【晓天衡宇·评测社区】法律实务榜单正式发布,评估大语言模型处理实际法律任务的实践能力
【榜单简介】
该榜单PLawBench为评测基准,对大模型在实际法律业务场景中的表现作出评测,主要覆盖用户理解、案例分析和文书生成三大方面。
PLawBench旨在评估大型语言模型(LLM)在法律实践中的表现,包含三项法律任务:用户理解、案例分析和法律文书起草,涵盖了个人事务、婚姻与家庭法、知识产权以及刑事诉讼等广泛的现实法律领域。该基准旨在评估大语言模型处理实际法律任务的实践能力。
【查看完整榜单】👉🏻 https://skylenage.net/sla/leaderboard
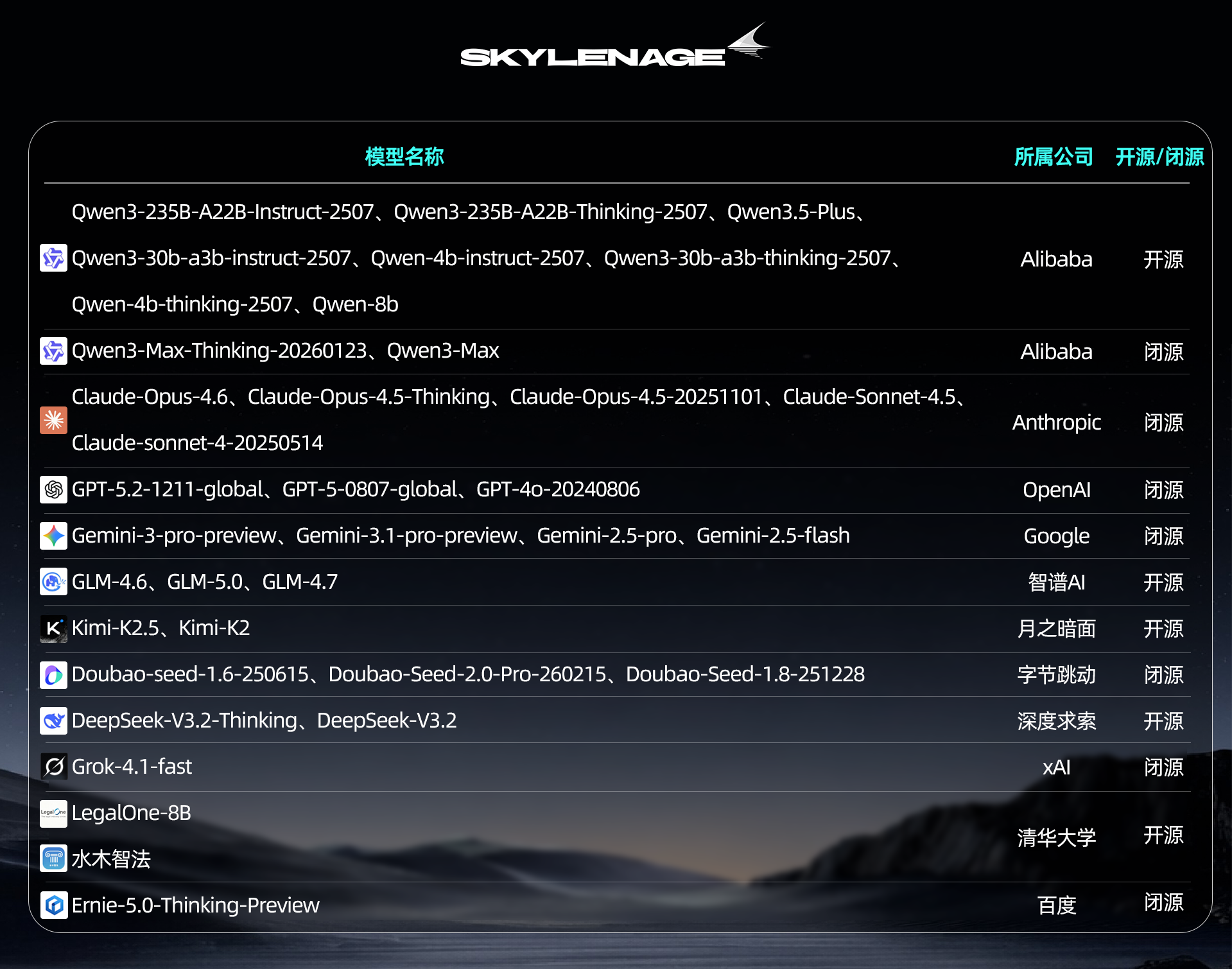
【参评模型】
【评测集解读】
评测维度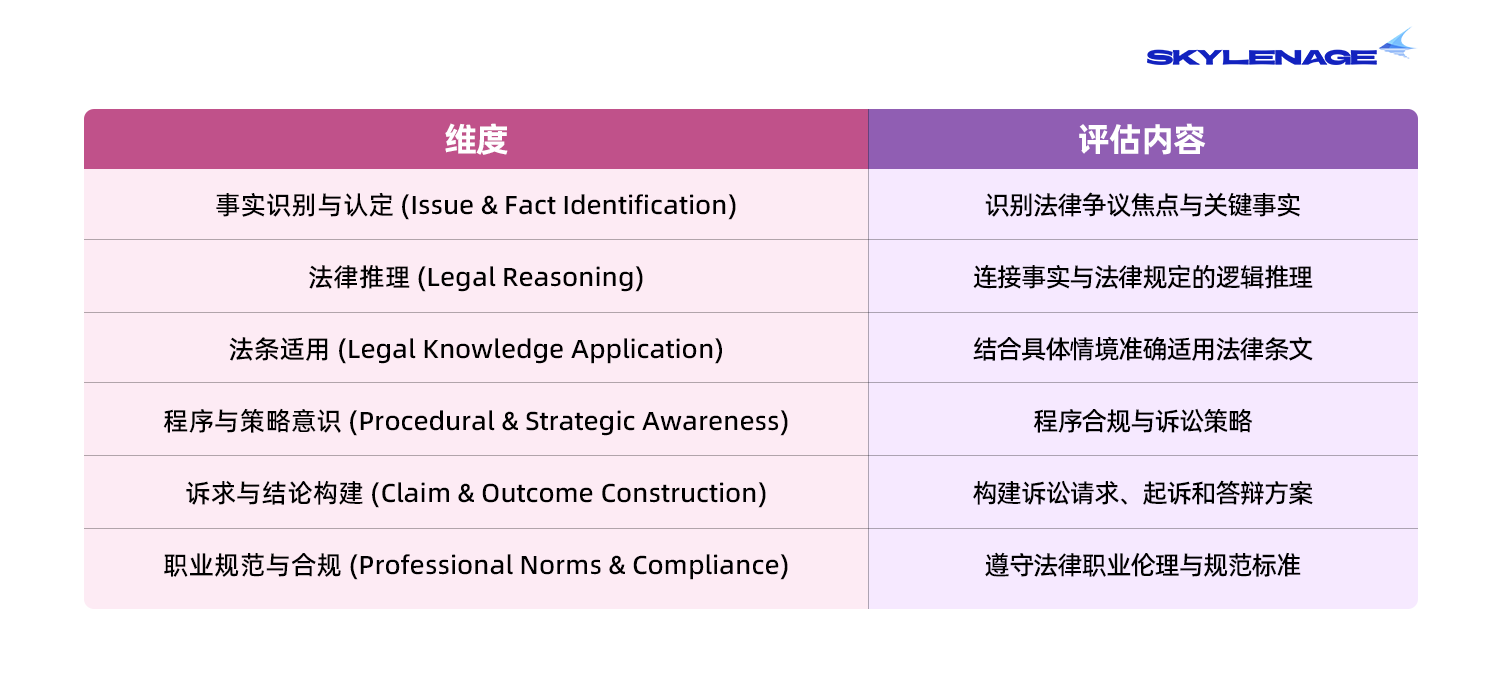
数据标准
我们采用 PLawBench(Practical Law Benchmark),一个基于真实法律实务场景的大模型评测基准,包含850道由通过国家统一法律职业资格考试的法律专家或硕士及以上学历法律从业者手工构建并标注的题目,涵盖 13 个法律实务场景,配备约 12,500个细粒度评分rubric条目,所有题目均来源于真实裁判文书、个人法律咨询记录及头部律所复杂案例。
-
广覆盖、重实务的评测场景
我们聚焦覆盖民事、商事、刑事、行政等重要法律领域,构建了从用户理解,到案例分析,再到法律文书生成这三大类任务,旨在模拟法律从业者真实的实务工作流程。 -
基于rubric的细粒度评估
不同于传统的单一准确率度量,PLawBench为每道题目设计了专属评分rubric,从事实认定、法律推理、法条适用、程序策略等多维度评价,确保评估与真实法律实践风险紧密对齐。 -
高信息密度与低同质化
题目来源涵盖裁判文书专家编辑文书、真实咨询记录以及头部律所的复杂案例,刻意引入模糊表述、情绪化叙述和关键事实遗漏等干扰,避免模板化答题。 -
能力解耦评测
我们基于法律实务的核心流程,将评测分解为六大评估维度(事实识别、法律推理、法条适用、程序策略、诉求构建、职业规范),支持定位模型具体薄弱环节并支撑针对性改进。
题目采用开放式问答(非选择题),要求模型生成完整的提问、法律分析与文书:

【评分标准】
所有模型均通过统一的 API 接口调用,采用默认超参数,仅将 max_token 限制调整为最大以确保输出完整性。模型输出由经过校准的 Gemini-3.0-Pro-Preview 担任 LLM Judge 自动评分(该评判模型在与人类专家的一致性研究中表现最优)。
为构建科学、客观且具备区分度的评价体系,我们从任务维度得分率和加权综合得分两大层面对模型进行全方位画像。
得分率

各任务子维度
根据任务特点,我们在三个任务中评测不同子维度:
Task 1(用户理解):综合评测咨询回复质量;
Task 2(案例分析):评估四个维度——结论 (Conclusion)、事实 (Facts)、推理 (Reasoning)、法条 (Statute);
Task 3(法律文书生成):区分原告文书 (Plaintiff) 和被告文书 (Defendant) 两个视角。
综合得分
综合得分为三个任务得分率的加权平均,权重按题目数量比例分配(Task1 : Task2 : Task3 ≈ 2 : 5 : 3)加权平均。
LLM Judge 评分范式
所有维度的数据均由经过校准的 Gemini-3.0-Pro-Preview 担任评委,依据每道题目的专属rubric对模型输出逐项评分。该评判模型在Pearson相关系数和Spearman相关系数上均展现出与人类专家最高的一致性(Pearson: Analysis 0.809 / Draft 0.715 / Consultation 0.861)。
【榜单速览】
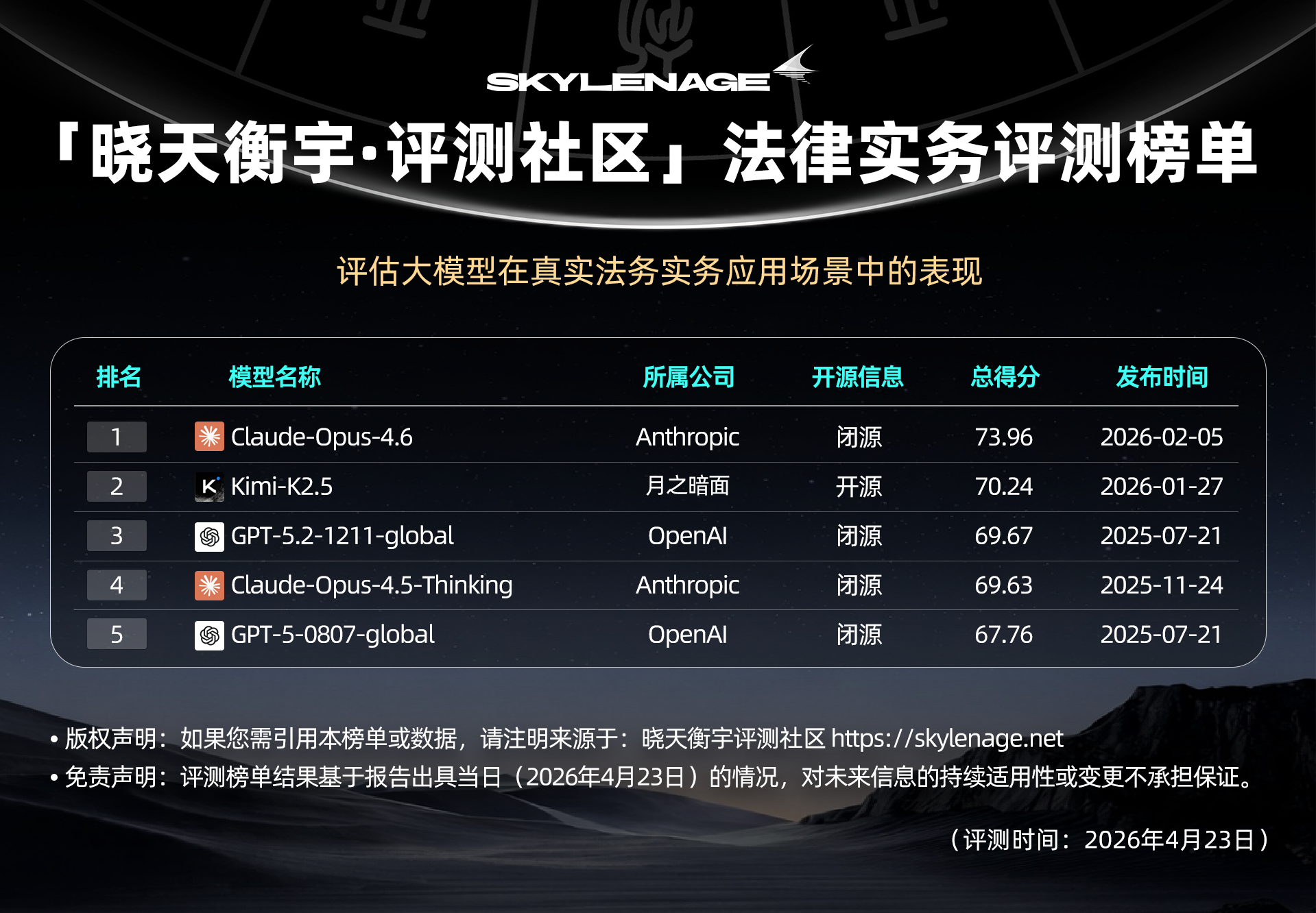
在模型性能对比中,Claude-opus-4-6 以 73.96% 的综合得分率位居榜首,显著优于其他模型,体现了其在复杂法律推理任务上的卓越能力。紧随其后的是 Kimi-k2.5(70.24%) 和 GPT-5.2-1211-global(69.67%),这三款模型稳居第一梯队。
Claude-opus-4-5-thinking(69.63%)、GPT-5(67.76%)、Gemini-3.0-pro(66.35%)、Gemini-3.1-pro(66.22%)、Claude-opus-4-5(66.47%)、Claude-sonnet-4-5(65.88%)、Qwen3-max-thinking(65.14%)、Qwen3-max(64.75%)集中在 65%–70% 区间,构成了性能稳定的第二梯队。
而在法律专用小模型方面,LegalOne-8B(60.03%) 表现值得关注,超越了多个通用大模型。
👉【获取完整榜单】
此处仅展示综合评分前五名预览,查看完整排名以及细分维度的详细对比数据,请访问晓天衡宇•评测社区官网:https://skylenage.net/sla/leaderboard
【榜单结论】
1、Task1(用户理解)与Task2(案例分析)的得分率普遍高于Task3(法律文书生成)
模型在咨询和分析任务中表现更佳,Task1平均得分率达70.2%,Task2达65.8%,而Task3仅为57.3%。这反映了当前模型在"安全生成"(遵循用户指令)方面的优势,但"推理深度"(主动识别程序瑕疵)存在明显短板。
Gemini 系列 在案例分析中擅长构建推理链条,但在处理咨询任务的复杂证据时偶有不足,说明当前模型尚无法兼顾"格式化生成"与"深度推理"——程序化任务表现优异的模型,在需要深度法律三段论推理的任务上往往力有未逮。
2、法律推理链的脆弱性
Task 2(案例分析)的四个子维度数据揭示了关键发现:
|
模型 |
结论 (Conclusion) |
事实 (Facts) |
推理 (Reasoning) |
法条 (Statute) |
|
Claude-opus-4-6 |
75.20 |
89.77 |
74.94 |
60.55 |
|
Kimi-k2.5 |
73.18 |
86.26 |
67.83 |
53.17 |
|
GPT-5.2 |
69.93 |
88.26 |
60.38 |
48.59 |
|
Qwen3-235b-instruct |
64.34 |
91.90 |
60.07 |
42.52 |
|
GPT-4o |
54.79 |
67.90 |
34.46 |
15.82 |
事实识别 (Facts) 维度得分普遍最高,多数前沿模型可达 80%–92%,说明模型在关键事实提取方面已具备较强能力。
法条引用 (Statute) 维度得分普遍最低,即便是最强的 Claude-opus-4-6 也仅有 60.55%,GPT-4o 更是低至 15.82%。这暴露了模型在精确引用法律条文方面的严重短板,包括引用已废止法条、条文编号与内容错配、一般法与特别法混淆等问题。
推理 (Reasoning) 维度介于两者之间,模型未能遵循法律三段论(大前提→小前提→结论)的逻辑链条,常出现逻辑跳跃或遗漏核心推理步骤,导致结论虽看似合理但法理上站不住脚。
3、代际跃迁效应显著
性能与模型规模和迭代代际呈正相关。同系列内,新一代模型持续超越旧版本:
Claude: opus-4-6(73.96)> opus-4-5-thinking(69.63)> opus-4-5(66.47)> sonnet-4-5(65.88)> sonnet-4(53.55);
GPT: 5.2(69.67)> 5(67.76)>> 4o(35.76),GPT-4o 排名垫底,凸显代际间法律推理能力的巨大跃迁;
Qwen: Qwen3-max(64.75)> 235b(63.08)> 30b(55.73)> 8b(43.11),规模效应明显。
(4)法律文书生成中的"盲从指令"问题
Task 3(法律文书生成)中,原告文书 (Plaintiff) 得分普遍低于被告文书 (Defendant)。
|
模型 |
Task3 均分 |
原告 |
被告 |
|
Claude-opus-4-6 |
70.12 |
70.51 |
69.72 |
|
GPT-5.2 |
68.58 |
58.25 |
63.42 |
|
GPT-5 |
68.54 |
61.05 |
76.03 |
|
Kimi-k2.5 |
64.08 |
59.64 |
68.53 |
|
Grok-4.1-fast |
39.23 |
30.25 |
48.22 |
这一问题源于模型在面对用户指令化时法律判断力的缺失。在原告角色中,模型倾向于盲目遵循用户指令(例如根据当事人要求列出不适格的被告或者选择了错误的管辖法院),而非主动识别用户叙述中隐藏的程序性瑕疵。DeepSeek 和 Kimi 系列尤为明显,表现为诉讼主体适格性错误 (Subject Suitability Errors)。
(5)法律专用模型 vs 通用大模型
值得注意的是,法律垂直领域模型的表现超出预计:LegalOne-8B(60.03%)仅以 8B 参数规模即超越了多个百亿级通用大模型(如 DeepSeek-V3.2 57.97%),说明垂直领域适配训练十分具有价值。
PLawBench 的榜单揭示了当前大语言模型在法律实务场景中的三个核心挑战:
1. 法律推理链条脆弱:模型在事实提取方面表现尚可,但在法律的严格逻辑推理上普遍薄弱,频繁出现逻辑跳跃和关键推理步骤缺失。
2. 法条引用精确度不足:即便最强模型的法条引用准确率也仅约 60%,引用废止法条、条文错配等幻觉问题普遍存在。
3.程序性法律判断缺失:模型倾向于"盲从式输出",缺乏主动识别程序瑕疵和进行策略性法律判断的能力。
当前最高综合得分率为 73.96%(Claude-opus-4-6),表明没有任何模型在 PLawBench上取得强势表现,法律实务场景下的细粒度推理能力仍有巨大提升空间。
【了解更多】
法律实务评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据:https://skylenage.net/sla/leaderboard
👇关注晓天衡宇•评测社区官方平台,获取更多大模型相关知识~ 

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 14
14 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)