机器学习可解释性工具LIME
文章目录
一、什么是LIME
与SHAP类似,LIME也是为了解决机器学习模型“黑盒”问题而生的一种可解释性工具。
LIME全称 Local Interpretable Model-agnostic Explanations(局部可解释的模型无关解释方法)。从名称也可以看出它的核心特点:局部(关注单个预测而非全局)、模型无关(理论上可解释任何模型)、可解释(输出人类易懂的解释)。
在机器学习场景中,LIME通过在一个局部区域内(即待解释样本附近)拟合一个简单、可解释的替代模型(如线性模型或决策树),来近似原复杂模型的决策边界。这个简单模型的参数就可以被理解为各个特征对预测结果的贡献。
简单来说,LIME回答了关键的问题:对于这个具体的预测,哪些特征起了最重要的作用?
示例:
对于这封被模型判定为“垃圾邮件”的邮件,LIME会显示:“因为出现了‘免费’、‘点击链接’等关键词,所以被判定为垃圾邮件;而‘亲爱的用户’这个特征则倾向于判定为正常邮件”。
为什么这张图片被CNN模型识别为“猫”?LIME会在图片上高亮出“猫耳朵”、“胡须”等关键像素区域,告诉你模型是基于这些特征做出的判断。
二、LIME的原理与特点
LIME的核心思想是通过在预测点附近进行扰动采样,构建一个局部线性模型来近似原模型的决策边界。
核心目标函数
LIME寻找一个可解释模型 g 来近似原模型 f,其目标是最小化以下三个部分的组合:
损失函数 L(f, g, π_x):衡量原模型 f 与替代模型 g 在局部区域 π_x 内的预测差异,差异越小越好。
模型复杂度 Ω(g):对替代模型 g 的复杂度进行惩罚(如限制线性模型的特征数量),确保替代模型足够简单、人类可以理解。
优化目标:在保证模型足够简单的前提下,找到使局部预测差异最小的替代模型 g。
其中各符号含义:
- x:待解释的样本
- f:原始复杂模型
- g:可解释的替代模型(属于模型族G,通常是线性模型)
- π_x:定义x附近的局部邻域的权重函数(距离越近的扰动样本权重越高)
- L:衡量f和g在局部区域差异的损失函数
- Ω(g):g的复杂度惩罚项
三个核心特点
LIME的设计基于以下三个关键原则:
-
局部保真度:LIME只保证在待解释样本的局部邻域内,简单替代模型与原模型的行为相似。它不关心全局的拟合效果。
-
模型无关性:LIME将原始模型视为一个黑盒,只需要能够查询模型的预测结果,而不需要访问模型内部结构。这意味着它可以解释任何模型——从简单的逻辑回归到复杂的深度神经网络。
-
可解释性:替代模型被限制为人类易于理解的简单模型(如线性模型、决策树),其参数可以直接解释为特征贡献。
LIME与SHAP的对比
| 对比维度 | LIME | SHAP |
|---|---|---|
| 理论基础 | 局部线性近似 | 博弈论Shapley值 |
| 解释范围 | 强局部解释,弱全局解释 | 局部与全局兼顾 |
| 稳定性 | 受随机扰动影响,结果可能波动 | 数学上更稳定、一致 |
| 计算效率 | 较快,采样数量可调节 | TreeSHAP较快,KernelSHAP较慢 |
| 全局特征重要性 | 需额外聚合,不原生支持 | 原生支持且数学严谨 |
| 适用场景 | 快速分析个别样本、调试异常预测 | 严谨的模型审计、全局行为分析 |
三、LIME的工作流程
LIME解释一个预测的过程可以分为四个步骤:
步骤1:生成扰动样本
- 在待解释样本 x0 附近随机生成大量扰动样本
- 对于连续特征:添加高斯噪声
- 对于离散特征:按类别分布随机采样
步骤2:获取预测结果
- 将扰动样本输入原始模型 f,获取对应的预测值
步骤3:计算样本权重
- 根据扰动样本与 x0 的距离(如欧氏距离、余弦距离)分配权重
- 距离越近的样本,在拟合替代模型时权重越高
步骤4:拟合局部替代模型
- 使用加权线性回归等方法,拟合一个可解释模型 g
- 模型 g 的系数即为各特征对预测的贡献

四、常见实现算法与技术细节
LIME的实现涉及几个关键问题的处理策略:
特征空间的表示
原始数据不一定适合直接扰动,LIME通常采用可解释特征表示:
- 对于文本:词袋表示(是否包含特定关键词)
- 对于图像:超像素表示(区域是否被激活)
- 对于表格数据:原始特征或二值化特征
扰动采样策略
不同数据类型采用不同的扰动策略:
| 数据类型 | 扰动策略 | 示例 |
|---|---|---|
| 表格数据 | 添加高斯噪声,按均值/中位数替换 | 年龄=35 → 35 + 随机噪声 |
| 文本数据 | 随机移除/替换单词 | “这部电影很棒” → “很棒的” |
| 图像数据 | 将超像素区域涂黑/置灰 | 将某个图片区域像素值设为0 |
特征选择
当原始特征数量较多时,LIME会自动选择最重要的K个特征用于解释(默认K=10),以提高可读性。
五、典型使用场景
LIME在以下场景中表现出色:
- 个别异常预测的调试:当模型对某个样本做出意外预测时,快速查明原因
- 模型对比与验证:对比不同模型对同一样本的解释,验证行为一致性
- 模型公平性初步检查:检查敏感特征(如性别、种族)是否在个别决策中起主导作用
- 快速原型验证:在模型开发早期快速获得可解释性反馈
- 图像/文本分类解释:直接可视化模型的关注区域或关键词
六、可视化及示例
LIME提供了针对不同数据类型的可视化工具。以下使用模拟表格数据 + XGBoost模型展示核心用法。
环境准备与安装
pip install lime
导入库与数据准备
import lime.lime_tabular
import numpy as np
import xgboost as xgb
import pandas as pd
import matplotlib.pyplot as plt
# 设置支持中文
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决'-'显示问题
plt.rcParams['axes.unicode_minus'] = False
# 设置随机种子
np.random.seed(39)
# 生成模拟数据
n_samples = 1000
X = np.random.rand(n_samples, 4)
y = 2 * X[:, 0] + 1.5 * X[:, 1] - 0.5 * X[:, 2] + 0.1 * X[:, 3] + np.random.normal(0, 0.1, n_samples)
# 训练模型
model = xgb.XGBRegressor(n_estimators=50, max_depth=3, random_state=42)
model.fit(X, y)
feature_names = ["房间数", "地段评分", "房龄", "周边配套"]
X_df = pd.DataFrame(X, columns=feature_names)
创建LIME解释器
# 对于表格数据,需要提供训练集和特征名称
explainer = lime.lime_tabular.LimeTabularExplainer(
training_data=X, # 训练数据(numpy数组格式)
feature_names=feature_names,
mode='regression', # 'regression' or 'classification'
verbose=True
)
# 选择一个样本进行解释
sample_idx = 0
sample = X[sample_idx]
1. 单个样本解释(文本输出)
功能:输出每个特征对预测的贡献(正/负影响)。
exp = explainer.explain_instance(
data_row=sample,
predict_fn=model.predict,
num_features=len(feature_names)
)
# 或者直接打印文本解释
print("特征贡献列表:")
for feature, weight in exp.as_list():
print(f" {feature}: {weight:.4f}")
输出:
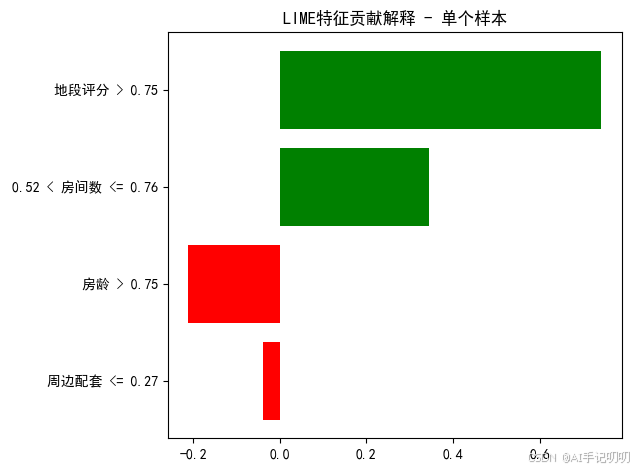
特征贡献列表:
地段评分 > 0.75: 0.7423
0.52 < 房间数 <= 0.76: 0.3446
房龄 > 0.75: -0.2110
周边配套 <= 0.27: -0.0394
注:LIME默认会对连续特征进行自动分箱处理,因此特征名会显示为数值区间形式
2. 特征贡献柱状图
功能:直观展示各特征的贡献大小和方向。
# 保存图片到本地
fig = exp.as_pyplot_figure()
plt.title('LIME特征贡献解释 - 单个样本')
plt.tight_layout()
plt.savefig('lime_sample_explanation.png', dpi=150, bbox_inches='tight')
plt.show()
七、LIME与SHAP的选择
基于实际应用场景的建议:
优先选择LIME的场景
| 场景 | 原因 |
|---|---|
| 快速原型验证 | LIME实现简单,参数少,可快速获得解释 |
| 异常预测调试 | 局部保真度高,特别擅长解释“意外”预测 |
| 图像/文本解释 | 可视化方式直观,超像素/单词级别高亮效果清晰 |
| 对解释效率要求高 | 可通过调节采样数平衡速度与质量 |
| 不需要全局特征重要性 | 仅需偶尔查看几个样本的原因 |
优先选择SHAP的场景
| 场景 | 原因 |
|---|---|
| 全局模型审计 | 原生支持全局特征重要性,数学保证强 |
| 模型合规性报告 | Shapley值理论基础扎实,结果可复现、稳定 |
| 特征交互分析 | SHAP依赖图可揭示复杂的非线性关系和交互 |
| 要求严谨性 | 业界认可度更高 |
| 树模型为主(XGBoost/LightGBM) | TreeSHAP计算快且精确 |
两者结合使用
实践中很多团队采取分阶段策略:
- 开发阶段:使用LIME快速迭代,调试个别样本
- 上线前审计:使用SHAP生成全局报告,验证模型行为一致性
- 生产监控:对异常预测样本,两者交叉验证,确认解释的可靠性
八、总结
LIME是目前最受欢迎的模型无关可解释性工具之一,它与SHAP互为补充:
| 维度 | LIME的优势 | LIME的局限 |
|---|---|---|
| 核心理念 | 局部线性近似,直观易懂 | 不保证全局一致性 |
| 实现复杂度 | 简单,几行代码即可 | 结果稳定性依赖采样参数 |
| 适用数据类型 | 表格、文本、图像均支持良好 | 高维表格数据特征选择可能不稳定 |
| 数学保证 | 计算灵活 | 缺乏SHAP的严密度量保证 |
通过LIME,可以:
- 快速理解单个异常预测的成因:发现模型何时、为何做出意外判断
- 验证模型行为是否符合预期:检查敏感依赖或逻辑漏洞
- 向非技术人员解释模型决策:可视化方式直观易懂,无需数学背景
- 在模型开发早期获取可解释性反馈:加速迭代和调试过程
LIME与SHAP是互补关系。理解其优缺点,根据具体场景选择合适的工具(或两者结合使用),才能充分发挥价值。
九、相关文章

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)