智汇云舟所理解的“空间智能“:不是炫技,而是让世界可被计算
市面上对"空间智能"的讨论,大多停留在炫目的3D渲染、逼真的三维重建。但在智汇云舟看来,真正的空间智能,绝不是"建个好看的模型"那么简单。
智汇云舟所理解的空间智能,是构建一个能够对三维世界进行理解、推理、预测和交互的综合性AI系统它应当具备四种核心能力:
空间关系推理:不只是识别"这是什么",更要理解"A在B的上方""C可以被D容纳"等复杂的空间与物理关系。
功能性与可供性理解:识别出"这是个可以坐的表面(椅子)","这是个可以打开的物体(门)",而不仅仅是类别标签。
物理常识推理:理解重力、支撑、遮挡等基本物理规律,能够预判"机器人在这个通道能否通过"。
跨模态交互:用自然语言就能查询三维场景、编辑数字世界。
这一理解,与AI教母李飞飞的最新论述高度吻合——"空间智能模型需要在语义、物理、几何与动态层面上,理解并生成复杂的虚拟或真实世界"。
视频孪生:空间智能的“时空操作系统”
如何实现这样的空间智能?智汇云舟给出的答案是:视频孪生。
作为"视频孪生技术首倡者",智汇云舟自2016年起便走上自主研发之路,打造出视频孪生专属的"孪舟"3D GIS引擎。2024年发布的孪舟V5.0版本,成为首款具备游戏级渲染效果的国产自研3D GIS引擎,在构建效率、运行性能、场景精度、空间计算四大维度实现全面优化。

在智汇云舟的架构中,视频孪生本质上是空间智能的"时空操作系统"。其核心逻辑是:以"3DGIS+Video+AI+IoT"为技术底座,将实时视频流与三维数字场景深度融合,为每一个像素赋予时空坐标,实现"所见即所得、看到即定位"。
这背后是一套完整的技术流程:多源数据实时采集→时空基准统一与像素坐标转换→三维场景构建与动态重建→AI智能分析与数据联动→实时交互反馈形成闭环。通过赋予全场景业务要素统一的时空属性,彻底打破了传统数据孤岛,支持在"时间+空间"双维度下的跨镜头、跨系统、跨场景关联检索与深度分析。
从“看得清”到“算得明”:空间智能的产业落地
技术理念再好,最终要看落地。智汇云舟围绕视频孪生空间智能,构建了完整的产品矩阵:
-
低代码PaaS平台:为所有数据添加时空属性,进行空间关系计算。
-
视频孪生一体机:提供LI位置智能服务,为数字孪生行业广泛赋能。
-
视频孪生行业解决方案:覆盖智慧城市、司法监所、数字乡村、交通、医院、军工、校园、工业、能源、水利等十余个行业。
更值得注意的是,智汇云舟已构建起覆盖"芯片-操作系统-数据库-中间件-整机"的全栈国产化适配体系,完成了与麒麟、统信、飞腾、鲲鹏、达梦以及摩尔线程等近30家主流国产软硬件的全面兼容认证。在国产计算生态加速崛起的当下,这一布局的战略价值不言而喻。
空间智能的下一站:从语义理解到大模型
站在2026年的时间节点,智汇云舟对空间智能的理解正在向更深层次演进。
一个关键的技术方向是三维语义理解。正如知识库研究所揭示的,当前LLM的成功很大程度上归功于海量文本数据,而空间智能面临的最大瓶颈是缺乏大规模、高质量、结构化的三维世界数据。手动标注3D数据成本极高,难以穷尽真实世界的复杂性。
破局之道在于构建自动化的三维语义数据"生产机器"——深度融合3D高斯泼溅(3DGS)技术与视觉基础模型,智汇云舟通过创新的语义提升算法,实现对大规模三维场景近乎全自动的单体化和语义标注。这将为训练真正的"空间智能大模型"提供海量高质量"燃料"。
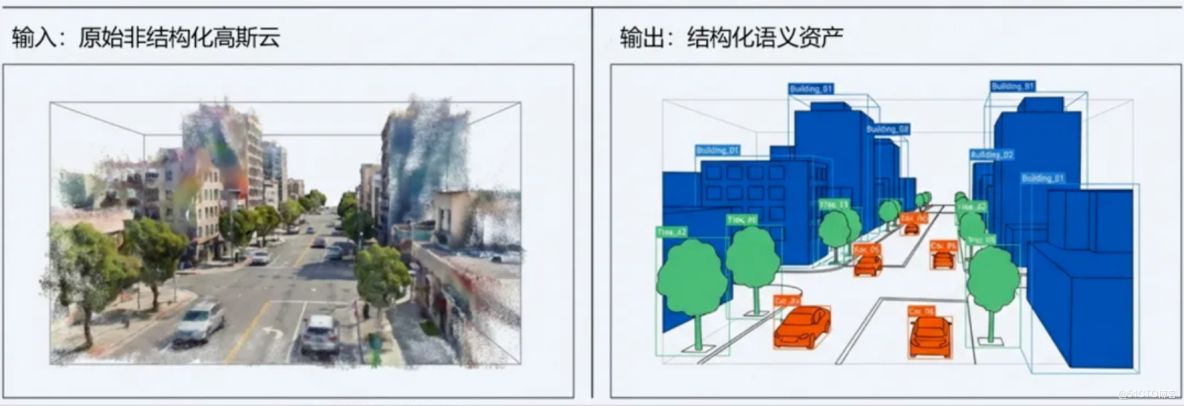
与此同时,随着3DGS重建技术逐渐走向实时化,空间智能模型将能够以准实时速度对动态场景进行深度理解和推理,并通过知识蒸馏与模型量化技术,最终部署在算力受限的嵌入式设备上,赋能低慢小无人车、自主巡检机器人等关键应用。
在智汇云舟看来,视频孪生是空间智能的"现在",而三维语义理解与空间智能大模型,是空间智能的"未来"。两者一脉相承:视频孪生解决"看得清、定得准"的问题,空间智能大模型解决"看得懂、会推理"的问题——共同指向一个目标:让物理世界真正可被计算、可被理解、可被优化。
从2016年自研引擎起步,到2024年孪舟V5.0惊艳亮相,再到未来空间智能大模型的远景规划,智汇云舟始终在以工程实践回答一个根本问题:空间智能不是实验室里的炫技,而是千行百业可用的数字生产力。对三维空间的语义化理解,终将成为开启下一代人工智能时代的钥匙。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)