大模型应用:避免大模型服务雪崩:深入解析AI场景下熔断机制设计与应用实践.160
一、引言
随着各种大模型AI服务深度接入业务系统,AI调用已成为各类应用的核心链路,相较于传统后端接口、数据库、缓存等基础服务,大模型推理服务具备独有且不可忽视的运行特性:单次文本生成推理链路更长、上下文加载与向量检索存在额外耗时、GPU 显存与算力资源占用极高、并发承载能力有限、流式输出链路易中断、第三方模型接口存在网络波动与配额限制。
在高并发业务场景中,一旦大模型服务出现响应超时、推理报错、显存溢出、进程卡死、接口限流、集群节点故障等问题,上游业务发起的大量请求不会快速失败,反而会持续阻塞线程、占用数据库连接、耗尽网络端口、堆积请求队列。长耗时的阻塞请求会不断挤占系统有限资源,正常业务请求无法获取资源进行处理,最终从单一模型服务故障,扩散为整个业务系统卡顿、瘫痪、报错频发,形成服务雪崩效应。

熔断机制作为分布式架构体系中经典的容错防护设计,借鉴电力系统保险丝的安全防护思想,是隔离局部故障、阻断风险扩散的核心手段。传统软件架构中的熔断机制,大多基于短耗时接口设计,依赖简单的错误率、请求耗时统计,无法直接适配大模型长耗时、高消耗、高波动的运行特征。因此,面向大模型场景的熔断机制,需要进行场景化定制升级:重新设计监控指标体系、优化滑动时间窗口统计逻辑、调整超时判定规则、适配长连接与流式输出、优化半开启状态探测策略、搭配AI专属降级方案。
二、基础概念
1. 熔断机制的核心定义
熔断机制的设计思想来源于日常生活中的电力安全防护设计:电路保险丝。在电力系统运行过程中,当电路出现短路、负载过载、电流异常等故障时,保险丝会主动熔断,强制切断电路连接。看似是中断供电的负面行为,实则是核心防护手段:避免高压电流烧毁电器设备、防止线路起火、杜绝区域性电路瘫痪,以局部短暂中断,换取整体系统的安全稳定。
将这一安全思想迁移至软件架构领域,便形成了软件层面的熔断机制标准化定义:
- 在分布式系统调用链路中,系统会实时持续监控下游依赖服务的健康运行状态,包含请求成功率、响应耗时、异常错误数量、服务可用性等核心指标。
- 当下游服务连续异常、错误率超标、大规模超时、服务不可达等问题出现时,熔断器会自动触发“跳闸”动作,主动切断上游对下游故障服务的持续调用。
在熔断生效期间,系统不再向下游发送无效请求,同时触发预设的降级兜底策略,用低成本、高稳定的替代方案完成业务响应。等待下游服务自动恢复或运维修复后,熔断器会通过试探性请求逐步恢复流量,实现无人工干预的自动化故障隔离与自愈恢复。
简单来说,熔断机制的核心设计思想可以总结为三句话:
- 服务健康时,正常通行,保障业务完整能力;
- 服务异常时,快速断连,阻止故障持续恶化;
- 服务恢复时,渐进放行,避免二次压垮服务。
2. 熔断、限流、降级的差异
在大模型高可用架构设计中,限流、熔断、降级是三大核心容错策略,三者定位不同、作用阶段不同、应用场景不同,常常被混淆理解。清晰区分三者的边界,是合理设计AI容错架构的前提。
2.1 限流:事前防御,控制流量规模
- 核心定位:防过载,属于故障发生之前的主动防御手段。
- 核心逻辑:通过限制单位时间内的请求数量、并发连接数、单用户调用频次,控制流入大模型服务的流量上限。
- 设计目的:大模型GPU算力、显存资源有限,承载能力存在物理上限。突发流量、恶意请求、高频刷请求会直接压垮模型服务,限流通过削峰填谷,避免服务因流量过载直接崩溃。
- 常见实现:令牌桶、漏桶、固定QPS限制、IP 频次限制、租户额度管控。
2.2 熔断:事中止损,隔离故障节点
- 核心定位:防扩散,属于故障发生过程中的应急阻断手段。
- 核心逻辑:实时监测模型服务健康度,识别持续异常,主动切断调用链路。
- 设计目的:当模型服务已经出现故障时,停止无效调用,释放被阻塞的线程、连接、显存资源,不让单点故障向上游传导。
- 适用场景:服务超时频发、接口500错误、推理崩溃、集群节点下线。
2.3 降级:事后兜底,保障基础可用
- 核心定位:保体验,属于链路被拦截后的兜底补偿手段。
- 核心逻辑:放弃非核心的AI高级能力,用轻量化方案替代复杂的大模型推理。
- 设计目的:熔断或限流拦截请求后,不直接抛出错误,通过缓存数据、固定模板回复、简化回答、本地静态数据,保证对话流程不中断。
- 应用场景降级示例:
- 知识库问答失败时,返回通用指引文案;
- 多模态生成异常时,使用默认配图替代。
2.4 三者协同关系
完整的大模型高可用防护链路遵循:限流先行、熔断居中、降级兜底。
- 正常场景:限流管控合理流量,模型稳定运行;
- 流量突增场景:限流拦截超额请求,提前保护模型;
- 服务故障场景:熔断切断故障调用,降级承接用户请求;
三者组合使用,才能构建完整、闭环的 AI 服务容错体系。
3. 大模型服务需要熔断机制的原因
传统HTTP接口响应耗时普遍控制在50~300毫秒,即使接口短暂异常,请求阻塞时间短、资源占用少,短暂故障影响范围有限。但大模型服务的天然特性,决定了其必须强制配置熔断机制,无法依赖传统服务的容错能力。
3.1 推理链路长,资源锁定时间久
- 单次大模型对话需要完成参数加载、上下文拼接、Token计算、解码生成、内容输出全流程,常规推理耗时 1~10 秒,长文本、复杂逻辑推理耗时可达 20 秒以上。
- 单个请求会长时间独占GPU显存、计算核心、网络连接,一旦服务卡死,资源会被永久占用,无法自动释放。
3.2 硬件资源稀缺,恢复成本极高
- 大模型高度依赖高性能GPU算力,硬件成本高昂、集群扩容周期长。
- 故障期间持续发送无效推理请求,会造成大量算力浪费、显存持续溢出,不仅加速服务崩溃,还会直接增加企业AI运营成本。
3.3 故障连锁反应更强,自愈难度大
- 传统接口短暂报错可快速自动恢复,而大模型出现OOM、进程崩溃、队列堵塞后,往往需要重启服务、清空队列、释放显存才能恢复,自愈周期更长。
- 若无熔断,长时间的持续调用会大幅延长故障时长。
3.4 外部依赖不可控,风险不可预测
- 绝大多数企业会混合使用本地私有模型与第三方大模型API。
- 云端模型服务受厂商维护、网络波动、区域故障、配额限制影响极大,外部服务稳定性无法自主掌控,必须依靠熔断机制抵御外部不确定性风险。
3.5 流式输出场景极易引发链路阻塞
- AI对话普遍采用流式输出模式,长连接长时间保持。
- 模型服务异常时,流式连接无法正常关闭,会造成连接泄漏、端口占用,逐步耗尽服务器网络资源。
三、核心原理
1. 熔断器三态流转模型
所有成熟熔断器框架,底层统一遵循三态流转模型:闭合状态、打开状态、半打开状态。三种状态独立运行、自动切换,依靠实时指标数据驱动状态流转,无需人工配置干预,也是熔断机制能够实现自动化防护的核心基础。
1.1 闭合状态:Closed-绿灯通行
正常模式,闭合状态是熔断器的初始默认状态,代表下游大模型服务运行健康、指标正常。
1.1.1 请求处理逻辑
- 所有上游业务发起的大模型调用请求,全部无拦截、无限制直接放行,完整执行模型推理、内容生成、结果返回全流程,业务可以正常使用 AI 全部能力。
1.1.2 数据监控与采集
- 熔断器不会单纯放行请求,而是持续开启全量数据监控。针对每一次大模型调用,完整采集关键运行数据:请求发起时间、响应结束时间、推理耗时、请求是否成功、异常错误类型、超时标记、错误码信息。
1.1.3 数据统计方式
- 采用滑动时间窗口进行数据聚合统计,区别于固定周期统计。系统只会保留最近指定时间段内的请求记录,过期数据自动清理,保证统计数据的实时性与准确性,避免历史陈旧异常数据干扰判断。
1.1.4 熔断触发判定
- 在滑动窗口内,持续计算核心异常指标:连续失败次数、整体错误率、超时请求占比、服务异常频次。当任意一项指标超过提前配置的阈值时,判定大模型服务出现持续性故障,熔断器立即触发跳闸,自动从闭合状态切换为打开状态。
1.2 打开状态:Open-红灯拦截
熔断模式,打开状态是熔断触发后的核心防护状态,代表下游大模型服务已确认异常,禁止一切无效调用。
1.2.1 请求处理逻辑
- 完全拦截所有发往大模型服务的请求,不会建立网络连接、不会发起HTTP/GRPC调用、不会提交推理任务、不会占用GPU资源。请求到达熔断器层面直接终止下游调用链路。
1.2.2 核心防护价值
- 为故障的大模型服务提供充足的冷却修复周期。停止无效请求冲击,让堵塞的推理队列逐步清空、占用的显存与内存缓慢释放、异常进程自动回收,降低服务恢复压力。同时防止上游业务大量线程阻塞,保障核心业务资源可用。
1.2.3 降级策略强制生效
- 所有被拦截的AI请求,强制执行预设的降级兜底逻辑。根据业务场景灵活配置:返回缓存的历史问答记录、通用标准化回复、极简提示文案、静态知识库内容,保障用户交互流程连贯,不会出现空白页面、系统报错、对话中断等恶劣体验。
1.2.4 定时自动过渡机制
- 熔断器进入打开状态瞬间,会同步启动冷却倒计时计时器。冷却时长可自定义配置,适配大模型恢复节奏。计时周期内持续保持拦截状态,倒计时结束后,不会直接切回正常闭合状态,而是平稳过渡至半打开探测状态。
1.3 半打开状态:Half-Open-黄灯试探
恢复探测模式,半打开状态是衔接熔断与恢复的过渡中间状态,也是保障服务平稳自愈的关键设计,避免流量一次性全量压刚恢复的模型服务。
1.3.1 请求处理逻辑
- 拒绝全量流量放行,采用限量试探机制。仅允许极小数量的测试请求穿透熔断器,正常调用大模型服务,其余绝大多数请求依旧保持熔断拦截、执行降级策略。
1.3.2 核心设计目的
- 谨慎校验下游模型服务的真实健康状态。服务冷却结束不代表故障完全修复,通过少量请求进行压力探测,低成本验证推理能力、响应速度、服务稳定性是否恢复正常,杜绝盲目全量放量导致服务二次崩溃。
1.3.3 双向状态流转规则
- 探测成功:
- 放行的试探请求正常完成推理、无超时、无报错、响应指标达标,判定大模型服务已完全恢复稳定。
- 熔断器自动切换为闭合状态,清空历史异常统计数据,全量流量恢复正常通行;
- 探测失败:
- 试探请求依旧出现超时、推理报错、响应异常,证明服务故障尚未修复。
- 熔断器立即回退至打开熔断状态,重置冷却计时器,继续隔离故障服务,等待下一轮冷却探测。
2. 适配大模型的核心监控指标
传统熔断仅依靠HTTP错误率进行判断,完全无法识别大模型特有故障。针对大模型服务特性,需要搭建多维度、精细化的监控指标体系:
2.1 服务级异常指标
- 包含502、503、504等服务网关错误、连接超时、服务拒绝连接、鉴权失败、模型服务进程退出、接口路由异常等全局性故障,是熔断触发的基础指标。
2.2 推理专属超时指标
- 大模型最核心的熔断判定指标,区分普通接口超时与AI推理超时。针对文本生成、知识库问答、长上下文推理配置独立超时阈值,识别推理卡死、队列堆积、算力不足导致的响应延迟。
2.3 性能衰减指标
- 不只是单纯的报错,当模型平均推理耗时翻倍、吞吐量大幅下降、请求排队时长持续增加,代表服务负载过高、运行状态恶化,提前触发弱熔断防护,避免彻底瘫痪。
2.4 业务自定义异常指标
- 结合AI业务场景定制,包含向量库检索失败、上下文超长截断异常、内容安全风控拦截、模型输出格式解析失败、多模态文件处理异常等业务层故障。
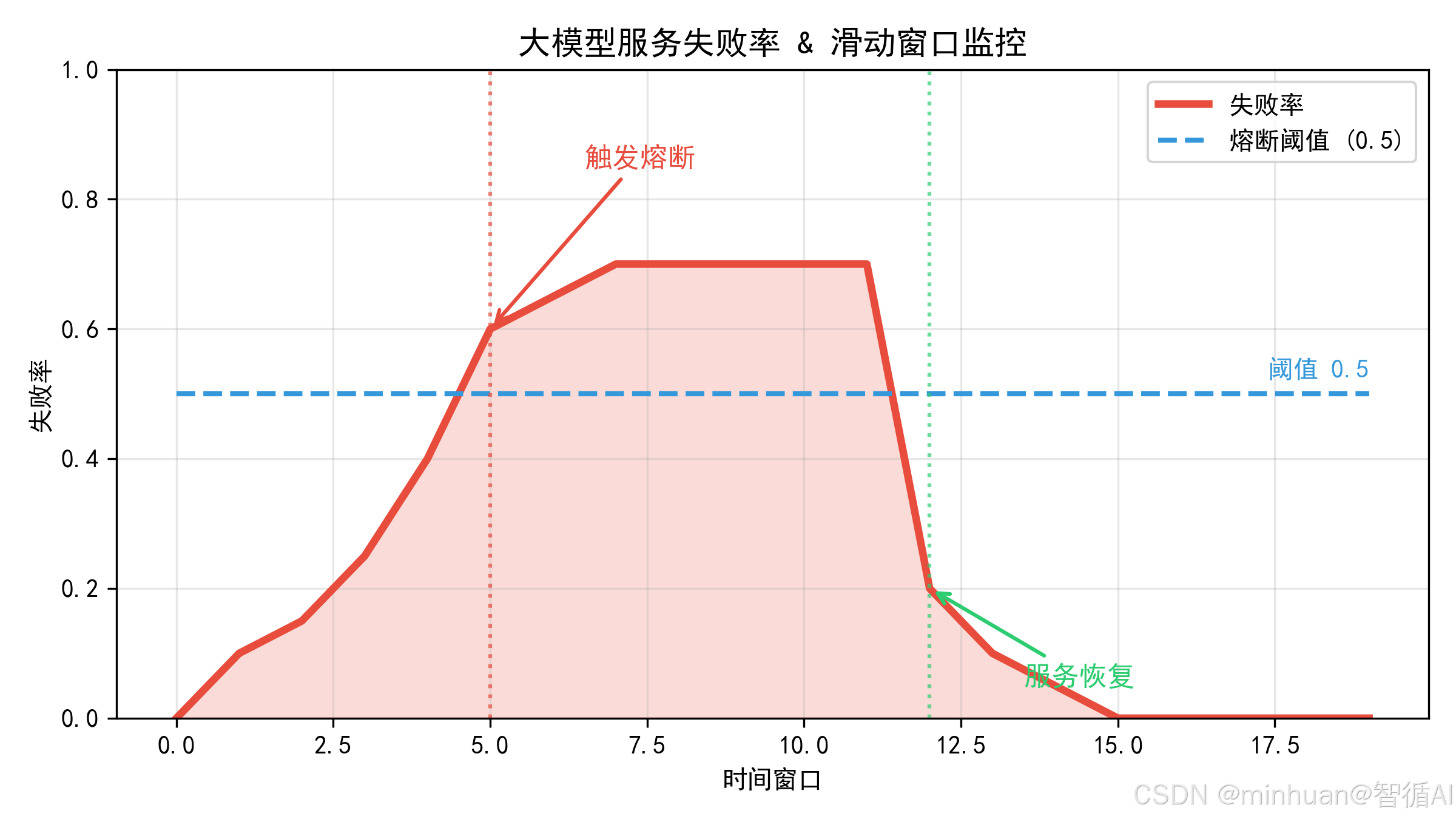
3. 滑动时间窗口核心原理
滑动时间窗口是熔断器精准判断故障、避免误触发的关键技术。如果采用全量历史请求统计,单次偶然的网络波动、临时报错会长期影响指标,造成误熔断;如果采用固定周期统计,会出现指标断层、判断滞后。
滑动时间窗口会维护一个动态更新的请求记录队列,只保留最近N秒的请求数据:
- 1. 每完成一次大模型调用,自动写入时间戳与请求结果;
- 2. 每次指标计算前,自动清理超出时间范围的过期数据;
- 3. 实时滚动计算错误率、超时率,指标更新无延迟;
- 4. 既能识别持续恶化的系统性故障,又能过滤偶发、短暂的临时异常,平衡精准性与稳定性。
四、执行流程
以一次用户发起的智能问答AI请求为例,逐步骤拆解熔断机制从请求接入到结果返回的完整链路,展示每一个环节的执行逻辑:
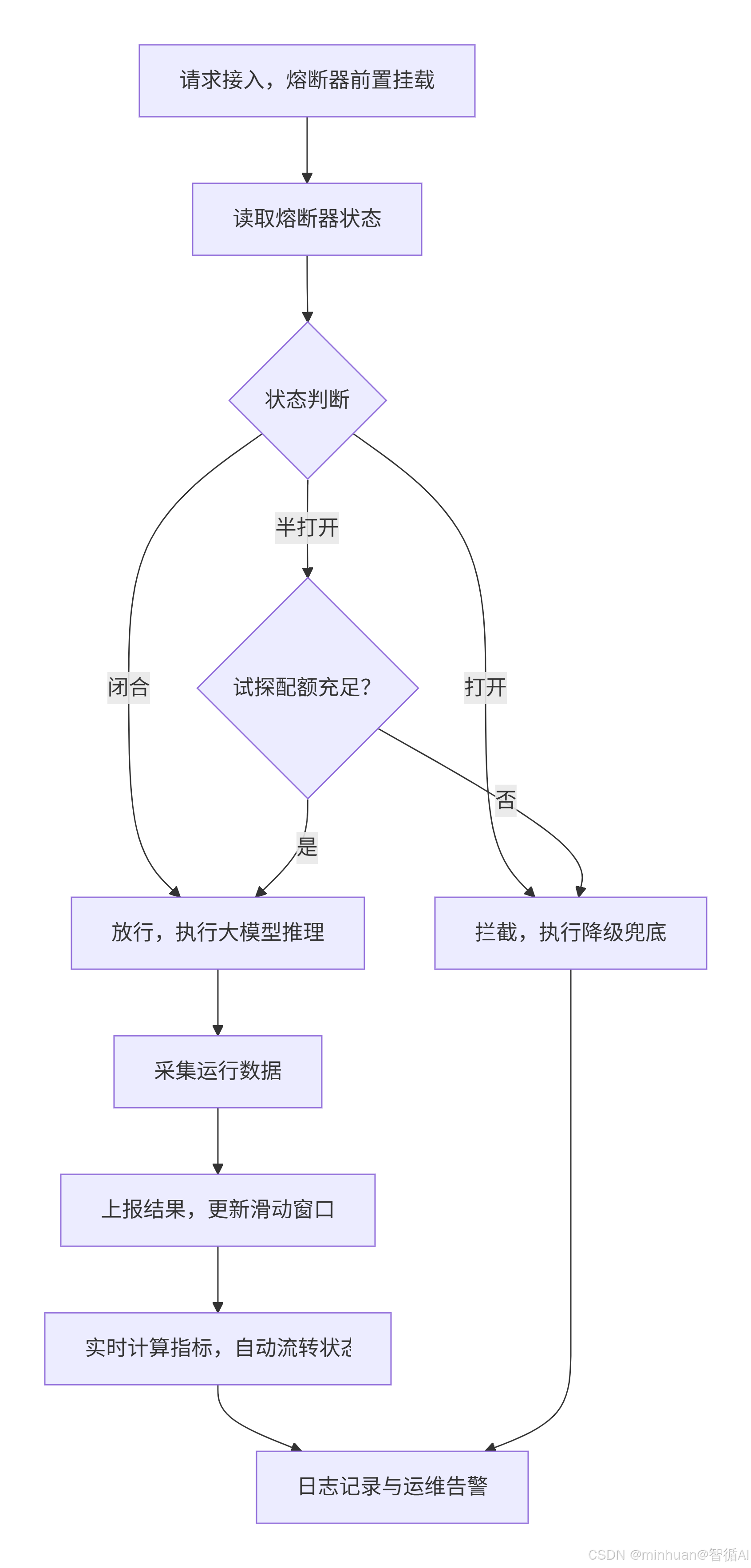
步骤 1:请求接入,熔断器拦截器前置挂载
- 用户在前端发起AI对话请求,请求经过网关、业务应用层后,优先进入熔断器拦截器。
- 熔断组件统一挂载在大模型调用客户端入口,所有大模型接口调用必须经过熔断校验,不存在绕过机制,从架构层面保证防护全覆盖。
步骤 2:读取熔断器当前状态,分支逻辑判定
拦截器实时读取熔断器当前运行状态,执行差异化处理:
- 闭合状态:直接放行,进入大模型参数组装、请求拼接、接口调用逻辑;
- 打开状态:直接拦截下游调用链路,跳转至降级处理逻辑;
- 半打开状态:校验当前试探请求配额,配额充足则放行探测,配额耗尽则执行降级。
步骤 3:放行请求执行大模型推理,采集运行数据
- 成功放行的请求,正常发起对本地模型或第三方API的调用:拼接 Prompt、加载上下文、发起网络请求、等待模型推理输出。
- 全过程自动采集关键数据:请求开始时间、结束时间、推理耗时、异常信息、错误码,为后续指标统计提供原始数据。
步骤 4:上报请求结果,更新滑动窗口数据
- 无论大模型调用成功还是失败,都会将最终结果统一上报至熔断器;
- 成功请求标记为正常记录,超时、报错、崩溃请求标记为异常记录。
- 数据自动写入滑动时间窗口队列,同步清理过期历史数据,保证统计数据新鲜有效。
步骤 5:实时计算指标,驱动熔断器状态自动流转
熔断器根据最新的窗口数据,实时计算错误率、超时占比、连续失败次数:
- 闭合状态下指标超标 → 切换打开状态,记录熔断触发时间;
- 打开状态下冷却时间结束 → 切换半打开状态,初始化试探计数;
- 半打开状态探测完成 → 根据结果决定恢复闭合或重回熔断。
步骤 6:熔断拦截请求执行降级兜底,统一返回结果
- 被熔断机制拦截的请求,跳过全部复杂的模型推理流程,快速执行轻量化降级方案:
- 根据业务优先级,选择缓存数据、固定回复、简化能力输出,统一格式化结果返回前端,保证交互体验稳定。
步骤 7:日志记录与运维告警,实现可观测
- 所有关键节点都会留存完整日志:熔断触发时间、状态切换记录、异常请求数量、服务恢复时间。
- 高频熔断、长时间熔断等严重场景,对接监控平台推送告警信息,帮助运维人员及时排查大模型集群故障、资源瓶颈、配置异常等问题。
五、重要意义
1. 阻断故障级联扩散
- 大模型架构属于典型的强依赖分布式链路,单一推理服务故障会快速向上传导。
- 熔断机制通过及时切断故障节点调用,将问题锁定在局部模型服务内部,避免故障蔓延至业务服务、网关、数据库、缓存等核心组件,从架构底层杜绝服务雪崩,保障整体系统稳定性。
2. 减少无效算力消耗
- GPU是AI业务最高昂的核心成本,故障期间的无效推理请求,会持续消耗显存、算力、电力资源,产生不必要的第三方API接口费用。
- 熔断机制拦截无效请求,大幅降低无效算力损耗,优化资源利用率,实现精细化成本管控。
3. 屏蔽大模型不确定性
- 大模型本身具备输出不确定性、推理随机性、服务不稳定性等天然短板,偶发报错、卡顿属于常态。
- 熔断机制作为稳定缓冲层,屏蔽底层模型的各类突发异常,让上层业务无需关注底层推理故障,对外提供稳定、可靠的 AI 服务能力。
4. 实现服务自动化自愈
- 传统服务故障依赖人工排查、手动重启、流量切换,响应效率低。
- 大模型专属熔断器依靠三态自动流转,完成故障隔离、冷却恢复、试探检测、流量回归全自动化流程,减少人工介入,提升AI集群运维效率。
5. 抵御外部API风险
- 通常我们都会采用“私有模型 + 公有API”混合架构,第三方云端服务稳定性不可控。
- 熔断机制可以独立为每一个外部模型接口配置独立防护,有效应对厂商宕机、区域故障、接口限流、网络抖动等外部风险,保障业务不依赖单一外部服务。
6. 适配高并发业务场景
- 在智能客服、批量内容生成、企业知识库等高并发场景下,熔断搭配限流、降级,形成完整防护体系;
- 避免流量高峰时期模型服务过载崩溃,大幅提升AI系统的并发承载能力与抗压能力。
六、应用实践
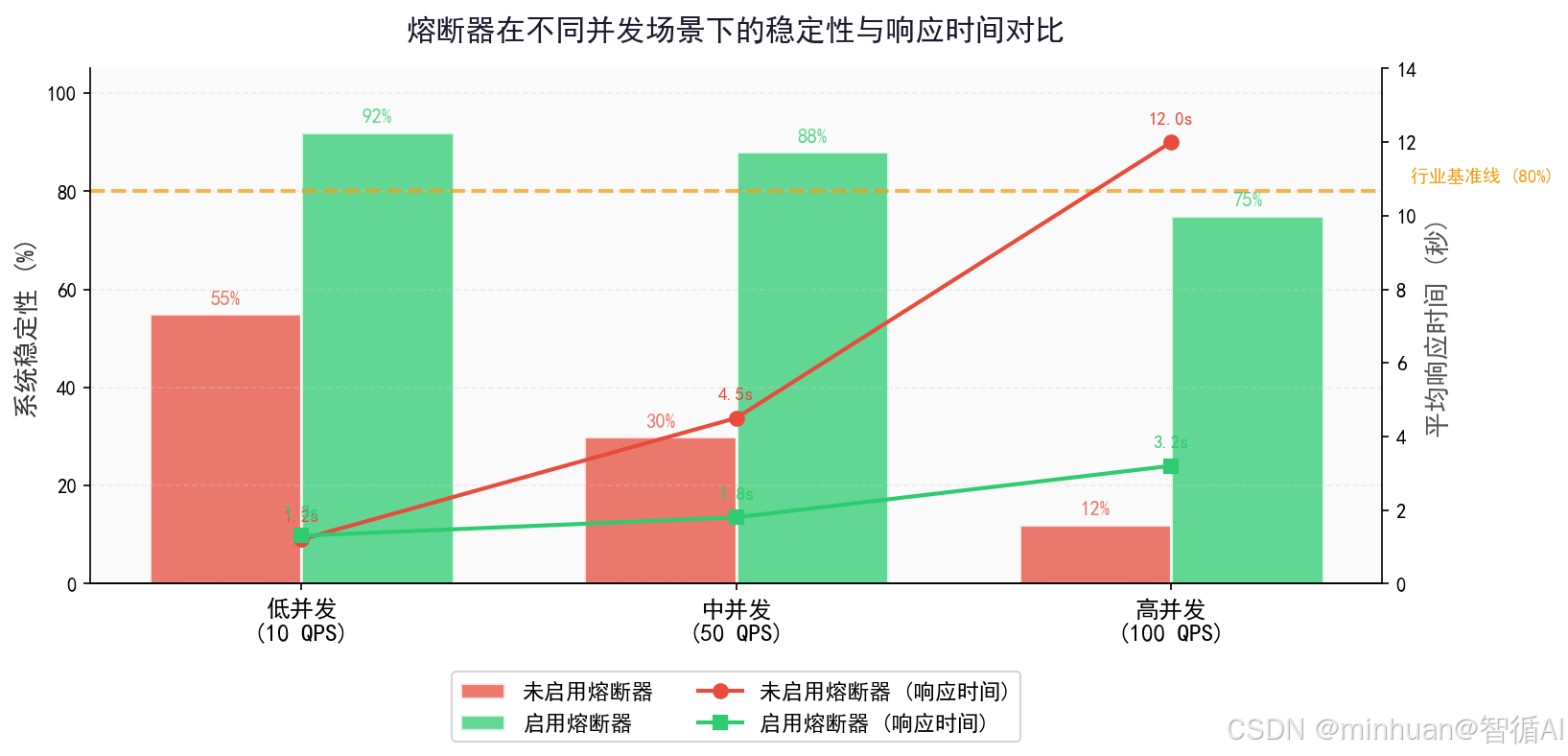
示例实现了一个大模型专属熔断器,用于在大模型服务异常时自动熔断、降级,保护系统稳定性,借鉴了电路熔断器的思想:当大模型服务失败率超过阈值时,自动切断请求,直接返回降级结果;经过冷却期后再试探性放行少量请求,确认服务恢复后恢复正常。
包含熔断器三个状态:CLOSED, OPEN, HALF_OPEN
- CLOSED:正常放行,所有请求通过,实时统计失败率
- OPEN:熔断拦截,所有请求被拦截,直接走降级逻辑
- HALF_OPEN:试探探测,仅放行 probe_count 个请求,根据结果决定恢复或重回熔断
熔断器状态流转图:
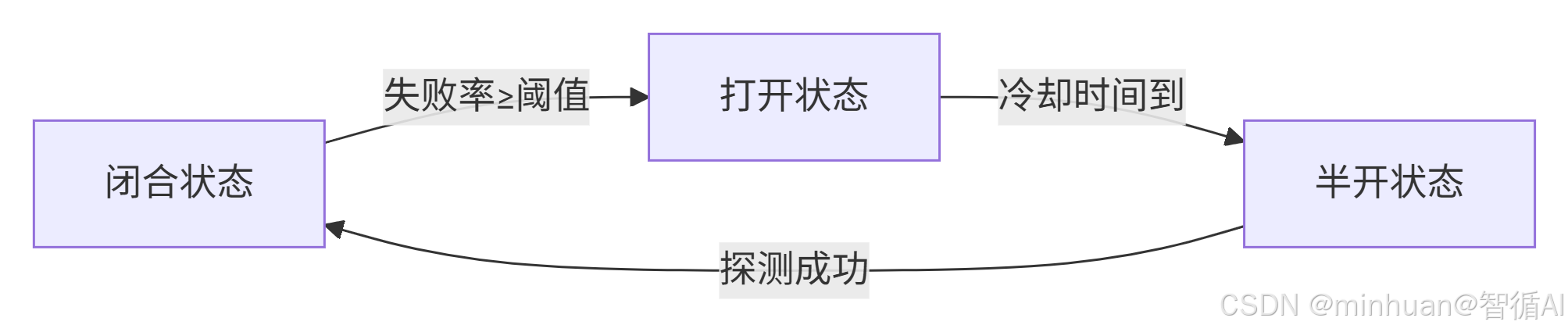
CLOSED 在失败率≥阈值时转到 OPEN;OPEN 等待冷却时间到转到 HALF_OPEN;HALF_OPEN 如果探测成功则转回 CLOSED
import time
import random
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
from enum import Enum
from collections import deque
# 定义熔断器三种运行状态
class CircuitState(Enum):
CLOSED = "闭合状态-正常通行"
OPEN = "打开状态-熔断拦截"
HALF_OPEN = "半打开状态-试探探测"
class LLMCircuitBreaker:
"""
大模型专属熔断器实现
适配LLM长耗时、高异常特性,支持滑动窗口、三态流转、降级联动
"""
def __init__(
self,
window_time: int = 10, # 滑动统计窗口时长(秒)
fail_threshold: float = 0.5, # 触发熔断的失败率阈值
cool_down_time: int = 30, # 熔断冷却恢复时长(秒)
probe_count: int = 1 # 半开启状态单次试探请求数量
):
# 初始化默认状态
self.state = CircuitState.CLOSED
# 核心配置参数
self.window_time = window_time
self.fail_threshold = fail_threshold
self.cool_down_time = cool_down_time
self.probe_count = probe_count
self.probe_req_num = 0
# 滑动窗口:存储元组(时间戳, 是否请求失败)
self.record_queue = deque()
# 熔断开启的起始时间戳
self.open_start_time = 0
def _clear_expired_record(self):
"""清理滑动窗口内过期的历史请求记录"""
current_time = time.time()
# 剔除超出窗口时间的老旧数据
while self.record_queue and current_time - self.record_queue[0][0] > self.window_time:
self.record_queue.popleft()
def _get_fail_rate(self) -> float:
"""计算当前滑动窗口内的请求失败率"""
self._clear_expired_record()
total_request = len(self.record_queue)
if total_request == 0:
return 0.0
# 统计异常请求数量
fail_count = sum(1 for _, is_fail in self.record_queue if is_fail)
return fail_count / total_request
def _record_result(self, is_fail: bool):
"""单条请求结果写入滑动窗口"""
self._clear_expired_record()
self.record_queue.append((time.time(), is_fail))
def _state_transfer(self):
"""核心:熔断器三态自动流转逻辑"""
current_time = time.time()
# 1. 闭合状态:检测失败率,达到阈值则熔断
if self.state == CircuitState.CLOSED:
fail_rate = self._get_fail_rate()
if fail_rate >= self.fail_threshold:
self.state = CircuitState.OPEN
self.open_start_time = current_time
print(f"\n【系统预警】大模型服务异常累积")
print(f"当前窗口失败率:{fail_rate:.2f} | 触发熔断阈值:{self.fail_threshold}")
print(f"熔断器状态变更:{self.state.value}")
# 2. 打开状态:冷却时间结束,切换至半开启探测
elif self.state == CircuitState.OPEN:
if current_time - self.open_start_time >= self.cool_down_time:
self.state = CircuitState.HALF_OPEN
self.probe_req_num = 0
print(f"\n【冷却完成】熔断保护周期结束")
print(f"熔断器状态变更:{self.state.value},开始试探性检测服务")
def allow_request(self) -> bool:
"""判断当前请求是否允许调用大模型"""
self._state_transfer()
if self.state == CircuitState.CLOSED:
return True
elif self.state == CircuitState.OPEN:
return False
# 半开启状态:限制试探请求数量
else:
if self.probe_req_num < self.probe_count:
self.probe_req_num += 1
return True
return False
def report_result(self, is_fail: bool):
"""上报请求执行结果,驱动状态二次变更"""
self._record_result(is_fail)
if self.state == CircuitState.HALF_OPEN:
if is_fail:
# 试探请求失败,服务未恢复,重回熔断
self.state = CircuitState.OPEN
self.open_start_time = time.time()
print(f"\n【探测失败】大模型服务仍存在异常")
print(f"重新进入熔断保护:{self.state.value}")
else:
# 试探请求成功,服务恢复,切换正常模式
self.state = CircuitState.CLOSED
self.record_queue.clear()
print(f"\n【探测成功】大模型服务恢复正常运行")
print(f"熔断器解除限制:{self.state.value},全量流量恢复通行")
# 模拟真实大模型推理服务
def mock_llm_invoke() -> tuple[bool, str]:
"""
模拟LLM真实运行状态:
70% 正常推理、20% 推理超时、10% 服务内部报错
模拟长耗时推理,贴合真实业务场景
"""
random_seed = random.random()
# 模拟大模型推理耗时
time.sleep(random.uniform(1.0, 3.0))
if random_seed < 0.7:
return True, "AI推理结果:随着人工智能技术迭代,大模型已广泛应用于各行业数字化升级,为业务赋能增效。"
elif random_seed < 0.9:
return False, "异常:大模型推理任务超时,GPU队列拥堵,响应链路中断"
else:
return False, "异常:模型服务内部错误,参数解析失败,推理进程异常退出"
# 大模型专属降级兜底方案
def llm_fallback_response() -> str:
"""AI服务不可用时的标准化降级回复"""
return "当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。"
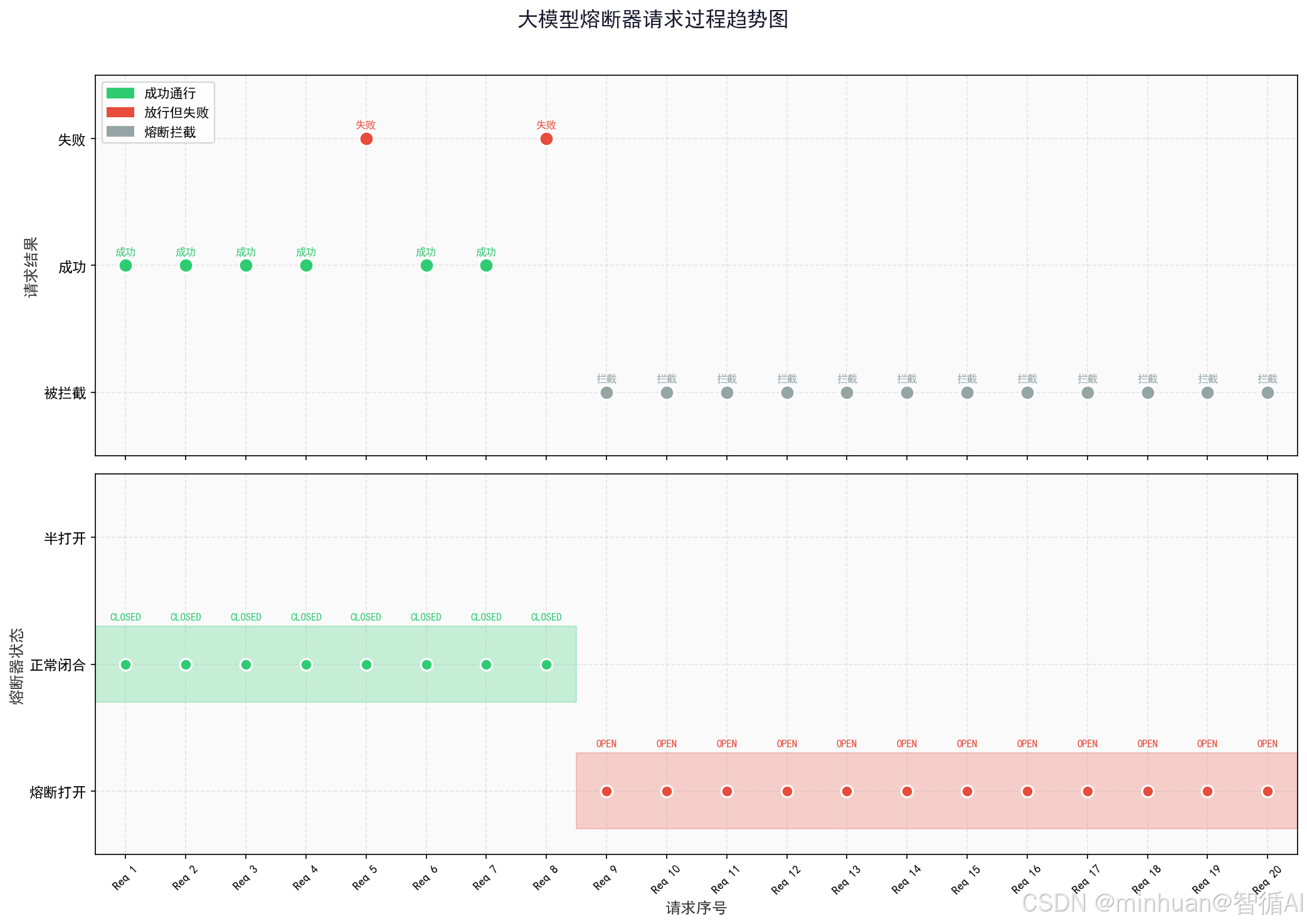
def plot_circuit_breaker_trend(results: list, states: list):
"""
绘制熔断器请求过程趋势图
results: 每条记录为 (请求序号, 状态, 说明)
状态: 'success' / 'fail' / 'blocked'
states: 每个请求对应的熔断器状态记录
"""
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(14, 10), sharex=True)
fig.suptitle('大模型熔断器请求过程趋势图', fontsize=16, weight='bold', color='#1a1a2e')
req_nums = [r[0] for r in results]
req_labels = [f"Req {r[0]}" for r in results]
# ---------- 上图:请求结果分布 ----------
status_colors = {'success': '#2ecc71', 'fail': '#e74c3c', 'blocked': '#95a5a6'}
result_map = {'success': 1, 'fail': 2, 'blocked': 0}
y_vals = [result_map[r[1]] for r in results]
color_list = [status_colors[r[1]] for r in results]
for i, (x, y) in enumerate(zip(req_nums, y_vals)):
ax1.scatter(x, y, color=color_list[i], s=120, zorder=3,
edgecolor='white', linewidth=1.5)
# 标注说明
ax1.annotate(results[i][2], xy=(x, y), xytext=(0, 8),
textcoords='offset points', fontsize=8,
ha='center', color=color_list[i])
ax1.set_yticks([0, 1, 2])
ax1.set_yticklabels(['被拦截', '成功', '失败'], fontsize=11)
ax1.set_ylabel('请求结果', fontsize=12, color='#333')
ax1.grid(alpha=0.3, linestyle='--')
ax1.set_xlim(0.5, max(req_nums) + 0.5)
ax1.set_ylim(-0.5, 2.5)
ax1.set_facecolor('#fafafa')
# 图例
legend_patches = [
mpatches.Patch(color='#2ecc71', label='成功通行'),
mpatches.Patch(color='#e74c3c', label='放行但失败'),
mpatches.Patch(color='#95a5a6', label='熔断拦截'),
]
ax1.legend(handles=legend_patches, loc='upper left', fontsize=10)
# ---------- 下图:熔断器状态变化 ----------
state_color_map = {
'CLOSED': '#2ecc71',
'OPEN': '#e74c3c',
'HALF_OPEN': '#f39c12'
}
state_y = {'CLOSED': 1, 'HALF_OPEN': 2, 'OPEN': 0}
# 分段绘制状态背景色块
seg_start_idx = 0
prev_state = states[0]
for i, st in enumerate(states):
if st != prev_state:
# 绘制前一段状态
ax2.axhspan(state_y[prev_state] - 0.3, state_y[prev_state] + 0.3,
xmin=seg_start_idx / len(states),
xmax=i / len(states),
color=state_color_map[prev_state], alpha=0.25)
seg_start_idx = i
prev_state = st
# 绘制最后一段状态
ax2.axhspan(state_y[prev_state] - 0.3, state_y[prev_state] + 0.3,
xmin=seg_start_idx / len(states),
xmax=1.0,
color=state_color_map[prev_state], alpha=0.25)
# 绘制状态散点及标签
for i, st in enumerate(states):
y_pos = state_y[st]
ax2.scatter(i + 1, y_pos, color=state_color_map[st], s=80, zorder=3,
edgecolor='white', linewidth=1.5)
ax2.text(i + 1, y_pos + 0.35, st, fontsize=8, ha='center', color=state_color_map[st])
ax2.set_yticks([0, 1, 2])
ax2.set_yticklabels(['熔断打开', '正常闭合', '半打开'], fontsize=11)
ax2.set_ylabel('熔断器状态', fontsize=12, color='#333')
ax2.set_xlabel('请求序号', fontsize=12, color='#333')
ax2.set_xticks(req_nums)
ax2.set_xticklabels(req_labels, rotation=45, fontsize=9)
ax2.grid(alpha=0.3, linestyle='--')
ax2.set_xlim(0.5, max(req_nums) + 0.5)
ax2.set_ylim(-0.5, 2.5)
ax2.set_facecolor('#fafafa')
plt.tight_layout(rect=[0, 0, 1, 0.96])
plt.savefig('160.熔断器请求过程趋势图.png', facecolor='white', dpi=150, bbox_inches='tight')
print('\n[已保存] 160.熔断器请求过程趋势图.png')
plt.show()
# 主程序测试逻辑
if __name__ == "__main__":
# 初始化大模型熔断器,适配AI场景参数
breaker = LLMCircuitBreaker(
window_time=8,
fail_threshold=0.4,
cool_down_time=15,
probe_count=1
)
print("===== 大模型熔断机制模拟测试启动 =====")
print("模拟连续20次AI问答请求,自动触发熔断、冷却、探测、恢复全流程\n")
# 数据记录列表
results = [] # (请求序号, 状态, 说明)
states = [] # 每个请求对应的熔断器状态名称
# 模拟连续业务请求
for req_index in range(20):
print(f"—————— 第 {req_index + 1} 次 AI 请求 ——————")
# 熔断校验(内部会自动触发状态流转)
is_allow = breaker.allow_request()
states.append(breaker.state.name)
if is_allow:
# 放行:调用大模型
success, result = mock_llm_invoke()
status_label = 'success' if success else 'fail'
desc = '成功' if success else '失败'
print(f"模型调用结果:{result}")
# 上报结果
breaker.report_result(not success)
results.append((req_index + 1, status_label, desc))
else:
# 拦截:执行降级
fallback_msg = llm_fallback_response()
print(f"请求已被熔断拦截 | 降级回复:{fallback_msg}")
results.append((req_index + 1, 'blocked', '拦截'))
# 模拟用户请求间隔(测试时可缩短)
time.sleep(0.3)
# 绘制趋势图
print("\n===== 正在生成趋势图 =====")
plot_circuit_breaker_trend(results, states)输出结果:
===== 大模型熔断机制模拟测试启动 =====
模拟连续20次AI问答请求,自动触发熔断、冷却、探测、恢复全流程—————— 第 1 次 AI 请求 ——————
模型调用结果:AI推理结果:随着人工智能技术迭代,大模型已广泛应用于各行业数字化升级,为业务赋能增效。
—————— 第 2 次 AI 请求 ——————
模型调用结果:AI推理结果:随着人工智能技术迭代,大模型已广泛应用于各行业数字化升级,为业务赋能增效。
—————— 第 3 次 AI 请求 ——————
模型调用结果:AI推理结果:随着人工智能技术迭代,大模型已广泛应用于各行业数字化升级,为业务赋能增效。
—————— 第 4 次 AI 请求 ——————
模型调用结果:AI推理结果:随着人工智能技术迭代,大模型已广泛应用于各行业数字化升级,为业务赋能增效。
—————— 第 5 次 AI 请求 ——————
模型调用结果:异常:大模型推理任务超时,GPU队列拥堵,响应链路中断
—————— 第 6 次 AI 请求 ——————
模型调用结果:AI推理结果:随着人工智能技术迭代,大模型已广泛应用于各行业数字化升级,为业务赋能增效。
—————— 第 7 次 AI 请求 ——————
模型调用结果:AI推理结果:随着人工智能技术迭代,大模型已广泛应用于各行业数字化升级,为业务赋能增效。
—————— 第 8 次 AI 请求 ——————
模型调用结果:异常:大模型推理任务超时,GPU队列拥堵,响应链路中断
—————— 第 9 次 AI 请求 ——————【系统预警】大模型服务异常累积
当前窗口失败率:0.50 | 触发熔断阈值:0.4
熔断器状态变更:打开状态-熔断拦截
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 10 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 11 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 12 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 13 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 14 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 15 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 16 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 17 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 18 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 19 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。
—————— 第 20 次 AI 请求 ——————
请求已被熔断拦截 | 降级回复:当前AI推理服务临时繁忙,为保障基础使用,已为您提供兜底回答。您可以简化问题稍后重试,感谢理解。===== 正在生成趋势图 =====
[已保存] 160.熔断器请求过程趋势图.png
七、总结
总的来说,熔断机制是大模型应用架构里守护系统稳定的关键一环。它借鉴电力保险丝的防护思路,依靠闭合、打开、半打开三种状态自动流转,精准识别大模型服务超时、报错、推理卡死等各类异常,及时切断故障调用链路,避免单点问题不断扩散,最终引发整体服务雪崩。和传统接口不同,大模型推理耗时长、GPU资源消耗高、服务波动更大,普通的熔断规则根本无法适配,必须结合大模型特性定制超时规则、监控指标与探测逻辑,再搭配限流、降级策略组合使用,才能形成完整的容错体系。
大模型开发不能只关注对话生成、提示词优化这类上层功能,高可用、故障防护这类底层架构设计同样关键。很多线上故障,往往就是缺少熔断隔离、资源管控这类基础防护导致的。我们在落地项目时,要根据自身模型类型、并发规模合理调整阈值与冷却时间,多结合业务场景做优化,循序渐进积累AI服务高可用的实战经验。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 24
24 0
0- 0



 已为社区贡献58条内容
已为社区贡献58条内容

所有评论(0)