RAG介绍
什么是RAG?详细的工作流程?
RAG就是Retrieval-Augmented Generation,就是检索增强生成。LLM的知识在训练完之后就已经固定了,遇到私有的数据或者最新的信息答不出来。RAG就是在生成答案之前,先去外部知识库检索相关内容,把检索的内容和用户问题一起交给LLM,让它基于上下文回答。
分为离线和在线两个阶段
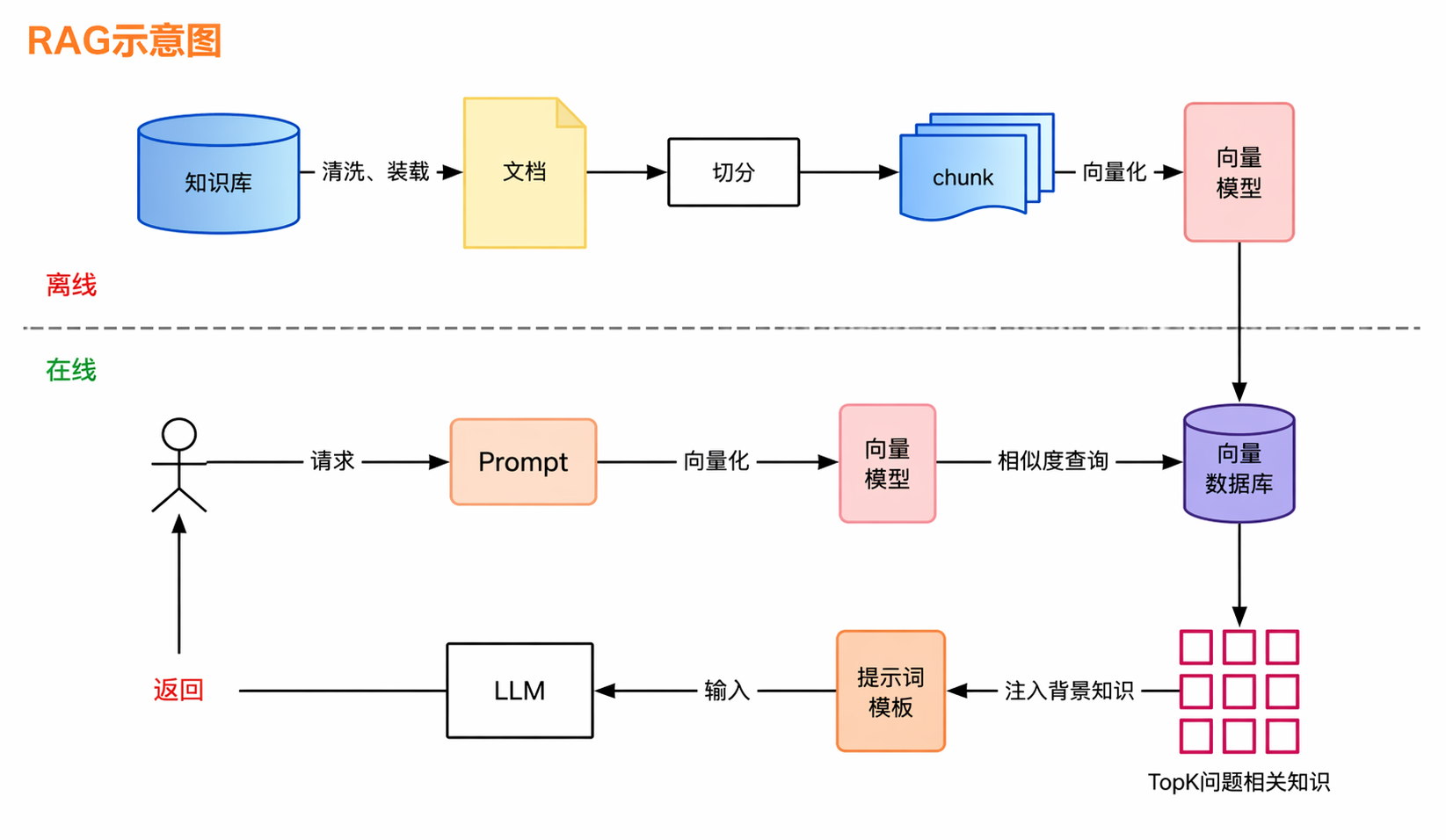
RAG不把知识塞到模型参数里,而是在用户提问的时候,实时去外部知识库检索,把找到的内容放进prompt给LLM读。
离线阶段:
第一步文档加载,把各种格式的原始数据读取进来,这一步通常用DocumentLoader来做。
接下来是文档切割,因为向量模型有输入长度限制,而如果把一整篇文章压缩成一个向量,细节信息会被平均到。所以要把文档切成一个个小片段(chunk),每个chunk代表一段聚焦的内容。chunk大小怎么定呢?实践中通常 500~1000 token 一个 chunk,同时做一定的重叠(比如前后各重叠 100 token),避免把一段完整的语义从中间切断。
然后是最核心的一步:Embedding(向量化)。会把一段文字转成一个高纬数字向量,比如一个 1536 维的浮点数列表。这东西听起来很玄,但其实你可以把它理解成一个「语义坐标系」。什么意思呢?语义相似的文本,它们在这个坐标系里的位置就靠近;语义不相关的,位置就离得远。
到这里,离线阶段就完成了。知识库已经建好,等着在线阶段来检索。
在线阶段:用户提问实时检索
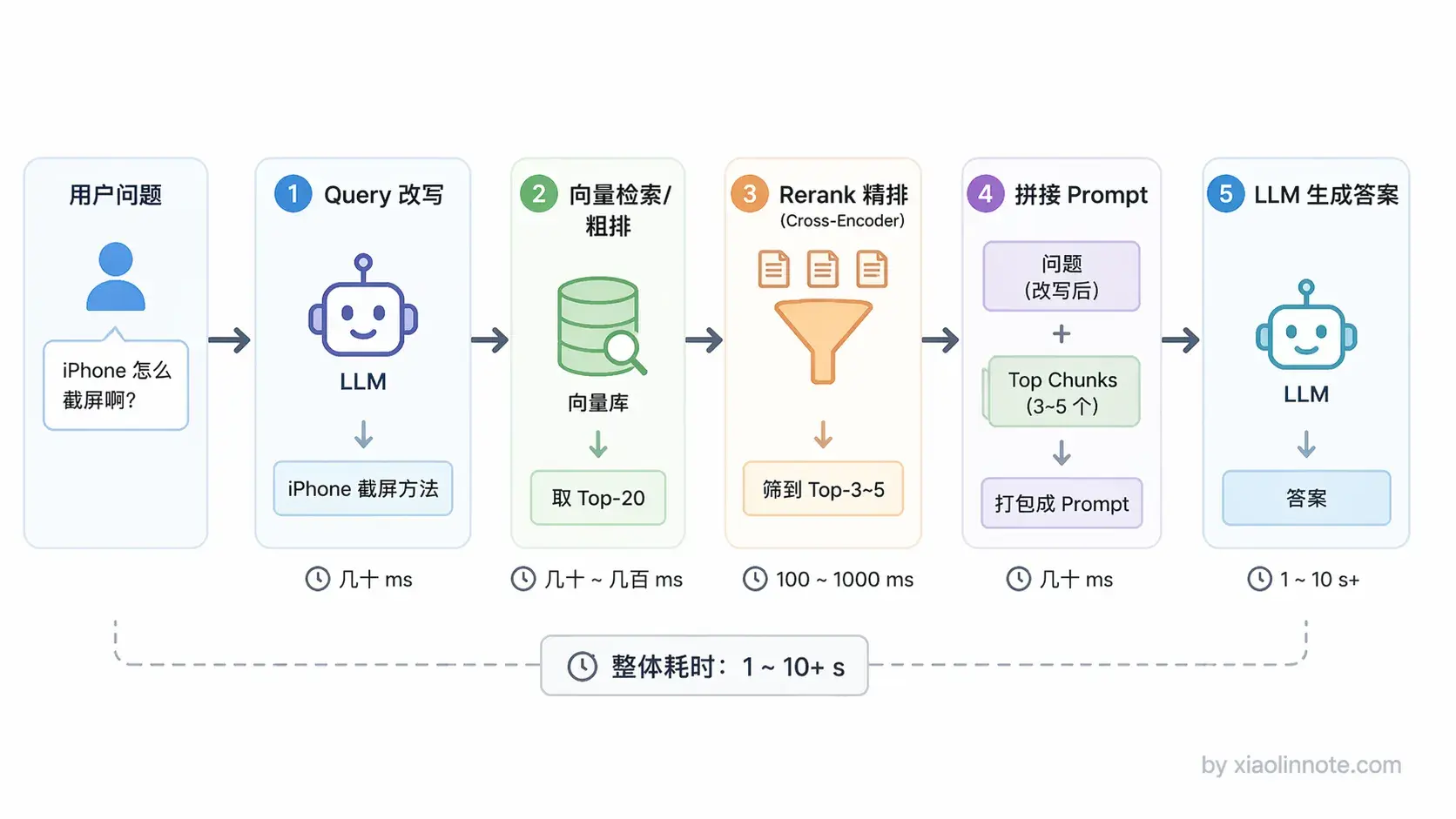
第一步query处理:让LLM把用户的问题改写成更适合检索的形式。
第二步向量检索(粗排):把用户的问题转成向量,使用和离线建库的时候完全相同的Embedding模型,再去向量库做相似度检索,找出向量距离最近的chunk。然后多路召回:
向量检索捕获语义相似性,BM25/全文检索负责捕获关键词精确匹配,
第三步是Rerank精排:弥补粗排的不足,会把用户问题和每个候选 chunk 拼在一起,深度理解它们之间的相关性,然后重新排序,把不相关的结果过滤掉。
最后是生成答案。
RAG主要解决什么问题?
第一是知识实效性。LLM训练完了对之后的事情一无所知。第二是私有知识覆盖,公司内部文档。第三是幻觉问题,没有知识依据时,容易自己编出答案,给了参考材料之后就可以有效减少幻觉。
RAG中文档怎么存?粒度多大?文档切割策略?
原始文档不能直接存进向量库,必须先切成小块再存。
每条chunk记录的结构?

向量区(告诉这段内容在空间里的位置)
原始文本(LLM真正阅读的内容)
数据:记的是来源文件名、页码、章节这些附加信息,用于过滤(「只搜客服部门的文档」)和溯源(「这个答案来自哪个文件的第几页」)
文档切割策略:
固定大小切割:按照固定字符数或者token数切割,加上重叠来缓解边界截断问题
语义边界切割:按照文档的自然语义边界来切。
特殊内容专项处理:比如代码按照函数或者类,表格按照整个表格。
父子切割:检索的时候用小块(精准定位),返回时用全景图(大块)
怎么规避语义切割?
第一是:切的时候不要在语义中间截断,用重叠切割来保证每个chunk内容是完整的。
第二个是切完之后用检索策略把上下文补回来,命中一个句子就把周围几句返回给LLM;
另一个有价值的方案:是Anthropic提出的Contextual Retrieval,在做embeding之前先让LLM看整篇文档为每一个chunk生成背景说明
Embedding是什么?如何选择和评估一个Embedding模型?
我的理解就是把一段文本转成一串数字向量的过程。有一个关键的特性:语义相近的文本,转出来的向量在数学空间里的距离也近。RAG的语义检索就是靠这个实现的。
选模型主要看三个维度:第一个就是中文支持,第二个是向量维度:维度越高精度越好,但存储成本也大,第三个是最大输入长度,这个决定处理多长的chunk
评估 Embedding 的原则:在真实业务数据上检验检索召回效果,看正确的 chunk 有没有出现在前 K 条结果里。,用 Hit@K 作为核心指标,才能确保模型在你的场景下真正好用。
Embedding有哪几种算法你了解?
第一代是静态词向量,以Word2Vec和GloVe为代表,把每个词映射成固定向量,但是不管上下文是什么,向量永远不变,处理不了多义词
第二代是以BERT为代表的上下文相关向量,同一词在不同语句下有不同的向量,但是检索速度太慢了
第三代是SBERT、SimCSE、BGE为代表的句子级对比学习EMbedding
什么是向量数据库?
专门用来存储和检索向量的数据库。指的是Embedding Model把文本、图片、音频等内容转化为一串浮点数。一句话会被转换成一个数组,语义越相近,在高维空间的距离就越近
核心操作叫近似最近搜索:根据查询向量在库里找出和它最相似的K个向量并返回原始内容。
选型:主要看三个维度:数据规模、部署方式、是否需要混合检索。
如果快速上线,首选Qdrant,性能比较好,API设计简洁、docker一条命令就能部署,而且是Rust写的,性能比较稳定。也支持分布式部署(分片+副本)
上手最快是Chroma,python直接pip install,本地内存运行。不适合大规模,稳定性不如Milvus和Qdrant
数据规模在千万到亿级,选Milvus,部署复杂度比较高。需要运维
数据在云上,用Pinecone。
向量检索和关键词检索的区别?
关键词检索(BM25类)靠的是词频统计,看查询词在文档里出现了多少次,擅长精准命中;向量检索靠的是 语义空间里的距离,擅长模糊语义匹配。所以RAG系统中通常两路都跑,向量检索捕获语义相关,BM25精准命中关键词,再用RPF算法把两路结果合并。
Query Rewrite的目的是什么?
主要是为了弥补用户的问题过于口语化、模糊、带缩写,但是文档写的是正式书面语,导致该找回的内容没被召回。有四种方式:
1.让LLM直接把口语化的问题转化成更精准的表达
2.Query扩展,补充相关关键词。把原始问题改写成3~5个不同角度的版本,分别做检索,然后合并去重
3.HyDE,让LLM先生成一个假设答案,然后用答案的向量做检索
4.Step-back Prompting 把具体问题向上抽象一层。先检索背景知识,然后结合背景知识回答具体问题。
多路召回具体怎么做?
多路召回就是同时用多种不同的检索方式去捞候选内容,然后合并排序,而不是只靠单一的向量检索。我理解核心出发点是向量检索和关键词检索各有盲区,向量检索擅长语义相似,但对精确词语比如产品型号、缩写、数字效果比较差;BM25 关键词检索正好相反,精确匹配强,但不理解语义。我在项目里常用的组合是向量检索加 BM25 混合检索,再加上多 Query 扩展,也就是把用户问题改写成多个版本分别检索。多路的结果用 RRF 算法融合,最后送进 Rerank 精排。
RAG的检索优化策略
RAG 检索优化策略可以系统性地分为 四层,每一层解决不同问题,组合起来才能显著提升检索效果:
1.索引层(Index Optimization)
- 作用:决定知识库内容如何存储,解决检索粒度与 LLM 上下文完整性的矛盾。
- 核心问题:
-
- 小 chunk → 检索精度高,但 LLM 上下文碎片化。
- 大 chunk → 上下文完整,但检索时语义稀释。
- 优化方法:
-
- Parent-Child Chunking:小块用于检索,大块用于 LLM 阅读,通过 ID 关联。
- 摘要索引(Summary Index):用摘要建向量索引,提高语义聚焦。
- 多粒度分层索引:章节级、段落级、句子级索引,根据问题类型自动选择。
2.查询层(Query Optimization)
- 作用:优化用户提问,使问题在向量空间里更容易命中知识库。
- 核心问题:用户 query 与文档表述不对齐。
- 优化方法:
-
- Query 改写:将口语化或模糊问题改写成正式问题。
- Multi-Query(多角度扩展):生成多种问法,增加召回率。
- HyDE(假设文档嵌入):先生成假设答案,再向量检索。
- Step-back Prompting:抽象问题,检索背景知识,再结合生成答案。
3.召回层(Recall Optimization)
- 作用:增加检索路径,覆盖可能漏掉的内容。
- 核心问题:单一检索可能漏掉信息。
- 优化方法:
-
- 多路召回:结合向量检索 + 关键词检索(BM25)等不同方法。
- RRF(倒数排名融合):按各路排名加权融合,得到统一的综合排序。
4.重排序层(Rerank / Re-ranking)
- 作用:从候选集合中挑出最相关的 chunk,保证 LLM 输入质量。
- 核心问题:多路召回后仍有冗余,直接塞给 LLM 消耗大且回答质量下降。
- 优化方法:
-
- Cross-encoder Rerank:将 query 与 chunk 拼成一对,模型整体判断相关性。
- 常用模型:BGE-Reranker-v2、BCE-Reranker、Cohere Reranker、Jina Reranker API。
- 结果:只保留 top-3~5 个最相关的 chunk 提供给 LLM。
如何规避RAG中大模型的幻觉?
幻觉主要有两类:检索没有召回到相关内容,LLM没有可用上下文,靠自身知识编造答案。
第二类是检索内容召回了但LLM没有严格遵循,在文档内容基础上加自己推断。
主要有4个方向:第一是Prompt强约束,明确告知LLM只能根据提供资料回答
第二是检索质量门控,Rerank分数低于阈值就直接拒答,不让LLM在低质量上下文硬撑。
第三是生成后引用核查,每个声明都需要在chunk里找到来源依据
第四是结构化输出强制溯源,让LLM输出JSON

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)