对同一个线程而言才有的。
但是根据上面的示例,我们可以想象一种情况,会不会特殊地出现两个线程,造成这种互相卡死的情况?很明显是有可能出现的。因此,我们会重点讨论这种情况的成因以及解决方法在后文。
死锁的产生
我们官方定义上面这种情况的产生,叫做“死锁”。
我们来介绍死锁产生的三种原因:
- 一个线程一把锁,但是重复加锁两次(对于synchronized可重入锁,不存在这种情况)
- 两个线程两把锁,两线程互相获取锁卡住
- M个线程N把锁(典型的“哲学家就餐问题”)
死锁成立的四个必要条件(任意打破一个,就能避免死锁问题):
- 锁是互斥的
- 锁不可被抢占(A先获取到locker,B也想获取locker,B就会被阻塞)
- 请求和保持(A已经获取到了locker1(不释放),但是还想获取locker2),也可以理解成“吃着碗里的,想着锅里的”
- 循环等待/环路等待(车钥匙在家,家钥匙锁在车里)
避免死锁的一般方法:
- 打破请求和保持==>代码中避免出现“锁的嵌套”
- 打破循环等待==>约定加锁的顺序(把锁进行编号1,约定任何一个线程多把锁的时候,都需要按照编号从小到大的顺序来加锁)
我们接下来对后两种情况进行介绍以及解决方法的介绍:
两个线程两把锁互相卡死
我们先通过一个简单的例子来说明这个情况:
就像
面对这种情况,我们必然束手无策啊(当然找开锁师傅何尝不是一种好办法),这就是一种“死锁”。
接下来我们就举一个这种情况的代码进行说明
public class demo17 { //两个线程两把锁,互相获取造成的死锁 public static void main(String[] args) { //先创建两把锁 Object locker1=new Object(); Object locker2=new Object(); Thread t1=new Thread(()->{ synchronized (locker1){ System.out.println("线程1获取到locker1"); try { Thread.sleep(1000); } catch (InterruptedException e) { throw new RuntimeException(e); } synchronized (locker2){ System.out.println("线程1获取到locker2"); } } }); Thread t2=new Thread(()->{ synchronized (locker2){ System.out.println("线程2获取到locker2"); try { Thread.sleep(1000); } catch (InterruptedException e) { throw new RuntimeException(e); } synchronized (locker1){ System.out.println("线程2获取到locker1"); } } }); t1.start(); t2.start(); } }可以看到我们通过Sleep的阻塞,保证两个线程都先获取一把锁,这样就造成了两个线程的互相卡死:
可以看到程序执行完第一层锁,就没能接着执行下去,卡死了。
根据上面的四个必要条件,我们只要破除一个条件就能避免这个程序死锁。
这个程序本质还是两个线程分别去获取两把锁,但是因为顺序问题造成了死锁
我们这里破解第四条,调整两个线程获取锁的合理顺序就能破解死锁问题:
public class demo18 { public static void main(String[] args) { //调整好,两个线程获取锁的顺序 //这样就不会造成死锁 Object locker1=new Object(); Object locker2=new Object(); Thread t1=new Thread(()->{ synchronized (locker1){ System.out.println("线程1获取到locker1"); try { Thread.sleep(1000); } catch (InterruptedException e) { throw new RuntimeException(e); } synchronized (locker2){ System.out.println("线程1获取到locker2"); } } }); Thread t2=new Thread(()->{ synchronized (locker1){ System.out.println("线程2获取到locker1"); try { Thread.sleep(1000); } catch (InterruptedException e) { throw new RuntimeException(e); } synchronized (locker2){ System.out.println("线程2获取到locker2"); } } }); t1.start(); t2.start(); } }可以看到我们利用了锁的不可抢占,以及调整了合理的顺序,解决了这个死锁问题。

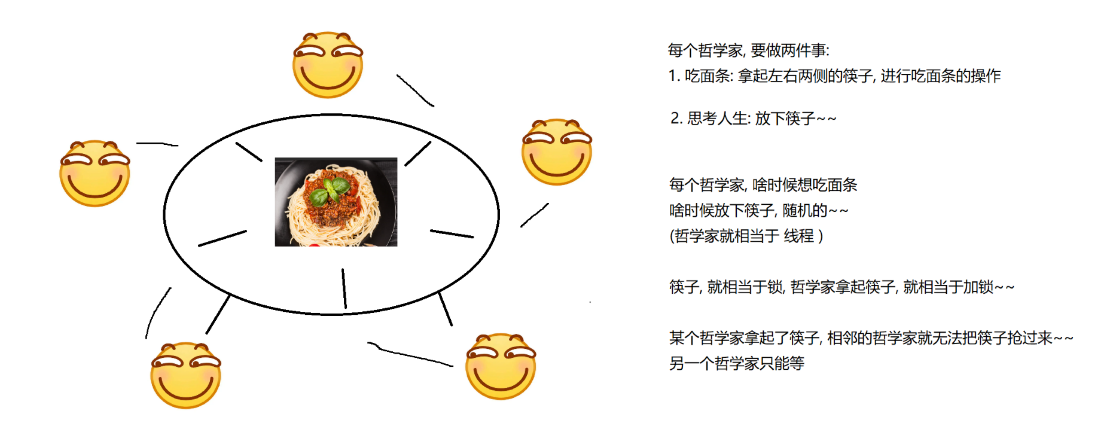
M个线程N把锁
这种死锁,最著名的例子就是“哲学家就餐问题”
如果每个哲学家都拿起了他们左手边的筷子,那么所有人都会缺少一只筷子,也就都无法进行就餐,陷入了“死锁”
根据上面一般解决死锁的方法,解决“哲学家就餐问题”一般使用的是“打破循环等待”。
我们对每一个筷子进行1--5的编号,每个哲学家都只能拿起小的筷子先,这样就一定会有一个先后顺序,就会有一个人先就餐完,然后依次每个线程都得以执行拿到锁。
Volatile解决可见性问题
前面我们提到内存可见性问题,本质上就是一个线程更新“主内存”中变量,另一个线程使用的是“工作内存”中的副本(没有及时更新数值),从而造成的线程不安全问题。
正常来说,更新变量应该耗时不长,为什么还会专门出现这种“变量更新不及时”问题呢???这实际上涉及到“编译器优化”功能
编译器优化问题:
引入问题之前,我们先通过一个代码示例来实际体验一下“可见性”造成的危害
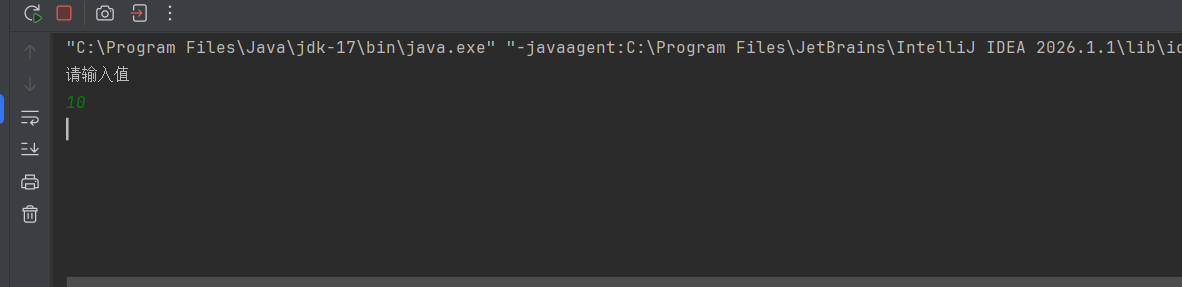
public class demo19 { public static int count=0; //内存可见性问题 public static void main(String[] args) { Thread t1=new Thread(()->{ while (count==0){ } }); Thread t2=new Thread(()->{ Scanner scanner=new Scanner(System.in); System.out.println("请输入值"); int n=scanner.nextInt(); count=n; }); t1.start(); t2.start(); } }可以看到关键逻辑就是:输入改变count的值后,所有线程将结束。
但实际执行的效果却是这样:
可以看到我们在给count赋值10后,线程1仍旧在执行,这就是一个典型的“内存可见性”问题。线程1的工作内存中没有及时更新到count的值!
那么具体“编译器优化”是怎么实现的呢?我们通过分析上面代码来了解。
这么一套编译器优化流程下来,也就出现了我们上面案例的bug出现,这是不可避免的,因此我们只能引入其他方法来解决这个问题

因此,在这里我们引入一个关键词volatile可以帮助我们解决可见性造成的线程不安全问题。
volatile的主要功能如下:
1.代码在写入volatile修饰的变量的时候,
- 改变线程工作内存中volatile变量副本的值
- 将改变后的副本的值从工作内存刷新到主内存
2.代码在读取volatile修饰的变量的时候,
- 从主内存中读取volatile变量的最新值到线程的工作内存中
- 从工作内存中读取volatile变量的副本
简单来说,我们可以这样理解volatile关键字:用volatile修饰的变量,就像被加上了一个“易变”的标识,这样每次对volatile修饰的变量进行修改时,CPU都会优先“更新所有有关的数值”。不会被优化掉。
我们只需要增加一个“volatile”在变量之前,编译器就不会优化掉相关的“更新操作”,我们的可见性问题也就可以完美解决掉了
补充说明:volatile并没有“互斥”特性,因此只能针对于“一个线程读,一个线程写”的情况,无法用于“两个线程同时对一个变量写”的情况,先后顺序无法确定
关于“内存可见性”的问题,有许多说明,这里我们介绍两种主流的说法,帮助大家理解其“内核”,应付面试
1.JMM(Java内存模型)
核心机制:
- Java进程中,每个线程都会有一份工作内存
- 这些线程会共享一个主内存
当一个线程针对某个数据进行操作的时候:
- 修改:先把数据从主内存拷贝到工作内存,对工作内存进行操作,再写回主内存
- 读取:把数据从主内存拷贝到工作内存,从工作内存中读取
造成内存可见性:
- t1线程while循环判定的是“工作内存”中的数据(相当于对变量的读取)
- t2线程更改的是主内存(更改t2的工作内存后,再写回去),但是由于t1工作内存一直是“以前主内存的副本”,导致修改没有影响到t1的工作内存
2.编译器优化机制(我们先前介绍的)
特殊情况补充:
如果我们没有加上volatile,但是在循环中加入sleep,也能解决这个问题,这是为什么呢???
本质:
sleep操作会占用更多资源,因此CPU看“大头”,忽略“小头”,也就不会编译器优化了,从而不会造成“内存可见性”的多线程不安全问题


Wait和Notify解决线程饿死问题
我们可以知道操作系统对线程的调度是随机的,因此谁先执行,哪个阶段是谁执行是完全不明确的
(注解:join方法只是规定了等待这个线程执行完,可以理解成实际上是决定“哪个线程最后执行”)
因此,可能会有某个线程不断插队执行,从而造成其他线程无法执行,出现“线程饿死”的情况
wait和notify组合的使用,一般是适用于“希望线程按照一定顺序先后执行”的时候

相当于去银行ATM机上取钱,但是1号取完就出来,但是他不放心钱拿完没,又回去看,就这样一直重复,那么2号就一直不能进去取钱,(1线程没完全结束,操作系统调用2,刚准备开始执行又调用回线程1)从而造成了“线程饿死”。
对于这个问题,我们解决的办法就是规划好“谁先执行,谁后执行”,做好顺序先后的规定调度即可
我们就要引入wait和notify方法。
wait方法:
1.wait做的事情:
- 使当前执行代码的线程进行等待(把线程放到等待队列中)
- 释放当前的锁
- 满足一定条件时被唤醒,重新尝试获取这个锁(wait要搭配synchronized来使用,脱离synchronized使用wait会直接抛出异常)
2.wait结束等待的条件:
- 其他线程调用该对象的notify方法
- wait等待时间超过(wait方法提供一个带有timeout参数的版本,来指定等待时间)
- 其他线程调用该等待线程的interrupted方法,导致wait抛出InterruptedException异常
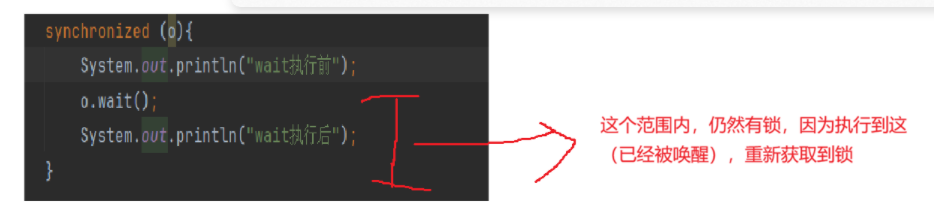
public class demo21 { public static void main(String[] args) throws InterruptedException { Object o=new Object(); synchronized (o){ System.out.println("wait执行前"); o.wait(); System.out.println("wait执行后"); } } }譬如这样执行之后,就wait之后就会进入“阻塞状态”,从而一直无法执行结束,我们也不能一直放任其阻塞,因此,我们就要使用到notify唤醒
注解:wait执行时干的“三件事”:
- 释放锁(把锁交给其他线程来执行)
- 等待其他线程的通知(进入阻塞状态)
- 当通知到达之后,从阻塞状态回归就绪状态,并且重新获取到锁
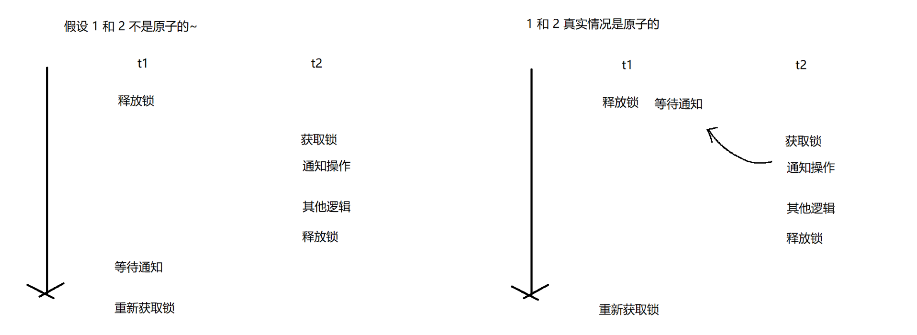
注:1和2必须是原子的(同时进行)
如果1和2不是同时进行就会出现下面的结果:
如果是第一种情况的话,wait刚释放完锁,还没有进行任何“准备”就被重新唤醒,唤醒之后wait又进入“阻塞状态”,这样之后就没有线程将他唤醒,一直错过了
一个小补充:后续操作仍然是有锁的,不会有线程安全问题
Notify方法:
notify方法是唤醒等待的线程
- 方法notify()也要在同步方法或同步块中调用,该方法是用来通知那些可能等待该对象的对象锁的其他线程,对其发出通知notify,并使它们重新获取到该对象的对象锁
- 如果有多个线程等待,则由线程调度器随机挑选出一个呈wait状态的线程(并没有“先来后到”)
- 在notify()方法后,当前线程不会马上释放该对象锁,要等到执行notify()方法的线程将程序执行完,也就是退出同步代码块之后,才会释放对象
在这里我们使用一个例子代码来给大家看看wait和notify结合使用的效果:
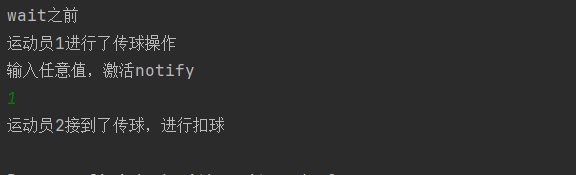
public class demo20 { //简单看看wait和notify的调用执行 public static void main (String[] args) { Object locker=new Object(); Thread t1=new Thread(()->{ synchronized (locker){ System.out.println("运动员1进行了传球操作"); Scanner scanner=new Scanner(System.in); System.out.println("输入任意值,激活notify"); scanner.next(); locker.notify(); } }); Thread t2=new Thread(()->{ synchronized (locker){ try { System.out.println("wait之前"); locker.wait(); System.out.println("运动员2接到了传球,进行扣球"); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); t2.start(); t1.start(); } }
可以看到线程2先获取到了锁,然后进行wait解锁锁交予线程1,线程1完成了先唤醒wait并且进行完剩下的所有操作之后,释放锁给线程1,重新获取到锁后线程1继续执行后续的内容
notifyAll:释放所有的线程
如果有多个线程wait进入阻塞的话,我们单单使用notify方法,操作系统只会随机唤醒一个阻塞的线程,如果我们需要全部线程启动的话,需要使用另一个方法notifyAll
public static void main(String[] args) throws InterruptedException { Object o=new Object(); Thread t1=new Thread(()->{ synchronized (o){ System.out.println("wait执行之前"); try { o.wait(); System.out.println("wait执行之后"); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); Thread t2=new Thread(()->{ synchronized (o){ System.out.println("wait执行之前"); try { o.wait(); System.out.println("wait执行之后"); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); Thread t3=new Thread(()->{ synchronized (o){ System.out.println("wait执行之前"); try { o.wait(); System.out.println("wait执行之后"); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); Thread t4=new Thread(()->{ synchronized (o){ System.out.println("wait执行之前"); try { o.wait(); System.out.println("wait执行之后"); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); Thread t5=new Thread(()->{ synchronized (o){ System.out.println("notify执行之前"); System.out.println("输入任意值,激活notify"); Scanner scanner=new Scanner(System.in); scanner.next(); o.notifyAll(); System.out.println("notify执行之后"); } }); t1.start(); t2.start(); t3.start(); t4.start(); t5.start(); }
wait和sleep的区别:
首先,我们要明确的是“wait和sleep都可以让线程阻塞,都可以指定阻塞的时间”
那么我们来看看它的区别是什么:
1.关于阻塞时间方面
- wait的设计是为了被notify,超时时间只是“后手”(防止一直不被唤醒“阻塞”)
- sleep的设计就是为了按照设定的时间进行“阻塞”效果
2.关于搭配锁状态方面
- wait必须搭配锁使用
- sleep不需要
3.关于释放锁的方面
- wait一进来就会先释放锁,等待notify唤醒和执行完后,再获取到锁
- sleep放在锁内部,休眠时不会释放锁
4.关于interrupt强制唤醒方面
- wait虽然能够通过interrupt唤醒,实际上更希望通过notify唤醒(正常情况),notify唤醒之后随时可以再wait,再notify
- sleep和interrupt,interrupt是可能把线程强制终止掉的
关于Java语言的多线程知识,我们就介绍到这里了,希望这篇文章能够帮助到大家查漏补缺或者更好的理解“多线程”这个我们以后开发中重要的部分。鄙人才疏学浅,如文章中有误,还请大家多多包涵。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)