Linux 基础(三):常用的文件操作指令
上一篇我们围绕 Linux 的目录操作展开,介绍了 pwd、ls、cd、mkdir、touch、rmdir、rm、cp、mv 等指令,按照“指令名称、指令原意、指令功能、语法格式、执行权限”五要素逐一拆解,掌握了目录的创建、切换、罗列、删除、移动与重命名。
本篇将把视角从目录转向普通文件,聚焦文件内容的查看、写入、搜索,以及文件的定位。涵盖 cat、more、less、head、tail、echo、grep、find、locate、which 等指令,同样沿用五要素的讲解规范,并结合实际场景对比不同指令的优缺点。
一、目录与文件
1.1 目录的本质
Linux 中的目录就是我们熟悉的 Windows 里的文件夹,用来组织和管理系统中的各种资源
但是我们在理解目录/文件夹的过程中往往存在着一个认知失误:将文件存放在目录中的过程理解为类似于物理上的”装进去,事实上目录/文件夹的工作原理并不是这样的。
目录里存的其实是一张由 “目录项 (directory entry)” 组成的表。每个目录项都记录着一个文件名和它对应的 inode号
inode,全称Index Node(索引节点),可以理解为系统给每个文件分配的“唯一工号”,它包含着文件的大小、权限、所有者、时间戳以及数据在磁盘上的位置,唯独不存文件名。
当你查看某个文件时,系统实际上完成了两步的工作:第一步是在目录这张登记表里检索匹配的文件名,拿到对应的 inode 号;第二步则是用这个 inode 号去磁盘上获取此文件的属性信息和数据存放位置,最后把内容读出来。
所以把文件“放入”目录,并不是物理上把它装了进去,而是在目录这张登记表上添了一行记录。移动文件也同样,只是在不同目录的登记表之间做删改,文件数据本身并没有被搬动。
1.2 目录与文件的关系
Linux 系统最大的特点在于“一切皆文件”,目录当然也不例外。可以把目录理解为一种特殊的文件。
只不过它和普通文件存储的内容不同:普通文件直接存储用户写入的数据,比如文字、代码或二进制内容;而目录文件存储的是目录项,也就是“文件名 → inode 号”的映射关系,并不直接存放用户数据。
1.3 文件的定义于操作概览
文件的定义:文件时存储在外存储器上的数据的集合(本质就是数据的集合)
文件的操作:
下文将从这五类操作切入,分别介绍各自常用的指令与用法。
二、读取文件
1)cat
示例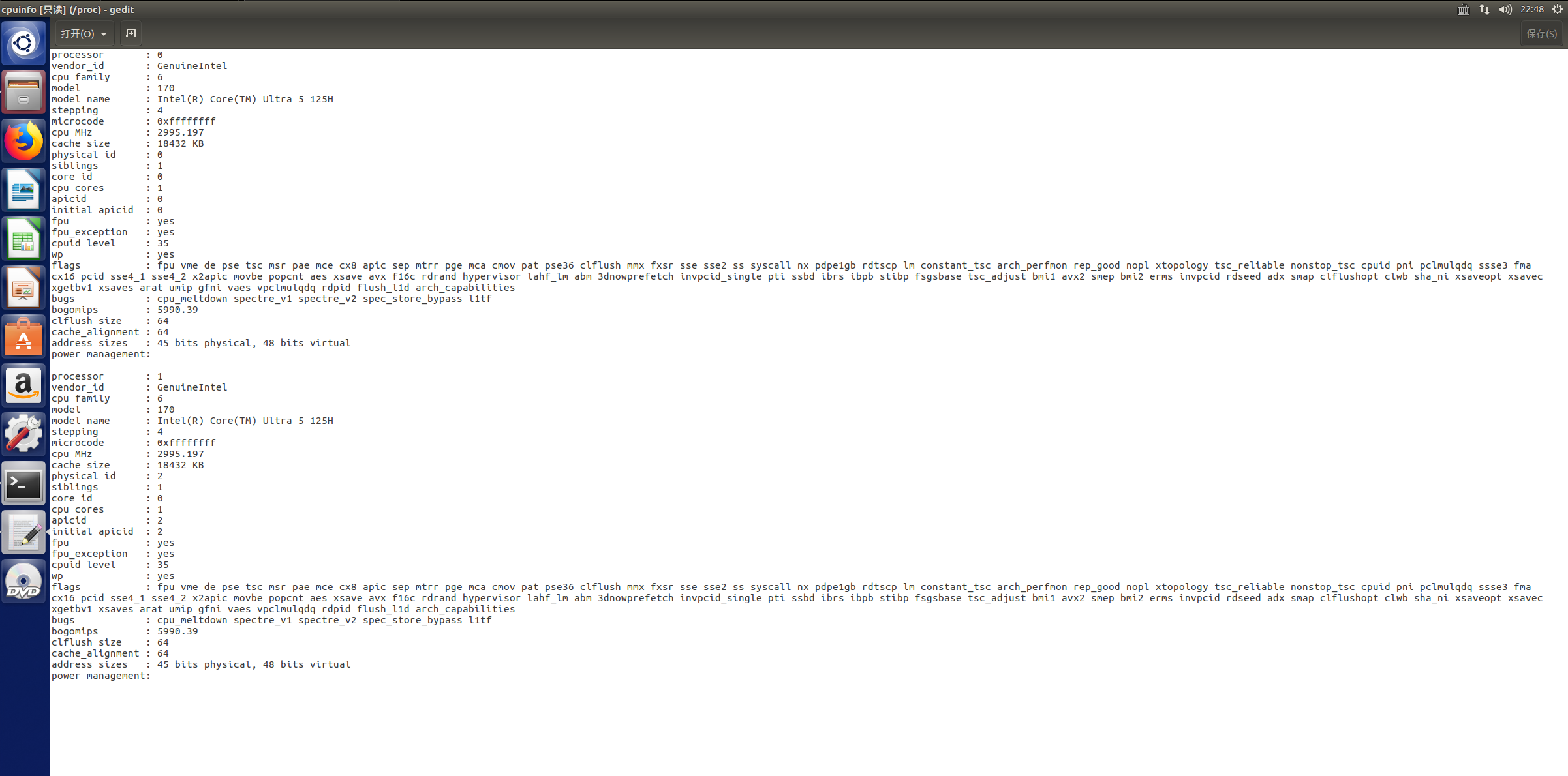
借助图形化界面可以看到/proc/couinfo文件打开后的内容如图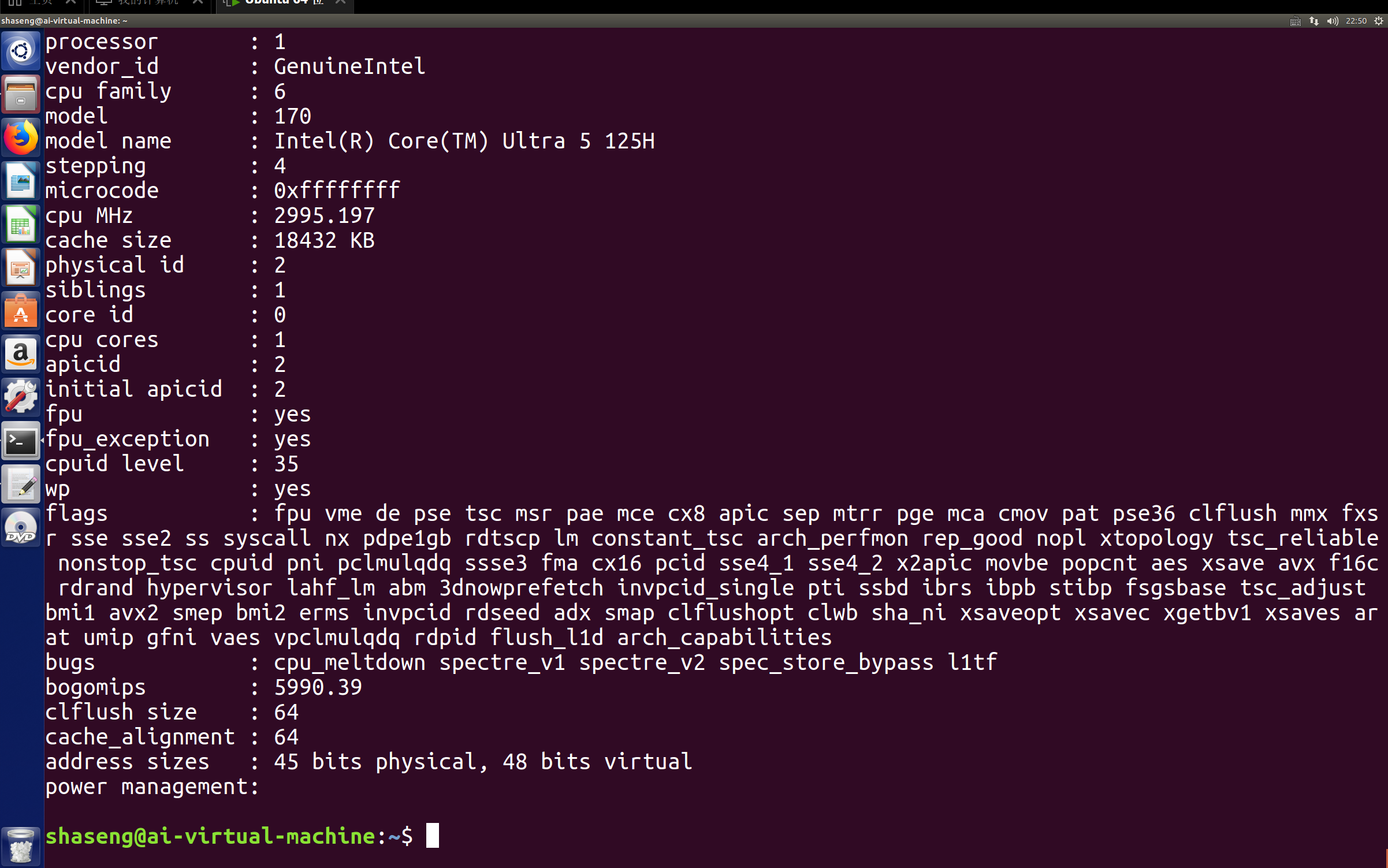
上图为使用’cat /proc/cpuinfo指令读取文件内容的界面,可以发现显示内容多少取决于页面字体大小,字体较大的情况可能只显示下半部分,在文件内容跟较多的情况下不容易分辨是否显示完全
上图为加入选项-n使用cat指令读取cpuinfo文件的内容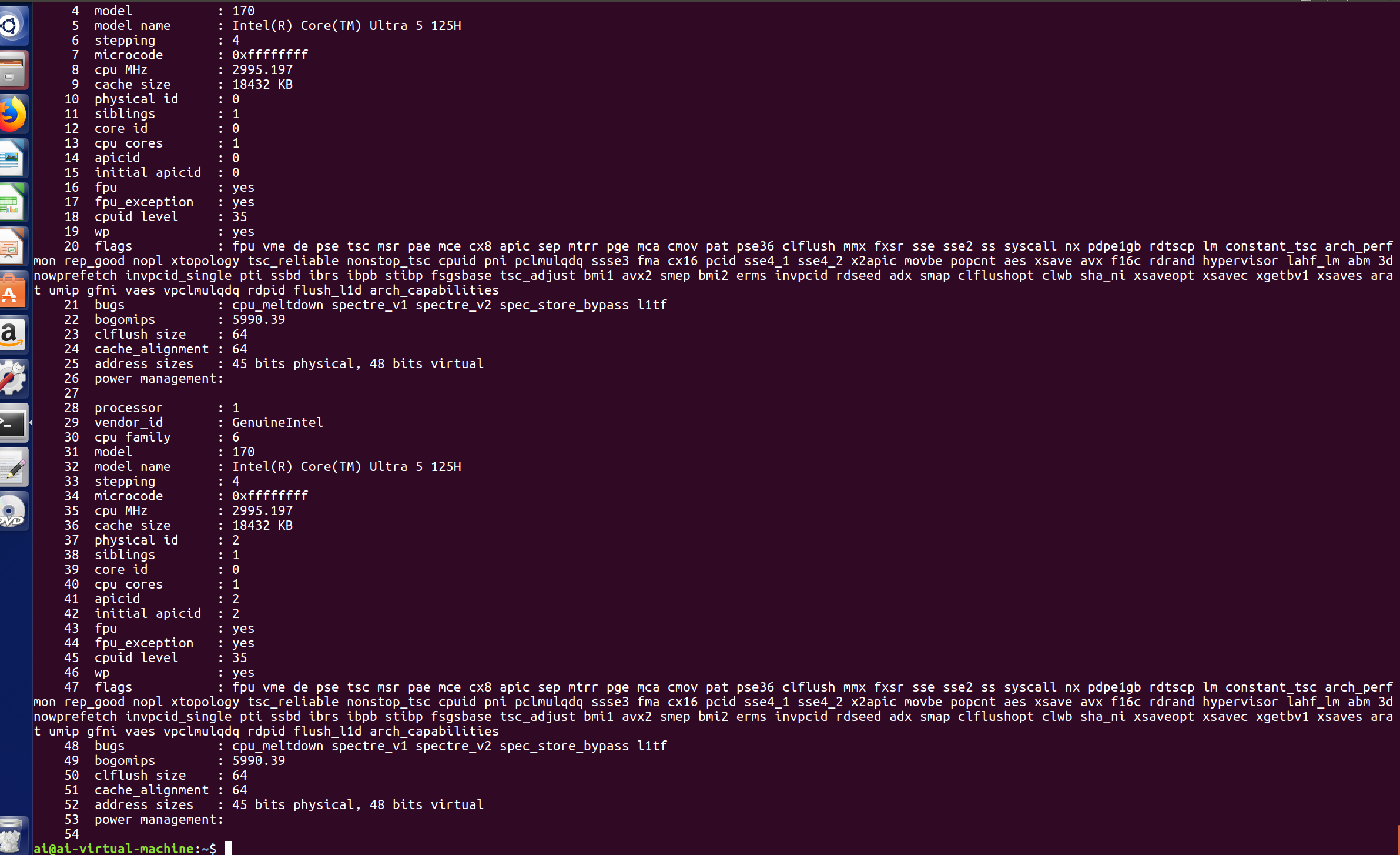
发现可以成功显示行号,但是依然是一次性将全部内容输出到终端,由于文件比较长,终端界面自动显示最后的部分
这也就是cat指令的局限性
2)more
示例
上图为使用more指令读取问价cpuinfo的用法示例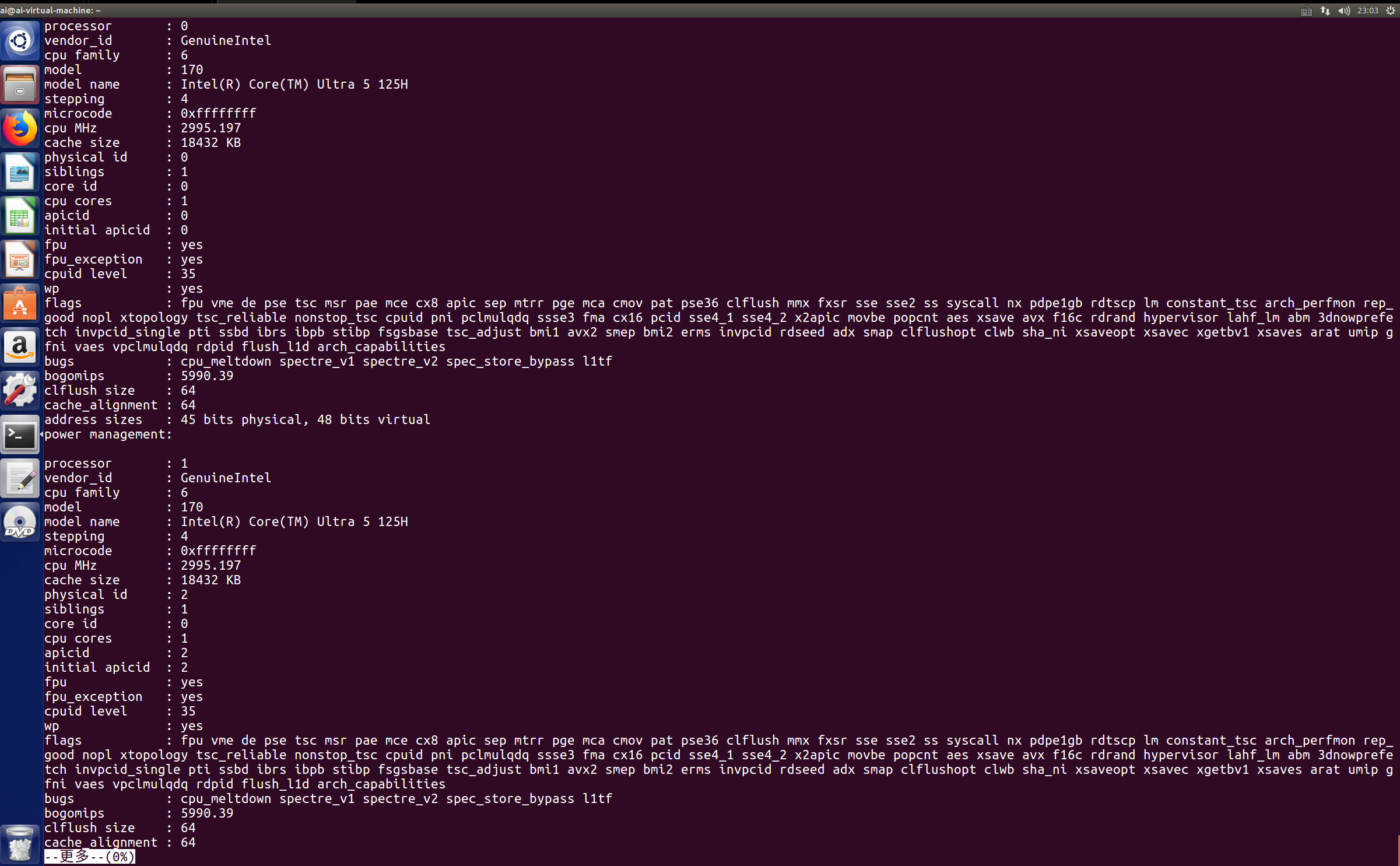
使用指令后出现上图界面,当页直接从第一行开始展示,后续按回车可以按行向下翻(在阅读过程中也能使用空格键向下翻动一页或者按Q/q键直接退出阅读),继续查看后续内容直至完成会出现正常命令行
如上图出现命令行说明正文全部阅读完毕
对内容比较少的文件,可以直接显示完整,对于比较长的文件more指令也能保证完整的读完所有文件内容
more与cat指令的对比:more指令修复cat指令的不足,可以通过翻页或翻行的方式展示文件的所有内容,如果已经通过翻页查看到所需内容,也支持直接按q退出展示模式/阅读模式,返回命令行。
但是他的翻页与换行只支持向下进行,不能向上翻页,也就是不支持回看文件的内容
3)less
示例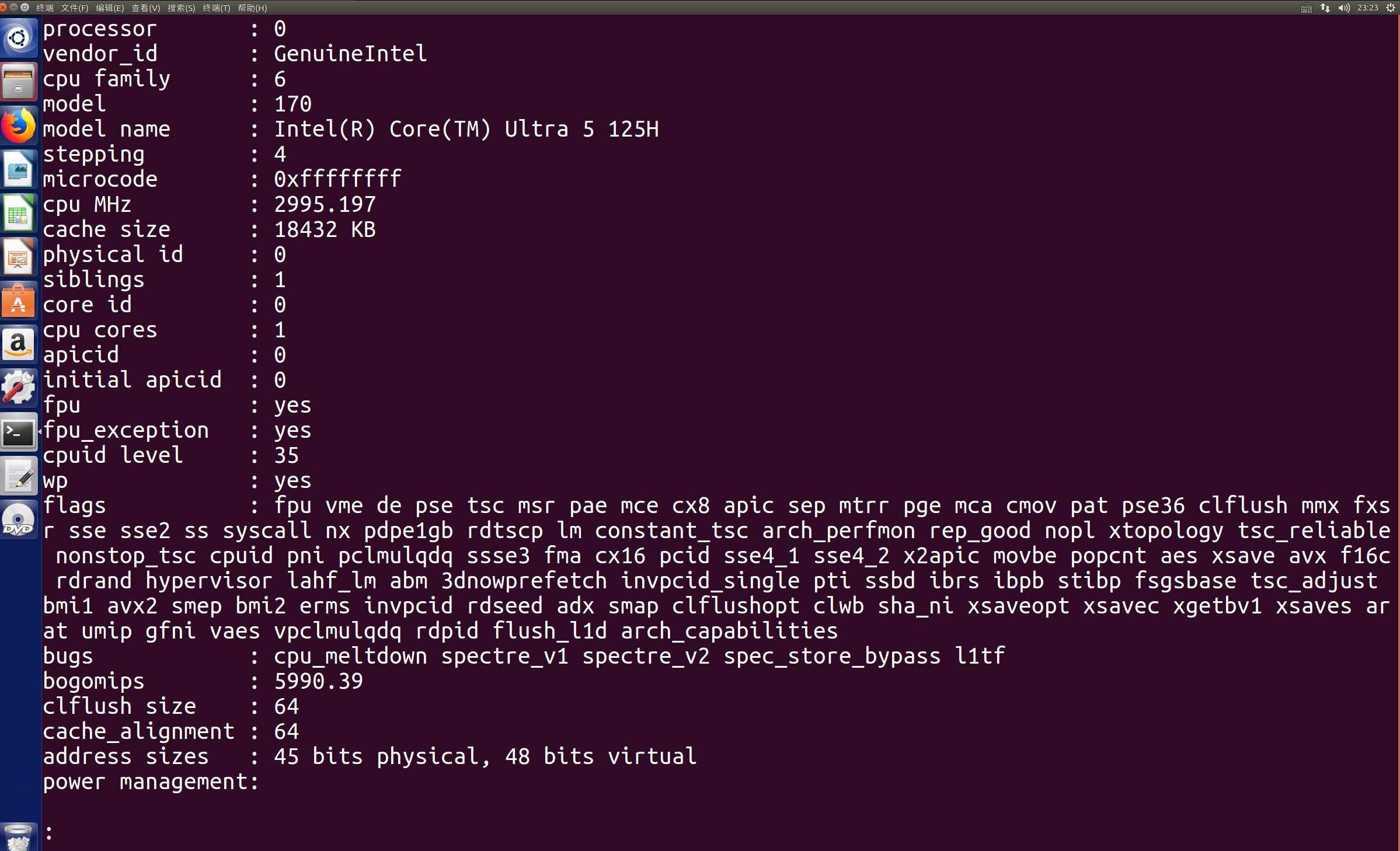
上图为使用‘less /proc/cpuinfo’之后进入的全屏交互的浏览模式,可以以通过前面提到的按键进行翻页,但是内容展示结束之后不会直接出现命令行(如下图)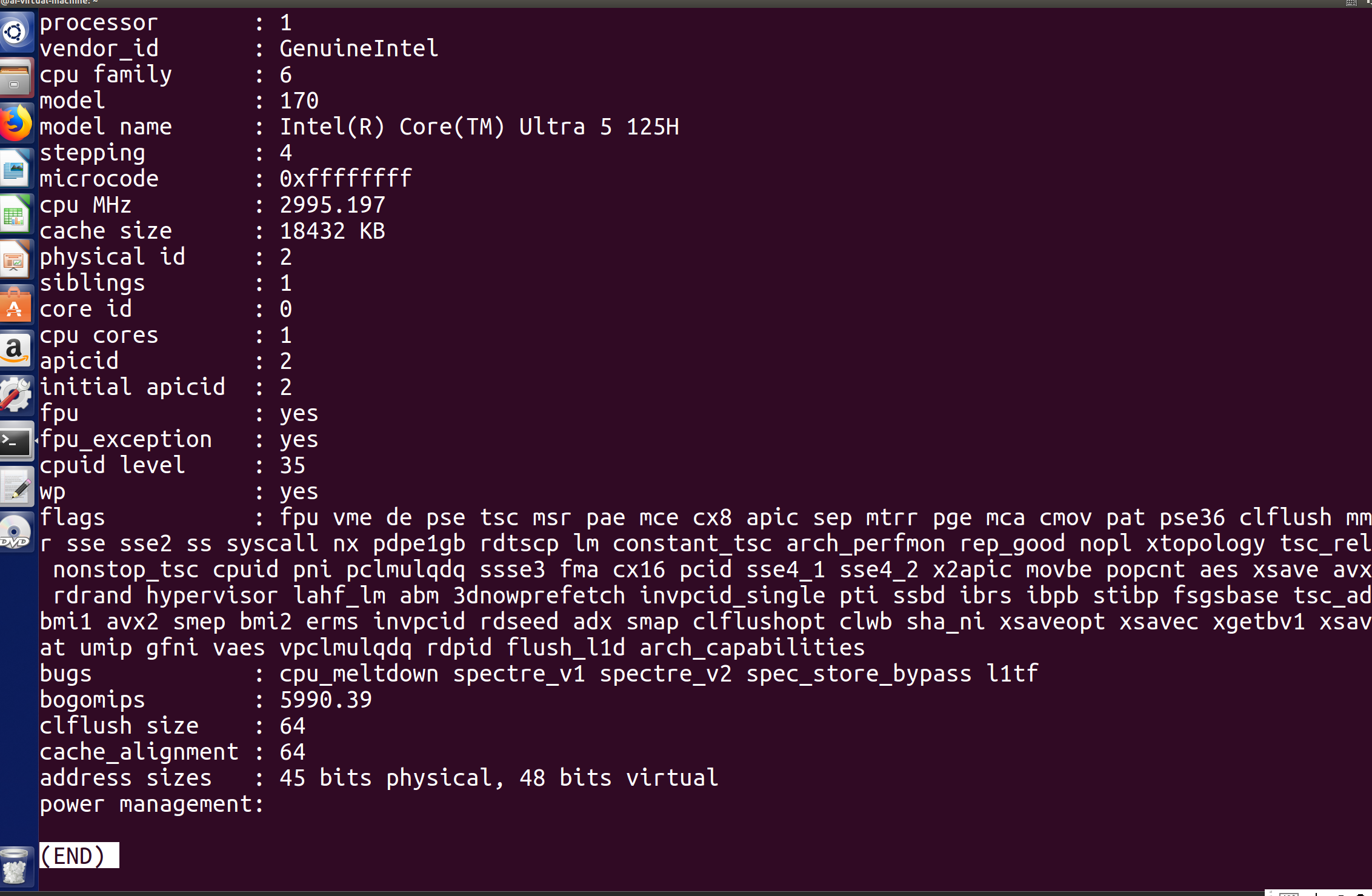
只能通过按下q手动退出阅读模式,这样直接使用指令也无法判定当前的浏览进度
故而引出-m选项协助我们查看阅读进度
(上图展示了less指令和结合-m选项之后的less指令,与前面介绍的 cat 等指令不同,less 采用的是全屏交互模式,文件内容并不会直接“打印”到终端的输出流中。因此连续执行两条指令时,它们的提示符和输出能够紧密衔接,不会被大段的文件正文隔开)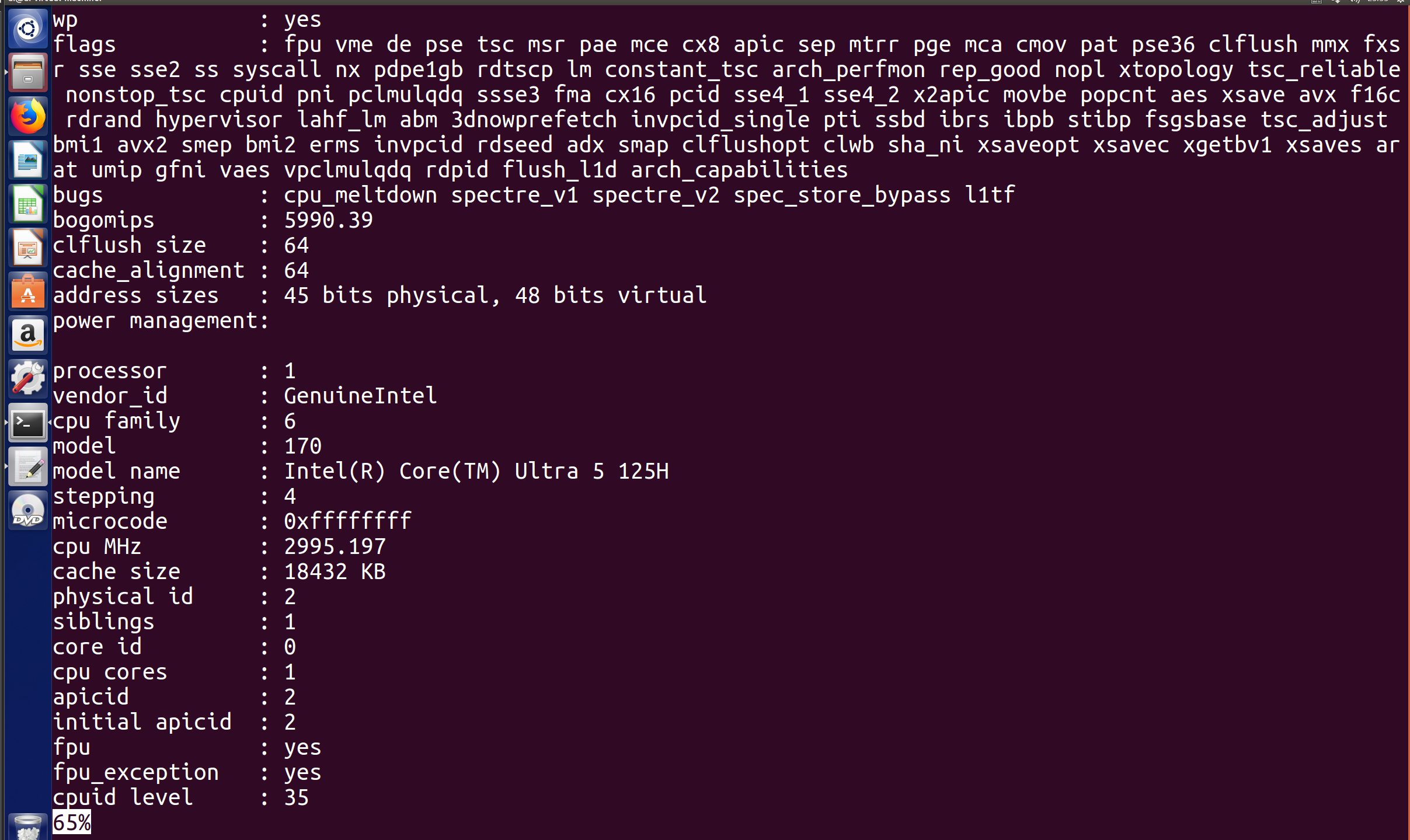
使用-m选项后可以显示当前的浏览进度(最下方的百分比)
上述三种读文件的指令(cat,more,less)各有优缺点。实际使用时的建议是:先用cat -n 查看文件,观察是否从第一行开始完整显示。如果内容被截断,再换用 more 或 less。
不过,这三个指令做的都是获取文件的全部内容。有些时候,我们关心的数据可能只集中在文件头部或末尾,真正需要的不是全文,而是部分内容。那这种情况该怎么处理呢?
这将用到后续的指令
4)head
示例
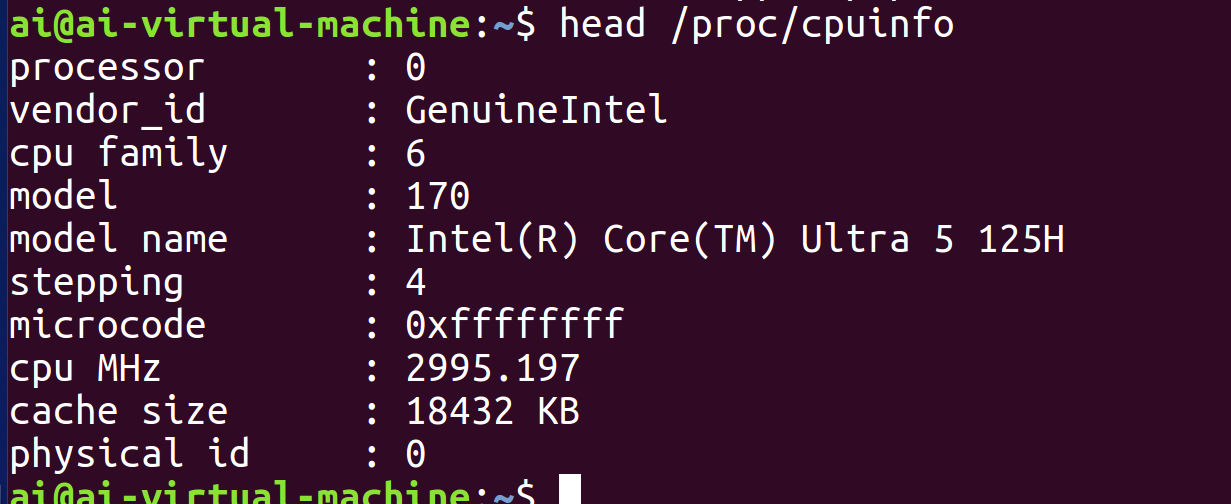
直接使用head指令不使用选项将默认显示前十行
使用选项-数字n之后仅显示前n行(使用-n 数字也可达到同样的效果,但是别输错)
使用-n 数字的时候-与n之间没有空格!否则会进入等待输入状态如下图(可以按下Ctrl+C退出此状态)
5)tail
示例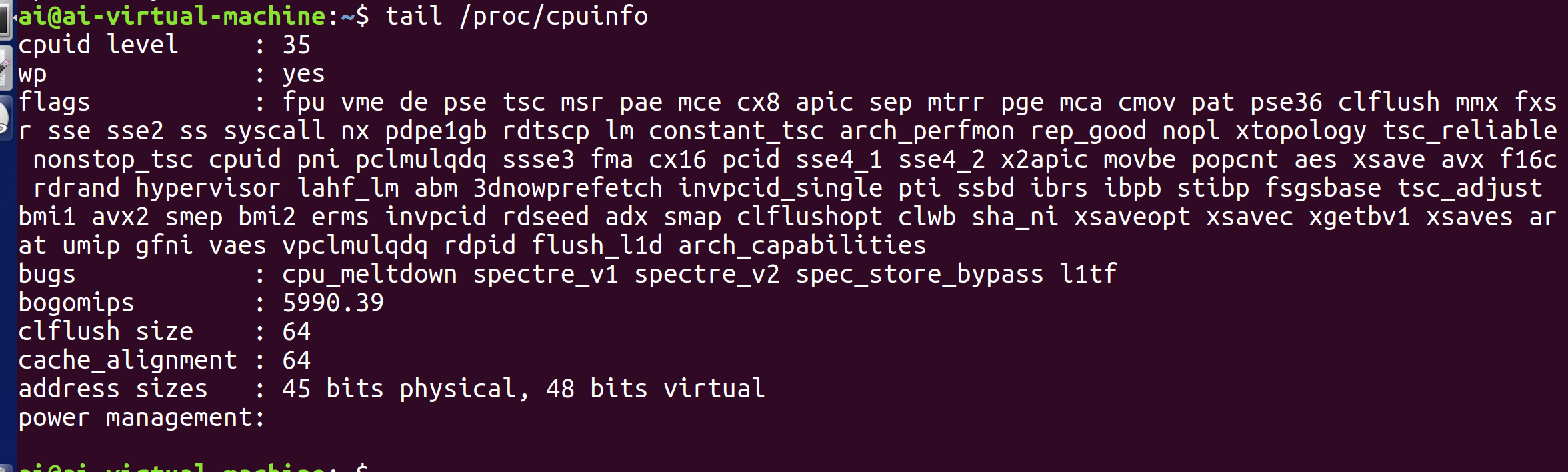
直接使用tail指令不使用选项将默认显示末尾十行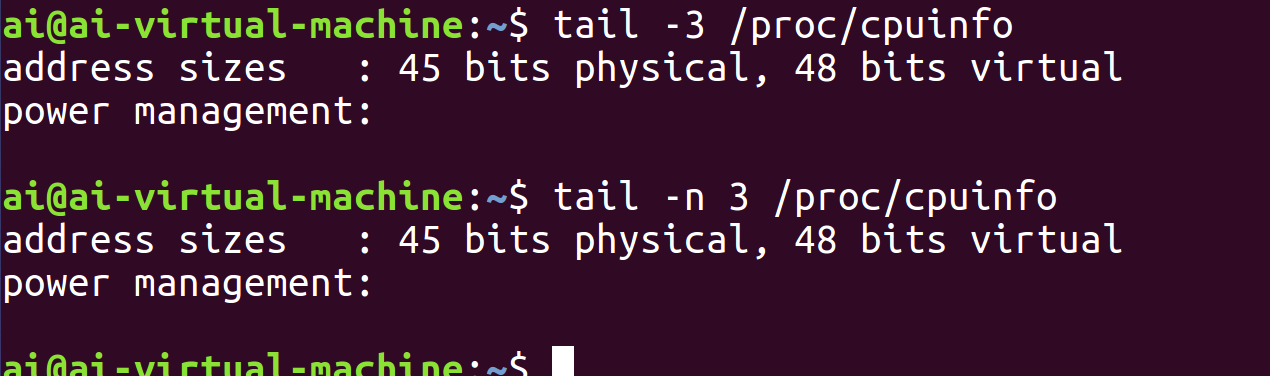
使用选项-数字(或-n 数字)之后仅显示末尾n行
但是这里只有两行信息,是因为这个文件在最后一段信息结束后,还有一个空行(即一个只包含换行符的行),在文本文件的定义里,空行也算作一行,因为它同样以换行符结尾,只是没有可见信息而已。
三、向文件内写入数据
向文件中写入数据,通常无法仅靠一条系统指令直接完成,还需要借助一些特殊的符号。除了之前学过的指令基本格式,这些符号叫什么、怎么用,是我们接下来要弄清楚的问题。
1)输出重定向符:> 与 >>
示例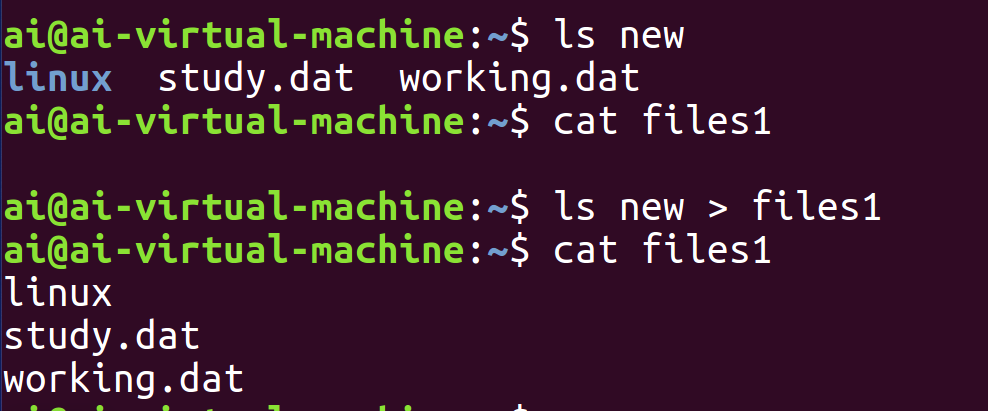
如图,使用ls new > files1后,ls指令原本会显示在屏幕上的目录列表被写入了files1文件中,终端上不再有输出,而读取files1文件即可看到 ls的结果。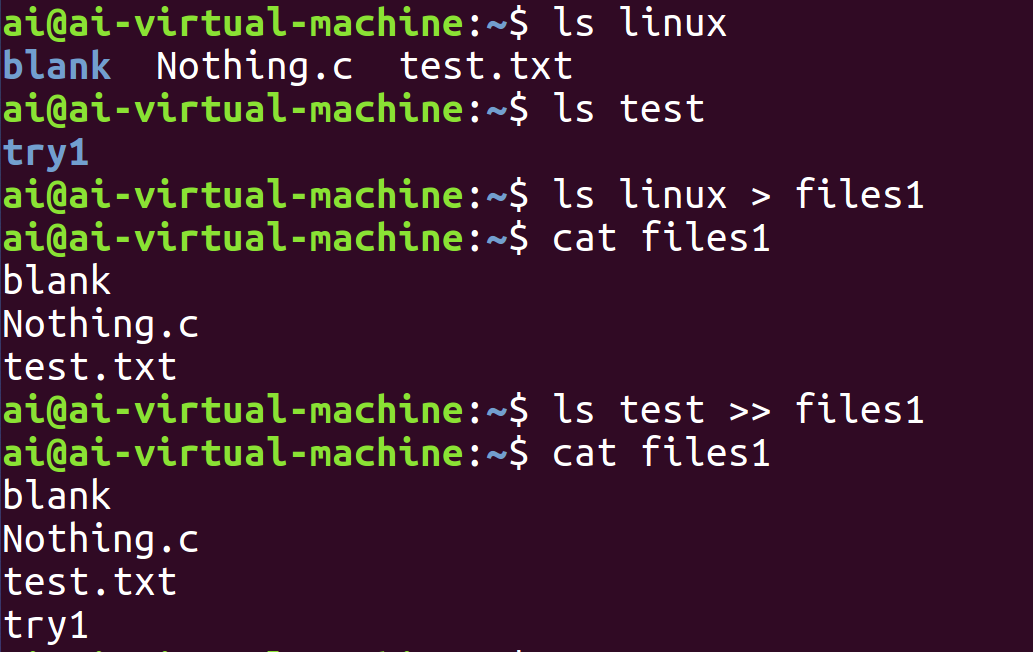
同时使用输出重定向符>与>>后可以发现前者是覆盖写入,也就是写入的同时清楚了原本的内容,而后者是追加写入,保留原内容
那如果想写入一段自己指定的文本内容,该怎么办?这就需要用到 echo 指令来配合。
2)辅助指令 echo
示例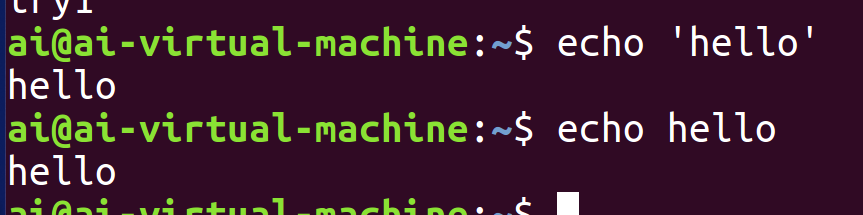
使用 echo 时,建议用单引号把要输出的内容括起来。虽然不加引号原则上也能执行,但加上单引号可以避免特殊字符被 Shell 意外解释,属于更规范的写法。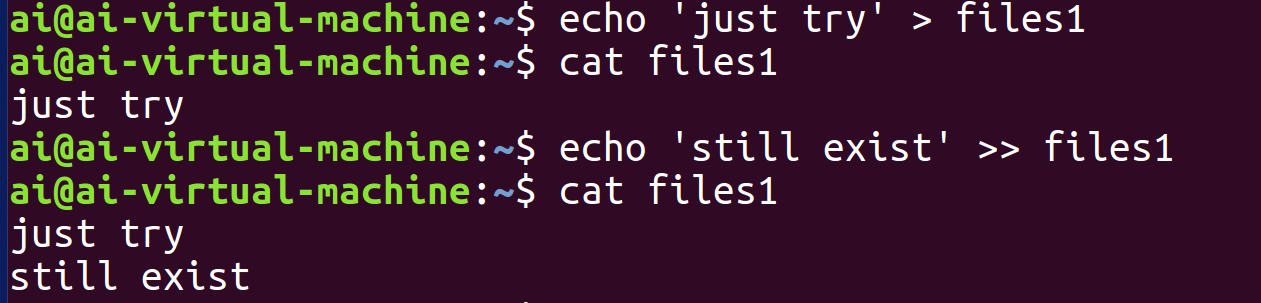
结合重定向符使用即可实现写入指定内容。
这里依然需要注意两个符号的区别:>是覆盖写入,>> 是追加写入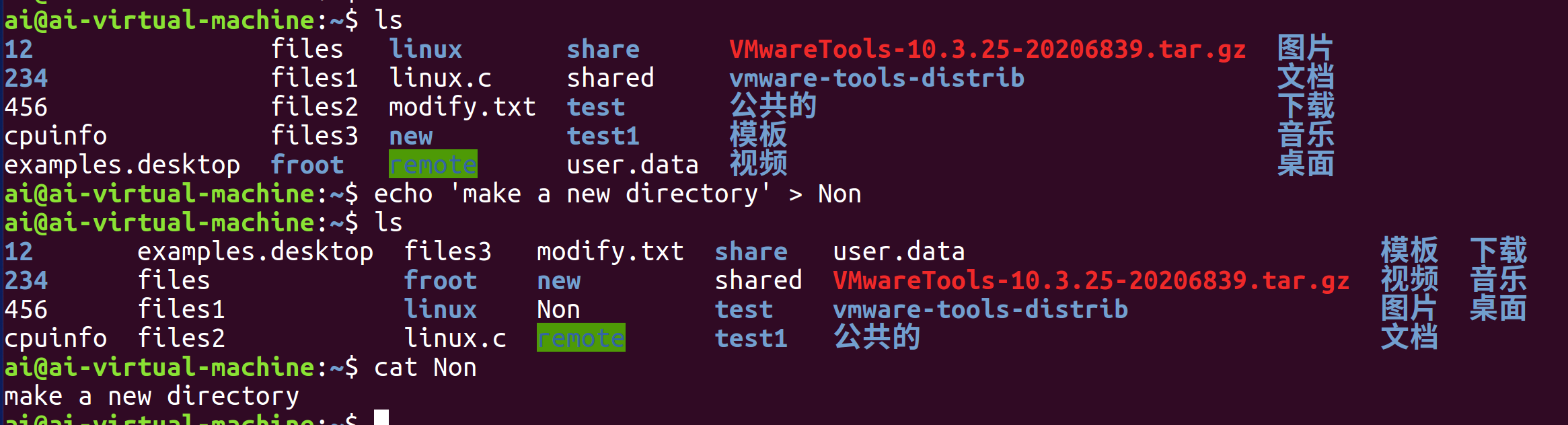
另外,如果指定的目标文件不存在,使用 > 或 >> 时都会 自动创建该文件。也就是说,写入操作本身不受文件是否已存在的限制。例如当前目录下原本没有Non文件,直接使用 echo ‘string’ > Non就会在写入内容的同时自动创建这个文件。
3)管道符 |
示例
此处示例中 grep ‘file’ 的作用是从前一条命令的输出结果中筛出包含 file 的内容,关于grep的详细用法会在下一部分展开。
管道符的实用之处在于,它能把前一个命令的输出直接“递”给后一个命令继续处理,省去了生成中间文件的麻烦。这种“输出即输入”的模式,在 面对大量数据、需要边筛选边处理的场景下尤为高效。
四、文件内容搜索
1)grep
示例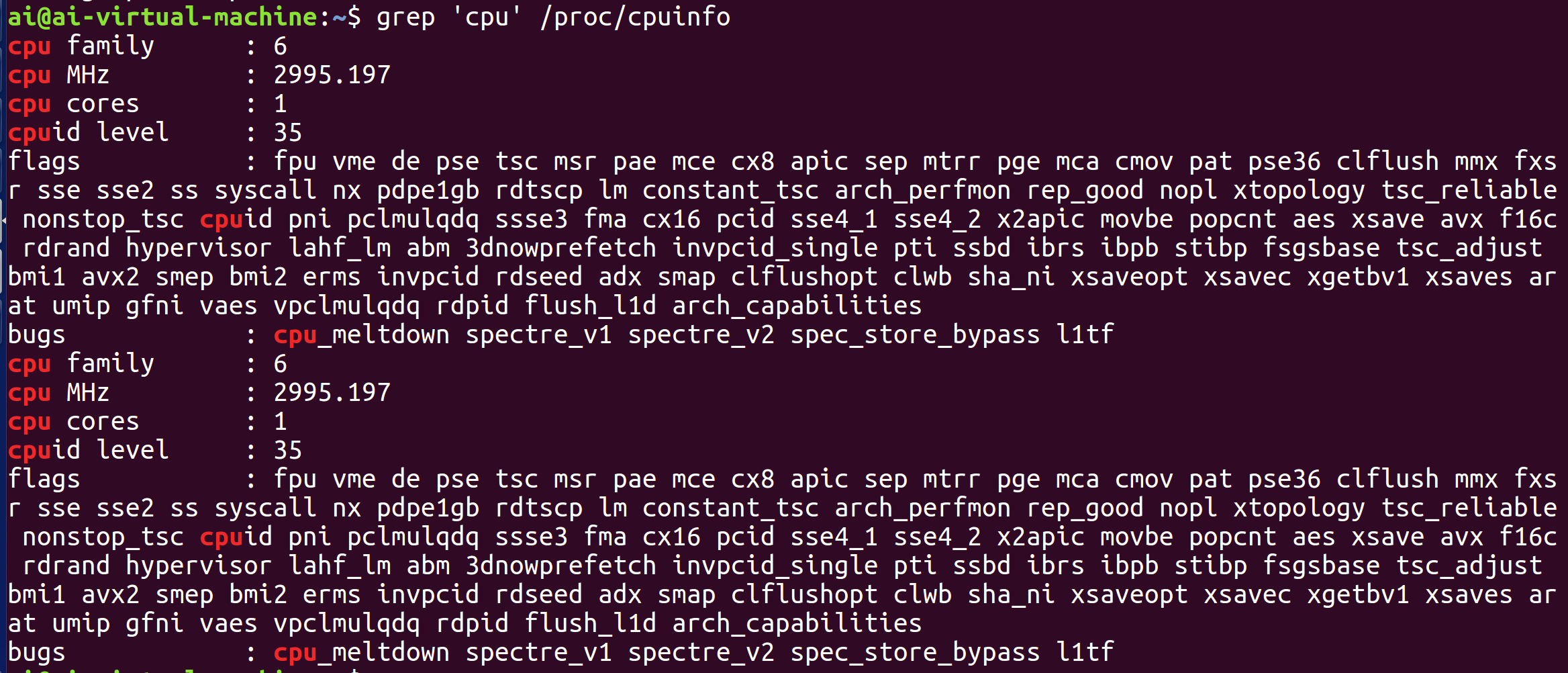
单纯使用 grep 能帮我们确认文件中存在目标数据,但还无法显示这些数据在文件中的具体定位。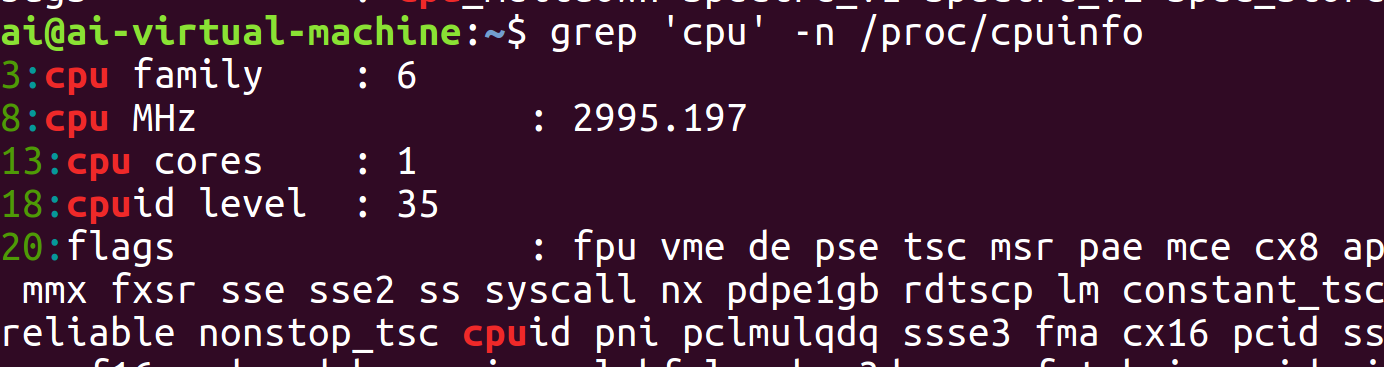
加上-n选项后,就能在输出结果的同时显示每一行对应的行号,方便快速定位
2)行首匹配^和行尾匹配$
行首匹配和行尾匹配并 不是独立的指令,而是配合 grep 使用的匹配符号。
示例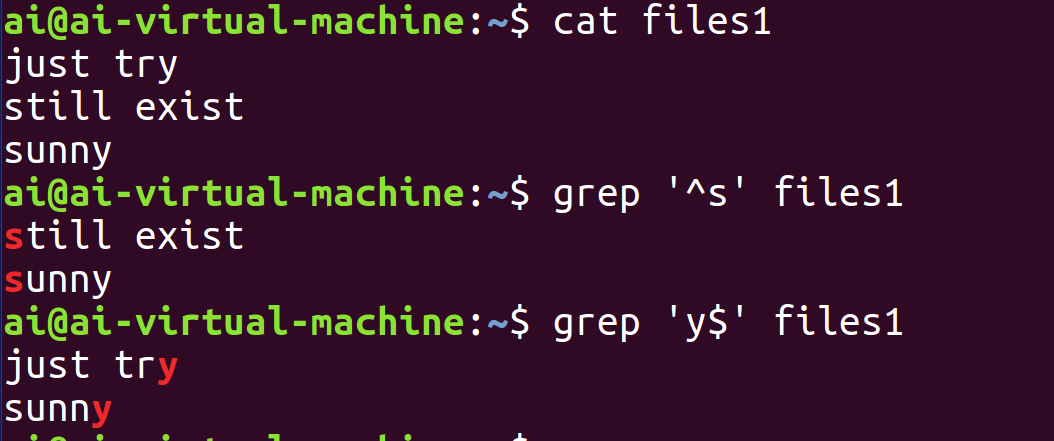
行首匹配时使用^,放在字符串前面,表示匹配以该字符串开头的行;行尾匹配时使用$,放在字符串后面,表示匹配以该字符串结尾的行。
结合这两个匹配符号,我们可以更精准地定位文件中的特定内容。
五、文件查找与定位
对普通文件的操作,除了读和写,还有编辑和定位。其中,文件内编辑(如在文件中删除、插入内容)借助系统指令很难高效完成,通常需要使用专门的编辑工具,这部分内容我们留到下一节专题再展开。
而很多文件操作的参数本身就是文件路径,因此在操作前,得先在系统中找到目标文件——这就要用到文件定位相关的指令了。
1)find
开始位置需要用户大致知道文件所在的目录。理论上直接写成 find / 从根目录搜也可以,但这样会扫描整个磁盘,过程堪比全盘杀毒,效率极低。因此需要指定一个尽量缩小的起始目录,这就要求使用者对系统的目录结构有一定了解。如果起始位置给错了,要么找不到文件,要么搜索过程相当漫长。
常用选项与示例1
-name:按文件名查找
-i:忽略大小写按文件名查找
参数为文件名,如图就是在家目录下寻找名为linux的文件。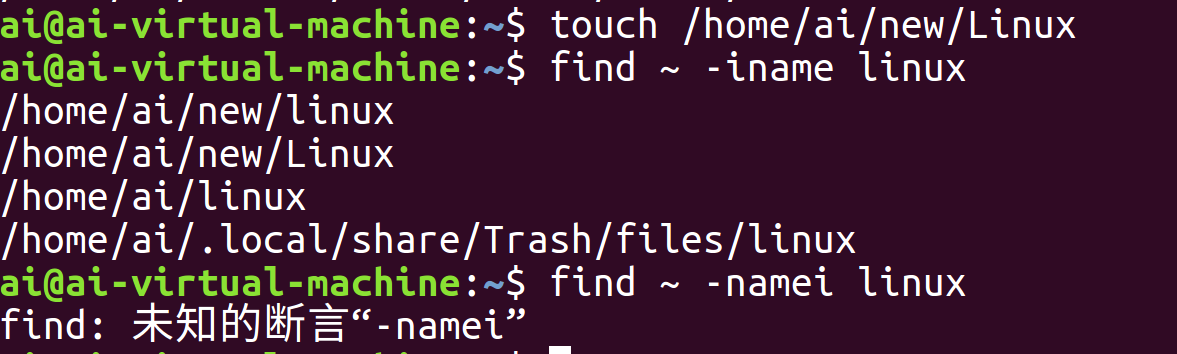
配合 -i 可以忽略大小写,-i 通常与 -name 连用,简写为 -iname(注意不可写成 -namei),即忽略大小写按文件名定位,故这次检索还能找到Linux文件
常用选项与示例2
-size:按文件大小定位文件,参数为文件大小
要注意,直接用ls -l查看文件信息中的文件大小的单位是1字节,而find搭配size使用时筛选的单位是512字节
实际使用过程中基本不会直接使用精确的数字作为参数,因为系统中大小刚好与目标完全一致的文件少之又少,在文件内随意改变哪怕一个空格都会对文件大小产生影响,所以实际使用过程中往往是限定一个范围使用:

这里使用条件-1时无法筛选出files和work,且使用-size -3时未能检索到大小为1500字节的great文件,这也印证了-n的实际检索目标是大小小于(n-1)*512的文件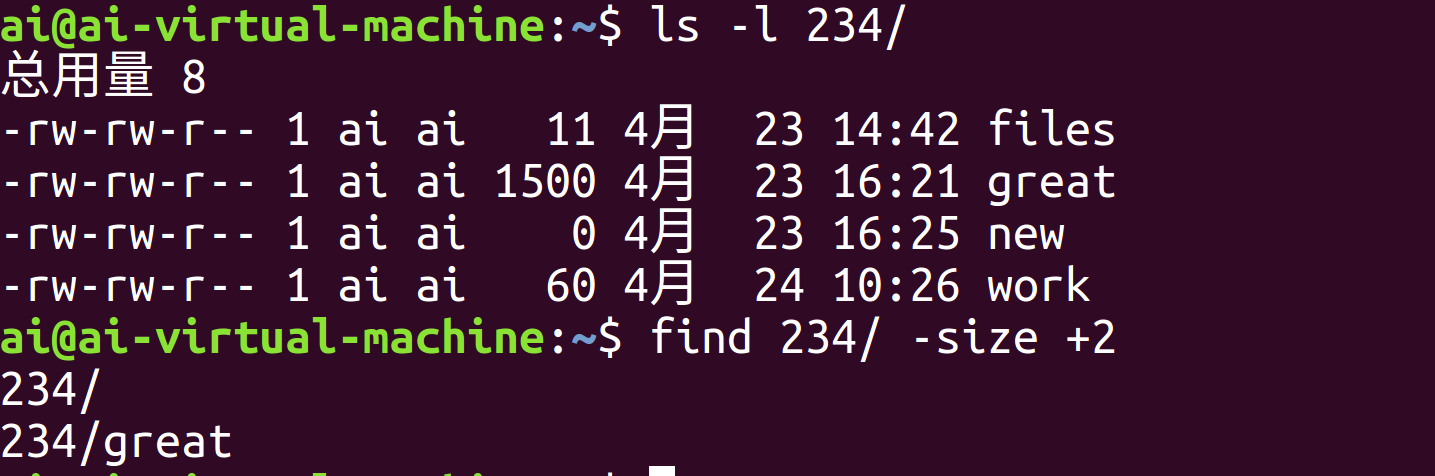
这里使用选项-size搭配+2时可以筛选出great文件,这是因为+2实际上是筛选出文件大小大于1024字节的文件
另外,这里可以发现检索结果中还有234/本身,这是因为find指令在查找时会把指定的那个起始目录本身也纳入搜索范围
常用选项与示例3
-type:按文件类型查找,参数为文件类型标识。
常用参数有 f(普通文件)和 d(目录)。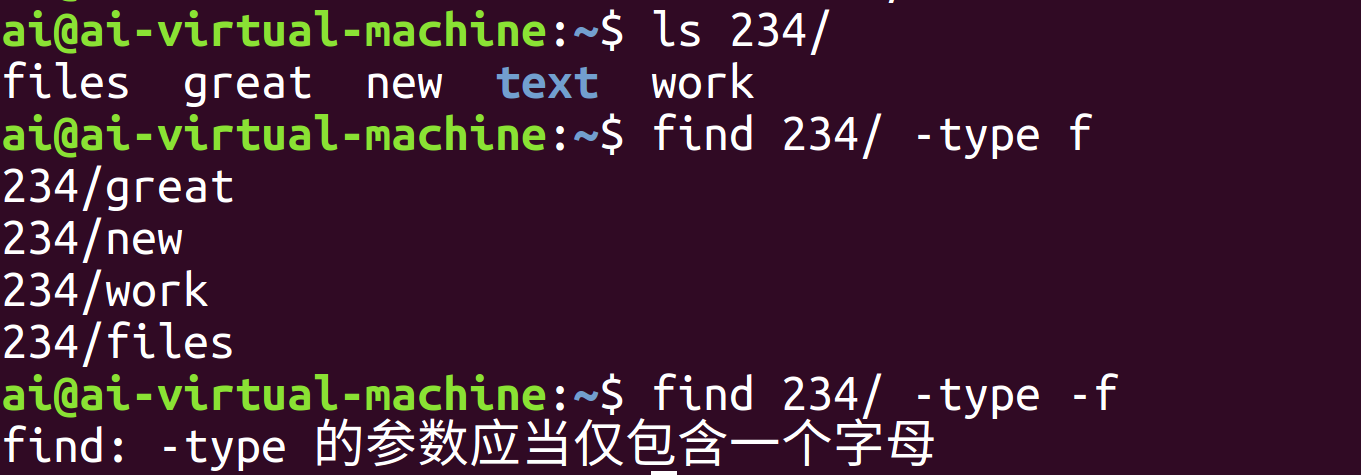
成功在当前目录下筛选出所有普通文件,过滤掉目录等其他类型。
需要注意的是,正确写法是-type f,参数f前面不需要也不能加-,因为-type预设的参数值就是f、d这类类型字符,而不是选项。如果误写成-type -f,系统会把-f当成一个未知的类型标识,从而导致报错。
find 指令功能强大,能搜索磁盘上所有匹配条件的文件,但它的底层原理是直接扫描磁盘,因此效率相对较低。
2)locate
示例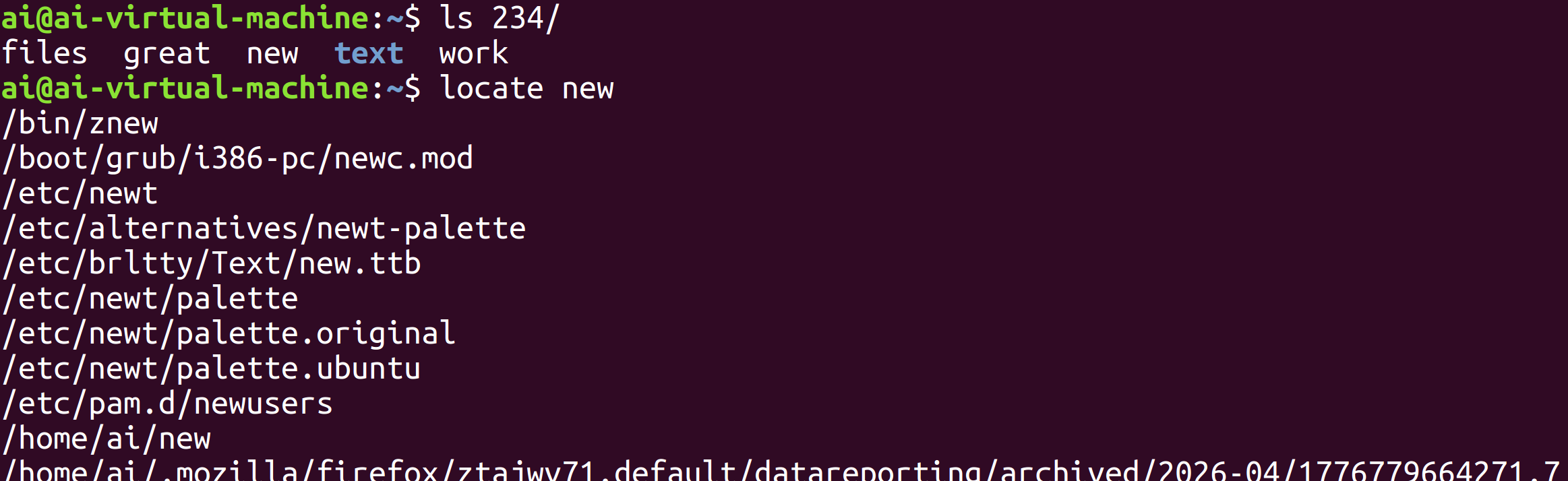
locate 的检索方式是模糊匹配,只要文件的完整路径中包含目标字符串,该文件就会被显示在结果中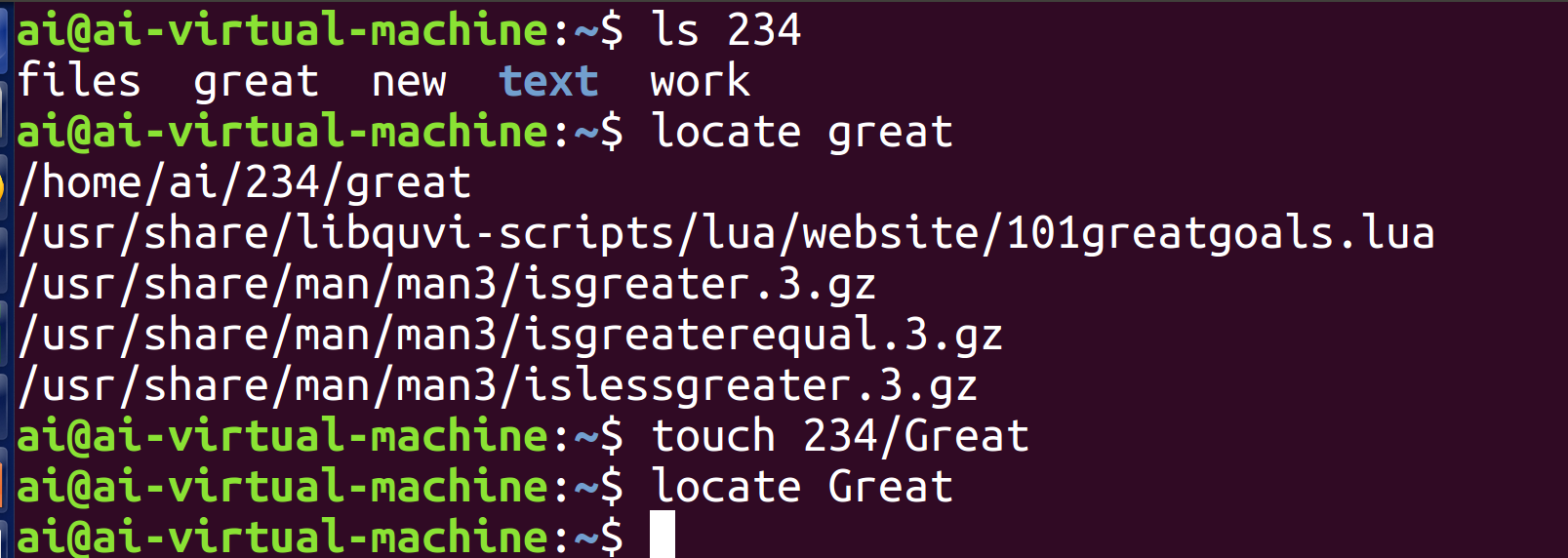
直接使用locate即可寻找目标文件great,但是面对新创建的文件Great却查询不到
这是因为就是locate的检索原理和find不同,Linux系统中存在一个文件数据库,该数据库中记录了文件名与文件路径的对应信息,当locate指令执行时, 就会去读取文件数据库,找到文件名对应的文件路径。
这也导致了locate指令的局限性:对于新建的文件或者目录,locate指令可能无法定位,原因是文件数据库可能还没有得到及时更新。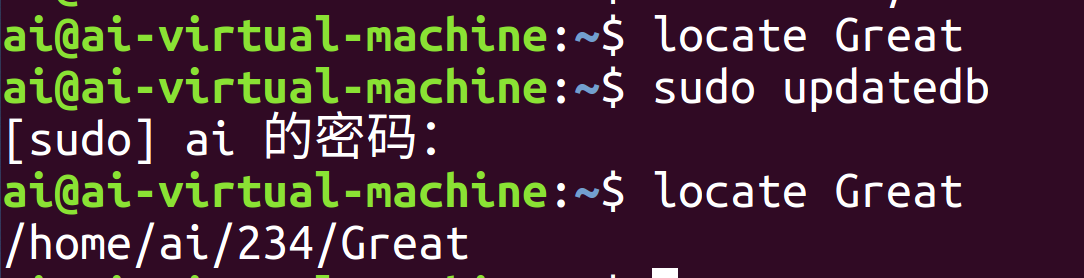
解决方案是使用sudo updatedb指令强制更新数据库,再使用locate指令就可以查找到新创建的文件了
3)find与locate的对比
| 对比维度 | find | locate |
|---|---|---|
| 查找原理 | 磁盘扫描,逐个对比 | 查询系统文件名数据库 |
| 速度 | 较慢 | 很快 |
| 能否找到新文件 | 能,只要磁盘上存在就能找到 | 不一定,数据库更新之前找不到 |
| 匹配方式 | 精确匹配(按选项指定) | 模糊匹配,路径中含关键词即显示 |
两者各有优劣,实际使用时可根据场景灵活选择:追求全准用 find,追求速度用 locate。
4)which
示例
which 的功能很简单,就是用来查某个命令的可执行文件存放在系统的哪个位置
它和前文的 find、locate 形成三个不同层面的“查找”对比:find查找磁盘上的任意文件,locate按数据库搜文件路径,which专搜可执行指令的位置。
结语
从最基础的“文件是什么”开始,我们逐步认识了目录与文件的本质区别,然后围绕普通文件的日常操作,逐一上手了读取、写入、搜索和定位四类指令。cat、more、less、head、tail 解决了“怎么看”的问题,>、>>、echo 和管道符 | 解决了“怎么写”的问题,grep 配合行首行尾匹配解决了“怎么搜”的问题,find、locate、which 则解决了“怎么找”的问题。掌握了这些,日常的文件查看、简单写入和快速定位基本就能应对了。
不过,到目前为止我们只是在对文件进行“整体”级别的操作。如果需要对文件内容做更精细的修改——比如删除某一行、替换某个词、插入一段新内容——就需要用到专门的文本编辑工具了。
下一篇将介绍 Linux 下最常用的文本编辑器 VIM,包括它的安装、启动与退出、三种工作模式,以及在命令模式下的常用操作,为后续更深入的文件编辑打好基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)