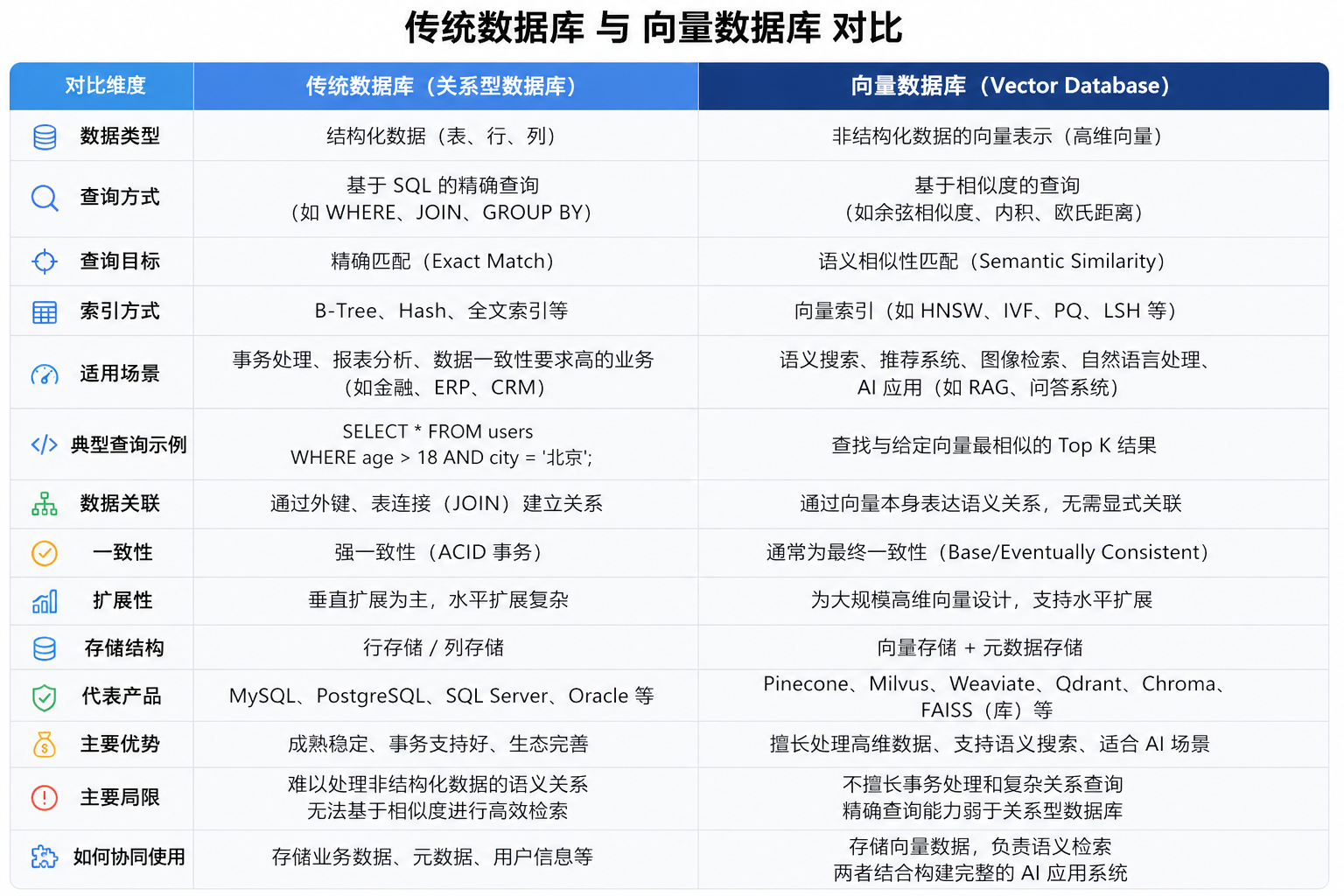
MySQL 与向量数据库的核心区别:从结构化数据到语义搜索
在数据技术不断演进的今天,传统数据库已经无法完全满足人工智能时代的需求。尤其是在大模型(LLM)和语义搜索兴起之后,一类新的数据库——向量数据库,逐渐成为热门选择。那么,经典的 MySQL 与向量数据库到底有什么本质区别?它们是否会相互取代?
两种数据库解决的是不同问题
MySQL 是一种典型的关系型数据库管理系统,长期以来广泛应用于各类业务系统中,例如电商、金融、用户管理等。它的核心能力在于高效地存储和查询结构化数据。
而向量数据库(如 Pinecone、Milvus、Chroma、Qdrant)则是为人工智能场景而生,主要用于存储和检索“向量数据”。这些向量通常是文本、图片或音频经过模型编码后的结果,本质上代表的是“语义信息”。
简单来说:
- MySQL 管理的是“数据本身”
- 向量数据库处理的是“数据的含义”
数据结构:表结构 vs 高维向量
在 MySQL 中,数据以表的形式组织,每一行记录都有固定的字段类型(schema)。例如,一个用户表可能包含姓名、年龄、邮箱等字段,这些信息都是明确、结构化的。
而向量数据库存储的则是高维数组(例如 768 维、1536 维),这些数字本身没有直观含义,但通过向量之间的距离,可以衡量数据之间的相似性。可以说向量数据一个专门用于存储和高效检索高维向量,以解决“语义相似性”问题的数据库系统。它填补了传统数据库在处理非结构化数据和语义理解上的巨大鸿沟。
两者之间的核心区别:
- MySQL 像一个 Excel 表格,你可以通过字段精准查找数据
- 向量数据库像一个“感知引擎”,可以帮你找到“感觉上相似”的内容
例如:
- 一句话:“今天天气很好”
- 经过模型编码 → 一个向量
- 另一句话:“阳光明媚的一天”
- 两者向量距离很近 → 语义相似
查询方式:精确匹配 vs 相似度搜索
查询方式是两者的最核心的区别
MySQL:精确查询
MySQL 使用 SQL 进行条件查询,例如:
SELECT * FROM users WHERE age = 25;
这种查询方式依赖明确的条件匹配,非常适合业务逻辑清晰的场景。
向量数据库:相似度检索
向量数据库则通过计算向量之间的距离来完成查询,例如:
- 查找“和这段话最相似的内容”
- 查找“最像这张图片的图片”
常见的相似度计算方式包括:
- 余弦相似度
- 欧几里得距离
这种方式更接近人类的“模糊理解能力”。
索引机制:B+ 树 vs ANN
为了提高查询效率,两类数据库采用了完全不同的索引策略:
- MySQL 使用 B+ 树索引,适合范围查询和精确匹配
- 向量数据库使用 ANN(近似最近邻)算法,例如 HNSW(分层小世界图)、IVF(倒排文件索引)
ANN(Approximate Nearest Neighbor,近似最近邻) 的优势在于:即使在数百万甚至上亿条向量数据中,也能快速找到“最相似”的结果。
典型应用场景对比
MySQL 适合的场景
- 电商系统(订单、库存)
- 用户管理系统
- 财务与交易系统
- 后台管理系统
向量数据库适合的场景
- 语义搜索(替代关键词搜索)
- AI 问答系统(RAG)
- 推荐系统(猜你喜欢)
- 图像检索(以图搜图)
是否可以互相替代?
答案是:不能。
实际上,在现代 AI 系统中,这两类数据库往往是“协同工作”的关系。例如:
- 使用 MySQL 存储业务数据(用户、订单等)
- 使用向量数据库存储 embedding(语义向量)
- 通过向量检索找到相关内容,再回到 MySQL 获取详细信息
这种架构在智能客服、知识库问答、搜索引擎中非常常见。
向量数据库
常用向量数据库对比
| 维度 | Pinecone | Milvus | Qdrant | Weaviate | Chroma | Elasticsearch / OpenSearch |
|---|---|---|---|---|---|---|
| 类型 | 云原生托管 | 开源分布式 | 开源(Rust) | 开源+云 | 轻量本地 | 搜索引擎扩展 |
| 部署方式 | SaaS | 自建/云 | 自建/云 | 自建/云 | 本地为主 | 自建/云 |
| 上手难度 | ⭐ 最简单 | ⭐⭐⭐⭐ 较复杂 | ⭐⭐ 简单 | ⭐⭐ 中等 | ⭐ 最简单 | ⭐⭐⭐ 中等 |
| 运维成本 | ⭐ 最低 | ⭐⭐⭐⭐ 高 | ⭐⭐ 低 | ⭐⭐ 中等 | ⭐ 极低 | ⭐⭐⭐ 中等 |
| 扩展能力 | 自动扩展 | 强(分布式) | 中等 | 强 | 弱 | 强 |
| 适合数据规模 | 百万~亿级 | 亿级以上 | 百万级 | 百万~亿级 | 小规模 | 百万级 |
| 索引支持 | 内部封装 | HNSW / IVF / PQ | HNSW | HNSW | FAISS封装 | HNSW |
| 查询性能 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 精度控制 | 自动优化 | 高(可调) | 中(简单调参) | 中 | 低 | 中 |
| 过滤能力(Filter) | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ |
| 混合搜索(Hybrid) | ⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ |
| AI生态集成 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 内置Embedding | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ |
| LangChain支持 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 多租户支持 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐ | ⭐⭐⭐⭐ |
| 持久化能力 | 云托管 | 强 | 强 | 强 | 弱 | 强 |
| 适合生产环境 | ✅ 强烈推荐 | ✅ 企业级 | ✅ 推荐 | ✅ 推荐 | ⚠️ 不建议 | ✅ 推荐 |
| 典型场景 | RAG / SaaS AI | 大规模AI平台 | 推荐系统 / RAG | AI应用平台 | Demo / 本地实验 | 搜索+推荐 |
相关推荐:
初创 / 快速上线 → Pinecone
本地开发 → Chroma
企业 / 大规模 → Milvus
通用项目 → Qdrant(最均衡)
AI原生应用 → Weaviate
搜索系统 → Elasticsearch

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)