Java开发者AI转型第二十四课!Spring AI 个人知识库实战(三)——记忆交互+SSE流式响应落地
大家好,我是直奔標杆!专注Java开发者AI转型实战分享,和各位战友一起吃透Spring AI,从零基础到企业级落地,每一步都不踩坑~ 今天咱们继续推进Spring AI个人知识库实战系列,来到第二十四课,也是知识库从“有数据”到“能交互”的关键一步!
在上一节课中,咱们一起搭建了知识库ETL异步流水线,把私有文档完成切片、降维,成功存入向量数据库,相当于给知识库搭好了“数据仓库”。而今天,咱们要做的就是给这个仓库装上“大脑”(上下文记忆)和“嘴巴”(流式交互),真正实现智能问答,解决企业级落地中的核心痛点!
做过AI实战的战友都知道,实验室里的demo很丝滑,但一到生产环境就容易出问题,咱们今天就直面两个高频坑,一起拆解解决:
1. 语境断层(无记忆的RAG):真实业务里的对话都是多轮的,比如用户先问“年假怎么规定?”,接着追问“那它能和调休一起休吗?”,如果直接把带代词的残缺句子传给大模型,大概率会得到无效回复——这就是RAG没有记忆的尴尬。
2. 网络雪崩(同步HTTP阻塞):大模型推理本身就耗时,如果还用传统同步阻塞的HTTP接口,高并发场景下很容易出现504 Gateway Timeout,用户体验直接拉满,生产环境根本无法上线。
那么问题来了:如何让AI既懂文档(RAG检索)又懂上下文(对话记忆)?如何把漫长的等待,变成ChatGPT那样丝滑的“打字机”体验?
本节课,咱们就手把手实战:通过编排ChatMemoryAdvisor与QuestionAnswerAdvisor的责任链,结合响应式编程的SSE(Server-Sent Events)协议,搭建一条高效、抗压的流式交互管道,彻底解决这两个痛点!
前置知识(必看):想要顺畅跟上本节课实战,建议先回顾以下几节课的内容,都是核心铺垫,避免踩坑:
-
Java开发者AI转型第五课!让AI懂规矩!Spring AI 结构化输出 (DTO) 映射与Flux流式打字机极速响应
-
Java开发者AI转型第六课!Spring AI 灵魂架构 Advisor 切面拦截与自定义实战
-
Java开发者AI转型第七课!AI失忆症克星!ChatMemory 对话历史管理与上下文实战
-
Java开发者AI转型第十五课!Spring AI 魔法:全新模块化RAG引擎一键闭环
本节章节目标(直奔核心,不绕弯)
咱们学习不搞虚的,每节课都有明确目标,学完就能落地:
-
认知重塑:吃透Advisor链式调用的底层执行逻辑,用数学逻辑拆解RAG检索中的“坏案(Bad Case)”,搞懂为什么会出现“答非所问”。
-
极简实战:抛弃繁琐的硬编码,在Service层优雅编排滑动窗口记忆与RAG检索组件,代码简洁且可复用,符合企业级开发规范。
-
协议降维:掌握WebFlux与SSE协议的实战用法,把耗时的阻塞请求,改造成轻量级的单向数据传送带,实现秒级流式响应。
知识库功能预览(先看效果,再敲代码)
在动手编码前,先给大家看一下本节课实战完成后的核心功能,做到心中有数:
-
登录页面:用户身份校验,隔离不同用户的知识库与对话历史;

-
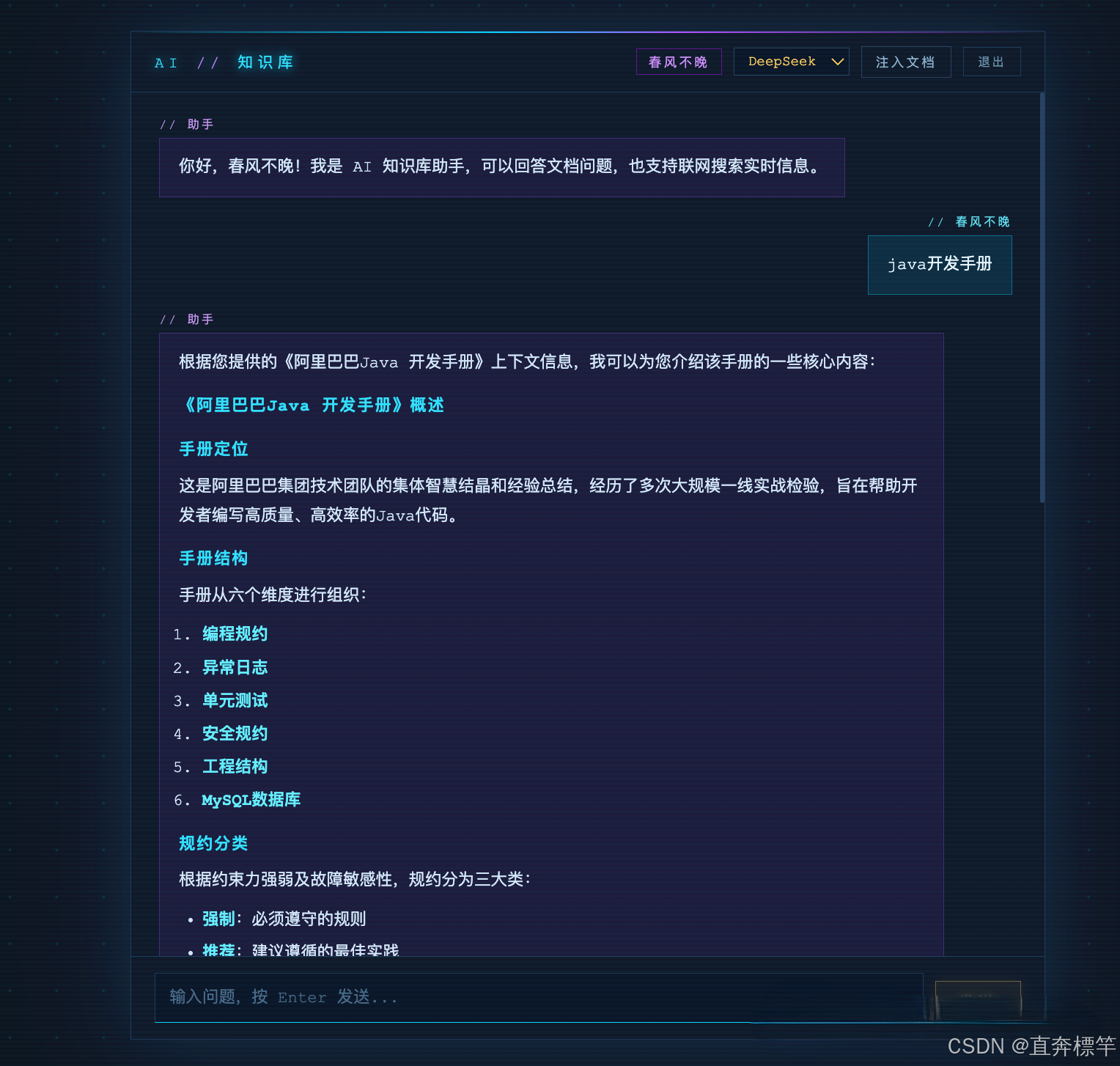
RAG对话:基于向量数据库检索私有文档,同时记住多轮对话上下文,不出现语境断层;
-
联网对话:(延伸功能)结合联网能力,补充知识库外的实时信息(本节课重点聚焦RAG记忆与SSE流式)。
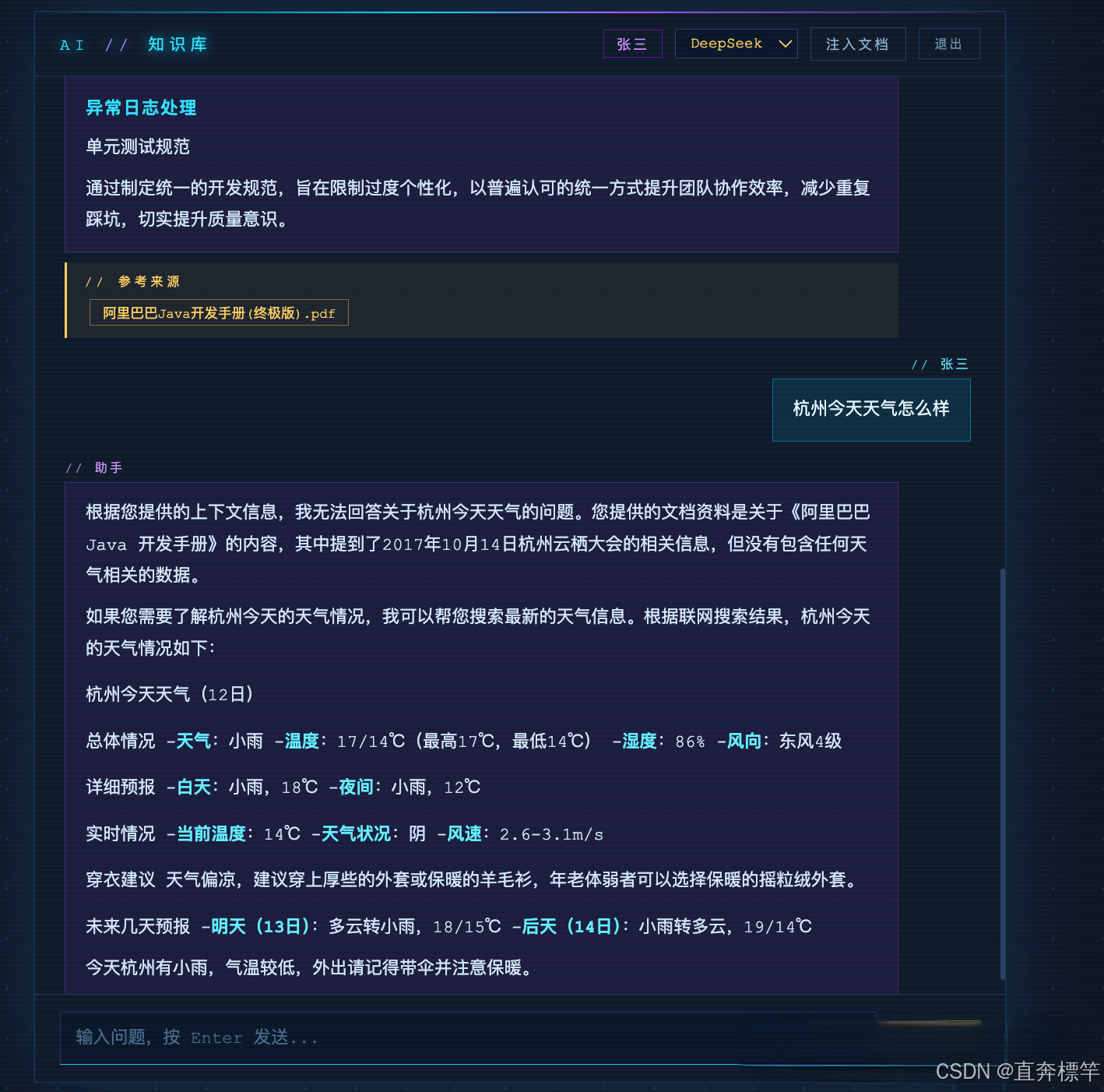
核心数据流转图(全局视角,避免踩坑)
编码前一定要先理清数据流转逻辑,不然容易写着写着乱了思路,全局流转如下(建议收藏):
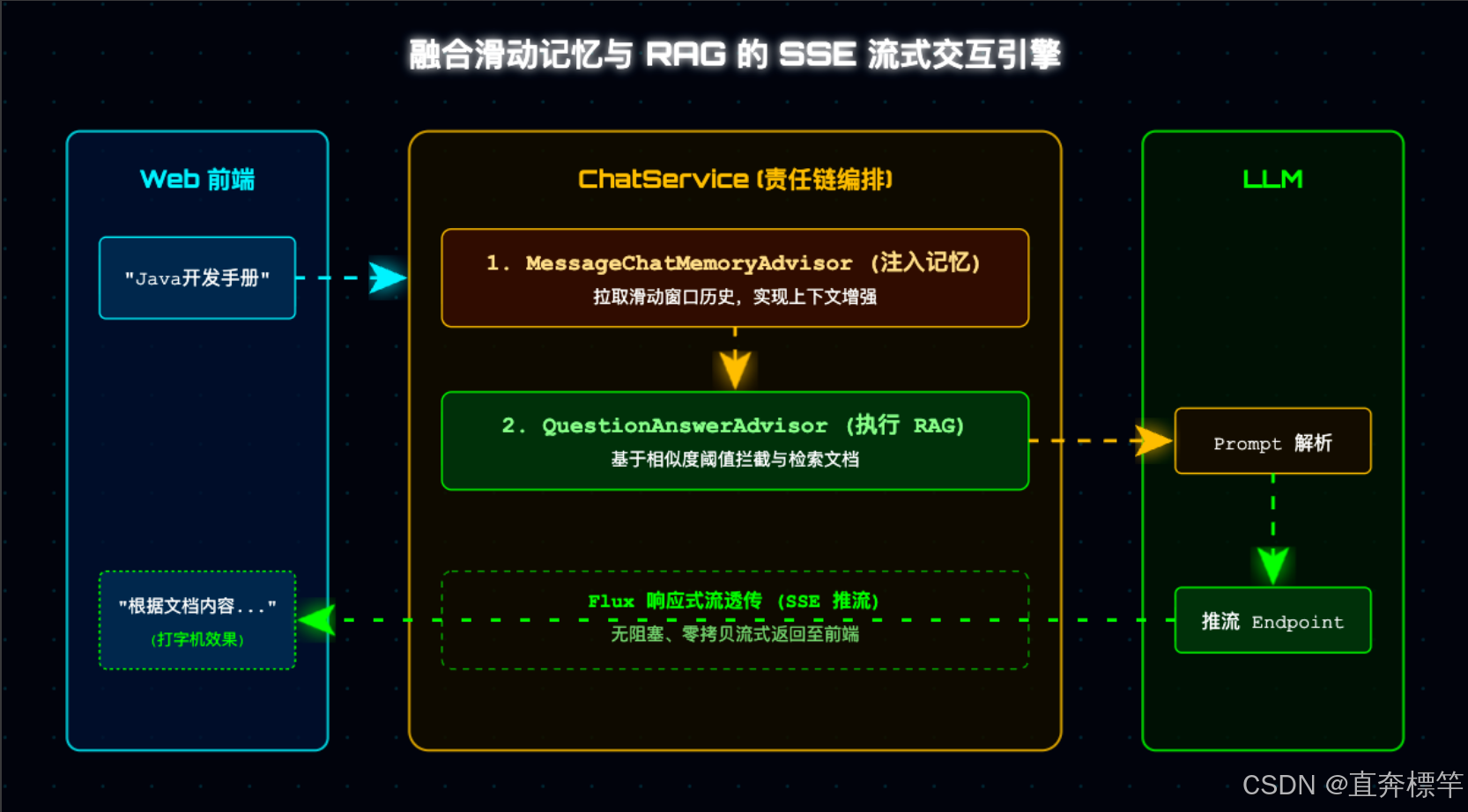
用户输入 → 前端通过SSE请求发送至后端 → Service层通过Advisor责任链,先拉取对话历史(ChatMemoryAdvisor),再检索向量库(QuestionAnswerAdvisor) → 拼接完整Prompt发送至大模型 → 大模型流式返回结果 → 通过SSE推送到前端,实现“打字机”效果。
实战环节:构建具备记忆和向量检索的服务(核心代码,可直接复用)
理清架构后,咱们直接切入核心代码。相信很多战友都踩过硬编码拼接对话历史的坑,代码冗余且难维护,今天咱们用Spring AI的Advisor机制,优雅编排记忆组件和问答组件,彻底解决这个问题!
public class ChatServiceImpl implements ChatService {
/** System Prompt:约束大模型严格基于知识库内容回答,杜绝幻觉(企业级必备) */
private static final String SYSTEM_PROMPT = """
你是一个由Spring AI驱动的私人知识库助手,专注于解答用户基于私有文档的疑问。
请严格根据提供的文档参考资料回答用户问题,不添加无关内容。
如果资料中没有相关信息,请明确告知“未检索到相关信息”,绝对不要编造内容、不要引申回答。
""";
private final ChatModelStrategyFactory strategyFactory;
private final VectorStore vectorStore;
private final ChatMemory chatMemory;
// 构造方法省略(实际开发中记得用依赖注入,避免硬编码)
@Override
public Flux<String> streamChat(String chatId, String message, ModelType modelType) {
// 根据传递的模型类型,获取对应的ChatClient(策略模式,灵活切换模型)
ChatClient chatClient = strategyFactory.getStrategy(modelType).getChatClient();
// 构建流式请求,编排Advisor责任链
return chatClient.prompt()
.system(SYSTEM_PROMPT) // 系统提示,约束大模型行为
.user(message) // 用户当前提问
.advisors(advisorSpec -> advisorSpec
// 1. 记忆Advisor:自动拉取当前会话的历史消息,注入上下文
.advisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
// 2. RAG Advisor:查询向量库,获取相关文档切片
// topK=4 取最相似的4个知识块,similarityThreshold=0.75 过滤低质量结果(后续优化)
.advisors(QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.topK(4)
.similarityThreshold(0.75)
.build())
.build())
// 透传会话ID,隔离不同用户的对话历史(关键:避免会话混乱)
.param(ChatMemory.CONVERSATION_ID, chatId)
)
.stream() // 开启流式响应
.content(); // 提取响应内容,返回Flux<String>
}
}底层细节剖析(吃透原理,不做黑盒调用)
很多战友只复制代码,却不懂底层逻辑,遇到问题无从下手,这里直奔標杆给大家拆解关键细节,帮大家吃透Advisor机制:
Advisor的执行本质是经典的责任链模式,通过getOrder()方法确定执行顺序:值越小,请求前(Pre-process)越先执行;响应后(Post-process)越后执行,就像穿衣服和脱衣服的逻辑——先穿内衣再穿外套,脱的时候则相反。
默认getOrder()顺序下,MessageChatMemoryAdvisor先执行,Spring AI底层会自动查询当前chatId对应的对话历史,拼接成完整上下文;随后QuestionAnswerAdvisor执行,从向量库(比如Redis)中检索出与用户问题最相关的文档切片,再重新构建用户提问(补充文档信息)。
这就是Spring AI高内聚架构的优势——所有繁琐的操作(历史拼接、向量检索),都被Advisor拦截器优雅封装,Service层只需要关注核心业务逻辑,代码简洁又易维护,这也是企业级开发的核心规范之一。
重点避坑:RAG中的“坏案(Bad Case)”与阈值调优(实战必看)
上面的代码中,我们设置了similarityThreshold(0.75),但在实战中,很多战友会遇到诡异问题:用户问“加班报销”,系统却搜出了《Java开发手册》,这就是典型的RAG坏案,今天咱们彻底拆解原因,给出可落地的调优方案!
1. 为什么会出现“答非所问”?(底层数学逻辑拆解)
很多战友误以为“相似度0.85就是高相关”,其实是陷入了认知误区,咱们用具体数值拆解:
假设向量库返回的距离(Distance)是0.148,Spring AI的相似度得分(Score)计算逻辑是:$$Score = 1 - Distance$$,也就是1 - 0.148 = 0.852。因为0.852 > 0.75,系统会认为这篇文档“高度相关”,强行推给大模型,最终导致答非所问。
2. 高维空间的“引力”陷阱(关键认知)
为什么毫无关联的内容,相似度能达到0.85?核心是两个误区,大家一定要避开:
-
百分制的错觉:人类觉得85分很高,但在OpenAI(如text-embedding-ada-002)生成的1536维空间中,绝大多数中文句子的余弦相似度底分都在0.70左右——这意味着0.75的阈值几乎是“地板价”,根本起不到过滤作用。真正高度相关的文本,相似度得分通常在0.88~0.95之间。
-
局部词汇重叠的干扰:搜索词中的“加”字,和《Java开发手册》中的“方法名加上...”,在向量计算时,微小的字面重合会产生错误的“引力”,直接拉高相似度得分,这也是RAG检索中常见的坑之一。
3. 企业级调优方案(直接落地,立竿见影)
针对以上问题,直奔標杆给大家两个实战调优方案,亲测有效,大家可以直接应用到项目中:
-
调高相似度阈值:将similarityThreshold提升至0.85及以上,过滤低质量关联结果,从源头减少坏案。
-
元数据过滤(企业级必备):存入向量库时,给文档打上分类标签(如category='hr_policy',表示人事政策类);检索时,通过filterExpression("category == 'hr_policy'")添加过滤条件,从物理层面隔绝无关文档(如《Java开发手册》),让其连打分的资格都没有,这也是提升RAG召回准确率的核心手段之一。
进阶实战:拥抱SSE传送带,实现丝滑“打字机”体验
Service层已经产出了Flux<String>流式数据,接下来的核心的是:如何在不阻塞Tomcat线程的前提下,将这条数据流安全暴露给前端,实现“打字机”效果?答案就是SSE协议!
传统Servlet体系中,请求和响应是绑定的,同步等待大模型响应时,线程会一直阻塞,高并发下很容易雪崩;而Spring WebFlux的响应式体系,配合SSE协议,就能完美解决这个问题——SSE就像一条单向传送带,将大模型生成的内容,实时、平滑地推送到前端,无需前端频繁轮询。
以下是SSE流式接口的实战代码,可直接复用:
/**
* 流式对话接口(SSE协议,企业级落地版)
* produces = MediaType.TEXT_EVENT_STREAM_VALUE 声明采用SSE协议
*/
@GetMapping(value = "/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> stream(
@RequestParam("message") String message,
@RequestParam(value = "chatId", defaultValue = "default") String chatId,
@RequestParam(value = "model", defaultValue = "openai") String model) {
// 省略参数校验(实际开发中务必校验,避免非法请求)
ModelType modelType = ModelType.valueOf(model.toUpperCase());
return chatService.streamChat(chatId, message, modelType)
// 客户端断开连接时,及时释放资源,避免线程浪费
.doOnCancel(() -> log.warn("[SSE] 客户端断开连接,会话ID: {}", chatId))
// 异常处理,给用户友好提示,避免前端报错
.onErrorResume(e -> {
log.error("[SSE] 流式响应异常: {}", e.getMessage(), e);
return Flux.just("\n\n[系统提示] AI服务暂时不可用,请稍后重试");
});
}底层细节剖析(关键优化点)
这里有一个极易被忽略的优化点,也是生产环境必须具备的:.doOnCancel(...)方法。
在同步接口中,如果用户不耐烦关掉网页,后端Java线程依然会继续等待大模型响应,导致算力和Token的严重浪费;而在Reactor响应式体系下,.doOnCancel(...)会监听客户端的TCP断开信号,并逆向传播,直接斩断正在等待的网络I/O,及时释放资源——这一个小优化,能在高并发场景下大幅提升系统稳定性,大家一定要加上!同时建议开启虚拟线程(spring.threads.virtual.enabled=true),避免并发过高时线程卡死。
本节课总结(重点回顾,加深记忆)
今天这节课,咱们聚焦Spring AI个人知识库的“交互层落地”,攻克了两个核心痛点,掌握了三个关键技能,直奔標杆帮大家梳理重点,方便后续回顾:
-
逻辑层:通过Advisor责任链,优雅编排ChatMemoryAdvisor(记忆)和QuestionAnswerAdvisor(RAG检索),解决了多轮对话的语境断层问题,让AI既懂文档又懂上下文。
-
网络层:利用WebFlux响应式流与SSE协议,将阻塞请求改造成流式响应,实现丝滑“打字机”体验,同时通过.doOnCancel(...)优化资源释放,避免线程浪费。
-
调优点:吃透RAG坏案的底层原因,掌握阈值调高、元数据过滤两种企业级调优方案,减少答非所问,提升知识库准确性。
其实Spring AI的核心优势,就是把复杂的AI交互逻辑封装成可复用的组件,让Java开发者不用关注底层细节,就能快速落地企业级AI应用——这也是咱们Java开发者AI转型的核心捷径,一起加油,直奔標杆!
下期预告(精彩抢先看)
【Java开发者AI转型第二十五课!Spring AI 个人知识库实战(四)——溯源引用落地,让AI回答有据可查】
咱们今天实现的接口已经能实现丝滑的多轮对话,但在严谨的企业级场景下,前端用户凭什么相信AI的答案?如果AI胡说八道、编造内容怎么办?
下一节课,咱们将推翻当前的纯文本提取模式,深入ChatResponse的深层嵌套,在数据流即将关闭的末端帧(EOF),劫持大模型参考的PDF来源文件名、页码等关键信息,将其作为“溯源引用(Citations)”拼接发送给前端——让咱们的知识库每一句话都有据可查,彻底杜绝幻觉,满足企业级合规要求!
精彩继续,咱们下节课见!
往期内容回顾(循序渐进,不踩坑)
-
Java开发者AI转型第二十一课!吃透Spring AI MCP底层源码,彻底告别黑盒调用
-
Java开发者AI转型第二十二课!Spring AI 个人知识库实战(一)——架构搭建与核心契约落地
-
Java开发者AI转型第二十三课!Spring AI个人知识库实战(二):异步ETL流水线搭建与避坑指南
我是直奔標杆,专注Java开发者AI转型实战分享,每一节课都结合企业级场景,不玩虚的、不绕弯子,和大家一起从零基础吃透Spring AI,稳步实现AI转型!如果觉得本节课对你有帮助,欢迎点赞、收藏、留言交流,一起进步~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)