RAG学习
官网教程
https://docs.langchain.com/oss/python/langchain/overview
https://docs.langchain.com/oss/python/integrations/embeddings
LangChain 含代码的教程
我们需要用到的召回、分词、embedding 模型、向量数据库、文档加载器里面都有。还有 Chat models,我们用的 HuggingFace 算是一种模型仓库。还有各个平台专门的,比如OpenAI,通义千问。
RAG基础
什么是 RAG
Retrieval-Augmented Generation 检索-增强 生成

{% note info %}
Prompting 工程用到的知识都是模型已有的知识,就是拿那些数据来训练的模型。但是如果模型训练用的数据比如截止到2025.12.31,那么近几个月(2026.4.11) 这段时间的知识是不知道的,可能会给出错误答案,RAG相当于去查询数据库,让模型利用检索到的数据以及自身的能力来进行回答。
{% endnote %}
{% note red ‘fas fa-question-circle’ simple %}
如果RAG检索到的知识和模型自身知识冲突呢?
如果RAG检索到过期消息和新消息呢?
{% endnote %}
那么我们怎么来选取用哪个技术呢?
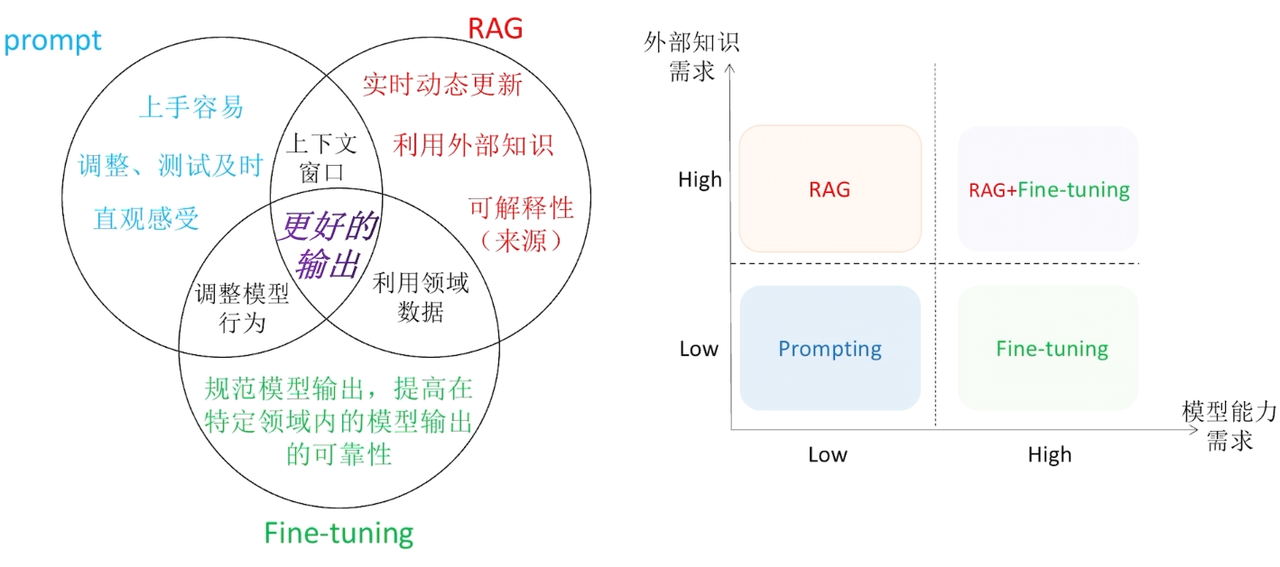
prompt 和 RAG 的共同特点是,二者都依赖于上下文窗口,就是输入给大模型的内容能有多长?比如 4K,8K。他们两个都占据窗口大小的。
之前试过想用agent分析一个地区一年的XX信息,大概有5000条,内容很长,发现模型只能分析前面一部分数据的内容,实际上是因为模型的上下文窗口很小,输入的内容后面大半部分模型都没读取到。
Fine-tuning 和 RAG 都是利用领域数据特性
prompt 和 Fine-tuning 都能调整模型行为
所以片面的来说,如果你想外部知识作为主导,用RAG,偏向调整模型能力,就是Fine-tuning。
如何快速实现一个RAG-LLM
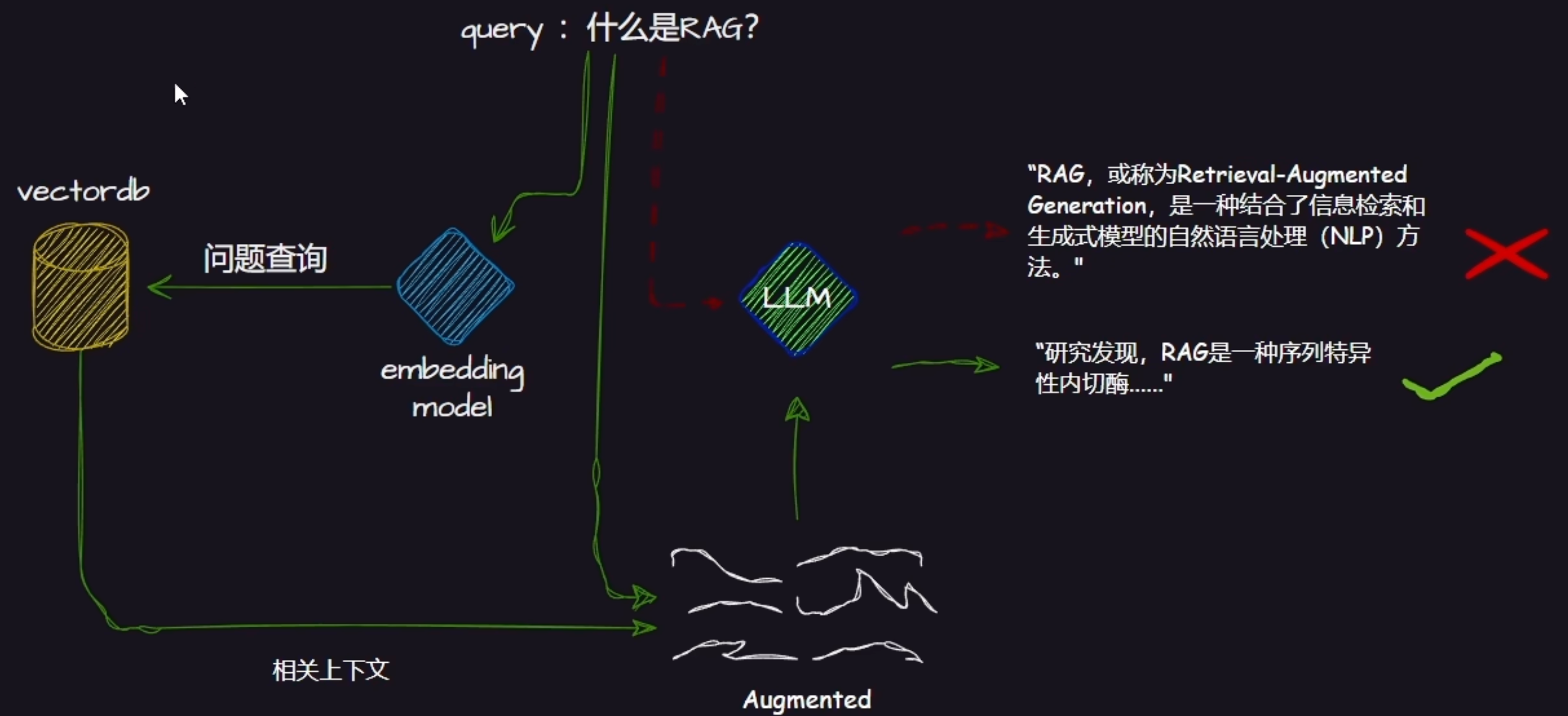
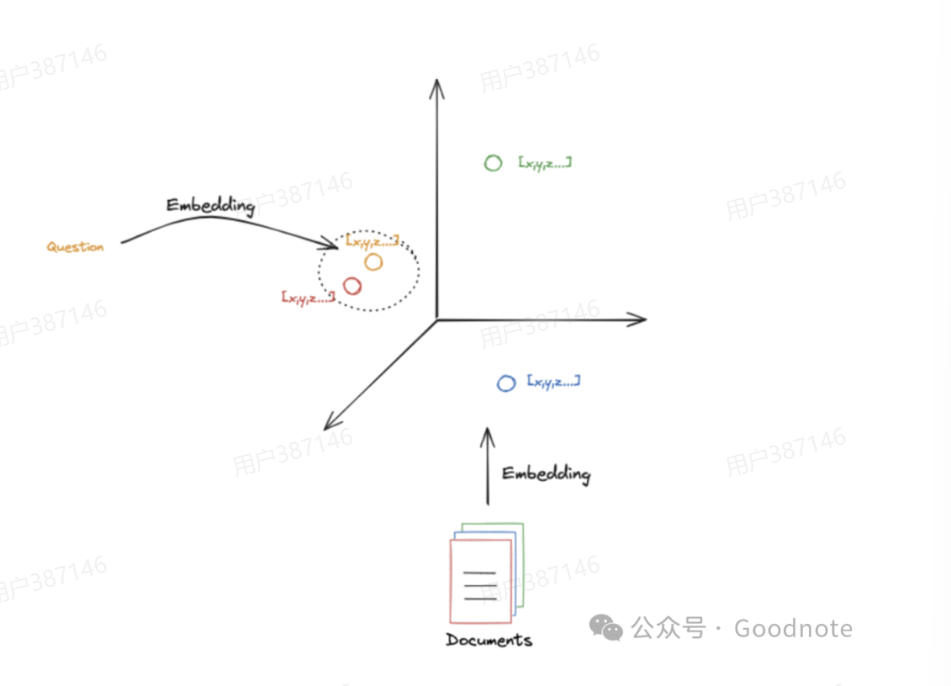
比如上面这个,提问问题:什么是RAG?
那么红色线条就是直接去大语言模型,利用已有知识进行回答,但是RAG(绿色线条),他就会去向量数据库里面查询知识,得到相关上下文,然后对这个上下文进行增强,基于之前的query和这个上下文再送给大语言模型。
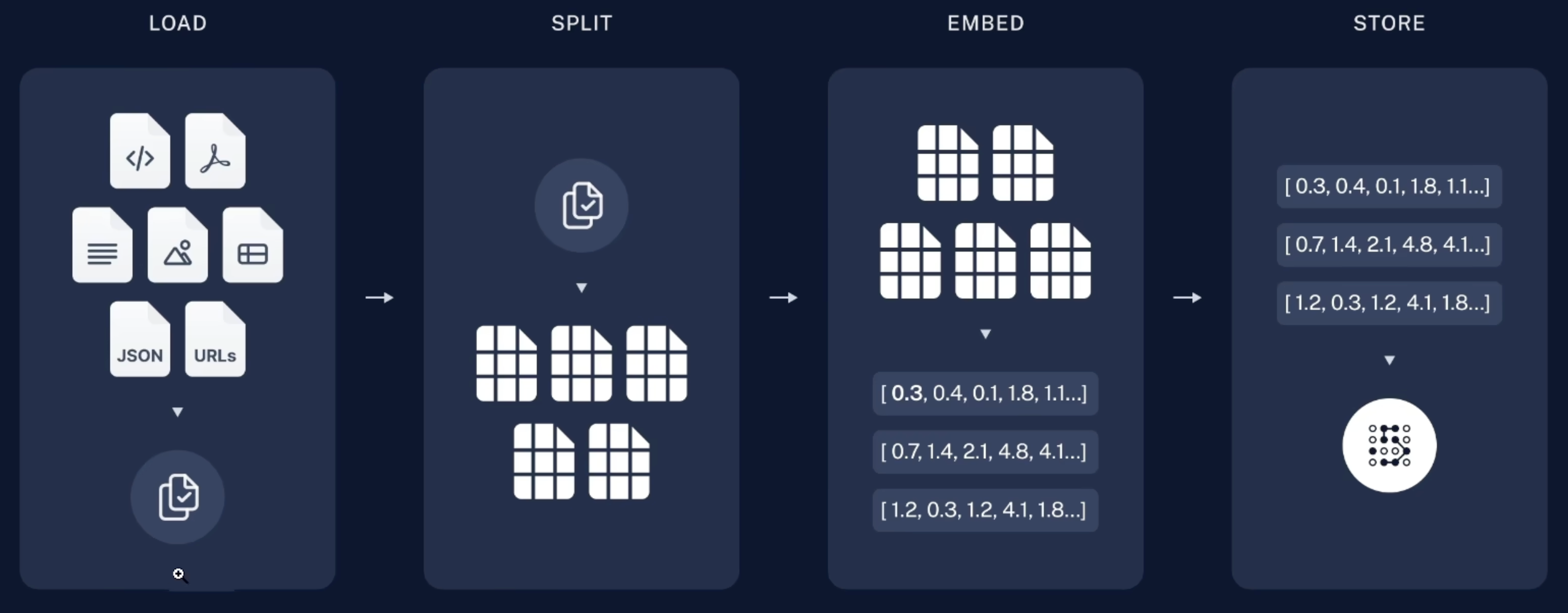
RAG 具体流程如图,我们以法律条文举例,它怎么来做
- 先把法律条文的word文档加载进来
- 按照指定的切分方法进行切分,比如我们切分成一段一段的(一段文字一个法律条文)
- 然后对每个条文进行embedding,然后放到数据库里面
- 作用就是:你比如一个词是”边缘计算“,传统搜索只能进行关键词匹配,最多模糊查询。但是 Embedding 可以把边缘计算、Edge Computing、分布式推理、云协作这些在数字空间放在很近的距离
- 存入数据库
如果有个问题来了,也会对它进行Embedding,然后去数据库查,把向量距离最近的几条拿出来,放到上下文中然后给大模型。
如何选取 pdf 加载器
Langchain 可以使用文档加载器加载不同的文档类型,比如 csv、txt、html、json以及pdf,下面介绍一下 pdf。
所有的这些文档加载器工具都通过 document_loaders 来调用。
from langchain_community.document_loaders import XXX
可以直接调用上面的语句来引入 PDF 解析的功能,有如下几种:
pypdf解析 pdf,它是按照page逐页解析,能够正确识别分栏、表格,但是不能识别正确的换行(有的真换行,有的是内容长自动换行)- 如果想提取图片信息,需要提前安装一个包
rapidocr-onnxruntime,并且设置PyPDFLoader(..., extract_images=True)。
- 如果想提取图片信息,需要提前安装一个包
pyplumber将 pdf 逐页进行解析,但是文本结构在分栏的时候存在混淆,解析不完全,也支持图片解析,也是用extract_images=True参数- 使用
PDFMiner,将整个文档解析成一个完整的文本。文本结构可以自行认为定义。分栏以及换行符都没问题。 - 使用非结构化
Unstructured,能够正确换行,默认把整个文档解析成一个完整的文本- 非结构化加载器针对不同的文本块创建了不同的元素。默认情况下是组合到一块的,也可以通过指定
mode=elements来保持这种分离,不过它是依据自己的逻辑进行分离的。
- 非结构化加载器针对不同的文本块创建了不同的元素。默认情况下是组合到一块的,也可以通过指定
Langchain 中的 textsplitter
文本分块: 当加载完一个文件之后,需要对文件进行分割,切割逻辑可以按照:章节、段落、句子、词组等。
为什么要分块?直接完整把完整的文件给大模型不行吗?
- 上下文长度的限制:LLM 通常有固定的输入长度限制(4K、8K、16K、32K 等),如 GPT-4 Turbo 为 128K。
- 提高处理效率:减少响应时间。(上下文少,处理速度快)
- 提高输出质量:LLM 处理较短的文本块时,通常能够生成更精确、更相关的输出。这是因为模型更容易理解和响应较小文本范围内的复杂性和细节。
TextSplitter 的工作流程
- 将文本拆分成小的、语义上有意义的块(通常是句子)。
- 将这些小块组合成一个较大的块,直到达到一定的大小
chunksize(通过用某种函数来衡量,一般是计算长度的函数)。 - 一旦达到这个大小,就将这个大块视为一个独立的文本片段,然后开始创建一个新的文本块,并保留一些重叠部分 (chunkoverlap 以保持块与块之间的上下文联系)。
想看源码可以安装配一下环境,我用的是 python3.10
pip install -U langchain langchain-community langchain-openai tiktoken chromadb cohere
from langchain_text_splitters import RecursiveCharacterTextSplitter
langchain 推荐使用 RecursiveCharacterTextSplitter 文本分块,可以传入的参数如下
separators:分割符,默认是["\n\n", "\n", " ", ""]第一个是指空行,第二个是换行,第三个是空格(英文每个单词中间都有空格,中文不是),第四个就是按照字符了。chunk_size:窗口大小,默认4000chunk_overlap:上下文重叠大小,默认200
进入源码分析
class RecursiveCharacterTextSplitter(TextSplitter):
"""Splitting text by recursively look at characters.
Recursively tries to split by different characters to find one
that works.
"""
def __init__(
self,
separators: list[str] | None = None,
keep_separator: bool | Literal["start", "end"] = True, # noqa: FBT001,FBT002
is_separator_regex: bool = False, # noqa: FBT001,FBT002
**kwargs: Any,
) -> None:
"""Create a new TextSplitter."""
super().__init__(keep_separator=keep_separator, **kwargs)
self._separators = separators or ["\n\n", "\n", " ", ""]
self._is_separator_regex = is_separator_regex
def _split_text(self, text: str, separators: list[str]) -> list[str]:
"""最终分片的结果"""
final_chunks = []
# 先选一个分割符
separator = separators[-1]
new_separators = []
# 找合适的分割符(如果text文本里面有这个分割符,那就代表可以来分割了)
for i, s_ in enumerate(separators):
separator_ = s_ if self._is_separator_regex else re.escape(s_)
if not s_:
separator = s_
break
if re.search(separator_, text):
separator = s_
new_separators = separators[i + 1 :]
break
separator_ = separator if self._is_separator_regex else re.escape(separator)
# 分割得到分割片段(这个里面还有keep_separator,就是分割后这个分割符还保留不,还能设置是保留在上一个句子屁股,还是下一个句子开始)
splits = _split_text_with_regex(
text, separator_, keep_separator=self._keep_separator
)
# 保存小于 chunk_size 的片段
good_splits = []
separator_ = "" if self._keep_separator else separator
for s in splits:
# 如果小于代表是好的,但是有可能存在 len(good_splits[0] + good_splits[1]) < _chunk_size, 不代表最终结果
if self._length_function(s) < self._chunk_size:
good_splits.append(s)
else:
# 先去合并之前的
if good_splits:
merged_text = self._merge_splits(good_splits, separator_)
final_chunks.extend(merged_text)
good_splits = []
# 如果没有新的分割符就放弃了,大就大吧,没招了
if not new_separators:
final_chunks.append(s)
# 如果有新的分割符,对这个玩意继续分割
else:
other_info = self._split_text(s, new_separators)
final_chunks.extend(other_info)
# 再合并
if good_splits:
merged_text = self._merge_splits(good_splits, separator_)
final_chunks.extend(merged_text)
return final_chunks
def _merge_splits(self, splits: Iterable[str], separator: str) -> list[str]:
# We now want to combine these smaller pieces into medium size
# chunks to send to the LLM.
# 分割符的长度
separator_len = self._length_function(separator)
docs = []
current_doc: list[str] = []
total = 0
for d in splits:
# 当前片的长度
len_ = self._length_function(d)
# 如果加上当前片超过了 chunk_size(那肯定不加了)
if (
total + len_ + (separator_len if len(current_doc) > 0 else 0)
> self._chunk_size
):
if total > self._chunk_size:
logger.warning(
"Created a chunk of size %d, which is longer than the "
"specified %d",
total,
self._chunk_size,
)
if len(current_doc) > 0:
# 把前面的合并一下,存起来作为一个分片了
doc = self._join_docs(current_doc, separator)
if doc is not None:
docs.append(doc)
# Keep on popping if:
# - we have a larger chunk than in the chunk overlap
# - or if we still have any chunks and the length is long
# 比如原来是 [A, B, C] 长度和小于 chunk_size
# 关键地方,用来做上下文重叠的,从第一个元素开始抽,抽到剩余部分长度加和小于 overlap,比如 B+C 小于 overlap,作为下一个的开始
# 如果最后一块 C > overlap,那好了,新的就从 D 开始了,此时两个玩意就没有重叠了
# 或者说剩余部分加新的 D 超过 chunk_size 那也不行接着减
while total > self._chunk_overlap or (
total + len_ + (separator_len if len(current_doc) > 0 else 0)
> self._chunk_size
and total > 0
):
total -= self._length_function(current_doc[0]) + (
separator_len if len(current_doc) > 1 else 0
)
current_doc = current_doc[1:]
# 没超过 chunk_size 的长度就往里加
current_doc.append(d)
total += len_ + (separator_len if len(current_doc) > 1 else 0)
doc = self._join_docs(current_doc, separator)
if doc is not None:
docs.append(doc)
return docs
源码好好记住,后面感觉很多东西都得靠这个理解的,比如 chunk_size 和 overlap 大小设置很关键,分割符决定了分的细不细,也影响分片之间会不会有重叠。如果分割符很宽泛,\n\n,那分割完,如果每个都不是 good_splits 了,那就不会经过 _merge_splits(),那就不会有重叠了。
如果分割符很宽泛,分割完每隔块都很大,并且没有再小的分割符了,那 chunksize 很鸡肋了。因为代码来看,超过了 chunksize 是需要更细的分割符去分割的。
这个应该很重要!!!好好记住
但是这里 " " 是适合英文的,中文的应该怎么搞?
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = chunk_size,
chunk_overlap = chunk_overlap, # 这俩根据实际情况
separators = ["\n\n", "\n", "。", ""], # 换为 。
keep_separator = "end", # 分割符放在最后,比如 。
is_separator_regex = True, # 默认关闭正则型的分割符
)
这里分割符、chunk_size、chunk_overlap 之类的都根据实际情况,根据文档内容选择合适的,不是固定的哦
如何选取 RAG 中的 embedding 模型
了解 RAG 中的 Embedding Vectors
- 什么是 embedding
- Sentence BERT
- 如何选取 embedding model
什么是 embedding
考虑一下如何表示“男人”,“女人”,我们可以从性别上出发,假设男性性别可以表示为“1”,女性性别可以表示为“9”,即可将“男人”,“女人”区分开来。
那么当加入“男孩”,“女孩”的时候,单纯靠性别已经无法完全区分上述四个单词,此时可以引入年龄,“男人”: [1, 35], “女人”: [9, 35], “男孩”: [1, 10], “女孩”: [9, 10]
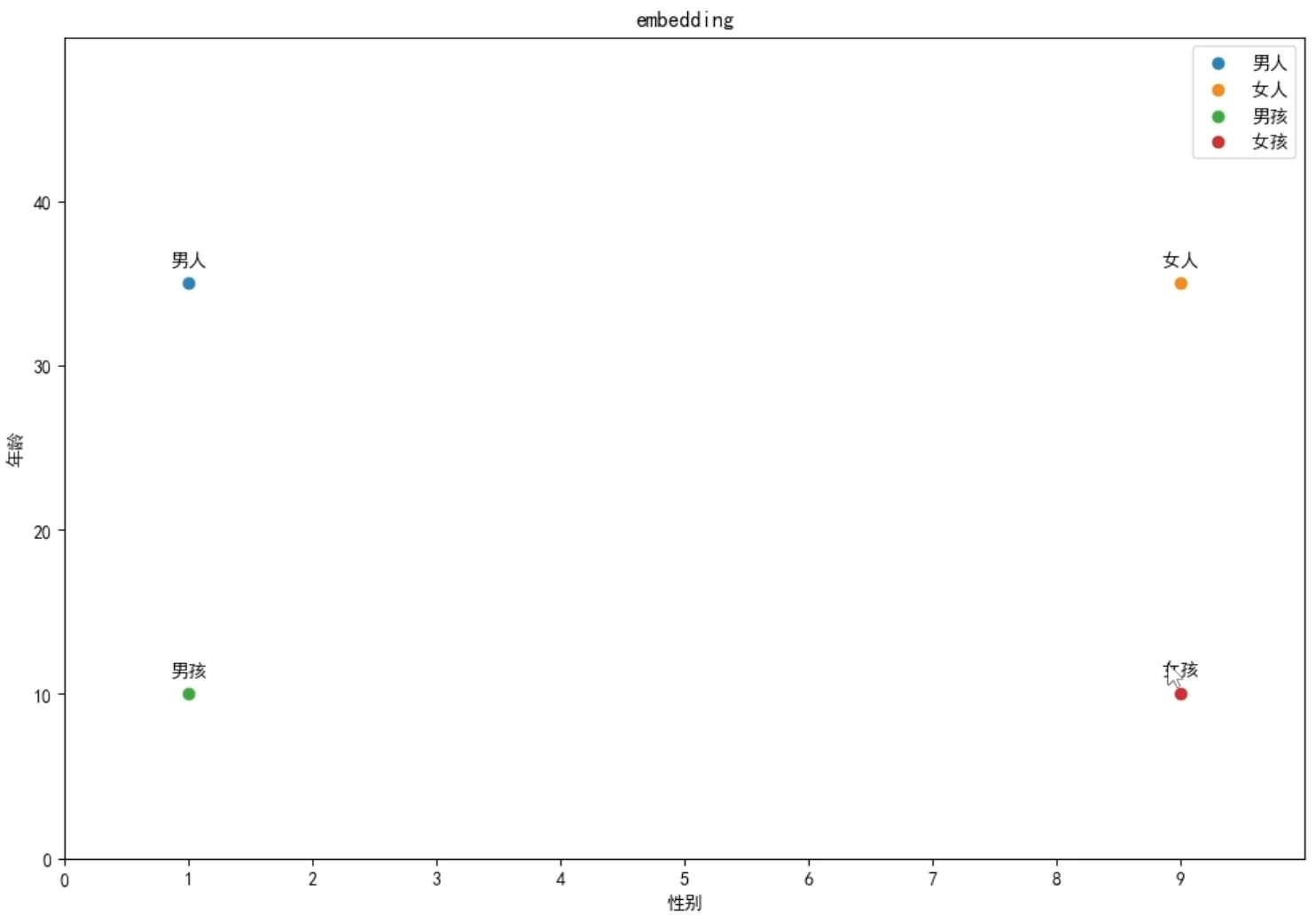
比如上面不仅表示了词,还表示了词之间的距离信息,越近词的含义也越接近
随着词汇的逐渐增加,二维已经不足以区分单词,例如引入新的单词 “国王” ,“皇后”,只靠年龄和性别,已经无法区分国王 —— 男人 , 皇后———女人
所以我们引入新的特征,例如’皇室的’ ,则 “男人”: [1, 35, 1], “女人”: [9, 35, 1],“男孩”: [1, 10, 1],“女孩”: [9, 10, 1],“国王”: [1, 35, 9],“皇后”: [9, 35, 9]
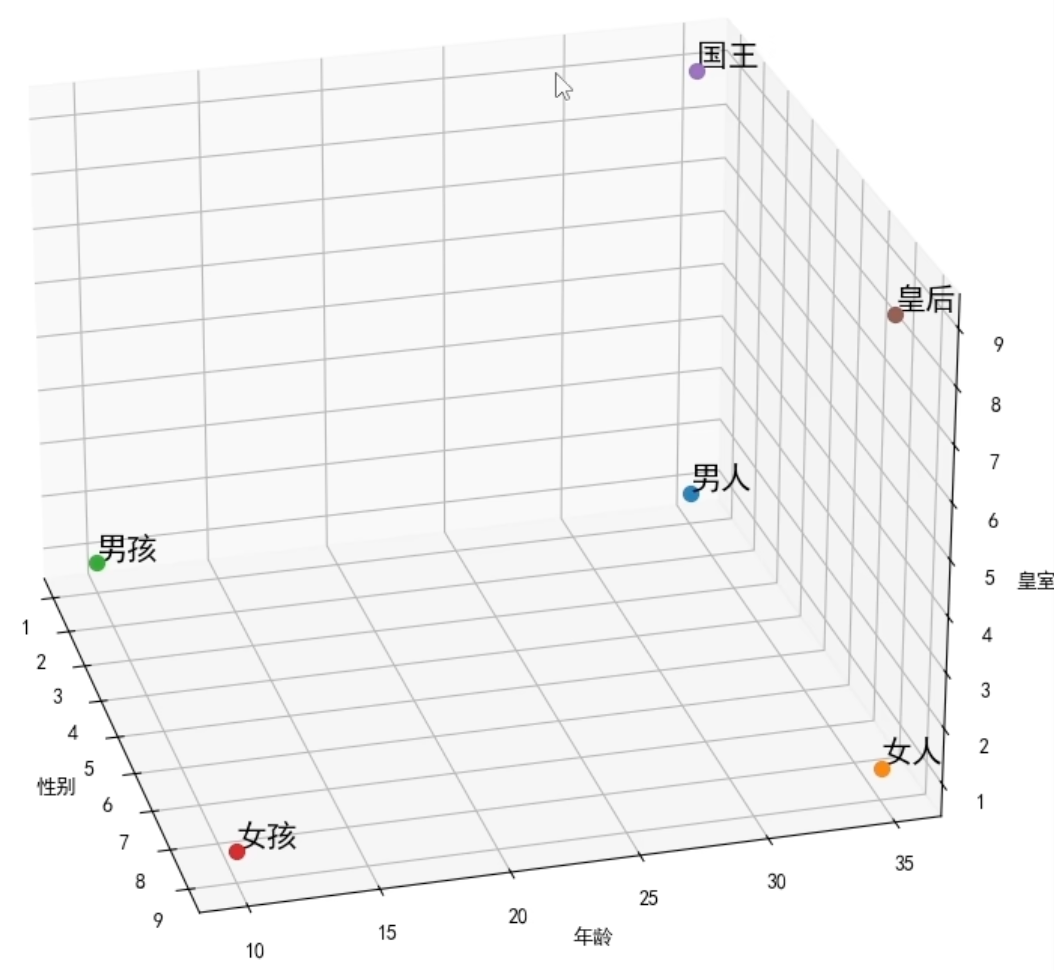
同样,如果词汇再增加,我们可以用更高维度的,比如 BERT-Base 模型就是 768 维,BERT-Large 就是 1024 维,维度并不是越大越好,根据你的数据库来判断。越大向量空间越稀疏,几乎所有点之间的距离都变得差不多了,就是区分度了,并且维度增加也有边际效用,准确率提升很小,反而会付出更多的存储和计算代价。
句子 sentence 的 embedding 计算大致如下
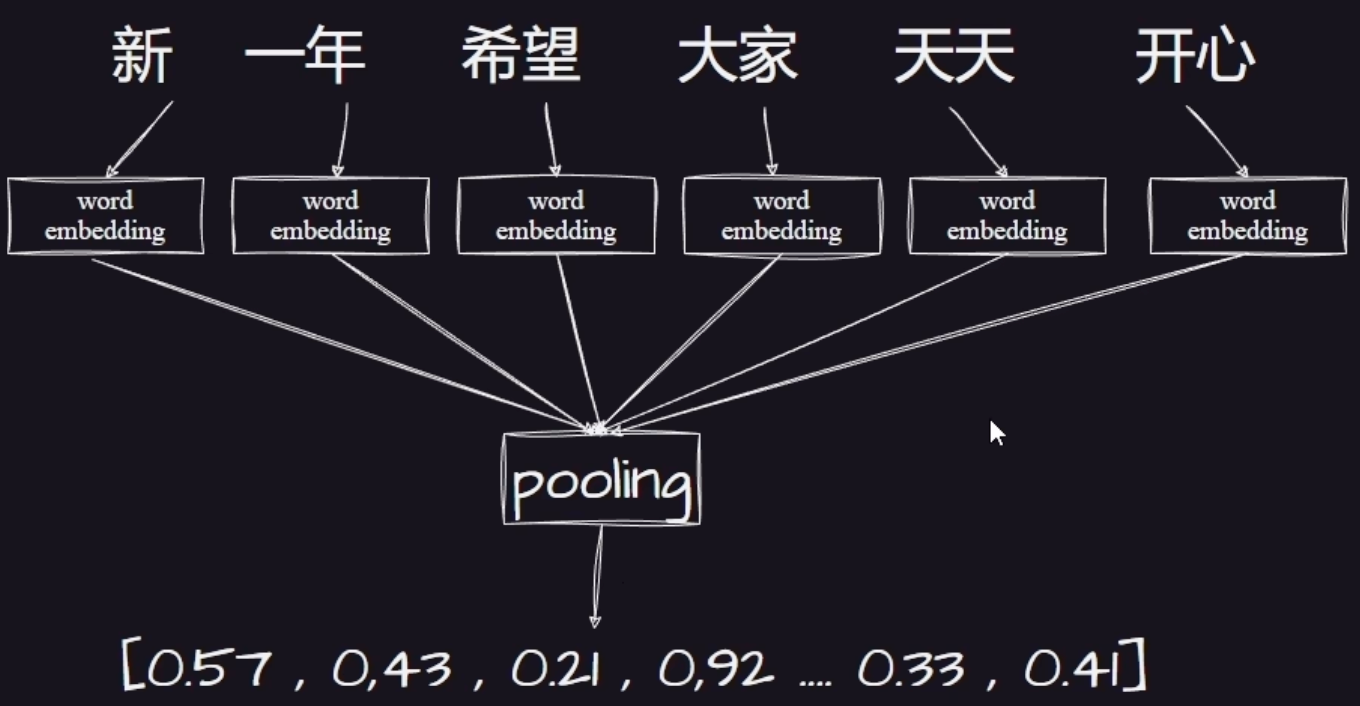
先分词,然后每个词计算一个 embedding,最后做一个池化。RAG是怎么做的呢?
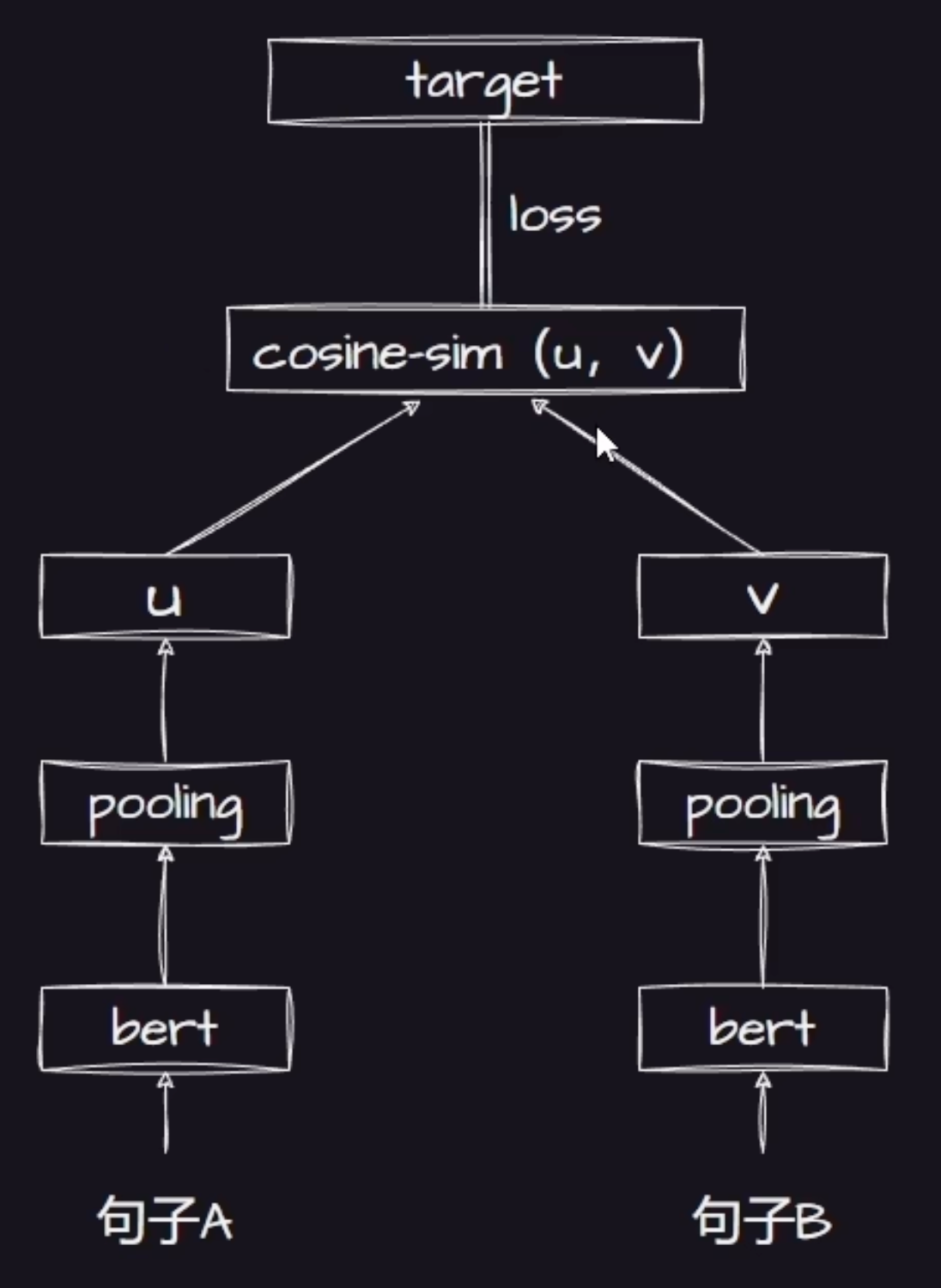
这个图片展示的是 Sentence-BERT 的典型架构,解决原生BERT在计算句子相似度时速度太慢的问题。
准备两个文本,两个句子分别进入同一个 BERT 模型(是同一份权重),然后把句子里的词都转换为对应的向量,比如这里有10个768维的词向量。然后在池化这一层,就会把一堆词向量转为一个句向量,比如 n 个768维的词转为 1 个768维的向量。这个池化有很多种,比如平均池化(10个值取平均值作为结果) 、最大池化(取最大值),这里一般是平均池化(效果最好)。然后进行相似度计算,得到一个 0~1 的值,1 代表完全一样,0代表毫不相干。target 是真实标签,比如人工标注相似度为 0.9。模型就会计算预测值和真实值之间的差距 loss,然后回头训练 BERT 的参数,直到模型准确的判断出语义相似度。
{% note info %}
余弦相似度和池化都是数学公式,固定的,没有参数训练,所以训练的是BERT的参数。
{% endnote %}
embedding 模型选取
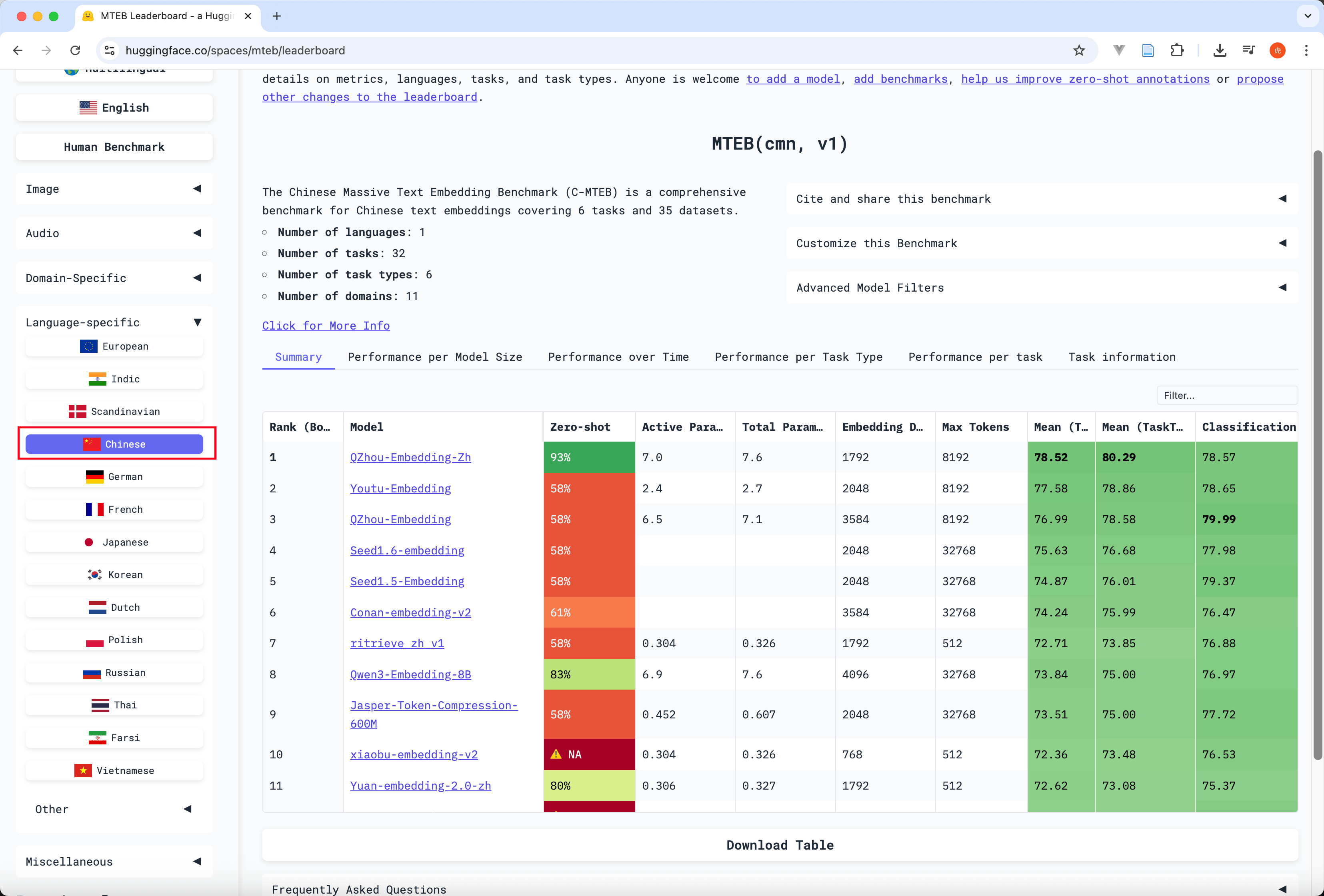
我们可以去 https://huggingface.co/spaces/mteb/leaderboard 实时查看不同 embedding 模型的排名(选择中文的),可以看到是多少维的,支持的最大 token 长度,类似句子长度(但是中文还不是一个汉子一个 token,从这里我们可以知道 chunk_size 是不能超过这个的,通常 chunk_size 要比这个小的多)。
我们可以选取第一个模型看一下它的一些信息,比如看一下用的什么池化
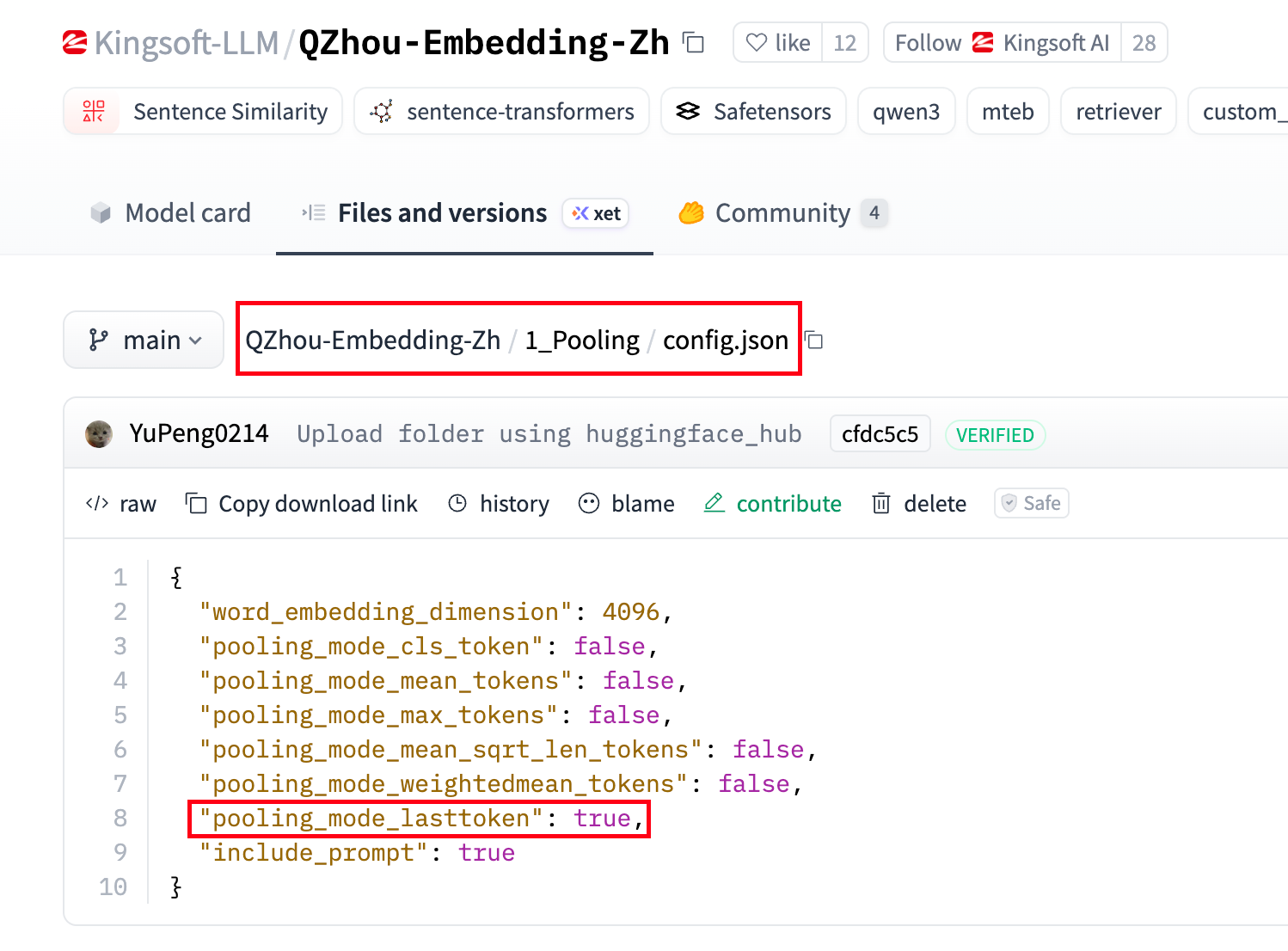
{% note info %}
这个 pooling_mode_lasttoken 含义是用最后一个 token 作为输出向量。其实原因是因为现在的生成式模型都用的单向注意力,每个词都只能看到它最左边的词,这意味着最后一个词把前面的词都读过了。
{% endnote %}
要是用的话我们安装 sentence-transformers 软件包
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('Kingsoft-LLM/QZhou-Embedding-Zh') # 想用别的模型只要换这个名字就行,这个名字你观察上面那个图最上方就知道了
第一次使用都会自动去下载(这个10几G,别下上面这个)
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('moka-ai/m3e-base')
#Our sentences we like to encode
sentences =['为什么良好的睡眠对健康至关重要?' ,
'良好的睡眠有助于身体修复自身,增强免疫系统',
'在监督学习中,算法经常需要大量的标记数据来进行有效学习',
'睡眠不足可能导致长期健康问题,如心脏病和糖尿病',
'这种学习方法依赖于数据质量和数量',
'它帮助维持正常的新陈代谢和体重控制',
'睡眠对儿童和青少年的大脑发育和成长尤为重要',
'良好的睡眠有助于提高日间的工作效率和注意力',
'监督学习的成功取决于特征选择和算法的选择',
'量子计算机的发展仍处于早期阶段,面临技术和物理挑战',
'量子计算机与传统计算机不同,后者使用二进制位进行计算',
'机器学习使我睡不着觉',
]
#Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences) # 把这几个编码为向量
具体用法还要去官方文档看,不同模型不太一样
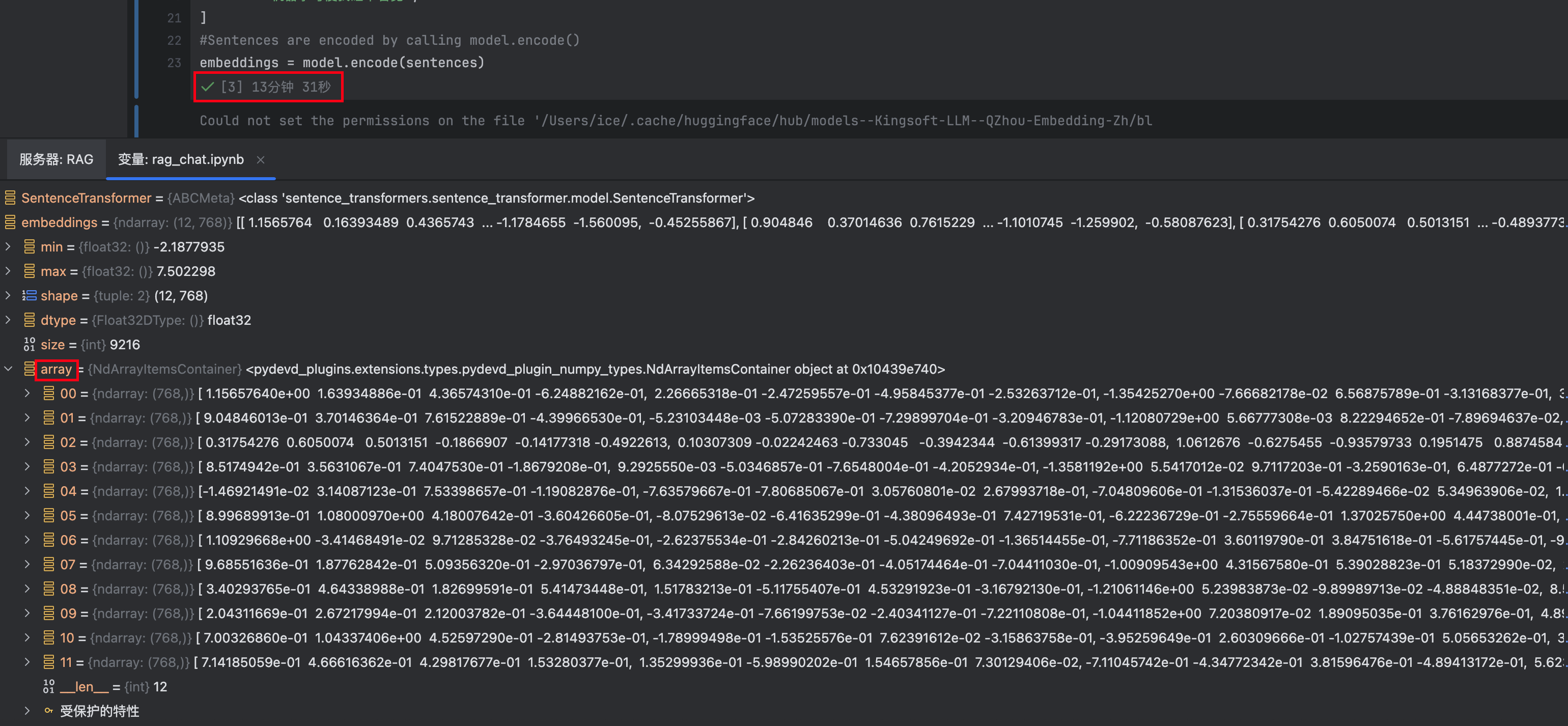
在 mac 上只用CPU跑,大概得 13 分钟了,可以看到 array 存的向量结果
{% note red ‘fas fa-question-circle’ simple %}
如何选择合适的embedding?
- 看
Max Tokens,如果你的chunk_size都大于 512 了,那么这里就不能选小于512都了。 - 看
Embedding Dimensions,如果我们的数据库语义分成丰富,那维度越大越好,如果语义比较精,聚焦于某个方面,那小一点比较好。 Model Size,看个人电脑的显存取决。- 可以初步用一个模型跑一下,拿一部分数据就像上面代码一样
encode一下,可视化看看效果如何,但也只是简单参考。(可以用sklearn.manifold里面的TSNE)
{% endnote %}
可视化如下
from sklearn.manifold import TSNE
import numpy as np
tsne = TSNE(n_components=2 , perplexity=5)
embeddings_2d = tsne.fit_transform(embeddings)
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # mac 上的字体
plt.rcParams['axes.unicode_minus'] = False
color_list = ['black'] * len(embeddings_2d[1:])
color_list.insert(0, 'red')
plt.scatter(embeddings_2d[:, 0], embeddings_2d[:, 1] , color=color_list )
for i in range(len(embeddings_2d)):
plt.text(embeddings_2d[:,0][i], embeddings_2d[:,1][i]+2, sentences[i] ,color=color_list[i] )
# 显示图表
plt.show()

基于 Huggingface + Langchain 快速实现RAG
Huggingface
Huggingface提供了两种方式调用LLM
- 通过Api token 的方式
- 本地加载
安装环境
pip install langchain langchain-huggingface langchain-text-splitters sentence-transformers
使用 API token 调用 LLM
生成 token
去 Huggingface 官网,搞一个token
生成 key 的时候注意,得把 make calls to Inference Providers 勾选上

我们详细解释一下,因为版本变更无论包名还是啥变化太大了
原生调用Huggingface
我们先说最原生的写法,python 怎么接到 huggingface 调用模型 Chat Completion
InferenceClient 是 Hugging Face 官方提供的“统一调用模型”的客户端。它就是一个 Python 用来向 Hugging Face 的模型服务发请求,然后拿回结果。它能连到 Hugging Face 的 Inference Providers,也能连你自己的 Inference Endpoint,甚至还能连本地兼容 OpenAI 接口的服务。
pip install huggingface_hub
from huggingface_hub import InferenceClient
client = InferenceClient(
api_key="hf_xxx"
)
completion = client.chat.completions.create( # chat.completions 指聊天窗口
model="meta-llama/Llama-3.1-8B-Instruct:scaleway",
messages=[
{
"role": "system",
"content": "Answer in plain text only. Do not call tools or functions."
},
{
"role": "user",
"content": "What is the capital of China?"
}
]
)
print(completion.choices[0].message.content)
但是,并不是所有的模型都支持调用的,只有 Inference Available 的才可以
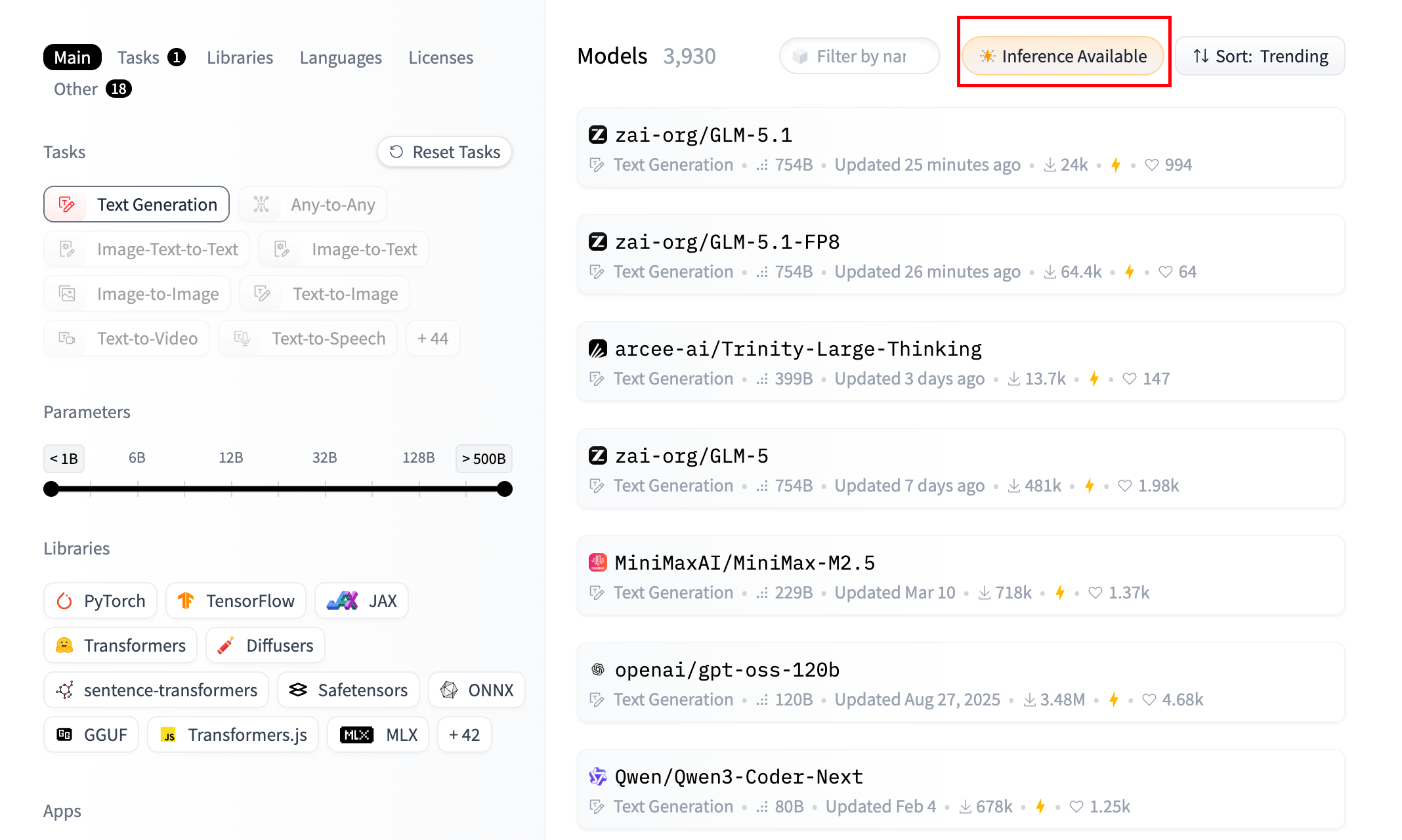
这个你发现直接就能访问成功,其实是因为有些提供算力的合作方,自己出钱把某些模型部署上,是大家共享的一个模型服务,然后你可以有额度的免费访问一点,之后就得收费了。HuggingFace 是存放这些模型,但是没部署,它在中间帮你做个统一API来访问。
Inference Endpoints 是 HuggingFace 自己的(有金主,自己也有点能力),你想部署一个你自己的模型服务,你花钱它来做(按分钟收费),你也不用搭环境,还能稳定在线,看日志、监控啥的都可以,你只需要调用就可以了
HuggingFace + LangChain
HuggingFace 是模型和推理服务平台,LangChain 是把模型做成应用的框架,负责把模型接到提示词、检索、工具、记忆、工作流、Agent里。所以调模型也是它的一部分。
pip install langchain langchain-huggingface langchain-text-splitters sentence-transformers
import os
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
from langchain_core.prompts import ChatPromptTemplate
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "hf_xxx"
llm = HuggingFaceEndpoint(
repo_id="meta-llama/Llama-3.1-8B-Instruct",
task="text-generation",
provider="auto",
max_new_tokens=128,
do_sample=False,
) # 把HuggingFace的远程推理适配到LangChain的LLM接口,相当于一个适配器
chat = ChatHuggingFace(llm=llm) # 把LLM包装成聊天模型
prompt = ChatPromptTemplate.from_messages([ # Prompt 模版
("system", "You are a helpful assistant."),
("human", "{question}")
])
chain = prompt | chat # chat 是聊天模型,所以提示也是聊天消息,所以用 ChatPromptTemplate
resp = chain.invoke({"question": "What is the capital of China?"})
print(resp.content)
当用 ChatHuggingFace + ChatPromptTemplate 时代表你把 LLM 包装成了一个聊天模型,也可以不用这个,直接用 LLM,如下
import os
from langchain_huggingface import HuggingFaceEndpoint
from langchain_core.prompts import PromptTemplate
os.environ["HUGGINGFACEHUB_API_TOKEN"] = "hf_xxx"
llm = HuggingFaceEndpoint(
repo_id="meta-llama/Llama-3.1-8B-Instruct",
task="text-generation",
provider="auto",
max_new_tokens=128,
do_sample=False,
)
prompt = PromptTemplate.from_template(
"Answer in plain text only.\nQuestion: {question}\nAnswer:"
)
chain = prompt | llm # llm 是普通LLM接口,前面要给它的是普通字符串 prompt,直接用 PromptTemplate 更合适
resp = chain.invoke({"question": "What is the capital of China?"})
print(resp)
算是直接调用的 LangChain 里面的 LLM 接口,第一个是先把 LLM 包装成聊天模型再调用。
很崩溃的是,其实后者这个会报错,报错原因是
Model meta-llama/Llama-3.1-8B-Instruct is not supported for task text-generation and provider novita. Supported task: conversational.我已经乱了,我看说是虽然这个任务是text-generation,也就是模型能力支持这个,但是其实没有provider支持这种,所以你用不了,但是ChatHuggingFace就可以,因为它封装了,,,没明白,所以支持第一种就完了。
{% note info %}
你可能好奇,这个 HuggingFaceEndpoint 怎么搞的,这和原生写法里面提到的概念好冲突,其实这个 HuggingFaceEndpoint 支持 Inference Provider 和 Inference Endpoint 两种
provider="auto",因为提供这个模型的 provider 可能不止一个,所以auto让 huggingface 自己找一个,repo_id指定模型,其实这两个参数配合就知道你是在用Provider模式endpoint_url="https://xxx.endpoints.huggingface.cloud",用这个不用上面那两个,就代表你在用Endpoint
{% endnote %}
{% note warning %}
LangChain 还是专门做文本生成和对话这一类的,所以如果你想做什么图片生成之类的,这个模版不适用,需要用原生调用HuggingFace去。
{% endnote %}
哎哎哎,有没有发现,前面叽里呱啦说的全是调用远程 Hugging Face 推理服务的,我如果本地有模型怎么搞???HuggingFacePipeline
第一种,直接当普通LLM用
from langchain_huggingface import HuggingFacePipeline
from langchain_core.prompts import PromptTemplate
llm = HuggingFacePipeline.from_model_id(
model_id="LiquidAI/LFM2.5-350M",
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 50,
"do_sample": False,
},
)
prompt = PromptTemplate.from_template(
"Question: {question}\nAnswer:"
)
chain = prompt | llm
resp = chain.invoke({"question": "What is the capital of China?"})
print(resp)
第一次会自动去下载模型,第二次就加载使用了
第二种,当聊天模型使用
import os
from langchain_huggingface import HuggingFacePipeline, ChatHuggingFace
from langchain_core.prompts import ChatPromptTemplate
os.environ["HF_XET_HIGH_PERFORMANCE"] = "1" # 开启高性能模型,尽可能吃满网络和CPU,下载快
llm = HuggingFacePipeline.from_model_id(
model_id="meta-llama/Llama-3.1-8B-Instruct",
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 50,
"do_sample": False,
},
)
chat = ChatHuggingFace(llm=llm)
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant."),
("human", "{question}")
])
chain = prompt | chat
resp = chain.invoke({"question": "What is the capital of China?"})
print(resp.content)
有些模型如果你要下载,可能需要通过申请
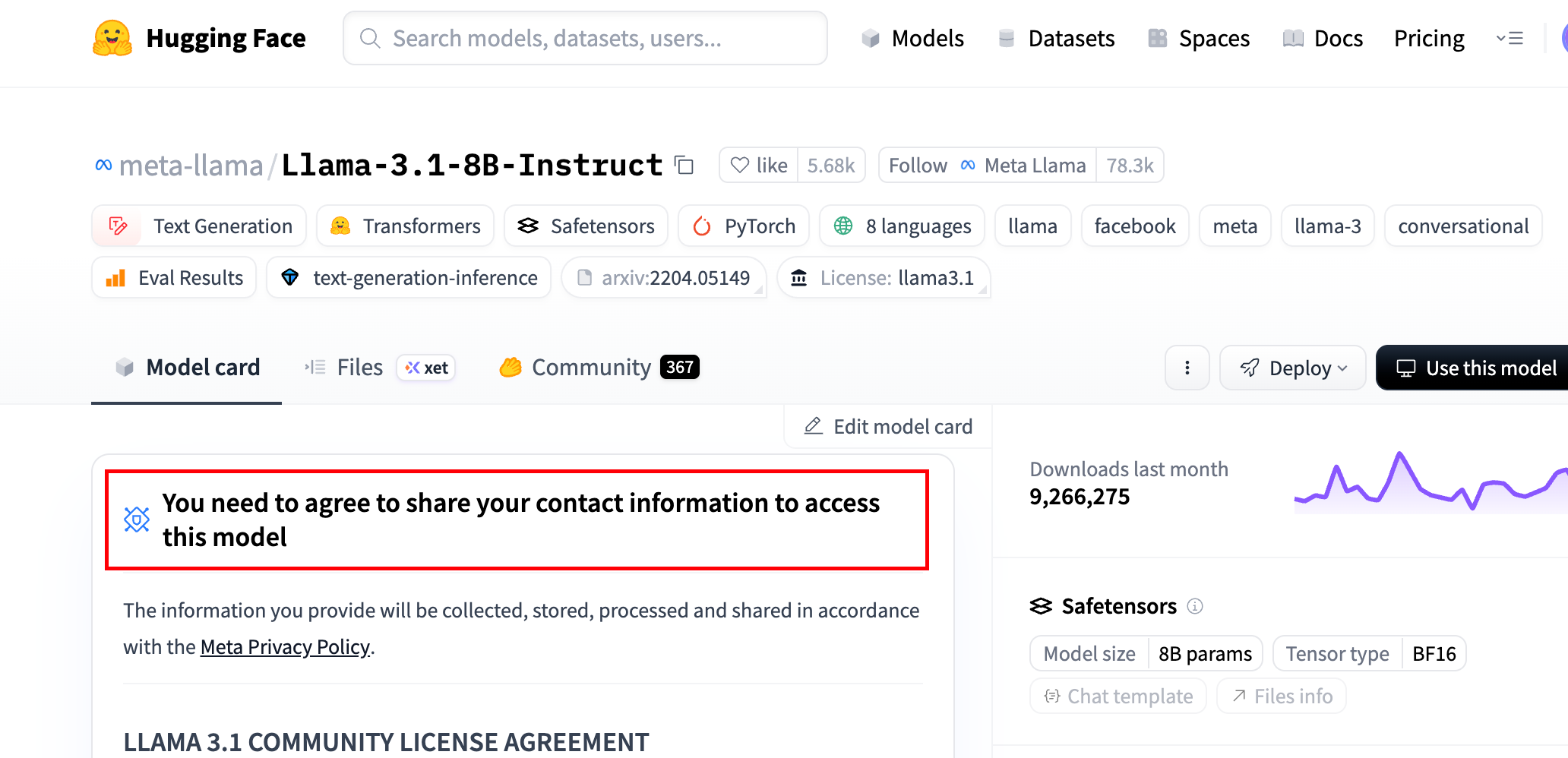
比如上面这个,需要通过申请才能下载,申请后还得审批,,,
我找了个小的,不用申请的 LiquidAI/LFM2.5-350M,需要自己一个一个点主页去看。下载很慢,,,
构建 RAG 检索
我们讲一下怎么把 RAG 检索应用到 LangChain 里面
pip install pypdf faiss-cpu langchain-huggingface sentence-transformers
对文本进行切分
from langchain_community.document_loaders import PyPDFLoader
###加载文件
loader = PyPDFLoader("https://arxiv.org/pdf/2309.10305.pdf")
pages = loader.load()
from langchain_text_splitters import RecursiveCharacterTextSplitter
###文本切分
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 300,chunk_overlap = 50,)
docs = text_splitter.split_documents(pages[:4]) # 只取了前四页,不然太多
对切分后的词进行向量嵌入,然后根据问题查询相似度最高的 3 个
from langchain_huggingface import HuggingFaceEmbeddings # 替代 from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
embeddings = HuggingFaceEmbeddings(
model_name="moka-ai/m3e-base"
)
db = FAISS.from_documents(docs, embeddings)
query = "How large is the baichuan2 vocabulary size?"
result_simi = db.similarity_search(query , k = 3)
然后对查询到的三个结果做一个拼接
source_knowledge = "\n".join([x.page_content for x in result_simi])
然后就是调用聊天模型了,我们采用本地模型,ChatHuggingFace 的方式吧
from langchain_huggingface import ChatHuggingFace
from langchain_core.prompts import ChatPromptTemplate
llm = HuggingFacePipeline.from_model_id(
model_id="LiquidAI/LFM2.5-350M",
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 50,
"do_sample": False,
},
)
chat = ChatHuggingFace(llm=llm)
augmented_prompt = [
("system", "You are a helpful assistant. Answer the user's question only using the provided contexts."),
("human", """Using the contexts below, answer the query.
contexts:
{source_knowledge}
query: {query}""")
]
prompt = PromptTemplate.from_messages(augmented_prompt)
chain = prompt | chat
resp = chain.invoke({
"source_knowledge": source_knowledge,
"query": query
})
print(resp.content)
{% note info %}
也可以通过 ModelScope 魔塔进行下载,和 HuggingFace 把模型下载到本地的方法就差距很多了
国内用 ModelScope 还是更方便
下载就不单独介绍了,前面你考虑一下,咱们用的是 HuggingFacePipeline 实际上是自动帮咱们下载的,自动下载的是放到一个默认的文件夹下面的,不是咱们手动下载模型、指定位置并且手动加载使用的。
{% endnote %}
RAG系统存在的缺陷
开发RAG系统面临的12个问题
缺失内容(Missing Content)
当用户的问题无法从文档库中检索到时,可能会导致大模型的幻觉现象。理想情况下,RAG 系统可以简单地回复一句 “抱歉,我不知道”,然而,如果用户问题能检索到文档,但是文档内容和用户问题无关时,大模型还是可能会被误导。
Clean your data & Better prompting
错过超出排名范围的文档(Missed Top Ranked)
由于大模型的上下文长度限制,我们从文档库中检索时,一般只返回排名靠前的 K 个段落,如果问题答案所在的段落超出了排名范围,就会出现问题。
Hyperparameter tuning & Reranking
- 调 top-k
- 调 chunk size / overlap
- 调相似度检索参数
- 加 reranker 提升真正相关内容的排名
不在上下文中(Not In Context)
包含答案的文档已经成功检索出来,但却没有包含在大模型所使用的上下文中。当从数据库中检索到多个文档,并且使用合并过程提取答案时,就会出现这种情况。
Tweak retrieval strategies & Finetune embeddings
- 改检索策略
- 优化 embedding
未能提取 (Note Extracted)
答案在提供的上下文中,但是大模型未能准确地提取出来,这通常发生在上下文中存在过多的噪音或冲突信息时。
Clean your data, prompt compression, & LongContextReorder
错误的格式(Wrong Format)
问题要求以特定格式提取信息,例如表格或列表,然而大模型忽略了这个指示。
Better prompting, output parsing, pydantic programs, & OpenAI JSON mode
- 明确格式要求
- 用结构化解析
- 用 schema 约束
- 尽量让输出可控
不正确的具体性(Incorrect Specificity)
尽管大模型正常回答了用户的提问,但不够具体或者过于具体,都不能满足用户的需求。不正确的具体性也可能发生在用户不确定如何提问,或提问过于笼统时。
Advanced retrieval strategies(高级检索策略)
不完整的回答(Incomplete Answers)
考虑一个问题,“文件 A、B、C 包含哪些关键点?”,直接使用这个问题检索得到的可能只是每个文件的部分信息,导致大模型的回答不完整。一个更有效的方法是分别针对每个文件提出这些问题,以确保全面覆盖。
Query transformations
数据摄入的可扩展性问题(Data Ingestion Scalability)
当数据规模增大时,系统可能会面临如数据摄入时间过长、系统过载、数据质量下降以及可用性受限等问题,这可能导致性能瓶颈甚至系统故障。
Parallelizing ingestion pipeline
就是并行化入库流程,提高吞吐。
结构化数据的问答(Structured Data QA)
根据用户的问题准确检索出所需的结构化数据是一项挑战,尤其是当用户的问题比较复杂或比较模糊时。这是由于文本到 SQL 的转换不够灵活,当前大模型在处理这类任务上仍然存在一定的局限性。
Chain-of-table pack & Mix-self-consistency pack
工具
复杂的PDF(Complex PDFs)
复杂的 PDF 文档中可能包含有表格、图片等嵌入内容,在对这种文档进行问答时,传统的检索方法往往无法达到很好的效果。我们需要一个更高效的方法来处理这种复杂的 PDF 数据提取需求。
Embedded table retrieval
备用模型(Fallback Model(s))
在使用单一大模型时,我们可能会担心模型遇到问题,比如遇到 OpenAI 模型的访问频率限制错误。这时候,我们需要一个或多个模型作为备用,以防主模型出现故障。
Neutrino router & OpenRouter
大语言模型的安全性(LLM Security)
如何有效地防止恶意输入、确保输出安全、保护敏感信息不被泄露等问题,都是我们需要面对的重要挑战。
NeMo Guardrails & Llama Guard
在 Glantz 的博客 中,他不仅整理了这些问题,而且还对每个问题给出了对应的解决方案,整个 RAG 系统的蓝图如下: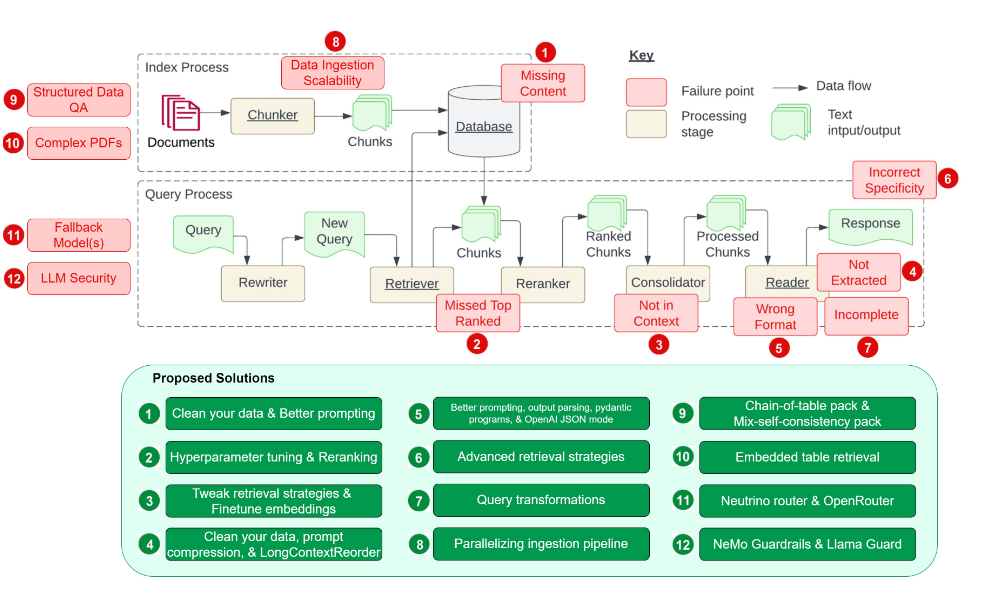
优化手段
多查询检索器
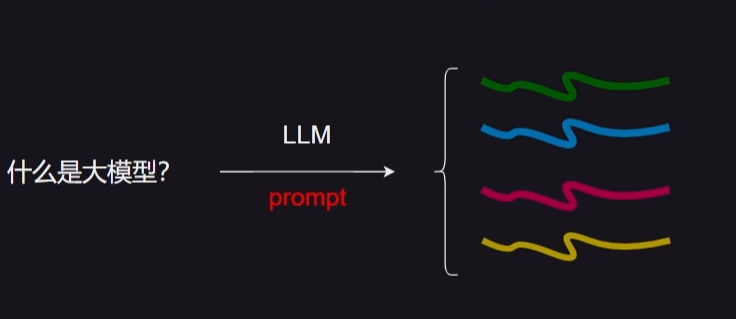
自动化提示调优:MultiQueryRetriever 通过使用大型语言模型 (LLM) 自动化。它根据给定的用户输入查询,生成多个从不同视角出发的查询。
检索并合并结果:对于每个生成的查询,系统检索一组相关文档,并对所有查询的结果进行合并,取它们的独特并集。这样做可以获得一个更大、可能更相关的文档集合。
克服限制,丰富结果:通过从同一个问题的多个视角生成查询,MultiQueryRetriever 可能能够克服基于距离的检索的某些限制,并获得更丰富的结果集。
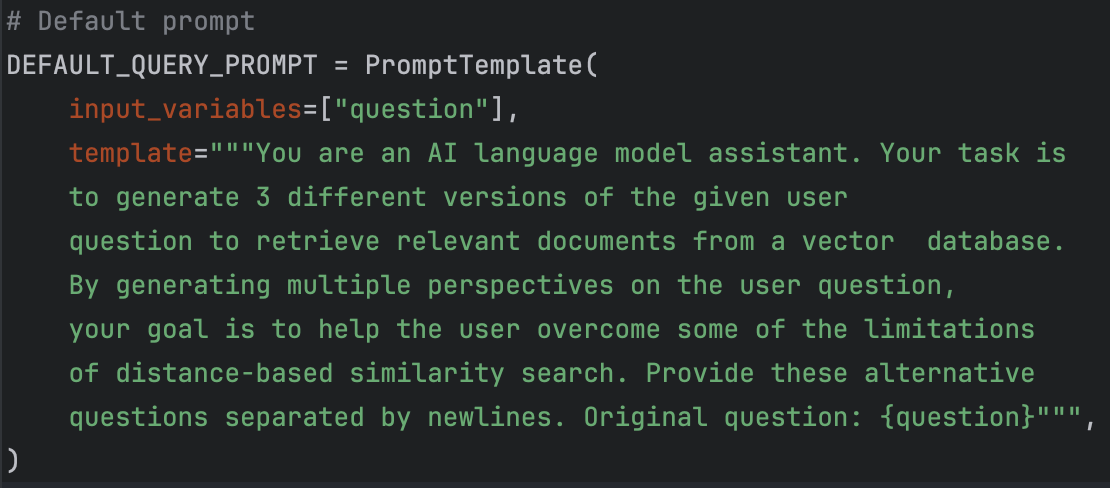
我们可以具体看一下代码流程(作者演示用的OpenAI的,但是这个收费,就不用了哈)
{% tabs MultiQueryRetriever ,1 %}
分片
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma # 换了一种向量库
# Load pdf
loader = PyPDFLoader("https://arxiv.org/pdf/2309.10305.pdf")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data[:6])
放入向量数据库
import os
from getpass import getpass
HUGGINGFACEHUB_API_TOKEN = getpass()
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HUGGINGFACEHUB_API_TOKEN
# VectorDB
embedding = HuggingFaceEmbeddings(
model_name="moka-ai/m3e-base"
)
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
# Set logging for the queries
import logging
logging.basicConfig()
logging.getLogger("langchain_classic.retrievers.multi_query").setLevel(logging.INFO)
from langchain_classic.retrievers.multi_query import MultiQueryRetriever
from langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFace
question = "what is baichuan2 ?"
llm = HuggingFaceEndpoint(
repo_id="meta-llama/Llama-3.1-8B-Instruct",
task="text-generation",
provider="auto",
max_new_tokens=128,
do_sample=False,
)
chat = ChatHuggingFace(llm=llm)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=chat
)
docs = retriever_from_llm.invoke(question)
len(docs) # 10
docs
生成的日志如下,三个不同的问题
INFO:langchain_classic.retrievers.multi_query:Generated queries:
['To overcome some limitations of distance-based similarity search, we can generate alternative versions of the user question to retrieve relevant documents from a vector database. Here are three different versions of the given question:',
'What is the context or topic associated with "baichuan2"?',
'What are the key characteristics or features of "baichuan2" that make it unique?',
'What documents or pieces of information are related to or mention "baichuan2" in any context?'
]
为什么是三个?可以看 MultiQueryRetriever.from_llm 的 prompt 参数的默认值。里面就写了要从3个不同角度去分析问题,所以你可以自己写 prompt 传入进去。
但是实际上不可能要三个回答结果,我们需要把上面的回答链接起来生成一个回答
from langchain_core.prompts import PromptTemplate
template = """基于以下提供的内容回答问题,如果内容中不包含问题的答案,请回答“我不知道”
内容:
{contexts}
问题: {query}
"""
mulitquery_PROMPT = PromptTemplate(input_variables=["query", "contexts"], template=template,)
# Chain
qa_chain = mulitquery_PROMPT | chat
out = qa_chain.invoke({"query": question,
"contexts": "\n---\n".join([d.page_content for d in docs])
})
print(out.content)
最终结果如下
Baichuan 2 is a large language model that has been developed to achieve comprehensive data scalability and representativeness. It is a foundation model that can be used for a wide range of natural language tasks, and it has been fine-tuned to align with human preferences. Baichuan 2 is available for both research and commercial use, and its models and pre-training data have been open-sourced to benefit the research community.
{% endtabs %}
上下文压缩
**上下文压缩:**不要立即按原样返回检索到的文档,而是可以使用给定查询的上下文对其进行压缩,以便仅返回相关信息。这里的“压缩”既指对单个文档内容进行压缩,也指整体上滤除文档。
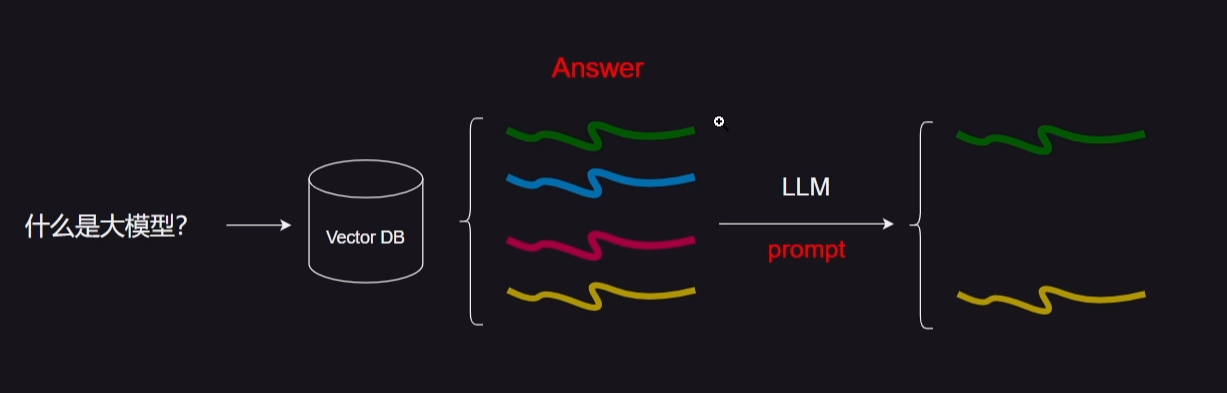
代码如下
{% tabs 上下文压缩 , 1 %}
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_classic.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# Load pdf
loader = PyPDFLoader("https://arxiv.org/pdf/2309.10305v2.pdf")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data[:6])
import os
from getpass import getpass
HUGGINGFACEHUB_API_TOKEN = getpass()
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HUGGINGFACEHUB_API_TOKEN
# VectorDB
embedding = HuggingFaceEmbeddings(
model_name="moka-ai/m3e-base"
)
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
retriever = vectordb.as_retriever()
vectordb.as_retriever()把向量库包装成一个检索器,变成一个查相关内容的对象
base_docs = retriever.invoke(
"What is baichuan2 ?"
)
base_docs
找出这个问题最相关的片段,返回结果是一个 Document 对象列表
每个对象大概信息是
doc.page_content: 文本内容doc.metadata: 来源信息,比如页码、文件名
Document(
metadata={
'source': 'https://arxiv.org/pdf/2309.10305v2.pdf',
'keywords': '',
'moddate': '2023-09-21T00:15:31+00:00',
'producer': 'pdfTeX-1.40.25',
'creationdate': '2023-09-21T00:15:31+00:00',
'creator': 'LaTeX with hyperref',
'ptex.fullbanner': 'This is pdfTeX, Version 3.141592653-2.6-1.40.25 (TeX Live 2023) kpathsea version 6.3.5',
'trapped': '/False',
'subject': '',
'total_pages': 28,
'page': 1,
'title': '',
'author': '',
'page_label': '2'
},
page_content='Baichuan 1. On general benchmarks like MMLU\n(Hendrycks et al., 2021a), CMMLU (Li et al.,\n2023), and C-Eval (Huang et al., 2023), Baichuan\n2-7B achieves nearly 30% higher performance\ncompared to Baichuan 1-7B. Specifically, Baichuan\n2 is optimized to improve performance on math\nand code problems. On the GSM8K (Cobbe\net al., 2021) and HumanEval (Chen et al., 2021)\nevaluations, Baichuan 2 nearly doubles the results\nof the Baichuan 1. In addition, Baichuan 2 also'
)
from langchain_classic.retrievers import ContextualCompressionRetriever
from langchain_classic.retrievers.document_compressors import LLMChainExtractor
from langchain_huggingface import HuggingFacePipeline, ChatHuggingFace
llm = HuggingFacePipeline.from_model_id(
model_id="LiquidAI/LFM2.5-350M",
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 128,
"do_sample": False,
"return_full_text": False,
}
)
chat = ChatHuggingFace(llm=llm)
compressor = LLMChainExtractor.from_llm(chat) # 用哪个 LLM 来做压缩
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What is baichuan2 ?"
)
compressed_docs
这里面流程是,compression_retriever.invoke(...) 是把问题给 retriever,让他检索相关的内容,然后用 chat 这个LLM来做上下文提取,LLMChainExtractor 作用是对初始检索到的每个文档,只抽取和当前问题相关的片段,而不是把整段都原样返回。
我们依旧从 LLMChainExtractor.from_llm() 里面看 prompt 源码

其实你发现了,其实只是用 LLM 给点 prompt,然后让他们来帮我们实现一些功能,结果如下

其实提取的过于狠毒了,是因为我们这个LLM很弱(大的下载太慢)
注意哈,这个1,2以及后面的3都是在 前期准备+查询向量库 之后做的,这三个都是在上面这些基础上实现的不同功能
from langchain_classic.retrievers.document_compressors import LLMChainFilter
_filter = LLMChainFilter.from_llm(chat)
compression_retriever = ContextualCompressionRetriever(
base_compressor=_filter, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What is baichuan2 ?"
)
compressed_docs
它的作用是 LLM 来过滤,让 LLM 判断,这些内容和问题是否有关,过滤掉无关的。
我们来看看 prompt

from langchain_classic.retrievers.document_compressors import EmbeddingsFilter
# 做相似度过滤, 如果和问题关联的阈值小于0.76就过滤掉,从向量库的角度上过滤,没借助LLM
embeddings_filter = EmbeddingsFilter(embeddings=embedding, similarity_threshold=0.76)
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What is baichuan2 ?"
)
{% endtabs %}
整体来说,做上下文压缩的有三种方式
- 借助LLM对每句话提取相关性比较强的内容
- 借助LLM去掉相关性不强的语句
- 借助Embedding,过滤掉相似度低的语句
前两个都是借助LLM的 prompt,最后这个是根据相似度阈值
集成检索器
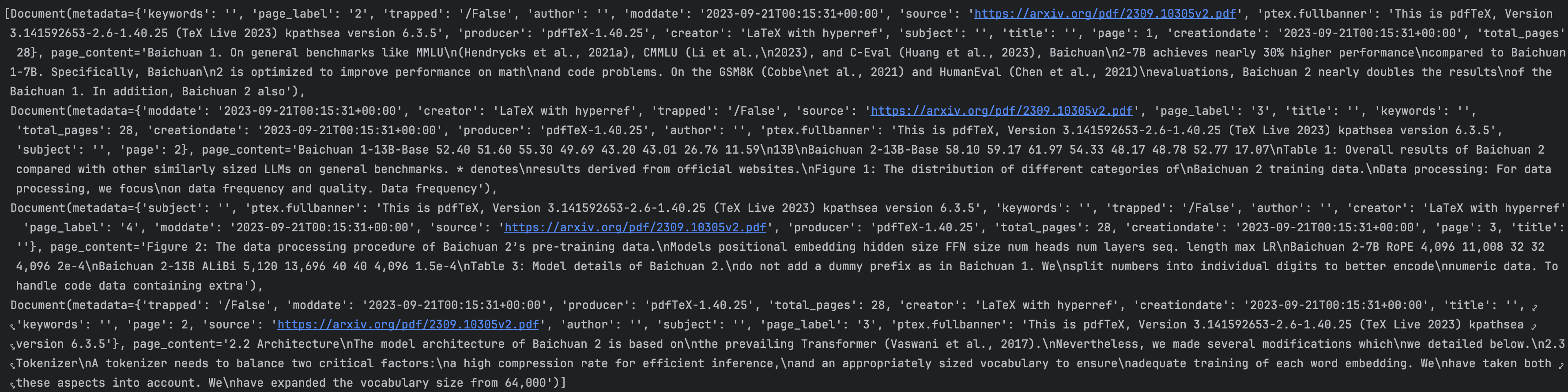
采用多个检索器 (retrievers) 作为输入,并结合它们的 invoke() 方法所返回的结果。然后,进行重排。最常见的模式是将稀疏检索器 (如 BM25) 与密集检索器 (如基于嵌入的相似性) 结合起来,因为它们的优势互补。这种结合也被称为“混合搜索” (hybrid search)。
说的抽象了,简单来说,稀疏检索器是看内容符不符合,密集检索器是看语义符不符合。
举例
{% tabs 集成检索器 , 1 %}
安装依赖
pip install rank_bm25
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_classic.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
import os
from getpass import getpass
HUGGINGFACEHUB_API_TOKEN = getpass()
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HUGGINGFACEHUB_API_TOKEN
# VectorDB
embedding = HuggingFaceEmbeddings(
model_name="moka-ai/m3e-base"
)
# Load pdf
loader = PyPDFLoader("https://arxiv.org/pdf/2309.10305v2.pdf")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data[:6])
from langchain_classic.retrievers import BM25Retriever, EnsembleRetriever
# BM25 检索
bm25_retriever = BM25Retriever.from_documents(
documents=splits
)
bm25_retriever.k = 4 # 选择匹配度最高的4个
# 相似度检索
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
retriever = vectordb.as_retriever(search_kwargs={"k": 4}) # 也是选择匹配度最高的4个
# 集成检索(混合检索)
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, retriever], weights=[0.5, 0.5]
)
# 示例
docs = ensemble_retriever.invoke("What is baichuan2 ?")
docs
这里 weights=[0.5, 0.5],最终分数怎么计算的呢,在 EnsembleRetriever.weighted_reciprocal_rank() 函数里面,公式如下
s c o r e ( d ) = ∑ i w i c + r a n k i ( d ) score(d) = \sum_{i} \frac{w_i}{c+rank_i(d)} score(d)=i∑c+ranki(d)wi
w_i表示第i个检索器的权重rank_i(d)是文档在第i个检索器结果里的名次c是一个常数,默认 60
假如文档A在BM25里面排第一,在向量检索里面没出现,分数就是 0.5 / ( 60 + 1 ) ≈ 0.0082 0.5/(60+1) \approx 0.0082 0.5/(60+1)≈0.0082
如果文档B在BM25排第2,在向量检索也排第2,那么分数就是 0.5 / ( 60 + 2 ) + 0.5 / ( 60 + 2 ) ≈ 0.0161 0.5/(60+2)+0.5/(60+2) \approx 0.0161 0.5/(60+2)+0.5/(60+2)≈0.0161
但是我们一般不用记这么精准,只要知道
- 如果两个检索都出现,分数会更高,只在一边出现,也可能是好结果,但优先级通常低一点
- 想更偏向于哪个(关键词 or 语义),就给谁更高的权重
前者是内容里关键词的匹配,后者是语义上的匹配
比如:
- 查模型名、报错名、函数名、专有名词
更适合让 BM25 权重大一点 - 查“这个东西大概是什么意思”“类似概念”
更适合让 向量检索权重大一点
{% endtabs %}
上下文重排
文档数比较多的时候哈,文档太少,tokens少没啥事
当模型需要处理超过 10 份+检索到的文档时,通常会出现性能下降的问题。由于文档 tokens 过多,即使文档中包含了相关信息,模型也可能因为信息量过大而无法有效地利用这些信息。为了避免这种性能下降,可以在检索后对文档进行重新排序。这样做的目的是将最相关的信息放在模型更容易“看到”或处理的位置。
{% tabs 上下文重排 , 1 %}
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_classic.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
# Load pdf
loader = PyPDFLoader("https://arxiv.org/pdf/2309.10305v2.pdf")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data[:6])
import os
from getpass import getpass
HUGGINGFACEHUB_API_TOKEN = getpass()
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HUGGINGFACEHUB_API_TOKEN
# VectorDB
embedding = HuggingFaceEmbeddings(
model_name="moka-ai/m3e-base"
)
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
retriever = vectordb.as_retriever(search_kwargs={"k": 10}) # 取十个
# 执行
base_docs = retriever.invoke(
"What is baichuan2 ?"
)
[base_doc.page_content for base_doc in base_docs]
from langchain_community.document_transformers import (
LongContextReorder,
)
reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(base_docs)
[reordered_doc.page_content for reordered_doc in reordered_docs]
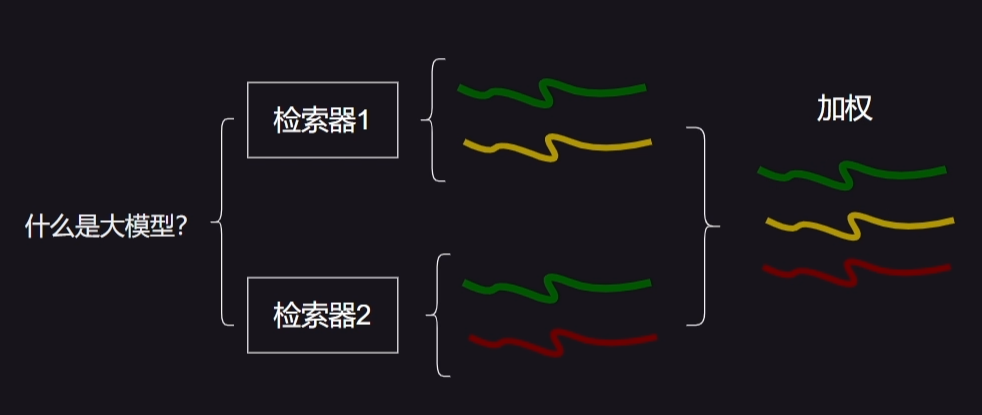
自己观察,其实顺序发生了变化的。这个依据是有一篇论文做了研究,发现大语言对开头和结尾的内容更敏感,中间的内容容易忽略,所以重排也是把相关性比较高的放在两端。
排序源码如下,只做了排序,别的没做,内容也没变动。
def _litm_reordering(documents: List[Document]) -> List[Document]:
"""Lost in the middle reorder: the less relevant documents will be at the
middle of the list and more relevant elements at beginning / end.
See: https://arxiv.org/abs//2307.03172"""
documents.reverse()
reordered_result = []
for i, value in enumerate(documents):
if i % 2 == 1:
reordered_result.append(value)
else:
reordered_result.insert(0, value)
return reordered_result
我们传进来的文档列表,相关性都是从高到低排好的,这里是先反转,然后从第一个开始,是偶数放最前面,奇数放最后,举个例子 [A, B, C, D ,E]
先变为 E, D, C, B, A
EE, DC, E, DC, E, D, BA, C, E, D, B
厉害哈!!
{% endtabs %}
父文档检索
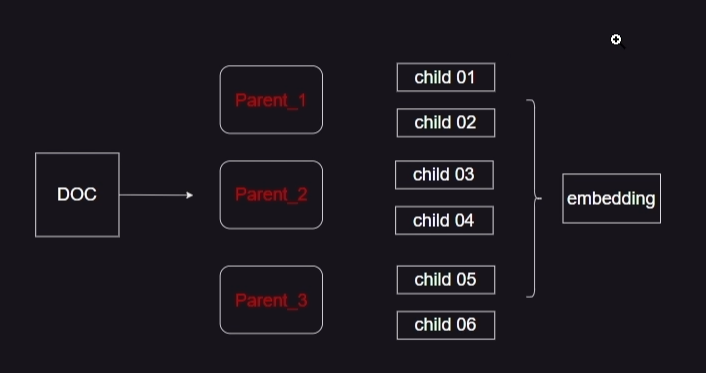
文档分割的冲突需求
需求小型文档:可以更准确地反映它们的含义。如果文档太长,其嵌入可能会失去意义。
需求足够长的文档:你希望文档足够长,以保留完整的每个块的上下文。
在检索过程中,它首先获取这些小块,然后查找这些块的父 ID,并返回那些较大的文档。
{% tabs 父文档检索 , 1 %}
from langchain_classic.retrievers import ParentDocumentRetriever
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_classic.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_classic.storage import InMemoryStore
# Load pdf
loader = PyPDFLoader("https://arxiv.org/pdf/2309.10305v2.pdf")
data = loader.load()
# Split
# text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
# splits = text_splitter.split_documents(data[:6]) # 这段代码没用的,不要混淆了
import os
from getpass import getpass
HUGGINGFACEHUB_API_TOKEN = getpass()
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HUGGINGFACEHUB_API_TOKEN
# This text splitter is used to create the child documents
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# The vectorstore to use to index the child chunks
embedding = HuggingFaceEmbeddings(
model_name="moka-ai/m3e-base"
)
vectorstore = Chroma(
collection_name="full_documents", embedding_function=embedding,
) # 只是创建数据库,还没有存入数据。collection_name 算是数据库名
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
)
retriever.add_documents(data[:6], ids=None)
- 默认传进来的参数
data[:6]为父文档,保存到docstore,也会被child_splitter切成更小的块写入vectorstore供检索
len(list(store.yield_keys())) # 6
# 注意这里是向量库,是被 child_splitter 之后存放的位置
sub_docs = vectorstore.similarity_search("What is baichuan2 ?")
len(sub_docs[0].page_content) # 375 没什么问题,因为是子块,都小于400长度
# 使用父文档检索
retrieved_docs = retriever.invoke("What is baichuan2 ?")
len(retrieved_docs[0].page_content) # 4528 一整页的长度
len(retrieved_docs) # 2 因为一共六页,说明检索的内容出现在了其中两页
# This text splitter is used to create the parent documents
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# This text splitter is used to create the child documents
# It should create documents smaller than the parent
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# The vectorstore to use to index the child chunks
embedding = HuggingFaceEmbeddings(
model_name="moka-ai/m3e-base"
)
vectorstore = Chroma(
collection_name="split_parents", embedding_function=embedding
)
# The storage layer for the parent documents
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
retriever.add_documents(data[:6], ids=None)
父文档不再是完整的页,而是用个大点的块,chunk_size=2000,子类用个小点的 chunk_size=400
len(list(store.yield_keys())) # 15 父文档长度
retrieved_docs = retriever.invoke("What is baichuan2 ?")
len(retrieved_docs[0].page_content) # 1965 因为父类我们定义长度小于2000
{% endtabs %}
RAGAs 评估 RAG 系统
流程
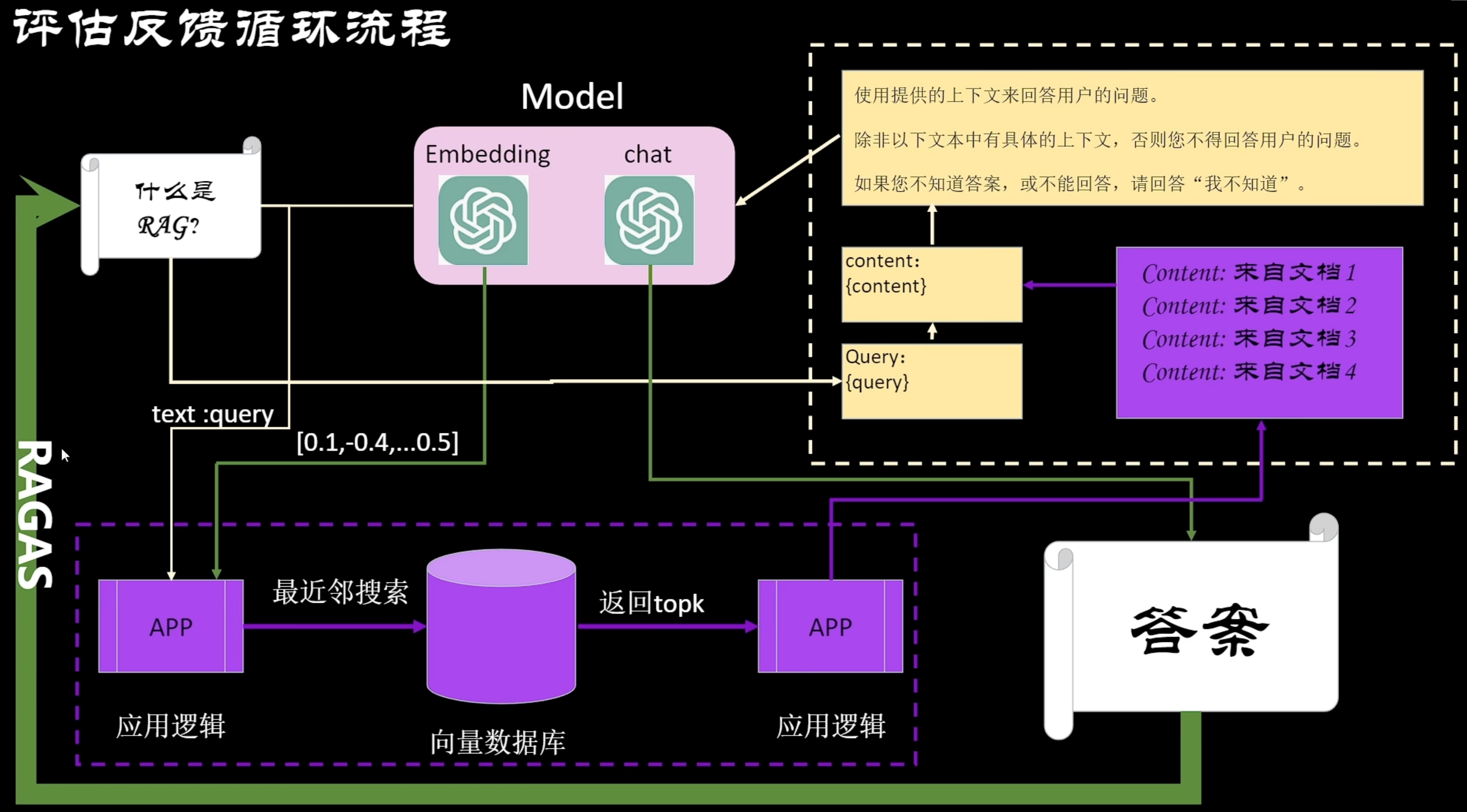
RAGAS是一个用于评估RAG系统的框架,它允许在不依赖人工注释的情况下,通过一套指标评估检索模块和生成模块的性能及其生成质量

Answer是大语言模型生成的答案,Ground_Truths才是真实答案
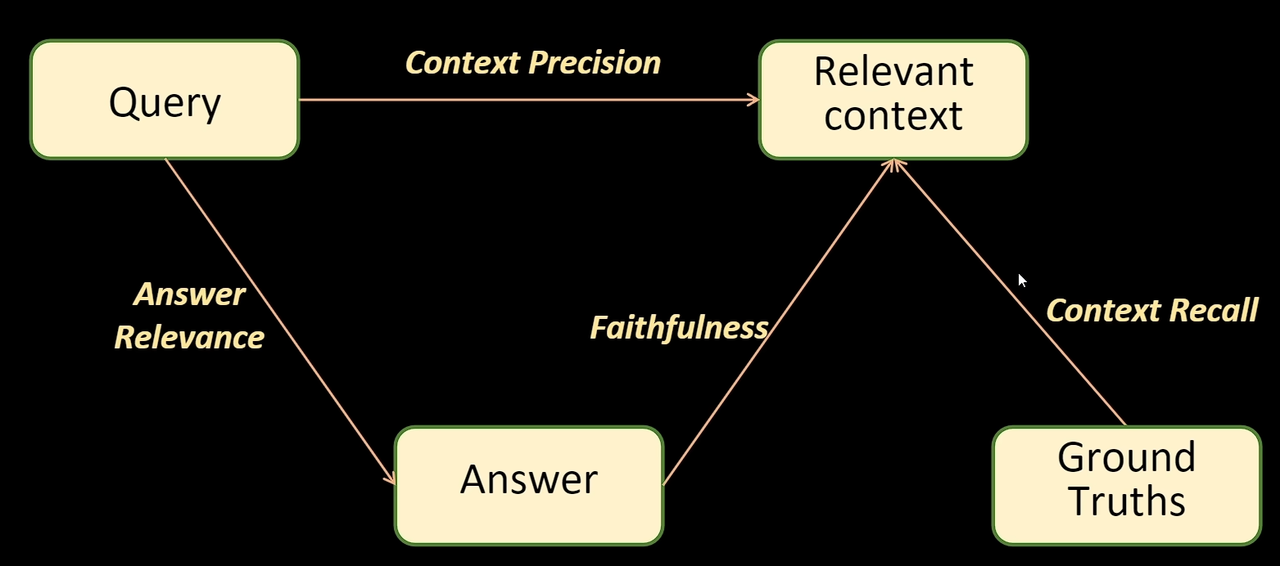
指标
-
Context Precision:Query 和 Relevant context 的准确度,也就是 Query 和向量库数据的准确度
Context Precision 衡量的是检索结果中相关信息是否排在前面。它会在每个相关结果出现的位置计算一次前缀 Precision,再对这些值取平均,因此越靠前出现相关内容,分数越高。
比如查询出来的结果是[相关,不相关,相关,不相关,相关]Precision@1 = 1/1Precision@2 = 1/2Precision@3 = 2/3Precision@4 = 2/4Precision@5 = 3/5
然后由上面这个结果计算Context Precision:只用相关的那个来进行加和作为分子,分母为相关的个数
Context Precision = 1 / 1 + 2 / 3 + 3 / 5 3 \text{Context Precision} = \frac{1/1 + 2/3 + 3/5}{3} Context Precision=31/1+2/3+3/5
-
Faithfulness:是回答的结果和上下文之间的匹配度,要严格依照查询的结果,防止出现幻觉
-
Answer Relevance:Query 和 Answer 之间的相关性
基于答案生成多个问题,把这些问题和真实Query计算余弦相似度取平均 -
Context Recall:真实答案是否在上下文中

RAG全链路
概览
整体框架
RAG 整体框架图
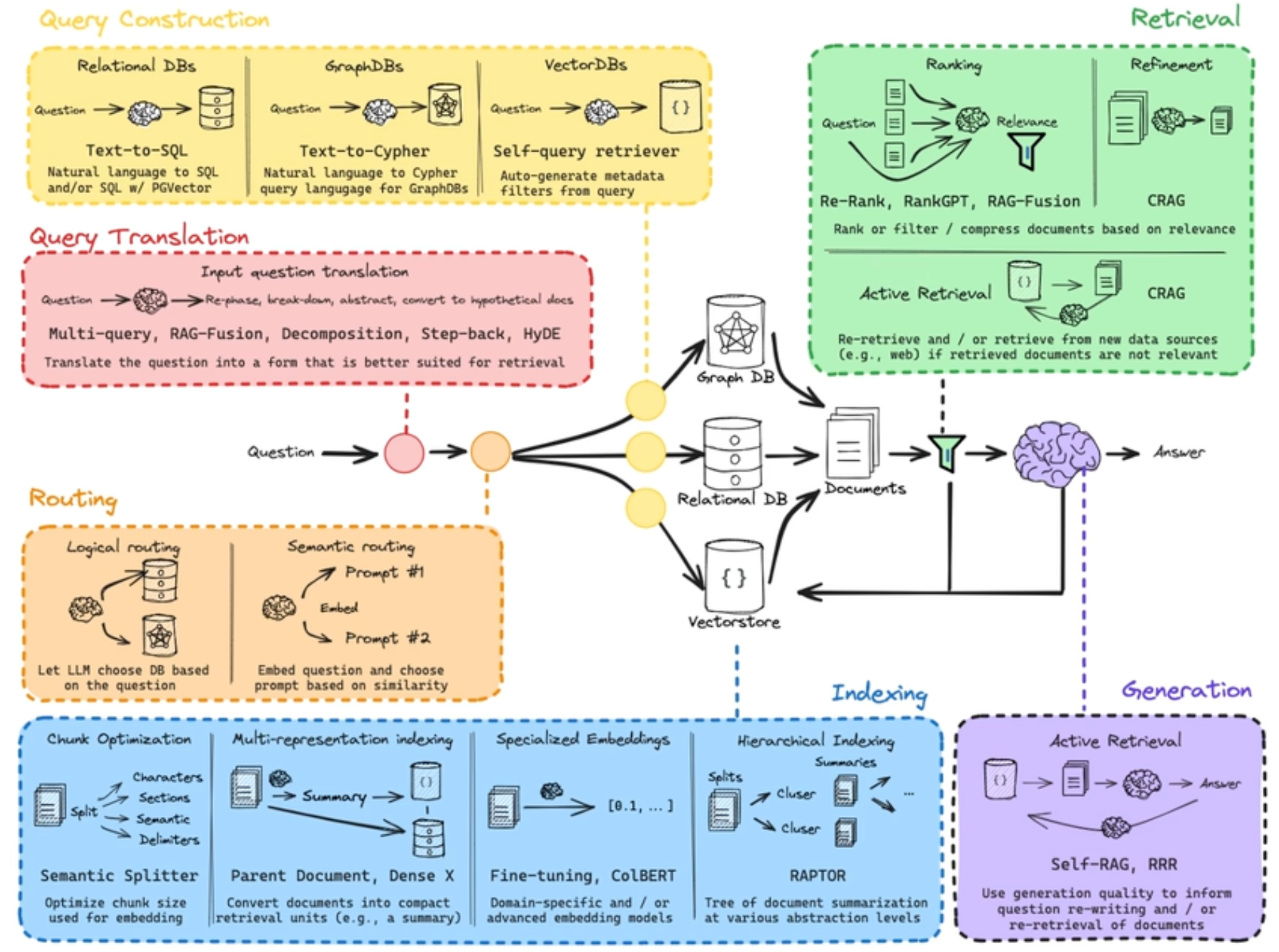
横轴是大语言模型训练的时候能给的数据量,其实就是相当于模型自己的知识了,纵轴是上下文窗口大小,相当于在询问的时候能给的一些外部信息量。
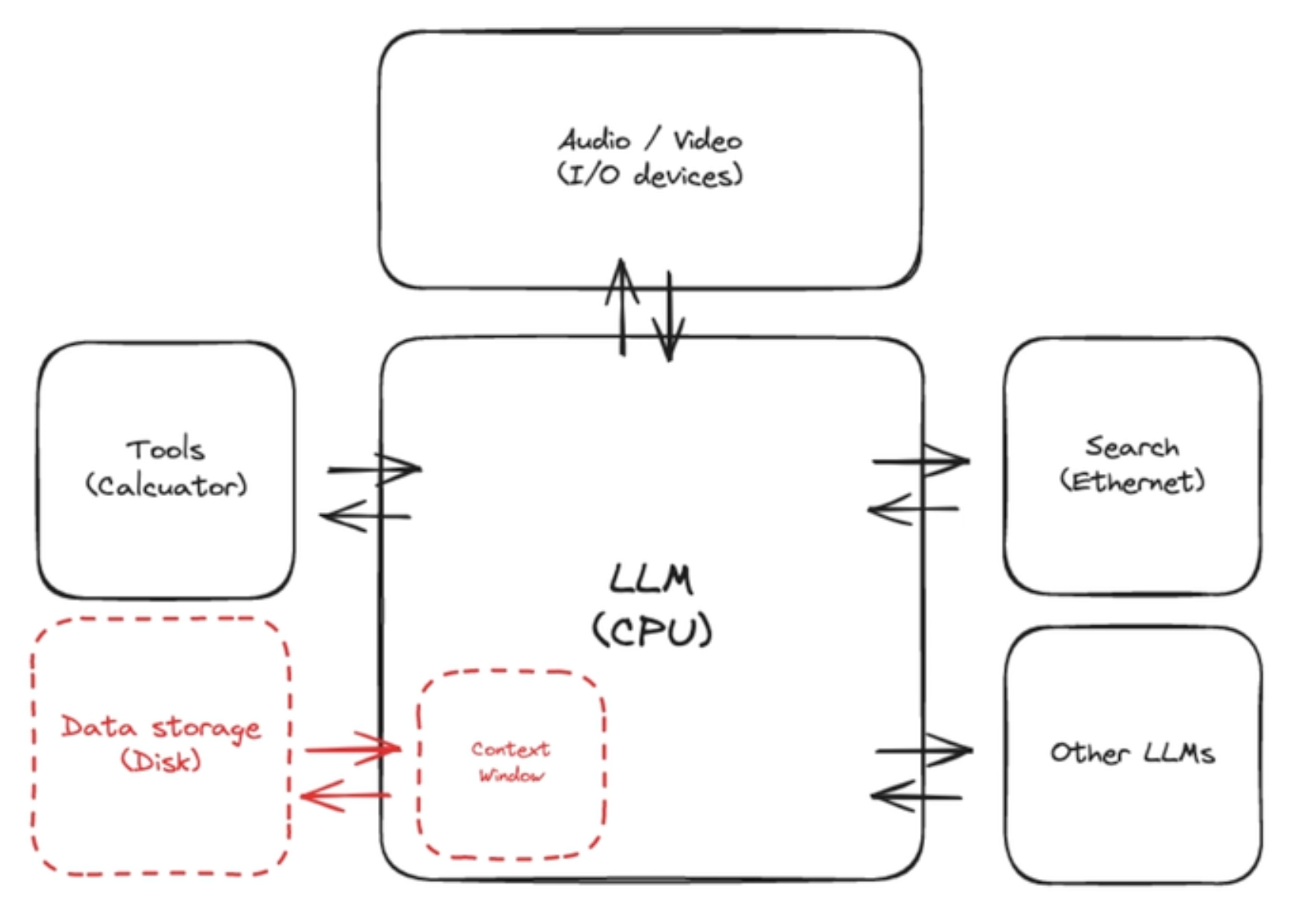
现在说大语言模型将发展成为一个操作系统,LLM作为CPU,他可以调用工具、Web搜索、I/O读取等等。
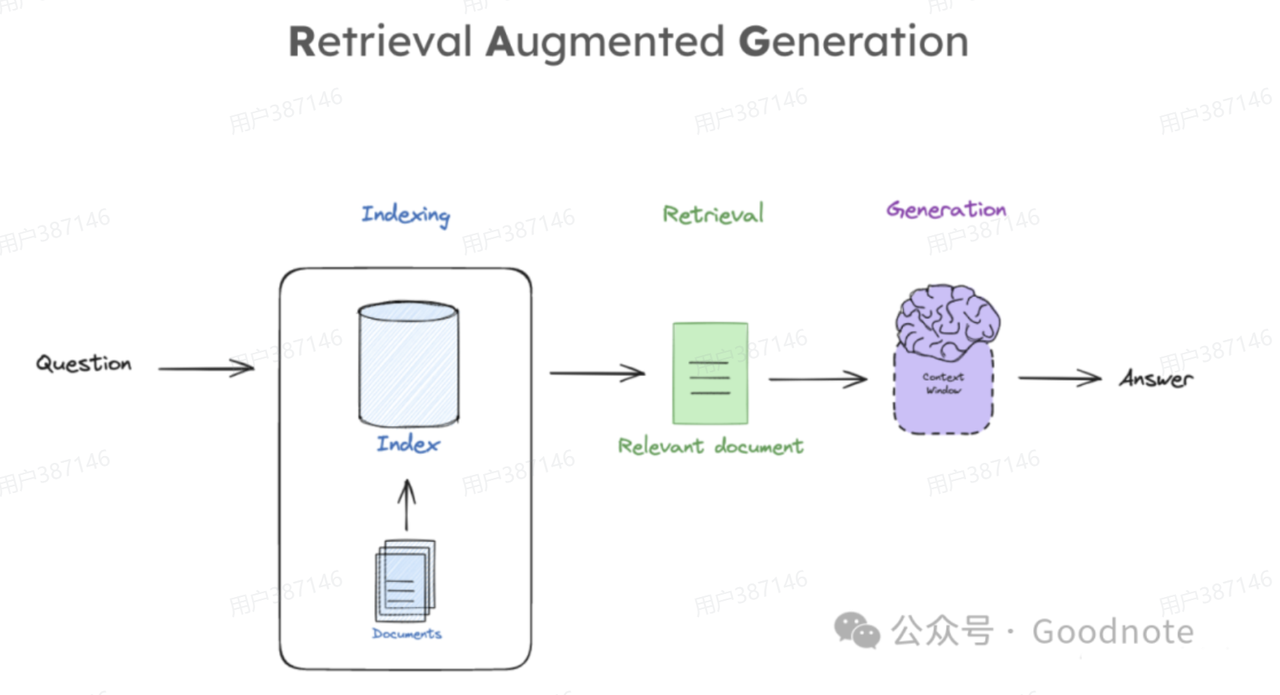
RAG 也是一种帮助LLM的一种技术,也是用来检索信息,放在上下文窗口里面给LLM的。整体流程就是先把文档向量化起来,确保它能被索引到,然后问题也是需要被向量化,然后检索到最相关的文档信息,最后把问题和检索到的文档一块放到大语言模型的上下文窗口进行回答。
{% note red ‘fas fa-question-circle’ simple %}
{% label 现在上下文窗口这么长了,RAG是不是不需要了?上下文窗口已经能输入很多东西了,就不需要RAG来检索筛选信息了。 red %}
我认为不是不需要 RAG,而是没那么‘必须’了。长上下文解决的是‘装得下’,RAG 解决的是‘该给什么’。如果资料很少、范围很固定,可以直接把材料放进上下文;但如果资料很多、更新快,或者对成本、速度、准确性有要求,RAG 还是很有价值。因为不是上下文越长,模型就越能稳定抓住最关键的信息。所以是:长上下文降低了 RAG 的使用门槛,但没有替代 RAG。小任务可以少用RAG,大知识库场景还是需要。
{% endnote %}
整体代码
#%% md
import bs4
from langchain_classic import hub
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
#### INDEXING ####
# Load Documents
# WebBaseLoader 负责抓取网页
# bs4.SoupStrainer 负责解析网页,拆标签、提正文
# class_ 属性就是条件,只提取头部、标题、正文。其他的菜单栏、页脚、评论区等无关的都过滤掉
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# Embed
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
#### RETRIEVAL and GENERATION ####
# Prompt
prompt = hub.pull("rlm/rag-prompt") # 从 Hub 上下载一个别人写好的模版,不用自己写了
# LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# Question
rag_chain.invoke("What is Task Decomposition?")
这个 rlm/rag-prompt 具体内容如下
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
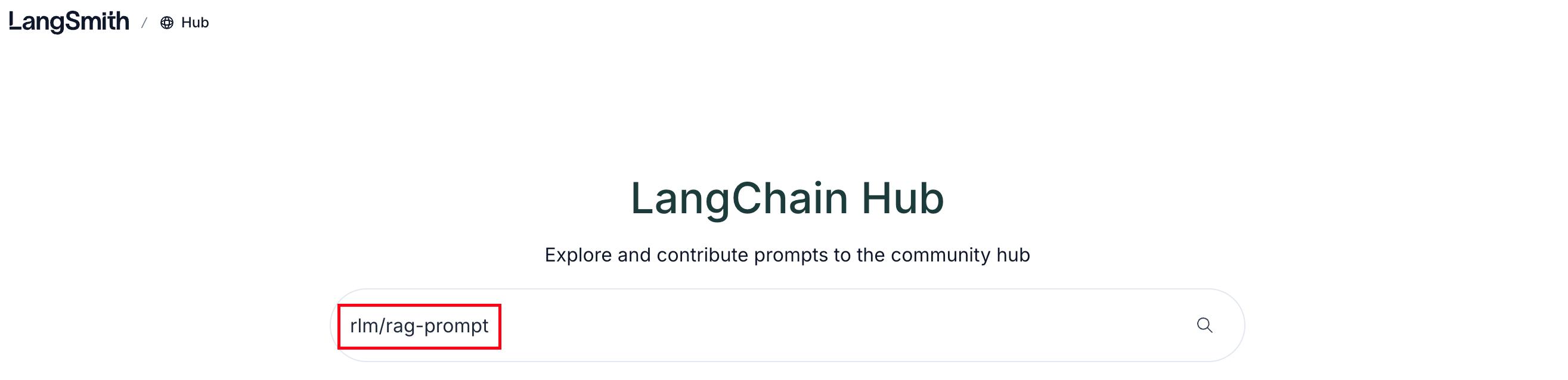
在 LangChain Hub 上搜索即可
- 这个
|是做了一个重载,含义是把前面结果的输出作为后一个点输入。 - 这个
RunnablePassthrough()是拿到rag_chain.invoke(...)把输入不做修改的传下去,这里就是把这个参数给question StrOutputParser():模型原本返回的可能是AIMessage(...)对象,里面除了回答的文字还有一些结构信息,不是纯回答,用这个就是拿到纯回答的内容。
Indexing
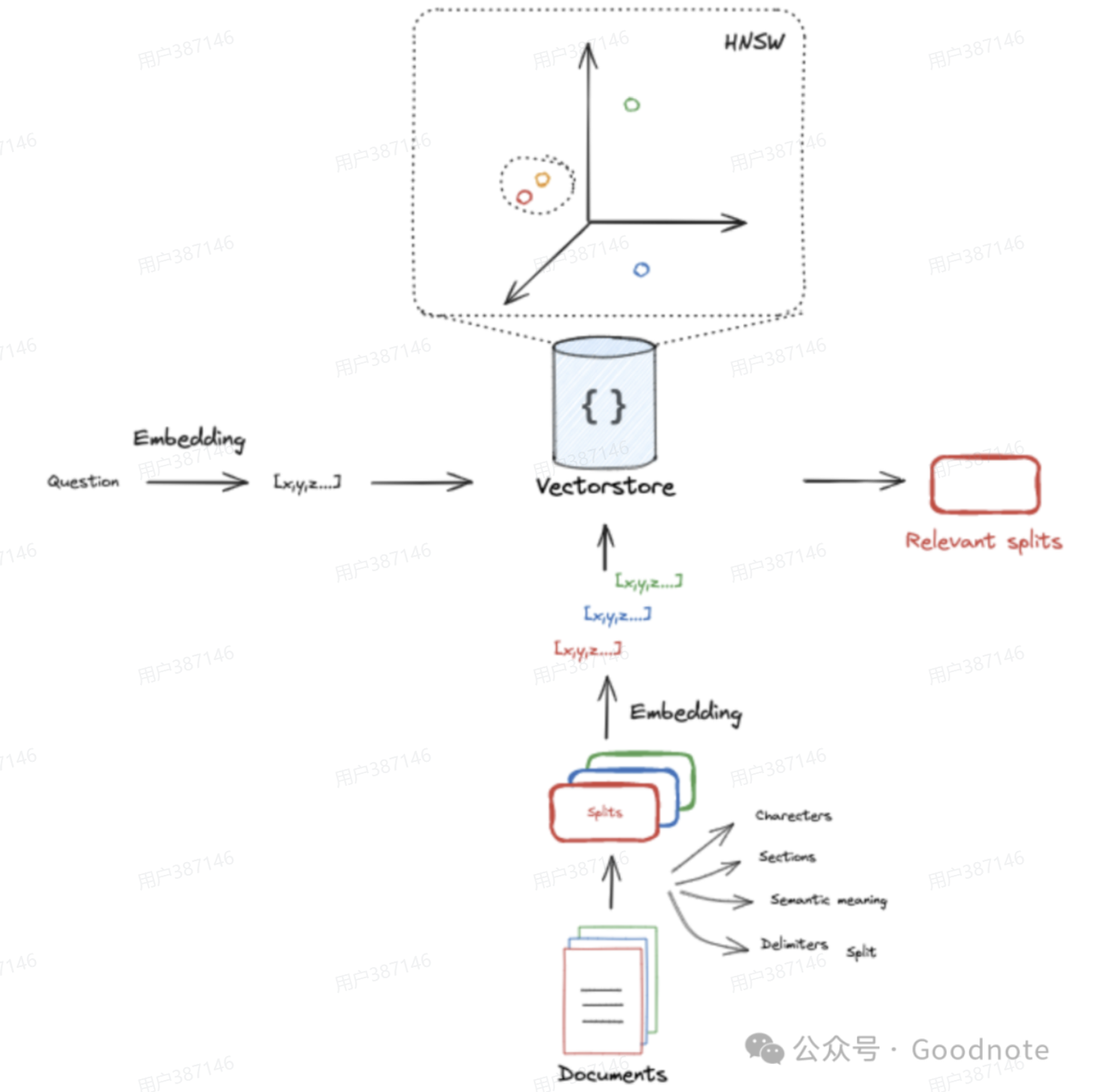
文档和问题都会 embedding 变为向量放入 VectorStore,不是只存向量结果的,还要包括元数据以及一些其他信息。
Embedding 是一种模型,只负责向量化,VectorStore 是数据库,负责存储、检索。
不同的 embedding 模型生成的向量维度通常不一样,比如上面这个 OpenAI 的,就是 1536 维。跟放在哪种数据库没要求。但是
- 比如你想把一堆数据弄进去,那都得是 1536 维的,不能维度不一致
- query 查询的问题 embedding 也得是1536维,这样才能相似度检索
那你想一堆数据,但是我有两个 embedding 模型都是1536维的,一个处理一半可以吗?
技术上应该不会报错,但是非常不建议混用,或者说别这么做,因为不同embedding模型不同向量空间位置通常是不同的语义。
HNSW
L2欧式距离、余弦相似度作用是判断两个语句是否相似,是评分规则
HNSW是,比如经过余弦相似度计算,我知道A、B和Query更相近,但是如何从100万条数据中快速定位到A,B。就是HNSW要做的,这是向量库需要实现的,HNSW 是目前非常主流、很高效的一类 ANN 方法,但不是唯一方法,不同向量库可能用不同的方式。
那感觉 HNSW 应该放在 Retrieval 这一节,对吧
距离度量
距离度量的选择取决于向量是怎么得到的,尤其取决于编码器的训练方式。模型训练的时候定义了这个向量空间该怎么比较,什么算远、什么算近。
不是所有的模型都该用同一种相似度,具体取决于模型,比如 OpenAI embedding,看官网说的,推荐使用 cosine similarity

- 计算会快一点
- 和欧式距离排序是一致的
大部分都是用 cosine,所以如果官方没有文档说明,就先用 cosine,如果有文档就按文档推荐的来。
Retrieval
Generation
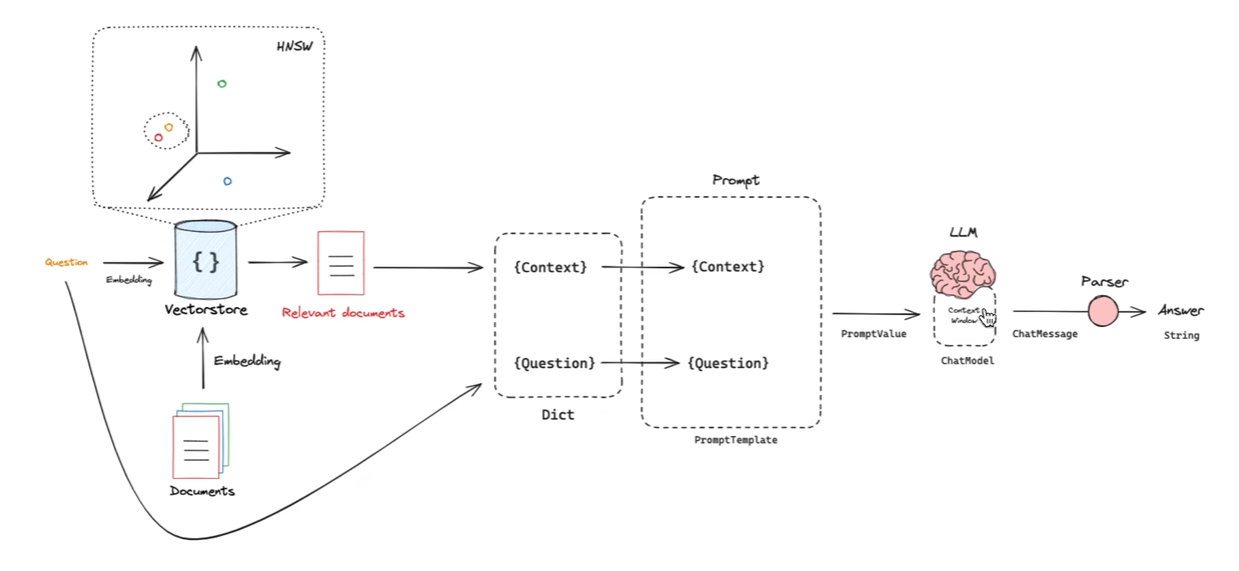
怎么有更好的 Context 和 Question 就更重要了
优化原始提问(Query Translation)
Multi Query(多查询策略)
在同一维度,根据用户输入的问题生成多个子问题,对同一问题生成多个视角的提问,然后依次进行检索,最后将检索到的文档合并返回。
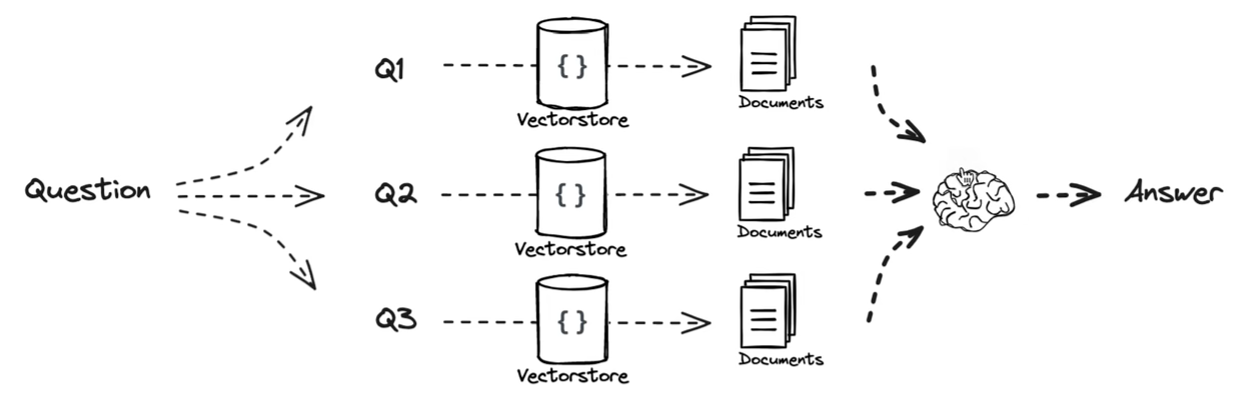
这个代码前面已经给过了,这里再给一下,但是不运行了
{% tabs MultiQuery2 , 1 %}
#### INDEXING ####
# Load blog
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
# Split
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Make splits
splits = text_splitter.split_documents(blog_docs)
# Index
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
from langchain_classic.prompts import ChatPromptTemplate
# Multi Query: Different Perspectives
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_queries = (
prompt_perspectives
| ChatOpenAI(temperature=0)
| StrOutputParser()
| (lambda x: x.split("\n"))
) # 3 个问题
用 LLM 生成三个问题,这里根据 Prompt 来做的,是自己定义的提示词,和前面 MultiQueryRetriever 一毛一样。
from langchain_classic.load import dumps, loads
def get_unique_union(documents: list[list]):
""" Unique union of retrieved docs """
# Flatten list of lists, and convert each Document to string
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
# Get unique documents
unique_docs = list(set(flattened_docs))
# Return
return [loads(doc) for doc in unique_docs]
# Retrieve
question = "What is task decomposition for LLM agents?"
retrieval_chain = generate_queries | retriever.map() | get_unique_union
docs = retrieval_chain.invoke({"question":question})
len(docs)
把生成的三个问题分别去向量库查询得到结果,然后取并集,dumps 用来把 Document 对象转为JSON格式,loads 用来把 JSON 对象转为 Doucment 对象。
from operator import itemgetter
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(temperature=0)
final_rag_chain = (
{"context": retrieval_chain,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
生成最终的结果
{% endtabs %}
RAG-Fusion(多查询结果融合策略)
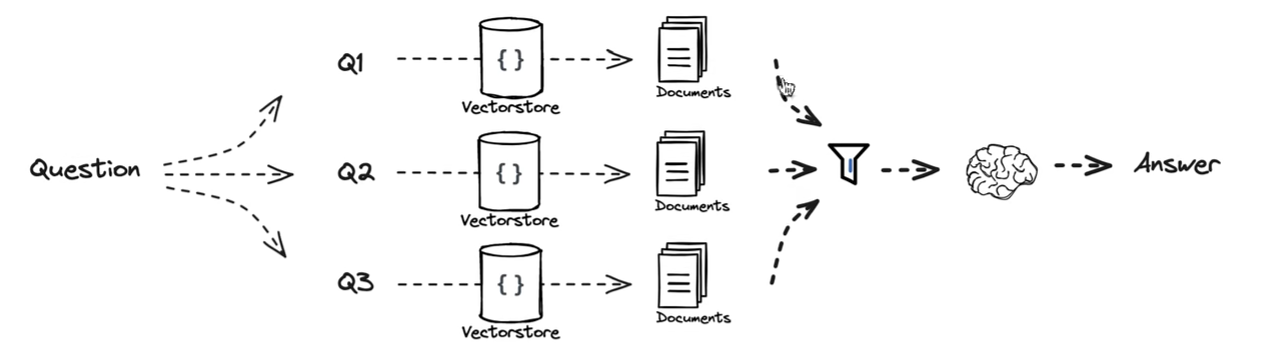
RAG Fusion 和 MultiQueryRetriever 基于同样的思路,在 Multi Query 多查询策略生成子问题并检索的基础上,它对检索结果执行倒数排名融合(Reciprocal Rank Fusion,RRF) 算法,使得检索效果更好。
这个前面没提到过,Multi Query 是对多个子问题检索的结果取并集,但是比如某个回答在两个问题里面都出现了,那么它的重要性显然要高一些,所以基于此,有RRF算法。
{% note info simple %}
先把用户问题改写成多个 query,各自检索,得到多份排序列表;再用 RRF 给每篇文档累计“排名分”,最后按总分重新排序。某个文档如果在多个改写 query 的检索结果里都排得靠前,它的总分就更高,最终会被排到前面。
{% endnote %}
目前这个提示词还没有集成到 langchain_classic.prompts 里面,不过在 LangChain Hub 里面有 https://smith.langchain.com/hub/langchain-ai/rag-fusion-query-generation
下面是具体实现代码
{% tabs RAG-Fusion , 1 %}
from langchain_classic.prompts import ChatPromptTemplate
# RAG-Fusion: Related
template = """You are a helpful assistant that generates multiple search queries based on a single input query. \n
Generate multiple search queries related to: {question} \n
Output (4 queries):"""
prompt_rag_fusion = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_queries = (
prompt_rag_fusion
| ChatOpenAI(temperature=0)
| StrOutputParser()
| (lambda x: x.split("\n"))
) # 这里只是用来生成四个问题
from langchain_classic.load import dumps, loads
####### 进行 Rerank #######
def reciprocal_rank_fusion(results: list[list], k=60):
""" Reciprocal_rank_fusion that takes multiple lists of ranked documents
and an optional parameter k used in the RRF formula """
# Initialize a dictionary to hold fused scores for each unique document
fused_scores = {}
# Iterate through each list of ranked documents
for docs in results:
# Iterate through each document in the list, with its rank (position in the list)
for rank, doc in enumerate(docs):
# Convert the document to a string format to use as a key (assumes documents can be serialized to JSON)
doc_str = dumps(doc)
# If the document is not yet in the fused_scores dictionary, add it with an initial score of 0
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
# Retrieve the current score of the document, if any
previous_score = fused_scores[doc_str]
# Update the score of the document using the RRF formula: 1 / (rank + k)
fused_scores[doc_str] += 1 / (rank + k)
# Sort the documents based on their fused scores in descending order to get the final reranked results
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
# Return the reranked results as a list of tuples, each containing the document and its fused score
return reranked_results
retrieval_chain_rag_fusion = generate_queries | retriever.map() | reciprocal_rank_fusion
docs = retrieval_chain_rag_fusion.invoke({"question": question})
len(docs)
打分公式就是
score + = 1 r a n k + k \text{score} += \frac{1}{rank + k} score+=rank+k1
k 默认是 60,rank 是文档在某个结果列表里的位置,排名越靠前,分数越大,但是差距不会特别夸张,因为有 k=60 在压平距离
某个文档的最终分数就是在每个问题里面的分数加和。
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
{"context": retrieval_chain_rag_fusion,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
{% endtabs %}
Decomposition(问题分解策略)
在下一个更简单维度,将一个复杂问题分解成多个子问题,将问题分解为一组子问题。之后解决这些子问题再进行合并。有两种类型:Answer recursively 和 Answer individually
from langchain_classic.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# Decomposition
template = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n
Generate multiple search queries related to: {question} \n
Output (3 queries):"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
# LLM
llm = ChatOpenAI(temperature=0)
# Chain
generate_queries_decomposition = ( prompt_decomposition | llm | StrOutputParser() | (lambda x: x.split("\n")))
# Run
question = "What are the main components of an LLM-powered autonomous agent system?"
questions = generate_queries_decomposition.invoke({"question":question})
三个问题如下
['1. What is LLM technology and how does it work in autonomous agent systems?',
'2. What are the specific components that make up an LLM-powered autonomous agent system?',
'3. How do the main components of an LLM-powered autonomous agent system interact with each other to enable autonomous behavior?']
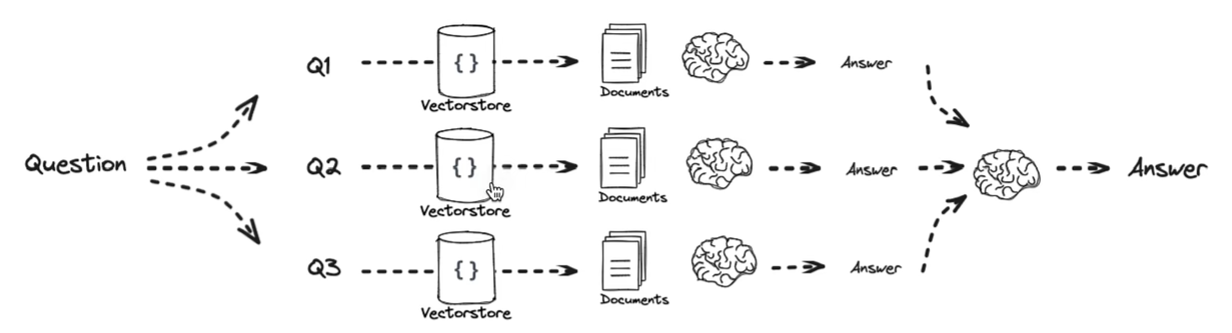
Answer recursively 递归回答
使用第一个问题的答案 + 检索来回答第二个问题,以此类推。
在前面得到 questions 对基础上,继续做,如下。
{% tabs AnswerRecursively , 1 %}
template = """Here is the question you need to answer:
\n --- \n {question} \n --- \n
Here is any available background question + answer pairs:
\n --- \n {q_a_pairs} \n --- \n
Here is additional context relevant to the question:
\n --- \n {context} \n --- \n
Use the above context and any background question + answer pairs to answer the question: \n {question}
"""
decomposition_prompt = ChatPromptTemplate.from_template(template)
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
def format_qa_pair(question, answer):
"""Format Q and A pair"""
formatted_string = ""
formatted_string += f"Question: {question}\nAnswer: {answer}\n\n"
return formatted_string.strip()
# llm
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
q_a_pairs = ""
for q in questions:
rag_chain = (
{"context": itemgetter("question") | retriever,
"question": itemgetter("question"),
"q_a_pairs": itemgetter("q_a_pairs")}
| decomposition_prompt
| llm
| StrOutputParser())
answer = rag_chain.invoke({"question":q,"q_a_pairs":q_a_pairs})
q_a_pair = format_qa_pair(q,answer) # Question & Answer 对
q_a_pairs = q_a_pairs + "\n---\n"+ q_a_pair
{% endtabs %}
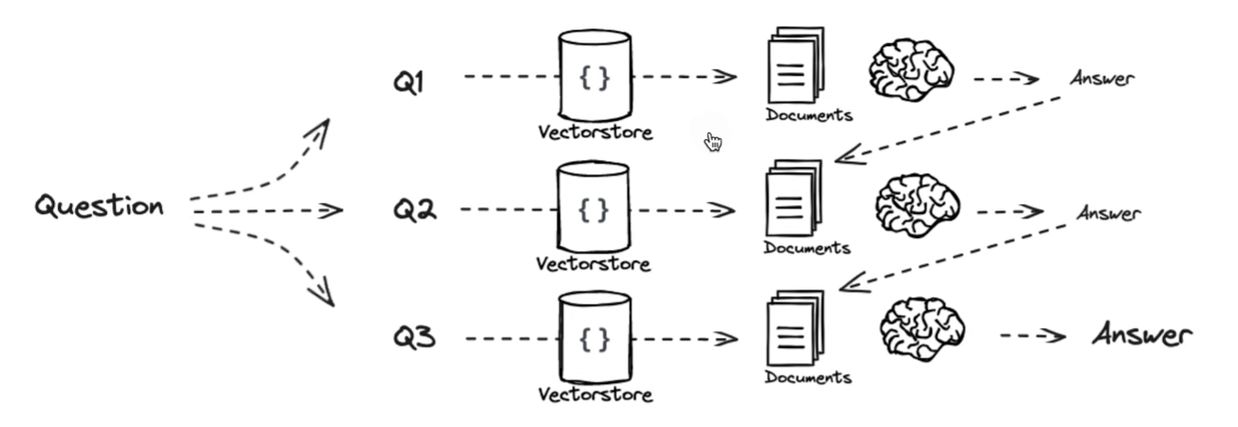
Answer individually 独立回答
独立解决每一个问题,最后将每个答案合并为最终答案。
{% tabs AnswerIndividually , 1 %}
# Answer each sub-question individually
from langchain_classic import hub
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# RAG prompt
prompt_rag = hub.pull("rlm/rag-prompt")
def retrieve_and_rag(question,prompt_rag,sub_question_generator_chain):
"""RAG on each sub-question"""
# Use our decomposition /
sub_questions = sub_question_generator_chain.invoke({"question":question})
# Initialize a list to hold RAG chain results
rag_results = []
for sub_question in sub_questions:
# Retrieve documents for each sub-question
retrieved_docs = retriever.get_relevant_documents(sub_question)
# Use retrieved documents and sub-question in RAG chain
answer = (prompt_rag | llm | StrOutputParser()).invoke({"context": retrieved_docs,
"question": sub_question})
rag_results.append(answer)
return rag_results,sub_questions
# Wrap the retrieval and RAG process in a RunnableLambda for integration into a chain
answers, questions = retrieve_and_rag(question, prompt_rag, generate_queries_decomposition)
def format_qa_pairs(questions, answers):
"""Format Q and A pairs"""
formatted_string = ""
for i, (question, answer) in enumerate(zip(questions, answers), start=1):
formatted_string += f"Question {i}: {question}\nAnswer {i}: {answer}\n\n"
return formatted_string.strip()
context = format_qa_pairs(questions, answers) # 拼接三个子问题+子问题答案
# Prompt
template = """Here is a set of Q+A pairs:
{context}
Use these to synthesize an answer to the question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context":context,"question":question})
{% endtabs %}
{% note info simple %}
Decomposition 只是把复杂问题拆成子问题。若子问题彼此独立,用 Answer individually,并行回答后再汇总;若子问题前后依赖、需要逐步利用前面的结果,用 Answer recursively,也就是按 Least-to-Most 方式递进求解。
{% endnote %}
{% note info simple %}
Answer individually 和 Multi Query 都是分解成多个子问题然后回答并汇总。不同的是 Answer individually 是对原问题拆分,Multi Query 是对原问题多角度描述。
{% endnote %}
Step-Back(问题回退策略)
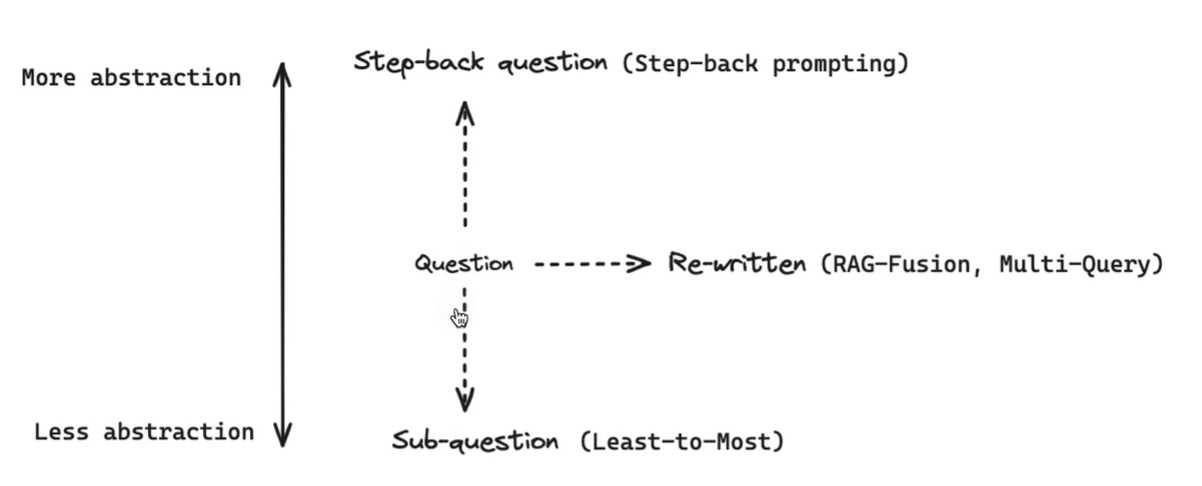
在更简单的维度,基于用户的原始问题生成一个后退问题,后退问题相比原始问题具有更高级别的概念或原则,从而提高解决复杂问题的效果。
构成上包括
抽象abstraction和推理reasoning两个步骤,比如给定一个问题,需要提示大模型,找到回答该问题的一个前置问题,得到前置问题及其答案后,再将其整体与当前问题进行合并,最后送入大模型进行问答,得到最终答案。例如一个关于物理学的问题可以后退为一个关于该问题背后的物理原理的问题,然后对原始问题和后退问题进行检索。
{% tabs Step-Back代码 , 1 %}
# Few Shot Examples
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
examples = [
{
"input": "Could the members of The Police perform lawful arrests?",
"output": "what can the members of The Police do?",
},
{
"input": "Jan Sindel’s was born in what country?",
"output": "what is Jan Sindel’s personal history?",
},
]
# We now transform these to example messages
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:""",
),
# Few shot examples
few_shot_prompt,
# New question
("user", "{question}"),
]
)
generate_queries_step_back = prompt | ChatOpenAI(temperature=0) | StrOutputParser()
question = "What is task decomposition for LLM agents?"
generate_queries_step_back.invoke({"question": question}) # 'What is the process of breaking down tasks for LLM agents?'
# Response prompt
response_prompt_template = """You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
# {normal_context}
# {step_back_context}
# Original Question: {question}
# Answer:"""
response_prompt = ChatPromptTemplate.from_template(response_prompt_template)
chain = (
{
# Retrieve context using the normal question
"normal_context": RunnableLambda(lambda x: x["question"]) | retriever,
# Retrieve context using the step-back question
"step_back_context": generate_queries_step_back | retriever,
# Pass on the question
"question": lambda x: x["question"],
}
| response_prompt
| ChatOpenAI(temperature=0)
| StrOutputParser()
)
chain.invoke({"question": question})
在LCEL里面,数据默认从左往右传,如果中间是一个字典,那么同一个输入会同时给字典里面的每个分支,所以这个里面 normal_context、step_back_context、question 都会接收这个 question。
{% endtabs %}
HyDE(Hypothetical Document Embeddings) 假设性文档嵌入
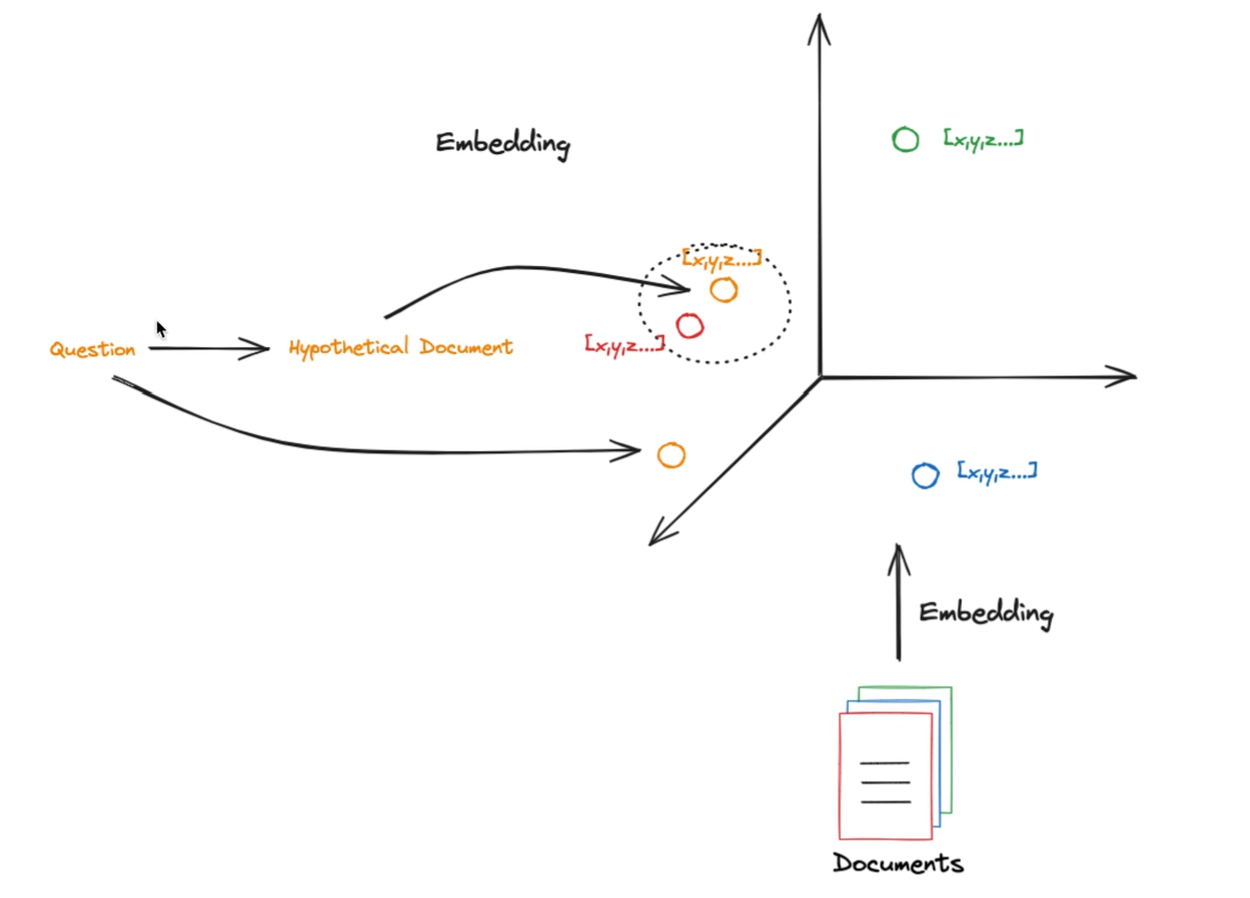
使用基于相似性的向量检索时,在原始问题上进行检索可能效果不佳,因为它们的嵌入可能与相关文档的嵌入不太相似,但是,如果让大模型生成一个假设的相关文档,然后使用它来执行相似性检索可能会得到意想不到的结果。这就是 假设性文档嵌入(Hypothetical Document Embeddings,HyDE) 背后的关键思想。
{% tabs HyDE代码 , 1 %}
from langchain_classic.prompts import ChatPromptTemplate
# HyDE document genration
template = """Please write a scientific paper passage to answer the question
Question: {question}
Passage:"""
prompt_hyde = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_docs_for_retrieval = (
prompt_hyde | ChatOpenAI(temperature=0) | StrOutputParser()
)
# Run
question = "What is task decomposition for LLM agents?"
generate_docs_for_retrieval.invoke({"question":question})
结果如下
“Task decomposition is a fundamental concept in the field of machine learning and artificial intelligence, particularly for agents utilizing the Large Language Model (LLM) framework. Task decomposition involves breaking down complex tasks into smaller, more manageable sub-tasks that can be individually addressed by the agent. This approach allows the agent to effectively tackle large and complex problems by dividing them into smaller, more manageable components.\n\nIn the context of LLM agents, task decomposition is crucial for improving the efficiency and effectiveness of the agent’s decision-making process. By breaking down a complex task into smaller sub-tasks, the agent can focus on solving each sub-task individually, leading to more accurate and timely responses. Additionally, task decomposition allows the agent to leverage its knowledge and expertise in specific domains, enabling it to provide more specialized and targeted solutions.\n\nOverall, task decomposition plays a critical role in enhancing the performance of LLM agents by enabling them to effectively handle complex tasks and make informed decisions. By breaking down tasks into smaller components, LLM agents can leverage their capabilities to provide more accurate and efficient solutions, ultimately improving their overall performance and effectiveness in various applications.”
# Retrieve
# 用生成的假设性文档去检索
retrieval_chain = generate_docs_for_retrieval | retriever
retireved_docs = retrieval_chain.invoke({"question":question})
retireved_docs
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context":retireved_docs,"question":question})
{% endtabs %}
{% note warning simple %}
注意,HyDE 可能出现的两个失败场景:
- 在没有上下文的情况下,HyDE 可能会对原始问题产出误解,导致检索出误导性的文档;比如用户问题是 “What is Bel?”,由于大模型缺乏上下文,并不知道 Bel 指的是 Paul Graham 论文中提到的一种编程语言,因此生成的内容和原文完全没有关系,导致检索出和用户问题没有关系的文档;
- 对开放式的问题,HyDE 可能产生偏见;比如用户问题是 “What would the author say about art vs. engineering?”,这时大模型会随意发挥,生成的内容可能带有偏见,从而导致检索的结果也带有偏见;
{% endnote %}
{% note success %}
Step-Back:先问更大的原理问题。
HyDE:先写一段像答案的假文档,再拿这段去搜。
{% endnote %}
其他方法
上面的查询重写(Query Rewriting),都是为了处理表达不清的用户输入,和处理聊天场景中的后续问题(Follow Up Questions)。
查询压缩(Query Compression),用户可能是以聊天对话的形式与系统交互的,为了正确回答用户的问题,我们需要考虑完整的对话上下文,为了解决这个问题,可以将聊天历史压缩成最终问题以便检索。
路由和高级查询
Routing(路由)
本节主要解决的是从获取query之后,所选择问题域的方案,包括Logical routing and Semantic routing,LLM会基于用户的问题,选择合适的逻辑路由(数据源选择)和语义路由(Prompt选择) 进行分发。
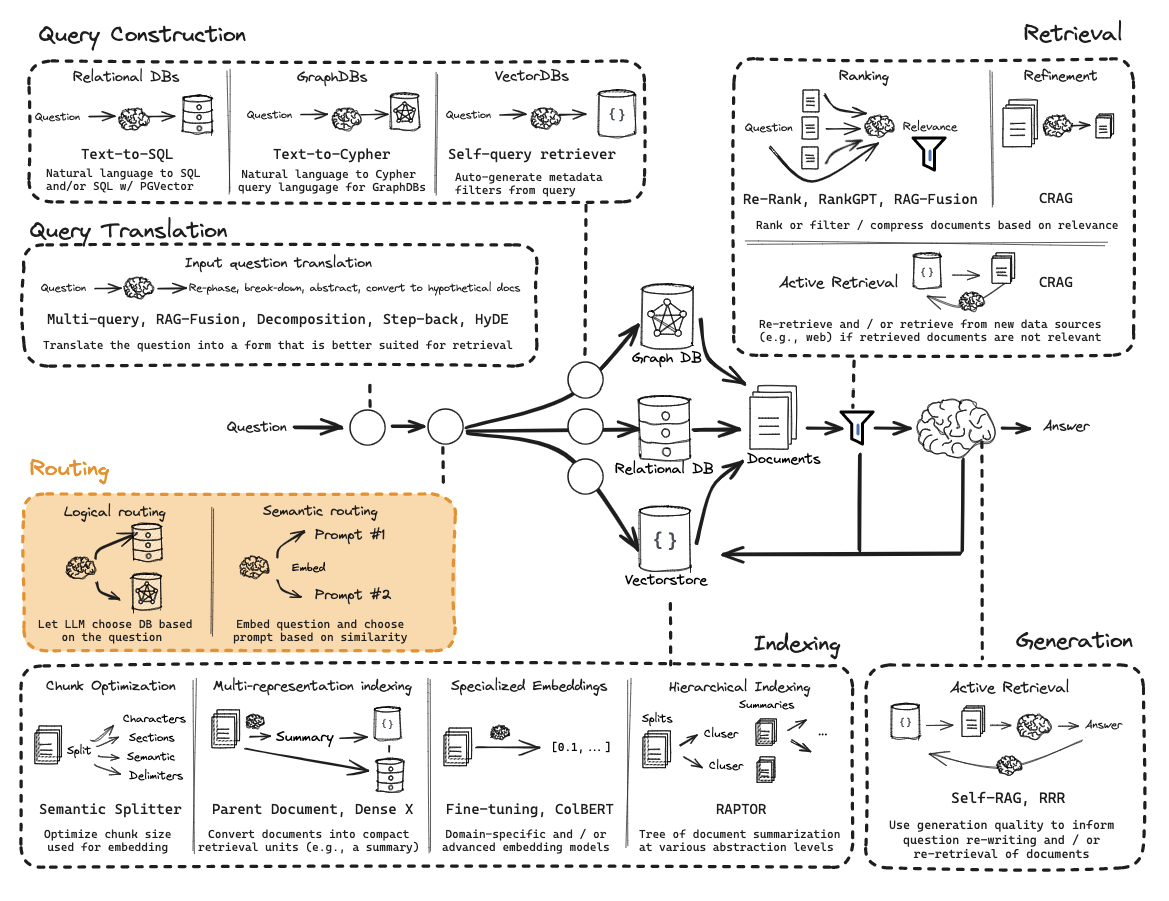
Logical Routing(逻辑路由)
配置不同的数据源以供选择。(Use function-calling for classification)
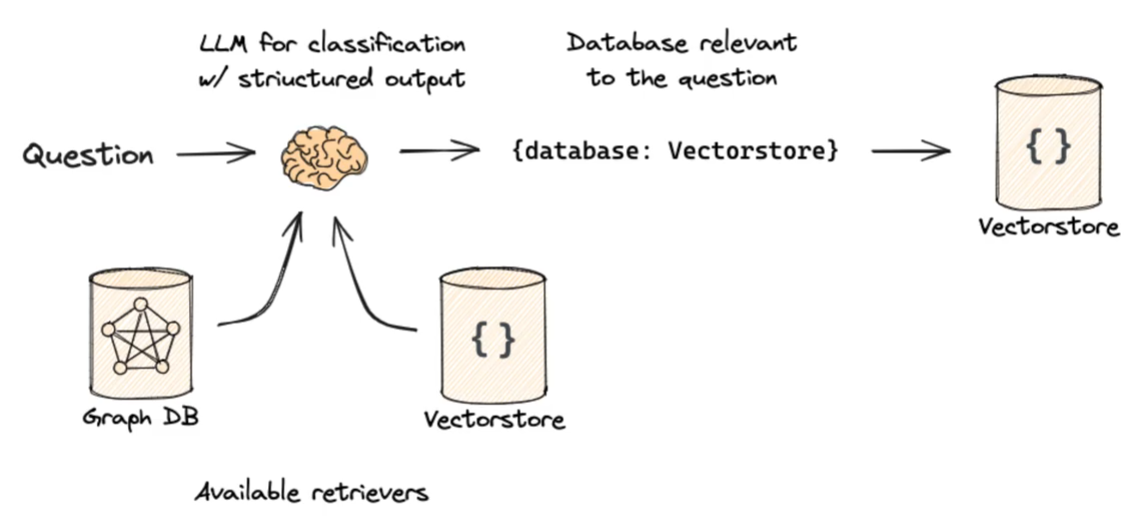
Local routing 本质上是先做分流,把查询路由到最相关的局部知识库、索引或专家模块,而不是对所有资源统一处理。这样可以减少搜索空间,提升检索效率和结果准确性。
上面这个图是一个例子,你可以用这种思想做很多东西

{% note info %}
“这张图展示的是用 function calling 约束 LLM 输出结构化结果的流程。先给模型绑定一个输出 schema,比如 datasource 字段;模型根据问题生成符合 schema 的 JSON;再通过 parser 解析成程序对象,供后续路由或工具调用使用。”
function calling / structured output 的本质,就是先给 LLM 规定好输出格式,再让它按这个格式产出结果,最后程序把结果解析成结构化对象继续执行。
{% endnote %}
{% tabs LogicalRouting , 1 %}
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
# Data model
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field(
...,
description="Given a user question choose which datasource would be most relevant for answering their question",
)
# LLM with function call
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(RouteQuery)
# Prompt
system = """You are an expert at routing a user question to the appropriate data source.
Based on the programming language the question is referring to, route it to the relevant data source."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
# Define router
router = prompt | structured_llm
RouteQuery 这是自己定义的类哈,with_structured_output() 支持直接接收 Pydantic 类作为输出 schema。还有比如说抽取字段(提取里面出现的人、物、时间、地点),生成固定格式结果都是这种。
question = """Why doesn't the following code work:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(["human", "speak in {language}"])
prompt.invoke("french")
"""
result = router.invoke({
"question": question,
"format_instructions": parser.get_format_instructions()
})
# 利用结果做后续操作
def choose_route(result):
if "python_docs" in result.datasource.lower():
### Logic here
return "chain for python_docs"
elif "js_docs" in result.datasource.lower():
### Logic here
return "chain for js_docs"
else:
### Logic here
return "golang_docs"
from langchain_core.runnables import RunnableLambda
full_chain = router | RunnableLambda(choose_route)
# 执行
full_chain.invoke({"question": question})
我觉的这个挺重要,做一个测试吧,用 HuggingFace,但是 HuggingFace 好像还不支持 with_structured_output,因为这个还是部分支持,所以这里用的 PydanticOutputParser 来代替的。这种方式其实也还是加到提示词里面了,手工 prompt + PydanticOutputParser。
{% note warning %}
其实如果把这种结构化输出直接加到 prompt 也是一种办法,但是可靠性比较差,你和它说要 JSON 输出或者从两个选项里面选,最终也有可能不符合要求,概率也挺高的。所以推荐上面这种方式。
{% endnote %}
import os
from getpass import getpass
HUGGINGFACEHUB_API_TOKEN = getpass()
os.environ["HUGGINGFACEHUB_API_TOKEN"] = HUGGINGFACEHUB_API_TOKEN
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
from langchain_huggingface import HuggingFacePipeline, ChatHuggingFace
from langchain_core.output_parsers import PydanticOutputParser
# Data model
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["python_docs", "js_docs", "golang_docs"] = Field(
...,
description="Given a user question choose which datasource would be most relevant for answering their question",
)
# LLM with function call
llm = HuggingFacePipeline.from_model_id(
model_id="LiquidAI/LFM2.5-350M",
task="text-generation",
pipeline_kwargs={
"max_new_tokens": 128,
"do_sample": False,
"return_full_text": False,
}
)
chat = ChatHuggingFace(llm=llm)
parser = PydanticOutputParser(pydantic_object=RouteQuery) # 输出类型
# Prompt
system = """You are an expert at routing a user question to the appropriate data source.
Based on the programming language the question is referring to, route it to the relevant data source.\n
{format_instructions}
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
# Define router
router = prompt | chat | parser
question = """Why doesn't the following code work:
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(["human", "speak in {language}"])
prompt.invoke("french")
"""
result = router.invoke({
"question": question,
"format_instructions": parser.get_format_instructions() # 在这个里面传入
})
result # RouteQuery(datasource='golang_docs')

{% endtabs %}
Semantic routing(语义路由)
配置不同的Prompt进行选择。
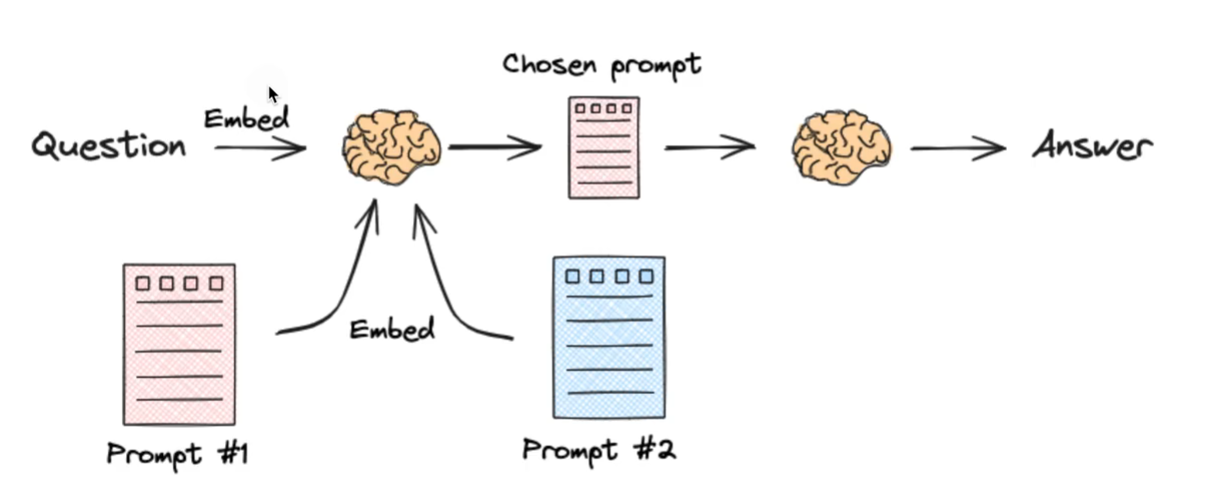
from langchain_community.utils.math import cosine_similarity
from langchain_core.output_parsers import StrOutputParser, PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Two prompts
physics_template = """You are a very smart physics professor. \
You are great at answering questions about physics in a concise and easy to understand manner. \
When you don't know the answer to a question you admit that you don't know.
Here is a question:
{query}"""
math_template = """You are a very good mathematician. You are great at answering math questions. \
You are so good because you are able to break down hard problems into their component parts, \
answer the component parts, and then put them together to answer the broader question.
Here is a question:
{query}"""
# Embed prompts
embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates)
# Route question to prompt
def prompt_router(input):
# Embed question
query_embedding = embeddings.embed_query(input["query"])
# Compute similarity
similarity = cosine_similarity([query_embedding], prompt_embeddings)[0]
most_similar = prompt_templates[similarity.argmax()]
# Chosen prompt
print("Using MATH" if most_similar == math_template else "Using PHYSICS")
return PromptTemplate.from_template(most_similar)
chain = (
{"query": RunnablePassthrough()}
| RunnableLambda(prompt_router)
| ChatOpenAI()
| StrOutputParser()
)
print(chain.invoke("What's a black hole"))
直接用问题跟 Prompt 之间计算余弦相似度来选择 Prompt
{% note success %}
- Logical routing:按规则/逻辑分流
- Semantic routing:按语义/相似度分流
后者这个例子也是用的embedding来选择模版,其实这就少调用了一次LLM选择模版,速度会更快一点。
{% endnote %}
Data model
from pydantic import BaseModel, Field
常见用途
路由
class RouteQuery(BaseModel):
datasource: Literal["python_docs", "js_docs", "golang_docs"]
抽取字段
class MeetingInfo(BaseModel):
person: str
date: str
time: str
topic: str
固定格式回答
class AnswerWithConfidence(BaseModel):
answer: str
confidence: float
嵌套输出
class Step(BaseModel):
explanation: str
output: str
class Solution(BaseModel):
steps: list[Step]
final_answer: str
分类
class TicketType(BaseModel):
category: Literal["complaint", "question", "refund", "technical"]
Field
Field 用来给字段添加额外元数据和约束
class RouteQuery(BaseModel):
datasource: str = Field(...)
这里 ... 表示字段是必填的,不能省略,也支持默认值,动态默认值
class User(BaseModel):
role: str = Field(default="guest")
class User(BaseModel):
id: str = Field(default_factory=lambda: uuid4().hex)
description 是字段说明,这个非常重要
这个不是给你看的,是给大模型看的,是让大模型知道这个字段是什么含义,它才知道怎么提取
class RouteQuery(BaseModel):
datasource: str = Field(
...,
description="The most relevant datasource for answering the user's question"
)
可以写字段含义、允许的值、判断标准、填写规则
examples 主要是增强表达力,帮助模型更稳定的理解格式
class Product(BaseModel):
category: str = Field(
...,
description="Product category",
examples=["laptop", "phone", "tablet"]
)
Literal、Enum
Literal 相当于一个轻量枚举,临时使用
from typing import Literal
datasource: Literal["python_docs", "js_docs", "golang_docs"]
如果经常用到,或者大型项目,还是推荐下面这种写法,更好复用
from enum import Enum
class Source(str, Enum):
python_docs = "python_docs"
js_docs = "js_docs"
golang_docs = "golang_docs"
class RouteQuery(BaseModel):
datasource: Source
Query Construction
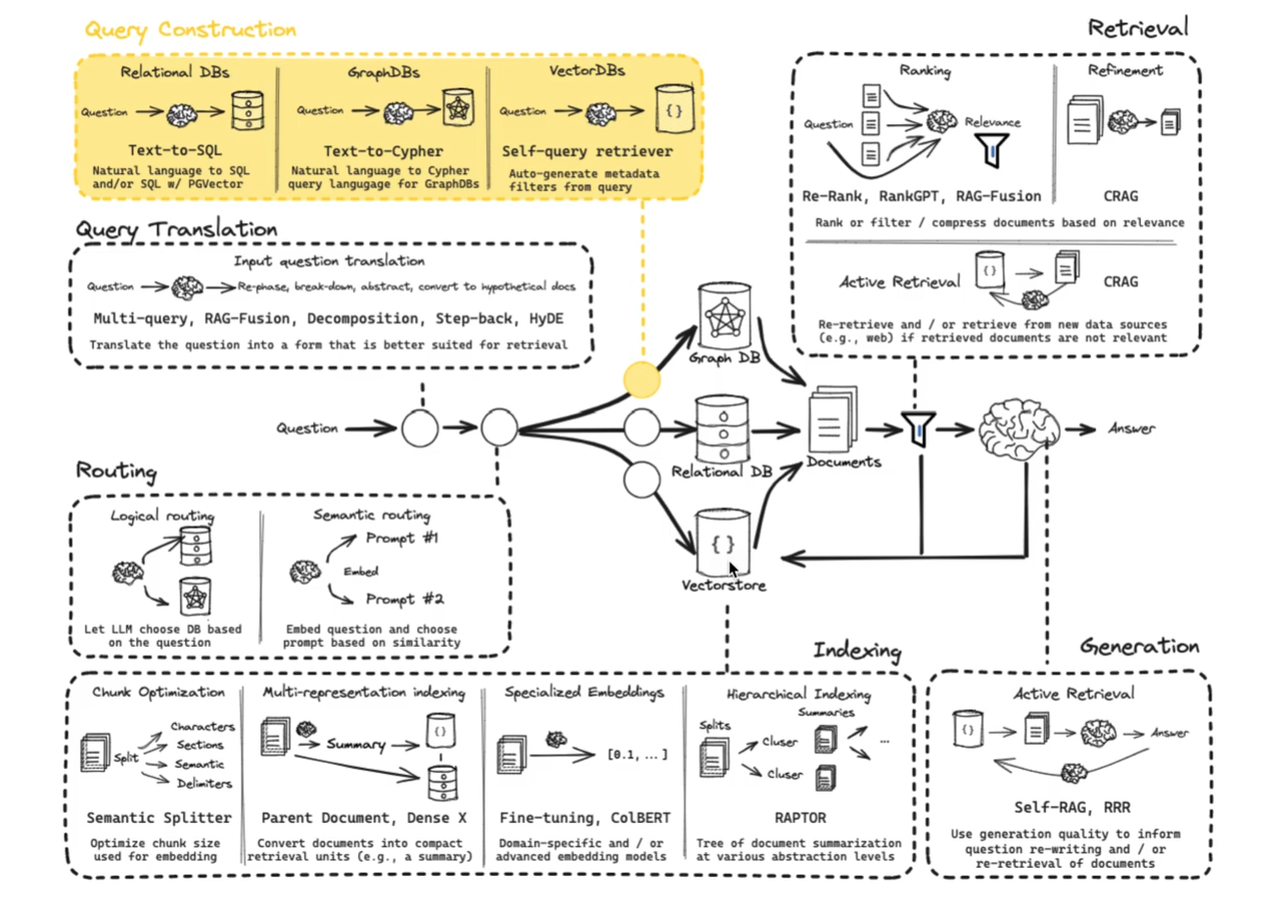
{% note info simple %}
数据可能存储在关系型数据库或图数据库中,根据数据的类型,我们将其分为结构化(SQL 或图数据库)、半结构化(将结构化元素与非结构化元素)和非结构化(向量数据库)三大类。
将自然语言与各种类型的数据无缝连接是一件极具挑战的事情。要从这些库中检索数据,必须使用特定的语法,而用户问题通常都是用自然语言提出的,所以我们需要将自然语言转换为特定的查询语法。这个过程被称为查询构造(Query Construction)。
查询构造主要有三种:Text-to-SQL(关系型数据库)、Text-to-Cypher(图数据库)、Self-Query rertriver(向量数据库),除此之外还有半结构化数据(Text-to-SQL + Semantic)。
{% endnote %}
其中向量数据库中常用的是基于元数据过滤器。
Query structuring for metadata filters 基于元数据查询过滤

许多向量库都包含元数据字段。这使得基于元数据过滤特定块成为可能。
{% note primary %}
元数据过滤器是基于某些特定的元数据属性(如时间、类别、语言、标签等)来限定查询的范围,从而缩小搜索空间,提高检索的精度。
在向量数据库中通常包含两部分元数据字段和主体数据:
- 元数据字段:不向量化,以原始形式(文本、数值、标签等)存储,用于精确过滤。
- 主体数据:需向量化(如文本、图像、音频),转为高维向量后用于相似性搜索。
{% endnote %}
{% note info %}
把自然语言查询解析成结构化检索条件的过程。LLM 根据预定义 schema,从用户问题中提取出内容查询词和元数据过滤条件,比如关键词和时间范围,再由 parser 转成程序对象,用于构造向量数据库查询。
{% endnote %}
# pip install langchain-yt-dlp
from langchain_yt_dlp.youtube_loader import YoutubeLoaderDL
docs = YoutubeLoaderDL.from_youtube_url(
"https://www.youtube.com/watch?v=pbAd8O1Lvm4", add_video_info=True
).load()
docs[0].metadata
{% note warning %}
这里面下载的依赖 langchain-yt-dlp 里的 youtube_loader 文件需要修改一下依赖(源文件代码依赖太老)
# from langchain.document_loaders.base import BaseLoader
# from langchain.schema import Document
from langchain_core.document_loaders.base import BaseLoader
from langchain_core.documents import Document
{% endnote %}
视频元数据如下
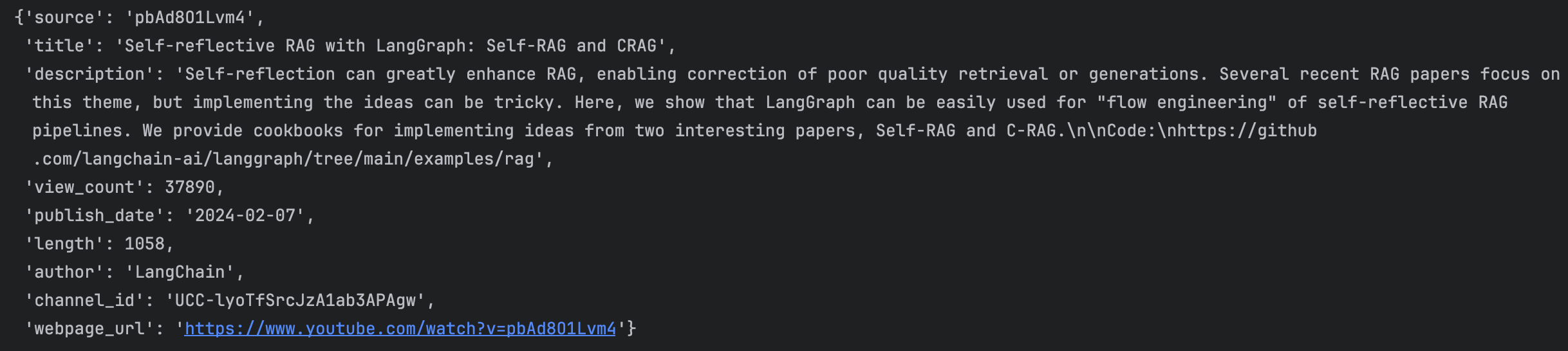
假设我们已经构建了一个索引,它能够:
- 对每个文档的
contents和title进行非结构化搜索 - 并且可以对
view count、publication date和length做区间过滤
我们希望把自然语言转换成结构化的搜索查询。
我们可以为这种结构化搜索查询定义一个 schema。
import datetime
from typing import Literal, Optional, Tuple
from pydantic import BaseModel, Field
class TutorialSearch(BaseModel):
"""Search over a database of tutorial videos about a software library."""
content_search: str = Field(
...,
description="Similarity search query applied to video transcripts.",
)
title_search: str = Field(
...,
description=(
"Alternate version of the content search query to apply to video titles. "
"Should be succinct and only include key words that could be in a video "
"title."
),
)
min_view_count: Optional[int] = Field(
None,
description="Minimum view count filter, inclusive. Only use if explicitly specified.",
)
max_view_count: Optional[int] = Field(
None,
description="Maximum view count filter, exclusive. Only use if explicitly specified.",
)
earliest_publish_date: Optional[datetime.date] = Field(
None,
description="Earliest publish date filter, inclusive. Only use if explicitly specified.",
)
latest_publish_date: Optional[datetime.date] = Field(
None,
description="Latest publish date filter, exclusive. Only use if explicitly specified.",
)
min_length_sec: Optional[int] = Field(
None,
description="Minimum video length in seconds, inclusive. Only use if explicitly specified.",
)
max_length_sec: Optional[int] = Field(
None,
description="Maximum video length in seconds, exclusive. Only use if explicitly specified.",
)
def pretty_print(self) -> None:
for field in self.__fields__:
if getattr(self, field) is not None and getattr(self, field) != getattr(
self.__fields__[field], "default", None
):
print(f"{field}: {getattr(self, field)}")
然后,我们通过给LLM Prompt 创建查询
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Given a question, return a database query optimized to retrieve the most relevant results.
If there are acronyms or words you are not familiar with, do not try to rephrase them."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0)
structured_llm = llm.with_structured_output(TutorialSearch)
query_analyzer = prompt | structured_llm
最终输出就类似下面这种
query_analyzer.invoke({"question": "rag from scratch"}).pretty_print()
# content_search: rag from scratch
# title_search: rag from scratch
query_analyzer.invoke(
{"question": "videos on chat langchain published in 2023"}
).pretty_print()
# content_search: chat langchain
# title_search: chat langchain
# earliest_publish_date: 2023-01-01
# latest_publish_date: 2024-01-01
{% note danger %}
很重要的一点,你写的基本上都是针对某个数据库,比如 MySQL,Oracle,FAISS 等,每个数据库语法都是有差距的。
{% endnote %}
索引生成优化
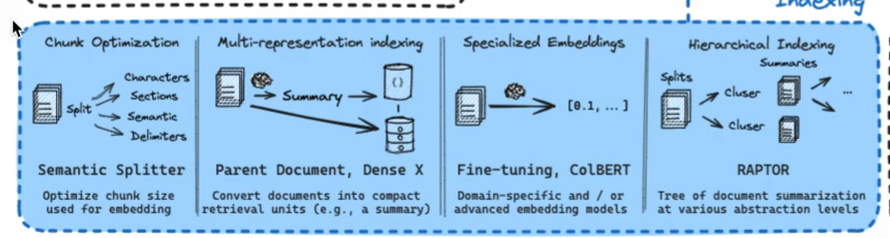
- 分块策略(Chunking)简单,更好的存储数据 split,chunk,overlap(简单而直观的数据分割存储方法)。有多种分块方法,可以分解多种格式的文件,以及Embedding模型。
- 多重表示索引(Multi-representation Indexing),先生成文档摘要(“命题”)。再进行进行相似性搜索,但将完整文档返回给LLM进行生成 。
- 专用嵌入(Specialized Embeddings),为文档生成特定的向量嵌入,便于高效的相似性计算。例如使用Colbert专一领域的生成索引的方式。
LangChain & Colbert = RAGatouille - 分层索引(Hierarchical Indexing),构建多层次的摘要索引树,将文档在不同抽象层次上进行摘要。
Multi-representation Indexing(多重表示索引)
文档通常不是全文字的,比如里面还有图片、表格,这些很难处理,该怎么搞出来呢。有一个就是专门做这个的 https://unstructured.io/
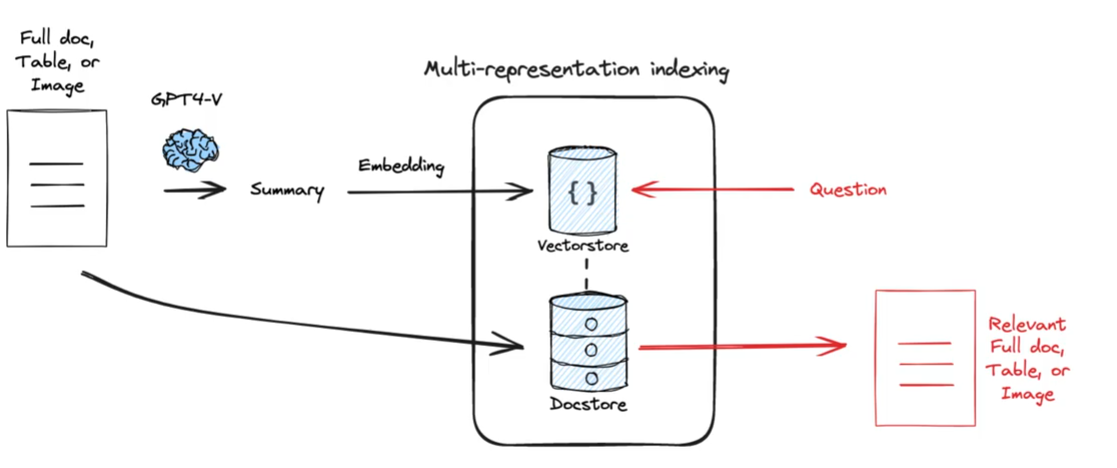
很久之前 LangChain 就提过这个问题,博客如下
Multi-Vector Retriever for RAG on tables, text, and images
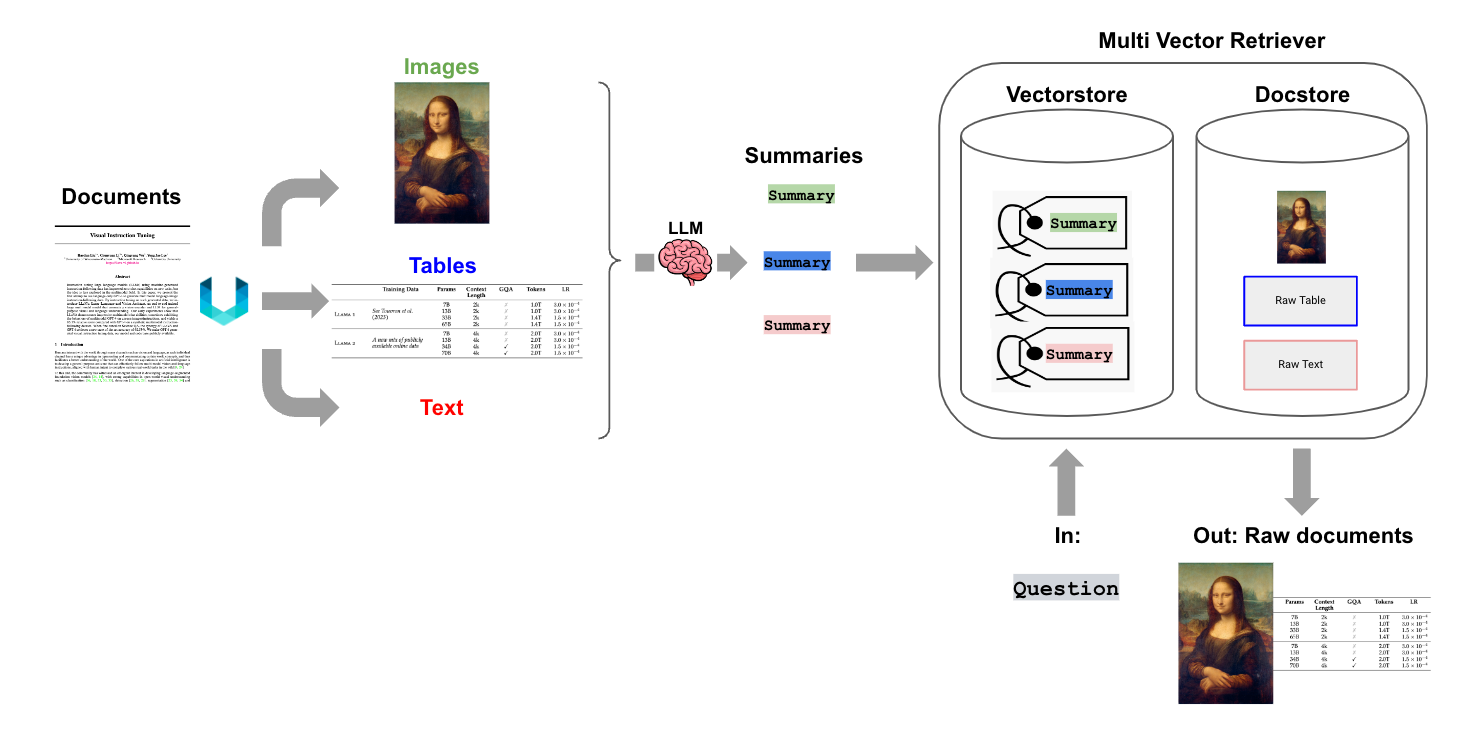
整体思路就是,用比如 Unstructured 提取文字、表格、图片,然后用 LLM 做一个摘要提取(文字可以不做摘要),生成文字摘要描述,然后向量化再进行后续检索,当然原来的文字、表格、图片都要完整保存一份。这样的话,其实无论是文字还是图片、表格,真正使用的时候,你想返回 summary 的也可以,想返回完整的的也可以。
代码未测试哦~
{% tabs 多重索引表示 , 1 %}
pip install unstructured[all-docs] pydantic lxml langchainhub
Unstructured 用于 PDF 分块时会使用:
tesseract:用于光学字符识别(OCR)poppler:用于 PDF 渲染和处理
brew install tesseract
brew install poppler
解析 PDF 中的表格和文本
应用到 LLaMA2 论文。
我们使用 Unstructured 的 partition_pdf,它通过使用版面布局模型来对 PDF 文档进行分段。
这个版面模型使得从 PDF 中提取表格等元素成为可能。
我们还可以使用 Unstructured 的分块(chunking)功能,它会:
- 尝试识别文档章节(例如 Introduction 等)
- 然后在保留章节结构的同时,按照用户定义的块大小构建文本块
path = "/Users/rlm/Desktop/Papers/LLaMA2/"
from typing import Any
from pydantic import BaseModel
from unstructured.partition.pdf import partition_pdf
# Get elements
raw_pdf_elements = partition_pdf(
filename=path + "LLaMA2.pdf",
# Unstructured first finds embedded image blocks
extract_images_in_pdf=False,
# Use layout model (YOLOX) to get bounding boxes (for tables) and find titles
# Titles are any sub-section of the document
infer_table_structure=True,
# Post processing to aggregate text once we have the title
chunking_strategy="by_title",
# Chunking params to aggregate text blocks
# Attempt to create a new chunk 3800 chars
# Attempt to keep chunks > 2000 chars
max_characters=4000,
new_after_n_chars=3800,
combine_text_under_n_chars=2000,
image_output_dir_path=path,
)
我们可以查看 partition_pdf 提取出来的元素。CompositeElement 是聚合后的文本块。
# Create a dictionary to store counts of each type
category_counts = {}
for element in raw_pdf_elements:
category = str(type(element))
if category in category_counts:
category_counts[category] += 1
else:
category_counts[category] = 1
# Unique_categories will have unique elements
unique_categories = set(category_counts.keys())
category_counts
# 把 partition_pdf 解析出来的元素,重新分成“表格”和“文本”两类。
class Element(BaseModel):
type: str
text: Any
# Categorize by type
categorized_elements = []
for element in raw_pdf_elements:
if "unstructured.documents.elements.Table" in str(type(element)):
categorized_elements.append(Element(type="table", text=str(element)))
elif "unstructured.documents.elements.CompositeElement" in str(type(element)):
categorized_elements.append(Element(type="text", text=str(element)))
# Tables
table_elements = [e for e in categorized_elements if e.type == "table"]
print(len(table_elements))
# Text
text_elements = [e for e in categorized_elements if e.type == "text"]
print(len(text_elements))
多向量检索器(Multi-vector retriever)
使用 multi-vector-retriever 来为表格生成摘要,也可以选择对文本生成摘要。
在保存摘要的同时,我们也会保存原始表格元素(raw table elements)。
这些摘要用于提升检索质量,具体原理可参考 multi vector retriever 的相关文档。
原始表格会传递给 LLM,这样 LLM 在生成答案时就能获得完整的表格上下文。
摘要(Summaries)
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
我们为每个元素创建一个简单的摘要链(summarize chain)。
你也可以在 Hub 中查看、复用或修改这个 prompt:
from langchain import hub
obj = hub.pull("rlm/multi-vector-retriever-summarization")
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. Table or text chunk: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature=0, model="gpt-4")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Apply to tables
tables = [i.text for i in table_elements]
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
# Apply to texts
texts = [i.text for i in text_elements]
text_summaries = summarize_chain.batch(texts, {"max_concurrency": 5})
使用带摘要的 Multi Vector Retriever
InMemoryStore用来存储原始文本和表格vectorstore用来存储嵌入后的摘要
import uuid
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
# 用于索引子块(child chunks)的向量库
vectorstore = Chroma(
collection_name="summaries",
embedding_function=OpenAIEmbeddings()
)
# 父文档(parent documents)的存储层
store = InMemoryStore()
id_key = "doc_id"
# 检索器(初始为空)
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
docstore=store,
id_key=id_key,
)
# Add texts
doc_ids = [str(uuid.uuid4()) for _ in texts]
summary_texts = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(text_summaries)
]
retriever.vectorstore.add_documents(summary_texts)
retriever.docstore.mset(list(zip(doc_ids, texts)))
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content=s, metadata={id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
# 检索是用的向量库,返回的是从 docstore 里取回来的原始文本块/表格
docs = retriever.invoke("What does the paper say about instruction tuning?")
{% endtabs %}
PAPTOR(递归检索与摘要技术)
{% note primary %}
传统的RAG方法通常仅检索较短的连续文本块,这限制了对整体文档上下文的全面理解。散乱的内容详略不一致的很多文档,如何进行有效分类和整理?RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)通过递归嵌入、聚类和总结文本块,构建一个自底向上的树形结构,在推理时从这棵树中检索信息,从而在不同抽象层次上整合长文档的信息。
这是层级性索引的方案其思想在于对文档进行生成聚类摘要,然后将设计成层级性。
{% endnote %}
树形结构构建
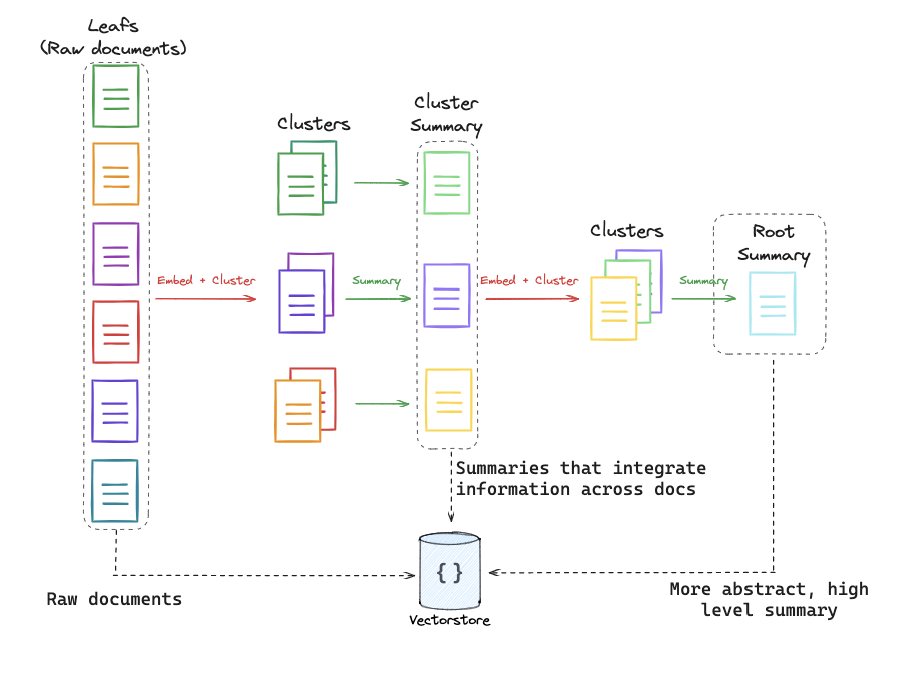
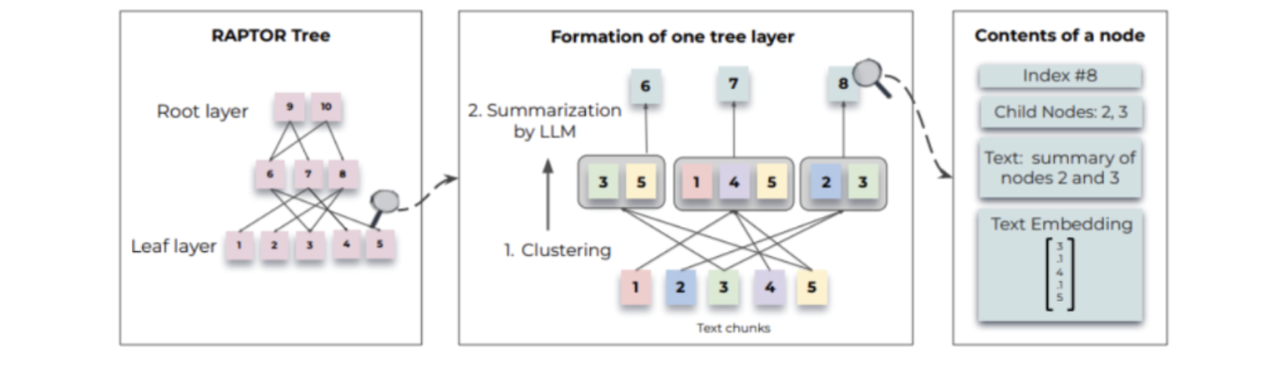
{% note primary %}
- 文本分块:首先将检索语料库分割成短的、连续的文本块。
- 嵌入和聚类:使用SBERT(基于BERT的编码器)将这些文本块嵌入,然后使用高斯混合模型(GMM)进行聚类。
- 摘要生成:对聚类后的文本块使用语言模型生成摘要,这些摘要文本再重新嵌入,并继续聚类和生成摘要,直到无法进一步聚类,最终构建出多层次的树形结构。
{% endnote %}
查询方法
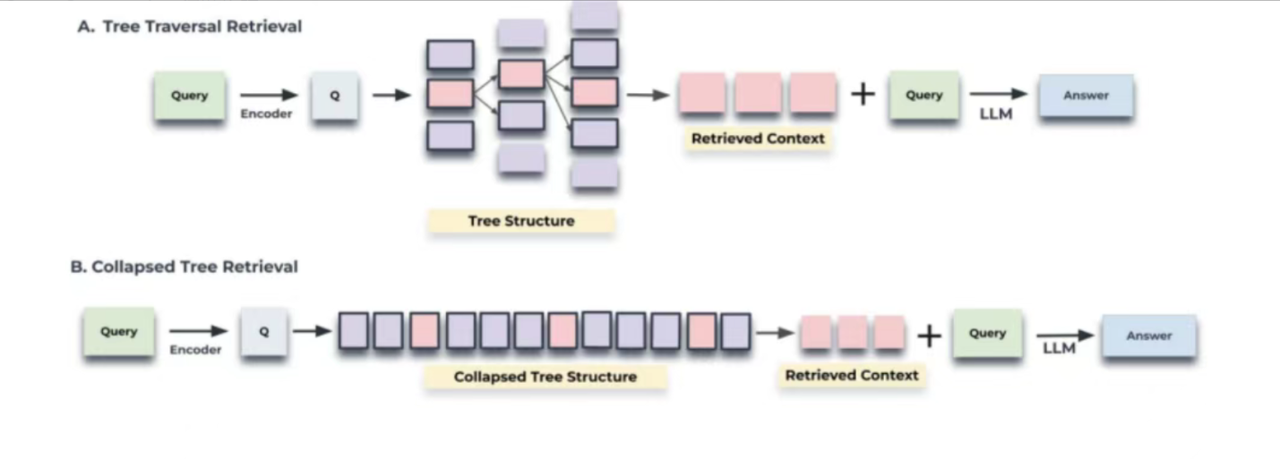
{% note info %}
- 树遍历:从树的根层开始,逐层选择与查询向量余弦相似度最高的节点,直到到达叶节点,将所有选中的节点文本拼接形成检索上下文。
- 平铺遍历:将整个树结构平铺成一个单层,将所有节点同时进行比较,选出与查询向量余弦相似度最高的节点,直到达到预定义的最大token数。
{% endnote %}
适用场景
资料很长、层级很强、答案分散在多处。
更具体一点,RAPTOR 特别适合:
- 长文档问答
比如论文、技术文档、年报、手册、书籍。
因为普通 RAG 往往只检到几个局部 chunk,而 RAPTOR 会先做“分层摘要”,能先抓大意,再往下找细节。 - 需要跨段落、跨章节综合回答的问题
比如不是问一句话能定位到的事实,而是问:
- 这篇论文的核心贡献是什么?
- 这份报告整体风险点有哪些?
- 这个系统设计思路是怎么展开的?
这类问题需要“先看全局,再看局部”,RAPTOR更合适。
- 文档天然有树状结构的时候,比如:
- 书 → 章节 → 小节
- 报告 → 一级标题 → 二级标题
- 技术文档 → 模块 → 子模块
RAPTOR 本身就是“树状摘要 + 检索”的思路,所以和这种材料很匹配。最适合“大文档、多层级、需要全局理解”的检索问答。
ColBERT
用法看官网 LangChain & Colbert = RAGatouille

ColBERT 是一种高效且精细的检索模型。传统检索模型通常在文本层面工作,即把整段文本编码成一个向量,再与查询向量比较相似度。
而 ColBERT 进一步细化到 token 层面:它会为文档中的每个 token 生成一个带上下文信息的向量,也会为查询中的每个 token 生成向量。
在计算文档得分时,ColBERT 会让查询中的每个 token 各自去文档中寻找最相似的 token,并将这些最大相似度加总,作为该文档与查询的相关性分数。
因此,ColBERT 能更细粒度地捕捉查询和文档之间的匹配关系,通常比单向量表示更准确。
人话就是原来是根据语句的相似性,现在更细粒度了,到词了。
适用场景
短查询、细粒度匹配、对检索精度要求高。
-
关键词很关键的场景
比如专业术语、报错信息、函数名、药名、型号名。
因为 ColBERT 是 token 级匹配,不是整段压成一个向量,所以更容易抓住这些关键字。 -
查询和答案是“局部强匹配”的场景
比如问题里有几个核心词,而文档里刚好某一小段、某几个词特别对应。
这种时候,普通 dense retrieval 可能觉得“整段不够像”,但 ColBERT 能发现“某几个词特别像”。 -
高精度检索 / 重排序场景
它很适合做 first-stage retrieval 之后的 rerank,或者直接用于高质量检索。
因为它比“整段一个向量”更细,所以通常更准,但代价也更高。 -
文档很多,但每条文档不一定很长的场景
比如知识库、FAQ、网页段落、检索库里的 passage。
ColBERT 本来就很适合 passage retrieval。
RAPTOR 更擅长“先看全局再找细节”,ColBERT 更擅长“盯住关键词和局部匹配,精确地找”。
Retrieval检索
Retrieval 检索优化策略
完成对问题的改写、不同知识库查询的构建以及路由分发、查询构建和索引生成优化之后可以进一步优化Retrieval检索。包括Ranking、Refinement以及Adaptive retrival。
Retrieval检索
首先需要先检索,之后再进行后面的Ranking、Refinement和Adaptive retrival操作。先来说一下检索:检索是在索引的基础上进行查询的,所以检索方式和索引结构分不开。构建索引的目的是为了更快的检索,检索器可以针对单个索引,也可以组合不同检索技术,主要有以下的几种类型:
父文档检索(Parent Document Retrieval)
当我们对文档进行分块的时候,我们可能希望每个分块不要太长,因为只有当文本长度合适,嵌入才可以最准确地反映它们的含义,太长的文本嵌入可能会失去意义;但是在将检索内容送往大模型时,我们又希望有足够长的文本,以保留完整的上下文。为了实现二者的平衡,有以下三种方式实现父文档检索:
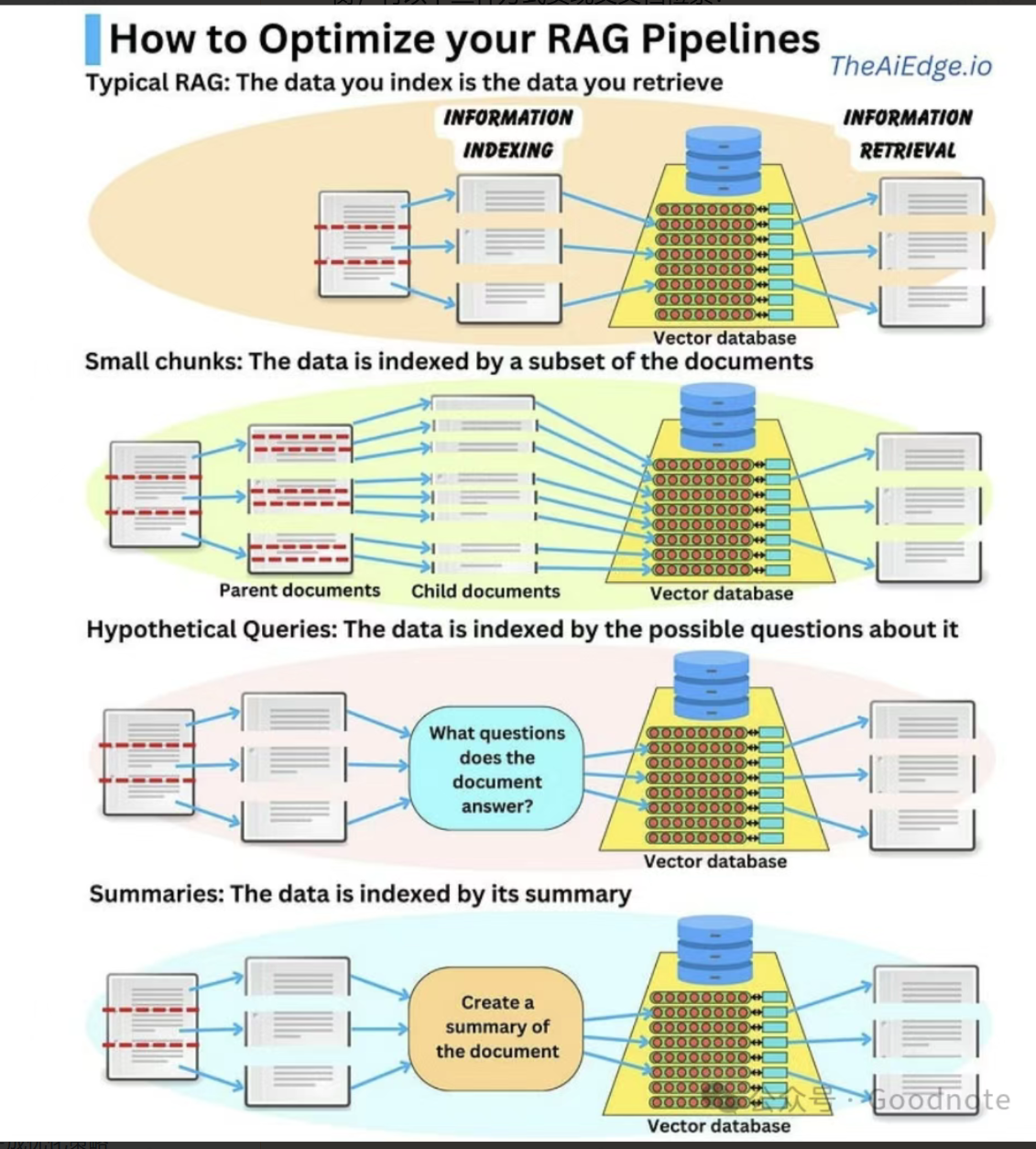
- 可以在检索过程中,首先获取小的分块,然后查找这些小分块的父文档,并返回较大的父文档,这里的父文档指的是小分块的来源文档,可以是整个原始文档,也可以是一个更大的分块。RAG基础-父文档检索
- 使用大模型对文档进行摘要,然后对摘要进行嵌入和检索,这种方法对处理包含大量冗余细节的文本非常有效,这里的原始文档就相当于摘要的父文档。RAG全链路-多重表示索引
- 通过大模型为每个文档生成假设性问题(Hypothetical Questions),然后对问题进行嵌入和检索,也可以结合问题和原文档一起检索,这种方法提高了搜索质量,因为与原始文档相比,用户查询和假设性问题之间的语义相似性更高。
层级检索(Hierarchical Retrieval)
有大量的文档需要检索,为了高效地在其中找到相关信息,一种高效的方法是创建两个索引:一个由摘要组成,另一个由文档块组成,然后分两步搜索,首先通过摘要筛选出相关文档,然后再在筛选出的文档中搜索。RAG全链路-PAPTOR
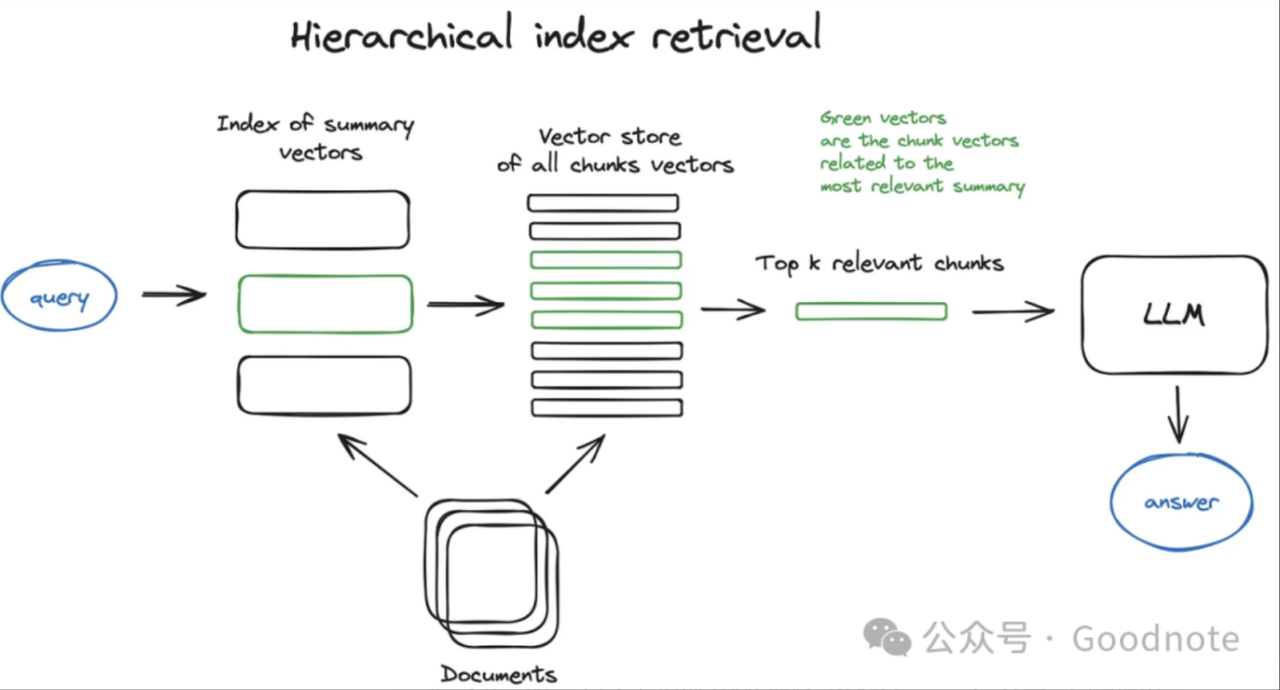
混合检索(Fusion Retrieval)
RAG 融合(RAG Fusion) 技术,它根据用户的原始问题生成意思相似但表述不同的子问题并检索。其实,还可以结合不同的检索策略,最常见的做法是将基于关键词的老式搜索和基于语义的现代搜索结合起来。
- 基于关键词的搜索又被称为稀疏检索器(sparse retriever),通常使用 BM25、TF-IDF 等传统检索算法;
- 基于语义的搜索又被称为密集检索器(dense retriever),使用的是现在流行的 Embedding 算法。
通常结合了稀疏检索(Sparse Retrieval) 和稠密检索(Dense Retrieval) 的策略,通常可以兼顾两种检索方式的优势,提高检索的效果和效率。两种方法的详细解释如下:
- 稀疏检索(Sparse Retrieval):这种方法通常基于倒排索引(Inverted Index),对文本进行词袋(Bag-of-Words)、BM25或者TF-IDF表示,然后按照关键词的重要性对文档进行排序。稀疏检索的优点是速度快,可解释性强,但在处理同义词、词语歧义等语义问题时效果有限。
- 稠密检索(Dense Retrieval):这种方法利用深度神经网络,将查询和文档映射到一个低维的稠密向量空间,然后通过向量相似度(如点积、余弦相似度)来度量查询与文档的相关性。稠密检索能更好地捕捉语义信息,但构建向量索引的成本较高,检索速度也相对较慢。
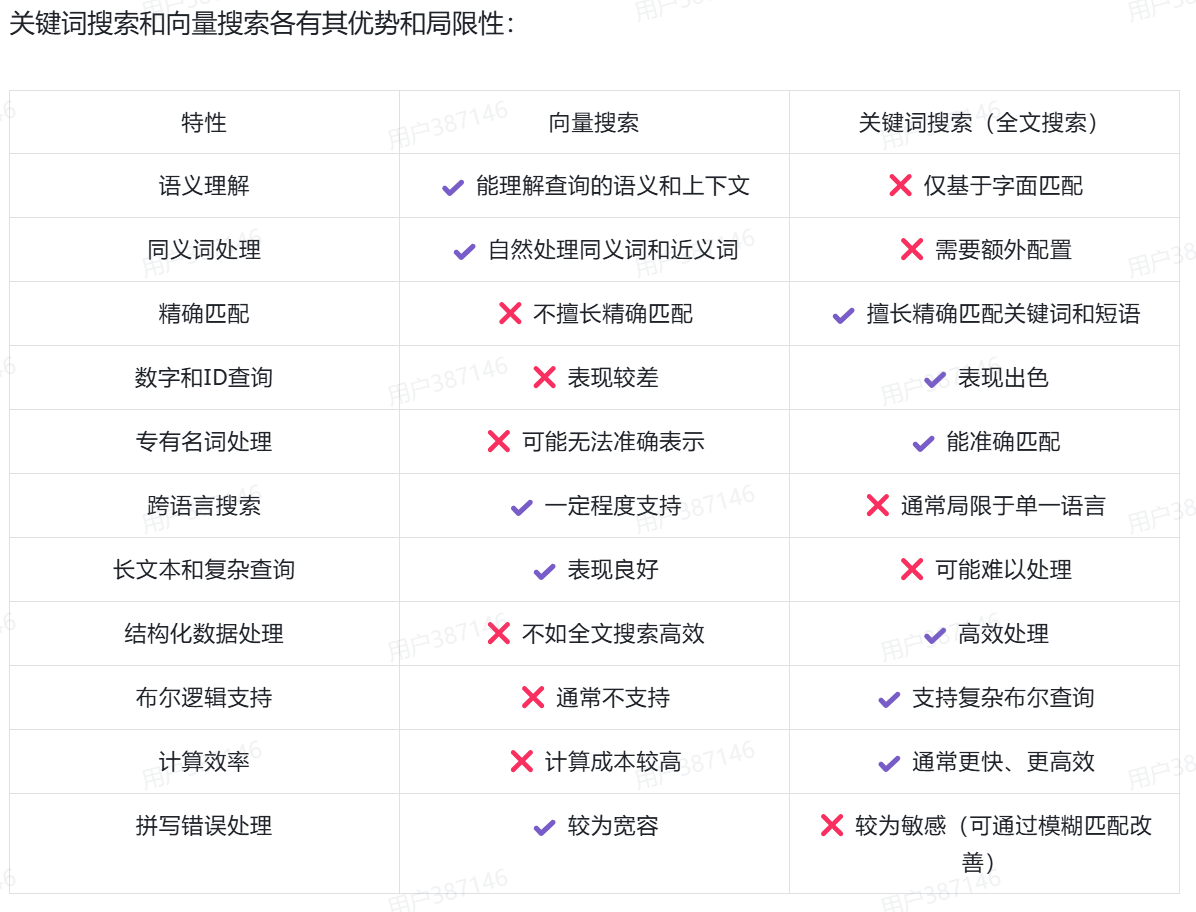
{% note info %}
在实际RAG系统的开发中,现实通常是各种情况都有,难以使用一种搜索方法解决全部问题。用户的查询可能涵盖广泛的类型,从精确的关键词匹配到抽象的概念探索,再到专业领域的术语搜索。同时,知识库中的数据也可能是多样化的,包含结构化和非结构化信息、数字数据、专有名词等。面对这些复杂的需求,仅依赖向量搜索或全文搜索中的一种往往会导致检索结果的不准确。这就是为什么在现代RAG系统中,混合搜索方法变得越来越重要的原因。
{% endnote %}
{% note success %}
混合搜索的工作原理:
- 并行执行:
- 对每个查询,系统同时执行向量搜索和全文搜索。
- 向量搜索捕捉查询的语义内容。
- 全文搜索处理关键词匹配和精确查找。
- 结果融合:
- 使用特定算法将两种搜索的结果合并成一个统一的结果集。
- 最常用的方法之一是倒数排名融合(Reciprocal Rank Fusion,RRF)算法。RRF
{% endnote %}
实现权重平衡的办法,可以通过直接调整经典RRF公式中的k值来实现。在经典RRF公式中,K为常数,建议设为60。实际这个K是可调的,通过调整k值,我们可以有效地改变关键词搜索和向量搜索的相对重要性权重,从而使RRF算法获得更好的性能。
直接修改k值是对RRF公式增加权重平衡的最简单方法,易于实施和调整,适合快速优化和实验。2023年5月,来自向量数据库初创企业Pinecone和伯克利的研究人员共同发表了论文,提出了一种新的混合搜索算法,称为TM2C2(Theoretical Min-Max Convex Combination),论文中,我们看到TM2c2算法有如下几个优势:
- 稳定性:相比传统的 min-max 归一化,TM2C2 更稳定。
- 性能:在大多数数据集上,TM2C2 优于 RRF 和其他基线方法。
- 可解释性:α 参数直观地表示了语义搜索和关键词搜索的相对重要性。
- 样本效率:只需要很少的训练样本就能调整到较好的性能。
TM2c2 算法实际上是RRF引入权重参数和归一函数后的变体。这一变化为特定场景下,混合搜索的性能提升提供了更多的可能性。
多向量检索(Multi-Vector Retrieval)
RAG全链路-多重表示索引
对于同一份文档,可以有多种嵌入方式,也就是为同一份文档生成几种不同的嵌入向量,这在很多情况下可以提高检索效果,这被称为多向量检索器(Multi-Vector Retriever)。为同一份文档生成不同的嵌入向量有很多策略可供选择,上面所介绍的父文档检索就是比较典型的方法。
当我们处理包含文本和表格的半结构化文档时,多向量检索器也能派上用场,在这种情况下,可以提取每个表格,为表格生成适合检索的摘要,但生成答案时将原始表格送给大模型。有些文档不仅包含文本和表格,还可能包含图片,随着多模态大模型的出现,我们可以为图像生成摘要和嵌入。
LangChain的 https://blog.langchain.com/semi-structured-multi-modal-rag/ 对多向量检索做了一个全面的描述,并提供了大量的示例,用于表格或图片等多模任务的检索。
{% note danger %}
注意:父文档检索和层级检索很相似,其区别在于父文档检索只检索一次摘要,然后由摘要扩展出原始文档,而层级检索是通过检索摘要筛选出一批文档,然后在筛选出的文档中执行二次检索。
多向量检索(Multi-Vector Retriever)是更大的框架;父文档检索和层级检索都可以看成它的具体实现或相关变体。
多向量检索强调的是同一份原始文档可以有多个检索表示,比如 chunk、摘要、表格说明、图片描述等;父文档检索是其中一种常见形式,它通常检索子块但返回父文档;层级检索则更强调多阶段检索流程,先用高层摘要筛选候选文档,再在候选范围内做更细粒度检索。
{% endnote %}
后处理
{% note primary %}
RAG 系统的最后一个问题,如何将检索出来的信息丢给大模型?
检索出来的信息可能过长,或者存在冗余(比如从多个来源进行检索),我们可以在后处理步骤中对其进行上下文压缩RAG基础-集成检索器、排序RAG基础-上下文重排 RAG全链路-Reranking重排去重等。LangChain 中并没有专门针对后处理的模块,文档也是零散地分布在各个地方,比如 Contextual compression、Cohere reranker 等。
{% endnote %}
Re-ranking 重排
这个之前有介绍过一点 3.2.1 Multi Query(多查询策略)
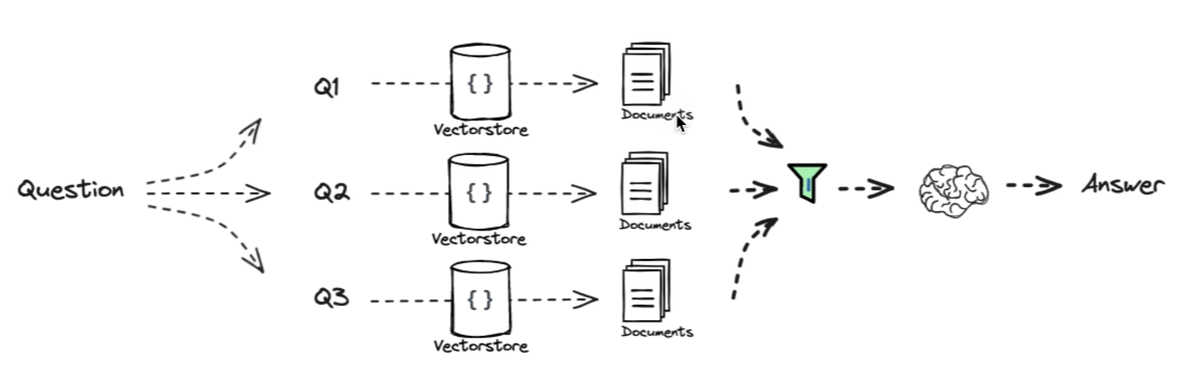
{% note primary %}
检索得到的数据直接提交给LLM去生成答案,但这样存在检索出来的chunks并不一定完全和上下文相关的问题,最后导致大模型生成的结果质量不佳。
这个问题很大程度上是因为召回相关性不够或者是召回数量太少导致的,从扩大召回这个角度思考,借鉴推荐系统做法,引入粗排或重排的步骤来改进效果。重排越来越popular,在上面的过滤策略中,我们经常会用到 Embedding 来计算文档的相似性,然后根据相似性来对文档进行排序(包括Fusion),这里的排序被称为粗排,我们还可以使用一些专门的排序引擎对文档进一步排序和过滤,这被称为精排。每个子问题检索到的文档根据设定的权重进行排序(每个子问题都用到的文档权重更高)。再基于这个权重,选择top-k的文档。
{% endnote %}
解决召回数量太少的方法是原有的top-k向量检索召回扩大召回数目(增大 k 值)
{% note info %}
Rerank主要有两种实现方式:
- 使用一些专门的排序引擎对文档进一步排序和过滤
- 使用大模型来做重排序
{% endnote %}
使用 Cohere 的Re-Rank方案
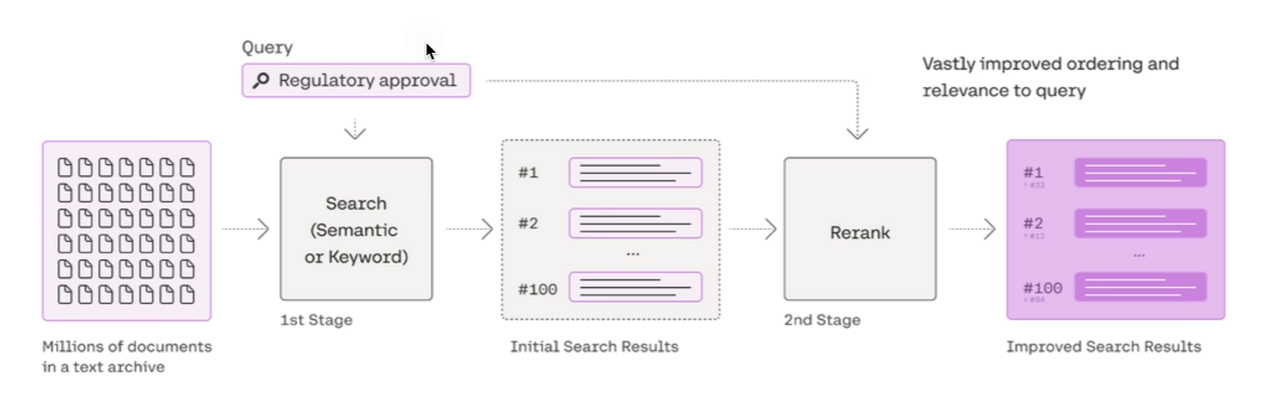
除此之外,排序引擎还有JinaRerank 、SentenceTransformerRerank、Colbert Reranker:
{% note info %}
- Jina AI 总部位于柏林,是一家领先的 AI 公司,提供一流的嵌入、重排序和提示优化服务,实现先进的多模态人工智能。可以使用 Jina 提供的 Rerank API 来对文档进行精排。
- 除了使用商业服务,我们也可以使用一些本地模型来实现重排序。比如 sentence-transformer 包中的 交叉编码器(Cross Encoder) 可以用来重新排序节点。LlamaIndex 默认使用的是
cross-encoder/ms-marco-TinyBERT-L-2-v2模型,这个是速度最快的。为了权衡模型的速度和准确性,请参考 sentence-transformer 文档,以获取更完整的模型列表。 - 另一种实现本地重排序的是 ColBERT 模型,它是一种快速准确的检索模型,可以在几十毫秒内对大文本集合进行基于 BERT 的搜索。
{% endnote %}
官网教程如上,我给一下核心代码
from langchain_cohere import CohereRerank
compressor = CohereRerank(model="rerank-english-v3.0")
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
这里面 base_compressor 不要按字面意思理解为压缩,ContextualCompressionRetriever 是先用 base_retriever 去检索,然后内容再经过 base_compressor 处理,可以进行筛选/重排/压缩。
base_compressor 的定义如下,也就是说,只要是实现了这个接口的都能传进去
base_compressor: BaseDocumentCompressor
"""Compressor for compressing retrieved documents."""
所以,CohereRerank 就可以。
class CohereRerank(BaseDocumentCompressor):
{% note info %}
embedding model 和 reranking model 是两种模型,重排序模型是根据Query和文档列表对文档列表进行打分重排序。
{% endnote %}
Retrieval(CRAG)
其本质上是一种Adaptive-RAG策略,实现方式为在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索,即纠对检索文档的自我反思/自我评分,主要采用如下步骤:
{% note primary %}
首先需要知道的是CRAG 发生在retrieval后,即当我们获得到了近似的document(或者说relevant snippets)之后。
然后会进入一个额外的环节,叫Knowledge Correction。在这里呢我们会先对retrieval得到的每一个相关切片snippets进行evaluate,评估一下我们获取到的snippet是不是对问的问题有效?(此处重点:evaluator也是一个LLM)
然后会有三种情况:
- Correct:那就直接进行RAG的正常流程。(不过图中是加了进一步的优化)
- Incorrect:那就直接丢弃掉原来的document,直接去web里搜索相关信息
- Ambiguous:对于模糊不清的,就两种方式都要
那么在最后的generation部分,也是根据三种不同的情况分别做处理。
- 之前是correct,那现在就直接拼接问题和相关文档
- 之前是incorrect,那现在就直接拼接问题和web获取的信息
- 之前是ambiguous,那现在就拼接三个加起来
以上是CRAG的原始大概逻辑,但在Langchain中对此进行了简化:
{% endnote %}
{% note primary %}
在Langchain中只存在两种情况,即:
- 当Incorrect的时候,直接就去web上search了(先经过一个transform_query对问题进行重写,变成更适合web搜索的形式)。
- 当至少有一个文档超过了相关性阈值(Correct),则进入生成阶段。
{% endnote %}
Generation生成优化策略
Retrieval(Self-RAG)
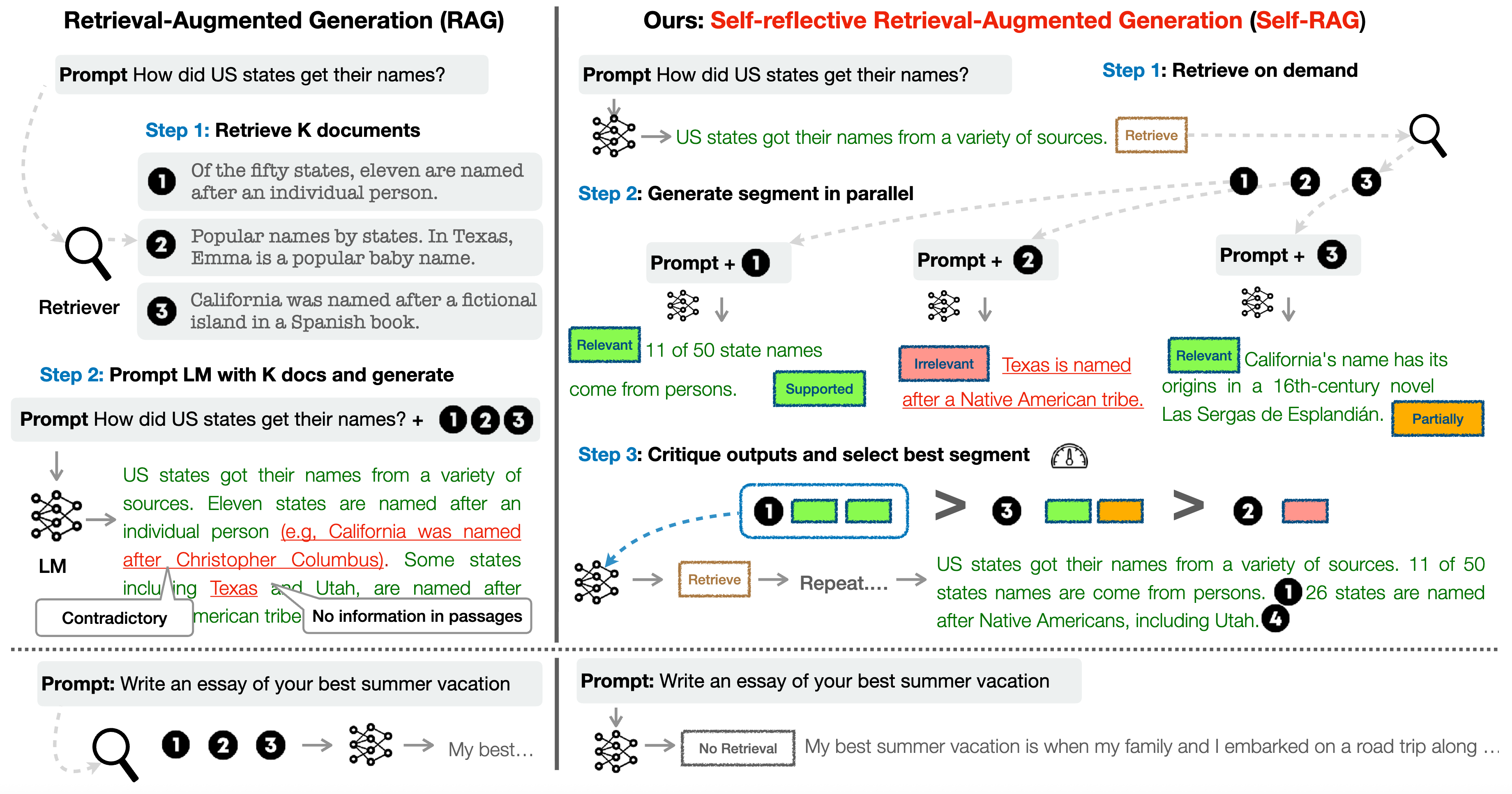
传统 RAG:固定步骤,检索文档–>拼接给大模型–>生成答案
Self-RAG:
- 模型根据用户提问,自己先判断是不是需要去 Retrieve,(你看那个神经网络模型,就代表一次思考)
- 不需要检索,直接去生成结果了
- 需要检索,那再进行第二步
- 生成多个候选答案片段,注意这里不是完整答案
每个答案片段都做一次思考,看看质量如何 - 选择最好的一段,并且继续检索、生成下一段,知道生成完整答案。(图里面前面只有1,2,3),生成的答案有4,代表这是下一轮循环生成的。
这是论文里面提到的。
下面看 LangGraph 实现的 Self-RAG
大概流程:
{% note info %}
和CRAG不一样的是,Self-RAG的流程是从检索前就开始进行的,评估三次。
{% endnote %}
这个图应该没给是否需要检索这个判断
先检索,然后对每个段落判断是否和问题相关(grade_documents),如果不相关,就重写一下问题去重新检索。如果至少有一篇文档相关,就进入生成答案,它这里做了简化,是把所有相关的(前面判断相关的)的文档给模型,生成答案,不是答案片段,然后再判断答案有没有幻觉(有没有文档支持),有幻觉就基于文档重新生成。最后判断这个答案真的回答了问题吗,有用吗。
这里不是每个 chunk 都生成一遍,减少LLM调用。并且实现上并没有完全按照 Self-RAG,比如没有在开始判断是否需要检索

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)