谷歌第8代TPU:训推双芯分家,硬刚英伟达“一芯通吃”

温馨提醒:数据中心4件套(服务器、存储、网络、SSD全解系列)姊妹篇已全部发布,之前购买过“架构师技术全店资料打包汇总(全)(已持续更新至48本)”的读者免费发放全店更新(请在发货的汇总链接下载),或请凭借购买记录在微店留言获取(PDF阅读版本)。
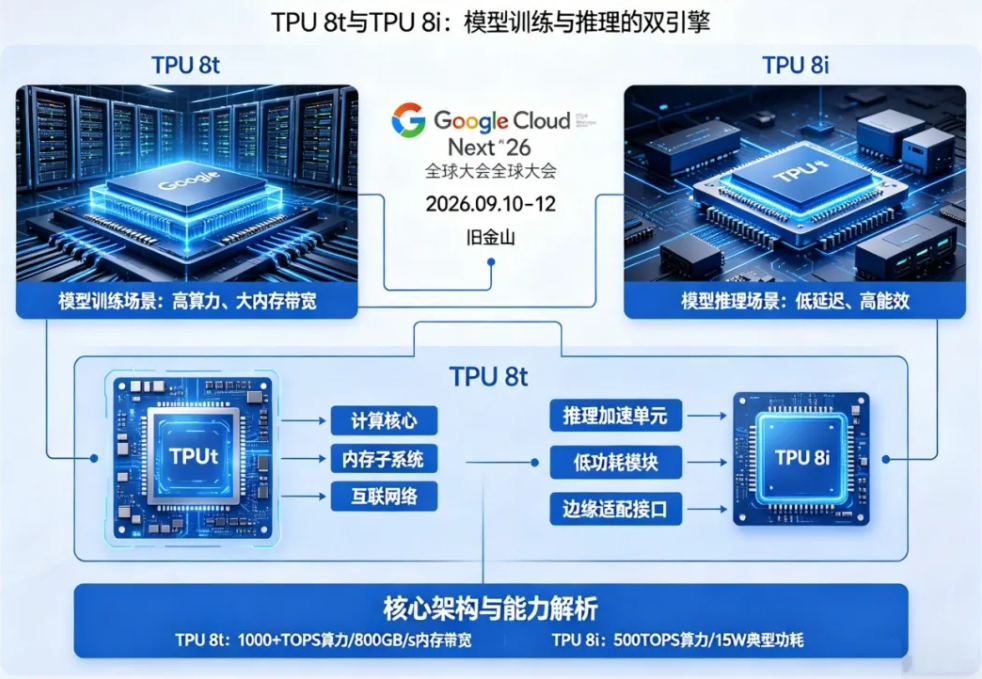
2026年4月22日,谷歌云在拉斯维加斯举办的 Next 2026 大会上,甩出了 AI 算力领域的王炸 ——第八代TPU正式亮相。这一次,谷歌没有延续 “一芯通吃” 的老路,而是史无前例地将训练与推理拆成两款独立芯片,TPU 8t 专攻大模型训练,TPU 8i 聚焦推理服务,彻底踩准了 AI 智能体时代的算力脉搏,也让全球 AI 硬件竞争进入全新阶段。
这场发布会远不止芯片那么简单。
谷歌CEO皮查伊开篇就放出重磅信号:2026 年谷歌将砸下1750亿 - 1850 亿美元投入 AI 基建,这个数字是 2022 年的近6倍;更惊人的是,谷歌内部已有75% 的新增代码由AI生成,工程师只负责审核把关,AI 早已深度渗透谷歌的技术血脉,而第八代 TPU(Google第七代Ironwood TPU:AI计算战场新格局),就是支撑这场智能革命的核心骨架。
一、训推彻底分家:两款芯片,各怀绝技
过去 AI 芯片总想着 “全能”,结果训练不够猛、推理不够省。谷歌这次直接破局,把训练和推理的需求拆得明明白白,两款芯片从架构到场景完全定制化,堪称 AI 算力的 “专业分工” 革命。
TPU 8t:万亿参数大模型的 “训练巨兽”
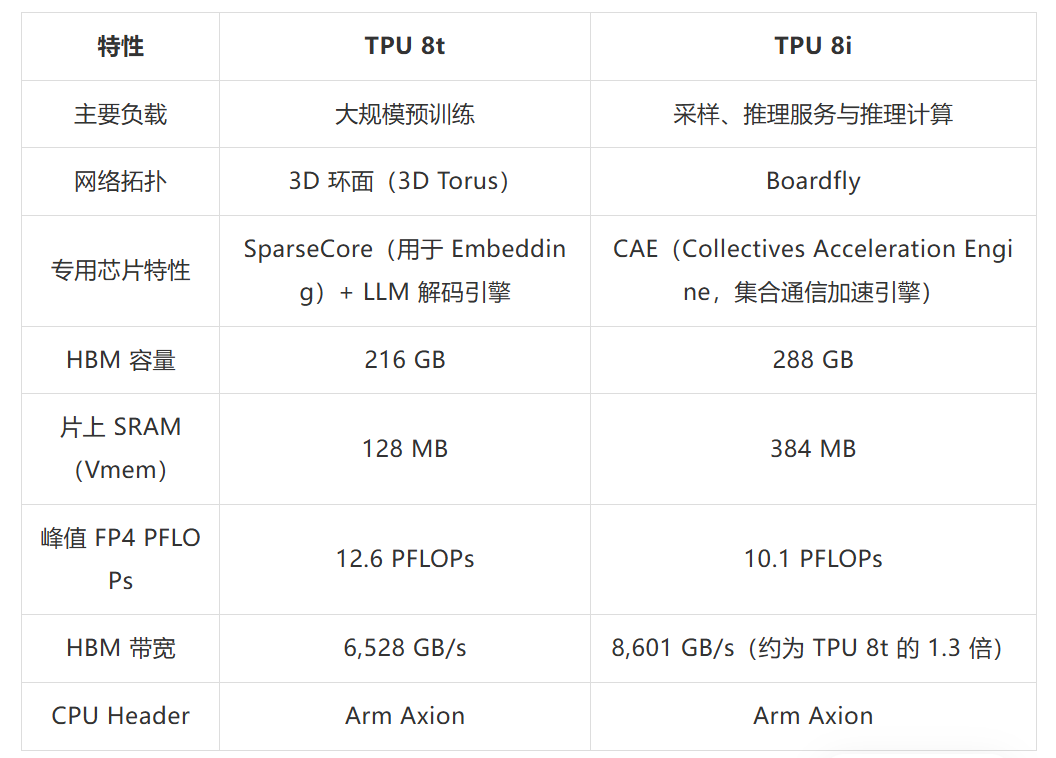
TPU 8t 是为千亿、万亿参数大模型预训练而生的算力猛兽,由谷歌与博通联手打造,浑身都是为训练优化的黑科技。
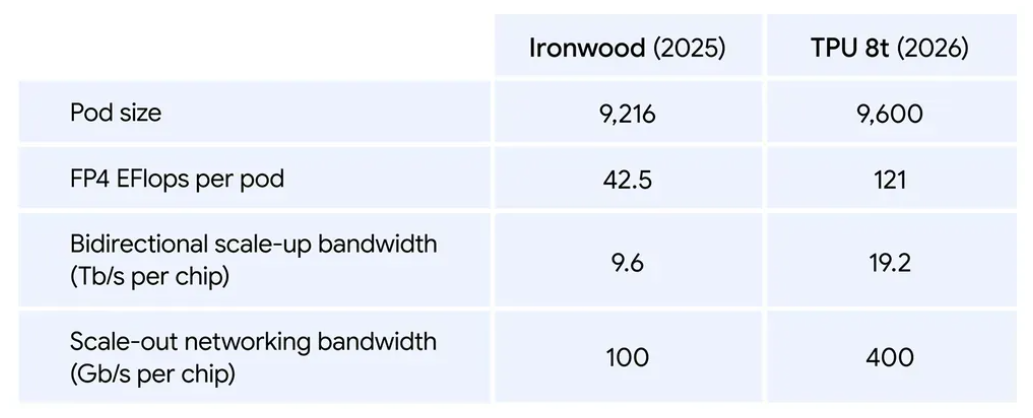
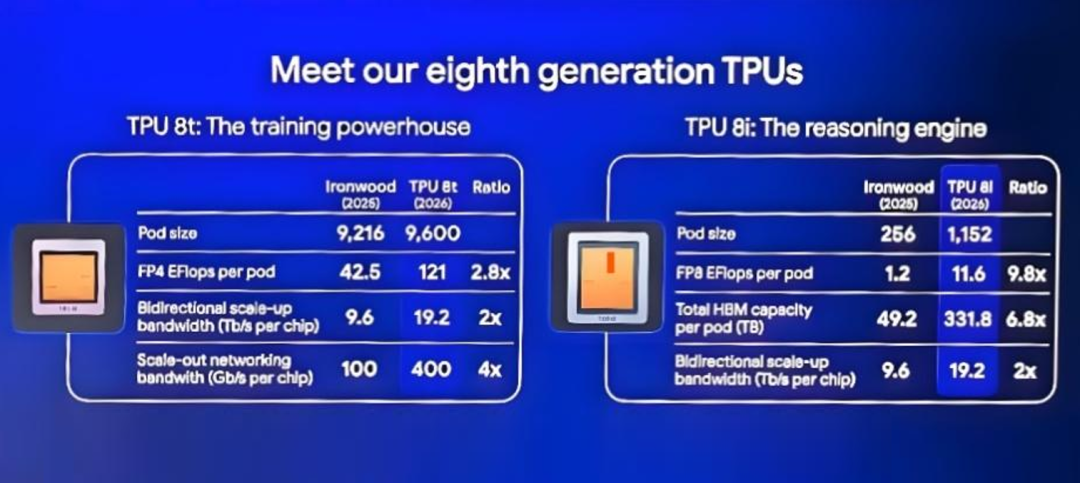
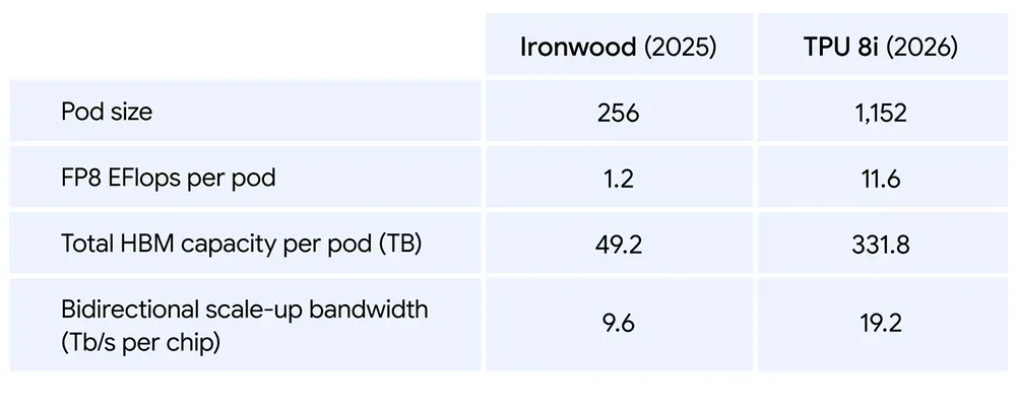
它的集群能力直接拉满:单个逻辑集群能塞进9600 枚芯片,共享 2PB 超大带宽内存,芯片间互联带宽比上一代翻番,总算力飙至121 ExaFlops,相当于把一座超算塞进一个集群里,最复杂的模型也能调用统一的超大内存池狂奔计算。
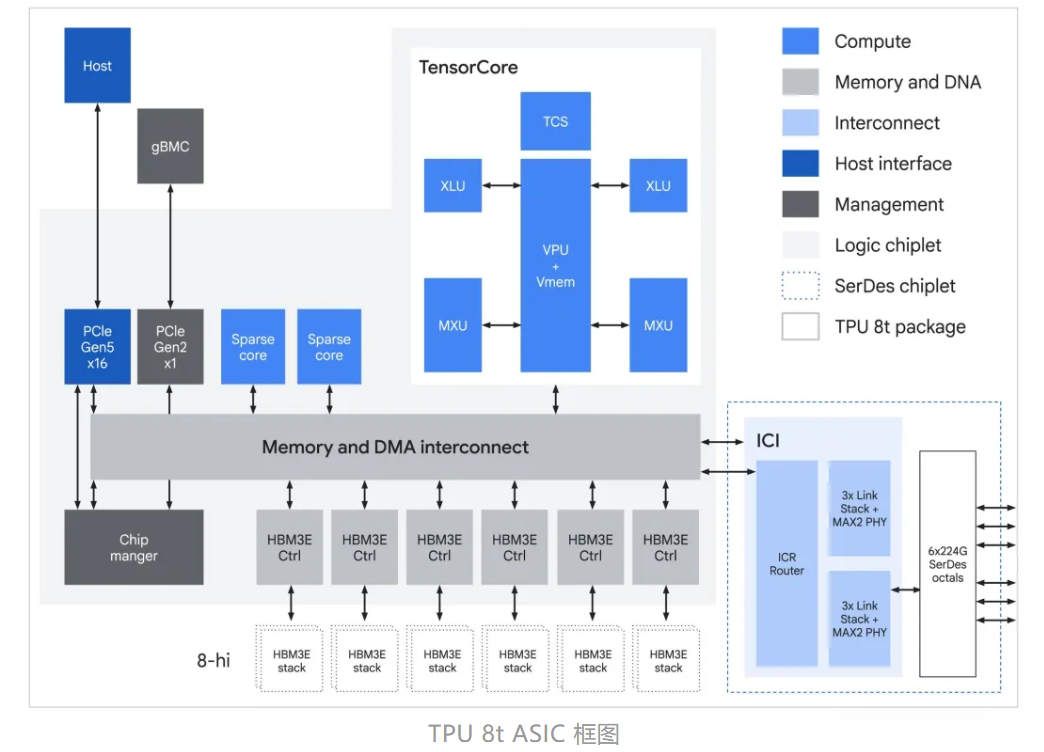
性能上更是碾压前代:整体计算性能比第七代 Ironwood 提升近3 倍,每瓦性能最高翻两倍,还自带 SparseCore 加速器,专治大模型不规则内存访问的痛点,支持原生 FP4 精度,算力翻倍的同时功耗大降,训练效率直接起飞。
更绝的是它的 “自愈” 能力:搭载实时遥测监控,能自动检测并绕过故障链路,配合光路电路交换(OCS)技术,不用人工干预就能自动重构硬件拓扑,大规模集群运行稳如泰山。
TPU 8i:打破内存墙的 “推理快刀”
如果说 TPU 8t 是蛮力巨兽,那TPU 8i 就是精准高效的推理专家。
谷歌首次携手联发科打造,目标只有一个 ——破解推理场景的 “内存墙” 瓶颈,让百万智能体同时跑也不卡顿。
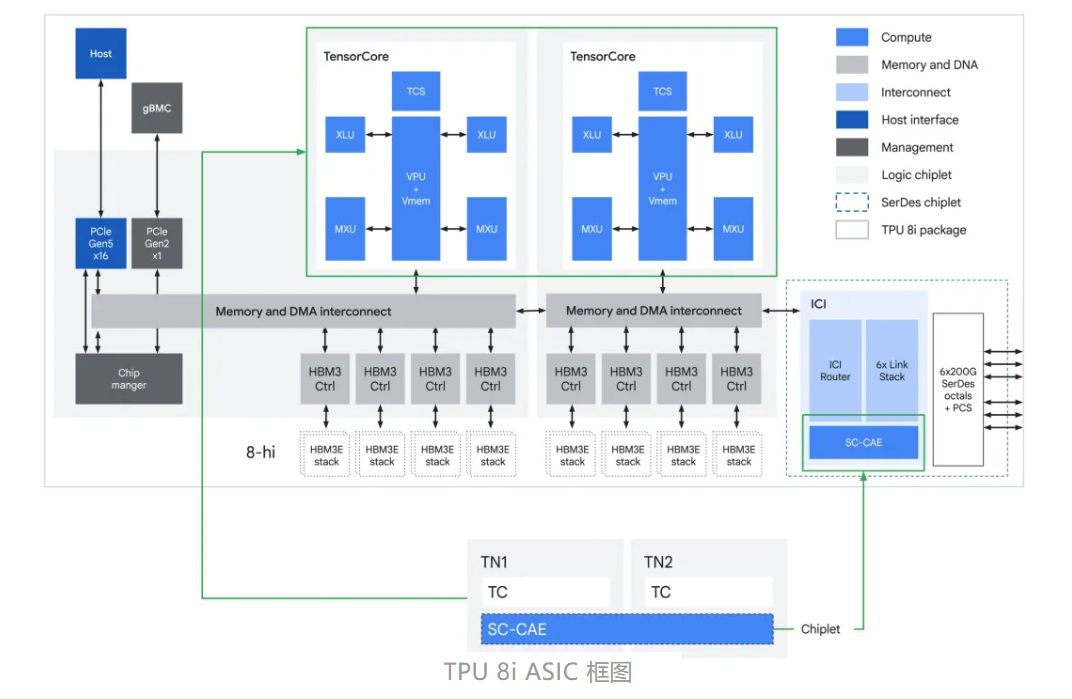
它直接把内存配置拉到极致:288GB 高带宽 HBM+384MB 片上 SRAM,SRAM 容量是上一代的 3 倍,模型的核心工作集能直接留在芯片里跑,彻底避免处理器空等数据,延迟直接砍半。
架构上更是创新:采用分层 Boardfly 网络拓扑,4 枚芯片为基础单元,36 个单元组成超大集群,任意两枚芯片通信最多只要 7 次跳转,并发能力拉满;还新增集合通信加速引擎,片上通信延迟再降 5 倍,完美适配 AI 智能体多任务并发的需求。
性价比直接封神:相比上一代性价比提升80%,同样成本能服务近两倍用户,每瓦性能提升 117%,大规模推理场景的成本难题直接解决。
两款芯片都采用台积电2 纳米制程,搭配谷歌自研 Arm 架构 Axion CPU,第四代液冷技术全程护航,计划 2026 年下半年开放使用,2027 年底实现量产,算力、能效、成本全维度拉满。
二、不止芯片:谷歌把 AI 智能体的全流程都搭好了
第八代 TPU不是孤立的硬件,而是谷歌 “代理式企业” 技术栈的核心,谷歌同步甩出软件、数据、安全、办公全链路升级,让算力能真正落地变现。
软件生态彻底开放:TPU 8系列终于原生支持 PyTorch 2.x,不用再折腾 torch_xla 兼容问题,Hugging Face 主流模型库开箱即用;再加上 Pallas 内核开发工具,开发者能精准控制芯片内存,把硬件性能榨干到极致,彻底摆脱过去 TPU 生态封闭的短板。
数据层面打通壁垒:推出 AI 专属 “知识目录”,原生集成 Gemini,能自动提取业务信息、映射数据关系,解决 AI 幻觉、延迟高的问题;跨云湖仓技术更绝,AWS、Azure 上的数据能像本地一样调用,智能体跨云找数据毫无障碍。
办公与安全全面 AI 化:谷歌 Workspace 迎来智能体升级,Gmail 有智能助手,聊天、文档、PPT、日历全能 AI 自动化;收购 Wiz 后推出反诈防御平台,精准识别 AI 代理合法性,安全问题一步到位;甚至把微软 365 迁移到谷歌 Workspace 的速度提升 5 倍,企业切换零门槛。
三、行业变局:AI 芯片进入 “专业化时代”
谷歌这次的训推分离,不是一时兴起,而是整个 AI 行业的必然趋势。当下AI 早已从单一模型训练,转向智能体、多任务并发、大规模推理,训练要极致吞吐量,推理要极致低延迟,一款芯片根本无法兼顾。

亚马逊Trainium+Inferentia、微软自研芯片、英伟达 Blackwell 系列优化推理,都在走专业化路线,而谷歌直接把这条路走得最彻底。对市场来说,这更是地震级变化。
此前谷歌TPU就拿下 Meta、Anthropic 巨额订单,第八代 TPU 发布后,直接挑战英伟达GPU的霸权地位,AI 算力市场从 “一家独大” 变成 “群雄逐鹿”,最终受益的是整个 AI 产业 —— 企业能用更低成本、更高效率跑 AI,智能体落地速度会再上一个台阶。

从2015年第一代TPU诞生,到 2026 年第八代双芯登场,谷歌用 11 年时间,把TPU 从 AI 辅助硬件,打成了智能体时代的算力基石。
第八代TPU的发布,不止是芯片的迭代,更是 AI 算力从 “通用” 走向 “专业” 的里程碑,接下来,百万 AI 智能体规模化落地的时代,真的要来了。
![]()
免费加入微信交流群,参与技术讨论!

温馨提醒:请之前购买过全店打包“架构师技术全店资料打包汇总(全)”的读者,请凭借购买记录在微店留言免费获取(PDF阅读版本)。后续所有更新均免费发放(目前48本资料)。

免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)