【论文阅读】保留传递性的图表示学习:连接局部连通性与基于角色的相似性
摘要
图表示学习(GRL)方法,如图神经网络和图Transformer模型,已成功用于分析图结构数据,主要聚焦于节点分类和链路预测任务。然而,现有研究大多仅考虑局部连通性,却忽略了长距离连通性和节点的角色。在本文中,我们提出了统一图Transformer网络(UGT),它能将局部和全局结构信息有效整合到固定长度的向量表示中。
首先,UGT通过识别局部子结构并聚合每个节点的k跳邻域特征来学习局部结构。其次,我们构建虚拟边,连接具有结构相似性的远距离节点,以捕捉长距离依赖关系。第三,UGT通过自注意力机制学习统一表示,对节点对之间的结构距离和p步转移概率进行编码。此外,我们还提出了一项自监督学习任务,该任务能有效学习转移概率,以融合局部和全局结构特征,这些特征随后可迁移到其他下游任务中。
在真实世界的基准数据集上针对各种下游任务进行的实验结果表明,UGT显著优于由最先进模型组成的基线模型。此外,在区分非同构图对方面,UGT达到了三阶Weisfeiler-Lehman同构测试(3d-WL)的表达能力。源代码可在https://github.com/NSLab-CUK/Unified-Graph-Transformer获取。
Keywords Graph Transformer · Graph Representation Learning · Structure-Preserving Graph Transformer · Local Connectivity · Role-based Similarity
1 引言
图神经网络(GNNs)和图Transformer已有效解决了图分析任务,如节点分类和链路预测[1,2,3]。GNNs通过迭代聚合具有均匀或注意力权重的邻节点特征来学习表示[1,4]。与GNNs不同,图Transformer模型利用自注意力机制学习节点表示,对节点间的成对连接进行编码,并且已展现出比GNN变体更优的性能[2]。
尽管现有模型已应用于多个领域,但GNNs和图Transformer仍存在三个固有局限性。首先,图Transformer模型缺乏捕捉局部结构间相似性的能力。一些最新的图Transformer(如GT[2]和SAN[5])使用图结构特征(如拉普拉斯特征向量)作为位置编码(PEs)来区分同构子结构。然而,尽管PEs能为单个节点的子结构分配可区分的表示,但它们并不总能反映子结构之间的结构相似性。考虑子结构相似性的PEs对于模型理解邻居间的连通性(而非简单聚合其特征向量)具有重要意义。在图1中,我们为两个节点“1”和“3”分配拉普拉斯特征向量作为PEs。尽管这两个节点具有相似的局部结构,但其向量表示却不相似。这种不精确性可能严重阻碍图结构表示的学习,并最终影响模型性能。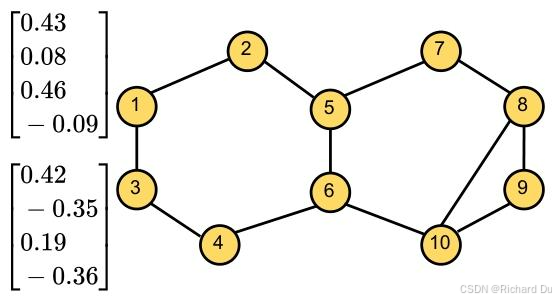
图1:拉普拉斯位置编码无法确保捕捉节点周围结构之间的相似性。两个相邻节点“1”和“3”虽然在结构上相似,但具有不同的位置编码。
其次,GNN聚合器和自注意力机制缺乏学习全局结构特征的能力。GNN变体(如GCN[1]、GAT[6]和GATv2[7,8,9])仅基于邻居特征构建节点嵌入。类似地,图Transformer模型通过自注意力对k跳距离内的节点对和子结构特征进行编码,从而学习节点表示[10,11,12]。尽管图Transformer在一层中的聚合范围比GNNs更大,但邻域聚合仍不足以揭示节点的长距离依赖关系或基于角色的相似性。
第三,现有模型缺乏将局部和全局结构特征整合为统一表示的能力,而这种统一表示可能对各种下游任务有益。例如,社交网络中的有影响力节点会是不同社区的中心,分析这些节点时需同时考虑“影响力(全局)”和“社区(局部)”。一些GNNs和图Transformer(如LSPE[13]和GPS[14])尝试捕捉节点周围k跳距离内的高阶子结构,并将其纳入消息或节点特征中。然而,随着图直径的增大,我们无法无限增大k跳距离。此外,全局结构特征(如长距离依赖关系)与节点角色(即根植于节点的子结构)相关。节点的相似角色并不总是意味着它们相邻或具有相似的节点特征,有时甚至恰恰相反。因此,这些特征的不同视角成为将其整合为统一向量表示的重大障碍。
为克服这些局限性,我们提出了统一图Transformer网络(UGT),它能将图的局部和全局结构特征用统一的向量表示来刻画。我们首先构建虚拟边,连接具有基于角色相似性的远距离节点。通过对包含虚拟边和实际边的k跳邻域进行采样,UGT能够同时观察节点的长距离依赖关系和局部连通性。我们提出了结构标识(一种子结构描述符),并将其用于Transformer层中的标识映射,以保留节点的角色信息。基于子结构描述符估计的结构距离也用于计算注意力分数,以考虑基于角色的相似性。同时,我们使用转移概率来计算注意力分数,以共同考虑邻近性和角色。最后,为弥合局部和全局结构之间的差距,UGT通过预训练来保留p步转移概率,这种概率考虑了两个节点之间的所有路径,并在多个尺度上反映邻近性和周围结构。我们的贡献如下:
- 提出了统一图Transformer网络(UGT),它能够学习局部和全局结构特征,并将其整合为统一表示。
- 我们提出的新颖采样方法在具有高基于角色相似性的节点之间构建虚拟边,并对k跳邻域进行采样,以同时观察长距离依赖关系和局部连通性。
- 提出了预训练任务,通过保留节点间的转移概率来弥合局部和全局结构之间的概念差距,这种转移概率从连接节点的所有路径中反映了节点的连通性和周围结构,且具有多尺度特性。
- 我们通过实验验证,在区分非同构图对方面,UGT达到了与三阶Weisfeiler-Lehman同构测试(3d-WL)相当的表达能力。
2 相关工作
本节将讨论现有研究如何尝试克服上一节中提到的局限性。一些现有的图Transformer尝试通过位置编码(PEs)来揭示相邻节点之间的局部结构相似性。SAN[5]将可学习的位置编码与注意力机制相结合,以学习局部结构。Graphformer[15]将节点度添加到节点特征中,并利用最短路径距离注意力偏置来整合边特征。GPS[14]使用随机游走位置编码(RWPE)为每个目标节点寻找相似的子结构。SAT[10]提取每个目标节点的k跳子图表示,并使用GNNs来更新目标节点的表示。尽管近距离邻居通常比远距离邻居具有更高的重要性[16,17],但现有模型在利用节点周围的子结构或路径考虑局部结构相似性时,并未保留目标节点与上下文节点之间的距离。现有研究与UGT的主要区别在于,我们通过结构标识和距离来描述和考虑子结构,同时保留距离信息。通过对距离的描述,结构标识超越了局部结构描述符的范畴,涵盖了包括节点角色在内的全局结构。
一些现有研究尝试捕捉全局结构特征。WRGAT[18]旨在通过利用节点之间的多种关系来突破GNNs的局限性。GeoGCNs[19]采用多种嵌入方法(如Poincare和Struc2vec),并选择能够保留全局结构特征的最优潜在空间。虽然GNN变体展示出捕捉全局信息的能力,但它们大多忽略了子结构相似性。一些图Transformer(如SAT[10]和Graphformer[15])尝试捕捉k跳距离内的高阶结构[20]。然而,高阶结构是在k跳距离内提取的,忽略了长距离依赖关系,因为k跳距离难以扩展到图的直径范围。与此不同,UGT通过构建虚拟边来连接具有子结构相似性的远距离节点。通过利用虚拟边观察整个图中的子结构出现情况,以及利用实际边观察k跳距离内的子结构共现情况,UGT能够同时学习局部和全局结构。然后,转移概率成为融合这两种特征的媒介。
3 统一图Transformer网络(UGT)
本节将介绍一种新颖的图Transformer模型——统一图Transformer网络(UGT),它能够学习图的局部和全局结构特征,并将这些特征整合为统一的向量表示。我们首先介绍如何采样上下文节点,然后详细描述UGT的设计,最后介绍自监督学习和微调任务。UGT的整体架构如图2所示。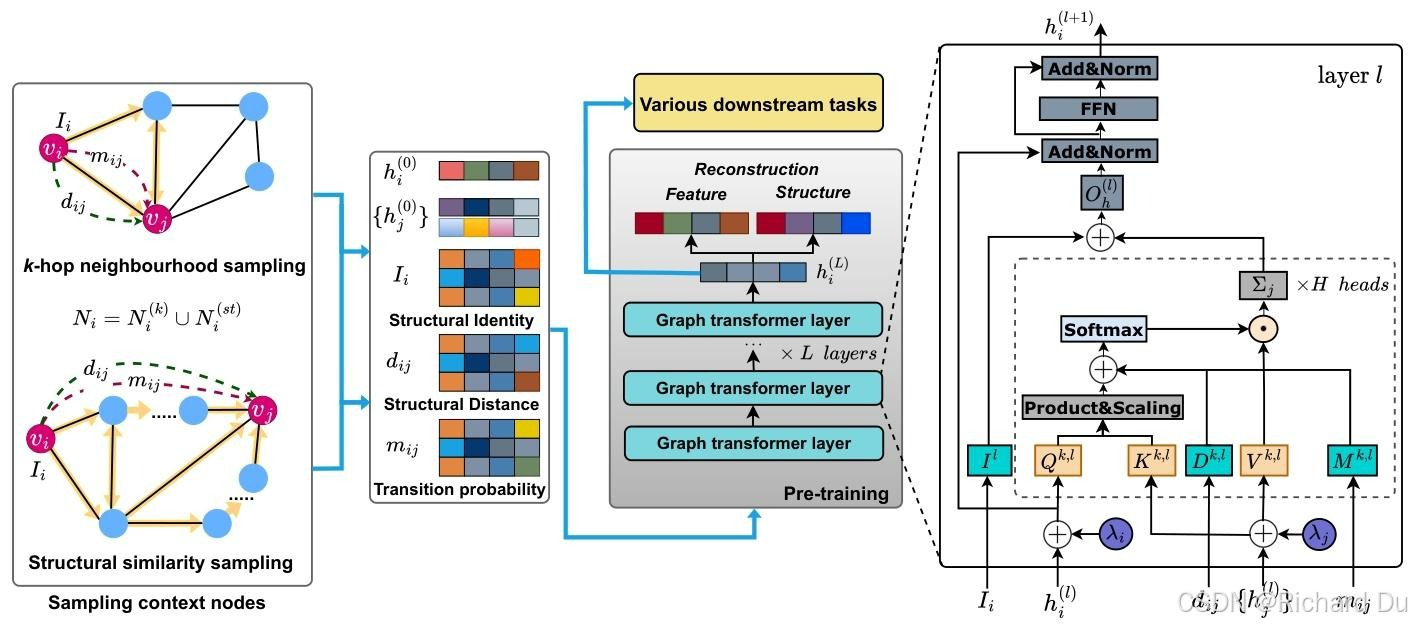
图2:UGT的整体架构。UGT由多个主要模块组成,包括上下文节点采样模块、I、d和m模块的构建以及预训练模块。学习到的表示可用于各种下游任务。
3.1 上下文节点采样
给定一个图G=(V,E)G=(V, E)G=(V,E),其中VVV是节点集,EEE是边集,我们的目标是为每个目标节点vi∈Vv_{i} \in Vvi∈V采样上下文节点vjv_{j}vj。若viv_{i}vi到vjv_{j}vj的距离在kkk跳以内,或者两个节点在结构上相似,则可以对vjv_{j}vj进行采样。形式上,对于每个目标节点viv_{i}vi,其邻居集可定义为:
Ni=Ni(k)∪Ni(st),(1)N_{i}=N_{i}^{(k)} \cup N_{i}^{(s t)}, \quad (1)Ni=Ni(k)∪Ni(st),(1)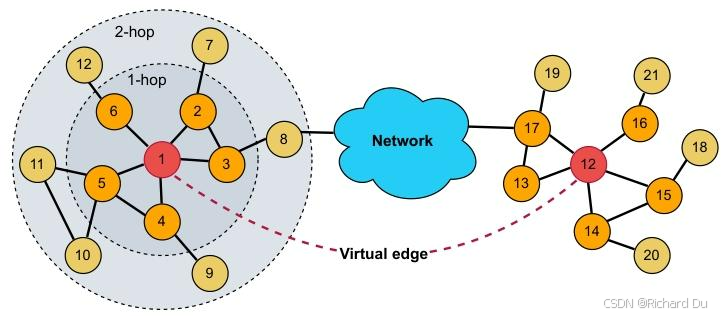
图3:UGT采样策略示例。我们对k跳邻域内的上下文节点进行采样,并在具有结构相似性的远距离节点之间建立虚拟连接。
其中,Ni(k)N_{i}^{(k)}Ni(k)表示viv_{i}vi的kkk跳邻居集,Ni(st)N_{i}^{(s t)}Ni(st)表示与viv_{i}vi结构相似的节点集。图3展示了一个包含目标节点“1”及其上下文的简化图。在全局采样中,若两个节点结构相似,我们会在它们之间构建虚拟边。例如,节点“1”和“12”结构相似,它们的度均为5,且都连接到两个三角形。需要注意的是,我们仅基于图结构来考虑相似性,不使用节点特征。设Ik(vi)I_{k}(v_{i})Ik(vi)表示viv_{i}vi在1到kkk跳范围内的有序度序列集,其中I0(vi)I_{0}(v_{i})I0(vi)为viv_{i}vi的度。通过比较viv_{i}vi和vjv_{j}vj的有序度序列,我们可以赋予一个分数来衡量结构距离。形式上,图中任意两个节点viv_{i}vi和vjv_{j}vj之间的结构距离和分数可定义为:
sk=fk(Ik(vi),Ik(vj)),(2)s_{k}=f_{k}\left(I_{k}\left(v_{i}\right), I_{k}\left(v_{j}\right)\right), \quad (2)sk=fk(Ik(vi),Ik(vj)),(2)
S(vi,vj)=exp(−sk),(3)S\left(v_{i}, v_{j}\right)=\exp \left(-\sqrt{s_{k}}\right), \quad (3)S(vi,vj)=exp(−sk),(3)
其中,fk(⋅,⋅)f_{k}(\cdot, \cdot)fk(⋅,⋅)是两个序列之间的结构距离。与Struc2vec[21]类似,我们使用动态时间规整(DTW)来衡量两个有序度序列之间的距离。然而,在大多数现实世界的网络中,度分布具有高度的不对称性,呈现出长尾分布。为了增强高度数节点之间的连接,我们引入另一个分数:
S(vi,vj)=exp(−sk)+exp(−1(dvi+dvj)),(4)S\left(v_{i}, v_{j}\right)=\exp \left(-\sqrt{s_{k}}\right)+\exp \left(-\frac{1}{\sqrt{\left(d_{v_{i}}+d_{v_{j}}\right)}}\right), \quad(4)S(vi,vj)=exp(−sk)+exp
−(dvi+dvj)1
,(4)
其中,dvid_{v_{i}}dvi表示节点viv_{i}vi的度。因此,分数高的两个节点在结构上更相似,且如果它们同时具有较高的度,那么在潜在空间中它们会更接近。
3.2 学习图的统一表示
3.2.1 输入表示
给定图GGG,节点viv_{i}vi的特征xi∈Rd0×1x_{i} \in R^{d_{0} \times 1}xi∈Rd0×1通过线性投影映射到ddd维隐藏特征x^i0\hat{x}_{i}^{0}x^i0,即:
x^i0=W0xi+b0,(5)\hat{x}_{i}^{0}=W_{0} x_{i}+b_{0}, \quad(5)x^i0=W0xi+b0,(5)
其中,W0∈Rd×d0W_{0} \in R^{d \times d_{0}}W0∈Rd×d0和b0∈Rdb_{0} \in R^{d}b0∈Rd是线性投影的参数,d0d_{0}d0是viv_{i}vi的原始特征维度。
由于我们旨在让UGT能够学习每个节点在整个图中的全局位置信息上下文,因此我们将一个经过线性变换的、维度为kkk的位置嵌入λi\lambda_{i}λi添加到节点特征中,即:
λ^i=W1λi+b1,(6)\hat{\lambda}_{i}=W_{1} \lambda_{i}+b_{1}, \quad (6)λ^i=W1λi+b1,(6)
hi0=x^i0+λ^i,(7)h_{i}^{0}=\hat{x}_{i}^{0}+\hat{\lambda}_{i}, \quad (7)hi0=x^i0+λ^i,(7)
其中,W1∈Rd×kW_{1} \in R^{d \times k}W1∈Rd×k和b1∈Rdb_{1} \in R^{d}b1∈Rd。需要注意的是,位置嵌入是预先计算好的,且仅在第一次添加,我们使用图拉普拉斯矩阵的特征向量作为位置嵌入。此外,在训练过程中,我们会随机翻转λ\lambdaλ,以使UGT能够捕捉符号不变性。
3.2.2 全局结构自注意力
我们提出一种自注意力偏置来编码局部和全局结构信息。由于我们旨在捕捉kkk跳范围内的上下文节点和远距离节点,自注意力需要从kkk跳距离和结构距离的角度理解节点对之间的距离。形式上,对于第lll层的第kkk个注意力头,viv_{i}vi和vjv_{j}vj之间的自注意力定义为:
αijk,l=(Qk,lhil)⋅(Kk,lhjl)dk+Dijk,l+Mijk,l,(8)\alpha_{i j}^{k, l}=\frac{\left(Q^{k, l} h_{i}^{l}\right) \cdot\left(K^{k, l} h_{j}^{l}\right)}{\sqrt{d_{k}}}+D_{i j}^{k, l}+M_{i j}^{k, l}, \quad(8)αijk,l=dk(Qk,lhil)⋅(Kk,lhjl)+Dijk,l+Mijk,l,(8)
其中,Qk,lQ^{k, l}Qk,l、Kk,l∈Rdk×dK^{k, l} \in R^{d_{k} \times d}Kk,l∈Rdk×d,k=1k=1k=1到HHH表示注意力头的数量,hih_{i}hi和hjh_{j}hj分别是节点viv_{i}vi和vjv_{j}vj的特征。Dijk,lD_{i j}^{k, l}Dijk,l和Mijk,l∈Rdk×dM_{i j}^{k, l} \in R^{d_{k} \times d}Mijk,l∈Rdk×d是两个节点viv_{i}vi和vjv_{j}vj之间的结构距离dijd_{i j}dij和转移概率mijm_{i j}mij的线性变换。下面我们介绍构建ddd和mmm的策略。
我们基于分层的角色信息来定义每个目标节点的结构标识,这些信息包括每个节点viv_{i}vi在kkk跳距离上下文中的度的最小值、最大值、平均值和标准差。形式上,节点viv_{i}vi的结构标识和结构距离可定义为:
Ii={dvi,T1,T2,⋯ ,Tk},(9)I_{i}=\left\{d_{v_{i}}, T_{1}, T_{2}, \cdots, T_{k}\right\}, \quad (9)Ii={dvi,T1,T2,⋯,Tk},(9)
dij=f([∥Ii(q)−Ij(q)∥2]−1),(10)d_{i j}=f\left(\left[\left\| I_{i}^{(q)}-I_{j}^{(q)}\right\| _{2}\right]^{-1}\right), \quad (10)dij=f([
Ii(q)−Ij(q)
2]−1),(10)
其中,dvid_{v_{i}}dvi表示节点viv_{i}vi的度,Tk={mink,maxk,μk,δk}T_{k}=\{min _{k}, max _{k}, \mu_{k}, \delta_{k}\}Tk={mink,maxk,μk,δk}表示第kkk跳距离处节点度的最小值、最大值、平均值和标准差的集合,Ii(q)I_{i}^{(q)}Ii(q)表示IiI_{i}Ii的第qqq个元素,fff表示线性变换后的结构距离。
虽然结构距离有助于模型找到具有结构相似性的远距离节点,但它无法捕捉两个节点之间的路径。为了弥补这一不足,我们提出基于转移概率的距离mmm,它从概率角度反映了任意两个节点之间的连接性。通过这种方式,UGT能够捕捉局部和全局结构信息,从而具备捕捉节点之间任何路径的能力。我们将从viv_{i}vi到vjv_{j}vj的转移概率距离mmm定义为:
mij=f(Aij1,Aij2,⋯ ,Aijp),(11)m_{i j}=f\left(A_{i j}^{1}, A_{i j}^{2}, \cdots, A_{i j}^{p}\right), \quad (11)mij=f(Aij1,Aij2,⋯,Aijp),(11)
其中,AijpA_{i j}^{p}Aijp表示ppp步内从viv_{i}vi到vjv_{j}vj的转移概率,fff表示线性变换后的转移概率。
3.2.3 图Transformer层
自注意力的输出被连接成一个向量表示,然后进行线性变换。在第lll层,节点viv_{i}vi的特征更新为:
h^il+1=Ohl∥k=1H(∑vj∈N(vi)α‾ijk,lVk,lhjl),(12)\hat{h}_{i}^{l+1}=O_{h}^{l} \| _{k=1}^{H}\left(\sum_{v_{j} \in N\left(v_{i}\right)} \overline{\alpha}_{i j}^{k, l} V^{k, l} h_{j}^{l}\right), \quad(12)h^il+1=Ohl∥k=1H
vj∈N(vi)∑αijk,lVk,lhjl
,(12)
其中,α~ijk,l=softmaxj(αijk,l)\tilde{\alpha}_{i j}^{k, l}=softmax_{j}(\alpha_{i j}^{k, l})α~ijk,l=softmaxj(αijk,l),Qk,lQ^{k, l}Qk,l、Kk,l,Vk,l∈Rdk×dK^{k, l}, V^{k, l} \in R^{d_{k} \times d}Kk,l,Vk,l∈Rdk×d,Ohl∈Rd×dO_{h}^{l} \in R^{d \times d}Ohl∈Rd×d,∥∥\|\|∥∥表示连接操作。输出随后通过残差连接和层归一化传入前馈网络(FFN):
h^il+1=LN(hil+h^il+1),(13)\hat{h}_{i}^{l+1}=LN\left(h_{i}^{l}+\hat{h}_{i}^{l+1}\right), \quad (13)h^il+1=LN(hil+h^il+1),(13)
h^^il+1=W2lReLU(W1lh^il+1),(14)\hat{\hat{h}}_{i}^{l+1}=W_{2}^{l} ReLU\left(W_{1}^{l} \hat{h}_{i}^{l+1}\right), \quad(14)h^^il+1=W2lReLU(W1lh^il+1),(14)
hil+1=LN(h^il+1+h^^il+1),(15)h_{i}^{l+1}=LN\left(\hat{h}_{i}^{l+1}+\hat{\hat{h}}_{i}^{l+1}\right), \quad (15)hil+1=LN(h^il+1+h^^il+1),(15)
其中,W1l∈R2d×dW_{1}^{l} \in R^{2 d \times d}W1l∈R2d×d和W2l∈Rd×2dW_{2}^{l} \in R^{d \times 2 d}W2l∈Rd×2d是可学习参数,LNLNLN表示层归一化。
由于节点的结构标识可以基于度信息充分提取节点周围的信息,因此有助于区分非同构子结构。因此,我们在每个Transformer层中添加一个经过线性变换的结构标识,如公式(12)所示:
h^il+1=f(Iil)+h^il+1.(16)\hat{h}_{i}^{l+1}=f\left(I_{i}^{l}\right)+\hat{h}_{i}^{l+1} . \quad (16)h^il+1=f(Iil)+h^il+1.(16)
我们相信,通过足够数量的Transformer层,UGT能够将不同的子结构映射到不同的表示中。
3.3 自监督学习任务
我们提出自监督学习任务,通过 pretext任务训练UGT来提取图结构,而不使用任何标签信息。我们的目标是学习能够捕捉任意两个结构相似节点之间的局部和全局结构的表示,这些表示随后可用于解决不同的下游任务。
如前所述,我们旨在保留ppp步转移概率中的关系结构信息,将局部和全局结构结合起来。给定目标节点viv_{i}vi和上下文节点vjv_{j}vj之间的连接,我们旨在最大化连接viv_{i}vi和vjv_{j}vj的路径的转移概率,而降低图中其他非连接节点对的概率。与Grarep和Glove类似,我们采用[22]提出的噪声对比估计。viv_{i}vi在ppp步的转移概率矩阵的损失函数可定义为:
L1p(vi)=(∑vjPk(vj∣vi)logσ(zizj))+λE,(17)L_{1}^{p}\left(v_{i}\right)=\left(\sum_{v_{j}} P_{k}\left(v_{j} | v_{i}\right) \log \sigma\left(z_{i} z_{j}\right)\right)+\lambda \mathbb{E}, \quad(17)L1p(vi)=
vj∑Pk(vj∣vi)logσ(zizj)
+λE,(17)
其中,E=Evk∼Pk(V)[logσ(−zizk)]\mathbb{E}=E_{v_{k} \sim P_{k}(V)} [\log \sigma(-z_{i} z_{k})]E=Evk∼Pk(V)[logσ(−zizk)],vkv_{k}vk表示通过负采样得到的节点。我们假设噪声服从均匀分布,这会产生一个对数尺度的新转移矩阵,该矩阵精确表示ppp步时任意两个节点之间的全局关系信息:
A′(p)=log(Ai,j(p)∑tAt,j(p))−log(∣Ns∣∣V∣),(18)A^{\prime(p)}=\log \left(\frac{A_{i, j}^{(p)}}{\sum_{t} A_{t, j}^{(p)}}\right)-\log \left(\frac{\left|N_{s}\right|}{|V|}\right), \quad (18)A′(p)=log(∑tAt,j(p)Ai,j(p))−log(∣V∣∣Ns∣),(18)
其中,A′(p)A^{\prime(p)}A′(p)是我们要保留的ppp步对数尺度概率矩阵,NsN_{s}Ns表示负采样集。最后,ppp步结构保留的损失函数可计算为:
L1p=∥A′(p)−Z(p)∥F2,(19)L_{1}^{p}=\left\| A^{\prime(p)}-Z^{(p)}\right\| _{F}^{2}, \quad (19)L1p=
A′(p)−Z(p)
F2,(19)
其中,Z(p)Z^{(p)}Z(p)是通过计算向量嵌入之间的余弦相似度构建的分数矩阵。
由于节点特征信息有助于多个下游任务,UGT还应学习节点特征信息的重构。我们定义基于节点原始特征重构的损失项为:
L2=1∣V∣∑vi∈V∥xi−x^i∥2,(20)L_{2}=\frac{1}{|V|} \sum_{v_{i} \in V}\left\| x_{i}-\hat{x}_{i}\right\| _{2}, \quad(20)L2=∣V∣1vi∈V∑∥xi−x^i∥2,(20)
其中,xix_{i}xi表示节点viv_{i}vi的原始特征,x^i=FFN(zi)\hat{x}_{i}=F F N(z_{i})x^i=FFN(zi)。我们通过多任务学习对模型进行训练,将两个损失线性组合:
L=α∑pL1p+βL2,(21)L=\alpha \sum_{p} L_{1}^{p}+\beta L_{2}, \quad(21)L=αp∑L1p+βL2,(21)
其中,α\alphaα和β\betaβ是超参数。
3.4 微调任务
为了将UGT应用于下游任务,将学习到的表示直接用于解决下游任务。在本研究中,我们提出了三个下游任务,包括节点聚类、节点分类和图级分类。对于节点聚类任务,我们如[23]所做的那样,使用模块性作为损失函数。对于节点分类,将来自Transformer层的节点viv_{i}vi的表示传入全连接(FC)层,得到分类输出yiy_{i}yi:
yi=W1ReLU(W2hil),(22)y_{i}=W_{1} ReLU\left(W_{2} h_{i}^{l}\right), \quad (22)yi=W1ReLU(W2hil),(22)
其中,W1∈Rd×CW_{1} \in R^{d \times C}W1∈Rd×C和W2∈Rd×dW_{2} \in R^{d \times d}W2∈Rd×d是权重矩阵,CCC表示类别数。在图级分类中,我们采用平均池化来获取图特征,并同样使用FC层来获取预测输出。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)