知识图谱(carel模型)【第十二章】
一、casrel模型的实现细节
- 使用bert模型对token编码,然后双层线性层+sigmoid函数预测是否是实体的开头和结尾-——————得到候选实体的每个token编码;
- 每个候选实体token编码加上平均向量;
- 对于每一个subject根据关系来解码出每个object的start+end位置;
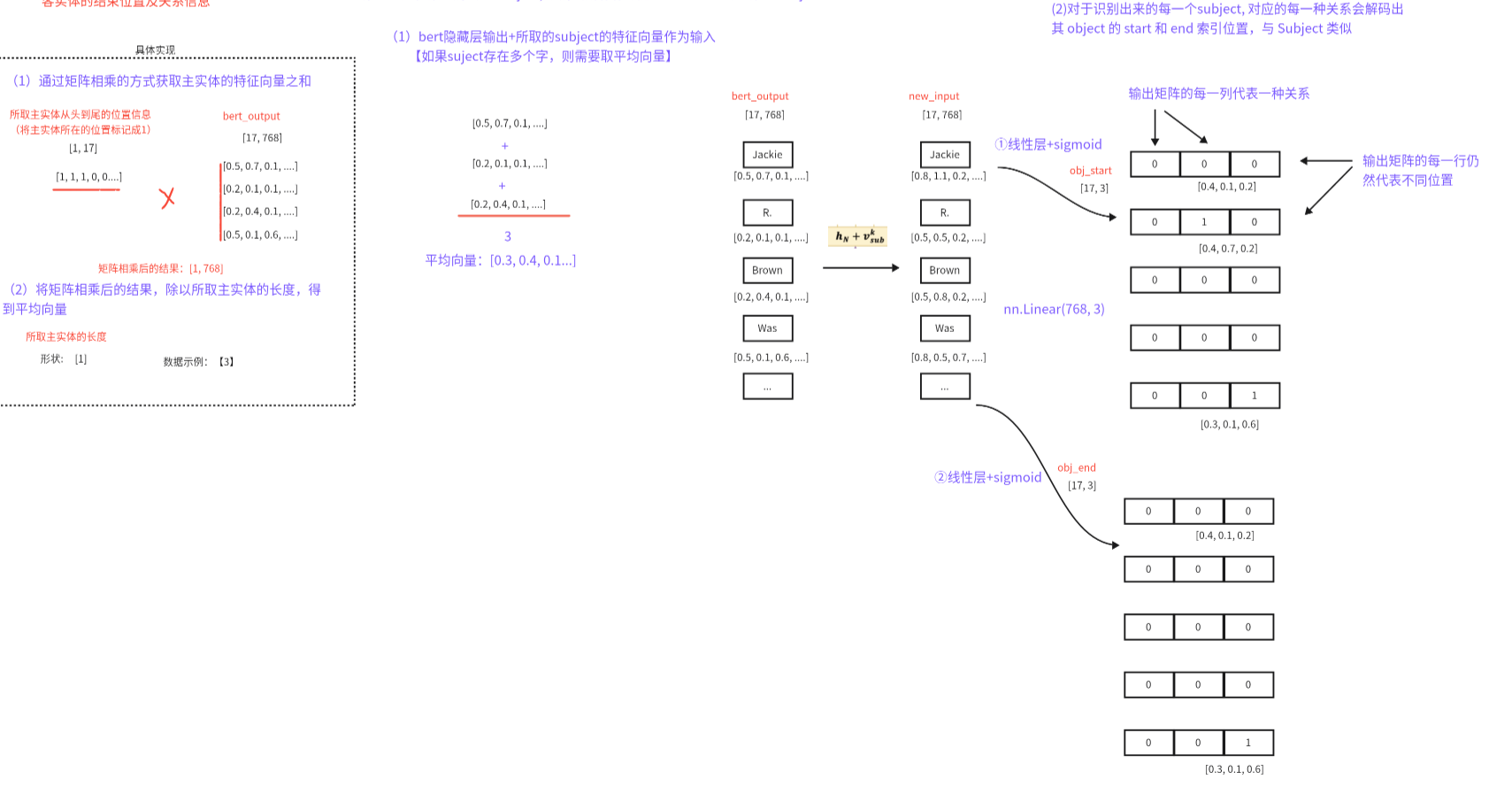
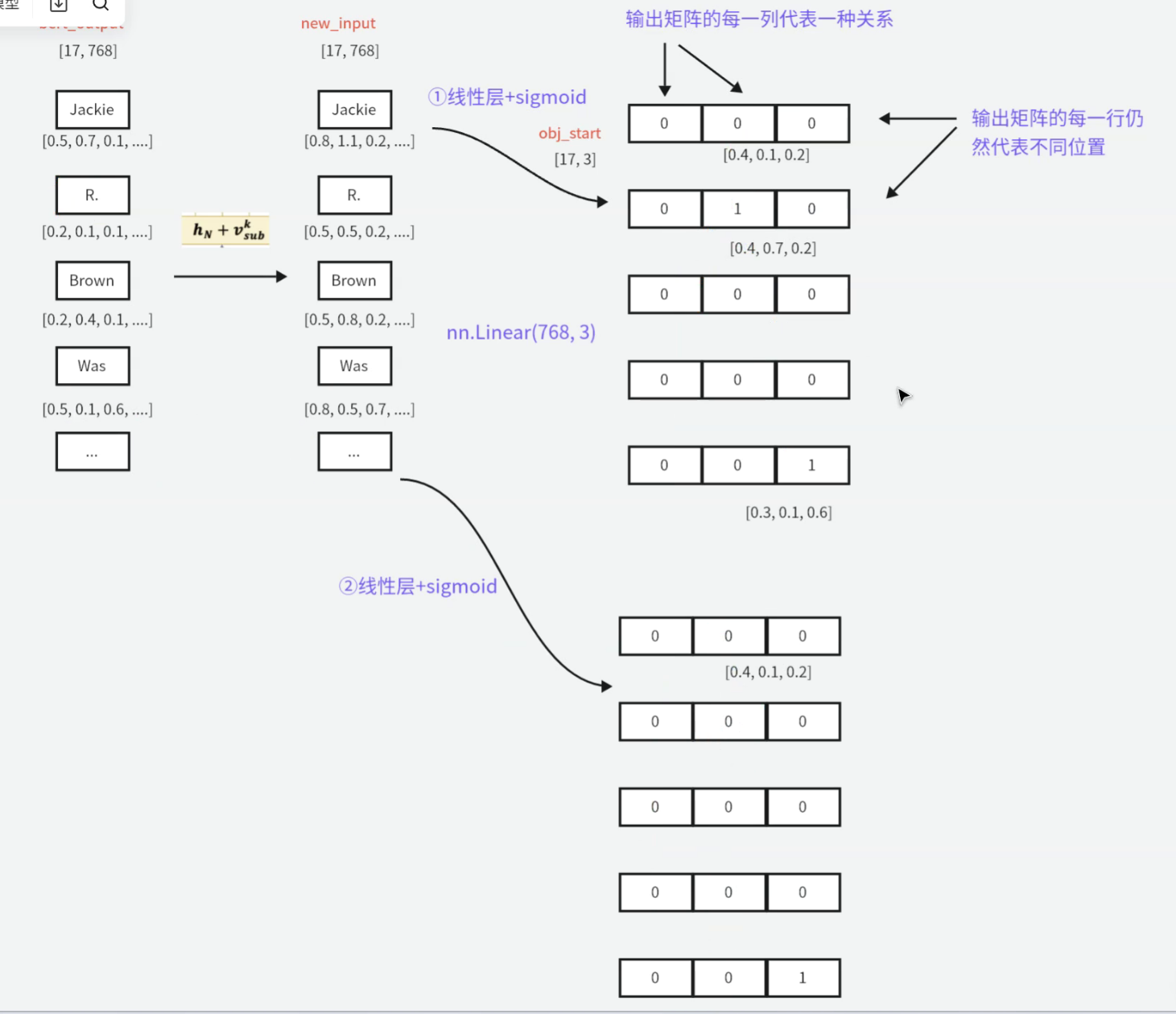
缺点:多一个关系就会多出现一个线性层+sigmoid组合,模型会越来越复杂;
优化:在预测客实体及关系时,线性层的输出是有几种关系就设置输出的维度为几,结果通过sigmoid即可。
优化展示:
有几种关系就输出几列,上面的是object的开始索引
下面的是object的结束索引
比如第一种关系(第一列):开始索引全是0,结束索引全是0,说明subject和object不存在这种关系;
第二种关系(第二列):开始索引有1,结束索引有1,那么这一块表示的是subject和object存在这种关系;
以此类推。

二、joint方法实现关系抽取
项目架构:

整体实现思路(1-4数据数据预处理,5-8模型部分):
1、获取数据,例如通过人工数据标注或者第三方数据等。
2、对数据进行处理,构造训练数据【合并在第4步】
3、构建DataSet类
4、加载数据集 DataLoader
5、定义模型
6、初始化模型、loss、优化器、前向传播、反向传播、梯度更新
7、模型训练、评估
8、模型加载、测试
config.py
# 导入必备的工具包
import torch
# 导入Vocabulary,目的:用于构建, 存储和使用 `str` 到 `int` 的一一映射
from fastNLP import Vocabulary
from transformers import BertTokenizer
import json
import os
base_dir = os.path.dirname(os.path.abspath(__file__))
print(f'base_dir-->{base_dir}')
# 构建配置文件Config类
class Config(object):
def __init__(self):
# 设置是否使用GPU来进行模型训练
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# self.device = 'mps'
self.bert_path = os.path.join(base_dir, 'bert-base-chinese')
self.num_rel = 18 # 关系的种类数
self.batch_size = 8
self.train_data_path = os.path.join(base_dir, 'data/train.json')
self.dev_data_path = os.path.join(base_dir, 'data/dev.json')
self.test_data_path = os.path.join(base_dir, 'data/test.json')
self.rel_dict_path = os.path.join(base_dir, 'data/relation.json')
id2rel = json.load(open(self.rel_dict_path, encoding='utf8'))
# print(f'id2rel-->{id2rel}')
self.rel_vocab = Vocabulary(padding=None, unknown=None)
# vocab更新自己的字典,输入为list列表
self.rel_vocab.add_word_lst(list(id2rel.values()))
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.learning_rate = 1e-5
self.bert_dim = 768
self.epochs = 10
if __name__ == '__main__':
conf = Config()
# 通过rel_vocab获取 rel2id 和 id2rel 字典
print(f'rel2id-->{conf.rel_vocab.word2idx}')
print(f'id2rel-->{conf.rel_vocab.idx2word}')
# 通过rel_vocab获取id对应的rel 或者 通过rel获取对应的id
print(conf.rel_vocab.to_word(2)) # 通过id对应的rel
print(conf.rel_vocab.to_index('出生地')) # 通过rel获取对应的id数据json格式化后结果:



2.1项目整体实现思路

训练函数:
P04_RE/Casrel_RE/train.py
import time
import pandas as pd
import torch
import torch.nn as nn
from torch.optim import AdamW
from tqdm import tqdm
from P04_RE.Casrel_RE.config import Config
from P04_RE.Casrel_RE.model.CasrelModel import CasRel
from P04_RE.Casrel_RE.utils.data_loader import get_data_loader
conf = Config()
def convert_score_to_zero_one(ts):
'''
将传进来的张量转成0或1
:param ts: 传进来的张量,也就是未处理的预测结果
:return:
'''
ts[ts>=0.5] = 1
ts[ts<0.5] = 0
return ts
def extract_sub(sub_head, sub_tail):
'''
:param sub_head: 主实体的开始位置 [155]
:param sub_tail: 主实体的结束位置 [155]
:return:
'''
# 1)取出1位置所对应的索引
# 使用torch.arange()函数,生成一个索引的序列,然后使用 boolean 张量来获取1所对应位置的索引
heads_index = torch.arange(0, len(sub_head), device=conf.device)[sub_head == 1]
# print(f'heads_index-->{heads_index}')
tails_index = torch.arange(0, len(sub_tail), device=conf.device)[sub_tail == 1]
# print(f'tails_index-->{tails_index}')
# 2)根据开始索引和结束索引,提取实体
subs = []
for head_index, tail_index in zip(heads_index, tails_index):
if head_index <= tail_index:
subs.append((head_index.item(), tail_index.item()))
# print(f'subs-->{subs}')
return subs
def extract_obj(obj_head, obj_tail):
'''
:param obj_head: 客实体的开始位置及关系信息 [155, 18]
:param obj_tail: 客实体的结束位置及关系信息 [155, 18]
:return:
'''
# 为了方便取到一个关系下的所有位置信息,需要先对矩阵进行转置
obj_head = obj_head.T
obj_tail = obj_tail.T
# print(f'obj_head-->{obj_head.shape}') # [18, 155]
# print(f'obj_tail-->{obj_tail.shape}') # [18, 155]
# 遍历每个关系,抽取该关系下的客实体
obj_and_rel = [] # 存储所有的客实体及关系
for rel_id in range(conf.num_rel):
# 获取该关系下的所有位置信息
head = obj_head[rel_id] # [155]
tail = obj_tail[rel_id] # [155]
# 调用 extract_sub()方法,抽取该关系下的主实体
objs = extract_sub(head, tail)
if len(objs) > 0: # 说明抽取到了客实体
for obj in objs:
obj_and_rel.append((rel_id, obj[0], obj[1]))
return obj_and_rel
def model2dev(model, dev_dataloader):
# 1.定义打印日志参数
df = pd.DataFrame(columns=['TP', 'PRED', "REAL", 'p', 'r', 'f1'], index=['sub', 'triple'])
df.fillna(0, inplace=True)
# 2.将模型设置为评估模式
model.eval()
# 3.内部遍历数据迭代器dataloader
for index, (inputs, labels) in enumerate(tqdm(dev_dataloader, desc='Casrel模型验证')):
# 3.1 将数据送入模型得到输出结果
outputs = model(**inputs)
# print(f'outputs-->{outputs}')
# 3.2 计算损失(略)
# 3.3 处理结果
# 1)将预测结果转成0或者1
pre_sub_heads = convert_score_to_zero_one(outputs['pre_sub_heads'])
# print(f'pre_sub_heads-->{pre_sub_heads.shape}')
pre_sub_tails = convert_score_to_zero_one(outputs['pre_sub_tails'])
# print(f'pre_sub_tails-->{pre_sub_tails.shape}')
pre_obj_heads = convert_score_to_zero_one(outputs['pre_obj_heads'])
# print(f'pre_obj_heads-->{pre_obj_heads.shape}')
pre_obj_tails = convert_score_to_zero_one(outputs['pre_obj_tails'])
# print(f'pre_obj_tails-->{pre_obj_tails.shape}')
# 2)取到1位置所对应的索引,然后基于开始索引和结束索引,提取实体
# 遍历批次内的每个样本
for batch_index in range(conf.batch_size):
# 抽取预测的主实体
pre_sub_head = pre_sub_heads[batch_index].squeeze(-1)
pre_sub_tail = pre_sub_tails[batch_index].squeeze(-1)
pre_sub = extract_sub(pre_sub_head, pre_sub_tail)
# print(f'pre_sub-->{pre_sub}')
# 抽取实际的主实体
real_sub = extract_sub(labels['sub_heads'][batch_index],
labels['sub_tails'][batch_index])
# print(f'real_sub-->{real_sub}')
# 抽取预测的客实体
pre_obj = extract_obj(pre_obj_heads[batch_index], pre_obj_tails[batch_index])
# print(f'pre_obj-->{pre_obj}')
# 抽取实际的客实体
real_obj = extract_obj(labels['obj_heads'][batch_index],
labels['obj_tails'][batch_index])
# print(f'real_obj-->{real_obj}')
# 3.4 统计批次内指标
# 计算预测的主实体的个数
df.loc['sub', 'PRED'] += len(pre_sub)
# 计算实际主实体的个数
df.loc['sub', 'REAL'] += len(real_sub)
# 计算预测正确的主实体个数
for sub in pre_sub:
if sub in real_sub:
df.loc['sub', 'TP'] += 1
# 计算预测的客实体及关系个数
df.loc['triple', 'PRED'] += len(pre_obj)
# 计算实际的客实体及关系个数
df.loc['triple', 'REAL'] += len(real_obj)
# 计算预测正确的客实体及关系个数
for obj in pre_obj:
if obj in real_obj:
df.loc['triple', 'TP'] += 1
# break
# break
# 4.统计整体指标
# 4.1 计算主实体的指标
# 计算精确率
sub_precision = df.loc['sub', 'TP'] / df.loc['sub', 'PRED']
df.loc['sub', 'p'] = sub_precision
# 计算召回率
sub_recall = df.loc['sub', 'TP'] / df.loc['sub', 'REAL']
df.loc['sub', 'r'] = sub_recall
# 计算f1
sub_f1 = 2 * sub_precision * sub_recall / (sub_precision + sub_recall)
df.loc['sub', 'f1'] = sub_f1
# 4.2 计算客实体的指标
# 计算精确率
obj_precision = df.loc['triple', 'TP'] / df.loc['triple', 'PRED']
df.loc['triple', 'p'] = obj_precision
# 计算召回率
obj_recall = df.loc['triple', 'TP'] / df.loc['triple', 'REAL']
df.loc['triple', 'r'] = obj_recall
# 计算f1
obj_f1 = 2 * obj_precision * obj_recall / (obj_precision + obj_recall)
df.loc['triple', 'f1'] = obj_f1
return sub_precision, sub_recall, sub_f1, obj_precision, obj_recall, obj_f1, df
def model2train():
# 1.构建数据迭代器Dataloader(包括数据处理与构建数据源Dataset)
train_dataloader, dev_dataloader, test_dataloader = get_data_loader()
# 2.实例化模型
model = CasRel(conf).to(conf.device)
param_optimizer = list(model.named_parameters())
# print(f'parameters-->{param_optimizer}')
# print([name for name, param in model.named_parameters()])
# 3.实例化损失函数对象(略)
# 4.实例化优化器对象
no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"] # no_decay中存放不进行权重衰减的参数{因为bert官方代码对这三项免于正则化}
# any()函数用于判断给定的可迭代参数iterable是否全部为False,则返回False,如果有一个为True,则返回True
# 判断param_optimizer中所有的参数。如果不在no_decay中,则进行权重衰减;如果在no_decay中,则不进行权重衰减
optimizer_grouped_parameters = [
{"params": [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], "weight_decay": 0.01},
{"params": [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], "weight_decay": 0.0}]
optimizer = AdamW(optimizer_grouped_parameters, lr=conf.learning_rate)
# 5.定义打印日志参数
start_time = time.time()
train_loss = 0 # 已经训练的损失之和
total_step = 0 # 总的批次数
best_triple_f1 = 0 # 最佳三元组f1
# 6.开始训练
# 6.1 实现外层大循环epoch
for epoch in range(conf.epochs):
# 6.2 将模型设置为训练模式
model.train()
# 6.3 内部遍历数据迭代器dataloader
for index, (inputs, labels) in enumerate(tqdm(train_dataloader, desc='Casrel模型训练')):
# 1)将数据送入模型得到输出结果
outputs = model(**inputs)
# 2)计算损失
loss = model.compute_loss(**outputs, **labels)
# print(f'loss-->{loss}')
# 3)梯度清零: optimizer.zero_grad()
optimizer.zero_grad()
# 4)反向传播(计算梯度): loss.backward()
loss.backward()
# 梯度裁剪
nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=10)
# 5)梯度更新(参数更新): optimizer.step()
optimizer.step()
# 6)打印内部训练日志
train_loss += loss.item()
total_step += 1
if (index+1) % 20 == 0:
print('epoch:%d------------loss:%.4f' % (epoch+1, train_loss/total_step))
# break
# 6.4 使用验证集进行模型评估【将模型设置为评估模式】
# 注意:我们最好等一个轮次训练完成之后,再去进行模型评估。而不是在一个轮次内部进行多次模型评估。对于后者总的评估次数会变多,有可能在验证集上获取更好的结果,但是在最终的测试集上效果可能更差,因为产生了过拟合。所以我们建议都是在一个轮次训练完成后,再进行模型评估。
result = model2dev(model, dev_dataloader)
print(f'df-->{result[-1]}')
# 6.5 保存模型: torch.save(model.state_dict(), "model_path")
if result[-2] > best_triple_f1:
print(f'当前模型效果更好,保存模型中...当前轮次为{epoch+1}, 当前模型的triple_f1为{result[-2]}')
best_triple_f1 = result[-2]
torch.save(model.state_dict(), 'save_model/casrel_best_f1.pth')
# break
# 6.6 打印外部训练日志
end_time = time.time()
print(f'训练时间:{end_time - start_time:.2f}')
if __name__ == '__main__':
model2train()测试函数:
/home/ec2-user/Casrel_RE/relationship_extract/codes/test.py
def model2test(model, test_iter):
'''
测试模型效果
:param model:
:param test_iter:
:return:
'''
model.eval()
# 定义一个df,来展示模型的指标。
df = pd.DataFrame(columns=['TP', 'PRED', "REAL", 'p', 'r', 'f1'], index=['sub', 'triple'])
df.fillna(0, inplace=True)
with torch.no_grad():
for inputs, labels in tqdm(test_iter):
logist = model(**inputs)
pred_sub_heads = convert_score_to_zero_one(logist['pred_sub_heads'])
pred_sub_tails = convert_score_to_zero_one(logist['pred_sub_tails'])
sub_heads = convert_score_to_zero_one(labels['sub_heads'])
sub_tails = convert_score_to_zero_one(labels['sub_tails'])
batch_size = inputs['input_ids'].shape[0]
obj_heads = convert_score_to_zero_one(labels['obj_heads'])
obj_tails = convert_score_to_zero_one(labels['obj_tails'])
pred_obj_heads = convert_score_to_zero_one(logist['pred_obj_heads'])
pred_obj_tails = convert_score_to_zero_one(logist['pred_obj_tails'])
for batch_index in range(batch_size):
pred_subs = extract_sub(pred_sub_heads[batch_index].squeeze(),
pred_sub_tails[batch_index].squeeze())
true_subs = extract_sub(sub_heads[batch_index].squeeze(),
sub_tails[batch_index].squeeze())
pred_ojbs = extract_obj_and_rel(pred_obj_heads[batch_index],
pred_obj_tails[batch_index])
true_objs = extract_obj_and_rel(obj_heads[batch_index],
obj_tails[batch_index])
df['PRED']['sub'] += len(pred_subs)
df['REAL']['sub'] += len(true_subs)
for true_sub in true_subs:
if true_sub in pred_subs:
df['TP']['sub'] += 1
df['PRED']['triple'] += len(pred_ojbs)
df['REAL']['triple'] += len(true_objs)
for true_obj in true_objs:
if true_obj in pred_ojbs:
df['TP']['triple'] += 1
df.loc['sub', 'p'] = df['TP']['sub'] / (df['PRED']['sub'] + 1e-9)
df.loc['sub', 'r'] = df['TP']['sub'] / (df['REAL']['sub'] + 1e-9)
df.loc['sub', 'f1'] = 2 * df['p']['sub'] * df['r']['sub'] / (df['p']['sub'] + df['r']['sub'] + 1e-9)
df.loc['triple', 'p'] = df['TP']['triple'] / (df['PRED']['triple'] + 1e-9)
df.loc['triple', 'r'] = df['TP']['triple'] / (df['REAL']['triple'] + 1e-9)
df.loc['triple', 'f1'] = 2 * df['p']['triple'] * df['r']['triple'] / (
df['p']['triple'] + df['r']['triple'] + 1e-9)
return df
后续优化:
- ==升级预训练模型==:从基础 bert-base 换成效果更好的中文预训练,如 RoBERTa-wwm-ext、MacBERT、Erlangshen-RoBERTa-large 等。
- ==修改主实体和bert隐藏层的融合方式==:可以使用拼接的方式(Bert隐藏层输入拼接上所取主实体的平均向量;另外也可以将所取的主实体的向量前拼接N个1,其他的向量拼接N个0),或者使用增强的方式(将所取的主实体对应的张量扩大N倍)。
- ==增加实体边界探索==:在 subject/object 边界预测上加一个==前馈全连接层== 或者是BiLSTM+Linear层,提高识别的准确性。
- 增加drop层:通过增加几个不同的drop层,提高模型的过拟合能力。
- 修改0/1的阈值:目前设置的阈值为0.5,可以修改这个阈值进行训练或预测,比如修改成0.45,0.55等。
- 增加训练数据:可以使用数据增强,或更多标注数据。
预测函数:
P04_RE/Casrel_RE/predict.py
import torch
from P04_RE.Casrel_RE.config import Config
from P04_RE.Casrel_RE.model.CasrelModel import CasRel
from P04_RE.Casrel_RE.train import convert_score_to_zero_one, extract_sub, extract_obj
conf = Config()
def model2predict(sample):
# 1.实例化模型
model = CasRel(conf).to(conf.device)
# 2.加载模型参数
model.load_state_dict(torch.load('save_model/casrel_best_f1.pth', weights_only=True))
# 3.预测主实体
# 3.1 先将文本送入bert分词器,获取input_ids, attention_mask
text = conf.tokenizer(sample)
# print(f'text-->{text}')
input_ids = torch.tensor([text['input_ids']]).to(conf.device)
mask = torch.tensor([text['attention_mask']]).to(conf.device)
# 3.2 调用模型的get_encoded_text(),获取bert_output
model.eval()
with torch.no_grad():
bert_output = model.get_encoded_text(input_ids, mask)
# 3.3 调用模型的get_subs()方法,获取主实体开始和结束位置信息
pre_sub_heads, pre_sub_tails = model.get_subs(bert_output)
# 3.4 抽取出主实体
sub_heads = convert_score_to_zero_one(pre_sub_heads)
# print(f'sub_heads-->{sub_heads.shape}') # [1, 20, 1]
sub_tails = convert_score_to_zero_one(pre_sub_tails)
# print(f'sub_tails-->{sub_tails.shape}') # [1, 20, 1]
subs = extract_sub(sub_heads.squeeze(), sub_tails.squeeze()) # 送入extract_sub的参数需要是一维的
# print(f'subs-->{subs}')
# 定义一个空列表,来保存所有抽取到的spo三元组
spo_list = []
if len(subs) > 0: # 需要进行判断,如果抽取到了主实体,则进行客实体的抽取
for sub in subs: # 因为可能抽取到了多个主实体,所以需要循环
# print(f'主实体-->{sub}') # (4, 6)
# 3.5 将抽取到的主实体id转成文字,如果文字中包含了特殊字符,则不需要进行客实体及关系的抽取了!
# 需要先将input_ids转成字符列表,然后再通过主实体的开始/结束位置索引获取对应的字符
text_list = conf.tokenizer.convert_ids_to_tokens(input_ids[0])
# print(f'text_list-->{text_list}')
sub_str = ''.join(text_list[sub[0]:sub[1]+1])
# print(f'主实体文字-->{sub_str}')
# 如果主实体中包含特殊字符,则不需要进行客实体及关系的抽取了!
if '[CLS]' in sub_str or '[SEP]' in sub_str or '[PAD]' in sub_str:
continue
# 4.预测客实体及关系
# 4.1 对每个主实体进行处理,获取sub_head2tail, sub_len
sub_head2tail = torch.zeros(len(input_ids[0])).to(conf.device)
sub_head2tail[sub[0]:sub[1]+1] = 1
# print(f'sub_head2tail-->{sub_head2tail}')
sub_len = torch.tensor([sub[1] - sub[0] + 1], dtype=torch.float).to(conf.device)
# print(f'sub_len-->{sub_len}')
# 4.2 调用模型get_objs_and_rels()方法,预测客实体和关系
# 在调用模型get_objs_and_rels()方法之前,需要将sub_head2tail, sub_len升维,添加batch_size的维度
pre_obj_heads, pre_obj_tails = model.get_objs_and_rels(bert_output, sub_head2tail.unsqueeze(0), sub_len.unsqueeze(0))
# print(f'pre_obj_heads-->{pre_obj_heads.shape}')
# print(f'pre_obj_tails-->{pre_obj_tails.shape}')
# 4.3 抽取出客实体及关系
obj_heads = convert_score_to_zero_one(pre_obj_heads)
obj_tails = convert_score_to_zero_one(pre_obj_tails)
obj_and_rels = extract_obj(obj_heads.squeeze(), obj_tails.squeeze())
# print(f'obj_and_rels-->{obj_and_rels}') # [(5, 8, 11)]
# 4.4 进行结果处理
if len(obj_and_rels) == 0:
print(f'没有识别出{sub_str}的客实体及关系')
else:
for rel_index, head, tail in obj_and_rels: # (rel_index, head, tail)
relation = conf.rel_vocab.to_word(rel_index)
# print(f'关系名称-->{relation}')
obj_str = ''.join(text_list[head:tail + 1])
# print(f'客实体文字-->{obj_str}')
# 如果客实体中包含特殊字符,则不需要进行spo组装
if '[CLS]' in obj_str or '[SEP]' in obj_str or '[PAD]' in obj_str:
continue
# 5.将三元组进行组装,并输出
spo = {}
spo['subject'] = sub_str
spo['predicate'] = relation
spo['object'] = obj_str
# print(f'三元组-->{spo}')
spo_list.append(spo)
# break
result_dict = {}
result_dict['text'] = sample
result_dict['spo_list'] = spo_list
return result_dict
if __name__ == '__main__':
sample = '基本资料 歌曲名称:为你叫好1歌手:吕薇 所属专辑:《但愿人长久》歌词 歌手:吕薇 词:清风 曲:刘青'
result_dict = model2predict(sample)
print(result_dict)三、joint联合抽取方法的优缺点
优点:
两个任务的表征有交互作用可能辅助任务的学习.
不用训练多个模型,一个模型解决问题,减少训练与预测的gap.
缺点:
更复杂的模型结构.
模型在同时学习实体识别和关系分类这两个任务时,它们所依赖的底层特征表示可能过度趋同或缺乏足够的任务特异性,也可能冲突会使模型学习变得混乱.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)