【技术追踪】TMSS:一种基于 Transformer 的端到端多模态分割与生存预测网络(MICCAI-2022)
一个偶然的机会,学习一下怎么用深度学习搞生存分析,还是多任务的!
论文:TMSS: An End-to-End Transformer-based Multimodal Network for Segmentation and Survival Prediction
代码:https://github.com/ikboljon/tmss_miccai
0、摘要
肿瘤内科医生评估癌症患者的生存情况时,依赖多模态数据开展分析。(临床基操)
尽管已有多模态深度学习方法被提出,但这类方法大多依赖两个或以上独立网络,仅在模型后期阶段进行知识共享。而肿瘤内科医生的临床分析过程与此不同,他们会在大脑中融合医学影像、患者病史等多源信息。(现有不足)
本研究提出一种深度学习方法,旨在模拟肿瘤内科医生量化癌症特征、预估患者生存期的分析逻辑。(2022年正是Transformer最火的时候)
本文提出 TMSS —— 一种基于 Transformer 的端到端多模态分割与生存预测网络,利用 Transformer 在处理不同模态数据上的优势开展建模。
该模型基于头颈部肿瘤分割与 PET/CT 影像结局预测挑战赛(HECKTOR)的训练数据集,完成了分割任务与预后任务的训练与验证。实验结果表明,所提出的预后模型以 0.763 ± 0.14 0.763±0.14 0.763±0.14 的一致性指数(c-index)显著优于现有最优方法,同时取得了与独立分割模型相当的 0.772 ± 0.030 0.772±0.030 0.772±0.030 的 Dice 系数。
1、引言
1.1、研究意义与当前挑战
(1)头颈部(H&N)癌是对发生于口腔、鼻腔、咽喉及其他头颈部区域恶性肿瘤的统称。对患者生存风险的早期预测与精准诊断(预后),可将头颈部癌患者的死亡率降低至 70%。(面向的疾病与生存预测意义)
(2)人工勾画影像病灶耗时且繁琐,自动预后与分割技术可通过加快流程、获得可靠结果,显著影响治疗方案的制定。(分割意义)
(3)尽管有研究利用了多模态数据,但医学影像与电子健康记录的学习过程相互独立,可能导致深度学习模型学到的特征区分度不足,进而影响最终预测结果。(现有研究不足)
1.2、本文贡献
本文提出了一种全新的端到端架构 TMSS,通过融合患者的 CT、PET 影像与电子健康记录(EHR) 数据,实现肿瘤分割掩码与患者生存风险评分的联合预测。(多模态数据多任务学习)
(1)提出 TMSS,一种针对头颈部癌症分割与风险预测的新型端到端解决方案。在同一数据集上,TMSS 的性能优于现有最优(SOTA)模型;
(2)验证了视觉 Transformer 编码器可通过将多模态数据投影至同一嵌入空间,实现对多模态数据的建模,同时完成肿瘤分割与疾病结局预测任务;
(3)提出了一种适用于分割掩码与风险评分预测的联合损失函数;
2、方法
在下文中,将描述如 图 1 所示的主体架构的构成。可以看到,该架构包含四个主要模块,下文将对各模块逐一进行详细说明。
Figure 1 | 所提出的 TMSS 架构及多模态训练策略:TMSS 将 EHR 和多模态图像线性投影为特征向量,并输入Transformer 编码器。CNN 解码器接收输入图像、各层的跳跃连接输出以及最终层输出以执行分割任务;而预测模块则利用编码器最后一层的输出来预测风险评分。
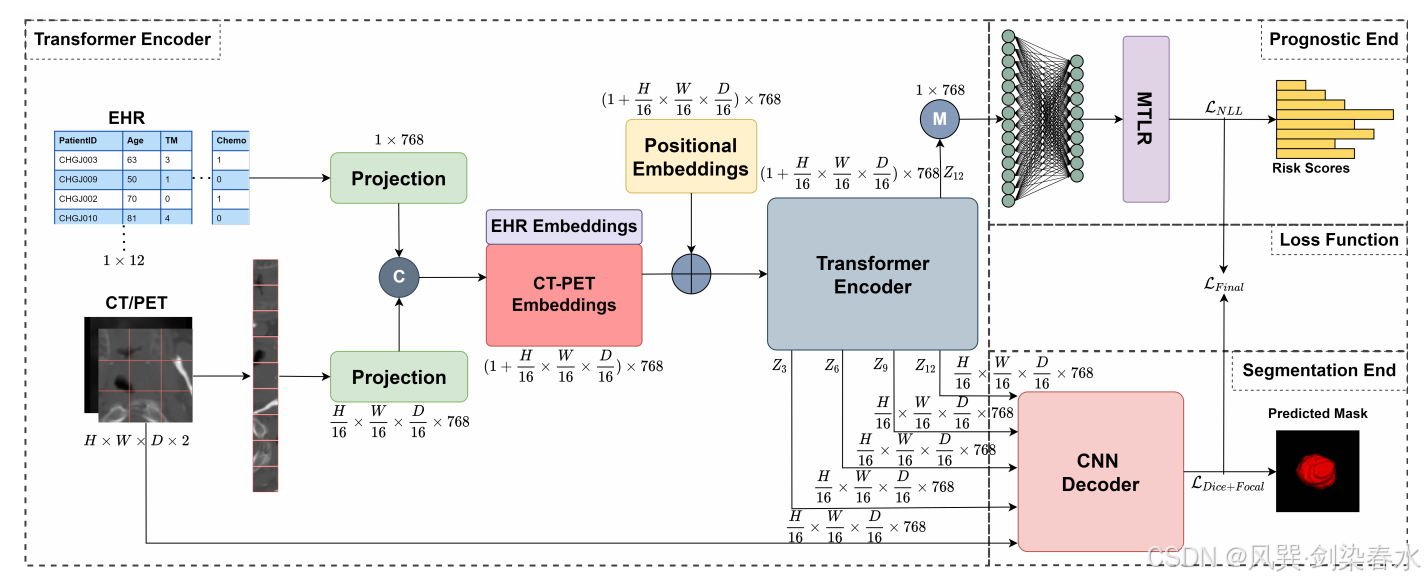
2.1、Transformer 编码器
该网络的核心优势在于,编码器本身可对 CT/PET 影像数据与电子健康记录(EHR)数据进行嵌入,并为其添加位置编码,同时提取不同模态间的依赖关系(即注意力机制)。
设尺寸为 x ∈ R H × W × D × C x∈\mathbb{R}^{H \times W \times D \times C} x∈RH×W×D×C 的 3D 图像,首先将其重塑为一组扁平化的 2D 图像块序列 x p ∈ R n × ( P 3 C ) x_p \in \mathbb{R}^{n \times (P^3C)} xp∈Rn×(P3C),其中 H H H、 W W W、 D D D 分别为 3D 图像的高度、宽度与深度, C C C 为通道数, P × P × P P×P×P P×P×P 表示每个图像块的尺寸, n = H W D / P 3 n = HWD / P^3 n=HWD/P3 为提取的图像块总数。
随后,这些图像块被投影至维度为 h h h 的嵌入空间,形成矩阵 I ∈ R n × h I \in \mathbb{R}^{n \times h} I∈Rn×h。同时,EHR 数据也被投影至维度为 E ∈ R 1 × h E \in \mathbb{R}^{1 \times h} E∈R1×h 的嵌入空间。将影像与 EHR 的嵌入结果拼接,得到矩阵 X ∈ R ( n + 1 ) × h X \in \mathbb{R}^{(n+1) \times h} X∈R(n+1)×h。接着,为每个图像块嵌入与 EHR 嵌入添加可学习的、维度相同的位置编码。由于本研究并非分类任务,因此移除了 ViT 中的类别标记(class token)。最终得到的嵌入向量将输入一个包含 12 层的 Transformer 编码器,其结构与原始 ViT 保持一致,包含归一化层、多头注意力层与多层感知机层。(简单的 Transformer 应用)自注意力机制的作用是学习包括影像与 EHR 在内的 n+1 个嵌入向量之间的关联关系。多头注意力中的自注意力计算方式如下:
Z = s o f t m a x ( Q K T D q ) V (1) Z = \mathrm{softmax}\left( \frac{QK^T}{\sqrt{D_q}} \right) V \tag{1} Z=softmax(DqQKT)V(1)
2.2、分割端
分割端采用基于卷积神经网络(CNN)的解码器,其结构与文献 [11] 中的解码器类似。原始图像与来自 ViT 第 3、6、9、12 层(即最后一层)的跳跃连接特征一同输入解码器。这些跳跃连接仅传递图像的潜在表征 Z l ∈ R ( n ) × h Z_l \in \mathbb{R}^{(n) \times h} Zl∈R(n)×h,其中 l ∈ { 3 , 6 , 9 , 12 } l \in \{3,6,9,12\} l∈{3,6,9,12},并输入至 CNN 解码器。上采样阶段采用卷积、反卷积、批归一化与修正线性单元(ReLU)激活函数,更多细节可参考文献 [22]。(接了个卷积解码器)
2.3、预后端
预后路径接收编码器输出的特征 Z 12 ∈ R ( n + 1 ) × h Z_{12} \in \mathbb{R}^{(n+1) \times h} Z12∈R(n+1)×h,首先计算其均值,将维度降至 Z m e a n ∈ R 1 × h Z_{mean} \in \mathbb{R}^{1 \times h} Zmean∈R1×h。随后,该潜在向量被输入两个全连接层,维度依次从 h h h 降至 512 和 128。最终得到的特征图被送入多任务逻辑回归(MTLR)模型,以完成最终的风险预测。MTLR 模块将未来时间区间划分为多个时间箱(time bin,为超参数),并针对每个时间箱使用逻辑回归模型预测事件是否发生。
2.4、损失函数
由于网络需同时完成两项任务,本研究构建了由三种损失组合而成的最终目标函数。分割端的损失由 Dice 损失(公式 2)与 Focal 损失(公式 3)共同构成。其中, N N N 为样本量, p ^ \hat{p} p^ 为模型预测值, y y y 为真实标签, α α α 为 Focal 损失中用于权衡精确率与召回率的权重(本研究中设为 1), γ γ γ 为聚焦参数(本研究中经验性设为 2)。
L D i c e = 2 ∑ i N p ^ i y i ∑ i N p ^ i 2 + ∑ i N y i 2 , (2) \mathcal{L}_{Dice} = \frac{2\sum_{i}^{N} \hat{p}_i y_i}{\sum_{i}^{N} \hat{p}_i^2 + \sum_{i}^{N} y_i^2}, \tag{2} LDice=∑iNp^i2+∑iNyi22∑iNp^iyi,(2) L F o c a l = − ∑ i N α y i ( 1 − p ^ i ) γ log ( p ^ i ) − ( 1 − y i ) p ^ i γ log ( 1 − p ^ i ) , (3) \mathcal{L}_{Focal} = -\sum_{i}^{N} \alpha y_i (1-\hat{p}_i)^\gamma \log(\hat{p}_i) - (1-y_i)\hat{p}_i^\gamma \log(1-\hat{p}_i), \tag{3} LFocal=−i∑Nαyi(1−p^i)γlog(p^i)−(1−yi)p^iγlog(1−p^i),(3) 预后端采用负对数似然损失(NLL),如公式 4 所示。如文献 [15] 所述,NLL 损失的第一行对应非删失数据,第二行对应删失数据,第三行为归一化常数。其中, w k T x ( n ) w_k^T x^{(n)} wkTx(n) 为模型预测值, b k b_k bk 为偏置项, y k y_k yk 为真实标签。
L N L L ( θ , D ) = ∑ n : δ ( n ) = 1 ∑ k = 1 K − 1 ( w k T x ( n ) + b k ) y k ( n ) + ∑ n : δ ( n ) = 0 log ( ∑ i = 1 K − 1 1 { t i ≥ T ( n ) } exp ( ∑ k = 1 K − 1 ( ( w k T x ( n ) + b k ) y k ( n ) ) ) ) − ∑ n = 1 N log ( ∑ i = 1 K exp ( ∑ k = 1 K − 1 w k T x ( n ) + b k ) ) , \begin{align*} \mathcal{L}_{NLL}(\theta, D) &= \sum_{n: \delta^{(n)} = 1} \sum_{k=1}^{K-1} (w_k^T x^{(n)} + b_k) y_k^{(n)} \\ &\quad + \sum_{n: \delta^{(n)} = 0} \log \left( \sum_{i=1}^{K-1} \mathbb{1}\{t_i \geq T^{(n)}\} \exp \left( \sum_{k=1}^{K-1} \left( (w_k^T x^{(n)} + b_k) y_k^{(n)} \right) \right) \right) \\ &\quad - \sum_{n=1}^N \log \left( \sum_{i=1}^K \exp \left( \sum_{k=1}^{K-1} w_k^T x^{(n)} + b_k \right) \right), \tag{4} \end{align*} LNLL(θ,D)=n:δ(n)=1∑k=1∑K−1(wkTx(n)+bk)yk(n)+n:δ(n)=0∑log(i=1∑K−11{ti≥T(n)}exp(k=1∑K−1((wkTx(n)+bk)yk(n))))−n=1∑Nlog(i=1∑Kexp(k=1∑K−1wkTx(n)+bk)),(4)
本研究网络训练所用的最终损失函数由上述三种损失组合而成,如公式 (5) 所示。超参数 β β β 用于为模型的两个分支分配权重,本研究中经验性地设置为 0.3。
L F i n a l = β ∗ ( L D i c e + L F o c a l ) + ( 1 − β ) ∗ L N L L (5) \mathcal{L}_{Final} = \beta * (\mathcal{L}_{Dice} + \mathcal{L}_{Focal}) + (1 - \beta) * \mathcal{L}_{NLL} \tag{5} LFinal=β∗(LDice+LFocal)+(1−β)∗LNLL(5)
3、实验与结果
3.1、数据集
(1)HECKTOR 挑战赛平台提供了一个多中心数据集,包含 PET 与 CT 影像、对应的分割掩码及电子健康记录数据。该数据来自 6 个不同的临床中心,其中训练集包含 224 例患者数据,测试集包含 101 例患者数据。由于竞赛需求,测试集的分割与预后任务真实标签未公开,因此本研究未使用其验证方法性能,转而在训练集上进行了 5 折交叉验证。
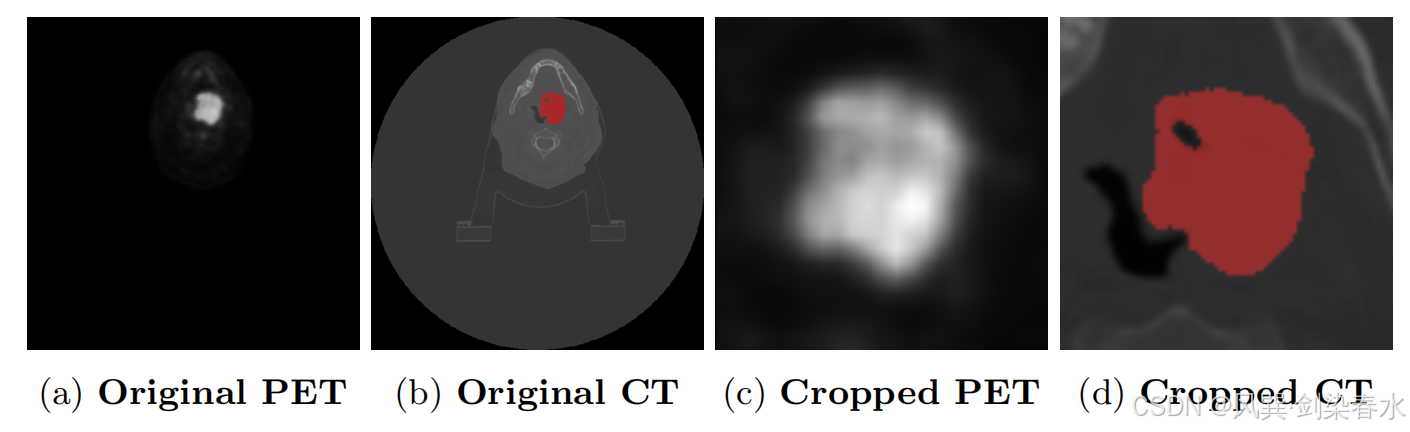
(2)电子健康记录(EHR)包含性别、体重、年龄、肿瘤分期(N 分期、M 分期、T 分期)、烟酒史、化疗史、人乳头瘤病毒(HPV)感染情况、TNM 分期版本及 TNM 分组等信息。影像数据包含 CT、PET 图像及肿瘤分割掩码,其样本切片分别如 图 2 所示。
Figure 2 | 影像数据集中的一个样本:(a) 展示原始 PET 扫描图像;(b) 展示原始 CT 扫描图像及叠加的真值掩膜;( c) 显示经裁剪后的 80×80×48 像素 PET 图像;(d) 显示经裁剪后的 80×80×48 像素 CT 图像及其真实 mask。
3.2、数据预处理
影像重采样与归一化
(1)将 CT、PET 图像统一重采样至 1.0 m m 3 mm^3 mm3 各向同性体素间距;
(2)CT:HU 值截断至 [−1024,1024],再归一化至 [−1,1];PET:采用 Z-score 标准化
图像裁剪
(1)将图像裁剪为 80×80×48 m m 3 mm^3 mm3 的尺寸,以实现方法对比并提升训练效率;
EHR 数据清洗
(1)剔除多中心数据中缺失率过高的变量(如吸烟 / 饮酒史、HPV 状态等);
(2)处理删失数据:将 75% 的删失样本标记为终止随访;
3.3、实施细节
硬件与训练设置
(1)硬件:单张 NVIDIA RTX A6000(48GB)。
(2)框架:PyTorch。
(3)训练参数:训练轮次 50 epoch,批量大小 16,初始学习率 4 × 10 − 3 4×10^{−3} 4×10−3,权重衰减 1 × 10 − 5 1×10^{−5} 1×10−5;第 35 轮后学习率衰减 10 倍。
模型结构参数
(1)图像块尺寸:16×16×16,嵌入维度 768。
(2)Transformer 编码器:12 层,每层 12 个注意力头。
(3)损失函数:权重系数 β = 0.3 β=0.3 β=0.3,超参数通过 OPTUNA 调优确定。
评估指标
(1)预后任务:一致性指数(C-index)。
(2)分割任务:Dice 相似系数(DSC)。
3.4、实验结果
Table 1 | 不同模型在 Hecktor 数据集上的预测性能:报告结果为 5 折交叉验证的均值及标准差;

为进行分割性能对比,本研究参照文献 [22] 的设置,复现了独立分割网络 UNETR。本研究提出的模型 Dice 相似系数(DSC)为 0.772±0.03,较专门针对分割任务优化的 UNETR 网络(DSC 为 0.774±0.01)仅低 0.002,二者性能相当。
早期 MICCAI 那么朴素么/(ㄒoㄒ)/~~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)