【27.77 亿 Token 烧出来的教训:Codex 技能过度设计踩坑实录】
📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、《解密程序员的思维密码——沟通、演讲、思考的实践》作者、清华大学出版社签约作家、Java领域优质创作者、CSDN博客专家、阿里云专家博主、51CTO专家博主、产品软文专业写手、技术文章评审老师、技术类问卷调查设计师、幕后大佬社区创始人、开源项目贡献者。
📘拥有多年一线研发和团队管理经验,研究过主流框架的底层源码(Spring、SpringBoot、SpringMVC、SpringCloud、Mybatis、Dubbo、Zookeeper),消息中间件底层架构原理(RabbitMQ、RocketMQ、Kafka)、Redis缓存、MySQL关系型数据库、 ElasticSearch全文搜索、MongoDB非关系型数据库、Apache ShardingSphere分库分表读写分离、设计模式、领域驱动DDD、Kubernetes容器编排等。
📙不定期分享高并发、高可用、高性能、微服务、分布式、海量数据、性能调优、云原生、项目管理、产品思维、技术选型、架构设计、求职面试、副业思维、个人成长等内容。

💡在这个美好的时刻,笔者不再啰嗦废话,现在毫不拖延地进入文章所要讨论的主题。接下来,我将为大家呈现正文内容。

前言
我之前陆续给AI配置了大量自定义技能(Skill),本意是通过精细化规则约束,提升代码生成质量、贴合工作规范。
比如日常写接口时,要求自动完善Swagger文档、补全详细参数示例、规范前端错误码、细化入参和出参说明等,这些定制化要求,都是我在工作中一步步积累、逐步适配补充的,只为让产出更贴合业务标准。
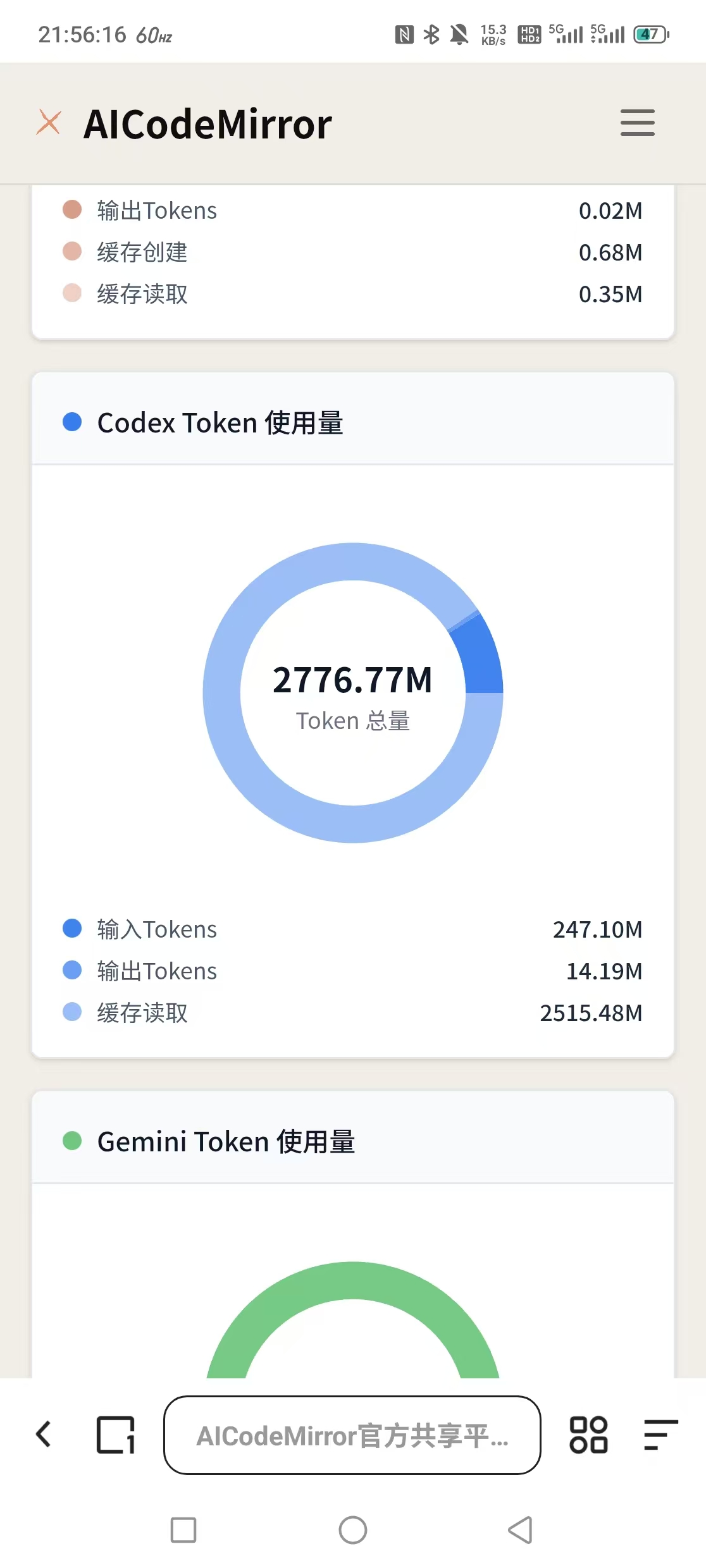
但实际使用下来效果很差,最近明显感知AI响应越来越卡顿,直接拖垮了整体工作效率。
复盘后发现核心问题出在技能的加载逻辑上:我设置的是按需触发、全局适配模式,每下发一个任务,系统都会自动加载、遍历全部Skill规则,逐一检测是否需要触发匹配。
可以参考:https://download.csdn.net/download/java_wxid/92785887?spm=1001.2014.3001.5501
随着日积月累,技能数量越来越多,即便很多技能当下任务用不到,也会被逐个扫描校验,大幅增加运行开销。
后续我尝试过各种优化手段:更换模型、调低运行配置至最低档位,都没有明显改善。
现在简单任务也要等待半分钟以上,复杂需求甚至要耗时好几分钟;就算多线程并行提交任务,整体运行速度依旧持续变慢,严重影响办公节奏。
现在我意识到,属于过度设计了。堆砌太多冗余技能反而得不偿失,相比复杂的技能套装,不如精简规则,只保留核心约束,直接用简洁清晰的要求交给大模型执行,反而会兼顾速度与实用性。
今天
我今天用了100多块钱,有点心痛。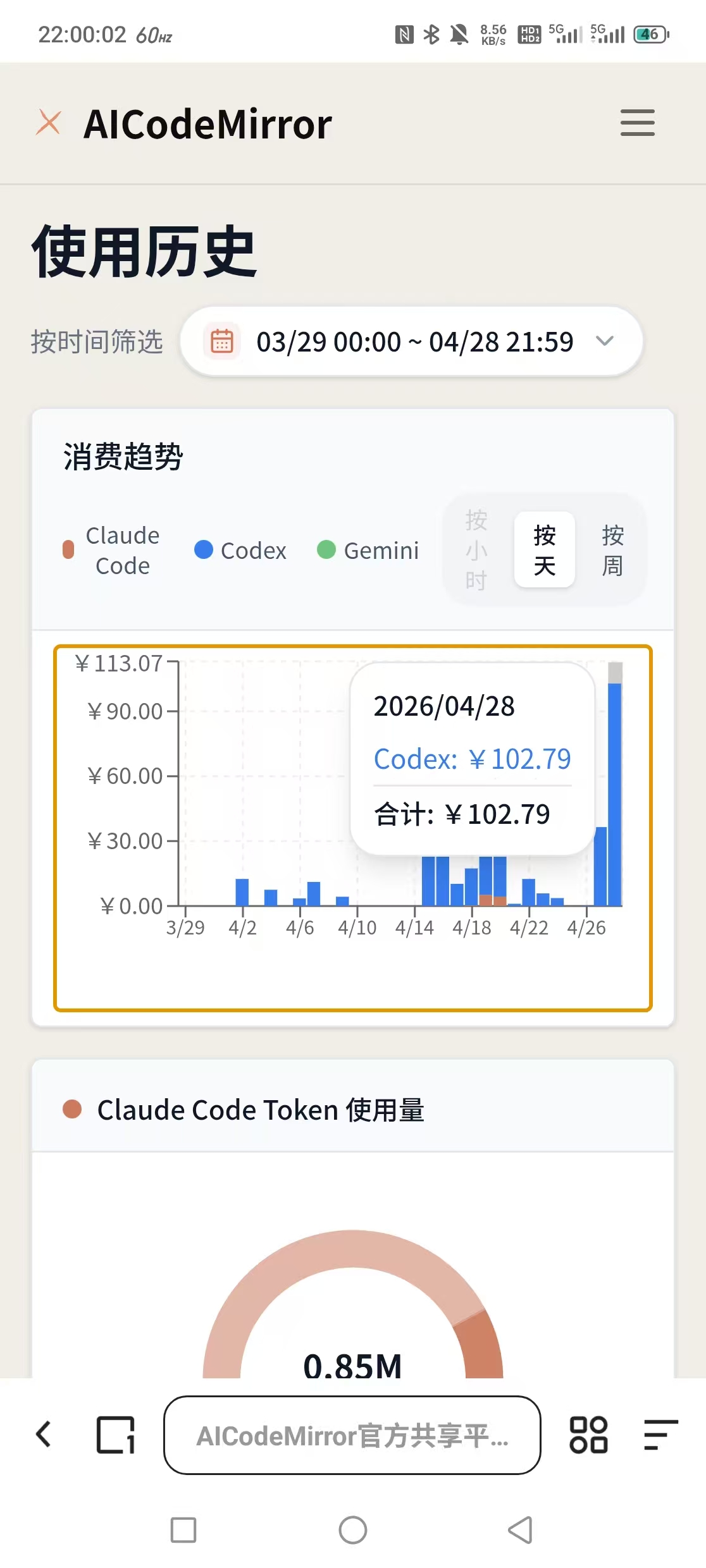
今天用下来,整体效果其实并不理想,工作效率的提升非常有限。
工作时我用的是 ChatGPT 5.5 的最高档位模型,虽然生成质量整体还不错,基本能满足需求,但依然会有不少漏洞和 bug,改来改去反而更耗时间。更关键的是,响应速度慢得离谱,同样的任务经常要等好几分钟。
我复盘了一下,核心问题应该出在我之前设计的复杂规则和一堆 Skill 上 —— 每次调用都要加载、校验一大堆技能配置,光这一步就严重拖慢了模型响应,成本也跟着上去了,等于自己给自己加了一堆不必要的负担。
晚上回家,我在一台全新的电脑上装了 CodeX,什么自定义规则都没加,直接用 ChatGPT 5.3 Codex 的低档位模型测试,结果响应速度快得惊人,一两秒就能出结果,工作中用同一模型缺要几分钟。
这一对比我才发现,之前花大量时间堆规则、做适配,全是无用功。这些过度设计不仅没带来质的提升,反而拖慢了速度、拉高了成本,让我在追求 “完美规范” 的路上,反而把效率给拖垮了。



优化
不要把大量 skill 和长全局规则挂在单一主 Agent 上,而是采用“轻量主脑 + 角色 Agent + 子 Agent 按需加载 + Hook 兜底 + Eval/Simulation 验证”的结构,这样速度、能力、可控性三者才不会互相打架。
总模型
- 人是最终裁决者,系统里的“主脑 Agent”只是编排器,不是无限膨胀的万能代理。
- 主脑 Agent 只做 4 件事:识别任务、选择角色、收敛结果、做最终质检。
- 角色 Agent 只做窄职责工作,不直接承担整条链路。
- 子 Agent 只在角色 Agent 真的需要重能力时才创建,用完即回收。
Skill负责“应该怎么做”。Hook负责“不能怎么做”。Memory负责“越用越懂你,但不能无限污染上下文”。Eval + Replay + Simulation负责“这套系统在真实任务里是否稳定”。
为什么不用“大一统主 Agent”
- 全局挂很多
skill会拖慢首包时间,因为每次都要做触发判断和规则解析。 - 主 Agent 背太多职责后,路由会变差,输出风格会漂,错误更难定位。
- 多角色拆分后,问题会变成“哪个角色失误”,而不是“整个系统为什么又玄学了”。
- 质量真正来自清晰边界、输出协议、验证闭环,不来自提示词堆积。
推荐的三层结构
-
Orchestrator Agent
职责:任务识别、编排、上下文裁剪、质量门禁、最终汇总。
要求:必须轻量,不默认加载重 skill,不默认做全仓深扫。 -
Role Agents
建议首批角色:PM/Growth、Architect、Dev、QA、Review、Docs、Release、Issue/Ops。
要求:每个角色只有清晰边界和固定输出协议,不互相越权。 -
Worker Agents
典型子角色:schema-worker、test-writer、seo-auditor、bug-reproducer、migration-checker、release-note-writer。
要求:强约束、短生命周期、有限输入、有限输出、明确文件或任务边界。
四大核心对象
-
Role
定义“它是谁、负责什么、不能碰什么、成功标准是什么”。 -
Memory
定义“哪些事实值得记、记到哪里、什么时候读、什么时候过期”。 -
Skill
定义“为完成某类任务可加载哪些流程、模板、工具、外部系统”。 -
Workspace
定义“角色定义、记忆、技能、运行日志、评测样本、交付物都放在哪里”。
记忆系统怎么设计
-
User Memory
存用户长期偏好。
例如:回答风格、默认技术栈、对风险的容忍度、常用命名、对速度和质量的偏好。 -
Project Memory
存项目长期事实。
例如:架构约束、目录约定、部署方式、测试命令、发布策略、SEO/GEO 目标、历史坑点。 -
Run Memory
存一次任务的过程事实。
例如:本轮目标、实际改动、失败原因、验证结果、待办尾项。 -
Pattern Memory
存高频可复用模式。
例如:issue 分诊模板、发布流程模板、PR 审查模板、SEO 检查模板。 -
记忆写入原则
只写高价值事实,不写猜测。
只写稳定内容,不写瞬时噪音。
写入要带来源和置信度。
长期记忆必须允许淘汰和修订。
Skill 体系怎么拆
-
Analysis Skills
例如需求拆解、架构审阅、issue triage、复盘分析。 -
Execution Skills
例如代码实现、测试生成、文档生成、发布准备、SEO 元数据生成。 -
Verification Skills
例如结构化输出校验、风险清单检查、SEO/GEO 审核、回归检查。 -
Integration Skills
例如 Git、CI/CD、Issue Tracker、Docs、CMS、搜索监控平台。 -
设计原则
主脑只挂路由级轻 skill。
角色 Agent 只挂本领域 skill。
重 skill 不进全局,按需加载。
每个 skill 都要有输入、输出、失败条件和边界说明。
Hook 兜底要覆盖什么
-
路由 Hook
检查任务是否发给了正确角色,防止 PM 去直接写代码,防止 Dev 去拍业务结论。 -
权限 Hook
限制危险操作、越权工具调用、无授权外部访问、错误分支发布。 -
输出 Hook
强制结构化输出,至少包含:结论、证据、风险、未决项、下一步。 -
改动范围 Hook
限制某个 Agent 只能改它负责的文件或模块。 -
事实校验 Hook
要求高风险结论必须带依据,高时效信息必须先查证。 -
记忆写入 Hook
没有确认价值的内容不能写长期记忆。 -
发布 Hook
没有通过测试、没有变更说明、没有回滚预案,就不能进入发布阶段。
SEO/GEO 的归属SEO/GEO 不是独立漂在流程外的一条线,而是整个研发流程中的横切能力。
-
在
PM/Growth阶段定义目标
包括:搜索意图、实体覆盖、页面策略、可检索内容、引用价值、转化目标。 -
在
Architect/Dev阶段实现
包括:信息架构、路由与渲染策略、元数据、结构化数据、页面语义块、可抓取性。 -
在
QA阶段校验
包括:标题描述、canonical、结构化数据、渲染结果、内容可抽取性、链接结构。 -
在
Release/Ops阶段监控
包括:收录、排名、点击、转化、引用表现、内容衰减和回补。
全流程编排
-
入口与分流
主脑 Agent 接收任务,识别任务类型、风险等级、所需角色、需要读取的最小上下文。
输出:task brief、role assignment、required memories、required skills。 -
需求定义
由PM/Growth Agent负责。
输出:目标、用户问题、验收标准、约束条件、SEO/GEO 要求、优先级。 -
方案设计
由Architect Agent或高级Dev Agent负责。
输出:技术方案、模块边界、数据流、风险点、测试策略、发布影响面。 -
实现执行
由Dev Agent负责。
必要时派生worker agents处理测试编写、迁移检查、单模块实现、SEO 元数据生成等窄任务。
输出:代码改动、实现说明、测试说明、剩余风险。 -
代码审查
由Review Agent负责。
关注点:逻辑错误、行为回归、边界条件、缺失测试、发布风险。
输出:按严重度排序的问题列表,而不是泛泛总结。 -
测试校验
由QA Agent负责。
覆盖:单测、集成、E2E、回归、性能基线、SEO/GEO 校验。
输出:通过项、失败项、复现方式、阻断级别。 -
文档编写
由Docs Agent负责。
更新:用户文档、内部运行手册、变更日志、FAQ、迁移说明。 -
上线发布
由Release Agent负责。
处理:版本号、发布说明、环境差异、发布步骤、回滚方案、发布后观察项。 -
发布后监控
由Issue/Ops Agent与Growth Agent负责。
处理:告警、issue 分诊、用户反馈、SEO/GEO 表现回收、知识沉淀、下一轮任务触发。
统一输出协议
所有角色 Agent 都必须按同一协议回传,主脑只接收这种格式:
结论证据风险未决项下一步
代码类任务额外要求:
改动范围验证结果发布影响
Workspace 建议目录
/workspace
/roles
orchestrator.md
pm-growth.md
architect.md
dev.md
qa.md
review.md
docs.md
release.md
issue-ops.md
/memory
/user
/project
/runs
/patterns
/skills
/routing
/development
/testing
/docs
/release
/seo-geo
/issue-triage
/hooks
route-check
permission-guard
output-schema
change-scope
fact-check
memory-write
release-gate
/evals
/routing
/task-success
/tool-compliance
/seo-geo
/regression
/simulations
/artifacts
/prd
/design
/reviews
/reports
/release-notes
评测和真实验证必须怎么做
-
静态 Eval
检查路由是否正确、输出是否合规、工具是否越权。 -
真实样本 Replay
把历史需求、历史 issue、历史 PR、历史发布事故拿来回放。 -
多轮 Simulation
模拟真实用户行为,不只测单轮问答。
例如:提需求、改需求、追问、打回、补充限制、要求上线、出现 bug、回滚。 -
线上门禁指标
最少看:任务成功率、误路由率、P95 延迟、失败恢复率、人工接管率、回归率。
最小可行落地顺序
-
第一阶段先做
Orchestrator + PM/Growth + Dev + QA + Review。
原因:这是最短闭环,能先把“需求到代码到校验”打通。 -
第二阶段补
Docs + Release + Issue/Ops。
原因:这一步开始形成真正的工程系统,而不是单次任务工具。 -
第三阶段加强
Memory + SEO/GEO + 自动化监控 + Replay Eval。
原因:这一步才决定系统能不能长期变聪明、变稳定,而不是越跑越乱。
真正的落地标准
- 没有输出协议的 Agent,不上线。
- 没有 Hook 的高风险能力,不开放。
- 没有 Eval 样本的 skill,不进入默认流程。
- 没有边界定义的角色,不允许派任务。
- 没有回放验证的自动化,不允许扩大权限。
📥博主的人生感悟和目标

希望各位读者大大多多支持用心写文章的博主,现在时代变了,信息爆炸,酒香也怕巷子深,博主真的需要大家的帮助才能在这片海洋中继续发光发热,所以,赶紧动动你的小手,点波关注❤️,点波赞👍,点波收藏⭐,甚至点波评论✍️,都是对博主最好的支持和鼓励!
- 💂 博客主页: Java程序员廖志伟
- 👉 开源项目:Java程序员廖志伟
- 🌥 哔哩哔哩:Java程序员廖志伟
- 🎏 个人社区:Java程序员廖志伟
- 🔖 个人微信号:
SeniorRD
📙经过多年在CSDN创作上千篇文章的经验积累,我已经拥有了不错的写作技巧。同时,我还与清华大学出版社签下了四本书籍的合约,并将陆续出版。
《Java项目实战—深入理解大型互联网企业通用技术》基础篇简体字的购书链接:https://item.jd.com/14152451.html
《Java项目实战—深入理解大型互联网企业通用技术》基础篇繁体字的购书链接:http://product.dangdang.com/11821397208.html
《Java项目实战—深入理解大型互联网企业通用技术》进阶篇的购书链接:https://item.jd.com/14616418.html
《解密程序员的思维密码–沟通、演讲、思考的实践》购书链接:https://item.jd.com/15096040.html
🔔如果您需要转载或者搬运这篇文章的话,非常欢迎您私信我哦~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)