Lora 代码参数介绍并实战【命名实体微调、自定义模型输出格式】
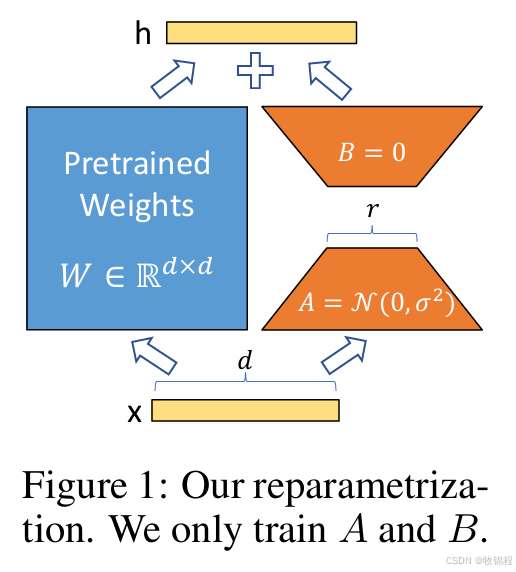
一、LoraConfig 模块详解
LoraConfig 是用于配置 LoRA(Low-Rank Adaptation) 微调方法的核心模块,它继承自 PeftConfig,提供了一系列参数来控制 LoRA 的行为。以下是关键参数及其对模型微调的影响:
1.1 核心参数及其作用
1.1.1 r(秩)
作用
定义 LoRA 适配器的低秩矩阵的维度(即“秩”),决定了参数更新的规模。
影响
-
较大的
r会增加适配器的参数数量,提升模型灵活性,但可能过拟合。 -
较小的
r减少计算量,但可能限制模型适应新任务的能力。 -
推荐范围:通常设置为
8、16或32,具体取决于任务复杂度。
1.1.2 target_modules(目标模块)
作用
指定需要应用 LoRA 的模型层(如 q_proj(查询投影)、v_proj(键投影)),支持正则表达式或列表。
影响
-
若未指定,PEFT 会自动推断架构,但对未知模型可能报错。
-
合理选择目标模块(如注意力层的
q、v)直接影响微调效果。
示例
target_modules=["q_proj", "v_proj"] 或 "all-linear"(选择所有的 linear/Conv1D 模块,除了输出层)。
注意力机制的核心层
选择q_proj(查询投影)和k_proj(键投影)的原因是:
-
这些层负责将输入映射到注意力空间的查询和键向量,直接影响模型对输入关系的建模能力。
-
相较于
v_proj(值投影)和o_proj(输出投影),调整q_proj和k_proj能更高效地改变注意力权重的分布,从而适应下游任务。
计算效率
仅选择部分模块(如q_proj和k_proj)而非全部注意力层,可以显著减少可训练参数量,提升训练速度。
1.1.3 lora_alpha(缩放因子)
作用
控制低秩矩阵的缩放幅度,与 r 共同决定权重更新的最终幅度。
影响
-
默认
lora_alpha/r(或lora_alpha/sqrt(r),若启用use_rslora)。 -
较大的
alpha会放大低秩矩阵的作用,增强适配效果,但需与r平衡。
1.1.4 lora_dropout(Dropout 率)
作用
在 LoRA 层中应用 Dropout 防止过拟合。
影响
-
较高的值(如
0.1)增强正则化,但可能削弱适配能力。 -
通常设为
0.0(默认)或较低值(如0.1)。
1.1.5 bias(偏置)
作用
是否在微调过程中更新模型的偏置(bias)参数。
参数选项
-
"none"(默认)
行为:冻结所有偏置参数,不进行更新。
适用场景:
-
希望保持预训练模型的稳定性,减少过拟合风险。
-
数据集较小,需要严格控制可训练参数数量。
-
"all"
行为:更新所有偏置参数,包括原始模型中的偏置和适配器可能引入的偏置(如有)。
适用场景:
-
需要最大灵活性,允许模型通过调整偏置更好地适配新任务。
-
数据集较大,能够支持更复杂的参数更新。
-
"lora_only"
行为:仅更新由 LoRA 适配器引入的偏置参数(若有)。
如果适配器未显式添加偏置(标准 LoRA 通常不引入偏置),则此选项无实际效果。
1.1.6 use_rslora(bool)
作用
用于控制是否启用 Rank-Stabilized LoRA(RS-LoRA)。
缩放因子调整
-
默认 LoRA:适配器的权重更新幅度由
lora_alpha / r控制。 -
RS-LoRA:将缩放因子调整为
lora_alpha / sqrt(r)。 -
数学意义:
-
当秩(
r)较小时,RS-LoRA 的缩放因子衰减更慢,避免因r过小导致更新幅度过大。 -
当
r增大时,缩放因子更平缓,提升训练稳定性。
-
性能优势
-
低秩场景(如
r=2或r=4):RS-LoRA 在实验中表现更优,尤其是在复杂任务(如生成、多分类)中,能更高效地利用低秩参数适配模型。 -
训练稳定性:通过调整缩放因子,减少梯度爆炸/消失风险,尤其适合深层模型或长序列任务。
适用场景
-
资源受限的低秩微调
-
复杂生成任务
-
长序列建模
1.1.7 modules_to_save(额外训练模块)
作用
指定除 LoRA 层外需要参与训练的其他模块(如分类头)。
示例
modules_to_save=["classifier"],适用于分类任务。
1.1.8 init_lora_weights(权重初始化)
作用
控制适配器权重的初始化方式,支持多种策略:
-
True:默认初始化。 -
"gaussian":高斯分布初始化。 -
"pissa":基于奇异值分解的快速初始化(收敛更快)。 -
"loftq":结合量化初始化(需配置loftq_config)。
影响
初始化策略直接影响训练稳定性和收敛速度。
1.1.9 use_dora(DoRA 开关)
作用
启用 权重分解低秩适应(DoRA),将权重更新分解为幅度和方向。
影响
-
在低秩(如
r=8)下性能显著优于普通 LoRA,但增加计算开销。 -
推荐在资源允许时启用。
1.2 微调时需重点关注的能力
1.2.1 任务适应能力
-
关键参数:
target_modules、r、lora_alpha。 -
通过调整目标模块和秩,控制模型对特定任务的适配程度。例如,选择注意力层的
q、v能有效提升模型对输入的理解能力。
1.2.2 参数效率与计算开销
-
关键参数:
r、use_dora、init_lora_weights。 -
较小的
r和高效初始化(如"pissa")可减少训练成本,同时保持性能。DoRA 虽增加开销,但能提升低秩下的表现。
1.2.3 抗过拟合能力
-
关键参数:
lora_dropout、modules_to_save。 -
合理设置 Dropout 和限制额外训练模块(如仅训练分类头)可防止过拟合。
1.2.4 量化与内存优化
-
关键参数:
loftq_config、init_lora_weights="loftq"。 -
通过 LoftQ 量化主干模型权重,可在有限内存下训练大模型(如 4-bit 量化)。
1.2.5 分布式训练兼容性
-
关键参数:
megatron_config、megatron_core。 -
在 Megatron 框架下训练时,需正确配置并行线性层参数。
1.3 使用建议
-
需要量化时,启用
loftq_config并设置init_lora_weights="loftq"。 -
追求更高性能时,启用
use_dora=True并适当增大r。 -
分布式训练需配置
megatron_config和megatron_core。
1.4 unsloth 中额外参数
finetune_vision_layers=True, # False if not finetuning vision layers
finetune_language_layers=True, # False if not finetuning language layers
finetune_attention_modules=True, # False if not finetuning attention layers
finetune_mlp_modules=True, # False if not finetuning MLP layers二、TaskType 模块概述
TaskType 是一个枚举类,用于标准化 PEFT 框架支持的任务类型。它定义了模型微调过程中不同的下游任务类型,帮助用户明确任务目标并适配相应的参数高效微调策略。
2.1 支持的 TaskType 枚举值及含义
2.1.1 SEQ_CLS(文本分类)
-
任务类型:对整段文本进行分类(如情感分析、主题分类)。
-
模型输出:分类标签(如
positive/negative)。 -
示例场景:
from peft import TaskType config = LoraConfig(task_type=TaskType.SEQ_CLS)2.1.2 SEQ_2_SEQ_LM(序列到序列语言建模)
-
任务类型:生成式任务,输入和输出均为序列(如翻译、摘要)。
-
模型输出:生成的目标序列。
-
示例场景:
config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM)2.1.3 CAUSAL_LM(因果语言建模)
-
任务类型:自回归生成任务(如文本续写、对话生成)。
-
模型输出:基于上文预测下一个词。
-
示例场景:
config = LoraConfig(task_type=TaskType.CAUSAL_LM)2.1.4 TOKEN_CLS(词元分类)
-
任务类型:对每个词元进行分类(如命名实体识别、词性标注)。
-
模型输出:每个词元对应的标签。
-
示例场景:
config = LoraConfig(task_type=TaskType.TOKEN_CLS)2.1.5 QUESTION_ANS(问答任务)
-
任务类型:基于上下文回答特定问题。
-
模型输出:答案的起始和结束位置。
-
示例场景:
config = LoraConfig(task_type=TaskType.QUESTION_ANS)2.1.6 FEATURE_EXTRACTION(特征提取)
-
任务类型:提取文本的隐藏表示(如生成句子嵌入)。
-
模型输出:最后一层(或指定层)的隐藏状态。
-
示例场景:
config = LoraConfig(task_type=TaskType.FEATURE_EXTRACTION)2.2 TaskType 的核心作用
2.2.1 指导模型适配器设计
-
不同任务类型需要不同的输出头(如分类器 vs 生成器),
TaskType帮助框架自动选择适配结构。 -
例如:
-
SEQ_CLS任务会在模型顶部添加分类层。 -
CAUSAL_LM任务会保留自回归生成能力。
-
2.2.2 优化训练流程
影响损失函数计算方式:
-
分类任务使用交叉熵损失。
-
生成任务使用语言建模损失(如交叉熵对生成词元的损失)。
2.2.23 控制参数更新范围
-
部分 PEFT 方法(如 IA3)会根据任务类型选择性地调整特定模块(如注意力 Key/Value 投影)。
2.3 选择 TaskType 的关键考量
2.3.1 任务本质
-
生成任务(如对话、翻译)→
SEQ_2_SEQ_LM或CAUSAL_LM。 -
结构化预测(如 NER)→
TOKEN_CLS。
2.3.2 模型架构兼容性
-
CAUSAL_LM通常用于 GPT、LLaMA 等自回归模型。 -
SEQ_2_SEQ_LM适用于 T5、BART 等编码器-解码器架构。
2.3.3 CAUSAL_LM(因果语言建模)
-
对于目前的大模型,基本上都是该类别
-
只有对于某一个专有领域的模型,才会选择其他的类别
三、加载配置
3.1 peft 加载
from peft import LoraConfig, get_peft_model, TaskType
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained('llama-7b', device_map="auto",
torch_dtype=torch.bfloat16, use_cache=False)
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=4,
target_modules=[
"q_proj", "v_proj", # 核心注意力
],
lora_dropout=0.05,
)
peft_model = get_peft_model(model, peft_config)3.2 unsloth 加载
from unsloth import FastVisionModel
model, tokenizer = FastVisionModel.from_pretrained(
"LLM-Research/Llama-3.2-11B-Vision-Instruct",
dtype=torch.bfloat16
)
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers=True, # False if not finetuning vision layers
finetune_language_layers=True, # False if not finetuning language layers
finetune_attention_modules=True, # False if not finetuning attention layers
finetune_mlp_modules=True, # False if not finetuning MLP layers
r=16, # The larger, the higher the accuracy, but might overfit
lora_alpha=16, # Recommended alpha == r at least
lora_dropout=0,
bias="none",
random_state=3407,
use_rslora=False, # We support rank stabilized LoRA
loftq_config=None, # And LoftQ
# target_modules = "all-linear", # Optional now! Can specify a list if needed
)四、代码实战
4.1 数据处理
命名实体识别 (NER) 是一种NLP技术,主要用于识别和分类文本中提到的重要信息(关键词)。这些实体可以是人名、地名、机构名、日期、时间、货币值等等。 NER 的目标是将文本中的非结构化信息转换为结构化信息,以便计算机能够更容易地理解和处理。
4.1.1 数据加载
https://www.modelscope.cn/datasets/kisskissMardy/CropDiseaseNer/summary
# -*- coding:utf-8 -*-
# @author: 牧锦程
import re
import json
def fix_number_format(text):
"""
将文本中形如 '数字 空格 数字' 的数字格式合并为连续数字格式。
"""
# 正则表达式:匹配形如 '1 200' 的数字
return re.sub(r'(\d+) (\d+)', r'\1\2', text)
def extract_entities(tokens, labels):
"""
从BIO标注数据中提取实体
Args:
tokens: 分词后的文本列表(如 ['用', '药', '太', '早'])
labels: 对应的BIO标签列表(如 ['O', 'B-Symptom', 'I-Symptom', 'O'])
Returns:
提取的实体列表,格式为 [{'entity_text': '黑点', 'entity_label': 'Symptom'}]
"""
# 将tokens和labels组合成元组列表
text_with_labels = list(zip(tokens, labels))
# 合并连续的B/I标签
entities = []
current_entity = {'entity_text': '', 'entity_label': ''}
for token, label in text_with_labels:
if label.startswith('B-'):
# 保存之前的实体
if current_entity['entity_text']:
entities.append(current_entity)
current_entity = {
'entity_text': token,
'entity_label': label.split('-')[1]
}
elif label.startswith('I-') and current_entity['entity_label']:
current_entity['entity_text'] += token
elif label == 'O' and current_entity['entity_text']:
if current_entity not in entities:
entities.append(current_entity)
current_entity = {'entity_text': '', 'entity_label': ''}
# 添加最后一个可能的实体
if current_entity['entity_text']:
entities.append(current_entity)
return entities
def process_dev_file(file_path, results):
"""处理dev.txt文件,返回符合要求的JSON数据"""
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 按空行分割段落
paragraphs = [p for p in content.split("\n")]
text, entitie = [], []
for para in paragraphs:
if para != '':
if len(para.split()) == 2:
text.append(para.split()[0])
entitie.append(para.split()[1])
else:
if len(text) != 0:
text.append(" ")
entitie.append("O")
else:
# 提取疾病实体
entities = extract_entities(text, entitie)
if entities:
temp = {
"text": fix_number_format("".join(text)),
"entities": str(entities)
}
else:
temp = {
"text": fix_number_format("".join(text)),
"entities": str(["没有找到任何实体"])
}
if temp not in results:
results.append(temp)
text, entitie = [], []
return results
def save_to_json(data, output_file):
"""将数据保存为JSON文件"""
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
4.1.2 Json 格式
<|im_start|>system
你是一个农业病虫害实体识别领域的专家,需要从给定的句子中提取农业相关的实体并以 json 格式输出。
注意:
1. 输出的每一行都必须是正确的 json 字符串。
2. 找不到任何实体时, 输出"没有找到任何实体"。
Example:
输入:(2)流行趋势预测:在品种发病和菌源存在的前提下,白叶枯病流行与否主要取决于气候条件。
输出:[{"entity_text": "白叶枯病", "entity_label": "Disease"}]
<|im_end|>
<|im_start|>user
③淹水、串灌、漫灌是引起稻曲病传播的重要原因。<|im_end|>
<|im_start|>assistant
[{'entity_text': '稻曲病', 'entity_label': 'Disease'}]
<|endoftext|>
在每一条数据中,都将输出定义为一个json格式的数据。
4.2 参数配置
4.2.1 模型加载
Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(151936, 2048)
(layers): ModuleList(
(0-35): 36 x Qwen2DecoderLayer(
(self_attn): Qwen2Attention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=True)
(k_proj): Linear(in_features=2048, out_features=256, bias=True)
(v_proj): Linear(in_features=2048, out_features=256, bias=True)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=2048, out_features=11008, bias=False)
(up_proj): Linear(in_features=2048, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=2048, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((2048,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((2048,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((2048,), eps=1e-06)
(rotary_emb): Qwen2RotaryEmbedding()
)
(lm_head): Linear(in_features=2048, out_features=151936, bias=False)
)
def _load_model(self):
"""模型"""
self.tokenizer = AutoTokenizer.from_pretrained(self.config["model_dir"],
use_fast=False)
self.model = AutoModelForCausalLM.from_pretrained(self.config["model_dir"], device_map="auto",
torch_dtype=torch.bfloat16, use_cache=False)
self.model.enable_input_require_grads()
print(self.model)4.2.2 Lora 参数配置
def _setup_lora_args(self):
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=4,
lora_alpha=8,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.01,
)
self.peft_model = get_peft_model(self.model, peft_config)
self.peft_model.print_trainable_parameters()4.2.3 训练参数配置
def _setup_train_args(self):
return TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
num_train_epochs=1,
gradient_checkpointing=True, # 显式启用
fp16=False, # 与bf16设置互斥
bf16=True,
logging_steps=100,
output_dir=self.config['output_dir'],
group_by_length=True,
report_to="none",
)4.3 模型训练
def run(self):
"""执行训练流程"""
self._load_model()
all_data = self._prepare_data()
self._setup_lora_args()
swanlab_callback = SwanLabCallback(
project="Qwen2.5",
experiment_name="Qwen2.5 命名实体任务微调"
)
trainer = Trainer(
model=self.peft_model,
args=self._setup_train_args(),
train_dataset=all_data["train_dataset"],
data_collator=DataCollatorForSeq2Seq(
tokenizer=self.tokenizer,
padding=True
),
callbacks=[swanlab_callback],
)
trainer.train(resume_from_checkpoint=self.config['resume_from_checkpoint'])
trainer.save_model(self.config["lora_dir"])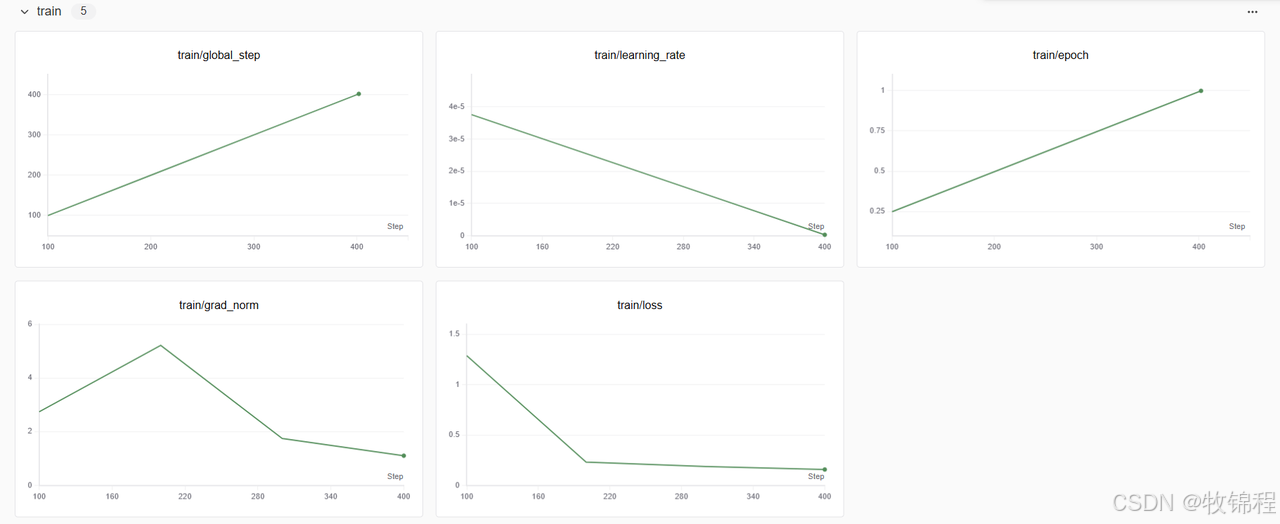
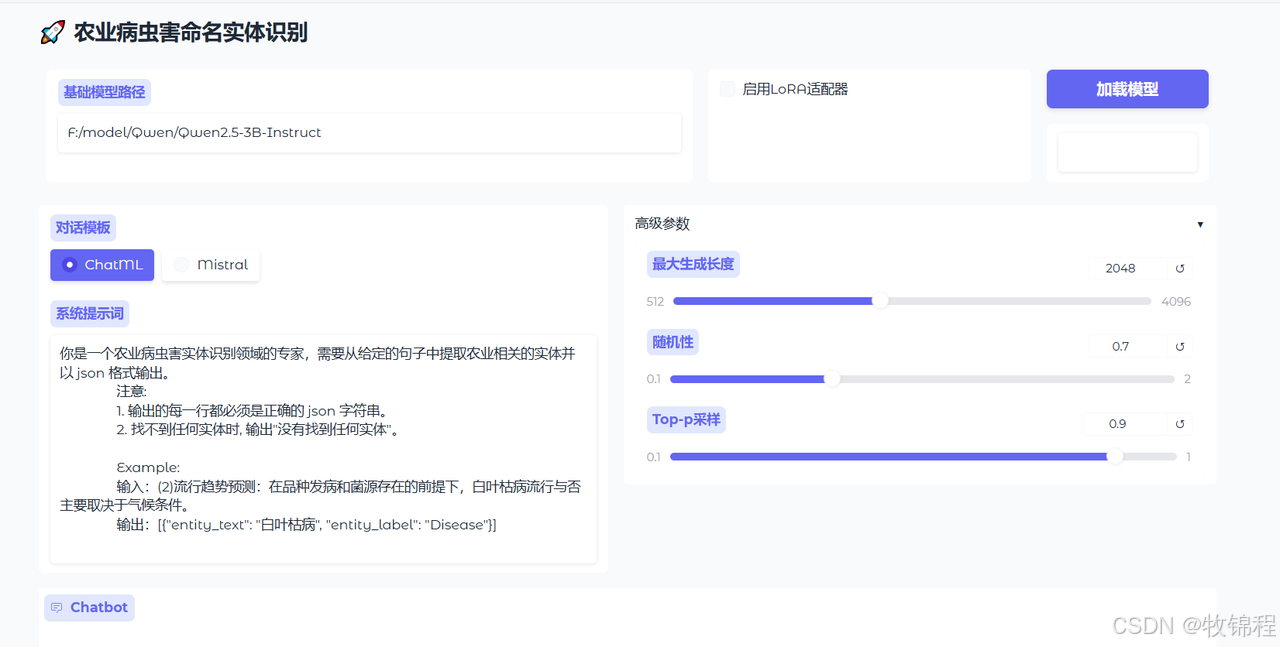
4.4 可视化界面

def stream_response(chat_history, system_prompt, template_name, max_length, temperature, top_p):
"""流式生成响应"""
# 获取最新用户消息
if not chat_history:
yield chat_history
return
# 提取最后一条用户消息和助手消息
last_user_msg = chat_history[-2]["content"]
existing_response = chat_history[-1]["content"] or ""
# 生成prompt时排除最后两条消息(用户和助手)
prompt = format_to_prompt(chat_history[:-2], last_user_msg, system_prompt, template_name)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
streamer = TextIteratorStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True,
timeout=120
)
generation_kwargs = dict(
**inputs,
streamer=streamer,
max_new_tokens=max_length,
temperature=temperature,
top_p=top_p,
do_sample=True,
pad_token_id=tokenizer.eos_token_id,
)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
partial_message = existing_response
for new_token in streamer:
partial_message += new_token
# 更新最后一条助手消息
updated_history = chat_history[:-1] + [{"role": "assistant", "content": partial_message}]
yield updated_history五、相关知识
5.1 data_collator
代码位置:transformers/data/data_collator.py
5.1.1 关键参数
|
参数 |
作用 |
取值 |
|
padding |
控制对输入序列进行填充,以使它们具有相同的长度。 |
|
|
max_length |
指定序列的最大长度。 如果序列长度超过这个值,将被截断;如果不足,则进行填充。 |
一个正整数,表示最大长度。 |
|
pad_to_multiple_of |
将序列长度填充到指定数值的倍数。 在使用计算能力 >= 7.5(Volta)的 NVIDIA 硬件上,启用 Tensor Core 可以显著提高计算性能。 这种优化特别适用于深度学习中的矩阵运算。 |
一个正整数,表示要填充到的倍数。 例如,如果设置为 8,序列长度会被填充到 8 的倍数(如 8, 16, 24 等)。 |
|
label_pad_token_id |
填充标签时使用的token_id |
默认为-100,具体可根据模型进行设置 |
5.1.2 目的
将单个样本数据转换为适合模型输入的批量数据(batch)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)