自动驾驶大模型---RAD(Reinforced Autonomous Driving)
1 前言
在前面的博客中,笔者写了大量的文章,去介绍普及自动驾驶端到端相关的内容,包括VLM/VLA或者VA等架构。本篇博客笔者主要介绍很多车企都在使用的世界模型生成方案---3DGS。
当下主流端到端智驾模型多采用模仿学习范式,但该范式在实际应用中存在难以解决的关键问题,这也成为 RAD(Reinforced Autonomous Driving)范式提出的核心动因:
- 因果混淆问题:模仿学习本质是拟合人类驾驶轨迹的相关性而非因果关系,模型易出现捷径学习。例如仅靠历史轨迹外推未来轨迹,而非基于障碍物、交通规则等真实因果因素做决策,且训练数据以常规驾驶行为为主,导致模型对碰撞等安全关键事件不敏感。
- 开环闭环差异问题:模仿学习以开环方式训练,而真实驾驶是闭环过程。单步微小的轨迹误差会随时间累积,使车辆陷入训练数据外的场景,此时仅靠模仿学习训练的模型极易失效。
- 传统闭环训练不可行:若直接在真实道路开展闭环强化学习训练,会面临极高的安全风险与运营成本;而基于游戏引擎的仿真环境,又无法提供逼真的传感器模拟结果,难以匹配真实驾驶场景的需求。
2 RAD 架构
该论文由华中科技大学与地平线团队联合提出,核心是打造了名为 RAD(Reinforced Autonomous Driving)的端到端自动驾驶训练范式。它创新性地结合 3D 高斯溅射(3DGS)技术构建数字孪生世界,用强化学习后训练突破传统模仿学习的瓶颈,既弥补了模仿学习在安全性和因果推理上的缺陷,又通过模仿学习正则化保证驾驶行为贴合人类习惯,大幅提升了自动驾驶策略的安全性与泛化能力。如下图所示:
2.1 总体架构
总体架构中主要包括两个方面的内容:
(1)VA端到端架构---下图中的上半部分;
VA端到端架构通过sensor获取图像信息,通过BEV Encoder得到BEV features,然后通过Perception Head进行解码,得到环境特征;同时Image Encoder通过 sensor获取原始的图像特征,然后再结合Perception Head解码得到的环境特征,输出最终的trajectory或者action。
(2)训练范式---下图中的下半部分;
训练主要分为三个阶段:
- 感知预训练;
- 规划预训练;
- 强化学习后训练;
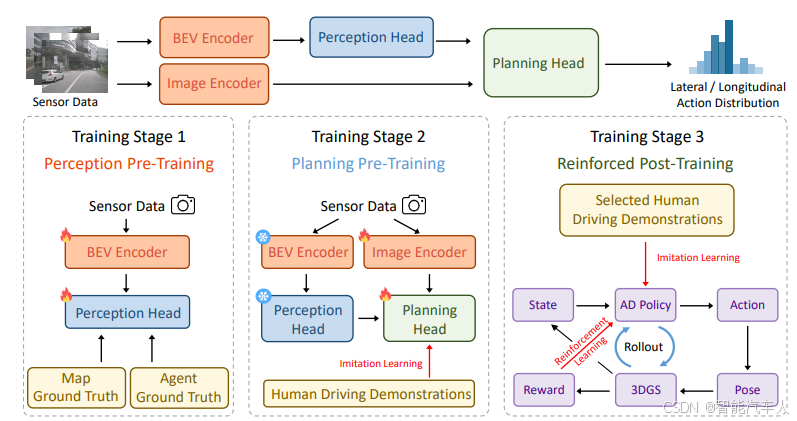
2.2 训练流程
RAD 包括三阶段训练范式,整体设计兼顾感知精度与训练效率,具体如下:
| 模块 / 阶段 | 核心构成与操作 | 关键作用 |
|---|---|---|
| 感知预训练 | 由真值标签监督地图头和智体头,使其输出准确的地图元素与交通参与者运动信息,仅更新 BEV 编码器、地图头和智体头的参数。 | 让模型提前掌握高级感知能力,为后续规划任务奠定基础,避免感知与规划的参数优化冲突 |
| 规划预训练 | 采用模仿学习,基于人类专家驾驶数据初始化模型的动作概率分布,此阶段仅更新图像编码器和规划头参数,冻结感知相关模块参数。 | 解决强化学习训练的冷启动问题,让模型先掌握基础的类人驾驶能力 |
| 强化后训练 | 设置多个并行训练单元,每个单元随机采样 3DGS 场景开展交互训练,生成的训练数据存入缓冲区。训练中用近端策略优化(PPO)算法微调模型,通过广义优势估计(GAE)传播奖励,同时将模仿学习作为正则约束模型行为。 | 通过与数字孪生环境的交互,让模型学习因果关系,提升对罕见危险场景的应对能力,最终形成安全可靠的驾驶策略 |
2.3 实验
- 实验设置:构建了由未见过的 3DGS 场景组成的闭环评估基准,将 RAD 与传统模仿学习方法在该基准上进行对比测试,重点评估碰撞率等核心安全指标。同时将 RAD 的端到端策略与主流模块化方案开展闭环性能比对。
- 关键结果:RAD 的综合性能显著优于传统模仿学习方法,其中碰撞率相比后者降低 3 倍,能有效应对无保护左转、行人突发横穿等危险场景。此外,其在轨迹平滑度、与人类驾驶行为的一致性等指标上也表现优异,验证了该范式在安全性和实用性上的优势。


3 总结
局限性与未来方向该范式目前仍存在部分待优化点:一是 3DGS 环境中其他交通参与者的行为基于场景回放生成,缺乏实时交互响应能力;二是在低光照、欠观测视角等场景下,3DGS 的场景重建效果还有提升空间。后续研究将聚焦提升数字孪生世界的交互真实性,同时探索进一步拓展强化学习的规模效应,持续突破端到端自动驾驶的能力边界。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)