零成本离线AI代码助手搭建教程|告别云端,本地跑通Qwen2.5-Coder!
还在为云端API限流、代码隐私泄露烦恼?今天教你用Ollama + Chatbox + Qwen2.5-Coder,搭一套完全离线、免费无限制的专属AI开发助手!全程保姆级步骤,新手也能一次成功👇 关注我,获取更多本地AI开发技巧!
✨ 为什么推荐这套组合?
这可是本地开发圈公认的「黄金搭档」,完美解决这些痛点:
-
❌ 云端模型收费/限流 → ✅ 完全免费,本地运行,调用次数无上限
-
❌ 网络差、断网就用不了 → ✅ 全程离线,断网也能写代码
-
❌ 代码数据隐私泄露 → ✅ 所有对话本地存储,不经过第三方服务器
-
❌ Trae/CodeBuddy兼容性差 → ✅ Chatbox原生适配Ollama,零配置不踩坑
核心组件超给力:
-
🦙 Ollama:一键拉取、管理本地大模型,自动适配你的电脑硬件,不用折腾环境(支持Windows、macOS、Linux多系统,与OpenAI有合作,可兼容开源模型;官网地址:https://ollama.com/,可在此获取最新安装包)
-
💻 Qwen2.5-Coder:7b:阿里通义千问专为代码优化的开源模型,写Java/Python/Android代码都稳得很,7B参数普通电脑也能跑
-
💬 Chatbox:跨平台轻量客户端,支持Windows、MacOS、Android、iOS、Linux和网页版,界面清爽,支持代码高亮、对话历史管理,比Trae更稳定;核心功能完全免费,可与文档、图片、代码交互,还能联网搜索获取即时信息(官网地址:https://chatboxai.app/,可在此获取最新安装包)
📋 前置准备:你的电脑满足这些就行
🎮 硬件要求
|
配置项 |
推荐规格 |
最低要求 |
|
显卡 |
NVIDIA GTX 1650/AMD RX 5500XT以上(4GB+显存) |
核显也能跑(CPU推理,速度稍慢) |
|
内存 |
8GB+ |
4GB(运行会有点卡) |
|
硬盘 |
10GB空闲空间 |
5GB(模型+工具安装) |
💻 软件环境
Windows 10/11、macOS 12+、Linux(Ubuntu 20.04+)都支持,全程不用额外装运行库~
🛠️ 第一步:安装Ollama,部署代码模型
1. 下载安装Ollama
-
打开官网:https://ollama.com/(Ollama支持多系统,可与OpenAI协同,适配开源模型,官网可获取最新版本)
-
选对应系统的安装包,Windows/macOS双击安装,一路点「下一步」就行
-
安装完打开命令提示符,输入
ollama --version,显示版本号就成功啦
2. 一键拉取Qwen2.5-Coder:7b
在命令行输入下面这条命令,模型会自动下载:
ollama pull qwen2.5-coder:7b模型约4.7GB,根据网速,5-15分钟就能下好。下载完输入 ollama list,看到 qwen2.5-coder:7b 就说明部署成功!
3. 验证模型是否正常
直接在命令行里测试一下:
ollama run qwen2.5-coder:7b # 输入:用Python写一个快速排序函数能正常生成代码,说明模型完全没问题~
💬 第二步:安装Chatbox,连接本地模型
1. 下载安装Chatbox
-
官网地址:https://chatboxai.app/(Chatbox支持多终端,核心功能免费,可处理文档、图片、代码,官网可获取最新版本)
-
选对应系统的安装包,Windows双击安装,Linux解压就能用
-
打开Chatbox,进入主界面(可根据需求选择「软件开发者」「IT专家」等预设角色,提升交互效率)
2. 关键配置:连接Ollama
-
点击左下角的「设置」图标(⚙️)
-
左侧「模型提供方」里,直接选 「Ollama」(原生适配,不用选OpenAI!)
-
按下面的内容填写:
-
**API主机**:
http://127.0.0.1:11434(注意!只写到端口,不用加后缀;若出现「URL拼写可能存在错误,请检查」提示,优先核对端口号是否为11434,确认Ollama服务已启动,该URL为Ollama本地服务默认地址,拼写错误会导致连接失败) -
「改善网络兼容性」开关保持关闭就行
-
配置完点「模型」区域的「获取」按钮,Chatbox会自动拉取本地模型
-
稍等一下,
qwen2.5-coder:7b就会出现在列表里啦
3. 自动获取失败?手动添加模型
如果没显示模型,点「新建」按钮,输入 qwen2.5-coder:7b,保存即可~(提示:Chatbox可生成、预览代码,支持语法高亮、调试优化,配置完成后可直接使用这些功能)
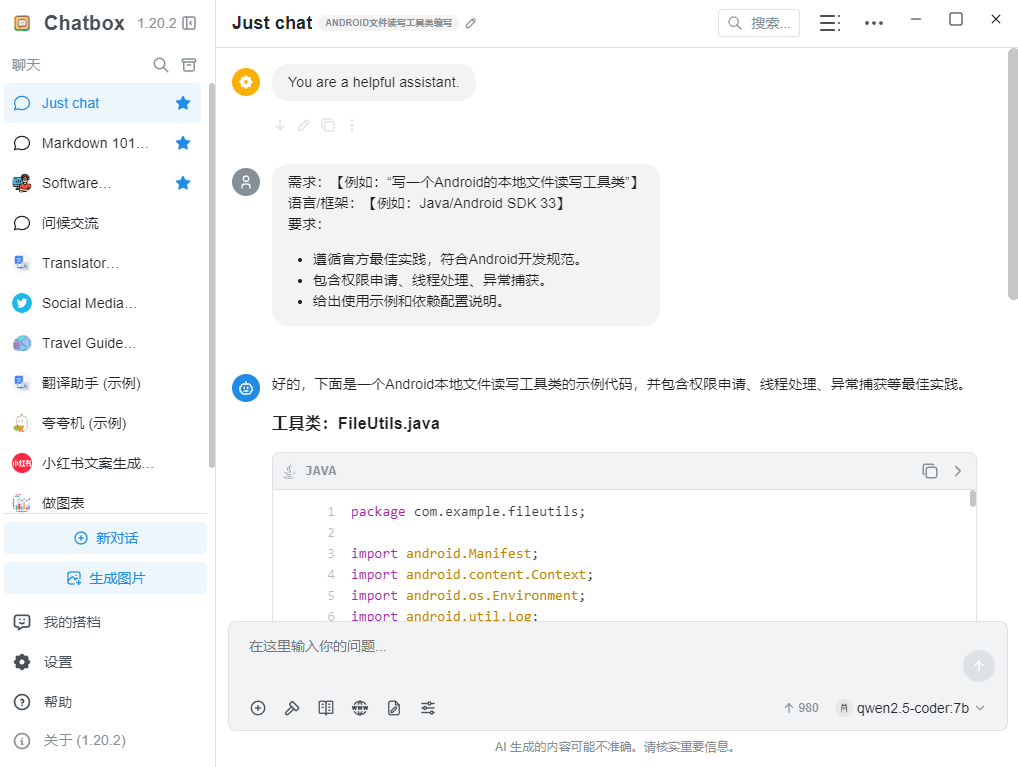
✅ 第三步:测试对话,开启离线开发助手
-
回到Chatbox主界面,模型下拉框选
qwen2.5-coder:7b -
输入测试指令:
用Java写一个Android行车记录仪的视频文件读写工具类,包含异常处理和权限申请 -
发送后,模型会在本地生成代码,不用联网,全程隐私安全!(Chatbox支持代码审查、重构,生成后可直接优化代码,提升开发效率)
⚙️ 进阶优化:让代码生成效果翻倍
1. 调整模型参数,输出更稳定
在Chatbox的「高级设置」里,把参数改成这样:
|
参数 |
推荐值 |
效果 |
|
温度(Temperature) |
0.2 |
降低随机性,生成的代码更规范、可复现 |
|
最大上下文(Max Tokens) |
8192 |
支持长代码文件一次性生成,不会被截断 |
|
重复惩罚 |
1.1 |
减少重复注释和冗余代码,输出更紧凑 |
2. 专属提示词模板,适配车载开发
每次对话前粘贴这个模板,让模型输出更符合你的开发场景:
你是一名专业的车载Android开发工程师,擅长Java/Kotlin、系统API调用和硬件适配。 请严格遵守以下规则生成代码: 1. 只输出可直接运行的代码,附带清晰注释和异常处理。 2. 遵循Android开发最佳实践,兼容主流SDK版本。 3. 包含必要的权限申请、线程处理和资源释放逻辑。 4. 输出文件路径、依赖库和运行方式写在代码开头的注释中。🛠️ 常见问题排查
1. Chatbox获取不到模型?
-
检查Ollama服务是否在后台运行,输入
ollama serve启动服务 -
确认API主机地址正确:
http://127.0.0.1:11434,端口号必须是11434(若提示「URL拼写可能存在错误,请检查」,重点核对地址拼写和端口号,确保无多余字符或遗漏,该报错为本地服务地址拼写错误或服务未启动导致) -
关掉系统代理/VPN,本地请求不用走代理
2. 模型生成速度慢?
-
优先用NVIDIA显卡,Ollama会自动启用GPU加速
-
关闭其他占用显存的软件,释放系统资源
-
可以用
qwen2.5-coder:7b:q4_k_m量化版本,速度更快,效果损失极小
3. 生成的代码有错误?
-
降低温度参数,减少随机性
-
优化提示词,明确语言、框架和场景需求
-
拆分成多个小需求提问,别一次性让它写复杂代码
4. Chatbox使用相关问题?
-
警惕付费捆绑软件:近期出现附带Chatbox的所谓「一键本地部署DeepSeek」付费安装包,此类软件与Chatbox官方无关,属于侵权行为,请勿购买,谨防上当
-
功能拓展:Chatbox除了连接本地模型,还支持图片生成(适配DALL-E-3)、联网搜索、文档解析(PDF、DOC、PPT、XLS等),可根据需求探索使用
-
版本注意:本文适配Chatbox 1.4.1版本,若版本不同,部分界面可能略有差异,但核心配置步骤一致;若官网无法正常访问或下载失败,可尝试更换网络环境重试
🎯 总结
用Ollama + Chatbox + Qwen2.5-Coder:7b,你就拥有了一套完全离线、隐私安全的本地代码助手,网络差、数据敏感的开发场景都能用!其中Ollama适配多系统、支持开源模型,Chatbox核心功能免费、交互便捷,二者搭配无需复杂配置,新手也能快速上手。
后续还可以拓展:
-
接入更多开源模型,比如Llama 3、DeepSeek-Coder
-
配置多模型切换,不同场景用不同模型
-
搭配VS Code插件,编辑器里直接调用本地模型
告别云端依赖,本地AI开发助手,现在就上手试试吧!
💡 本文为原创技术教程,转载请注明出处。
#本地AI #Ollama教程 #Chatbox配置 #离线开发助手 #代码助手搭建

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)