深耕算力底层:单精度浮点加法,AI 运算的核心底座
当我们谈论AI算力的“内卷”,聊的是GPU的万亿次FLOPS、NPU的算力集群、大模型的训练速度,却很少有人关注:支撑起这一切的,是一个看似简单却无可替代的底层运算——单精度浮点加法(FP32加法)。
它没有大模型的光环,没有芯片架构的复杂,却像建筑的基石、机器的齿轮,贯穿AI运算的每一个环节。从ChatGPT的千亿参数训练,到自动驾驶芯片的实时推理,再到边缘AI的轻量化计算,每一次数据的流转、每一次模型的迭代,本质上都离不开单精度浮点加法的支撑。深耕算力底层,读懂FP32加法,才算真正摸清了AI算力的核心逻辑。
一、打破认知:AI算力的“天花板”,藏在最简单的加法里
很多人误以为,AI算力的核心是“复杂算法”“高端芯片”,却忽略了一个本质:所有AI运算,最终都会拆解为最基础的浮点运算。而单精度浮点加法,就是这一切的起点。
我们常说的AI算力单位“FLOPS”(每秒浮点运算次数),核心统计的就是“浮点加法+浮点乘法”的总次数——其中,浮点加法的占比高达40%~60%,尤其是在神经网络的卷积、全连接、归一化等核心算子中,加法运算贯穿始终。
举个通俗的例子:大模型训练时,千亿级参数的矩阵乘法,拆解到硬件底层,就是无数个“乘法+加法”的组合(即MAC乘累加运算:Out = A×B + C)。其中,乘法负责参数与数据的匹配,而加法负责将所有匹配结果汇总、收敛,最终输出有效特征。没有高效的单精度浮点加法单元,再强大的芯片架构、再复杂的算法,都会陷入“算得慢、算不准”的困境。
更关键的是,单精度浮点加法(FP32)是AI算力的“通用基座”。它拥有完整的动态范围和精度,既能满足传统AI模型的训练需求,也是后续半精度(FP16/BF16)、整型(INT8/INT4)量化的“原始参考标准”——所有低精度运算,本质上都是对FP32运算的简化和优化,目的是在精度可接受的范围内,提升算力效率、降低功耗。
二、硬核拆解:单精度浮点加法,到底特殊在哪里?
参与有效浮点加减运算的两个操作数,其数据表示形式以及运算规则要遵循IEEE754 标准规范,规范中定义的规格化浮点数由三部分组成:符号、移码表示的指数以及由一个隐含位和一串原码数构成的尾数,且计算结果也要符合这种数据表示形式。因而,浮点加减运算的基本过程包含以下几个操作步骤:
(1) 指数相减,求阶差:比较两个操作数指数的大小,并求出指数差的绝对值。
(2) 交换尾数:根据指数比较的结果,交换两个尾数,使得较大的数总是去加减较小的数。
(3) 对阶移位:根据指数差绝对值的大小,将较小尾数进行右移,使得两个操作数的指数相同。
(4) 尾数加减运算:对两个尾数进行有效加减运算。
(5) 补码转换:当尾数相减结果为负值时,需将补码表示的结果转换为原码形式。
(6) 前导 1 检测:判断尾数计算结果中最左边第一个“1”出现的位置,并将判定的结果作为下一步规格化移位操作时的移位量。
(7) 规格化操作:对尾数计算结果进行规格化操作,同时根据移位的方向和移位量相应地调整指数。
(8) 舍入处理:根据 IEEE754 标准中的舍入模式,结合规格化移位后所产生的舍入位,对最终结果进行舍入处理。
(9) 舍入后的处理:舍入后如果尾数发生了溢出,还需要进行第二次规格化操作,即尾数再右移 1 位,同时指数还要加 1 进行调整,但之后不可能出现第二次舍入的过程。
浮点加减的一般计算过程包括 9 个串行的独立操作,当我们对这些操作特点进行分析后会发现,有些操作在一定的情况下是可以取消的:
(1) 当两个操作数的指数不相等时,可以取消补码转换操作;当指数相等且计算结果是负值时,需要补码转换操作,但不需要舍入处理。
(2) 在有效加法运算中,计算结果不需要全长的规格化移位,最多可能需要右移 1 位;在有效减法运算中,当指数差的绝对值小于或等于 1 时,不需要全长的对阶移位,但计算结果可能要进行全长的规格化移位;在有效减法运算中,当指数差的绝对值大于 1 时,可能需要全长的对阶移位,但计算结果不需要全长的规格化移位,最多可能需要左移 1 位。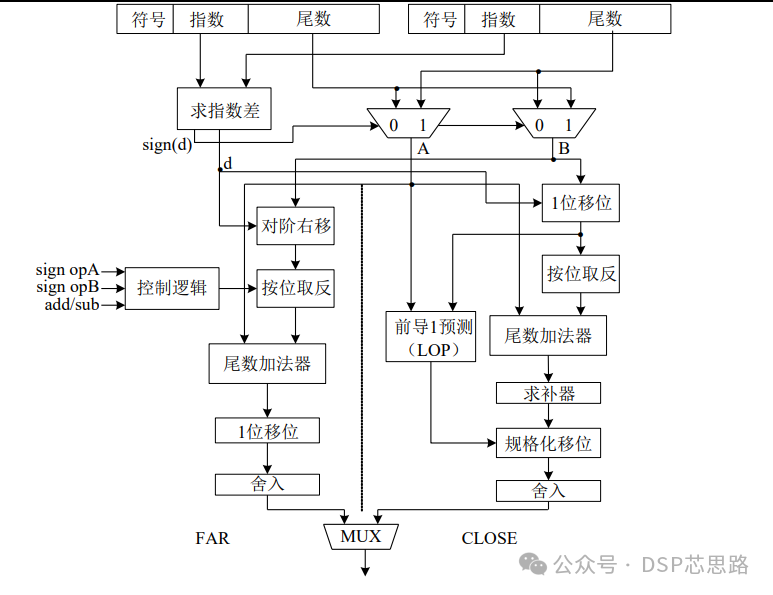
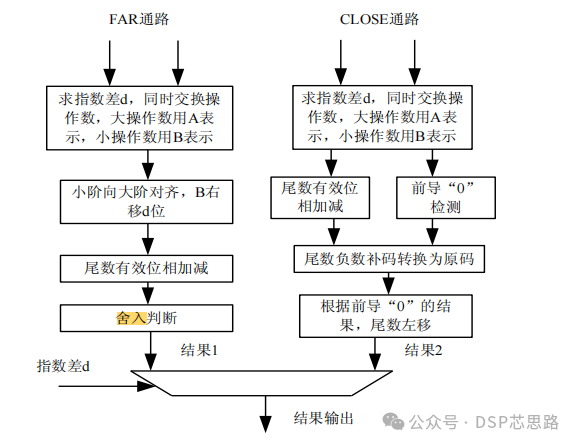
Farmwald 根据这些操作特点,提出了 Two-Path 算法,该算法将浮点加减计算过程的单数据通路(Single-Path)分成两个数据通路进行运算:
CLOSE 通路:指数差的绝对值小于或等于 1 且进行有效减法运算。在CLOSE 通路上取消了全长的对阶移位,而且当指数差等于 0 时不需要舍入处理;
对于 CLOSE 通路,对齐操作的移位最多为 1 位,d 的计算只由最后两位相减并且舍入判断操作可以避免。
FAR 通路:进行所有的有效加法运算以及指数差绝对值大于 1 时的有效减法运算。在 FAR 通路上取消了全长的规格化移位,但需要对阶移位及舍入处理。
对于 FAR 通路,尾数在最终的规格化时候,不需进行移位或者只需进行一位左移;尾数运算结果始终为正,不需转换成原码的操作;当两个操作数的指数相差非常大时,可以将较大的数当成结果直接输出;
1、求指数差,交换数据
2、FAR通路实现
3、CLOSE通路
4、非规格化数通路
双通路结果选择及最终结果选择
三、场景落地:从大模型到边缘AI,FP32加法无处不在
单精度浮点加法的价值,从来不是“纸上谈兵”,而是贯穿AI产业的每一个场景,从最顶尖的大模型训练,到最贴近生活的边缘AI,它都在默默发挥作用。
### 1. 大模型训练:FP32加法是“精度基石”
大模型(如GPT-4、文心一言)的训练,需要处理海量的参数和数据,对计算精度的要求极高——一旦精度不足,就会导致模型收敛失败、推理结果偏差。而单精度浮点加法(FP32)的高精度特性,能够保证参数更新的准确性,是大模型训练的“标配”。
虽然现代大模型会采用FP16/BF16半精度进行训练,以提升速度、降低功耗,但核心的参数初始化、梯度更新等关键环节,依然需要依赖FP32加法进行校准,确保模型的精度不受损失。可以说,没有FP32加法的支撑,大模型的训练就无从谈起。
### 2. 工业/边缘AI:FP32加法是“效率核心”
在工业AI、储能PCS、自动驾驶等边缘场景中,AI芯片(如DSP、边缘NPU)需要兼顾“精度”与“低功耗”,而单精度浮点加法单元,正是实现这一平衡的关键。
以储能PCS芯片为例,其核心的功率控制算法,需要实时进行大量的浮点运算,其中FP32加法占比超过50%——它负责将采集到的电压、电流数据进行汇总、计算,输出精准的控制信号。如果FP32加法效率不足,就会导致控制延迟增加,影响储能系统的稳定性。
同样,在自动驾驶芯片中,实时路况的识别、路径规划的计算,都需要FP32加法的支撑,确保数据处理的精度和速度,保障行车安全。
### 3. 通用AI芯片:FP32加法是“标配能力”
无论是GPU、NPU,还是DSP、FPGA,所有通用AI芯片,都必须标配单精度浮点加法单元。这是因为,FP32加法是AI运算的“通用语言”,能够适配各种AI模型和算法,确保芯片的通用性和兼容性。
比如TI C2000 DSP,作为工业AI、储能AI的核心芯片,其内部就集成了高性能的FP32加法流水线,能够高效支撑浮点运算,满足工业场景的高精度控制需求;而NVIDIA GPU的CUDA核心,本质上就是由无数个浮点加法器、乘法器组成,每一个CUDA核心的运算能力,都直接取决于FP32加法的效率。
四、深耕底层:读懂FP32加法,解锁AI算力的核心密码
当下,AI算力的竞争越来越激烈,各大厂商纷纷在芯片架构、工艺制程上“卷”精度、“卷”速度,却往往忽略了:底层运算的优化,才是提升算力的“捷径”。而单精度浮点加法,作为AI运算的核心底座,正是这一“捷径”的关键。
对于芯片设计者而言,优化FP32加法单元的流水线设计、降低运算延迟、提升吞吐量,是提升芯片算力的核心方向——每一次FP32加法效率的提升,都能直接转化为芯片的竞争力;对于AI从业者而言,读懂FP32加法的原理,能够更好地理解AI芯片的算力瓶颈,优化模型算法,让模型在现有硬件上发挥出最佳性能;对于行业而言,深耕FP32加法等底层运算,才能真正打破AI算力的“卡脖子”困境,构建自主可控的AI算力体系。
我们总说“万丈高楼平地起”,AI算力的“高楼”,正是建立在单精度浮点加法这一“基石”之上。它没有复杂的架构,没有耀眼的光环,却用最基础的运算,支撑起了AI产业的蓬勃发展。
深耕算力底层,从读懂单精度浮点加法开始——因为,只有掌握了这一核心底座,才能真正解锁AI算力的无限可能,在AI算力的竞争中,抢占底层优势,实现从“跟跑”到“领跑”的跨越。
有兴趣学习浮点运算的朋友,请阅读下面文章,报名参与!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)