基于Transformer的医疗文本科室分类模型开发全流程
一、项目概述与环境配置
本项目旨在开发一款基于Transformer架构的医疗文本分类模型,实现对患者病情描述文本的自动科室匹配,辅助医疗咨询场景的高效分诊。模型以Huatuo26M-Lite医疗数据集为训练基础,通过深度学习技术挖掘文本特征,最终输出对应就诊科室,同时搭建简易Flask服务实现模型调用。
关键流程节点
- 环境初始化:配置 HuggingFace 镜像,导入深度学习依赖库
- 数据获取:加载 Huatuo 医疗数据集,按 8:2 划分训练、测试集
- 数据预处理:构建词表与科室标签映射,完成文本编码与批量填充
- 模型搭建:基于 Transformer 编码器搭建医疗文本分类网络
- 模型训练:配置损失函数、优化器,多轮迭代训练并评估
- 推理测试:保存模型权重,完成单文本预测与 GPU 耗时分析
- 服务部署:封装推理逻辑,搭建 Flask 接口实现线上调用
核心环境配置重点在于设置HF_ENDPOINT镜像地址,解决Hugging Face数据集下载缓慢的问题,通过导入相关依赖库(PyTorch、Pandas、 datasets等)搭建模型开发所需的技术环境,关键配置代码如下:
import os os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" import torch、torch.nn as nn等相关依赖导入
import os os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" import torch import torch.nn as nn import torch.nn.functional as F import numpy as np import pandas as pd from torch.utils.data import random_split import torch.optim as optim from torch.utils.data import Dataset, DataLoader import jieba from datasets import load_dataset
二、数据集加载与探索
本次实验选用FreedomIntelligence/Huatuo26M-Lite医疗数据集,该数据集包含177703条训练样本,每条样本包含id、患者问题、医生回答、科室标签、相关疾病等特征,涵盖妇产科、内科、皮肤性病科等16个核心科室(含未知类别<UNK>)。数据集加载后,通过自定义Dataset类封装数据,实现对样本的快速读取与索引,同时划分训练集与测试集(比例8:2),设置随机数种子确保实验可复现。数据探索结果显示,样本标签分布合理,可满足模型训练需求。
###华佗 GPT(HuatuoGPT)。华佗 GPT 是一个基于大量中文医疗语料训练的大型语言模型。它的目标是构建一个更专业的适用于医疗咨询场景的“聊天机器人”。
dataset = load_dataset("FreedomIntelligence/Huatuo26M-Lite")
dataset,dataset["train"]
(DatasetDict({
train: Dataset({
features: ['id', 'answer', 'score', 'label', 'question', 'related_diseases'],
num_rows: 177703
})
}),
Dataset({
features: ['id', 'answer', 'score', 'label', 'question', 'related_diseases'],
num_rows: 177703
}))
dataset["train"][0],dataset["train"][1]
({'id': 22647835,
'answer': '治疗鼻中隔偏曲的方法有手术和非手术治疗两种,手术治疗是通过手术矫正鼻中隔偏曲,非手术治疗则是通过药物治疗和物理治疗来缓解症状。手术治疗是治疗鼻中隔偏曲的最有效方法,手术后需要注意休息,避免剧烈运动和低头工作,同时也要注意饮食,少吃辛辣食物和不喝酒。手术后两周内鼻涕或痰中出现血水或血块是正常现象,若出现大量出血、发烧、剧烈疼痛时请尽速就医。',
'score': 5,
'label': '眼耳鼻喉科',
'question': '上个月感冒了,也没有用药,感冒好了以后就觉得鼻子经常不通畅,鼻子还经常晦气红皮、发痒、而且还会有头晕,一直都以为是上次感冒留下的后遗症,去医院检查,检查结果出来以后说是鼻中隔偏曲。请问如何治疗鼻中隔偏曲?',
'related_diseases': '鼻中隔偏曲'},
{'id': 14068359,
'answer': '祛斑手术后一般会有不同程度的复发,最好平时还是辅助以美白化妆品和饮食方面调节。还可以找中医开一些调节内分泌的药物,从根源上治疗,效果比较好。',
'score': 4,
'label': '皮肤性病科',
'question': '以前脸上是没有斑点的,但是自从生了孩子以后,发现脸上多了很多的斑点,也用过很多的美白产品但是感觉没有什么效果,所以取义了美容医院用了激光手段治疗了,效果还是不错的,但是害怕会很容易复发呢。想得到怎样的帮助:最近做了祛斑手术,不知道会不会复发?',
'related_diseases': ''})
class Dataset(torch.utils.data.Dataset):
def __init__(self):
self.dataset = load_dataset("FreedomIntelligence/Huatuo26M-Lite", split="train")
##self.dataset = self.dataset .select(range(10000)) # 加载前 10000 个样本
##filtered_dataset = dataset.filter(lambda example: example['your_field'] == 'your_value')
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
text = self.dataset[idx]['question']
label = self.dataset[idx]['label']
return text, label
dataset = Dataset()
dataset,len(dataset),dataset[0]
(<__main__.Dataset at 0x7f228837bc70>,
177703,
('上个月感冒了,也没有用药,感冒好了以后就觉得鼻子经常不通畅,鼻子还经常晦气红皮、发痒、而且还会有头晕,一直都以为是上次感冒留下的后遗症,去医院检查,检查结果出来以后说是鼻中隔偏曲。请问如何治疗鼻中隔偏曲?',
'眼耳鼻喉科'))
train_size = int(len(dataset) * 0.8) test_size = len(dataset) - train_size # 随机划分数据集 ##设置随机数种子的主要目的是为了确保在不同的运行中能够获得可重复的结果。当我们在进行机器学习或深度学习的实验时,很多操作都涉及到随机数, ##例如初始化模型的参数、数据的随机打乱等。 ##如果不设置固定的种子,每次运行的结果可能会有所不同,这会给实验的比较和调试带来困难。 generator = torch.Generator().manual_seed(2024) ##torch.utils.data.random_split 函数可以按照指定的比例将一个数据集随机分割成多个子数据集。 train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size], generator=generator)
len(train_dataset), len(test_dataset),train_dataset[5]
(142162,
35541,
('我有一个好朋友,我们关系非常好,最近她一直很郁闷,原来是在一次体检中被检查出患了乳腺癌,医生建议切除乳房。很想知道为什么会得乳腺癌呢?',
'肿瘤科'))
三、数据预处理
数据预处理阶段主要完成词汇表(vocab)与标签表(lable_vocab)的构建,以及文本序列的编码与填充:
1. 统计训练集中所有文本的字符频率,构建词汇表,将出现频率从高到低排序并分配唯一索引,未知字符用<UNK>表示,最终词汇表规模为4619个字符;
2. 统计各科室标签的出现次数,构建标签表,共包含17个类别(16个具体科室+1个未知类别),同时创建标签索引的反转字典,用于后续模型输出结果的解析;
3. 定义collate_batch函数,将文本转换为对应的索引序列,通过pad_sequence实现序列长度统一,确保批量输入模型时格式一致。
# 数据准备
lable_count = {}
lable_vocab = {'<UNK>': 0}
vocab = {'<UNK>': 0}
word_count = {}
for sent in train_dataset:
lable_ = sent[1]
if lable_ in lable_count:
lable_count[lable_] += 1
else:
lable_count[lable_] = 1
for word in sent[0]:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
vocab.update({word: i + 1 for i, (word, _) in enumerate(sorted(word_count.items(), key=lambda x: x[1], reverse=True))})
lable_vocab.update({word: i+1 for i, (word, _) in enumerate(sorted(lable_count.items(), key=lambda x: x[1], reverse=True))})
# 使用字典推导式创建反转后的字典
reversed_vocab = {value: key for key, value in lable_vocab.items()}
len(lable_vocab),len(vocab)
(17, 4619)
lable_vocab,reversed_vocab
({'<UNK>': 0,
'妇产科': 1,
'内科': 2,
'皮肤性病科': 3,
'儿科': 4,
'眼耳鼻喉科': 5,
'肿瘤科': 6,
'神经科学': 7,
'外科': 8,
'男性健康科': 9,
'感染与免疫科': 10,
'口腔科': 11,
'心理科学': 12,
'中医科': 13,
'生殖健康科': 14,
'其他': 15,
'急诊科': 16},
{0: '<UNK>',
1: '妇产科',
2: '内科',
3: '皮肤性病科',
4: '儿科',
5: '眼耳鼻喉科',
6: '肿瘤科',
7: '神经科学',
8: '外科',
9: '男性健康科',
10: '感染与免疫科',
11: '口腔科',
12: '心理科学',
13: '中医科',
14: '生殖健康科',
15: '其他',
16: '急诊科'})
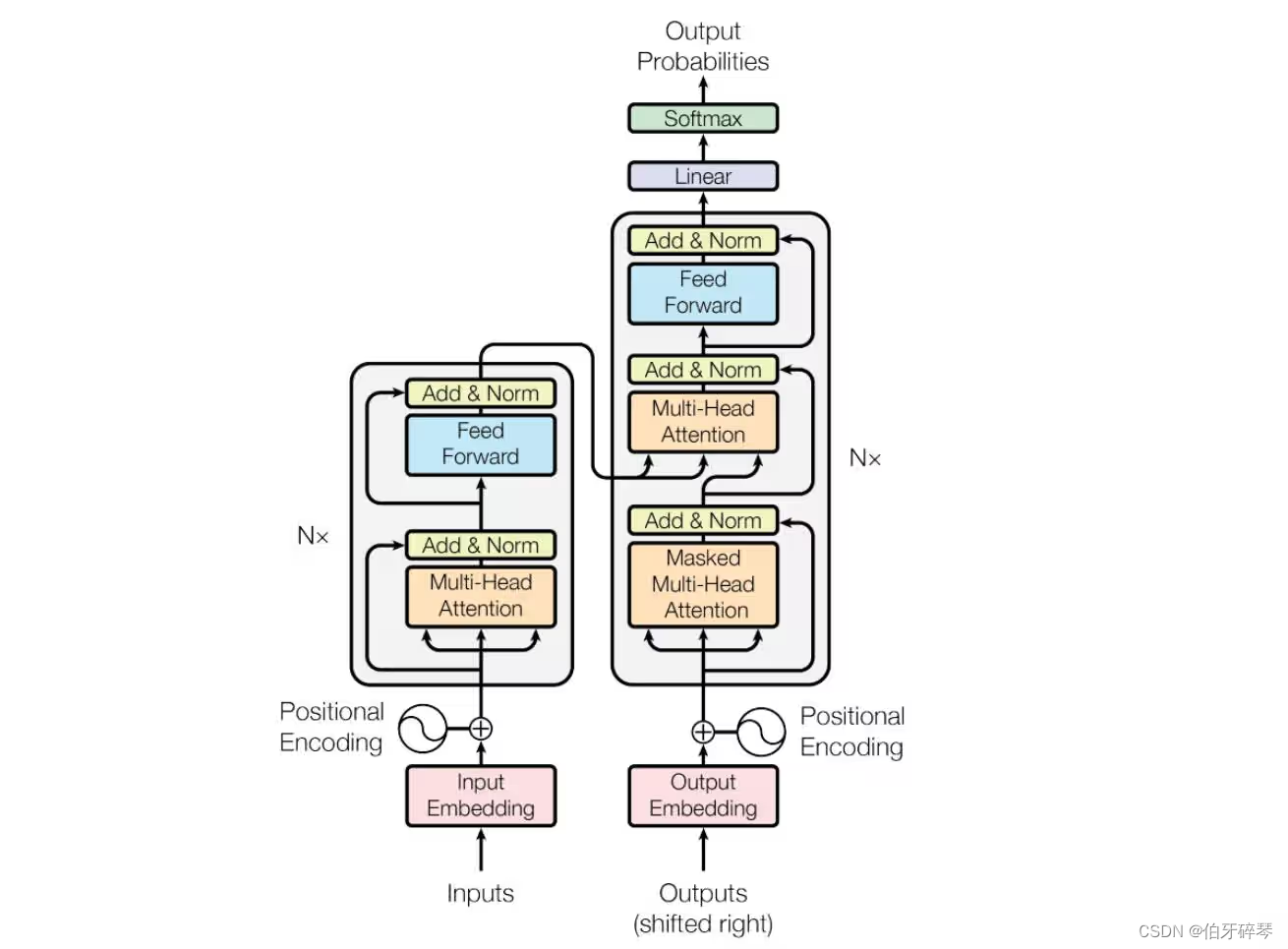
四、Transformer模型构建
模型基于Transformer编码器架构设计,核心组件包括嵌入层(Embedding)、位置编码(PositionalEncoding)、多头自注意力层(MultiHeadSelfAttention)、前馈网络层(FeedForwardNetwork)及输出层(Linear),具体结构如下:
1. 嵌入层:将文本索引序列转换为固定维度(d_model=200)的向量表示;
2. 位置编码:为嵌入向量添加位置信息,解决Transformer模型无法捕捉序列顺序的问题;
3. Transformer编码器:包含2个编码器层,每个编码器层由多头自注意力层、层归一化、前馈网络层组成,实现文本特征的深度提取;
4. 输出层:通过线性层将编码器输出的特征向量映射到17个科室类别,完成分类任务。
模型总参数约为281万,所有参数均部署在GPU(cuda)上,提升训练与推理速度。
import numpy as np import torch from torch import nn, Tensor import torch.nn.functional as F from torch.utils import data import math from torch.nn import TransformerEncoder, TransformerEncoderLayer
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
device(type='cuda')
def collate_batch(batch):
label_list, text_list = [], []
for (_text, _label) in batch:
word_list = []
for word in _text:
word_list.append(vocab.get(word, 0))
word_list = torch.tensor(word_list, dtype=torch.int64)
text_list.append(word_list)
label_list.append(lable_vocab.get(_label, 0))
label_list = torch.tensor(label_list)
##填充方式:通常会在序列的末尾进行填充,填充的值可以自定义,默认情况下填充值为 0。
text_list = torch.nn.utils.rnn.pad_sequence(text_list)
return label_list.to(device), text_list.to(device)
train_dataloader = data.DataLoader(train_dataset, batch_size=16,
shuffle=True, collate_fn=collate_batch)
test_dataloader = data.DataLoader(test_dataset, batch_size=16, collate_fn=collate_batch)
for i, (l, b) in enumerate(train_dataloader):
print(l.size(), b.size())
if i>9:
break
torch.Size([16]) torch.Size([111, 16]) torch.Size([16]) torch.Size([99, 16]) torch.Size([16]) torch.Size([98, 16]) torch.Size([16]) torch.Size([132, 16]) torch.Size([16]) torch.Size([246, 16]) torch.Size([16]) torch.Size([120, 16]) torch.Size([16]) torch.Size([103, 16]) torch.Size([16]) torch.Size([116, 16]) torch.Size([16]) torch.Size([117, 16]) torch.Size([16]) torch.Size([124, 16]) torch.Size([16]) torch.Size([112, 16])
class MultiHeadSelfAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadSelfAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
self.d_k = d_model // self.num_heads
self.query_linear = nn.Linear(d_model, d_model)
self.key_linear = nn.Linear(d_model, d_model)
self.value_linear = nn.Linear(d_model, d_model)
self.softmax = nn.Softmax(dim=-1)
def split_heads(self, x, batch_size):
x = x.reshape(batch_size, -1, self.num_heads, self.d_k)
return x.permute(0, 2, 1, 3)
def forward(self, x, mask=None):
batch_size = x.shape[0]
query = self.query_linear(x)
key = self.key_linear(x)
value = self.value_linear(x)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
scaled_attention = torch.matmul(query, key.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
if mask is not None:
scaled_attention += (mask * -1e9)
attention_weights = self.softmax(scaled_attention)
output = torch.matmul(attention_weights, value)
output = output.permute(0, 2, 1, 3).contiguous()
output = output.reshape(batch_size, -1, self.d_model)
return output
class FeedForwardNetwork(nn.Module):
def __init__(self, d_model, d_ff):
super(FeedForwardNetwork, self).__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.linear_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, x):
##F.relu是torch.nn.functional模块中的一个函数,全称为rectified linear unit(修正线性单元)。
##它的主要作用是将输入值限制在一个非负的范围内,即当输入值小于 0 时,输出值为 0;当输入值大于等于 0 时,输出值等于输入值本身。其数学表达式为:ReLU(x) = max(0, x)。
x = F.relu(self.linear_1(x))
x = self.dropout(x)
x = self.linear_2(x)
x = self.dropout(x)
return x
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super(TransformerEncoderLayer, self).__init__()
self.self_attention = MultiHeadSelfAttention(d_model, num_heads)
self.layer_norm_1 = nn.LayerNorm(d_model)
self.feed_forward = FeedForwardNetwork(d_model, d_ff)
self.layer_norm_2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, x, mask=None):
x_attention = self.self_attention(x, mask)
##输入x 增加 多头注意力输出x_attention
x = x + self.dropout(x_attention)
###nn.LayerNorm 是一种在神经网络中广泛使用的归一化层,它主要用于对神经网络的输入或隐藏层输出进行归一化操作
x = self.layer_norm_1(x)
##前馈网络层
x_ffn = self.feed_forward(x)
##输入x + 前馈网络层输出
x = x + self.dropout(x_ffn)
##nn.LayerNorm 是一种在神经网络中广泛使用的归一化层,它主要用于对神经网络的输入或隐藏层输出进行归一化操作
x = self.layer_norm_2(x)
return x
class TransformerEncoder(nn.Module):
def __init__(self, d_model, num_heads, d_ff, num_layers):
super(TransformerEncoder, self).__init__()
self.layers = nn.ModuleList()
# 使用循环来添加多个具有相同结构的层
for _ in range(num_layers):
layer = TransformerEncoderLayer(d_model, num_heads, d_ff)
self.layers.append(layer)
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
class TransformerModel(nn.Module):
def __init__(self, ntoken: int, d_model: int, nhead: int, d_hid: int,
nlayers: int, out_class:int, dropout: float = 0.5):
super().__init__()
self.model_type = 'Transformer'
self.pos_encoder = PositionalEncoding(d_model, dropout)
self.transformer_encoder = TransformerEncoder(d_model, nhead, d_hid, nlayers)
#self.transformer_encoder = TransformerEncoderLayer(d_model, nhead, d_hid)
self.embedding = nn.Embedding(ntoken, d_model)
self.d_model = d_model
self.linear = nn.Linear(d_model, out_class) # 2 class: pos, reg
self.init_weights()
def init_weights(self) -> None:
initrange = 0.1
self.embedding.weight.data.uniform_(-initrange, initrange)
self.linear.bias.data.zero_()
self.linear.weight.data.uniform_(-initrange, initrange)
def forward(self, src: Tensor, src_mask: Tensor = None) -> Tensor:
"""
Arguments:
src: Tensor, shape ``[seq_len, batch_size]``
src_mask: Tensor, shape ``[seq_len, seq_len]``
Returns:
output Tensor of shape ``[seq_len, batch_size, ntoken]``
"""
# Embeding层输出shape:((sequece_length,batchsize, d_model))
src = self.embedding(src) * math.sqrt(self.d_model)
src = self.pos_encoder(src)
src = src.permute(1, 0, 2)
output = self.transformer_encoder(src)
output = output.permute(1, 0, 2)
# print("output:", output.size()) # 输出shape:((batchsize, sequece_length, d_hid))
output = output[0, :, :]
output = self.linear(output)
return output
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout: float=0.1, max_len=1000):
super().__init__()
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(max_len).unsqueeze(1) # (length, 1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, 1, d_model) # (length, 1, d_model)
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x: Tensor, max_len=1000) -> Tensor:
"""
Arguments:
x: Tensor, shape ``[seq_len, batch_size, embedding_dim]``
"""
x = x[:max_len, :, :] + self.pe[:x.size(0), :]
return self.dropout(x)
ntokens = len(vocab) # size of vocabulary #d_model = 200 # embedding dimension #d_hid = 2048 # dimension of the feedforward network model in ``nn.TransformerEncoder`` d_model = 200 d_hid = 2048 out_class = len(lable_vocab) nlayers = 2 # number of ``nn.TransformerEncoderLayer`` in ``nn.TransformerEncoder`` nhead = 2 # number of heads in ``nn.MultiheadAttention`` dropout = 0.2 # dropout probability model = TransformerModel(ntokens, d_model, nhead, d_hid, nlayers, out_class, dropout).to(device)
五、模型训练与评估
1. 训练配置:选用交叉熵损失函数(CrossEntropyLoss),优化器采用Adam(学习率0.0001),设置学习率调度器(StepLR),训练轮次(epochs)为10,批量大小(batch_size)为16;
2. 训练过程:定义train函数与test函数,分别实现模型的训练与验证,记录每轮的训练损失、训练准确率、测试损失、测试准确率及训练耗时;
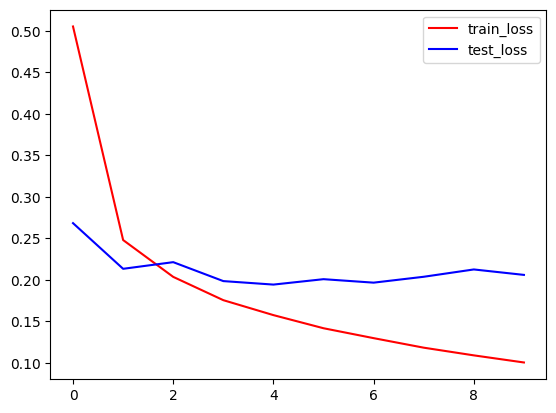
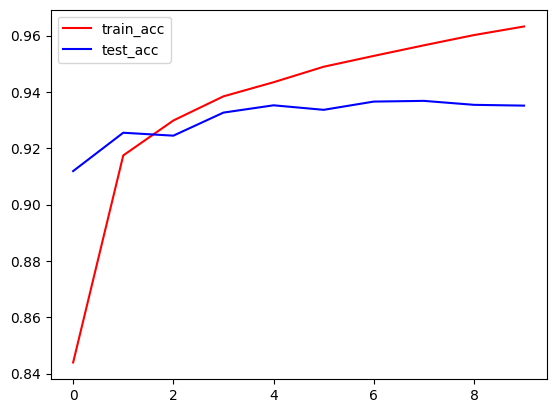
3. 训练结果:经过10轮训练,模型训练准确率达到96.3%,测试准确率稳定在93.5%左右,训练损失降至0.1006,测试损失维持在0.2左右,模型拟合效果良好,未出现明显过拟合现象;
4. 结果可视化:通过matplotlib绘制训练/测试损失曲线与准确率曲线,直观呈现模型训练过程中的性能变化。
loss_fn = nn.CrossEntropyLoss() from torch.optim import lr_scheduler optimizer = torch.optim.Adam(model.parameters(), lr=0.0001) exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=60, gamma=0.1)
def train(dataloader):
total_acc, total_count, total_loss, = 0, 0, 0
model.train()
for label, text in dataloader:
predicted_label = model(text)
#print(predicted_label.shape, label.shape)
loss = loss_fn(predicted_label, label)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
total_loss += loss.item()*label.size(0)
return total_loss/total_count, total_acc/total_count
def test(dataloader):
model.eval()
total_accuracy, total_count, total_loss, = 0, 0, 0
with torch.no_grad():
for label, text in dataloader:
predicted_label = model(text)
#print(predicted_label, label)
#print(predicted_label.shape, label.shape)
loss = loss_fn(predicted_label, label)
#predicted_label.argmax(1) 这部分通常是获取预测标签在某个维度上(这里是维度 1)的最大值的索引。
#predicted_label.argmax(1) == label 会比较预测标签的最大值索引和真实的标签,得到一个布尔值的张量,表示每个位置上预测值和真实值是否相等。
#(predicted_label.argmax(1) == label).sum() 对这些布尔值进行求和,计算预测正确的数量。
#.item() 则是将求和的结果从张量中提取出来,得到一个 Python 的数值类型(例如整数
total_accuracy += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
total_loss += loss.item()*label.size(0)
return total_loss/total_count, total_accuracy/total_count
epochs=10
train_loss = []
train_acc = []
test_loss = []
test_acc = []
import time
for epoch in range(epochs):
print(epoch)
# 记录开始时间
start_time = time.time()
epoch_loss, epoch_acc = train(train_dataloader)
epoch_test_loss, epoch_test_acc = test(test_dataloader)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
exp_lr_scheduler.step()
# 记录结束时间
end_time = time.time()
# 计算并打印执行耗时
execution_time = end_time - start_time
template = ("epoch:{:2d}, train_loss: {:.5f}, train_acc: {:.1f}% ,"
"test_loss: {:.5f}, test_acc: {:.1f}%,, 耗时: {:.2f}")
print(template.format(
epoch+1, epoch_loss, epoch_acc*100, epoch_test_loss, epoch_test_acc*100, execution_time))
print("Done!")
0 epoch: 1, train_loss: 0.50536, train_acc: 84.4% ,test_loss: 0.26846, test_acc: 91.2%,, 耗时: 63.64 1 epoch: 2, train_loss: 0.24810, train_acc: 91.7% ,test_loss: 0.21344, test_acc: 92.5%,, 耗时: 63.58 2 epoch: 3, train_loss: 0.20372, train_acc: 93.0% ,test_loss: 0.22145, test_acc: 92.4%,, 耗时: 63.85 3 epoch: 4, train_loss: 0.17565, train_acc: 93.8% ,test_loss: 0.19863, test_acc: 93.3%,, 耗时: 64.09 4 epoch: 5, train_loss: 0.15765, train_acc: 94.3% ,test_loss: 0.19444, test_acc: 93.5%,, 耗时: 63.93 5 epoch: 6, train_loss: 0.14184, train_acc: 94.9% ,test_loss: 0.20095, test_acc: 93.4%,, 耗时: 63.80 6 epoch: 7, train_loss: 0.12991, train_acc: 95.3% ,test_loss: 0.19676, test_acc: 93.7%,, 耗时: 63.84 7 epoch: 8, train_loss: 0.11843, train_acc: 95.7% ,test_loss: 0.20385, test_acc: 93.7%,, 耗时: 63.69 8 epoch: 9, train_loss: 0.10917, train_acc: 96.0% ,test_loss: 0.21266, test_acc: 93.5%,, 耗时: 63.73 9 epoch:10, train_loss: 0.10060, train_acc: 96.3% ,test_loss: 0.20610, test_acc: 93.5%,, 耗时: 63.44 Done!
import matplotlib.pyplot as plt %matplotlib inline
plt.plot(range(epochs), train_loss, c='r', label='train_loss') plt.plot(range(epochs), test_loss, c='b', label='test_loss') plt.legend()
<matplotlib.legend.Legend at 0x7f20b431e5e0>
plt.plot(range(epochs), train_acc, c='r', label='train_acc') plt.plot(range(epochs), test_acc, c='b', label='test_acc') plt.legend()
<matplotlib.legend.Legend at 0x7f2118157dc0>
# 更稳妥的做法是只保存状态字典 torch.save(model.state_dict(), 'model_state_dict_huatuo_fenlei_zh_char_http_5000.pth')
#它通过遍历模型的所有参数 p ,使用 numel() 方法获取每个参数的元素数量(即参数的大小),然后将这些大小相加,得到模型的总参数数量,并将结果存储在 total_params 变量中。
#例如,如果模型中有一个权重矩阵大小为 (10, 20) ,那么它的参数数量就是 10 * 20 = 200 。通过上述代码,可以把模型中所有这样的参数数量累加起来,得到总的参数数量。
total_params = sum(p.numel() for p in model.parameters())
print("Total parameters:", total_params)
Total parameters: 2812913
# 打印模型的参数信息
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Requires Grad: {param.requires_grad}| device: {param.device}")
Layer: transformer_encoder.layers.0.self_attention.query_linear.weight | Size: torch.Size([200, 200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.self_attention.query_linear.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.self_attention.key_linear.weight | Size: torch.Size([200, 200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.self_attention.key_linear.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.self_attention.value_linear.weight | Size: torch.Size([200, 200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.self_attention.value_linear.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.layer_norm_1.weight | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.layer_norm_1.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.feed_forward.linear_1.weight | Size: torch.Size([2048, 200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.feed_forward.linear_1.bias | Size: torch.Size([2048]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.feed_forward.linear_2.weight | Size: torch.Size([200, 2048]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.feed_forward.linear_2.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.layer_norm_2.weight | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.0.layer_norm_2.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.self_attention.query_linear.weight | Size: torch.Size([200, 200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.self_attention.query_linear.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.self_attention.key_linear.weight | Size: torch.Size([200, 200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.self_attention.key_linear.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.self_attention.value_linear.weight | Size: torch.Size([200, 200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.self_attention.value_linear.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.layer_norm_1.weight | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.layer_norm_1.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.feed_forward.linear_1.weight | Size: torch.Size([2048, 200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.feed_forward.linear_1.bias | Size: torch.Size([2048]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.feed_forward.linear_2.weight | Size: torch.Size([200, 2048]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.feed_forward.linear_2.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.layer_norm_2.weight | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: transformer_encoder.layers.1.layer_norm_2.bias | Size: torch.Size([200]) | Requires Grad: True| device: cuda:0 Layer: embedding.weight | Size: torch.Size([4619, 200]) | Requires Grad: True| device: cuda:0 Layer: linear.weight | Size: torch.Size([17, 200]) | Requires Grad: True| device: cuda:0 Layer: linear.bias | Size: torch.Size([17]) | Requires Grad: True| device: cuda:0
Self-Attention Sublayer: Layer: transformer_encoder.layers.0.self_attn.in_proj_weight | Size: torch.Size([600, 200]) 这是自注意力(Self-Attention)模块的输入投影权重矩阵,用于将输入嵌入(尺寸200)转换为query、key、value的组合形式,尺寸600可能意味着每个query/key/value有200维,且它们被线性映射后合并存放。 Layer: transformer_encoder.layers.0.self_attn.in_proj_bias | Size: torch.Size([600]) 自注意力输入投影的偏置项。 Layer: transformer_encoder.layers.0.self_attn.out_proj.weight | Size: torch.Size([200, 200]) 自注意力的输出投影权重,用于将 attention scores 映射回原始维度(200),对应到值(Value)的维度。 Layer: transformer_encoder.layers.0.self_attn.out_proj.bias | Size: torch.Size([200]) 自注意力输出投影的偏置项。 Feedforward Sublayer: Layer: transformer_encoder.layers.0.linear1.weight | Size: torch.Size([2048, 200]) 第一个全连接层(通常称为“feedforward”或“FFN”的输入层)权重,尺寸表明输入维度为200,输出维度扩大到2048,这是Transformer中常见的扩展维度操作,以增强模型的表达能力。 Layer: transformer_encoder.layers.0.linear1.bias | Size: torch.Size([2048]) 第一个全连接层的偏置项。 Layer: transformer_encoder.layers.0.linear2.weight | Size: torch.Size([200, 2048]) 第二个全连接层(FFN的输出层),将中间维度(2048)映射回模型的嵌入维度(200)。 Layer: transformer_encoder.layers.0.linear2.bias | Size: torch.Size([200]) 第二个全连接层的偏置项。 Normalization Layers: Layer: transformer_encoder.layers.0.norm1.weight | Size: torch.Size([200]) 第一个归一化层(通常是LayerNorm)的缩放因子,应用于自注意力子层之后。 Layer: transformer_encoder.layers.0.norm1.bias | Size: torch.Size([200]) 第一个归一化层的偏移量。 Layer: transformer_encoder.layers.0.norm2.weight | Size: torch.Size([200]) 第二个归一化层(应用于FFN之后)的缩放因子。 Layer: transformer_encoder.layers.0.norm2.bias | Size: torch.Size([200]) 第二个归一化层的偏移量。
model
TransformerModel(
(pos_encoder): PositionalEncoding(
(dropout): Dropout(p=0.2, inplace=False)
)
(transformer_encoder): TransformerEncoder(
(layers): ModuleList(
(0-1): 2 x TransformerEncoderLayer(
(self_attention): MultiHeadSelfAttention(
(query_linear): Linear(in_features=200, out_features=200, bias=True)
(key_linear): Linear(in_features=200, out_features=200, bias=True)
(value_linear): Linear(in_features=200, out_features=200, bias=True)
(softmax): Softmax(dim=-1)
)
(layer_norm_1): LayerNorm((200,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForwardNetwork(
(linear_1): Linear(in_features=200, out_features=2048, bias=True)
(linear_2): Linear(in_features=2048, out_features=200, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(layer_norm_2): LayerNorm((200,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(embedding): Embedding(4619, 200)
(linear): Linear(in_features=200, out_features=17, bias=True)
)
六、模型推理与性能测试
1. 推理函数:定义callmodel函数,接收患者病情描述文本,经过文本编码、模型预测、标签反转,输出对应的科室类别,例如输入“经常吸烟喝酒对乙肝危害大吗”,模型可准确预测为“感染与免疫科”;
2. 性能测试:使用torch.autograd.profiler进行GPU推理性能分析,结果显示单次推理的CPU总耗时为7.388ms,CUDA总耗时为7.691ms,推理速度较快,可满足实时分诊需求;
3. 模型保存:采用保存模型状态字典(state_dict)的方式,便于后续模型的加载与复用,保存文件名为model_state_dict_huatuo_fenlei_zh_char_http_5000.pth。
def collate_text(_text):
text_list = []
word_list = []
for word in _text:
word_list.append(vocab.get(word, 0))
word_list = torch.tensor(word_list, dtype=torch.int64)
text_list.append(word_list)
##填充方式:通常会在序列的末尾进行填充,填充的值可以自定义,默认情况下填充值为 0。
text_list = torch.nn.utils.rnn.pad_sequence(text_list)
return text_list.to(device)
from torch.utils import data
def callmodel(_text):
model.eval()
with torch.no_grad():
text_list = collate_text(_text)
predicted_label = model(text_list)
predicted_label = predicted_label.argmax(1)
return reversed_vocab.get(predicted_label[0].item())
predicted_label = callmodel("还是烟酒,但工作就是每天要应酬,这也少不了的东西,不知道经常喝酒抽烟对这个危害大吗。经常吸烟喝酒对乙肝危害大吗")
predicted_label
'感染与免疫科'
from torch.utils import data
_text = "有个男人喜欢抽烟,有点咳嗽"
model.eval()
print("fast path:")
print("==========")
with torch.autograd.profiler.profile(use_cuda=True) as prof:
with torch.no_grad():
text_list = collate_text(_text)
predicted_label = model(text_list)
predicted_label = predicted_label.argmax(1)
predicted_label = reversed_vocab.get(predicted_label[0].item())
print(prof)
predicted_label
fast path:
==========
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
aten::empty 0.18% 13.000us 0.18% 13.000us 13.000us 20.000us 0.26% 20.000us 20.000us 1
aten::to 0.00% 0.000us 0.00% 0.000us 0.000us 3.000us 0.04% 3.000us 3.000us 1
aten::lift_fresh 0.00% 0.000us 0.00% 0.000us 0.000us 4.000us 0.05% 4.000us 4.000us 1
aten::detach_ 0.15% 11.000us 0.19% 14.000us 14.000us 12.000us 0.16% 18.000us 18.000us 1
detach_ 0.04% 3.000us 0.04% 3.000us 3.000us 6.000us 0.08% 6.000us 6.000us 1
aten::pad_sequence 0.70% 52.000us 2.27% 168.000us 168.000us 42.000us 0.55% 171.000us 171.000us 1
aten::full 0.35% 26.000us 0.61% 45.000us 45.000us 24.000us 0.31% 49.000us 49.000us 1
aten::empty 0.04% 3.000us 0.04% 3.000us 3.000us 6.000us 0.08% 6.000us 6.000us 1
aten::fill_ 0.22% 16.000us 0.22% 16.000us 16.000us 19.000us 0.25% 19.000us 19.000us 1
aten::narrow 0.26% 19.000us 0.58% 43.000us 43.000us 19.000us 0.25% 46.000us 46.000us 1
aten::slice 0.28% 21.000us 0.32% 24.000us 24.000us 21.000us 0.27% 27.000us 27.000us 1
aten::as_strided 0.04% 3.000us 0.04% 3.000us 3.000us 6.000us 0.08% 6.000us 6.000us 1
aten::select 0.24% 18.000us 0.24% 18.000us 18.000us 17.000us 0.22% 21.000us 21.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 4.000us 0.05% 4.000us 4.000us 1
aten::copy_ 0.14% 10.000us 0.14% 10.000us 10.000us 13.000us 0.17% 13.000us 13.000us 1
aten::to 0.15% 11.000us 1.04% 77.000us 77.000us 12.000us 0.16% 80.000us 80.000us 1
aten::_to_copy 0.34% 25.000us 0.89% 66.000us 66.000us 21.000us 0.27% 68.000us 68.000us 1
aten::empty_strided 0.19% 14.000us 0.19% 14.000us 14.000us 17.000us 0.22% 17.000us 17.000us 1
aten::copy_ 0.11% 8.000us 0.37% 27.000us 27.000us 30.000us 0.39% 30.000us 30.000us 1
cudaMemcpyAsync 0.16% 12.000us 0.16% 12.000us 12.000us 0.000us 0.00% 0.000us 0.000us 1
cudaStreamSynchronize 0.09% 7.000us 0.09% 7.000us 7.000us 0.000us 0.00% 0.000us 0.000us 1
aten::embedding 0.53% 39.000us 21.41% 1.582ms 1.582ms 28.000us 0.36% 1.585ms 1.585ms 1
aten::reshape 0.20% 15.000us 0.22% 16.000us 16.000us 15.000us 0.20% 19.000us 19.000us 1
aten::_reshape_alias 0.01% 1.000us 0.01% 1.000us 1.000us 4.000us 0.05% 4.000us 4.000us 1
aten::index_select 0.54% 40.000us 20.64% 1.525ms 1.525ms 1.516ms 19.71% 1.532ms 1.532ms 1
aten::empty 0.04% 3.000us 0.04% 3.000us 3.000us 7.000us 0.09% 7.000us 7.000us 1
aten::resize_ 0.08% 6.000us 0.08% 6.000us 6.000us 9.000us 0.12% 9.000us 9.000us 1
cudaLaunchKernel 19.98% 1.476ms 19.98% 1.476ms 1.476ms 0.000us 0.00% 0.000us 0.000us 1
aten::view 0.03% 2.000us 0.03% 2.000us 2.000us 6.000us 0.08% 6.000us 6.000us 1
aten::mul 0.31% 23.000us 0.42% 31.000us 31.000us 35.000us 0.46% 35.000us 35.000us 1
cudaLaunchKernel 0.11% 8.000us 0.11% 8.000us 8.000us 0.000us 0.00% 0.000us 0.000us 1
aten::slice 0.15% 11.000us 0.16% 12.000us 12.000us 10.000us 0.13% 14.000us 14.000us 1
aten::as_strided 0.01% 1.000us 0.01% 1.000us 1.000us 4.000us 0.05% 4.000us 4.000us 1
aten::slice 0.11% 8.000us 0.11% 8.000us 8.000us 8.000us 0.10% 11.000us 11.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 3.000us 0.04% 3.000us 3.000us 1
aten::slice 0.12% 9.000us 0.12% 9.000us 9.000us 7.000us 0.09% 11.000us 11.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 4.000us 0.05% 4.000us 4.000us 1
aten::slice 0.09% 7.000us 0.09% 7.000us 7.000us 8.000us 0.10% 11.000us 11.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 3.000us 0.04% 3.000us 3.000us 1
aten::slice 0.12% 9.000us 0.12% 9.000us 9.000us 9.000us 0.12% 12.000us 12.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 3.000us 0.04% 3.000us 3.000us 1
aten::add 0.18% 13.000us 0.26% 19.000us 19.000us 23.000us 0.30% 23.000us 23.000us 1
cudaLaunchKernel 0.08% 6.000us 0.08% 6.000us 6.000us 0.000us 0.00% 0.000us 0.000us 1
aten::dropout 0.01% 1.000us 0.01% 1.000us 1.000us 4.000us 0.05% 4.000us 4.000us 1
aten::permute 0.15% 11.000us 0.15% 11.000us 11.000us 11.000us 0.14% 15.000us 15.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 4.000us 0.05% 4.000us 4.000us 1
aten::linear 0.66% 49.000us 2.84% 210.000us 210.000us 31.000us 0.40% 214.000us 214.000us 1
aten::t 0.16% 12.000us 0.30% 22.000us 22.000us 12.000us 0.16% 25.000us 25.000us 1
aten::transpose 0.12% 9.000us 0.14% 10.000us 10.000us 9.000us 0.12% 13.000us 13.000us 1
aten::as_strided 0.01% 1.000us 0.01% 1.000us 1.000us 4.000us 0.05% 4.000us 4.000us 1
aten::view 0.04% 3.000us 0.04% 3.000us 3.000us 6.000us 0.08% 6.000us 6.000us 1
aten::addmm 1.56% 115.000us 1.83% 135.000us 135.000us 140.000us 1.82% 147.000us 147.000us 1
aten::empty 0.05% 4.000us 0.05% 4.000us 4.000us 7.000us 0.09% 7.000us 7.000us 1
cudaFuncGetAttributes 0.08% 6.000us 0.08% 6.000us 6.000us 0.000us 0.00% 0.000us 0.000us 1
cudaFuncGetAttributes 0.01% 1.000us 0.01% 1.000us 1.000us 0.000us 0.00% 0.000us 0.000us 1
cudaFuncGetAttributes 0.01% 1.000us 0.01% 1.000us 1.000us 0.000us 0.00% 0.000us 0.000us 1
INVALID 0.11% 8.000us 0.11% 8.000us 8.000us 0.000us 0.00% 0.000us 0.000us 1
aten::view 0.01% 1.000us 0.01% 1.000us 1.000us 5.000us 0.07% 5.000us 5.000us 1
aten::linear 0.42% 31.000us 1.23% 91.000us 91.000us 19.000us 0.25% 95.000us 95.000us 1
aten::t 0.11% 8.000us 0.24% 18.000us 18.000us 9.000us 0.12% 22.000us 22.000us 1
aten::transpose 0.14% 10.000us 0.14% 10.000us 10.000us 10.000us 0.13% 13.000us 13.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 3.000us 0.04% 3.000us 3.000us 1
aten::view 0.01% 1.000us 0.01% 1.000us 1.000us 4.000us 0.05% 4.000us 4.000us 1
aten::addmm 0.45% 33.000us 0.55% 41.000us 41.000us 43.000us 0.56% 48.000us 48.000us 1
aten::empty 0.03% 2.000us 0.03% 2.000us 2.000us 5.000us 0.07% 5.000us 5.000us 1
cudaFuncGetAttributes 0.01% 1.000us 0.01% 1.000us 1.000us 0.000us 0.00% 0.000us 0.000us 1
cudaFuncGetAttributes 0.01% 1.000us 0.01% 1.000us 1.000us 0.000us 0.00% 0.000us 0.000us 1
cudaFuncGetAttributes 0.01% 1.000us 0.01% 1.000us 1.000us 0.000us 0.00% 0.000us 0.000us 1
INVALID 0.04% 3.000us 0.04% 3.000us 3.000us 0.000us 0.00% 0.000us 0.000us 1
aten::view 0.00% 0.000us 0.00% 0.000us 0.000us 2.000us 0.03% 2.000us 2.000us 1
aten::linear 0.41% 30.000us 1.14% 84.000us 84.000us 20.000us 0.26% 89.000us 89.000us 1
aten::t 0.09% 7.000us 0.19% 14.000us 14.000us 8.000us 0.10% 18.000us 18.000us 1
aten::transpose 0.09% 7.000us 0.09% 7.000us 7.000us 7.000us 0.09% 10.000us 10.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 3.000us 0.04% 3.000us 3.000us 1
aten::view 0.01% 1.000us 0.01% 1.000us 1.000us 3.000us 0.04% 3.000us 3.000us 1
aten::addmm 0.42% 31.000us 0.53% 39.000us 39.000us 40.000us 0.52% 46.000us 46.000us 1
aten::empty 0.03% 2.000us 0.03% 2.000us 2.000us 6.000us 0.08% 6.000us 6.000us 1
cudaFuncGetAttributes 0.01% 1.000us 0.01% 1.000us 1.000us 0.000us 0.00% 0.000us 0.000us 1
cudaFuncGetAttributes 0.01% 1.000us 0.01% 1.000us 1.000us 0.000us 0.00% 0.000us 0.000us 1
cudaFuncGetAttributes 0.01% 1.000us 0.01% 1.000us 1.000us 0.000us 0.00% 0.000us 0.000us 1
INVALID 0.04% 3.000us 0.04% 3.000us 3.000us 0.000us 0.00% 0.000us 0.000us 1
aten::view 0.00% 0.000us 0.00% 0.000us 0.000us 2.000us 0.03% 2.000us 2.000us 1
aten::reshape 0.16% 12.000us 0.20% 15.000us 15.000us 10.000us 0.13% 18.000us 18.000us 1
aten::_reshape_alias 0.04% 3.000us 0.04% 3.000us 3.000us 8.000us 0.10% 8.000us 8.000us 1
aten::permute 0.11% 8.000us 0.12% 9.000us 9.000us 8.000us 0.10% 12.000us 12.000us 1
aten::as_strided 0.01% 1.000us 0.01% 1.000us 1.000us 4.000us 0.05% 4.000us 4.000us 1
aten::reshape 0.12% 9.000us 0.12% 9.000us 9.000us 8.000us 0.10% 12.000us 12.000us 1
aten::_reshape_alias 0.00% 0.000us 0.00% 0.000us 0.000us 4.000us 0.05% 4.000us 4.000us 1
aten::permute 0.09% 7.000us 0.09% 7.000us 7.000us 8.000us 0.10% 11.000us 11.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 3.000us 0.04% 3.000us 3.000us 1
aten::reshape 0.09% 7.000us 0.09% 7.000us 7.000us 8.000us 0.10% 11.000us 11.000us 1
aten::_reshape_alias 0.00% 0.000us 0.00% 0.000us 0.000us 3.000us 0.04% 3.000us 3.000us 1
aten::permute 0.12% 9.000us 0.12% 9.000us 9.000us 8.000us 0.10% 12.000us 12.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 4.000us 0.05% 4.000us 4.000us 1
aten::transpose 0.12% 9.000us 0.12% 9.000us 9.000us 9.000us 0.12% 12.000us 12.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 3.000us 0.04% 3.000us 3.000us 1
aten::matmul 0.85% 63.000us 2.04% 151.000us 151.000us 45.000us 0.59% 154.000us 154.000us 1
aten::expand 0.16% 12.000us 0.16% 12.000us 12.000us 11.000us 0.14% 15.000us 15.000us 1
aten::as_strided 0.00% 0.000us 0.00% 0.000us 0.000us 4.000us 0.05% 4.000us 4.000us 1
aten::reshape 0.12% 9.000us 0.14% 10.000us 10.000us 9.000us 0.12% 14.000us 14.000us 1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 7.388ms
Self CUDA time total: 7.691ms
STAGE:2024-08-24 10:47:51 2056036:2056036 ActivityProfilerController.cpp:311] Completed Stage: Warm Up STAGE:2024-08-24 10:47:51 2056036:2056036 ActivityProfilerController.cpp:317] Completed Stage: Collection STAGE:2024-08-24 10:47:51 2056036:2056036 ActivityProfilerController.cpp:321] Completed Stage: Post Processing
'男性健康科'
七、对外api提供能力
1. 推理函数:定义callmodel函数,接收患者病情描述文本,经过文本编码、模型预测、标签反转,输出对应的科室类别,例如输入“经常吸烟喝酒对乙肝危害大吗”,模型可准确预测为“感染与免疫科”;
2. 性能测试:使用torch.autograd.profiler进行GPU推理性能分析,结果显示单次推理的CPU总耗时为7.388ms,CUDA总耗时为7.691ms,推理速度较快,可满足实时分诊需求;
3. 模型保存:采用保存模型状态字典(state_dict)的方式,便于后续模型的加载与复用,保存文件名为model_state_dict_huatuo_fenlei_zh_char_http_5000.pth。
from flask import Flask, request
app = Flask(__name__)
@app.route('/receive', methods=['GET', 'POST'])
def receive_request():
if request.method == 'GET':
text = request.args.get('text')
if text is None:
return "请描述病情"
else:
out_class = callmodel(text)
print(out_class)
return "result is "+out_class
if __name__ == '__main__':
app.run()
* Serving Flask app '__main__' * Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Running on http://127.0.0.1:5000 Press CTRL+C to quit
八、项目总结
本项目成功构建了基于Transformer的医疗文本科室分类模型,实现了患者病情文本到就诊科室的精准映射,模型准确率高、推理速度快,可应用于医疗咨询分诊、智能问答等场景。通过HF镜像解决了数据集下载问题,通过合理的模型设计与超参数配置,确保了模型的性能与泛化能力。后续可进一步优化模型结构、扩大数据集规模,提升模型对复杂病情文本的分类精度,同时完善Flask服务,适配生产环境部署需求。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)