Langgraph框架 持久性&Memory&Tool
持久性
检查点(Checkpointing)是 LangGraph 持久性的核心机制。它允许你在图执行过程中的任何点保存状态,并在需要时恢复。
核心概念
-
检查点(Checkpoint): 图状态的快照,它记录了工作流在某一时刻的完整状态(State),包括所有的变量、对话历史和执行进度
-
线程(Thread): 用于访问检查点的唯一标识
-
检查点保存器(Checkpointer): 负责保存和恢复状态的组件
线程Thread
线程是检查点保存器保存的每个检查点分配的唯一 ID 或线程标识符,可以理解为线程是一个带唯一 ID 的用来存历史状态、记忆、对话上下文的会话记录容器
当使用检查点调用图表时,必须指定thread_id作为configurable配置部分的一部分:
# 调用图时必须指定 thread_id
config = {"configurable": {"thread_id": "unique_thread_id"}}
result = graph.invoke(input_data, config=config)这样的作用是告诉 LangGraph 的 Checkpointer(检查点保存器)去加载或创建一个特定的会话历史
如果是新thread_id:开启一个全新的、记忆为空白的会话;如果是旧的thread_id:加载该会话的最后一次 Checkpoint,AI 就能“记住”之前聊过的所有内容。
特点
-
每个线程代表一个独立的对话或执行上下文
-
线程允许在图执行后访问图的状态
-
支持多个并发线程
from langchain.chat_models import init_chat_model
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.graph import StateGraph, MessagesState, START, END
import os
from dotenv import load_dotenv
load_dotenv()
class MyState(MessagesState):
result: str
llm = init_chat_model(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model_provider="openai",
model='MiniMax-M2.1')
async def process_message(state: MessagesState):
response = await llm.ainvoke(state["messages"])
return {"messages": response}
async def optimize_message(state: MessagesState):
messages = state["messages"] + [{"role": "system", "content": "请用幽默的形式回复用户"}]
response = await llm.ainvoke(messages)
return {"messages": response}
builder = StateGraph(state_schema=MyState)
builder.add_node("process_message", process_message)
builder.add_node("optimize_message", optimize_message)
builder.add_edge(START, "process_message")
builder.add_edge("process_message", "optimize_message")
builder.add_edge("optimize_message", END)
# 没有使用持久性
# graph = builder.compile()
# input_message = {"role": "user", "content": "你好呀!我的名字叫jran"}
# result = graph.invoke({"messages": [input_message]})
# result["messages"][-1].pretty_print()
#
# input_message = {"role": "user", "content": "我的名字叫什么?"}
# result = graph.invoke({"messages": [input_message]})
# result["messages"][-1].pretty_print()
async def main():
# 创建内存检查点进行持久化存储
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "user_123"}}
input_message = {"role": "user", "content": "你好呀!我的名字叫jran"}
result = await graph.ainvoke({"messages": [input_message]}, config)
result["messages"][-1].pretty_print()
input_message = {"role": "user", "content": "我的名字叫什么?"}
result = await graph.ainvoke({"messages": [input_message]}, config)
result["messages"][-1].pretty_print()
if __name__ == '__main__':
import asyncio
asyncio.run(main())
graph = builder.compile(checkpointer=InMemorySaver())表明checkpointer是一个巨大的会话仓库,它里面存储着所有thread_id的所有checkpoint
config是一个标识符,目的是根据里面的thread_id找到对应的checkpoint
每次调用这样的代码:graph.invoke(input, config),系统就会根据thread_id找到所有的checkpoint并加载最新的checkpoint,运行完过后把现在的对话记录成新的checkpoint放在checkpointer里面,也就是checkpoint随对话轮次数增加而增加
检查点checkpoint
检查点是在每个超级步骤中保存的图状态的快照,由StateSnapshot具有以下关键属性的对象表示:
-
config:与此检查点相关的配置。
-
metadata:与此检查点相关的元数据。
-
values:当前State的值。也就是图执行到目前为止,所有变量的状态值(如
"messages","steps","results"等字段的值)。 -
next:图中接下来要执行的节点名称的元组。
-
tasks:包含具体要执行的任务的详细信息,用PregeTask类型表示。比next更详细
checkpoint的作用
| 功能 | 描述 |
| 🌟 容错恢复 | 如果执行中断(如容器崩溃、任务超时),可以从上次保存的状态恢复,不用重跑整个流程 |
| 💾 状态追踪/审计 | 可以记录每一步节点执行时的中间状态,方便 Debug、回溯和监控 |
| 🔁 实现有状态的异步/长流程图 | 对于多轮对话、多阶段任务,检查点使 LangGraph 支持状态持久化和任务跟踪 |
本质上来讲,checkpoint就是把某个节点运行完后的State存储起来(数据库或者磁盘),如果出现中断,加载这个State从后续节点开始运行。
更新state
graph.update_state()方法可以让我们在不经过节点的条件下更新state里的值
更新对应状态,就是手动修改线程里的状态数据。它不会删除历史,只会生成新的检查点。你可以改消息、改工具结果、加用户信息、删内容、覆盖内容。更新完之后,下一次 run 就从新状态继续执行。这是实现人工介入、调试、纠错的核心功能
graph.update_state()依赖于cheakpoint机制,因此图在编译时必须传入checkpointer;本质上graph.update_state()就是创建一个新的checkpoint
方法参数
config
-
必须包含thread_id指定要更新的线程
-
可选包含checkpoint_id来分叉选定的检查点
values
-
用于更新状态的值
-
更新会传递给 reducer 函数(如果定义了)
-
没有 reducer 的通道会被覆盖
as_node
-
可选参数,指定更新来自哪个节点
-
影响下一步执行的节点
记忆存储
store接口
如果说chekpoint是“短期记忆”(InMemorysaver),即在同一个thread_id下面保存上下文,那么store就是“长期记忆”(InMemoryStore),记录用户的身份、偏好等等
-
检查点保存器单独无法跨线程共享信息
-
Store 接口解决了这个问题
-
可以在所有聊天对话中保留用户特定信息
用法
每种内存类型都是一个具有特定属性的 Python 类(Item)。我们可以通过上述转换将其作为字典访问dict。它具有以下属性:
-
value:此内存的值(本身就是一个字典)
-
key:此命名空间中此内存的唯一键(随便起名字)
-
namespace:字符串列表,此内存类型的命名空间(随便起名字)
-
created_at:此内存创建的时间戳
-
updated_at:此内存更新的时间戳
核心操作
-
存储数据:store.put(namespace, key, value)
-
读取数据:store.get(namespace, key)
-
搜索数据:store.search(namespace, query)
-
删除数据:store.delete(namespace, key)
from typing import Annotated, List
from typing_extensions import TypedDict
from operator import add
import uuid
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.memory import InMemoryStore
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
from langchain_core.runnables import RunnableConfig
from langgraph.store.base import BaseStore
from langchain.chat_models import init_chat_model
import os
from dotenv import load_dotenv
load_dotenv()
# 初始化大模型
llm = init_chat_model(api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model_provider="openai",
model='qwen-plus-2025-01-25')
# 定义状态结构
class MessagesState(TypedDict):
messages: Annotated[List[BaseMessage], add]
# 创建检查点保存器和内存存储
checkpointer = InMemorySaver()
in_memory_store = InMemoryStore()
# 聊天机器人节点 *代表后面的参数必须使用显示写出参数名称 store=in_memory_store
def chatbot(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
"""主聊天机器人节点,处理用户消息并生成回复"""
# 获取用户ID和最新消息
user_id = config["configurable"]["user_id"]
last_message = state["messages"][-1]
# 定义内存命名空间
namespace = (user_id, "memories")
# 简单的聊天逻辑
user_input = last_message.content.lower()
# 将聊天历史获取并组装提示词
memories = store.search(namespace)
memory_text = "\n".join(m.value["memory"] for m in memories)
prompt = f"请参考聊天记录:{memory_text}\n\nHuman: {user_input}\nAI:"
response = llm.invoke(prompt).content
# 存储对应的问题和答案
memory = f"问题:{user_input} --- 答案:{response}"
memory_id = str(uuid.uuid4())
store.put(namespace, memory_id, {"memory": memory})
# 返回AI消息
return {"messages": [AIMessage(content=response)]}
# 创建图
def create_persistent_graph():
"""创建持久化的聊天机器人图"""
# 创建状态图
workflow = StateGraph(MessagesState)
# 添加节点
workflow.add_node("chatbot", chatbot)
# 添加边
workflow.add_edge(START, "chatbot")
workflow.add_edge("chatbot", END)
# 编译图,使用检查点保存器和存储
graph = workflow.compile(checkpointer=checkpointer, store=in_memory_store)
return graph
# 工具函数:显示状态历史
def show_state_history(graph, config):
"""显示状态历史"""
print("\n=== 状态历史 ===")
history = graph.get_state_history(config)
for i, snapshot in enumerate(history):
print(f"\n步骤 {i}:")
print(f" 配置: {snapshot.config}")
print(f" 值: {snapshot.values}")
print(f" 下一步: {snapshot.next}")
print(f" 元数据: {snapshot.metadata}")
# 工具函数:显示存储的记忆
def show_memories(store, user_id):
"""显示用户的所有记忆"""
print(f"\n=== 用户 {user_id} 的记忆 ===")
namespace = (user_id, "memories")
memories = store.search(namespace)
if memories:
for memory in memories:
print(f"记忆ID: {memory.key}")
print(f"内容: {memory.value}")
print(f"创建时间: {memory.created_at}")
print(f"更新时间: {memory.updated_at}")
print("---")
else:
print("没有找到记忆")
# 主程序
def main():
# 创建图
graph = create_persistent_graph()
# 用户配置
user_id = "user_123"
thread_id = "conversation_1"
config = {
"configurable": {
"thread_id": thread_id,
"user_id": user_id
}
}
print("=== LangGraph 持久化聊天机器人 ===")
print("输入 'quit' 退出,'history' 查看状态历史,'memories' 查看记忆")
while True:
user_input = input("\n用户: ").strip()
if user_input.lower() == 'quit':
break
elif user_input.lower() == 'history':
show_state_history(graph, config)
continue
elif user_input.lower() == 'memories':
show_memories(in_memory_store, user_id)
continue
# 创建用户消息
initial_state = {
"messages": [HumanMessage(content=user_input)]
}
# 运行图
try:
result = graph.invoke(initial_state, config)
# 显示AI回复
ai_message = result["messages"][-1]
print(f"AI: {ai_message.content}")
except Exception as e:
print(f"错误: {e}")
print("\n=== 最终状态 ===")
final_state = graph.get_state(config)
print(f"最终状态: {final_state.values}")
print("\n=== 所有记忆 ===")
show_memories(in_memory_store, user_id)
# 演示不同线程间的记忆共享
def demo_cross_thread_memory():
"""演示跨线程记忆共享"""
print("\n=== 跨线程记忆共享演示 ===")
graph = create_persistent_graph()
user_id = "user_456"
# 第一个对话线程
config1 = {
"configurable": {
"thread_id": "thread_1",
"user_id": user_id
}
}
print("线程1 - 建立记忆:")
result1 = graph.invoke({
"messages": [HumanMessage(content="我叫jran,我喜欢音乐")]
}, config1)
print(f"AI: {result1['messages'][-1].content}")
# 第二个对话线程(相同用户)
config2 = {
"configurable": {
"thread_id": "thread_2",
"user_id": user_id
}
}
print("\n线程2 - 访问记忆:")
result2 = graph.invoke({
"messages": [HumanMessage(content="你还记得我吗?")]
}, config2)
print(f"AI: {result2['messages'][-1].content}")
# 显示共享的记忆
show_memories(in_memory_store, user_id)
if __name__ == "__main__":
# 运行主程序
main()
# 演示跨线程记忆共享
demo_cross_thread_memory()注意:命名空间必须是元组tuple,因为元组是不可改变的。
namespace = ("users", "user_123", "preferences")
namespace = ("global",)这两种都是对的
Memory记忆
记忆对agent来说至关重要,短期记忆可以让模型记住与用户的交互记录,使模型可以从反馈中学习与完善;长期记忆可以使模型记住用户的相关信息,为用户提供针对性的解答方案
-
短期记忆(或线程范围的记忆)通过维护会话中的消息历史记录来跟踪正在进行的对话。LangGraph 将短期记忆作为代理状态的一部分进行管理。状态使用检查点持久化到数据库中,以便线程可以随时恢复。短期记忆会在图被调用或某个步骤完成时更新,并且在每个步骤开始时读取状态。
-
长期记忆跨会话存储用户特定或应用程序级别的数据,并在对话线程之间共享。它可以在任何时间、任何线程中调用。记忆的作用域是任何自定义命名空间,而不仅仅是单个线程 ID。LangGraph 提供存储,方便您保存和调用长期记忆。
通常在生产中,短期记忆用redis + 长期记忆用postgres
管理短期记忆
启用短期记忆后,长对话可能会超出 LLM 的上下文窗口。常见的解决方案如下:
-
修剪消息:删除前 N 条或后 N 条消息(在调用 LLM 之前)
-
从 LangGraph 状态中永久删除消息
-
总结消息:总结历史记录中较早的消息,并用摘要替换它们
-
管理检查点以存储和检索消息历史记录
-
自定义策略(例如,消息过滤等)
修剪消息
大多数 LLM 都有一个最大支持的上下文窗口(以 token 为单位)。决定何时截断消息的一种方法是计算消息历史记录中的 token 数量,并在接近该限制时进行截断。
trim_messages()是 LangChain/LangGraph 提供的一个消息裁剪工具函数,专门用于在将对话历史发送给大模型之前,智能地删减掉一部分内容,以确保消息总长度不超过模型的上下文窗口限制
-
max_tokens:目标最大token数
-
strategy:保留哪部分信息;“last”表示保留最近的对话
-
token_counter:用于计数的函数或模型,用来计算token数量
-
start_on:保留的内容必须从这类消息开始;“human”表示从用户消息开始保留
-
end_on:选择从哪一类消息结束
-
include_system:保证系统提示词(prompt)不被删掉
def call_llm(state: MessagesState):
messages = trim_messages(
state["messages"],
strategy="last", # 修剪策略(last从末尾,first从开头, middle从中间)
token_counter=count_tokens_approximately, # 用来估算token数量
max_tokens=100, # 修剪后的消息总 token 不超过 200
start_on="human", # 控制从哪一类消息开始截取(从最后一个 human 消息开始往前保留)
end_on=("human", "ai"), # 允许哪些角色作为修剪终点
)
print("修剪后的消息:", messages)
response = llm.invoke(messages)
return {"messages": [response]}
checkpointer = InMemorySaver()
builder = StateGraph(MessagesState)
builder.add_node(call_llm)
builder.add_edge(START, "call_llm")
graph = builder.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
graph.invoke({"messages": "我的名字叫jran"}, config)
graph.invoke({"messages": "帮我家的猫写一首诗"}, config)
graph.invoke({"messages": "现在对狗做一样的事情"}, config)
final_response = graph.invoke({"messages": "我的名字叫什么?"}, config)
print("最终消息:")
print(final_response["messages"])删除消息
trim_message()是“临时裁剪”,让传给llm的文本数量变少了,但消息本身还在;而Remove_message()是“永久删除”,根据thread_id从state[message]里面删除多条消息。
from langchain_core.messages import RemoveMessage
from langgraph.graph import MessagesState
def delete_old_messages(state: MessagesState):
messages = state["messages"]
# 删掉最早的 2 条
to_remove = [RemoveMessage(id=m.id) for m in messages[:2]]
return {"messages": to_remove}总结消息
修剪或删除消息的问题在于,可能会因剔除消息队列而丢失信息。因此,一些应用程序受益于一种更复杂的方法,即使用聊天模型来汇总消息历史记录。
SummarizationNode是 LangGraph 提供的一个预置节点,专门用于在对话过长时自动将历史消息压缩为摘要,从而解决 LLM 上下文窗口超限的问题
SummarizationNode虽然不是一个函数,但是它是一个可调用对象;这个类中实现了__call__方法让它可以向函数一样被调用。
下载模块
pip install langmem使用方法
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph.prebuilt.chat_agent_executor import AgentState
from langmem.short_term import SummarizationNode
from langchain_core.messages.utils import count_tokens_approximately
# 1. 模型
model = ChatOpenAI(model="gpt-4o")
summarization_model = model.bind(max_tokens=128) # 摘要用小输出
# 2. 摘要节点(核心)
summarization_node = SummarizationNode(
token_counter=count_tokens_approximately,
model=summarization_model,
max_tokens=384, # 给主模型的总token上限
max_summary_tokens=128,# 摘要本身最大长度
output_messages_key="llm_input_messages"
)
# 3. 扩展状态(存摘要)
class State(AgentState):
context: dict
# 4. 集成到 Agent(pre_model_hook 自动触发)
agent = create_react_agent(
model=model,
tools=[],
state_schema=State,
pre_model_hook=summarization_node # 每次调用LLM前执行摘要
)这里summarization_model是需要为摘要专门创建一个模型。
-
max_tokens:在进入摘要模型之前:已有的摘要+用户问题<=384
-
max_tokens_before_summary:当前对话[AI, Human, tools, AI, Human, tools]tokens长度大于50就触发摘要
-
max_summary_tokens:摘要的长度 128 tokens
-
摘要 + 用户的问题 -> llm摘要 # 摘要 + 用户的问题在重新进行摘要不能超过384token,超过的会被舍弃掉
还有两个很重要的参数initial_summary_prompt和existing_summary_prompt
initial_summary_prompt是第一次生成摘要时的提示词模板
existing_summary_prompt是后续更新摘要时的提示词模板,在后续更新摘要时,应该在prompt里写明把旧的摘要和新的信息结合形成一个新的摘要
工具Tool
工具封装了可调用函数及其输入模式。这些可以传递给兼容的聊天模型,让模型决定是否调用工具以及使用哪些参数。
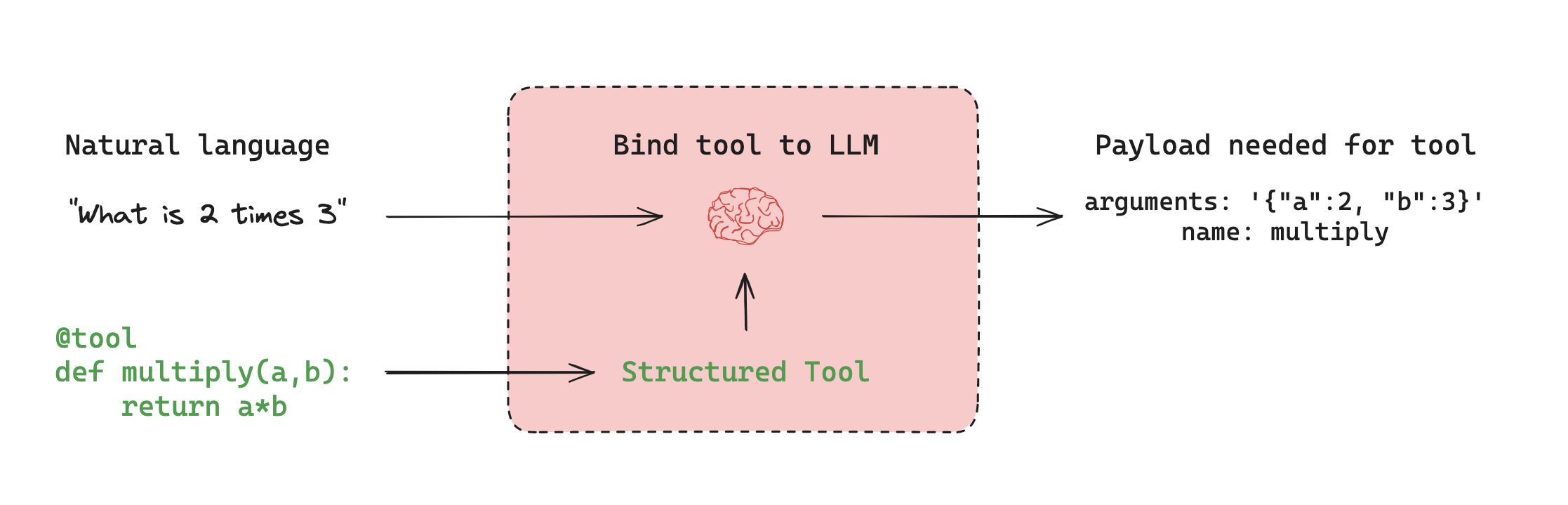
LangChain 为常见的外部系统(包括 API、数据库、文件系统和 Web 数据)提供预构建的工具集成。
浏览集成目录以查找可用的工具。
常见类别:
-
搜索:Bing、SerpAPI、Tavily
-
代码执行:Python REPL、Node.js REPL
-
数据库:SQL、MongoDB、Redis
-
Web 数据:抓取和浏览
-
API:OpenWeatherMap、NewsAPI等
from langchain.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""将两个数目相乘."""
return a * b
# 运行工具
print(multiply.invoke({"a": 6, "b": 7})) # returns 42
tool_call = {
"type": "tool_call",
"id": "1",
"args": {"a": 42, "b": 7}
}
print(multiply.invoke(tool_call))
print("=" * 8, "在工作流中使用", "=" * 8)
from langgraph.prebuilt import ToolNode
from langgraph.graph import StateGraph, MessagesState, START, END
from langchain_tavily import TavilySearch
@tool
def tavily_search_tool(query: str) -> str:
"""这是一个搜索工具"""
tool_instance = TavilySearch()
return tool_instance.run(query)
# 执行工具的节点
tool_node = ToolNode([tavily_search_tool])
# 绑定工具到模型
model_with_tools = llm.bind_tools([tavily_search_tool])
def should_continue(state: MessagesState):
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return END
def call_model(state: MessagesState):
messages = state["messages"]
response = model_with_tools.invoke(messages)
return {"messages": [response]}
builder = StateGraph(MessagesState)
# 定义节点和边
builder.add_node("call_model", call_model)
builder.add_node("tools", tool_node)
builder.add_edge(START, "call_model") # 模型因为绑定了工具,决定是否要使用工具,返回:tool message
builder.add_conditional_edges("call_model", should_continue, ["tools", END])
builder.add_edge("tools", "call_model")
graph = builder.compile()
print(graph.invoke({"messages": [{"role": "user", "content": "上海的天气?"}]}))TavilySearch()是Python SDK 中一个专门用于联网搜索的工具,调用该tool后,它会帮你给Tavily Search API发送HTTP请求并返回搜索结果,类似于Web RAG
上下文管理
LangGraph 中的工具有时需要上下文数据,例如仅在运行时使用的参数(例如,用户 ID 或会话详细信息、状态等),这些数据不应由模型控制。LangGraph 提供了三种方法来管理此类上下文:
| 类型 | 使用场景 | 可变的 | 寿命 |
| 配置 | 静态、不可变的运行时数据 | ❌ | 单次调用 |
| 短期记忆 | 调用期间动态变化的数据 | ✅ | 单次调用 |
| 长期记忆 | 持久的跨会话数据 | ✅ | 跨多个会话 |
短期记忆
短期记忆保持在单次执行期间发生变化的动态状态
一般的工具函数接收的是用户的输入Query;ToolRuntime是 LangChain/LangGraph 专门给「工具函数」用的运行时对象,ToolRuntime负责把所有的上下文、状态、用户信息、调用工具id等全部传入给函数
# 1. 定义状态 (State)
class CustomState(MessagesState):
user_name: str
# 2. 定义工具
@tool
def get_user_name(runtime: ToolRuntime) -> str:
"""从状态中检索当前用户名。"""
# 在 LangGraph 中,可以通过 InjectedState 注入整个状态
return runtime.state.get("user_name", "未知用户")
@tool
def update_user_name(new_name: str, runtime: ToolRuntime) -> Command:
"""更新短期记忆中的用户名。"""
print(f"--- 触发更新用户名工具: {new_name} ---")
# Command 会在工具执行完后直接作用于 Graph 的 State
return Command(
update={
"user_name": new_name,
"messages": [
ToolMessage(
content=f"姓名已经更改成: {new_name}.",
tool_call_id=runtime.tool_call_id,
)
],
}
)
tools = [get_user_name, update_user_name]
llm_with_tools = llm.bind_tools(tools)
# 3. 定义节点函数
def call_model(state: CustomState):
"""模型决策节点"""
response = llm_with_tools.invoke(state["messages"])
return {"messages": [response]}
# 4. 构建图 (Workflow)
workflow = StateGraph(CustomState)
# 添加处理节点
workflow.add_node("agent", call_model)
workflow.add_node("tools", ToolNode(tools))
# 设置连线
workflow.add_edge(START, "agent")
# 动态决定:是去执行工具还是直接结束
workflow.add_conditional_edges(
"agent",
tools_condition, # 内置函数:判断消息中是否有 tool_calls
{"tools": "tools", "__end__": END},
)
# 工具执行完后回到 agent,让模型根据工具结果说话
workflow.add_edge("tools", "agent")
# 5. 编译并运行
checkpointer = InMemorySaver()
app = workflow.compile(checkpointer=checkpointer)
# --- 测试运行 ---
config = {"configurable": {"thread_id": "1"}}
print("\n--- 第一次对话 ---")
input_1 = {"messages": [{"role": "user", "content": "我的名字是jran"}]}
for event in app.stream(input_1, config, stream_mode="values"):
event["messages"][-1].pretty_print()
print("\n--- 查看当前 State 中的 user_name ---")
print(f"State Name: {app.get_state(config).values.get('user_name')}")
print("\n--- 第二次对话 ---")
input_2 = {"messages": [{"role": "user", "content": "我的名字是什么?"}]}
for event in app.stream(input_2, config, stream_mode="values"):
event["messages"][-1].pretty_print()长期记忆
使用长期记忆来存储对话中特定于用户或应用程序的数据。这对于像聊天机器人这样的应用程序非常有用。
要使用长期记忆,需要:
-
配置存储以在调用之间保留数据。
-
使用该ToolRuntime功能从工具或提示中访问store。
class UserInfo(TypedDict):
name: str
language: str
@tool
def update_user_info(user_info: UserInfo, runtime: ToolRuntime) -> str:
"""更新用户信息"""
print("工具被调用,接收到的 user_info:", user_info)
user_id = runtime.config.get("configurable").get("user_id")
runtime.store.put(("users",), user_id, user_info)
return "用户信息更新成功"
@tool
def get_user_info(runtime: ToolRuntime) -> str:
"""查找用户信息."""
user_id = runtime.config.get("configurable").get("user_id")
user_info = runtime.store.get(("users",), user_id)
return str(user_info.value) if user_info else "Unknown user"
tools = [update_user_info, get_user_info]
llm_with_tools = llm.bind_tools(tools)
# 4. 定义节点
def call_model(state: MessagesState):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 5. 构建图
workflow = StateGraph(MessagesState)
workflow.add_node("agent", call_model)
workflow.add_node("tools", ToolNode(tools)) # ToolNode 会自动处理 store 的传递
workflow.add_edge(START, "agent")
workflow.add_conditional_edges("agent", tools_condition)
workflow.add_edge("tools", "agent")
# 6. 初始化存储与持久化器
# 创建内存存储对象
store = InMemoryStore()
# 创建内存持久化器
checkpointer = InMemorySaver()
# 存储初始化用户信息
store.put(
("users",),
"user_123",
{
"name": "jran",
"language": "中文",
}
)
# 预存初始数据
store.put(("users",), "user_123", {"name": "jran", "language": "中文"})
# 编译图 (关键:传入 store)
app = workflow.compile(checkpointer=checkpointer, store=store)
# --- 模拟运行 ---
config = {"configurable": {"thread_id": "thread_1", "user_id": "user_123"}}
print("\n=== 任务 1: 查询初始信息 ===")
for event in app.stream({"messages": [{"role": "user", "content": "查询用户信息"}]}, config, stream_mode="values"):
event["messages"][-1].pretty_print()
print("\n=== 任务 2: 更新信息 ===")
# 模拟用户说:我的名字叫李铭,使用的语言是西班牙语
for event in app.stream({"messages": [{"role": "user", "content": "我的名字叫李铭,使用的语言是西班牙语"}]}, config,
stream_mode="values"):
event["messages"][-1].pretty_print()
print("\n=== 任务 3: 再次查询 (验证长期记忆) ===")
for event in app.stream({"messages": [{"role": "user", "content": "我现在的名字和语言是什么?"}]}, config,
stream_mode="values"):
event["messages"][-1].pretty_print()
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 27
27 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)