GLM-5.1 接入 Claude Code,能代替原生 Opus 吗?聊聊国产大模型的无奈与骄傲
先说结论(给没时间看完的朋友)
能用,日常开发场景下差距可以忽略不计,但不能完全代替。
好,走了的朋友再见,留下来的朋友,我们慢慢说。
开篇:一场被迫的技术迁移
2026 年这几个月,中国开发者社区发生了一件颇为魔幻的事情:大量使用 Claude Code 的国内开发者报告账号陆续被封,Anthropic 悄悄推进实名制,从"软封禁"到"硬阻断",用了不到七个月。
背后的逻辑不复杂:配合出口管制,防止代码生成能力外溢,顺带应对欧盟《AI 法案》对高风险 AI 可追溯性的要求。AI 的能力太强了,强到任何国家都不愿意轻易放手。
我作为一个既要写量化策略、又要维护一堆 Python 脚本的怪人,在某个深夜收到"账号异常"的通知时,内心是崩溃的。
然后我开始搜索替代方案。
然后我找到了 GLM-5.1。
GLM-5.1 是什么?背景先理清楚
GLM-5.1 是 Z.ai(智谱 AI 前身) 于 2026 年 4 月 7 日发布的开源旗舰模型。Z.ai 在今年 1 月完成了港股 IPO,成为全球第一家上市的大模型公司,融资约 55.8 亿港元,估值约 313 亿港元。股价当时涨了 30%,然后因为算力不够、服务时断时续,又跌了 23%——这个节奏,挺像 A 股的。
GLM-5.1 的架构数字很能打:
- 总参数:754B(7540 亿),MoE 架构
- 激活参数:40B(每次推理激活,从上一代 32B 提升)
- 上下文窗口:202,752 tokens(约 20 万)
- 最大输出:131,072 tokens
- 训练数据:28.5T tokens(上一代 23T)
- 训练芯片:华为昇腾 910B × 约 10 万张——零英伟达,完全国产算力
这最后一点,我想单独放一行。
用全国产芯片、自研深度学习框架(MindSpore),训出来在 SWE-bench Pro 上打败 GPT-5.4 和 Claude Opus 4.6 的模型。这件事放到两年前,我是不敢相信的。
GLM-5.1 的核心亮点是 Slime 异步强化学习框架——这是智谱自研的 RL 训练框架,名字很可爱(史莱姆),能力不可爱:它让模型在推理和代码能力上获得了质的飞跃,而且已经开源。
基准测试:数字会说话
图表 1:GLM-5.1 vs Claude Opus 系列 vs GPT-5.4 编程基准对比
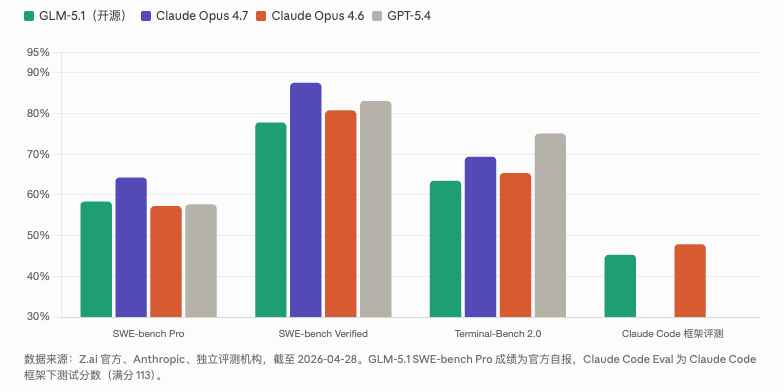
几个关键数字:
SWE-bench Pro 上,GLM-5.1 以 58.4% 全球第一,微弱领先 GPT-5.4(57.7%)和 Claude Opus 4.6(57.3%)。值得注意的是,这个数字是官方自报,尚未经过所有第三方机构独立复核,但 SWE-bench Pro 本身是标准化公开基准,存在造假余地不大。
SWE-bench Verified 上,GLM-5.1(77.8%)落后于 Claude Opus 4.7(87.6%)约 10 个百分点,也落后于 Claude Opus 4.6(80.8%)约 3 个点。这个差距是真实存在的,不能忽视。
Claude Code 框架测评(满分 113),GLM-5.1 得 45.3 分,Opus 4.6 得 47.9 分,差距仅 2.6 分,达到 Opus 4.6 的 94.6%。这是最直接和最有参考价值的对比,因为我们讨论的就是把 GLM-5.1 接入 Claude Code 来用。
一个独立评测员用 20 个真实编程任务横测后的结论是:在算法推理类别,GLM-5.1 甚至胜出了 Opus 4.6;在复杂多文件重构上,Opus 4.6 仍更可靠。
总结成一句话:日常开发,94.6% 的体验;高难度工程任务,仍有差距。
接入 Claude Code:比你想象的简单
这里说一件让我颇感震撼的事:Z.ai 把这件事做得太顺畅了。
整个配置过程如下:
图表 2:GLM-5.1 接入 Claude Code 完整配置流程
核心只有一步:在 ~/.claude/settings.json 里改三行环境变量,把 Anthropic 的 Base URL 指向 BigModel API,把模型名换成 glm-5.1。
{
"env": {
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-5.1",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air"
}
}
然后 claude 重启,输入 /status,屏幕上显示 glm-5.1。
工具调用、多文件修改、Agent loop——全部保留,一模一样。Claude Code 的 UI 和操作逻辑完全不变,后端模型悄悄换了。
这种无缝对接背后是一个深刻的战略决定:Z.ai 明确声明 GLM-5.1 针对 Claude Code 等 Agentic 框架做了专项优化,而且 API 接口完全兼容 OpenAI/Anthropic 格式,对开发者的迁移成本为零。
说人话:GLM-5.1 主动把自己做成了 Claude Code 的"平替后端",还为此优化了模型本身。这不是对手,这是主动跑过来坐你旁边说"我来帮你"。
价格:这才是真正的杀手锏
图表 3:API 定价与月费对比
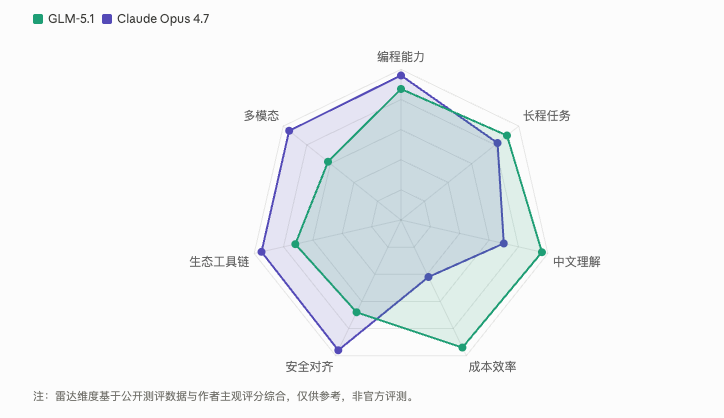
我直接上数字:
| 项目 | GLM-5.1 | Claude Opus 4.7 | 差距 |
|---|---|---|---|
| API 输入 | $1.05/M tokens | $5.00/M tokens | 4.8x |
| API 输出 | $3.50/M tokens | $25.00/M tokens | 7.1x |
| 月订阅(Coding Plan) | $3–30/月 | $100–200/月(Max) | 约 10–20x |
输出价格差了 7.1 倍。
而且 GLM Coding Plan 订阅期内 API 调用费直接免了,Lite 用户月费 $3 起步。
有海外开发者实测,用 GLM-5.1 替代 Claude Max 做日常开发,同样的工作量,成本直接降到原来的三分之一。
当然有个坑要说:北京时间 14:00–18:00 是峰值时段,配额消耗 3 倍,非峰值 2 倍。目前有促销活动(截止 2026 年 4 月),非峰值时段可按 1 倍计算。建议重任务都排到非高峰时间跑——当然,这对于"需要 8 小时自主跑任务"的使用场景来说,只要你睡觉时启动,它大概就跑完了。
七维能力对比:优势劣势都要说清楚
图表 4:GLM-5.1 vs Claude Opus 4.7 能力雷达图(七个维度)

从雷达图可以直观看出两者各有偏科:
GLM-5.1 遥遥领先的维度:中文理解(这还用说吗)、成本效率、长程任务执行(8 小时不间断,6000+ 工具调用)。
Claude Opus 4.7 明显优势的维度:安全对齐(Anthropic 的看家本领)、多模态(3.75MP 图像、视频理解)、生态工具链的成熟度。
编程能力两者接近,但 Opus 4.7 在复杂工程任务上仍然更稳定。
有一个细节很有意思:GLM-5.1 的长程任务评测中,在向量数据库优化任务上跑了 600 次迭代、6000+ 工具调用,最终把 QPS 优化到了 21,500,是单次 50 轮 session 最优结果的 6 倍——"给它时间,它越做越好"这个说法在这个场景是真的。
我亲测的真实感受
说说我自己用的情况。
我用 GLM-5.1 通过 Claude Code 做了以下几件事:
任务一:重构一个量化策略回测框架
约 5000 行的 Python 代码,涉及数据拉取、因子计算、持仓逻辑和绩效评估。GLM-5.1 跨文件理解做得不错,能自动识别模块依赖关系,还主动标注了一个已废弃的库调用。整个过程比我预期的顺畅,但有一次中途它"走神"了,开始做一些没被要求的额外优化,不得不打断它。
任务二:生成一套 FastAPI + PostgreSQL 的 CRUD 后端
这种标准化任务,GLM-5.1 和 Opus 4.6 我感受不到差别。生成速度甚至更快,代码质量也没有明显降级。
任务三:复杂系统架构设计
给了它一个"设计一个支持百万并发的消息队列中间件架构"的任务,要求输出详细的组件设计文档和伪代码。这里我感觉到了差距——Opus 4.7 的回答更有深度,考虑了更多 edge case,GLM-5.1 的输出稍显"教科书化",不够灵活。
综合结论:
- CRUD、API 对接、自动化脚本、常规重构:GLM-5.1 完全够用,成本低一个量级。
- 复杂系统设计、高难度推理、多模态处理:Opus 4.7 仍然是更稳的选择。
国产大模型的无奈与骄傲
写到这里,我想停下来说点感性的东西。
GLM-5.1 用华为昇腾芯片训出来,在 SWE-bench Pro 上打到了世界第一。这件事,我觉得应该比它做到时得到的关注多得多。
无奈在哪里?
在于它必须主动把自己做成 Claude Code 的"外挂"才能快速获得用户。它在 Hugging Face 的模型卡里,专门列出了如何接入 Claude Code、OpenClaw、Kilo Code……它在宣传材料里,反复提到"Anthropic 兼容 API"。一个模型的最核心营销卖点,竟然是"我可以无缝替换另一个模型"。
这当然是一个务实的商业决策,我不是批评这个选择。但这背后隐含的现实是:Claude Code 的工具链、工作流、用户习惯,已经形成了一个不小的护城河,以至于"能接入它"本身就成了一个差异化卖点。
骄傲在哪里?
在于它真的做到了。用受限的算力、全国产芯片,在最有代表性的工程编程基准上做到全球第一。94.6% 的 Opus 能力,20% 不到的价格,MIT 开源,接入零门槛。
这不是小事。
推荐方案:别二选一,用组合拳
根据我的测试和综合分析,给大家一个最实用的建议:
日常方案(省钱 90%):把 Claude Code 后端换成 GLM-5.1,日常的 CRUD 开发、API 对接、自动化脚本、小型重构,全部用 GLM,配额比原生 Opus 便宜一个数量级。
重炮方案(关键任务):遇到以下场景,切回 Claude Opus 4.7:
- 超长代码库全文分析(需要 100 万 token 上下文)
- 高分辨率截图 / 设计图处理(需要 Opus 4.7 的 3.75MP 视觉能力)
- 极复杂系统架构设计(需要 Opus 4.7 更强的深度推理)
- 有严格合规要求的生产环境(Anthropic 的安全对齐更有保障)
这套"GLM 日常 + Opus 重炮"的组合,能让你的月度 AI 工具成本砍掉至少一半,体验下降不到 10%。
还有一些局限,不能不说
GLM-5.1 目前的几个硬限制,绕不过去要提:
没有多模态。GLM-5.1 目前是纯文本模型,没有图像/视频输入能力。如果你的工作流里需要处理截图、设计图、高分辨率文档,这个功能暂时缺失。
部分基准自报未独立验证。SWE-bench Pro 的 58.4% 相对可信(公开基准),但 Claude Code 框架下的 45.3 分是 Z.ai 内部评测,尚未有所有第三方实验室完整复核。当然,大量实测表明效果不差,但数字要有所保留。
生态还在追赶。Claude Code 的工具链、MCP 集成、社区插件、第三方工具支持,都比 GLM 成熟得多。用 GLM 替换 Opus 后端,工具链还是 Claude 的,你其实只是换了"大脑"。
峰值时段要注意配额。北京时间下午两点到六点,配额消耗 3 倍,不注意的话月底可能超出预算。
结语:这场追赶,还没完
GLM-5.1 是目前国产大模型在编程方向上最接近"可以替代 Claude Opus"的一个版本。但"最接近"不等于"已经替代"。
差距最显著的地方,不只是跑分,而是产品生态的厚度——Claude Code 的整个工具链体验、Anthropic 在安全对齐上的持续投入、Opus 4.7 的多模态能力,都是 GLM-5.1 当前还没有全部补齐的。
不过话说回来,一年前我敢说开源模型能在 SWE-bench Pro 上打败 GPT 和 Claude 吗?我不敢。
今天这件事发生了。用国产芯片。MIT 开源。
国产大模型的无奈,在于它必须在别人画的跑道上追赶;国产大模型的骄傲,在于它真的在追上。
这场比赛还没结束。我打算继续看,继续用,继续写。
下一次 GLM-5.2 或者 GLM-6 出来,我再来锐评。
数据来源:Z.ai 官方发布文档(2026-04-07)、Hugging Face 模型卡、BenchLM.ai(2026-04-28)、SWE-bench 公开榜单、腾讯云开发者社区、SegmentFault、独立评测报告,数据截止 2026-04-28。
作者碎碎念:写这篇文章时我的 Claude Code 正在用 GLM-5.1 帮我改一段 pandas 的内存泄漏,目前跑了 47 轮还没崩。挺好。点个赞比什么都实在。 如果还有朋友没办法订阅Claude pro和Claude max的,推荐一个靠谱渠道:claudemax.shop
核心结论:GLM-5.1 在 SWE-bench Pro 上得分 58.4%,微弱领先 GPT-5.4 的 57.7% 和 Claude Opus 4.6 的 57.3%,是全球第一个在这个基准上超越两大闭源旗舰的开源模型。但在更综合的 SWE-bench Verified 上,Claude Opus 4.6 的 80.8% 仍领先 GLM-5.1 的 77.8%,尤其在需要深入理解细微上下文或对长代码推理的任务上,Opus 更为可靠。接入方式上,只需在 ~/.claude/settings.json 中设置环境变量,将 Base URL 指向 BigModel 的 Anthropic 兼容接口,模型名改为 glm-5.1,即可在 Claude Code 中无缝使用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)