[AVSR]Robust Self-Supervised Audio-Visual Speech Recognition论文阅读与总结
一、论文背景介绍
论文标题:Robust Self-Supervised Audio-Visual Speech Recognition
作者是来组Meta AI团队和TTIC(丰田芝加哥理工)的三个大佬,而Meta AI团队可以说是全球语音自监督最强团队之一,曾经做出了wav2vec、HuBERT、WavLM、XLS-R等一系列里程碑模型,他们很多经典论文可以说是学习AVSR方向学生们的必读作品s
二、Abstract-摘要
在基于音频的automatic speech recognition (ASR)自动语音识别任务中,模型在环境噪音的影响下识别率会显著下降,其中尤其容易受到他人语音干扰的影响,因为模型不好判断说话人是谁。Audio-visual speech recognition (AVSR)即视听语音识别系统,通过引入视觉模态的信息,利用视觉对语音噪音影响的不变性,来增强模型对语音识别任务中抗干扰能力的提升,提高模型的鲁棒性,并帮助模型聚焦于说话人,而以往AVSR模型大多聚焦与有监督学习范式,受限于标注数据的规模。所以在本文基于AV-Hubert(同团队提出的视听模型)提出了一种自监督的AVSR框架。
这个AVSR框架在LRS3(当时最大的AVSR数据集)上,通过文中的方法在存在混响噪声的情况下,使用不到10%的标注数据(433小时 vs. 30小时),性能较现有最优水平提升了约50%(词错率从14.1%降至28.0%),同时实现基于音频的模型的词错误率(WER)平均降低超过75%(25.8% 对比 5.8%)
三、方法介绍
3.1核心主角:AV-HuBERT 模型:
AV-HuBERT = 音频 + 视频版的 HuBERT,可以说是这篇论文的基础,下面我会介绍这个模型,如果想进一步了解可以点击链接阅读论文了解。
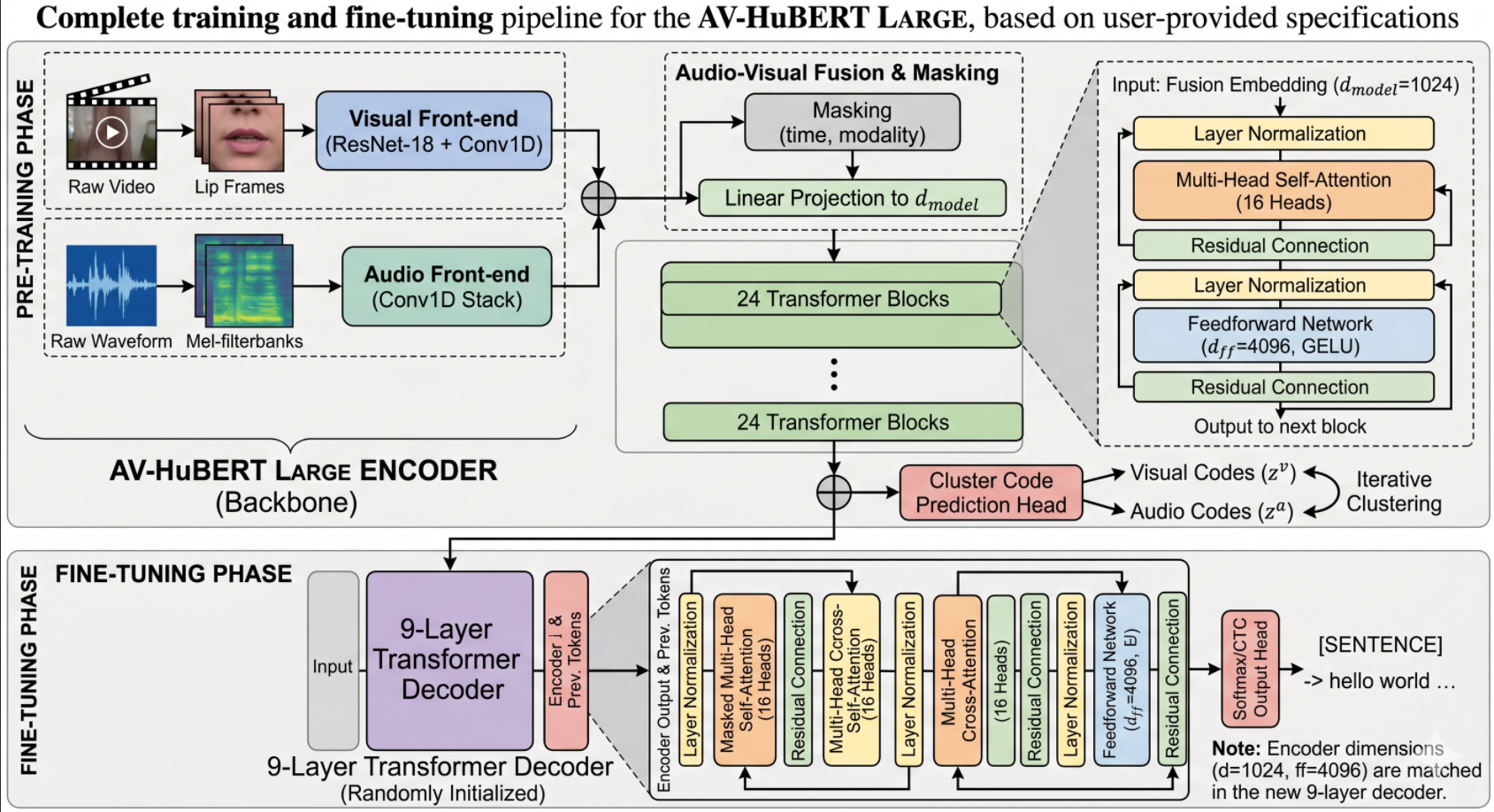
如果用一句话概括AV-HuBERT模型的作用:用无标注音视频自己教自己,学会声音和唇形的对应关系。
3.2迭代学习 (Iterative Refinement):
它的学习逻辑步骤可以分为特征聚类和掩码预测两部分,具体是这样:
1、第一步(冷处理):首先在没有标注的音频特征MFCC(梅尔倒谱系数)上通过聚类,生成离散的标签,给后续的掩码预测任务生成可使用的标签。使用这些离散的标签作为真值,把掩码处理后的音视频数据输入模型,训练一轮。
2、第二步:迭代启动的关键,通过第一轮的训练,我们已经有了一个能够具有初步知识的AV-HuBERT模型,此时我们再把这一批数据输入到训练了一轮的模型中,处理完后,把模型最后一层,即第24层中所有的输出向量读出,此时的输出向量已经具有对数据的更深刻理解,通过对这些输出向量再次进行聚类,通常聚类数量会变多,我们得到了一批新的标签,这一步生成的标签质量极高,已经非常接近“音素”或“字根”。
3、第三步:此时重复第二步(论文中重复迭代了5次),在这个过程中,模型被迫学习唇形和声音的关联。即便视频中某几帧被遮挡(Masked),模型也要能根据音频预测出对应的视觉单元标签;反之亦然。这种跨模态预测让模型真正理解了“所见即所闻”。
3.3、模型架构细节:
为了承载海量的无标注数据,本文采用了高性能的 Transformer 结构,整体架构分为预训练编码器和微调解码器两部分:
-
编码器:预训练好的 AV-HuBERT
- 论文默认使用 LARGE 版本:24 层 Transformer、16 个注意力头,与之对应的base版本则是有12层Transformer块。
- 可以同时输入音频特征 + 唇形视觉特征,输出融合后的音视频联合表征
- 预训练时做掩码聚类预测,微调时作为主干特征提取器
-
解码器:随机初始化的 Transformer
- 论文使用 9 层随机初始化的 Transformer 解码器
- 通过交叉注意力关注编码器输出的音视频特征
- 最终输出语音识别的文本序列
-
微调策略
- 先冻结预训练编码器训练若干步,保证训练稳定
- 再全部参数一起更新,让模型适配语音识别任务
-
输入说明
- 音频:正常语音频谱特征
- 视频:嘴部区域图像帧,捕捉唇动信息
- 微调时不使用掩码、不丢弃模态,保证信息的完整
四、实验部分详细介绍:
4.2 噪声设置与添加方式
为了测试模型的鲁棒性,论文引入了四种不同类型的噪声,分别是 natural 自然噪声、music 音乐噪声、babble 多人嘈杂声,以及 speech 交叉语音噪声。其中前三种噪声来自 MUSAN 数据集,而 speech 噪声直接取自 LRS3 数据集中其他说话人的语音,用来模拟多人同时说话的场景。
噪声的添加方式采用语音领域标准的信噪比混合方法,在训练时以0.25的概率随机将噪声与干净语音混合,信噪比固定为 0dB,也就是语音和噪声的音量相当。在之后的测试阶段,则使用了更丰富的信噪比等级,包括 -10dB、-5dB、0dB、5dB、10dB,覆盖从噪声远大于语音到几乎干净的所有场景,全面评估模型在不同噪声强度下的表现。
同样的为了探究预训练(包括无预训练、使用干净音频预训练和噪声增强训练)对于实验结果的影响,以及输入模态(音频或音视频)对模型的影响,文章则针对这些情况也安排了六组不同的对比实验进行比较。其中对于微调阶段仅输入音频的组别,通过对视频模态输入全零向量的安排来实现。
4.3 主要实验结果分析
4.3.1 视觉模态的影响
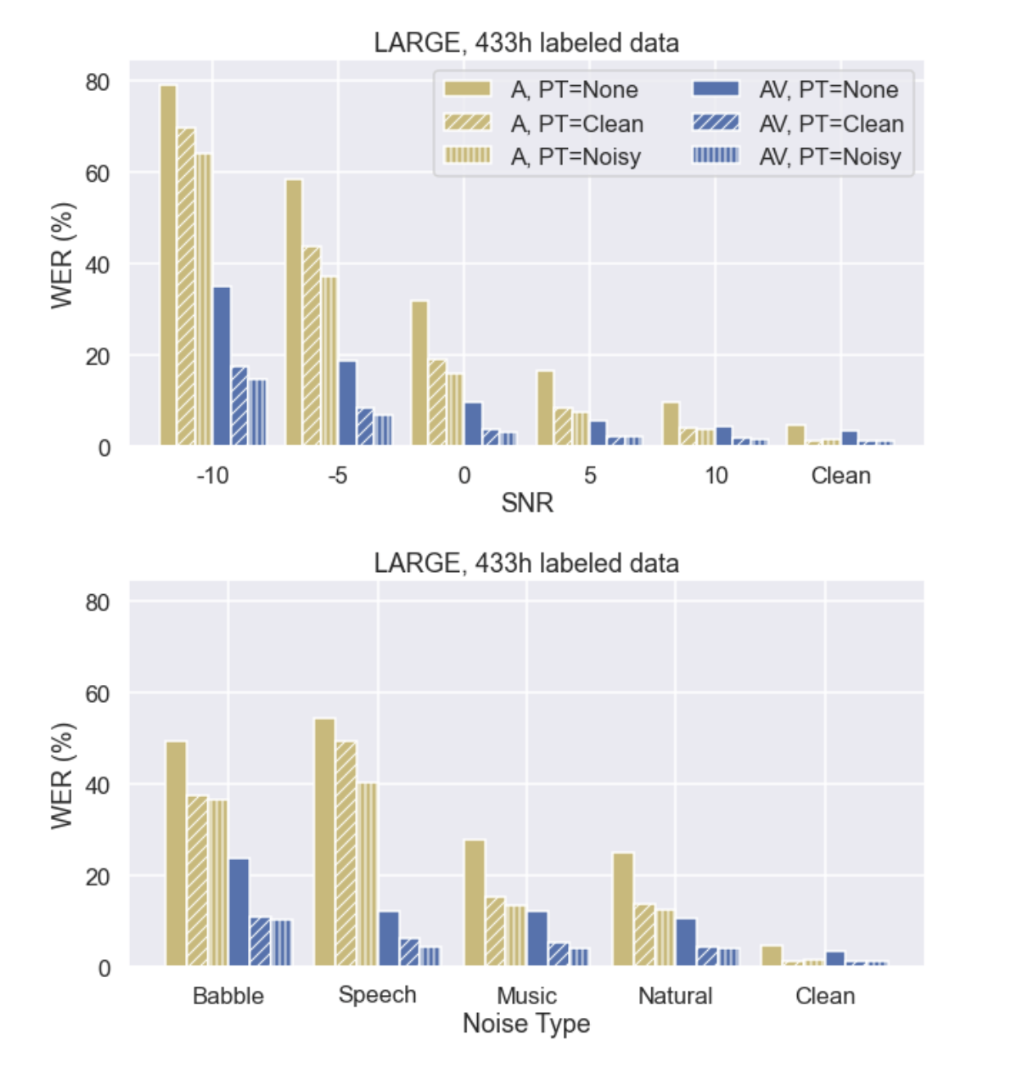
从第一张图可以看出, 噪音确实对于识别结果有着负面作用,但是在同一个噪音强度下,一方面音视频输入的错词率显著低于仅输入音频情况下的错词率。另一方面,在PreTrain阶段不引入,引入纯净音频和引入噪音增强的音频的情况下,错词率都有着一定程度的降低。而对于不同类型的噪音中,babble和speech两种与说话人声音比较相似的噪音对于识别结果的干扰是最大的。
实验结果可以从两个维度来看,分别是低资源场景和中资源场景。在低资源场景下,模型只使用 30 小时标注数据,在 babble 嘈杂噪声环境下,词错误率(WER)大幅下降,相比之前的最优模型提升接近 50%,只用不到十分之一的数据就实现了质的突破。同时,相比于纯音频的语音识别模型,本文的音视频模型将词错误率平均降低超过 75%,抗噪优势极其明显。
在使用全部 433 小时标注数据的中资源场景下,模型的表现进一步提升,在嘈杂噪声下的识别效果继续刷新最优记录,在干净语音上的词错误率更是低至 1.4%,展现出极强的识别能力。
4.3.2 预训练的影响
从上图中分析得到的,通过比较PT=None即无预训练和PT=Clean即使用干净音频进行预训练,平均而言,在分别使用30小时和433小时标注数据的情况下,AV-HuBERT预训练带来了显著的相对提升,分别达到78.3%(42.9%降至9.3%)和53.4%(14.8%降至6.9%)。该模型在低资源场景下取得了更大的提升,这证实了AV-HuBERT模型学习到的自监督视听表征所产生的影响。
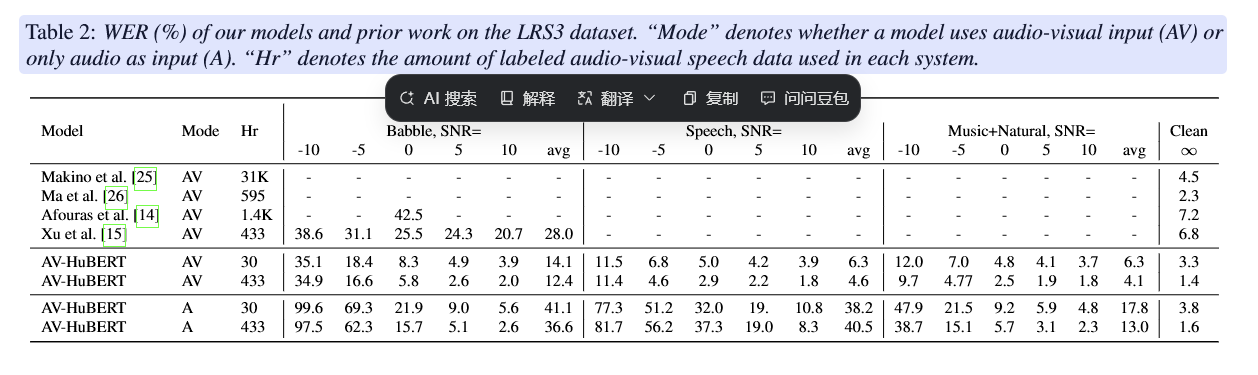
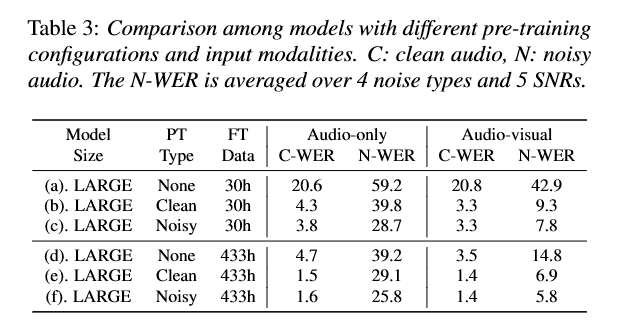
上图表一分析了文章提出的模型与之前的作者的模型在LRS3数据集上识别的错词率,表二则比较了模型在不同预训练方式和微调资源下,对于噪音增强情况下的预训练得到的错词率的比较和提升,可以看出除了在从零微调训练30H的情况下引入视频模态的错词率高于音频模态,在其他所有的情况下,引入视频模态、引入噪音增强预训练都对于模型的识别能力都有着极大的增强。
4.5 实验总结
本文提出了一种基于AV-HuBERT方法的新型先进视听语音识别(AVSR)模型,用于多模态语音表示学习。据我们所知,这是首次尝试利用大量未标记的视听语音数据构建AVSR模型。我们的视听语音识别器即使在仅有数小时标记数据的情况下,也能实现较高的识别准确率,且对不同噪声类别具有鲁棒性。在使用不到10%标记数据的情况下,我们的模型性能比当前最优模型(SOTA)提升约50%。我们的后续工作将包括将视听语音识别技术应用于现实世界的低资源和多语言场景。
码字不易,整理精读更费时间~如果这篇博客对你有收获,麻烦点个赞、收藏、转发支持一下吧!你的鼓励就是我持续更新优质论文精读的动力~
后续还会持续更新更多唇读、AVSR、自监督学习顶会论文精读,欢迎关注不迷路!我们下篇论文见~ 🚀

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)