从 CUDA 叛逃到 ROCm:一个金融 AI 程序员的血泪迁移实录

作者:某不想被算力卡脖子的大模型从业者
发布时间:2026-04-28
关键词:ROCm、AMD Instinct、CUDA迁移、HIP、vLLM、PyTorch、MI300X
前言:为什么我要从 CUDA 跑路?
我不是 NVIDIA 的黑粉,我只是一个穷。
作为一个在金融 AI 领域打工的程序员,每天的工作离不开训练模型、跑推理。去年团队在云上用 H100 做推理服务,账单看完直接开始考虑人生的意义——那个价格,感觉不是在买算力,是在买我几根头发。
然后 AMD 的 MI300X 出现在了我的视野里。192GB HBM3 显存,怼 LLM 长上下文天然有优势;配套的 ROCm 开放生态正在快速追平 CUDA;而且价格,真的香。
于是,从去年底到现在,我把团队的核心推理链路从 CUDA 全栈迁移到了 ROCm,踩了不少坑,也学到了很多。今天就来完整复盘这段旅程。
(事先说明:本文不是广告,踩的坑都是真坑,爽的地方也是真爽。)
第一章:搞清楚 ROCm 是什么——别被名字吓到
很多人第一次看到 ROCm 这个名字,会跟我当年一样:"这是个啥?Radeon Open Compute?那不是给游戏卡用的?"
其实 ROCm(Radeon Open Compute Platform)已经是一个完整的 GPU 计算软件生态,从驱动、运行时、数学库、AI 框架,到开发工具,一条龙覆盖。截至2026年4月,ROCm 的生产推荐版本是 7.2.2,同时还有 7.9.0 技术预览版走在更激进的路上(但那个不推荐上生产,6周一个版本,我光跟版本号就能累死)。
更有意思的是,从 ROCm 6.4 开始,AMD 把驱动层从 ROCm 里拆出来,单独搞了一个 Instinct Datacenter GPU Driver,版本号也独立了(现在是 30.x 体系)。这个改动的意思是:以后你可以单独升级驱动而不用重装整个 ROCm,或者反过来,升级 ROCm 用户空间而不动驱动——IT 运维的同学可以松口气了。
当前支持的主力硬件:
- AMD Instinct MI300X:192GB HBM3,CDNA 3架构,最流行的数据中心 AI 卡
- AMD Instinct MI325X:256GB HBM3E,增强版
- AMD Instinct MI355X:288GB HBM3E,最新旗舰
- AMD Instinct MI350X / MI350:新一代,ROCm 7.0+ 支持
如果你在用 AMD 开发者云、ModelScope 魔搭创空间或者其他兼容平台,大概率环境里就已经有现成的 ROCm Docker 镜像,直接拉就完事,不用自己折腾驱动。

第二章:ROCm 环境搭建——从 Hello World 开始
2.1 最推荐的方式:用 Docker(别跟自己过不去)
本地或云端跑 ROCm,最省心的方式永远是 Docker。AMD 官方维护了一套完整的镜像体系,PyTorch、vLLM、JAX、TensorFlow 各有专属镜像,经过完整测试:
# 拉取 PyTorch ROCm 镜像(ROCm 6.4 + PyTorch 2.6)
docker pull rocm/pytorch:rocm6.4_ubuntu22.04_py3.10_pytorch_release_2.6.0
# 启动容器(关键:--device 参数暴露 GPU)
docker run -it \
--device=/dev/kfd \
--device=/dev/dri \
--group-add video \
--shm-size 16G \
--security-opt seccomp=unconfined \
-v $(pwd):/workspace \
rocm/pytorch:rocm6.4_ubuntu22.04_py3.10_pytorch_release_2.6.0
进去之后,跑个最简单的验证:
import torch
print(torch.cuda.is_available()) # ROCm 里仍然用 cuda 命名空间,返回 True
print(torch.cuda.get_device_name(0)) # 会显示 AMD Instinct MI300X
print(torch.cuda.device_count()) # GPU 数量
# 跑个矩阵乘法验证 HIP 后端
device = torch.device("cuda:0")
a = torch.randn(4096, 4096, device=device)
b = torch.randn(4096, 4096, device=device)
c = torch.matmul(a, b)
print(f"矩阵乘法完成,shape: {c.shape}")
划重点:ROCm 里的 PyTorch 保留了
torch.cuda.*的接口名!意思是你的大部分 PyTorch 代码不需要改任何一行就能在 ROCm 上跑,这是 AMD 深谋远虑的地方——或者说,是工程师们夜以继日搞兼容层的功劳。
2.2 验证 GPU 状态
# 相当于 nvidia-smi,但用 AMD 自己的工具
amd-smi monitor
# 或者老工具(未来会弃用,但现在还能用)
rocm-smi --showproductname
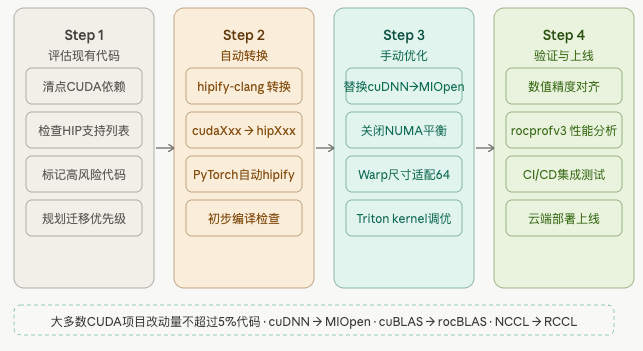
第三章:CUDA 到 ROCm 丝滑迁移——hipify 的秘密
3.1 迁移的核心思路:HIP 是桥梁
AMD 的答案叫 HIP(Heterogeneous-compute Interface for Portability)。HIP 的 API 故意设计成跟 CUDA 高度相似,核心原则就是:让你迁移的时候尽量少改代码。
CUDA 到 HIP 的映射关系举几个例子:
| CUDA | HIP(ROCm) |
|---|---|
cudaMalloc |
hipMalloc |
cudaMemcpy |
hipMemcpy |
cudaDeviceSynchronize |
hipDeviceSynchronize |
__global__ kernel |
完全相同 |
threadIdx / blockIdx |
完全相同 |
cuBLAS |
rocBLAS |
cuDNN |
MIOpen |
NCCL |
RCCL |
TensorRT |
❌ 没有直接对应,用 Triton-ROCm |
3.2 自动化工具:hipify-clang
HIPIFY 是 ROCm 自带的代码转换工具,分两个版本:
- hipify-clang:基于 Clang 的完整语法解析,准确度高,推荐用这个
- hipify-perl:正则替换,简单快速但容易漏边界情况
实际用法:
# 安装(Docker 镜像里一般自带)
sudo apt install hipify-clang
# 转换单个文件
hipify-clang my_cuda_kernel.cu --cuda-path=/usr/local/cuda-12.8 \
-I /usr/local/cuda-12.8/include
# 批量转换目录
find . -name "*.cu" -o -name "*.cuh" | \
xargs -I{} hipify-clang {} --cuda-path=/usr/local/cuda-12.8
# 查看转换统计(有哪些 API 被替换了)
hipify-clang --print-stats my_kernel.cu
转换后的文件会从 .cu 变成 .hip,里面的 cuda* 全部变成 hip*。
3.3 踩坑1:Warp Size——最容易翻车的地方
CUDA 的 Warp 大小是 32,而 AMD GPU 的 Wavefront(对应概念)大小是 64。如果你的代码里有 hardcode 的 32,或者用了 warpSize 但没用正确的运行时查询方式,迁移到 ROCm 后会算出错误结果但不报错——这是最坑的那种错误。
错误写法:
// CUDA 里没问题,ROCm 里悄悄出错
int lane_id = threadIdx.x % 32;
__shared__ float warp_reduce[32];
正确写法:
// 用宏查询,ROCm 里会自动返回 64
int warp_size = __AMDGCN_WAVEFRONT_SIZE; // 不推荐,将来要废弃
// 推荐:运行时查询
int warp_size = warpSize; // HIP 里这个变量是运行时值
int lane_id = threadIdx.x % warpSize;
// 或者直接 64 (AMD 专属优化路径)
#ifdef __HIP_PLATFORM_AMD__
const int WARP_SIZE = 64;
#else
const int WARP_SIZE = 32;
#endif
⚠️ 注意:从 ROCm 6.4 开始,
__AMDGCN_WAVEFRONT_SIZE和__AMDGCN_WAVEFRONT_SIZE__这两个宏作为编译时常量已被弃用,未来版本会删除。现在起请改用运行时查询。
3.4 踩坑2:NUMA 自动均衡必须关掉
这是我亲身血泪教训。MI300X 是一个多芯片堆叠的 GPU,内部有复杂的 NUMA 拓扑。Linux 默认的 NUMA 自动均衡(numa_balancing)会不时迁移内存页,跟 MI300X 的访存模式冲突,导致 GPU 挂起或者莫名其妙的性能抖动。
AMD 官方文档明确要求:在运行 MI300X 工作负载前必须关闭 NUMA 自动均衡。
# 关闭 NUMA 自动均衡(需要 root)
echo 0 > /proc/sys/kernel/numa_balancing
# 确认关闭(返回 0 即为关闭)
cat /proc/sys/kernel/numa_balancing
# 永久生效(写入 sysctl)
echo "kernel.numa_balancing=0" >> /etc/sysctl.conf
sysctl -p
3.5 PyTorch 项目:你可能真的一行不用改
这是 ROCm 最温暖的地方之一。PyTorch 本身内置了 HIPIFY 工具链,会在构建时自动把 CUDA 后端代码转成 HIP。对于纯 PyTorch 代码(没有自定义 CUDA kernel),迁移步骤就是:
# 第一步:换 Docker 镜像(原来的换成 ROCm 版本)
docker pull rocm/pytorch:rocm6.4_ubuntu22.04_py3.10_pytorch_release_2.6.0
# 第二步:启动容器,在里面直接运行你的训练脚本
python train.py # 就这样,没有第三步
真的就这么简单,我第一次成功跑起来的时候愣了一下,以为环境有问题。
第四章:vLLM 云端推理实战——把 LLM 服务跑在 MI300X 上
4.1 为什么选 vLLM + ROCm
对于大模型推理服务,我测试了几个方案,最终选定 vLLM。理由:
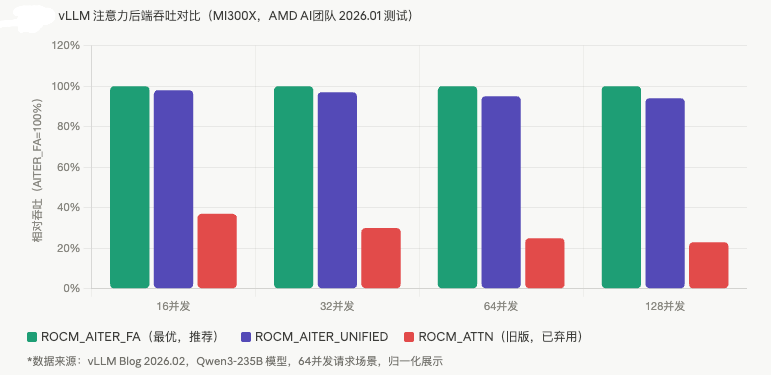
- vLLM 现在对 AMD GPU 有专项优化,2026年2月发布了 7 种注意力后端的详细对比
- 最优后端 ROCM_AITER_FA 相比旧版 ROCM_ATTN,吞吐提升 2.7~4.4倍(不是百分比,是倍数,我当时看到这个数据眼睛一亮)
- MI300X 的 192GB 显存对于大模型来说是巨大优势,可以跑很多 H100 单卡跑不动的模型
4.2 一键拉起 vLLM 服务
# 拉取 AMD 优化的 vLLM 镜像
docker pull rocm/vllm:rocm6.3.1_instinct_vllm0.8.3_20250415
# 启动推理服务
docker run -it \
--device=/dev/kfd \
--device=/dev/dri \
--group-add video \
--shm-size 16G \
--security-opt seccomp=unconfined \
-p 8000:8000 \
-e HUGGINGFACE_HUB_CACHE=/workspace \
-v $(pwd):/workspace \
rocm/vllm:rocm6.3.1_instinct_vllm0.8.3_20250415 \
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-3.1-70B-Instruct \
--tensor-parallel-size 4 \
--dtype float16 \
--max-model-len 32768
4.3 性能调优:几个关键参数
跑 vLLM 之前,先把这几个环境变量和参数配好:
# 1. 关 NUMA 自动均衡(前面说过,必须做)
echo 0 > /proc/sys/kernel/numa_balancing
# 2. 设置最优注意力后端
export VLLM_ATTENTION_BACKEND=ROCM_FLASH_ATTN
# 3. RCCL 通信优化(多卡必配)
export NCCL_MIN_NCHANNELS=112
# 4. 开 multiprocessing 模式(vLLM 推荐)
# 在启动命令里加 --distributed-executor-backend mp
启动参数调优建议:
# vLLM 在 MI300X 上的最优配置(经过实测)
launch_args = {
"--tensor-parallel-size": 4, # 4卡 TP,视模型大小调整
"--max-model-len": 32768, # MI300X 大显存,可以跑更长上下文
"--max-num-seqs": 256, # 并发请求数
"--distributed-executor-backend": "mp", # multiprocessing 模式
# 注意:MI300X 上 chunked-prefill 在某些场景会降速,先关掉测试
"--disable-chunked-prefill": True,
}
4.4 实测性能(参考)
基于 AMD 官方 2026.01 的测试数据(8x MI300X,Qwen3-235B 模型,ROCm 7.0):
- ROCM_AITER_FA 后端 vs 旧版 ROCM_ATTN:64并发场景下吞吐提升约 4倍
- TTFT(首token延迟):ROCM_AITER_FA 在 64/128 并发下明显领先
- MI300X 的 HBM3 带宽优势在长上下文场景尤为突出
第五章:云端实战——ModelScope 魔搭创空间
对于没有本地 AMD 硬件的同学,魔搭创空间(ModelScope)提供了可以直接使用 AMD 算力的实例。
5.1 环境选择
进入创空间后,选择 GPU 实例 → 查找支持 AMD Instinct 的配置。镜像建议选官方维护的 ROCm + PyTorch 组合镜像,省得自己装环境。
5.2 快速验证脚本
# 在魔搭创空间实例里,运行这个脚本验证环境
import torch
import subprocess
print("=" * 50)
print(f"PyTorch 版本:{torch.__version__}")
print(f"ROCm 版本:{torch.version.hip}")
print(f"GPU 数量:{torch.cuda.device_count()}")
for i in range(torch.cuda.device_count()):
props = torch.cuda.get_device_properties(i)
print(f"GPU {i}: {props.name}")
print(f" 显存:{props.total_memory / 1024**3:.1f} GB")
# 跑个简单的矩阵乘法基准
import time
device = "cuda:0"
N = 8192
a = torch.randn(N, N, device=device, dtype=torch.float16)
b = torch.randn(N, N, device=device, dtype=torch.float16)
# 预热
for _ in range(3):
c = torch.matmul(a, b)
torch.cuda.synchronize()
# 正式测试
t0 = time.time()
for _ in range(100):
c = torch.matmul(a, b)
torch.cuda.synchronize()
t1 = time.time()
flops = 2 * N**3 * 100 / (t1 - t0)
print(f"\n矩阵乘法 FP16 TFLOPS:{flops/1e12:.1f}")
print("=" * 50)
 第六章:我的避坑总结
第六章:我的避坑总结
迁移这几个月,我把常见问题总结成一张表,按照"踩坑概率"和"处理难度"来分:
必须处理的高风险项:
- Warp Size:硬编码 32 → 改成
warpSize或平台宏,优先级最高 - NUMA 自动均衡:不关会导致 GPU 挂起,每次启动第一件事
- TensorRT:ROCm 没有直接对应的,需要换成 Triton-ROCm 或 Composable Kernel
中等难度项:
- cuDNN → MIOpen:大部分 API 有对应,但部分算子行为细节不同,精度测试要仔细
- 自定义 CUDA kernel:hipify 能处理大部分,但复杂的 PTX/inline assembly 要手动重写
基本无痛的项:
- PyTorch 代码:拉 Docker 镜像直接跑,0改动
- vLLM 部署:换 AMD 版 Docker 镜像,加
--device参数 - NCCL → RCCL:PyTorch 框架层自动处理,用户感知不到
6.1 一个特别要提的新情况
AMD 从 ROCm 6.4 开始宣布,__AMDGCN_WAVEFRONT_SIZE 宏作为编译时常量已弃用,预计 2026年某版本删除。如果你的代码或者依赖的库里有这个宏,现在就要开始计划替换了,别等到删掉了再哭。
迁移检查清单:
# 扫描项目里所有用到这个宏的地方
grep -r "__AMDGCN_WAVEFRONT_SIZE" . --include="*.cu" --include="*.cpp" \
--include="*.hip" --include="*.h"
第七章:ROCm 生态现状评价——客观说说
作为一个从 CUDA 迁过来的用户,我尽量客观地评价一下:
ROCm 的优势:
- 开源:代码全部在 GitHub 上,遇到问题可以看源码,有种莫名的安心感
- MI300X 的显存优势:192GB 对大模型来说是降维打击,某些 H100 需要 4 卡的活,MI300X 2 卡能搞定
- PyTorch 生态支持很好:upstream 已经集成,不再是二等公民
- vLLM 性能提升明显:AITER_FA 后端的优化成果是实打实的
ROCm 的不足(截至2026年4月):
- 生态成熟度仍落后 CUDA:部分第三方库没有 ROCm 版本,某些 CUDA-only 的优化技巧无法直接复用
- 性能测试显示还有差距:针对计算密集型任务,CUDA 仍然比 ROCm 快 10~30%(内存密集型任务差距已经很小)
- 调试工具:rocprofv3 还在 beta 阶段,rocprof 旧工具即将停止支持,这个切换期有点尴尬
- 文档体验:新旧工具并存,文档分散,初学者容易看到过时内容
我的综合结论:对于以 PyTorch + vLLM 为主的推理场景,ROCm 已经完全可以生产可用;对于复杂自定义 CUDA kernel 或者重度依赖 CUDA 特有库的训练场景,迁移成本会高一些,需要评估。
结语:开放生态值得押注
从最开始对 ROCm 半信半疑,到现在把核心推理服务跑在 MI300X 上,这几个月的迁移之旅让我对 AMD 的开源策略有了更多的信心。
ROCm 不完美,坑也不少,但它在认真补。vLLM 的 AITER_FA 后端、PyTorch 的 upstream 支持、MI300X 的大显存优势——这些不是 PPT 上的数字,是实际跑起来能感受到的东西。
更重要的是,开放生态的价值在长期。当你的算力供应商不再只有一家,你跟他们谈价格的底气也不一样了。
作为一个既做 AI 工程又看一点市场逻辑的人,我觉得 ROCm 生态值得现在就开始投入时间了解——不是因为它已经全面超越 CUDA,而是因为迁移能力本身就是竞争力。
关于作者: 量化金融 + AI 工程双线作战,CSDN 博主,主要聊大模型部署、AI 基础设施和金融科技。有问题欢迎评论区讨论,踩过的坑能帮你省不少时间。
本文基于2026年4月28日前公开资料,ROCm版本信息来自AMD官方文档,vLLM性能数据来自vLLM Blog官方发布,实践经验基于个人测试环境。不同硬件配置和工作负载下实际性能可能有所差异。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)