工信部《“人工智能+制造”专项行动》落地,PLM是最佳切入点吗?
一、政策出台背景:从“打样”到“铺开”
2026年1月,工信部等八部门联合印发《“人工智能+制造”专项行动实施意见》(以下简称《意见》)。
这份文件不是又一份“指导性文件”——它明确提出,到2027年,要推动3至5个通用大模型在制造业深度应用,打造100个工业领域高质量数据集,推广500个典型应用场景。
语气很硬。数字很具体。这是“十五五”期间落实“人工智能+”行动的关键政策文件,也是新型工业化战略的重要拐点。
但对于制造业企业的CTO和IT负责人来说,政策文件读完之后往往会面临一个更现实的问题:切入点在哪里?
从哪个系统开始,才能把AI从“概念”落到“流程”,从“试点”走向“规模化”?
《意见》给出了三大方向:研发设计、生产制造、经营管理。
这三个环节的AI融合深度和实施难度并不相同。
经营管理场景多为汿水辅助,门槛低但价值天花板明显;生产制造环节数据量大,但工业环境复杂,模型落地的成本和风险都很高;而研发设计环节——数据密度最高、流程介入点最明确、价值可量化程度最强。
所以,如果要找一个系统来承接《意见》在研发设计环节的要求,那个系统只能是PLM。
二、《意见》研发设计环节的核心要求
《意见》对“研发设计”环节的表述很有层次。
其原文提出:“重点推进智能辅助设计、软件代码辅助编写、药物研发等,打造个性化、低成本、高效能的新型研发设计模式。
加强工业研发数据集建设和开源共享,探索建立人工智能预测结果评估体系”。拆解开来,它实际上包含三个维度的要求。
第一个维度:设计自动化。“智能辅助设计”不是简单地给设计师配一个对话机器人。它要求的是从需求解析到方案输出的全链条智能化。
需求文档能不能自动解析?历史方案能不能自动检索?设计约束能不能自动校验?这些问题的答案,全部埋在PLM的数据层里。
第二个维度:数据工程。“工业研发数据集建设”是《意见》用词最重的地方之一。制造业的研发数据——图纸、BOM、工艺文件、变更单、检测报告——大多散落在PLM系统中。
如果这些数据没有统一的入口和标准,“数据集”就是空话,大模型就是无源之水。
第三个维度:知识复用与流程智能。“探索建立人工智能预测结果评估体系”这句话听起来很抽象,但拆解到制造业场景里,它就是说:让系统能够基于历史数据和知识积累,自动完成检索、匹配、推荐、校验、审批等一系列动作。
谁来做?当然是承载了这些数据和流程的系统。
三、逐项对标:PLM如何承接《意见》要求
下面我们逐一对标《意见》在研发设计环节的具体要求,看PLM在每一个切入点上的定位和价值。
3.1 文档智能解析“设计自动化”
《意见》提出“智能辅助设计”。这个词的前置条件是:设计输入必须结构化。
制造业的设计输入是什么?客户需求说明书、产品规格书、行业标准、历史设计方案、外部供应商文档——这些文档的格式五花八门,从PDF、Word到扫描件,大多数企业目前仍然依赖人工解读和录入。
这是研发效率的第一个泄开口。
PLM的文档智能解析能力,正好对应这个痛点。通过对文档的自动解析、实体识别、关键参数提取,将非结构化的需求文档转化为结构化的设计输入。
一份航空航天领域的客户需求说明书,可能涉及数百个技术参数和性能指标,人工解读通常需要2至3天,智能解析可以压缩到小时级。
这不是替代设计师,而是把设计师从繁琐的文档录入中解放出来,让他们能够专注在创造性工作上。
3.2 风险预警“智能检测”
《意见》在生产制造环节强调“安全生产风险预警与事件告警”,而在研发环节,类似的逻辑同样成立。
产品在研发阶段的设计缺陷——无论是材料选型错误、公差超差、还是工艺可制造性不足——如果没有及时发现,到中试或量产阶段才暴露,修改成本会成倍增加。
这就是所谓的“错误发现越晚,代价越大”。
PLM的风险预警能力,是基于它的数据底座和知识库实现的。
当设计方案提交后,系统可以自动将其与历史方案、行业标准、类似产品的故障模式进行比对,实时标识潜在风险点。
这种预警不是简单的“规则匹配”,而是基于大模型的语义理解——它能读懂工程图纸中的设计意图,识别出当前方案与工艺能力之间的矛盾。
一家汽车零部件企业如果能在设计阶段就抓住公差超差问题,避免开模后才发现,其节省的模具费用和时间成本是非常可观的。
3.3 BOM校验“质量前置”
BOM(物料清单)是制造业最核心的数据结构之一。
从EBOM到MBOM的转化过程,是连接研发与生产的“桥梁”。
这个过程中的任何错误——漏料、重复料号、替代关系混乱——都会直接导致生产中断。
现在很多企业的BOM校验仍然依赖人工比对,效率低下且漏检率高。
PLM的智能BOM校验,能够在设计阶段自动识别并修正这些问题。系统可以自动比对上下游
BOM的一致性,检查替代关系的合法性,校验物料选型与设计规范的匹配度。
它把质量控制的关口从“生产端”前移到了“研发端”。
这正是《意见》所强调的“质量前置”理念。不是等问题发生了再去检测,而是在设计阶段就把问题灭掉。
3.4 知识图谱“知识工程”
《意见》提出“加强工业研发数据集建设”,但光有数据集还不够。
数据必须组织化、结构化,才能被模型高效使用。
知识图谱是实现这一目标的核心技术手段。它把产品的组成关系、工艺约束、材料属性、设计经验等知识要素,组织成一张可计算、可推理的网络。
PLM是建设这张网络的天然载体。一个产品的全生命周期数据——从概念设计、详细设计、工艺规划、到变更记录、试验数据——全部存储在PLM中。
基于这些数据构建知识图谱,可以让设计师在新项目启动时,立即获取历史产品的设计经验、常见陷阱、最优工艺参数等关键信息。
这是从“经验驱动”到“知识驱动”的跳跃。
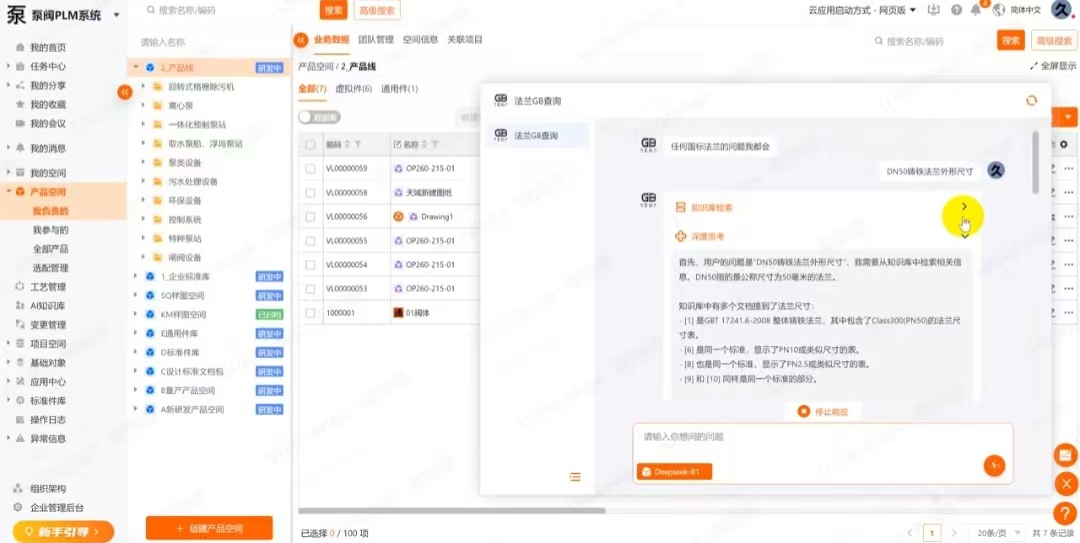
3.5 智能搜索“智能决策支持”
《意见》强调“提升辅助设计、仿真模型构建等能力”。辅助设计的前提是信息的快速获取。
传统的关键词搜索在PLM场景下效果很有限:设计师搜“轴承”,得到的结果可能包含上千条记录,但他真正需要的是“这个力矩工况下使用哪种轴承更合适”。
这是一个语义层面的问题,传统搜索解决不了。
智能搜索是解决这个问题的关键能力。
它能理解设计师的真实意图,基于语义理解和上下文关联,精准地返回最相关的历史方案、标准件、设计规范和工艺参数。
在一个成熟的PLM系统中,智能搜索可以把设计师寻找参考方案的时间从天级压缩到分钟级。这种效率提升是立竿见影的。
而且,它不是一个独立的工具,它必须深嵌在PLM的数据体系和权限体系中,才能保证检索结果的准确性和安全性。
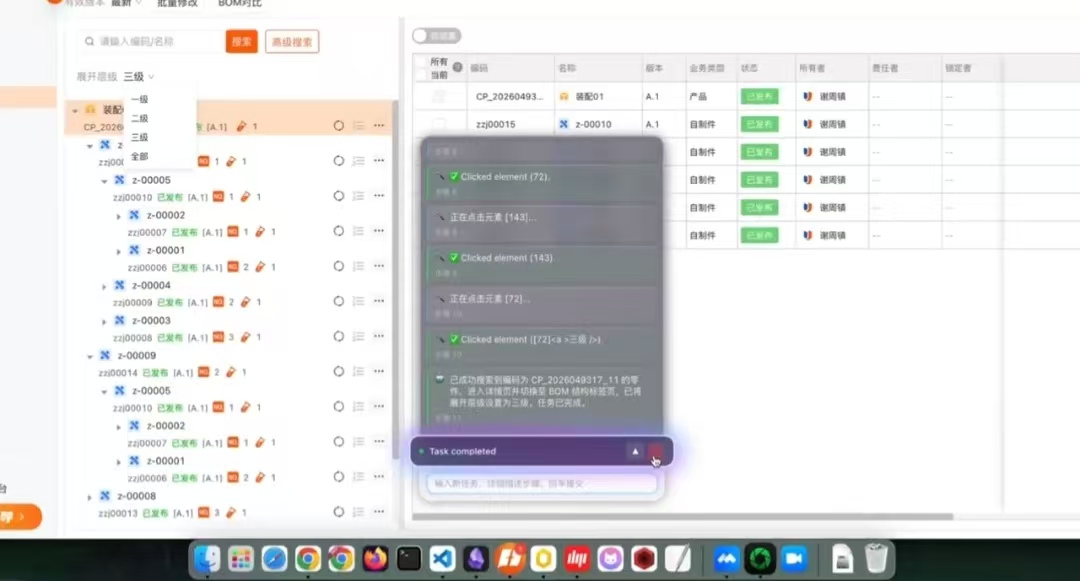
3.6 智能流程驱动“流程智能化”
《意见》的最终目标不是“单点智能化”,而是“全流程转型升级”。
设计自动化、智能检测、质量前置、知识工程、智能决策支持——这些能力如果是孤立的工具,价值很有限。
它们必须被编织进一个统一的流程框架,才能产生协同效应。而PLM,正是这个框架。
智能流程驱动的含义是:基于业务规则和AI能力,让流程本身具有“智慧”。
举个例子:当设计方案提交审批时,系统不仅能自动检查格式规范,还能自动解析方案内容,与历史方案比对,生成审批意见草稿,推送给相关审批人。审批人只需要确认或微调,而不是从零开始审阅。这是从“人驱动流程”到“AI驱动流程”的转变。而这一切的前提,是PLM已经建立了完整的流程模型和数据关系。
四、结论:研发设计环节的AI落地,PLM是第一站
回到最初的问题:《意见》落地,PLM是最佳切入点吗?
答案不是绝对的。没有什么“最佳切入点”是适用于所有企业的。不同行业、不同规模、不同数字化基础的企业,切入点应该不同。
但如果把范围缩小到《意见》中“研发设计”这一环节,那么PLM确实是数据密度最高、流程介入点最明确、价值可量化最强的系统。
具体来说,三个理由支撑这个判断。
第一,数据基础。PLM是制造业企业研发数据的唯一系统性入口。
设计图纸、BOM、工艺文件、变更记录——这些数据是训练行业大模型的原材料。没有PLM提供的结构化数据,《意见》提出的“100个高质量数据集”就缺乏数据源。
第二,流程内嵌。文档解析、风险预警、BOM校验、知识图谱、智能搜索、流程驱动——这些能力不是外挂工具,它们必须嵌入到工程变更管理、文档审批、配置管理等核心流程中才能发挥价值。
PLM是唯一具备这些流程模型的系统。
第三,价值可见。研发设计环节的AI应用,最容易量化为经济效益。
设计周期缩短20%、设计变更次数减少30%、开模前设计缺陷检出率提升到90%——这些指标可以直接转化为完整的投资回报框架,向决策层证明AI落地的价值。
所以,对于正在规划“人工智能+制造”落地路径的制造业企业,如果你的PLM系统已经建立了较好的数据基础和流程规范,那么优先从PLM切入AI融合,是成本最低、风险最小、价值最快显现的选择。
如果PLM的基础还没打好,那么先把PLM做好。
因为没有地基,就没有切入点。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)