一文搞懂 GraphRAG:传统 RAG 的「进化版」,如何让 AI 真正理解复杂知识?
含原理图解 · 场景对比 · 工作流全解析

前言
你有没有遇到过这种情况——用 RAG 搭了知识库,回答简单问题挺准,但一旦问「整体趋势是什么」「几个阵营各自的优势」这类问题,AI 就开始胡说八道?
这正是传统 RAG 的天花板。本文从原理到实践,带你彻底搞懂 GraphRAG 是如何打破这个天花板的。
一、传统 RAG 到底哪里不行了?
传统 RAG 的工作逻辑非常直接:
文档切块 → 转向量 → 存向量数据库 → 用户提问 → 检索相似块 → 大模型生成答案
这套方案对回答具体、局部、明确的问题效果很好。但一旦遇到这类问题:
「这份关于市场趋势的长期报告里,主要提到了哪几个竞争阵营?他们各自的优劣势是什么?」
它就开始掉链子。原因是这类问题的特征:
- 不针对某个单点事实
- 需要对整个文档集做高层次总结
- 需要发现潜在主题、趋势、矛盾或阵营
- 依赖关系推理和全局洞察
⚠️ 传统 RAG 核心短板:群体洞察、复杂关系分析、全局总结
二、什么是 GraphRAG?一句话先理解
| 方式 | 核心逻辑 |
|---|---|
| 传统 RAG | 从「相似文本」里找答案 |
| GraphRAG | 从「知识关系和全局结构」中做推理与总结 |
GraphRAG = 知识图谱(Knowledge Graph)+ RAG

它不只是检索相似文本,还会构建实体、关系、社区和摘要,让系统真正理解知识之间的结构关系——更接近人类的思维方式:综合已有知识体系进行提炼,而不是只看一段文字。
三、知识图谱基础:节点、边、社区
知识图谱(Knowledge Graph)也叫语义网络,由两类核心元素组成:
- 节点 Node:表示实体、概念、事件、对象等
- 边 Edge:表示节点之间的关系
实际应用举例
- Google 搜索依赖知识图谱理解查询与实体关系
- Facebook 利用知识图谱分析用户关系链,实现好友推荐
社区(Community)
GraphRAG 还引入了「社区」概念——图谱中连接紧密的一组实体,通常代表:
- 一个主题
- 一条故事线
- 一组高度相关的实体关系
社区有层级结构(C0 → C3):
| 层级 | 特点 |
|---|---|
| C0 / C1 | 高层级,更概括、更宏观 |
| C2 / C3 | 低层级,更具体、更细节 |
编号越小越宏观,编号越大越具体。
四、GraphRAG 核心工作流(图解)
整个流程分为两个阶段:索引阶段 和 查询阶段。
📦 索引阶段(Indexing Phase)
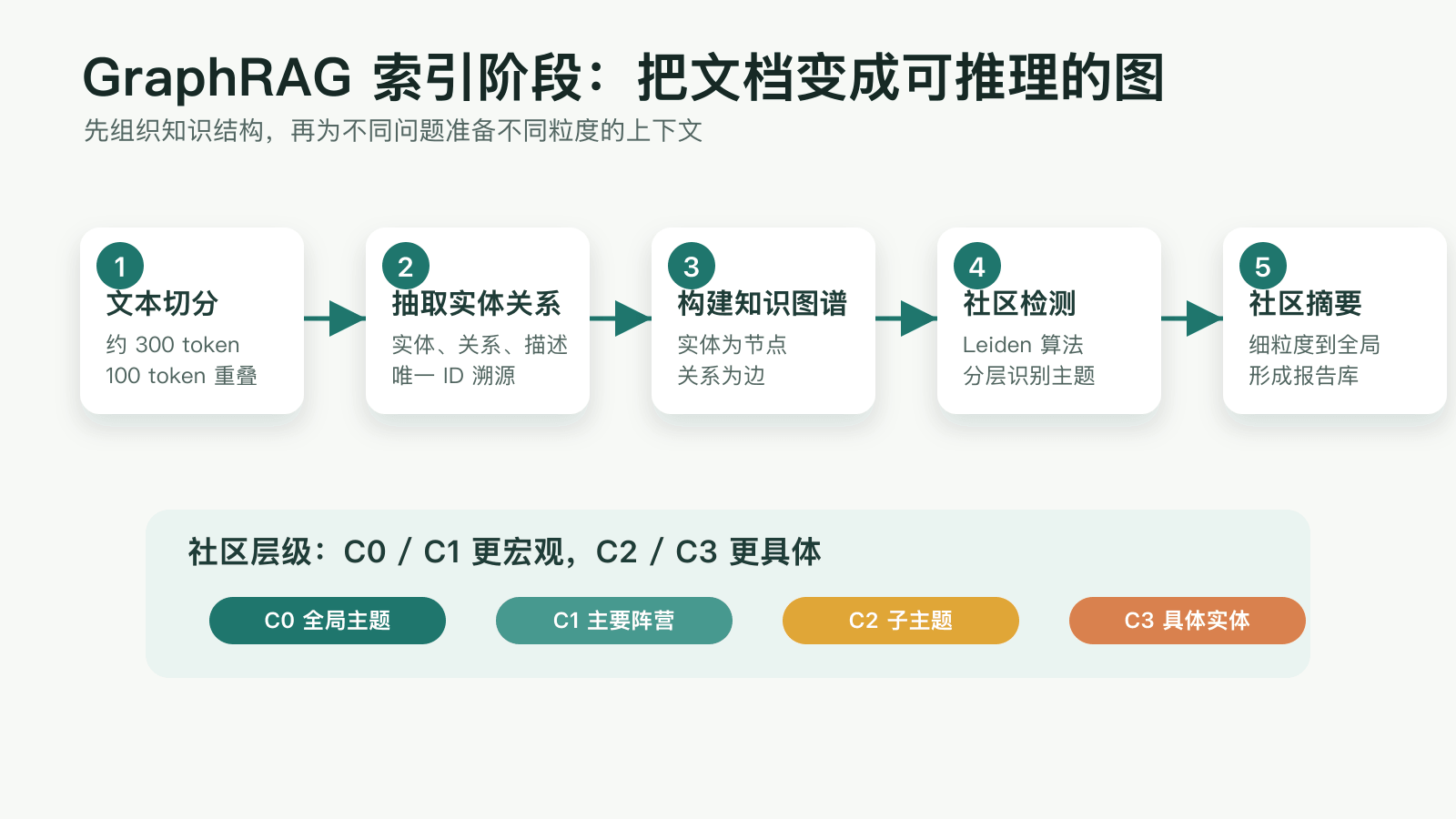
Step 1:文本切分
将文档切分为约 300 token 的子块,设置 100 token 的重叠部分,保留上下文连贯性。
Step 2:LLM 提取实体和关系
从每个文本块中:
- 提取实体、关系
- 生成实体及关系的简短描述
- 为每个实体分配唯一 ID,方便溯源
Step 3:构建知识图谱(KG)
以实体为节点、关系为边,构建全局知识图谱,展现文档中的复杂关系网络。
Step 4:Leiden 社区检测算法
识别图谱中的社区,该算法特点:
- 支持分层社区检测
- 可递归识别子社区
- 每个节点只属于一个社区
- 尽量避免遗漏节点
- 节点大小通常与重要性成正比
Step 5:分层社区摘要
| 级别 | 内容 |
|---|---|
| 第一级 | 细粒度摘要,针对具体社区 |
| 第二级 | 中等粒度,整合相关社区 |
| 第三级 | 全局级,高层次概览 |
🔍 查询阶段(Query Phase)
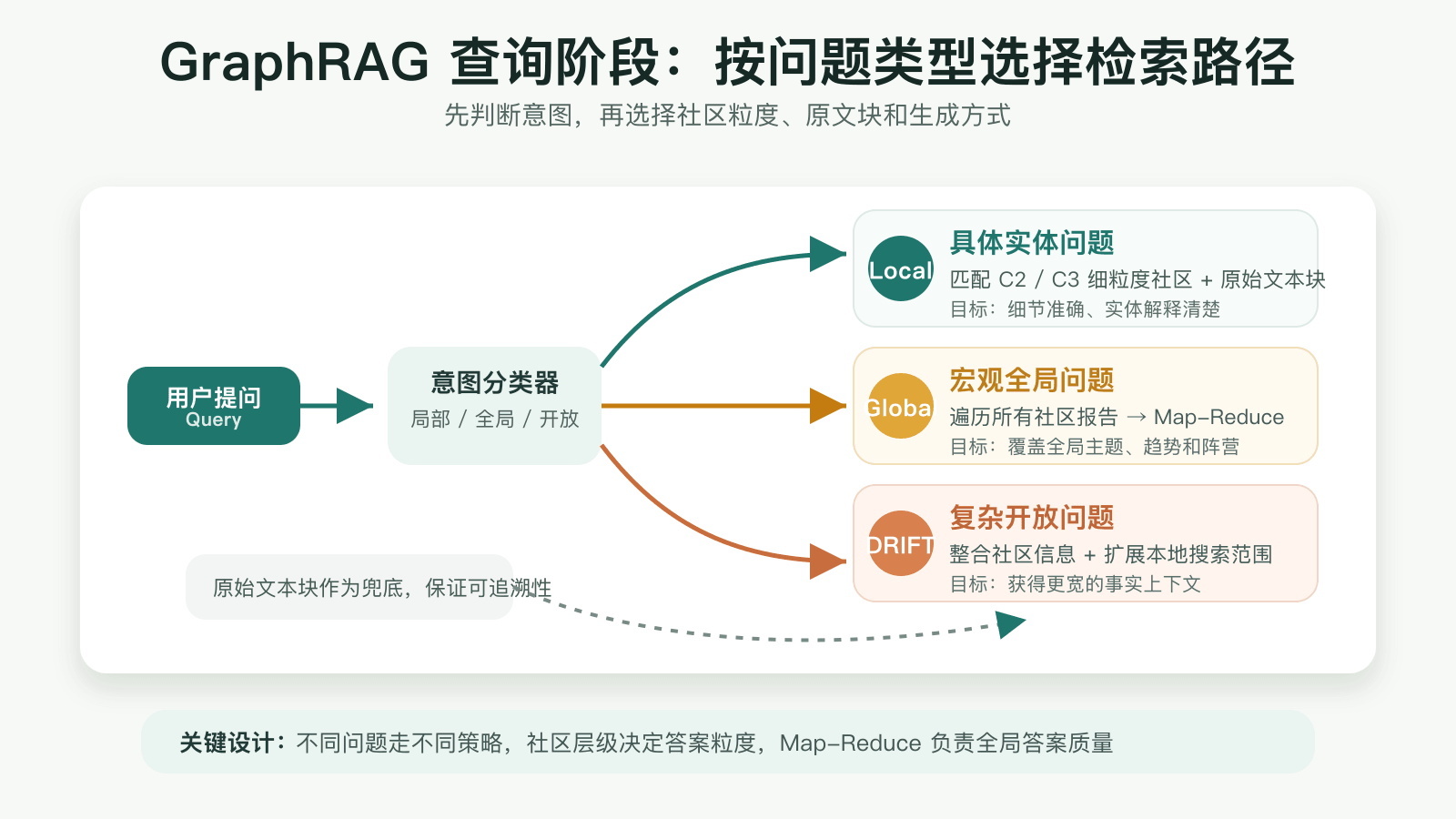
查询阶段根据问题类型,动态选择不同的检索策略,核心流程如下:
用户提问
│
├── 问题是关于具体实体? ──→ 本地搜索 Local Search
│ └── 匹配 C2/C3 细粒度社区 + 原始文本块 → 生成答案
│
├── 问题是宏观全局型? ──→ 全局搜索 Global Search
│ └── 遍历所有社区报告 → Map-Reduce → 生成全局答案
│
└── 问题复杂且开放? ──→ DRIFT 搜索
└── 整合社区信息 + 扩展本地搜索范围 → 生成综合答案
查询阶段的关键设计思路:
- 不是所有问题都用同一种策略:系统会根据问题的性质(局部 vs 全局、明确 vs 开放)自动匹配最合适的检索路径,避免资源浪费
- 社区层级决定答案粒度:本地搜索用细粒度社区(C2/C3)保证细节准确,全局搜索用高层级社区(C0/C1)保证覆盖面广
- 原始文本块作为兜底:无论哪种搜索,最终答案生成时都可以回溯原始文本块,保证可追溯性
- Map-Reduce 保证全局搜索质量:不是简单拼接所有社区摘要,而是通过重要性评分筛选,确保答案质量和相关性
💡 工程建议:实际落地时,可以在问题前加一层意图分类器,自动判断应该走本地搜索还是全局搜索,进一步提升响应效率。
五、三种查询方式深度对比

1. 本地搜索 Local Search
结合知识图谱中的相关数据和原始文本块生成答案。
- 适合:关于具体实体的问题
- 使用社区:C2 / C3 低层级细粒度社区
- 示例:
洋甘菊的治疗特性是什么?
2. 全局搜索 Global Search
搜索所有社区报告,用 Map-Reduce 方式生成答案。
- 适合:宏观性、全局性问题
- 使用社区:C0 / C1 高层级社区摘要
- 示例:
本文的核心主题是什么?
3. DRIFT 搜索
本地搜索的扩展版,整合社区信息让搜索起点更宽泛。
- 适合:复杂、开放、与固定模板不完全匹配的问题
- 特点:检索更多类型的事实
六、Map-Reduce 查询机制原理
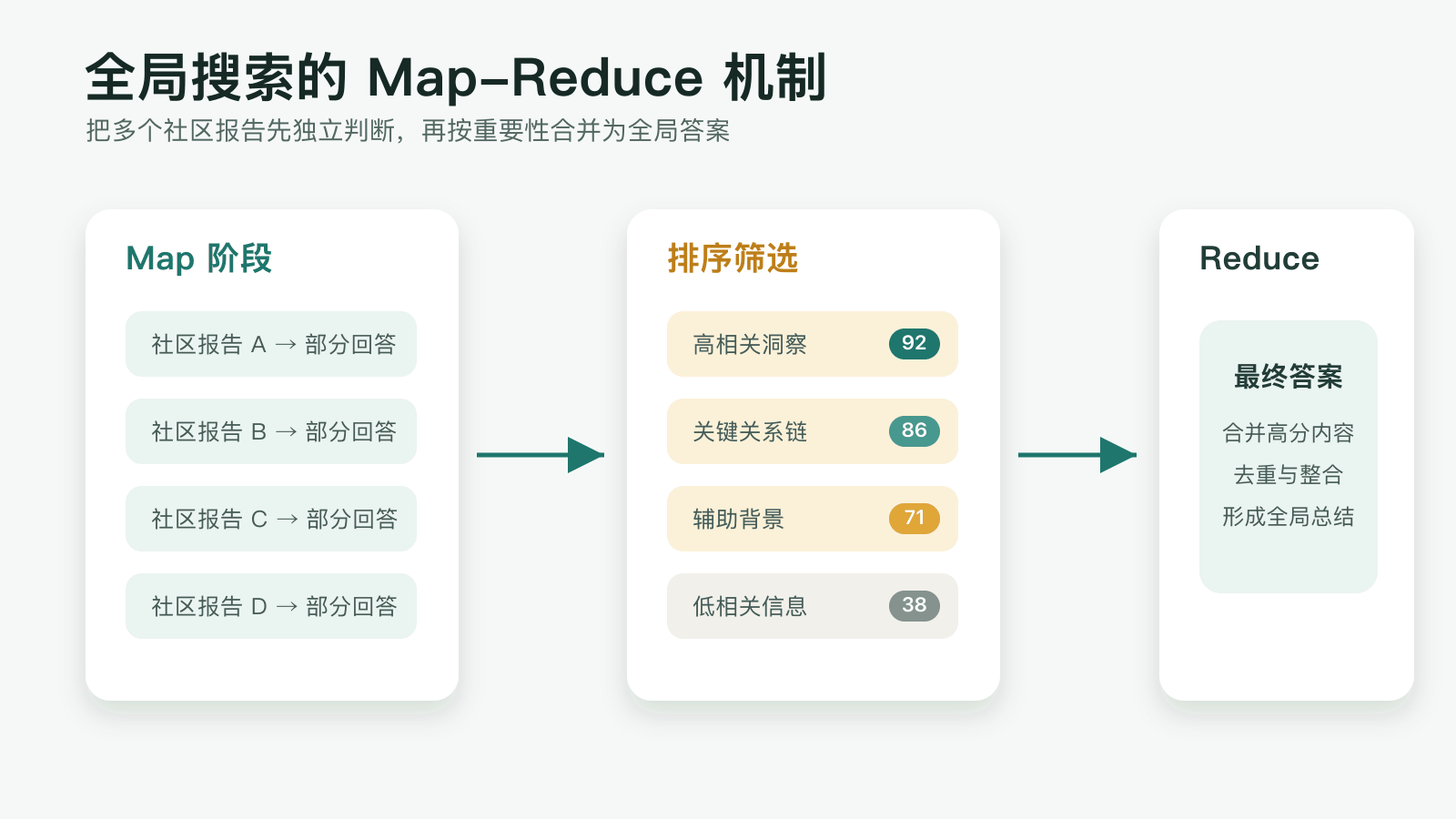
全局搜索的核心是 Map-Reduce 模式:
Map 阶段:
├── 并行处理每个社区报告
├── 为每个社区生成部分回答
└── 给每个部分回答打重要性分数(0-100)
Reduce 阶段:
├── 按重要性分数排序
├── 选取高分内容
└── 合并生成最终的全局答案
七、适合 vs 不适合场景清单
✅ GraphRAG 擅长的场景
- 长文档或多文档总结
- 复杂报告分析
- 竞争格局分析
- 市场趋势洞察
- 多实体关系推理
- 知识体系梳理
- 跨文档主题发现
- 法律、金融、科研、企业知识库等高复杂度场景
❌ 不一定适合的场景
- 简单事实问答(传统 RAG 更高效)
- 单段文本查询
- 对实时性要求极高但图谱更新成本高的任务
- 数据规模小、关系结构不复杂的任务
八、总结
| 传统 RAG | GraphRAG | |
|---|---|---|
| 核心逻辑 | 相似文本检索 | 知识结构推理 |
| 擅长场景 | 局部事实问答 | 全局洞察、关系推理 |
| 索引成本 | 低 | 较高 |
| 查询复杂度 | 低 | 中-高 |
| 最佳用例 | 精确单点问答 | 复杂知识库、多文档分析 |
一句话总结:传统 RAG 擅长「从相似文本中找答案」,GraphRAG 擅长「从知识关系和全局结构中做推理与总结」。两者是互补关系,根据业务场景合理选择,才是工程化落地的正确姿势。
如果本文对你有帮助,欢迎点赞 + 收藏,后续会持续更新 GraphRAG 实战部分(Neo4j + 项目部署)!
Tags: GraphRAG · RAG · 知识图谱 · LLM · 大模型 · AI工程

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)