第3节:核心心脏,手写 Agent 的 Main Loop
Agent Harness 专题
上一节:第2节:从Framework到Harness,Agent需要怎样的底层支撑?
本节:第3节:核心心脏,手写 Agent 的 Main Loop
这一节,我们来亲手实现整个系统里最核心的部分:Main Loop。
所有顶级的 Agent 引擎,表面上看起来像魔法一样,能在本地项目里来回穿梭、读代码、改文件、跑测试。
但如果你把这些系统一层层拆开,最终都会看到一个极其朴素、却又极其强健的东西:
一个持续运转的循环。
这个循环,在学术界通常被称为 ReAct(Reason + Act) 范式;而在工程实践里,我们更习惯叫它 Agent Loop,或者 Main Loop。
如果说 Harness 是操作系统,那么 Main Loop 就是它的“心脏起搏器”。
为什么 Agent 必须依赖 Main Loop?
大模型面对的,不是一个静态题目,而是一个开放、动态、需要不断探索的环境。
当它拿到一个宏大的任务时,它不可能像传统问答机器人那样,只靠一次 API 调用就输出最终答案。
原因很简单:
- 它不知道当前目录下有什么文件
- 它不知道代码运行后会报什么错
- 它不知道工具执行后会返回什么结果
- 它也不知道前一步的尝试会不会失败
换句话说,大模型天然带着一种“针眼瞎”式的信息缺口。
它必须一边思考,一边行动,再根据行动结果修正下一步判断。
这就是 Main Loop 存在的根本原因。
从 CoT 到 ReAct:智能体范式是怎么演进的?
为了让大模型真正具备“解决问题”的能力,研究界和工程界其实走过了几条不同的路。
1. 纯推理模式的局限
最典型的代表,就是 Chain of Thought(CoT)。
这种方法会在 Prompt 里加入类似 “Let’s think step by step” 的提示,要求模型把思考过程显式写出来。
它确实大幅提升了逻辑推导能力,但也有一个非常明显的问题:
它只能思考,不能感知真实世界。
如果代码库变了、报错信息变了、外部环境变了,模型依然只能基于训练数据和当前 Prompt 做推断,很容易滑向幻觉。
2. 纯行动模式的局限
另一条路线,是直接给模型一堆工具,让它预测“下一步该执行什么动作”。
这种方式的优点是能动起来,但缺点同样明显:
它会很像一个横冲直撞的莽夫。
模型虽然会调用工具,却缺少稳定的状态跟踪和自我反思能力,遇到报错之后也常常不知道为什么错、该怎么调整。
3. ReAct:让思考与行动交织起来
ReAct 的关键突破,在于它不再把“思考”和“行动”分开,而是把两者编织进同一个闭环。
一个真正的智能体,在每一轮里都要完成 4 件事:
-
思考(Reason / Thought)
分析当前线索,决定下一步意图。
比如:“我看到了 calc.go 这个文件,下一步应该先读取它。” -
行动(Act / Action)
向外部环境发出操作请求。
比如:调用 read_file 工具。 -
观察(Observe / Observation)
外部环境把行动结果回传给模型。
比如:返回 calc.go 的具体代码内容。 -
继续下一轮
模型把新的 Observation 纳入上下文,再次思考、再次行动,形成闭环。

图 1:Main Loop 的整体心跳结构
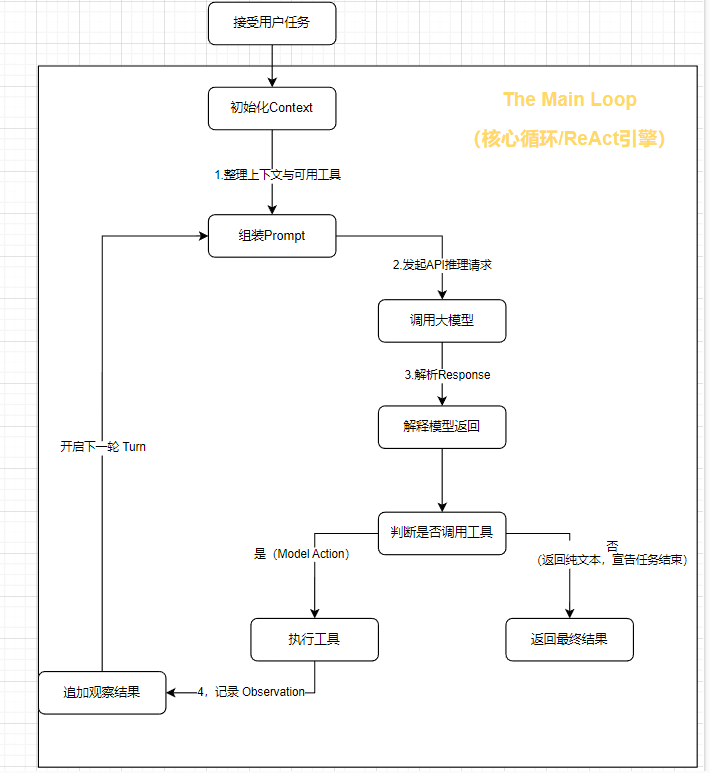
图 2:ReAct 让 Agent 从一次性回答,变成持续探索
Harness 视角下,Main Loop 有什么不同?
从 Harness 的角度看,Main Loop 不是一个“业务流程图”,而是一个高度克制的运行时循环。
它最重要的特征,通常有 3 个:
-
极度纯粹,没有预设分支
Loop 本身不承担业务逻辑,不写死“先做什么、再做什么”。路径完全由模型的实时推理决定。 -
不在这里设置生硬的最大步数
很多玩具框架喜欢限制最大轮数,比如 5 步、10 步、20 步。
但真实工业任务很可能需要几十轮。顶级引擎不会在这里简单粗暴截断,而是依赖后续的内存压缩、死循环干预和风险控制机制来维持稳定。 -
上下文是唯一的记忆载体
在 Main Loop 里,系统最核心的状态,就是不断累加的上下文。
每一次 Thought、Action、Observation,都会被追加进去,成为下一轮推理的依据。
正因为它足够朴素,才足够稳定。
项目开发:先定义统一的数据血液
在 Harness 引擎中,各个组件之间传递的核心数据,其实就是上下文。
大模型、工具系统、主循环,三者都围绕这一份上下文在协作。
但问题在于,不同模型供应商的 API 格式差异非常大。Claude、OpenAI、Gemini,各自都有不同的字段设计、消息结构、工具调用格式。
所以,在正式写 Main Loop 之前,我们必须先做一件事:
定义一套属于我们自己的统一 Schema。
它要能承载 ReAct 范式里最重要的几类信息:
- 消息角色
- 文本内容
- 工具调用请求
- 工具执行结果
- 轮次间持续追加的上下文历史
只有先统一“血液”,后面的 Provider、Registry、Engine 才能真正解耦。
第 1 步:实现核心引擎
下面这段代码,就是我们这个项目当前的 Main Loop 雏形。
/**
* ReAct 引擎核心(Main Loop)
*/
public class AgentEngine {
private static final Logger log = Logger.getLogger(AgentEngine.class.getName());
private final LLMProvider provider;
private final Registry registry;
private final String workDir;
public AgentEngine(LLMProvider provider, Registry registry, String workDir) {
this.provider = provider;
this.registry = registry;
this.workDir = workDir;
}
public void run(String userPrompt) {
log.info("[Engine] 引擎启动,工作目录: " + workDir);
// 初始化上下文
List<Message> contextHistory = new ArrayList<>();
Message systemMsg = new Message();
systemMsg.setRole(Role.SYSTEM);
systemMsg.setContent("You are my-claw, an expert coding assistant. You have full access to tools in the workspace.");
contextHistory.add(systemMsg);
Message userMsg = new Message();
userMsg.setRole(Role.USER);
userMsg.setContent(userPrompt);
contextHistory.add(userMsg);
int turnCount = 0;
// ======== 主循环:ReAct 心跳 ========
while (true) {
turnCount++;
log.info("========== [Turn " + turnCount + "] 开始 ==========");
// 获取可用工具
var availableTools = registry.getAvailableTools();
// 模型思考
log.info("[Engine] 正在思考 (Reasoning)...");
Message response = provider.generate(contextHistory, availableTools);
// 追加到历史
contextHistory.add(response);
// 输出模型思考
if (response.getContent() != null && !response.getContent().isEmpty()) {
System.out.println("🤖 模型: " + response.getContent());
}
// 退出条件:无工具调用 = 任务完成
if (response.getToolCalls() == null || response.getToolCalls().isEmpty()) {
log.info("[Engine] 任务完成,退出循环。");
break;
}
// 执行工具
log.info("[Engine] 模型请求调用 " + response.getToolCalls().size() + " 个工具...");
for (ToolCall toolCall : response.getToolCalls()) {
log.info(" -> 🛠️ 执行工具: " + toolCall.getName() + ", 参数: " + toolCall.getArguments());
ToolResult result = registry.execute(toolCall);
if (result.isError()) {
log.warning(" -> ❌ 工具执行报错: " + result.getOutput());
} else {
log.info(" -> ✅ 工具执行成功 (返回 " + result.getOutput().getBytes().length + " 字节)");
}
// 构造观察结果,加入上下文
Message observation = new Message();
observation.setRole(Role.USER);
observation.setContent(result.getOutput());
observation.setToolCallId(toolCall.getId());
contextHistory.add(observation);
}
}
}
}
这段代码看上去不长,但已经具备了 Main Loop 的核心骨架:
- 初始化系统消息和用户消息
- 把历史上下文持续累加起来
- 交给模型生成下一步决策
- 判断是否存在工具调用
- 执行工具并把结果作为 Observation 回写上下文
- 若无工具调用,则退出循环
你可以把它理解为一个最小可运行的“Agent 心跳”。
第 2 步:写一个最小可验证的测试闭环
光有 Main Loop 还不够,我们还需要一个最小实验环境,来验证这颗“心脏”是否真的会跳。
所以这里我用了两个 Mock 组件:
- 一个伪造的 LLMProvider
- 一个伪造的 Tool Registry
前者负责模拟模型在第 1 轮发起工具调用,在第 2 轮输出最终结论。
后者负责模拟工具执行结果,比如返回一条假的文件列表。
@SpringBootApplication
public class Main {
private static final Logger log = LoggerFactory.getLogger(Main.class);
// ========== 伪造 LLM Provider ==========
static class MockProvider implements LLMProvider {
private int turn = 0;
@Override
public Message generate(List<Message> messages, List<ToolDefinition> availableTools) {
turn++;
Message msg = new Message();
msg.setRole(Role.ASSISTANT);
if (turn == 1) {
msg.setContent("让我来看看当前目录下有什么文件。");
ToolCall call = new ToolCall();
call.setId("call_123");
call.setName("bash");
call.setArguments("{\"command\": \"ls -la\"}");
msg.setToolCalls(List.of(call));
} else {
msg.setContent("我看到了文件列表,里面包含 main.go,任务完成!");
}
return msg;
}
}
// ========== 伪造 Tool Registry ==========
static class MockRegistry implements Registry {
@Override
public List<ToolDefinition> getAvailableTools() {
return List.of();
}
@Override
public ToolResult execute(ToolCall call) {
ToolResult result = new ToolResult();
result.setToolCallId(call.getId());
result.setOutput("-rw-r--r-- 1 user group 234 Oct 24 10:00 main.go\n");
result.setError(false);
return result;
}
}
public static void main(String[] args) {
SpringApplication.run(Main.class, args);
log.info("欢迎来到 my-claw 引擎启动序列");
log.info("架构蓝图搭建完毕,等待各核心模块注入!");
log.info("=========");
String workDir = System.getProperty("user.dir");
LLMProvider provider = new MockProvider();
Registry registry = new MockRegistry();
AgentEngine engine = new AgentEngine(provider, registry, workDir);
engine.run("帮我检查当前目录的文件");
}
}
这个测试环境的意义不在于“功能完整”,而在于它验证了最关键的一点:
模型发起行动 -> 工具返回结果 -> 模型继续推理 -> 循环自然结束。
只要这个闭环成立,后面接入真实模型、真实工具、真实上下文工程,才有意义。
第 3 步:看测试结果是否符合预期
下面是这段 Main Loop 跑起来之后的日志输出:
2026-04-28T12:05:33.394+08:00 INFO 29888 --- [ main] com.example.javaclaw.Main : 欢迎来到 my-claw 引擎启动序列
2026-04-28T12:05:33.394+08:00 INFO 29888 --- [ main] com.example.javaclaw.Main : 架构蓝图搭建完毕,等待各核心模块注入!
2026-04-28T12:05:33.394+08:00 INFO 29888 --- [ main] com.example.javaclaw.Main : =========
2026-04-28T12:05:33.395+08:00 INFO 29888 --- [ main] c.example.javaclaw.engine.AgentEngine : [Engine] 引擎启动,工作目录: D:\Code\Agent Harness\harness-learning\my-claw
2026-04-28T12:05:33.395+08:00 INFO 29888 --- [ main] c.example.javaclaw.engine.AgentEngine : ========== [Turn 1] 开始 ==========
2026-04-28T12:05:33.396+08:00 INFO 29888 --- [ main] c.example.javaclaw.engine.AgentEngine : [Engine] 正在思考 (Reasoning)...
🤖 模型: 让我来看看当前目录下有什么文件。
2026-04-28T12:05:33.396+08:00 INFO 29888 --- [ main] c.example.javaclaw.engine.AgentEngine : [Engine] 模型请求调用 1 个工具...
2026-04-28T12:05:33.396+08:00 INFO 29888 --- [ main] c.example.javaclaw.engine.AgentEngine : -> 🛠️ 执行工具: bash, 参数: {"command": "ls -la"}
2026-04-28T12:05:33.396+08:00 INFO 29888 --- [ main] c.example.javaclaw.engine.AgentEngine : -> ✅ 工具执行成功 (返回 51 字节)
2026-04-28T12:05:33.396+08:00 INFO 29888 --- [ main] c.example.javaclaw.engine.AgentEngine : ========== [Turn 2] 开始 ==========
2026-04-28T12:05:33.396+08:00 INFO 29888 --- [ main] c.example.javaclaw.engine.AgentEngine : [Engine] 正在思考 (Reasoning)...
🤖 模型: 我看到了文件列表,里面包含 main.go,任务完成!
2026-04-28T12:05:33.396+08:00 INFO 29888 --- [ main] c.example.javaclaw.engine.AgentEngine : [Engine] 任务完成,退出循环。
如果把这段日志翻译成人话,其实就是:
- 模型先思考
- 然后决定调用工具
- 工具把结果返回回来
- 模型基于 Observation 继续思考
- 发现任务已经完成,于是自然退出
这就是一个最小版的 ReAct Main Loop。
它还不复杂,但已经足够真实。
这一节的结论
Agent 的核心,不是“会不会调工具”,而是它有没有一个稳定、透明、持续运转的 Main Loop。
这个 Loop 不需要一开始就做得很花哨。
恰恰相反,它越朴素、越克制、越像一个真正的操作系统心跳,后面就越容易扩展出:
- 更强的上下文工程
- 更完整的工具系统
- 更稳的死循环干预
- 更严格的安全审批与边界控制
所以,手写 Main Loop 的意义,不只是“把代码跑起来”。
更重要的是,它让我们第一次真正掌握了 Agent 的心脏。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)