(论文速读)Sonnet:多变量时间序列预测的谱算子神经网络
论文题目:Sonnet: Spectral Operator Neural Network for Multivariable Time Series Forecasting(多变量时间序列预测的谱算子神经网络)
会议:AAAI2026
摘要:多变量时间序列预测方法可以整合外生变量的信息,从而显著提高预测精度。变压器体系结构由于能够捕获长期序列依赖关系,在各种时间序列预测模型中得到了广泛的应用。然而,变压器的新兴应用往往难以有效地模拟变量之间随时间变化的复杂关系。为了缓解这种情况,我们提出了一种新的架构,称为谱算子神经网络(Sonnet)。Sonnet将可学习的小波变换应用于输入,并使用Koopman算子进行频谱分析。它的预测技能依赖于多变量相干注意(MVCA),这是一种利用光谱相干性来模拟变量依赖关系的操作。我们的实证分析表明,Sonnet在47项预测任务中的34项中表现最佳,相对于最具竞争力的基线,平均绝对误差(MAE)降低了2.2%。我们进一步表明,MVCA可以弥补各种深度学习模型中na¨ıve注意力的不足,在最具挑战性的预测任务中平均降低了10.7%的MAE。
代码地址:Code & data — https://github.com/ClaudiaShu/Sonnet
Sonnet:用谱算子神经网络征服多变量时间序列预测
一、背景与问题:为什么现有方法不够好?
时间序列预测是机器学习中的经典问题,但"多变量时间序列(Multivariable Time Series,MTS)预测"有其独特之处——它不是预测所有变量,而是利用多个外生变量(exogenous variables)来预测单一目标变量。这种设定在现实中极为普遍:用搜索引擎的查询频率预测流感发病率、用气象站数据预测某地气温、用电网传感器数据预测电价,都是典型例子。
外生变量之所以重要,是因为它们往往携带目标变量自身历史数据所不具备的预测信号。然而,如何有效地从外生变量中提取信息,同时避免过拟合,是一个悬而未决的难题。
现有方法的三类缺陷
第一类:忽视变量间依赖的方法
DLinear、PatchTST等模型对每个变量独立建模,无法利用外生变量。在ILI(流感预测)等任务上,这类方法甚至无法超越最简单的持久性(Persistence)基线——也就是直接用上一个时间步的值作为预测。
第二类:建模变量依赖,但破坏时序结构
Samformer、iTransformer、TimeXer等基于Transformer的方法在变量维度上做注意力时,会把时间序列沿时间维度嵌入,破坏了时序信息,导致在需要保留时序结构的MTS任务上性能受限。
第三类:保留时序结构,但扩展性差或感受野受限
- Crossformer 和 ModernTCN 在外生变量数量或序列长度增加时,GPU内存消耗急剧上升。
- DeformTime(同组前期工作)用可变形注意力捕获跨变量依赖,但本质上受限于卷积核感受野,无法探索更广范围的外生变量。
根本问题在哪里?
上述方法都在时域上建模变量间关系,而忽略了一个强有力的频域工具:谱相干性(Spectral Coherence)。两个时间序列在某些频率上高度相关,而在另一些频率上完全无关——这种结构化的频域依赖关系,是时域注意力(点积相似度)难以捕捉的。
二、Sonnet的核心思想
Sonnet的基本逻辑可以概括为:把时间序列变换到时频域,在频域中用谱相干性建模变量依赖,再用Koopman算子稳定地预测时频动态,最后重建回时域输出预测。
整个模型由五个模块串联组成,下面逐一介绍。
三、模块详解
3.1 联合嵌入(Joint Embedding)
给定输入矩阵 ,包含 C 个外生变量和 1 个内生(目标)变量,Sonnet分别用两个可学习权重矩阵对它们进行线性投影:
超参数 控制外生变量在最终嵌入维度中所占的比例。两者拼接得到联合嵌入
。
这个设计有一个优雅的性质:当 时,模型退化为纯自回归模式(只看目标变量历史);当
时,仅依赖外生变量。在强季节性任务(如ELEC用电量预测)上,实验证明
是最优的——说明此时外生变量信息并不有用,Sonnet能自适应地识别这一点。
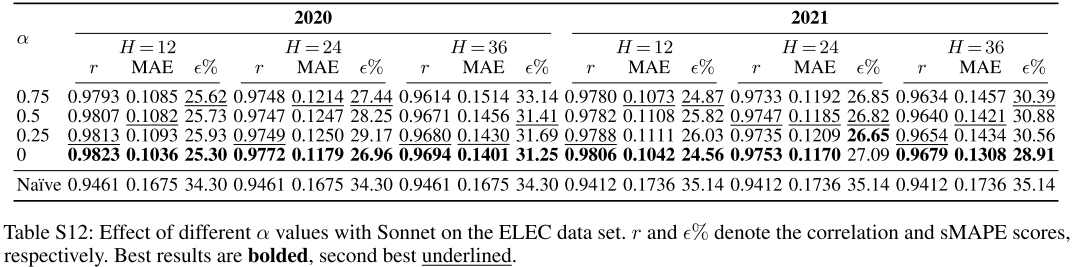
📌 Table S12(不同
值在ELEC任务上的消融结果),展示
在所有设置中最优。
3.2 可学习小波变换(Learnable Wavelet Transform)
小波变换的优势在于同时保留时域和频域信息,而Fourier变换只保留频率信息。Sonnet定义了 K 个可学习的小波原子,第 k 个原子为:
其中 均为可学习参数,分别控制高斯包络的宽度、线性和二次频率调制。这使得每个小波原子能够自适应地学习数据中的局部时频结构,而不像传统小波那样固定母小波形状。
对输入嵌入 E 与每个原子做逐元素乘法,得到 K 个投影 ,合并为
。这 K 个投影就是多分辨率的时频分解结果,分别对应不同的时频子空间。
3.3 多变量相干注意力(MVCA)—— 核心创新
这是Sonnet最重要的创新模块。MVCA用谱相干性(spectral coherence)代替传统的点积相似度,来衡量两个时间步之间变量的关联程度。
具体计算流程:
- 对小波域表示 P 做线性投影,得到Query、Key、Value:
。
- 对每个注意力头(对应一个小波原子),沿变量维度做FFT:
- 计算互功率谱密度和自功率谱密度:
- 计算归一化谱相干性(沿频率维度平均后取模):
- 经缩放、Softmax、Dropout后得到注意力权重
,与Value做逐元素乘法,最后接残差MLP捕获非线性依赖。
为什么谱相干性比点积更好?
点积注意力衡量的是两个向量在时域上的内积相似度。而谱相干性衡量的是两个序列在多个频率上的线性依赖强度:若两个时间步在多个频带上都高度相关,则该时间步对注意力输出的贡献越大。这对于捕获变量间的跨频率耦合关系(如搜索词频率与流感发病率之间的周期性共振)具有天然优势。
MVCA是即插即用的模块,可以直接替换其他预测模型(如iTransformer、Samformer、PatchTST)中的朴素注意力机制,无需修改整体架构。
3.4 Koopman引导的谱演化(Koopman-Guided Spectrum Evolvement)
Koopman算子理论提供了一种将非线性动力系统线性化的框架。Sonnet在小波空间中学习一个Koopman算子 :
是通过QR分解得到的酉矩阵,保证
,防止数值放大;
是由可学习相位角
构成的对角矩阵,控制各小波通道的时频演化。
与传统Koopman框架逐时间步递归应用不同,Sonnet用一次前向传播直接从输入映射到输出,避免了误差的逐步积累,同时保证了训练的稳定性。
3.5 序列重建与卷积解码器
通过将演化后的状态与各小波原子做逐元素乘法再对 K 个原子求和,实现时频域到时域的逆变换,得到重建嵌入。
最后,一个3层1D卷积解码器(核尺寸依次为5、3、3,通道数依次为 4H, 2H, H)将重建表示映射到预测序列,再经线性投影输出最终的 。
四、实验设置
数据集
论文在12个真实世界数据集上评估,覆盖多个应用领域,共47个预测任务:
| 数据集类别 | 具体数据集 | 预测目标 | 外生变量数 | 测试期数 |
|---|---|---|---|---|
| 电力变压器温度 | ETTh1, ETTh2 | 油温 | 6 | 1 |
| 用电量 | ELEC(苏黎世) | 家庭用电量 | 8(天气) | 2年 |
| 能源价格 | ENER(西班牙) | 实时电价 | 19 | 1年 |
| 天气预报 | WEA-LD/NY/HK/CT/SG | 850hPa温度 | 44 | 3年 |
| 流感预测 | ILI-ENG/US2/US9 | ILI发病率 | 13~752(搜索词频率) | 4个流感季 |
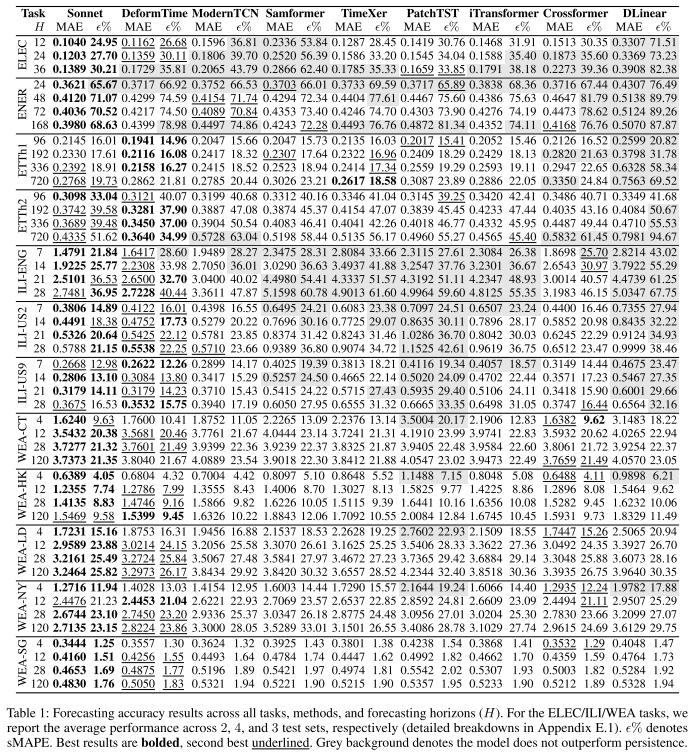
📌 Table 1 的整体概览(或直接使用Table 1的截图),展示12个数据集、9种方法、多个horizon的MAE和sMAPE结果全貌。
重点说明:WEA和ILI任务具有多个测试期、超过10年训练数据、以及大量外生变量,是评估MTS能力最具代表性的任务。ILI任务尤其困难——在H=21或28天的长期预测中,流感动态高度不规则,且强烈依赖网络搜索词外生变量。
基线方法
共对比8个当前SOTA基线,按是否捕获变量间依赖分为两类:
- 不捕获变量间依赖:DLinear、PatchTST
- 捕获变量间依赖:Crossformer、iTransformer、Samformer、TimeXer、ModernTCN、DeformTime(最强基线)
五、实验结果
5.1 整体预测性能
Sonnet在47个任务中34个取得最佳MAE,9个取得次佳。与最强基线DeformTime相比,MAE平均降低2.2%(p=5×10⁻⁴,统计显著)。
值得关注的是Sonnet表现较弱的地方:ETT任务。ETTh1和ETTh2只有6个外生变量、仅2年训练数据,Sonnet依赖的正是"丰富外生变量+充足训练历史",因此在此类任务上优势不突出。去除ETT任务后,Sonnet相对所有基线的MAE平均降低3.3%。
不同类别基线的MAE降幅对比(相对Sonnet):
| 基线类型 | 代表模型 | Sonnet降低MAE |
|---|---|---|
| 不捕获变量依赖 | DLinear | 31.1% |
| 不捕获变量依赖 | PatchTST | 29.8% |
| 嵌入沿时间维度 | Samformer | 23.9% |
| 嵌入沿时间维度 | iTransformer | 22.9% |
| 保留时序+捕获依赖 | Crossformer | 8% |
| 保留时序+捕获依赖 | ModernTCN | 11.1% |
| 保留时序+捕获依赖 | DeformTime(最强) | 3.4% |
这个结果揭示了一个清晰的规律:在MTS预测中,"保留时序结构"和"捕获变量间依赖"是相辅相成的两个关键要素,缺一不可。
在ILI和WEA任务上,Sonnet在32个子任务中分别有25或26个(依MAE/sMAPE)排名第一,MAE平均降低3.5%(ILI)和2%(WEA)。
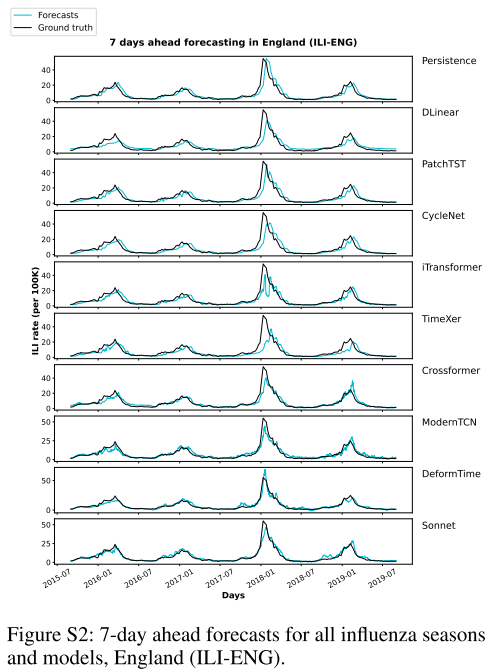
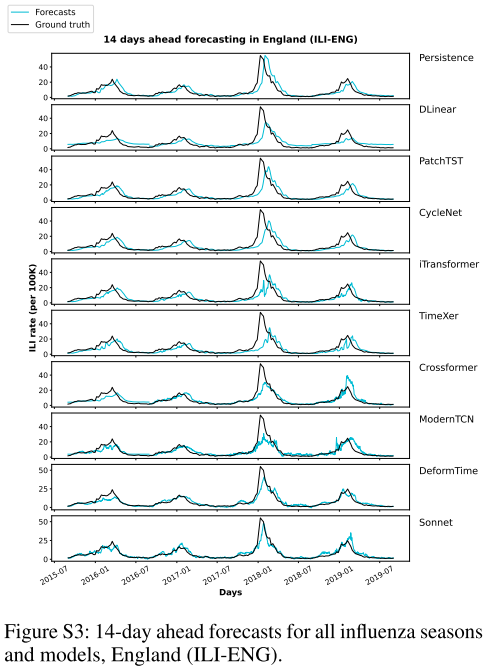
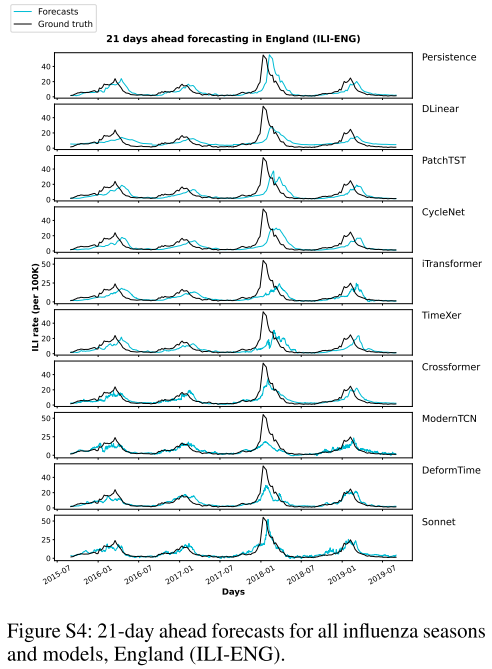
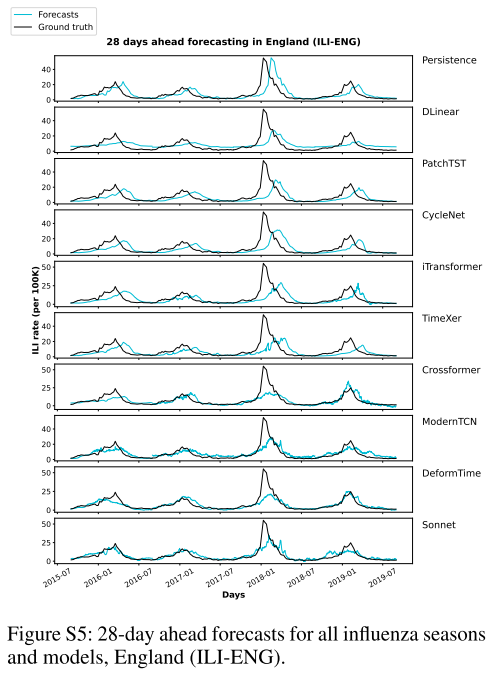
📌 Figure S2–S5(ILI-ENG各horizon的预测时序图),直观展示Sonnet预测曲线与真实值的拟合情况,以及与其他模型的对比。
5.2 预测性能随Horizon增长的变化
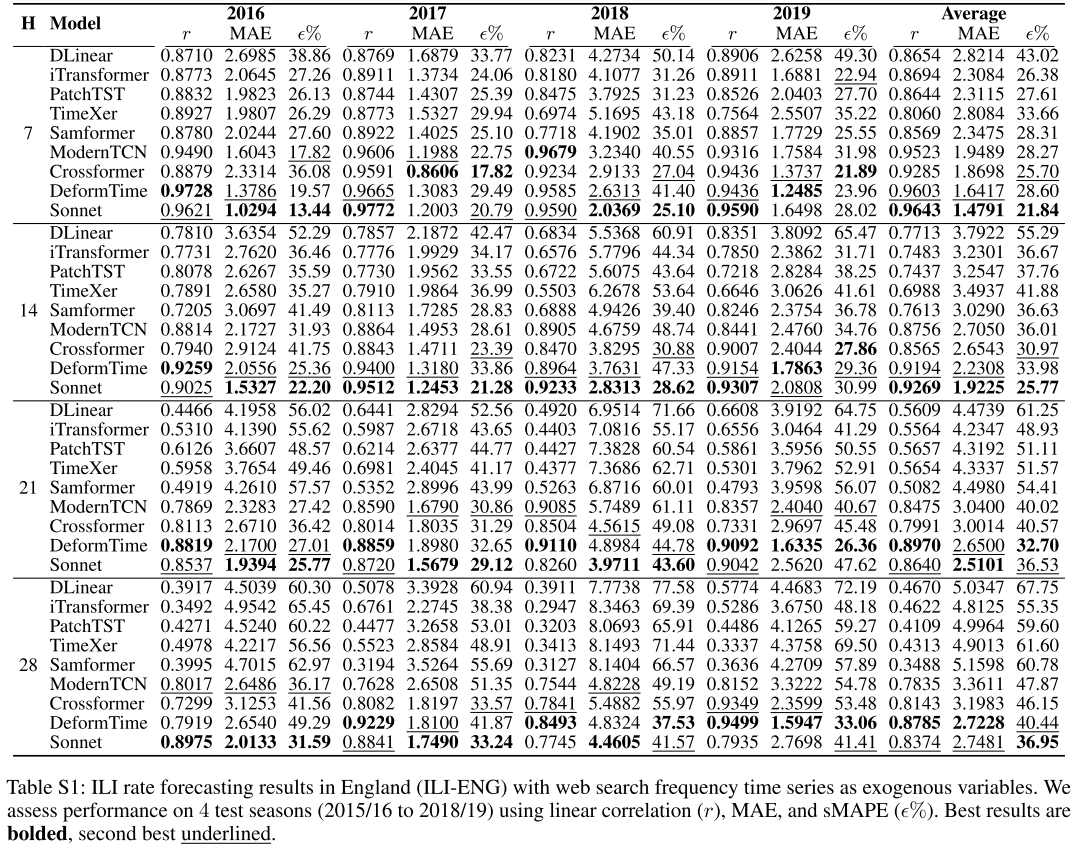
📌 Table S1(ILI-ENG各测试季、各horizon的详细结果),展示随H从7增至28天,Sonnet相对各基线的优势是否保持。
在ILI-ENG任务上,以H=7天为例,Sonnet的平均MAE为1.4791(r=0.9643),DeformTime为1.6417(r=0.9603);在H=28天,Sonnet为2.7481(r=0.8374),DeformTime为2.7228(r=0.8785)。可以看出,随预测horizon增加,各模型性能均有所下降,但Sonnet的优势在大多数任务上能持续保持。消融实验进一步证明,谱相干性对长期预测尤为重要:移除相干性建模后,ILI任务最长horizon(H=28天)的MAE上升幅度高达13.6%,远大于最短horizon(H=7天)时的2%。
5.3 MVCA作为即插即用注意力模块
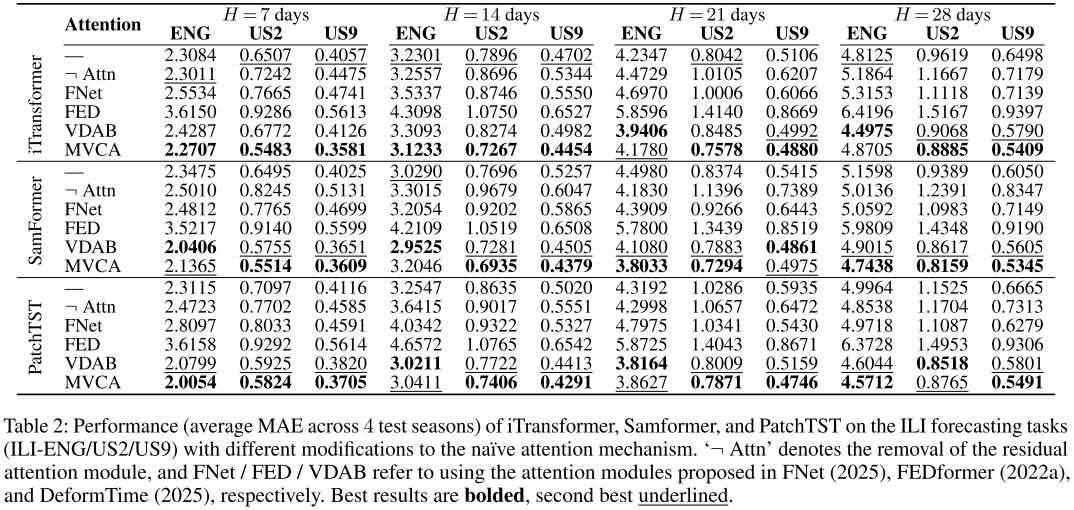
📌 Table 2(MVCA在三个基础模型上的对比结果),展示将朴素注意力替换为各种注意力变体后的MAE变化。
在iTransformer、Samformer、PatchTST三个基础模型上,分别测试了以下注意力配置:
- ¬ Attn:直接移除注意力模块
- FNet:无参数Fourier注意力
- FED(FEDformer):频率增强分解注意力
- VDAB(DeformTime):可变形变量注意力
- MVCA(Sonnet):多变量相干注意力
关键发现:
-
对于基础模型,移除注意力模块并不总是使性能下降(部分horizon甚至提升),说明朴素注意力未必总能捕获有用信息。
-
将朴素注意力替换为MVCA,在所有ILI任务上MAE平均降低10.7%,sMAPE平均降低9%。对PatchTST(不捕获变量间依赖)的提升最大,达15.1%。
-
FED注意力(FEDformer)表现最差:它只关注季节性频率分解,忽略变量间依赖,在MTS任务上收益甚微甚至有损。
-
MVCA相对次优方案VDAB,进一步将MAE降低3.5%,sMAPE降低3%,在US region上的优势尤为一致。
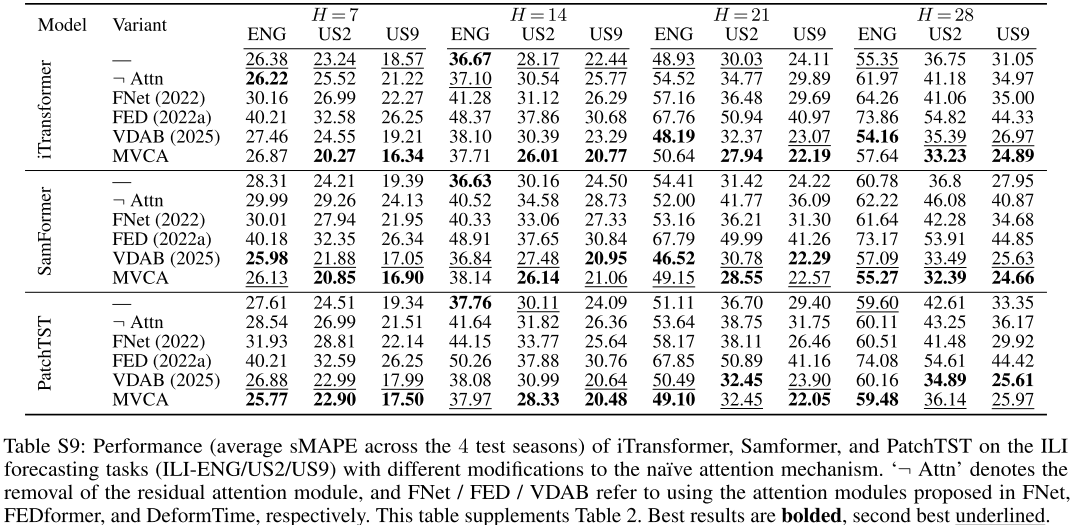
📌 Table S9(Table 2的sMAPE版本),与Table 2形成双指标佐证。
5.4 Sonnet内置不同注意力变体的对比

📌 Table 3(Sonnet内使用不同注意力模块时在ILI和WEA任务上的表现)。
在Sonnet框架内将MVCA替换为其他注意力模块:MVCA在32个任务中26个取得最佳MAE,平均优于其他变体2.9%(MAE)和2%(sMAPE)。最差的依然是FED:MVCA相对其MAE降低高达51.5%,再次说明在MTS任务中,仅靠季节性分解而不建模变量间依赖是远远不够的。
5.5 消融实验

📌 Table S10(消融研究结果),重点看 $\Delta%$ 列。
| 移除组件 | ILI+WEA平均MAE增幅 | 备注 |
|---|---|---|
| 整个MVCA | +6.3% | 影响最大 |
| 相干性建模(¬ Coher) | +5.2% | 长预测horizon时更重要 |
| MLP残差连接(¬ MLP) | +4.1% | |
| 联合嵌入(¬ Embed) | +4.0% | |
| Koopman算子(¬ Koop) | +3.2% |
MVCA是对整体性能影响最大的模块,而相干性建模和MLP残差连接作为其两个子组件,各自贡献了相当比例的性能提升,说明两者协同工作效果最佳。
六、计算效率分析
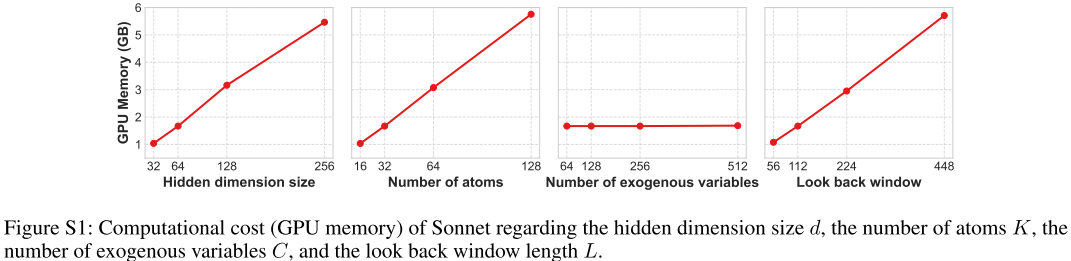
📌 Figure S1(GPU内存随各超参数变化的折线图)。
Sonnet的GPU内存消耗具有良好的扩展性:
- 随外生变量数 C 增加:内存保持不变(因为输入被映射到固定维度的嵌入空间)。这是相对于Crossformer和ModernTCN的重要优势——后者在变量数增加时内存显著上升。
- 随隐藏维度 d、原子数 K、回望窗口 L 增加:内存线性增长,行为可预测且可控。
七、随机性与鲁棒性
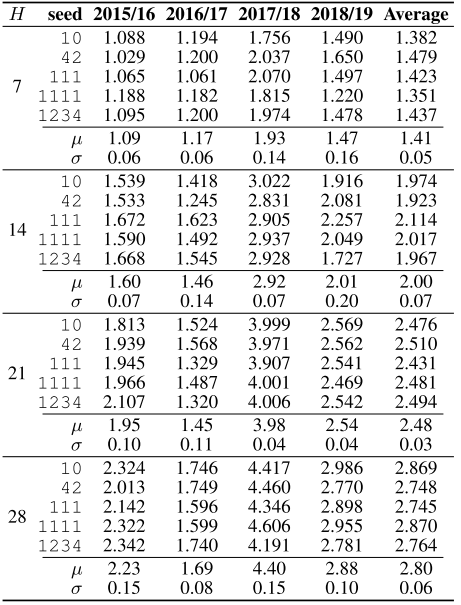
📌 Table S11(5个随机种子下的ILI-ENG MAE结果)。
在ILI-ENG数据集上,用5个不同随机种子(10、42、111、1111、1234)运行Sonnet,各预测horizon的平均MAE标准差均不超过0.07。这在实际单位下约等于每10万人口中7人的差异,表明模型结果高度稳定可靠,不依赖特定随机初始化。
八、局限性
论文作者坦诚地指出了三点局限:
-
缺乏理论证明:模型的有效性仅通过大规模实验验证,缺乏理论层面的保证。作者通过覆盖多领域、多测试期、超过十年训练历史的广泛实验来弥补这一不足。
-
MVCA的普适性尚待验证:目前的实验支持MVCA作为朴素注意力的直接替代,但在更广泛的任务类型上的表现有待进一步探索。
-
可解释性差:与大多数SOTA预测模型一样,Sonnet是一个黑箱模型,无法直接解释某次预测是由哪些外生变量的哪些时间步驱动的,只能通过元分析(meta-analysis)近似归因。
九、总结
Sonnet从三个维度推进了MTS预测的边界:
方法层面:首次将谱相干性(频域变量依赖度量)引入注意力机制,提出可学习小波变换在时频域建模,并用频域Koopman算子稳定预测时频动态。
模块层面:MVCA作为即插即用的注意力替换模块,能在不改变现有架构的前提下,大幅提升MTS预测的准确率(平均MAE降低10.7%)。
评估层面:构建了更具挑战性和代表性的MTS评估体系——包含流感预测、天气预报等多测试期、长训练历史、大量外生变量的任务——为未来MTS预测研究提供了更可靠的benchmark。
如果你正在做与MTS相关的预测任务,尤其是外生变量丰富、训练数据充足的场景(公共卫生、气象预报、能源预测等),Sonnet和MVCA都值得认真尝试。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)