自动驾驶数据闭环中,Video Clip 的多模态特征到底怎么提取?
一、问题背景:Clip 不是视频,而是一个多模态数据包
在自动驾驶数据闭环里,我们经常会说:
从一个 Clip 中提取 GPS 轨迹 shape、天气检测结果、关键帧 CLIP embedding 等特征。
很多人第一反应会以为 Clip 就是一段 .mp4 视频,然后所有特征都从视频画面里提取。
这是一个典型误区。
在自动驾驶场景中,一个 Clip 通常不是单一视频文件,而是一段时间窗口内的多模态数据包,里面可能包含:
1. 多路 Camera 视频
2. LiDAR 点云
3. Radar 目标
4. GPS / RTK / IMU 定位轨迹
5. CAN 总线信号
6. 车辆控制信号
7. 感知 / 预测 / 规控中间结果
8. 地图匹配结果
9. 人工接管 / 急刹 / TTC 等事件信号
所以,工程上真正要做的不是“从视频里提取所有东西”,而是:
把一个多模态 Clip 中不同来源的数据,对齐到同一个时间窗口下,然后分别提取语义特征、运动特征、环境特征和结构化标签,最终形成可检索、可训练、可评测的数据资产。
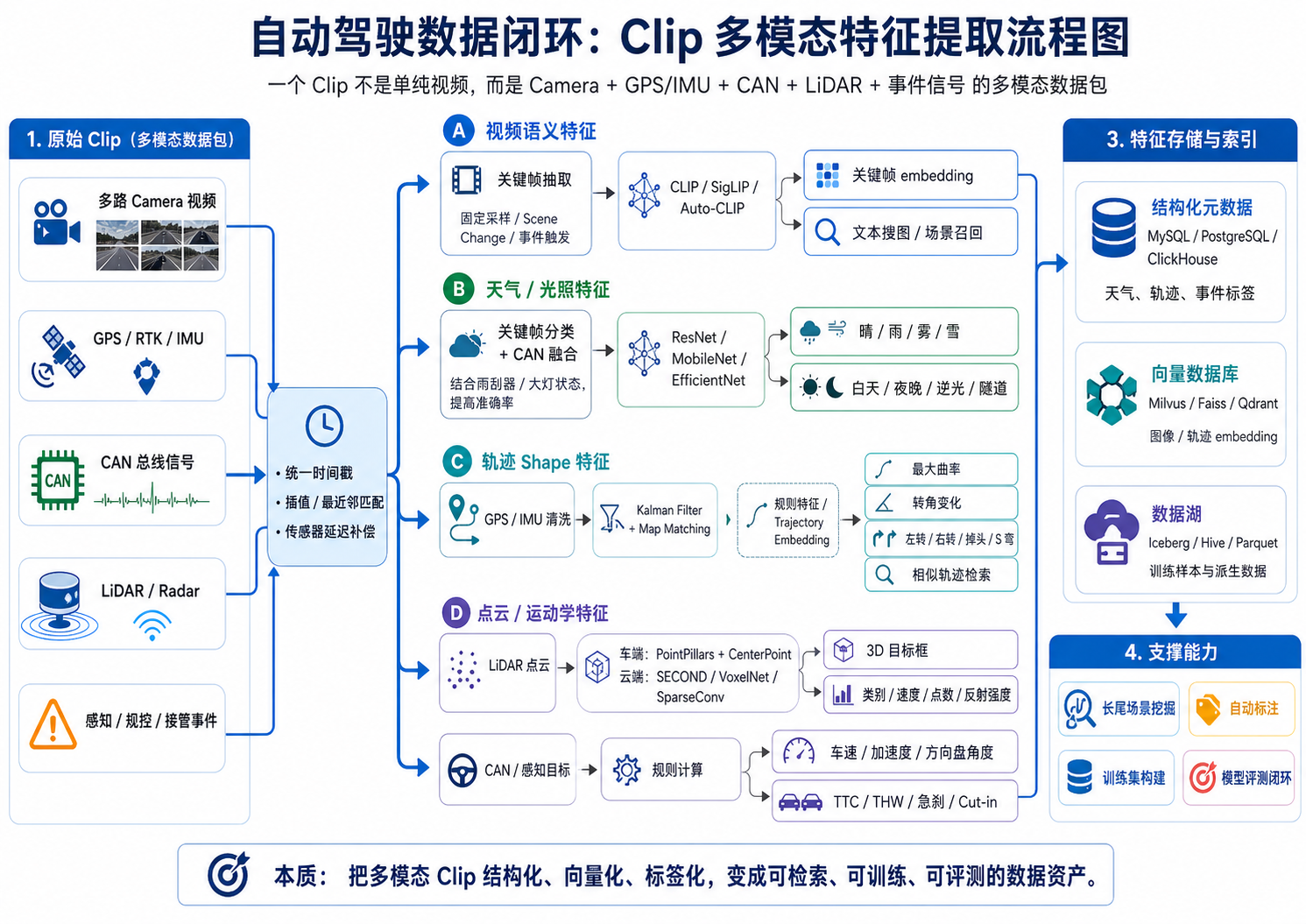
二、整体 Pipeline:一个 Clip 如何变成可检索特征?
一个典型的自动驾驶 Clip 特征提取流水线,可以抽象成下面这个结构:
Raw Clip
├── Camera Video
├── GPS / IMU
├── CAN Signal
├── LiDAR / Radar
├── Perception Result
└── Event Trigger
↓ 时间同步 / 数据对齐
Feature Extraction
├── 关键帧抽取
├── 图像语义 embedding
├── 天气 / 光照识别
├── GPS 轨迹 shape 编码
├── 运动学特征提取
├── 点云特征提取
└── 场景规则标签生成
↓
Feature Store / Metadata Store
├── MySQL / PostgreSQL:结构化标签
├── Iceberg / Hive:批量训练数据
├── Milvus / Faiss:向量索引
└── S3 / OSS / HDFS:原始 Clip 与派生数据
最终目标是让系统支持类似这样的检索:
搜索:雨天 + 夜晚 + 大曲率左转 + 前方行人横穿 + 接管前 5 秒
如果没有特征提取和元数据建设,这种查询只能靠人工翻视频。
有了特征化之后,就可以通过:
结构化条件过滤 + 向量相似检索 + 规则场景标签
快速定位目标数据。
三、关键帧 CLIP Embedding 怎么提取?
1. 为什么要提取关键帧 embedding?
视频原始数据太大,不能每一帧都进入语义模型。
比如一段 30 秒视频,30 FPS,一路摄像头就有:
30 秒 × 30 帧 = 900 帧
如果是 6 路摄像头,就是 5400 帧。
全量跑视觉大模型,成本不可接受。
所以第一步必须做关键帧抽取。
2. 关键帧抽取方法
工程上常见三种方案。
方案一:固定采样
最简单:
每 1 秒抽 1 帧
每 2 秒抽 1 帧
适合做粗粒度语义检索。
优点是简单稳定,缺点是可能漏掉突发事件。
方案二:帧间差分 / Scene Change
通过相邻帧差异判断画面变化:
diff = abs(frame_t - frame_t-1)
score = mean(diff)如果 score 超过阈值,就认为发生了明显变化。
工程上可以用:
FFmpeg scene filter
OpenCV frame difference
SSIM
更推荐在大规模离线处理中使用 FFmpeg,因为它在 C/C++ 层完成解码和过滤,避免 Python 层大量内存拷贝。
示例:
ffmpeg -i input.mp4 \
-vf "select='gt(scene,0.3)'" \
-vsync vfr \
keyframe_%05d.jpg方案三:事件触发关键帧
自动驾驶里最有价值的不是随机帧,而是事件前后的帧。
例如:
接管前 5 秒
急刹前 3 秒
TTC 小于阈值的时间段
感知低置信度时刻
规划轨迹突变时刻
这种方式最适合做数据闭环,因为它直接围绕模型失败场景抽样。
3. CLIP Embedding 用什么模型?
关键帧抽出来之后,需要把图像变成向量。
常见模型:
CLIP ViT-B/32
CLIP ViT-L/14
Chinese-CLIP
SigLIP
EVA-CLIP
自研自动驾驶场景 CLIP
基础流程:
关键帧
↓
Resize / Normalize
↓
Image Encoder
↓
Embedding Vector
↓
写入 Milvus / Faiss / Qdrant
示例输出:
{
"clip_id": "clip_20260428_001",
"camera": "front",
"timestamp": 1714280001.234,
"embedding_dim": 768,
"embedding": [0.012, -0.331, 0.092, "..."]
}4. CLIP Embedding 适合解决什么问题?
它最适合做语义召回。
例如:
“雨天路口有行人横穿”
“前方大货车遮挡视野”
“施工区域锥桶密集”
“夜晚逆光场景”
文字 query 经过 Text Encoder 变成文本向量,图片经过 Image Encoder 变成图像向量,两者可以做相似度检索。
但要注意:
CLIP Embedding 适合做候选召回,不适合直接作为最终真值。
因为它可能把“广告牌上的人”和“真实行人”混淆,也可能对中国道路上的特殊交通参与者理解不足。
所以工程上通常是:
CLIP 粗召回
↓
规则 / 轻量模型 / VLM 精筛
↓
人工抽检
↓
进入训练集
四、天气 / 光照特征怎么提取?
1. 天气不是只靠图像判断
天气特征看似可以从视频中识别,但真实工程里不能只依赖视觉模型。
因为图像可能受曝光、污渍、摄像头脏污影响。
更稳的方式是多源融合:
视觉分类结果
+ CAN 信号
+ 雨刮器状态
+ 大灯状态
+ 时间信息
+ 地理位置天气 API
+ 感知模型置信度变化
2. 视觉侧用什么模型?
如果只是识别:
晴天
雨天
雪天
雾天
夜晚
逆光
隧道
脏污
不需要上大模型。
工程上更常用轻量分类模型:
ResNet-18
ResNet-50
MobileNetV3
EfficientNet-B0
ConvNeXt-Tiny
Swin-Tiny
原因很简单:
便宜
快
稳定
容易部署
适合批处理
输出可以是多标签结果:
{
"weather": {
"rain": 0.82,
"fog": 0.13,
"snow": 0.01,
"sunny": 0.05
},
"light": {
"night": 0.91,
"backlight": 0.64,
"tunnel": 0.02
}
}3. CAN 信号如何参与判断?
例如雨天识别:
视觉模型判断:rain = 0.72
雨刮器状态:wiper_level = 3
车速:45 km/h
前挡摄像头亮度下降
融合后可以给出更高置信度:
rainy = true
confidence = high
再比如夜晚:
时间戳:20:30
大灯状态:on
图像亮度:低
视觉模型:night = 0.93
最终标签:
{
"weather_tag": "rain",
"light_tag": "night",
"confidence": 0.94,
"source": ["vision_classifier", "can_wiper", "headlight"]
}五、GPS 轨迹 Shape 怎么提取?
1. 轨迹不是从视频里提取的
GPS 轨迹 shape 来自:
GPS
RTK
IMU
轮速计
高精地图匹配结果
不是来自图像。
它描述的是车在一段时间内怎么运动。
例如:
直行
左转
右转
掉头
S 弯
大曲率转弯
环岛绕行
车道偏移
低速蠕行
这些都属于轨迹 shape 特征。
2. 原始轨迹需要先清洗
原始 GPS 常见问题:
跳点
漂移
丢点
时间戳不齐
坐标系不统一
隧道/高架下定位异常
所以第一步通常是:
时间排序
异常点剔除
插值补齐
Kalman Filter 平滑
Map Matching
坐标系转换
一般会把经纬度转换成局部坐标系:
(latitude, longitude)
↓
ENU / UTM / local BEV coordinate
↓
(x, y, heading, speed, acceleration)
3. 轨迹 Shape 的规则特征
最常用的是统计特征,不一定要上深度模型。
典型特征包括:
轨迹总长度
平均速度
最大速度
平均加速度
最大减速度
最大曲率
平均曲率
航向角变化
横向位移
纵向位移
轨迹包围盒面积
是否发生掉头
是否大曲率转弯
是否频繁变道
例如曲率可以用于识别转弯:
curvature ↑ 说明轨迹弯曲程度高
heading_delta ↑ 说明车辆方向变化明显
简单标签可以这样生成:
if heading_delta > 70° and curvature > threshold:
tag = "large_turn"
if speed < 5 km/h and duration > 10s:
tag = "low_speed_crawling"
if deceleration < -4 m/s²:
tag = "hard_brake"4. 轨迹 Embedding 用什么模型?
如果只是做规则场景识别,统计特征足够。
如果要做“相似轨迹检索”,例如:
找出所有和这个 Clip 类似的左转轨迹
找出所有类似 S 弯的轨迹
找出所有类似环岛绕行的轨迹
可以把轨迹序列编码成向量。
可选模型:
LSTM / GRU
1D-CNN
Temporal Convolution Network
Transformer Encoder
Trajectory2Vec
输入:
[(x1, y1, v1, a1, heading1),
(x2, y2, v2, a2, heading2),
...
(xn, yn, vn, an, headingn)]
输出:
trajectory_embedding: 128d / 256d
但在工程里,我更建议先用规则特征 + 统计特征。
原因是:
可解释
便宜
稳定
容易调参
适合面试和生产落地
深度轨迹 embedding 更适合后续做高级相似检索。
六、点云特征怎么提取?
1. 点云特征提取的目标
LiDAR 点云主要用于提取 3D 空间结构信息。
常见目标:
障碍物 3D 检测
点云语义分割
道路边界识别
车道线 / 路沿提取
静态障碍物识别
异形物体识别
遮挡区域分析
点云地图匹配
2. 工程落地优先选什么模型?
从工程落地角度,模型选择要看场景。
车端实时 / 边缘部署
优先:
PointPillars + CenterPoint
原因:
PointPillars 把 3D 点云压成 BEV 伪图像
后面可以用 2D CNN 提特征
算子友好
TensorRT 部署相对容易
延迟低
显存占用小
这类方案适合:
车端实时感知
边缘节点快速过滤
低延迟场景触发
云端自动标注 / 离线挖掘
优先:
SECOND
VoxelNet
CenterPoint
PV-RCNN
SparseConv based 3D detector
核心是稀疏卷积。
点云天然稀疏,大部分 3D 空间没有点,如果使用普通 3D 卷积,显存和计算会爆炸。
稀疏卷积只在有点的体素上计算,更适合云端高精度离线标注。
不建议作为工程主力的模型
不建议直接上:
PointNet / PointNet++
原始点云 Transformer
原因:
KNN / Ball Query 算子不规则
TensorRT 支持不友好
访存不连续
延迟不可控
大规模部署成本高
除非是研究验证,不建议作为生产主链路。
3. 点云特征最终怎么入库?
点云模型输出一般包括:
3D box
类别
置信度
速度
朝向
点云密度
遮挡程度
反射强度统计
可以写成结构化结果:
{
"clip_id": "clip_20260428_001",
"timestamp": 1714280001.234,
"objects": [
{
"class": "vehicle",
"bbox_3d": [12.3, 3.1, 1.5, 4.2, 1.8, 1.6, 0.12],
"confidence": 0.91,
"velocity": 8.2,
"point_count": 142,
"intensity_mean": 0.63
}
]
}这些结果可以用于后续场景挖掘:
前方大车遮挡
近距离 cut-in
低反射目标
异形障碍物
施工区锥桶
点云稀疏/传感器异常
七、运动学特征怎么提取?
自动驾驶数据闭环里,很多高价值场景不是靠图像识别出来的,而是靠运动学信号发现的。
典型特征:
ego_speed
ego_acceleration
yaw_rate
steering_angle
brake_pressure
longitudinal_acc
lateral_acc
TTC
THW
relative_distance
relative_velocity
例如急刹:
if acceleration < -4.0 m/s²:
tag = "hard_brake"例如危险跟车:
TTC = relative_distance / relative_speed
if TTC < 2.0s:
tag = "dangerous_following"例如 Cut-in:
目标车辆横向距离快速减小
目标从相邻车道进入自车道
纵向距离小于阈值
TTC 降低
这些特征通常来自:
CAN
IMU
感知目标
预测轨迹
规控日志
模型不是重点,关键是规则体系 + 时序窗口 + 数据对齐。
八、最终特征如何存储?
工程上不要把所有特征都塞进一个表。
建议拆成三类存储。
1. 结构化元数据
适合存 MySQL / PostgreSQL / Doris / ClickHouse:
clip_id
start_time
end_time
vehicle_id
software_version
weather_tag
light_tag
road_type
event_type
max_speed
max_curvature
min_ttc
hard_brake_flag
takeover_flag
用于条件过滤。
2. 批量训练数据
适合存 Iceberg / Hive / Parquet:
训练样本
场景片段
关键帧路径
传感器数据路径
标注结果
质量校验结果
用于离线训练和样本构建。
3. 向量特征
适合存 Milvus / Faiss / Qdrant:
image_embedding
video_embedding
trajectory_embedding
scene_embedding
用于相似检索和语义检索。
九、一个完整的 Clip 特征结果示例
最终,一个 Clip 可能被加工成这样:
有了这种结构,后续数据检索就非常简单。
例如:
SELECT clip_id
FROM scene_metadata
WHERE weather = 'rain'
AND light = 'night'
AND takeover = true
AND min_ttc < 2.0
AND shape = 'large_left_turn';再结合向量检索:
文本 query:“雨夜路口左转时前方有行人横穿”
↓
CLIP text embedding
↓
Milvus TopK
↓
与 SQL 结果求交集
↓
得到高价值训练 Clip
十、工程落地时最容易踩的坑
1. 不做时间同步
多模态数据如果时间没对齐,后面所有特征都是错的。
例如:
{
"clip_id": "clip_20260428_001",
"time_range": ["2026-04-28T10:00:00", "2026-04-28T10:00:30"],
"vehicle_id": "car_001",
"version": "ads_v2.3.1",
"environment": {
"weather": "rain",
"light": "night",
"confidence": 0.94
},
"trajectory": {
"shape": "large_left_turn",
"max_curvature": 0.18,
"heading_delta": 86.2,
"avg_speed": 23.4,
"max_deceleration": -3.8
},
"event": {
"takeover": true,
"hard_brake": false,
"min_ttc": 1.7
},
"vision": {
"keyframes": [
{
"timestamp": 1714280001.2,
"camera": "front",
"image_uri": "s3://bucket/keyframes/001.jpg",
"embedding_id": "milvus_88231"
}
]
},
"lidar": {
"object_count": 23,
"near_vehicle_count": 4,
"low_reflectivity_object": true
},
"scene_tags": [
"rain_night",
"large_left_turn",
"takeover_before_5s",
"low_ttc",
"complex_intersection"
]
}视频帧是 t = 10.2s
GPS 是 t = 10.8s
CAN 是 t = 9.9s
点云是 t = 10.1s
如果直接拼接,会导致错误判断。
必须做:
timestamp alignment
nearest neighbor matching
interpolation
sensor delay compensation
2. 全量跑大模型
全量跑 CLIP、VLM、3D 检测大模型,成本会爆炸。
正确方式:
结构化信号粗筛
↓
轻量模型筛选
↓
TopK 候选送大模型
↓
人工抽检
3. 只有特征,没有版本
数据闭环必须记录:
特征提取代码版本
模型版本
参数版本
数据源版本
标注版本
时间窗口版本
否则模型效果变差时,无法回溯是哪批数据污染了训练集。
4. 只看召回,不看质量
挖出来 100 万个 Clip 没意义。
真正有意义的是:
是否提升目标场景 recall
是否降低接管率
是否降低碰撞率
是否改善 mAP / NDS
是否减少人工筛选成本
数据闭环的最终价值,不是数据量,而是模型改进。
十一、推荐的工程化技术选型
| 模块 | 推荐方案 | 说明 |
|---|---|---|
| 视频解码 | FFmpeg / PyAV | 大规模批处理优先 FFmpeg |
| 关键帧抽取 | 固定采样 + scene filter + 事件触发 | 不建议全帧处理 |
| 图像 embedding | CLIP / SigLIP / EVA-CLIP / Auto-CLIP | 用于语义召回 |
| 天气识别 | ResNet / MobileNet / EfficientNet | 轻量分类模型即可 |
| 轨迹特征 | 规则特征 + Kalman Filter + Map Matching | 优先可解释方案 |
| 轨迹 embedding | LSTM / GRU / 1D Transformer | 用于相似轨迹检索 |
| 点云车端模型 | PointPillars + CenterPoint | 延迟低,部署友好 |
| 点云云端模型 | SECOND / VoxelNet / PV-RCNN / CenterPoint | 精度优先 |
| 向量库 | Milvus / Faiss / Qdrant | 存 embedding |
| 元数据存储 | MySQL / PostgreSQL / ClickHouse | 存结构化标签 |
| 离线数据湖 | Iceberg / Hive / Parquet | 存训练数据资产 |
| 调度系统 | Airflow / DolphinScheduler / Argo | 管理 DAG |
| 分布式计算 | Spark / Flink / Ray | 批处理、实时、AI 任务分别适配 |
十二、总结:Clip 特征提取的本质
自动驾驶 Clip 特征提取,本质不是“从视频里抽几个特征”,而是构建一个面向模型迭代的数据索引系统。
真正工程化的做法是:
视频负责语义
GPS/IMU 负责轨迹
CAN 负责车身状态
点云负责空间结构
感知结果负责目标关系
规控日志负责失败原因
最后把它们统一沉淀成:
结构化标签
向量 embedding
场景 tag
质量分
数据版本
这样才能支撑后续的:
长尾场景挖掘
自动标注
主动学习
训练集构建
仿真回归
模型评测闭环
一句话总结:
Clip 特征提取不是算法脚本,而是自动驾驶数据闭环的索引层。谁能把 Clip 结构化、向量化、标签化,谁就能真正把 PB 级路测数据变成可训练、可评测、可迭代的模型燃料。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 17
17 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)