TTE中科院一区故障诊断论文(开源代码)
论文题目:
发表期刊: IEEE Transactions on Transportation Electrification(中科院一区Top期刊)
DOI:10.1109/TTE.2026.3684854
开源代码: https://github.com/huang-yu-han/TKS-TDM
作者:黄宇涵、胡小溪、何艺鸣等
作者单位:哈尔滨工业大学、北京交通大学先进轨道自主运行全国重点实验室、华中科技大学智能制造装备与技术全国重点实验室
一、究背景与动机
1.1 铁路转辙机的重要性与故障诊断的迫切需求
在过去的几十年中,铁路交通经历了从传统机械系统向现代电气化与自动化控制体系的深刻转型。随着铁路基础设施建设趋于饱和,行业正逐步进入存量资产管理时代,智能化运营与维护已成为保障铁路安全、效率与可持续发展的核心命题。在此背景下,铁路转辙机(Railway Turnout Actuator, RTA)作为铁路系统的关键机电执行部件,承担着驱动道岔转换列车运行方向的核心功能,其可靠性对整个铁路网络的安全稳定运行至关重要。
以ZDJ9型转辙机(ZDJ9-RTA)为例,该设备由电机、机械传动组件、拐臂杆、表示杆及开关电路控制器构成。工作时,电机驱动机械传动机构产生线性运动,经由拐臂杆推动道岔尖轨侧向位移,表示杆则将尖轨实时位置反馈至开关电路控制器,进而为铁路信号联锁系统提供电气反馈。ZDJ9-RTA在铁路车站道岔区及编组场中大量部署,长期连续服役使得设备降级与机械磨损不可避免。更为关键的是,转辙机通常不具备冗余备份,任何故障均可能直接导致列车运行中断,引发严重的运输效率损失。与此同时,现场故障维修仍高度依赖专家经验,维护响应效率低下,系统停机时间长,给铁路安全运营带来极大挑战。因此,对转辙机开展高效、精确的智能故障诊断研究,对于降低维护成本、提升设备可靠性、推进铁路智能化运维转型具有重要的现实意义与工程价值。
1.2 现有方法的局限性:两大核心痛点
近年来,面向铁路转辙机的故障诊断方法取得了重要进展。研究人员先后提出了基于信号处理的多尺度排列熵方法、端到端深度学习方法等,并进一步探索了多传感器采集方案,通过在减速器箱体、拐臂杆、开关电路控制器等不同部件上安装传感器,以及利用多相电气信号(电流/电压/功率)、三相电流等多源信号来拓展诊断维度。然而,尽管上述研究为转辙机故障诊断奠定了坚实基础,它们仍面临两个相互关联且难以回避的核心瓶颈,制约着该领域的进一步发展:
瓶颈一:单轴测量导致空间信息捕获不足。
现有绝大多数研究依赖单一传感器的单方向测量,难以全面描述转辙机复杂的多维空间响应,容易在实际中遗漏关键方向上的故障特征信息,削弱模型对不同故障类型的辨识能力。即便部分研究在不同部件上部署了多个传感器,每个传感器仍仅采集单轴数据,方向维度上的信息丰富度依然受限。迄今为止,尚无研究尝试将多传感器多轴信号引入转辙机故障诊断,这一空白亟待填补。
瓶颈二:多传感器全序列处理引发冗余与实时性困境。
在引入多传感器配置后,直接处理来自多通道传感器完整时间序列所带来的时序信息冗余问题变得尤为突出。转辙机一次完整的动作过程中,并非所有时间节点都携带等价的故障信息——故障特征往往集中于道岔锁定瞬间等特定动作阶段,而大量平稳段信号对诊断贡献甚微。然而,现有方法对全序列进行无差别处理,不仅浪费了大量计算资源,更严重阻碍了模型在实际工程中的实时部署。
正是在上述双重挑战的驱动下,本文在业界首次将多传感器多轴信号应用于铁路转辙机故障诊断,并从系统层面设计了一套能够同时解决空间信息不足与时序冗余计算低效这两大核心痛点的端到端智能诊断框架,从而实现精确、高效且具备实用部署能力的转辙机故障诊断。
二、方法介绍:TKS-TDM端到端诊断框架
2.1 整体架构设计思想
本文提出的时序关键点选择-Transformer诊断模型(Temporal Key Selection-Transformer Diagnostic Model, TKS-TDM)是一个面向多传感器多轴信号的端到端故障诊断框架(整体架构见图1,)。该框架由三个功能互补、协同运作的核心模块组成:多通道信号特征表示模块(Multichannel Signal Feature Representation Module, MSFRM)、关键点选择模块(Key Point Selection Module, KPSM) 以及状态分类模块(Condition Classification Module, CCM)。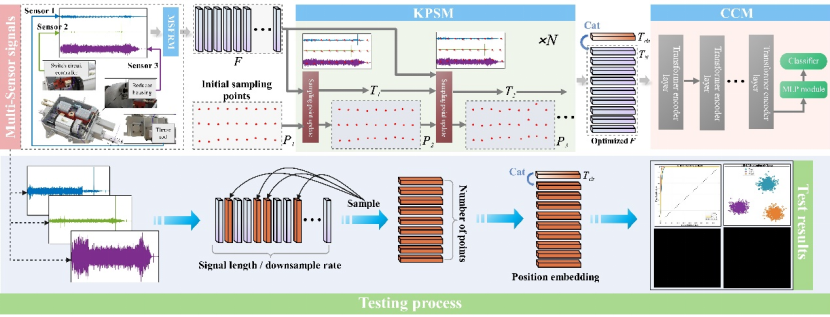
图1 TKS-TDM整体框架图
三个模块的整体设计逻辑遵循“表示→选择→分类”的渐进式处理范式:MSFRM将原始多通道故障信号转化为信息密度更高的时序特征表示;KPSM在特征序列上自适应地定位并提取最具诊断价值的时间关键点;CCM则对稀疏关键点特征进行全局依赖建模,最终输出故障类别诊断。这种设计将计算资源的分配高度集中于真正携带故障信息的时序区域,从而在不牺牲诊断精度(乃至进一步提升精度)的前提下,实现显著的计算效率增益。
2.2 多通道信号特征表示模块(MSFRM)
原始多传感器多轴信号来自若干个不同物理位置的传感器,每个传感器提供多个方向的分量,合计形成多通道信号矩阵。MSFRM首先对每个传感器通道进行逐通道自适应归一化处理,消除不同传感器量程差异对模型学习的干扰,形成统一的归一化多通道输入。
值得注意的是,与图像数据中各通道之间存在显式空间相关性不同,多通道转辙机时序信号在通道索引方向上具有排列不变性——即改变通道排列顺序并不改变信号的物理本质。因此,本文摒弃了对通道间空间关系的显式建模,转而设计了一种创新的跨通道映射机制:将同一时刻不同通道采集到的多维测量值,通过非线性映射投影至高信息密度的特征空间,实现各通道信息在时间点维度上的深度融合。MSFRM采用分层卷积-池化架构:初始卷积层建立局部时序模式,逐级池化操作对时序维度进行压缩,两个瓶颈层(bottleneck layer)承担跨通道交互建模的职责。每个瓶颈层遵循"压缩-变换-扩展"的经典结构,依次施加多尺度卷积操作完成通道降维、特征变换与维度恢复,并配备残差连接以保障梯度的有效传递。
通过上述设计,MSFRM实现了两个关键目标:一是通过非线性映射将多通道原始数据融合为统一的高层特征表示,有效捕获通道间相关性;二是通过时序压缩大幅降低后续处理的序列长度,同时提升每个时间点的信息密度,为关键点采样提供更具辨识性的特征基础。
2.3 关键点选择模块(KPSM)
KPSM是TKS-TDM框架的核心创新所在(模块详细架构见图2)。该模块的设计出发点在于:转辙机信号的故障特征具有鲜明的时序稀疏性——有诊断价值的信息往往高度集中于特定动作阶段(如道岔锁定瞬间的机械冲击响应),而非均匀分布于整个运行周期。若能精准识别并聚焦于这些关键时刻,即可在大幅压缩计算量的同时维持乃至提升诊断性能。
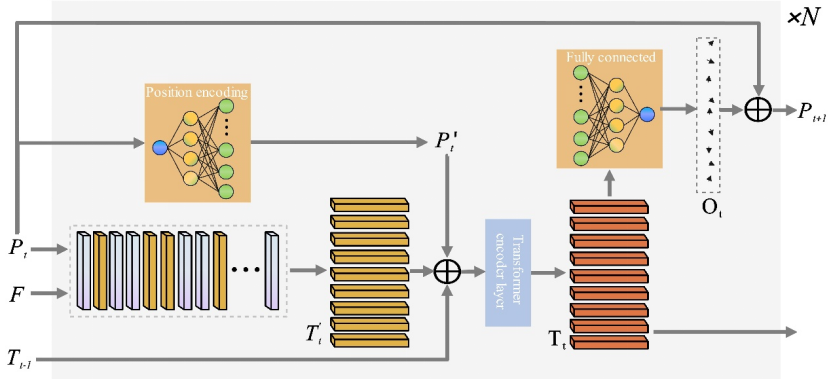
图2 KPSM整体框架图
KPSM的详细过程如下,初始化与采样:KPSM定义n个可学习采样点
,在第一次迭代时将整个时序范围等分为n个区间,取各区间中点作为初始采样位置。这一均匀初始化策略确保了模型在训练早期对整个时序区间具有完整的覆盖能力,避免了过早陷入局部偏优的采样配置。随后,通过可微分的一维线性插值操作,在MSFRM输出的特征矩阵F上完成特征提取,获得初始采样特征。
迭代优化机制:由于最优采样点位置无法在单次前向传播中直接确定,KPSM设计了多轮迭代的渐进式优化策略。在每次迭代中,模块引入位置编码机制,将当前采样点的坐标值通过线性映射转化为高维位置嵌入,并与采样特征及上一迭代输出的历史特征进行拼接融合,共同输入Transformer编码器进行上下文关联建模。Transformer输出的融合特征一方面通过全连接层预测各采样点的位置偏移量,更新下一轮的采样坐标;另一方面作为历史记忆特征参与下一轮迭代的特征融合,确保模型能够在多尺度时序信息的支撑下持续优化采样决策。经过多轮次迭代后,采样点逐步从初始均匀分布收敛至对分类损失最敏感的时序区域,最终仅以几个关键点(不足原始序列0.5%的时间点)承载最丰富的故障判别信息。
可微分采样保障端到端训练: KPSM中的采样操作通过PyTorch的gridsample函数实现,其梯度可通过一维线性插值核函数对采样位置坐标的偏导数进行解析推导,从而在端到端训练框架下,分类损失的梯度可完整回传至采样点坐标,驱动采样位置的自适应优化,而无需任何额外的监督信号。
2.4 状态分类模块(CCM)
经KPSM筛选出的稀疏关键点特征,虽已高度浓缩了转辙机运行的核心故障信息,但各关键点之间的长程时序依赖关系尚未得到充分建模。为此,CCM采用基于Transformer的编码器架构作为最终特征提取与故障分类模块(架构详见图3)。
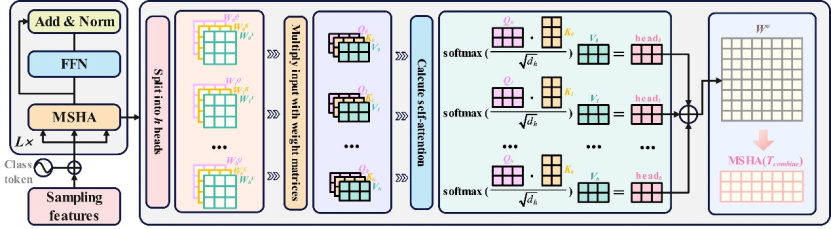
图3 CCM整体框架图
CCM引入可学习的类别词元(class token
,与稀疏关键点特征拼接后共同输入多层Transformer编码器。每层编码器由多头自注意力机制(Multi-head Self-Attention, MSA)与前馈神经网络(Feed-Forward Network, FFN)构成,并配以残差连接与层归一化以稳定训练过程。MSA机制能够自适应地计算所有关键点之间的注意力权重,识别对特定故障模式最具诊断价值的关键点组合,即便这些关键点在时序上相距较远;多头设计则进一步允许模型从多个表示子空间同时捕捉不同类型故障所对应的复杂时序模式。经过若干层Transformer编码后,类别词元位置的输出特征作为整个稀疏序列的全局表示,最终通过分类头映射至若干类故障状态,完成转辙机运行状态的精确判定。
三、实验验证与结果分析
3.1 数据集介绍
本研究采用来某铁路交通产业集团有限公司所提供的两个真实工程数据集,开展系统性的实验验证(多传感器安装位置与数据采集方案见图4)。

图4 ZDJ9-RTA传感器布置示意图
其中铁路试验线数据集(Railway Test Line Dataset): 在公司专用铁路试验线上,于ZDJ9-RTA三个关键机械连接点——减速器箱体、拐臂杆侧和开关电路控制器侧——分别安装一枚三轴振动传感器,共形成九个振动信号通道(分别对应三个传感器的x、y、z轴方向)。所有信号以512Hz采样频率采集10秒,每通道获得5120个数据点。该数据集在受控运行条件下涵盖16种工作状态,按照正转(normal-to-reverse)与反转(reverse-to-normal)两个操作方向划分为8类场景,包括:欠驱动(3kN)、正常操作(4kN)、不同程度的过驱动(5/6/8kN)、空载运行、解锁故障,以及接近行程终点时的表示信号突然丢失。
现场部署数据集(Field Deployment Dataset): 直接采集自在役铁路道岔设备,故障类别分布、采样频率与采集时长均与试验线数据集保持一致,但现场振动信号不可避免地受到多种真实环境扰动的叠加影响,包括邻近列车运行诱发的机械振动、日常维护中的瞬态冲击以及其他场地特有的噪声源。这些扰动是铁路日常运营中不可规避的客观存在,使该数据集高度贴近转辙机真实服役状态,成为评估诊断模型鲁棒性的关键基准(两个数据集在“欠驱动3 kN,正转方向”故障类型下的振动信号波形对比见图5,两数据集信号波形对比图,真实现场噪声对信号波形的影响清晰可见)。
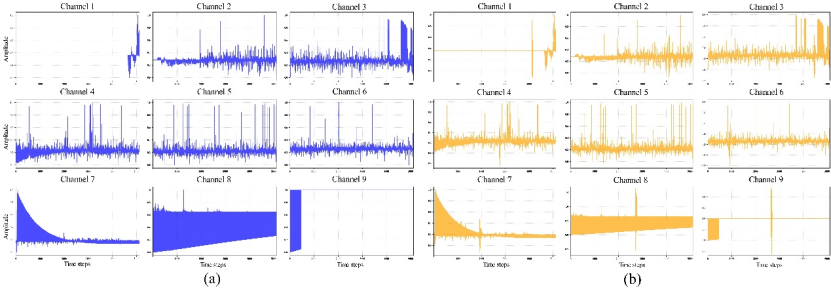
图5 两数据集信号波形对比图
两个数据集均采用分层随机采样,按照0.64:0.20:0.16的比例划分为训练集、验证集和测试集,分别用于模型参数优化、超参数调整与早停判断以及最终性能的无偏评估。
3.2 模型超参数分析与最优配置选取
为系统确定TKS-TDM的最优超参数配置,本文首先利用贝叶斯优化确定超参数搜索范围,随后对三个对模型性能影响最显著的核心超参数——采样点数量、嵌入维度以及迭代次数——进行全面的网格搜索(超参数敏感性分析结果见图6,超参数敏感性分析图)。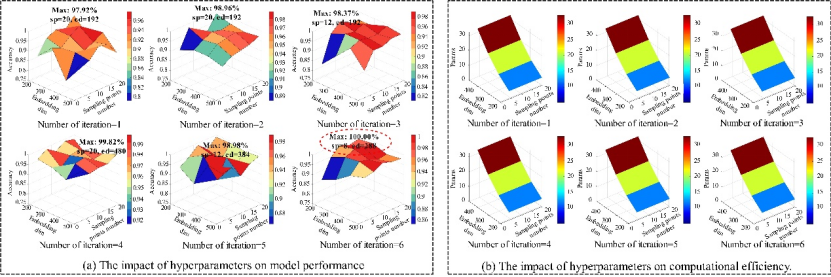
图6 超参数敏感性分析图
分析结果表明,当迭代次数较低(1~2次)时,KPSM无法充分优化采样位置,最高准确率仅分别为97.92%和98.37%;随着迭代次数增至3~4次,采样点逐步聚焦于高诊断价值的时序区域,准确率显著提升;在6次迭代时,采用8个采样点与288维嵌入维度的配置达到100%的完美分类精度。在计算效率层面,嵌入维度对模型复杂度的影响远大于迭代次数和采样点数量——较大的嵌入维度(384/480)虽精度优异,但显著增加了FLOPs与参数量,不适合资源受限场景的部署。
3.3 消融实验:各模块贡献的系统验证
为定量评估TKS-TDM各设计组件的必要性与有效性,本文设计了七种消融/对比变体并在铁路试验线数据集上开展系统实验,评估指标涵盖准确率(ACC)、宏平均F1分数(F1)、AUC以及计算复杂度(Params、FLOPs)。
MSFRM的作用验证(Ablation 1): 移除MSFRM,强制KPSM直接在原始9通道信号上进行关键点选择。结果显示模型性能出现灾难性崩溃(ACC=14.07%,F1=7.15%,AUC=66.86%),尽管模型极度轻量(0.05M参数,FLOPs仅1.20×10⁻⁴B)。这一结果说明,在缺乏有效特征表示的情况下,KPSM实质上是在“信息贫瘠的原始信号“中进行无效采样,后续CCM所接收到的是稀疏且缺乏代表性的低级特征,导致严重的性能退化。MSFRM通过多通道表示学习与时序压缩,使每个时间点承载更丰富的跨通道聚合信息,是KPSM有效运作的前提基础。
KPSM的作用验证(Ablation 2): 保留MSFRM,移除KPSM,将MSFRM的完整输出序列直接送入CCM处理。结果显示诊断性能仍保持竞争力(ACC=97.50%,F1=97.52%,AUC=99.78%),但计算开销急剧上升至21.09M参数、8.70B FLOPs,是完整TKS-TDM(0.17B FLOPs)的约51倍。这一对比充分证明KPSM是解决多传感器全序列融合中冗余-延迟瓶颈的关键机制:通过将推理计算集中于少数故障信息丰富的关键时刻,在几乎不损失精度的同时实现了计算量的大幅压缩。
多传感器三轴融合的必要性验证(Variant 4/5): 分别将输入限制为随机选取的单通道(Variant 4)和三通道(Variant 5)信号。实验结果均出现显著的性能下降,有力证明了九通道多传感器多轴融合对于捕获全方向互补机械响应信息的核心价值,也从实验层面验证了本文在业界首次引入多传感器多轴配置的重要性。
CCM架构选择验证(Variant 2/3): 以LSTM(Variant 2)替换Transformer的CCM时,准确率下降至89.07%(尽管参数量降至8.21M,但FLOPs反增至0.23B,原因在于当采样点数远小于嵌入维度时,LSTM的计算复杂度高于Transformer);以MobileNet V1(Variant 3)替换CCM时,准确率为94.14%,同样低于完整TKS-TDM,进一步验证了Transformer架构在稀疏关键点全局建模中的优越性。
完整TKS-TDM框架(ACC=99.66%,F1=99.91%,AUC=99.87%,Params=11.76M,FLOPs=0.17B)在所有变体中取得了性能与效率的最优综合表现,系统验证了各设计选择的合理性与必要性。
为深入理解KPSM的工作机理,本文对不同故障类型下学习到的采样行为进行了可视化(见图7):灰色圆点表示均匀初始化的采样位置,红色五角星表示经KPSM端到端优化后的最终关键点位置。分析表明,在信号高动态波动区域(如机械冲击响应阶段),采样点发生显著位移以精准捕捉故障瞬态特征;在平稳段,采样点几乎保持不动,避免对冗余信息的无效建模。以“空载运行(反转)”为例,KPSM将第五个采样点平均偏移-157.84个降采样时间步,精准对准振动信号早期动态波动区域;以"解锁故障(反转)"为例,KPSM将第五个采样点平均偏移-184.37个时间步,准确定位机械冲击脉冲的峰值位置,充分展现了模型的可解释性与物理一致性。本文还通过扰动敏感性测试(对优化后的采样位置施加系统性偏移)与梯度收敛性分析,从定量角度验证了KPSM所选关键点位于损失敏感邻域内的局部最优配置,而非视觉上合理但物理上偶然的采样位置。
图7 各故障类型下信号采样点可视化图
3.4 对比实验:与七种先进方法的系统比较
本文将TKS-TDM与七种先进故障诊断基线方法进行了系统性对比,包括:专为转辙机设计的LD-RPMNet(结合卷积局部特征提取与Transformer全局建模)和DS-WCNN(双尺度宽卷积核振动诊断网络)、具有传感器通道注意力机制的FDCSANet、基于单向Patch嵌入的多通道Transformer方法MSiT,以及BiLSTM、Wide-ResNet和AlexNet等经典方法。所有基线方法均保持原始架构不变,仅调整输入层以适配九通道振动信号输入,确保对比的公平性。实验指标包括ACC、F1、AUC(均报告10次独立运行的均值±标准差)以及Params与FLOPs,结果如图8所示。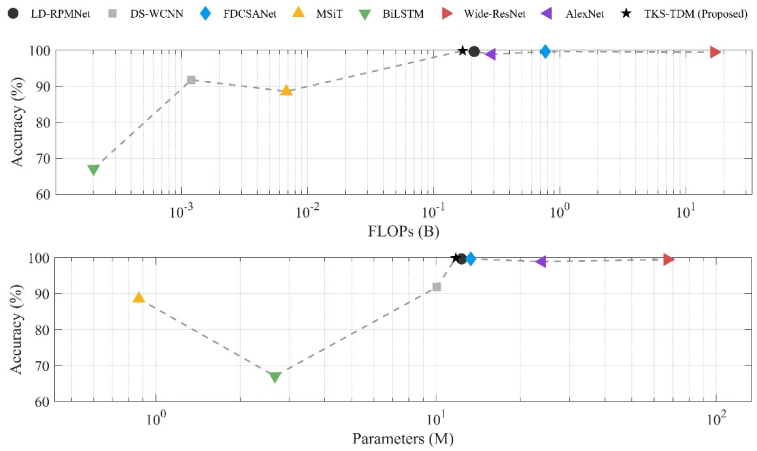
图8 对比实验结果图
铁路试验线数据集:TKS-TDM以99.66% ± 0.34%的准确率、99.91%±0.09%的F1分数、99.87% ± 0.11%的AUC全面超越所有对比方法,居于最优水平。次优方法FDCSANet的准确率为98.06%,比TKS-TDM低1.60个百分点,且其FLOPs(0.77B)是TKS-TDM(0.17B)的约4.5倍。计算开销最大的Wide-ResNet(16.76B FLOPs,TKS-TDM的约98.6倍)准确率仅为96.25%,在精度与效率两个维度均处于明显劣势。计算效率与诊断精度的综合权衡对比(见图8)直观展示了TKS-TDM在帕累托前沿的领先地位——在所有方法中,TKS-TDM是唯一同时实现最高精度与极低计算量的方法。为进一步强化统计可靠性,本文采用配对单侧Wilcoxon符号秩检验(Holm校正控制族错误率)和Cliff's Δ效应量指标对10次独立运行结果进行了严格的非参数显著性检验,结果显示TKS-TDM相对所有基线方法的提升均在统计显著性检验下得到充分支持。
现场部署数据集:在真实现场噪声干扰下,所有方法的性能均有不同程度的下降,但TKS-TDM展现出最强的鲁棒性——准确率仅从99.66%(试验线)下降至95.66%(衰减幅度约4个百分点),而FDCSANet下降约3.29个百分点,LD-RPMNet下降约3.52个百分点,Wide-ResNet下降约1.98个百分点,DS-WCNN下降约7.42个百分点,其中Wide-ResNet总体域内精度虽下降较少,但其绝对精度仍低于TKS-TDM。TKS-TDM在现场条件下以95.66%±1.05%的准确率、95.55%±1.02%的F1分数、99.38%±0.44%的AUC继续位居第一。这一鲁棒性优势与模型设计逻辑高度吻合:MSFRM通过时序压缩与跨通道融合提升了每个候选时间点的信息密度,KPSM则进一步规避了对长段噪声主导或准平稳区域的无效表示,使分类器所接收到的输入始终是对分类目标损失最敏感的关键时刻信息,从而在真实现场扰动下保持了更强的抗噪判别能力。
3.5 跨域泛化实验:面向实际部署的泛化能力评估
在前述域内诊断实验之外,为系统评估TKS-TDM在不同铁路运行环境之间的迁移泛化能力,本文构建了一套严格的跨域泛化评估框架。该框架首先从信号层面(统计特性分布)和特征层面(MSFRM输出特征的最大均值差异MMD与t-SNE可视化,见图9)对两个数据集之间的分布差异进行了定量刻画,验证了试验线域与现场部署域之间确实存在实质性的分布偏移(类间MMD均值达0.689,部分类别高达0.953),从而充分证明了开展严格跨域评估的必要性。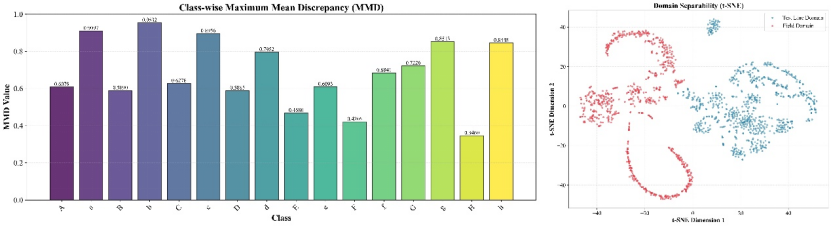
图9 域分布差异分析图
在此基础上,本文设计了五种迁移学习任务开展系统评估(结果汇总见图10,跨域泛化性能对比图):T1(试验线→现场,零样本迁移): 这是最严苛的跨域设置——模型仅在试验线数据集上训练,直接应用于现场数据集的测试集,不进行任何目标域微调。TKS-TDM在此条件下达到88.71% ± 3.26%的准确率,分别比FDCSANet(81.30%)、LD-RPMNet(78.38%)和Wide-ResNet(73.88%)高出7.41、10.33和14.83个百分点。值得注意的是,Wide-ResNet尽管在域内实验中取得了较高精度,但在零样本跨域场景下出现了最严重的性能退化(衰减22.37个百分点),表明其存在对源域噪声模式的过度拟合。相比之下,TKS-TDM的跨域衰减仅为10.95个百分点,充分验证了其关键点选择机制所赋予的表示不变性——通过聚焦故障特征集中的时序区域,有效抑制了对域特有干扰特征的过度依赖,从而在跨域迁移中保持了更强的泛化能力。
图10 跨域泛化性能对比图
T2(现场→试验线,零样本迁移): TKS-TDM在反向迁移中同样保持领先(90.24% ± 2.81%),验证了双向跨域鲁棒性。T3~T5(少样本自适应,K=1/3/5样本/类): 在极端标签稀缺的条件下,TKS-TDM展现出优异的小样本适应效率:仅使用每类1个样本(共16个样本)时,准确率已达到90.66% ± 2.82%;当K增至5时,准确率进一步提升至94.33% ± 1.35%,与完整监督训练下的在域结果(95.66%)仅相差约1.3个百分点,而此时基线方法仍与完整监督结果存在较大差距,充分体现了TKS-TDM的样本高效适应能力。
此外,本文还在零样本跨域迁移场景下开展了受控鲁棒性压力测试,包括加性噪声(不同信噪比条件)、瞬态冲击干扰(不同幅度比)以及传感器失效(不同传感器丢失数量)等三种典型现场扰动场景(结果见论文图11)。实验表明,TKS-TDM在中等加性噪声(SNR=10dB)和瞬态冲击干扰(幅度比
=2.0)条件下分别维持81.01%和81.44%的准确率,展现出对环境扰动的强鲁棒性;但在传感器完全丢失的情况下性能下降较为明显,这与TKS-TDM优先通过充分多传感器融合最大化诊断精度的设计理念一致,符合铁路安全标准中传感器冗余配置与异常即时告警的运维要求。
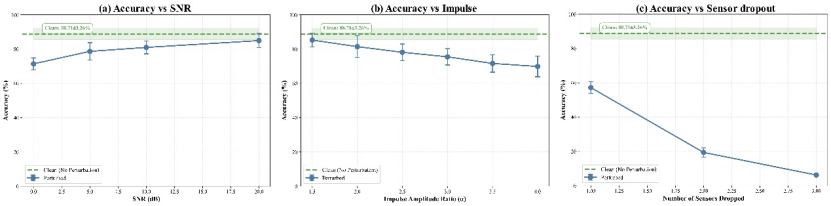
图11 受跨域迁移影响的受控鲁棒性压力测试(零样本测试→现场)
为进一步评估TKS-TDM的实用部署可行性,本文在标准CPU平台(第12代Intel Core i7-12700H,2.30GHz,20核心)上进行了CPU推理基准测试。如图12所示,测试结果表明,单样本端到端推理延迟约为19.96 ms(P99: 29.27ms),批处理吞吐量达170.5样本/秒(batch=32),完全满足铁路车站侧集中监控平台对多台转辙机实时诊断的部署需求,且无需依赖GPU加速资源,极大降低了系统集成的硬件门槛。
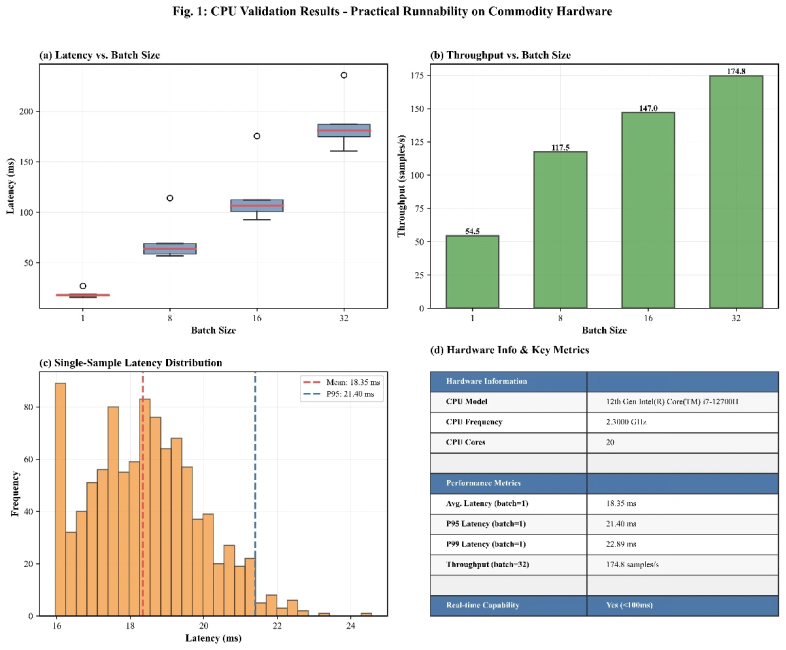
图12 实际部署验证
四、结论
本文针对铁路转辙机故障诊断领域中单轴传感器空间信息捕获不足、多传感器全序列处理计算冗余高这两大核心痛点,提出了端到端深度学习诊断框架TKS-TDM,并在业界首次引入多传感器多轴信号完成对转辙机全方向响应的全面表征。通过多通道信号特征表示模块(MSFRM)、渐进式关键点选择模块(KPSM)与基于Transformer的状态分类模块(CCM)的协同设计,TKS-TDM实现了将推理计算高度集中于不足原始序列0.5%的关键时刻,在减少计算量的同时全面超越现有最优方法。在两个权威真实数据集上,TKS-TDM分别取得了99.66%与95.66%的最优诊断精度;在跨域泛化评估中,零样本迁移准确率达88.71%,5样本/类少样本自适应准确率达94.33%,有力验证了其在多样化实际铁路运行条件下的部署潜力。本工作为电气化铁路系统的智能化运维提供了一套高效、精确、具备实际可部署性的转辙机故障诊断技术方案,有望推动铁路维护模式从被动响应向主动预测的智能化转型。
未来工作将着重探索以下三个方向:(1)开集识别与不确定性感知机制:当前框架假设标签一致性与独立同分布数据,难以应对真实铁路运行中不断演化的工况条件与未见过的新型故障类型,未来将引入开集识别和不确定性量化方法以实现未知故障类别的可靠识别;(2)面向传感器拓扑的空时融合表示:进一步显式利用多传感器的物理布局信息和三轴方向语义,设计能够感知传感器空间关系的精细化时空特征融合机制,深度挖掘不同物理位置与方向之间的相互作用信息;(3)跨设备迁移诊断:通过域自适应与生成式数据增强技术,提升模型在不同ZDJ9-RTA设备单元间的跨设备泛化能力,以应对大规模现场部署中不同设备个体间的差异性,实现在有限目标域标签下的高效迁移。上述研究方向将进一步增强本框架在真实铁路动态运营环境中的适用性与韧性,为铁路智能运维的工程实践持续提供技术支撑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)