破解医疗大模型“重文轻图”局限!Emory大学提出MedLVR潜在视觉推理框架
摘要 (Abstract)
医疗视觉-语言模型 (VLMs) 在医疗视觉问答 (VQA) 任务中展现出巨大潜力,但其推理过程在很大程度上仍是“以文本为中心”的:图像仅作为静态上下文被编码一次,随后的推理过程由语言主导。这种范式在临床场景中存在根本性缺陷,因为准确的诊断答案通常依赖于细微的、局部的视觉证据,而这些证据无法在静态嵌入中被可靠地保留。 为此,本文提出了 MedLVR(潜在视觉推理框架),在自回归解码中引入了显式的视觉证据状态。MedLVR 不再单纯依赖基于文本的中间推理,而是在解码器中插入一段简短的潜在推理片段,通过复用隐藏状态作为连续的潜在步骤,在生成答案之前迭代地保留和细化与查询相关的视觉证据。 为了提供有效的视觉监督,本文采用了两阶段训练策略:
- ROI(感兴趣区域)监督的微调:将潜在状态与临床相关的图像证据对齐。
- **视觉-潜在策略优化 (VLPO)**:在结果级奖励下,进一步优化潜在推理和答案生成。 在 OmniMedVQA 及五个外部医疗 VQA 基准上的实验表明,MedLVR 始终优于近期的推理基线模型,并在 Qwen2.5-VL-7B 主干网络上将平均得分从 提升至 。结果表明,潜在视觉推理为保留诊断相关的视觉证据及提高医疗 VQA 的可靠性提供了有效机制。
I. 引言 (INTRODUCTION)
虽然视觉语言模型 (VLMs) 在自然图像任务上取得了令人瞩目的成果,但在医疗影像中的应用仍具挑战。临床决策往往依赖极少数细微且高度局部的视觉线索。大多数现有的医疗 VLMs 仅将图像作为上下文进行一次编码,随后主要依赖自回归文本生成进行推理。这导致推理过程容易偏向语言先验,脱离诊断相关的视觉证据,产生看似流利但在图像上缺乏依据的结论。
目前加强视觉线索与推理耦合的方法主要分为两类:
- **“思考图像” (Thinking about Images)**:通过监督微调 (SFT) 提取或蒸馏思维链 (CoT) 轨迹,改善文本空间的推理。但由于它仍在文本描述上进行推理而非直接针对视觉语义,依然容易偏向语言先验。
- **“借助图像思考” (Thinking with Images)**:通过缩放、裁剪或工具调用等外部感知操作重新检查视觉线索。这通常带来巨大的计算开销,且重新获取的视图也未必能持续约束解码过程。
现有医疗 VLMs 存在结构性错配:中间推理主要通过文本空间解码实现,缺乏显式机制在解码过程中持续维护和更新视觉约束。受近期“在连续潜在空间进行中间推理”研究的启发,本文引入了一种面向医疗 VQA 的潜在视觉推理路径。在该路径中,模型在语言解码和潜在更新之间交替,使用潜在状态作为内部载体,在整个生成过程中持续保留和刷新视觉基础约束。
为了稳定潜在推理,本文提出了两阶段训练策略:第一阶段使用 SFT 施加 ROI 级的一致性目标以抑制偏移;第二阶段使用视觉-潜在策略优化 (VLPO),将连续的潜在嵌入视为策略动作,允许策略梯度直接作用于潜在推理步骤。
主要贡献如下:
- 大规模多模态医疗视觉定位语料库:整合了 31 个公共数据集(涵盖 8 种影像模态),构建了约 800,000 个细粒度的问答-边界框对。
- 两阶段优化的潜在视觉推理:提出了面向医疗的潜在视觉推理路径,并开发了结合 ROI 监督微调与 VLPO 的两阶段优化策略。
- 全面的基础推理评估:对涵盖不同范式的多种基线模型进行了基准测试与消融实验。
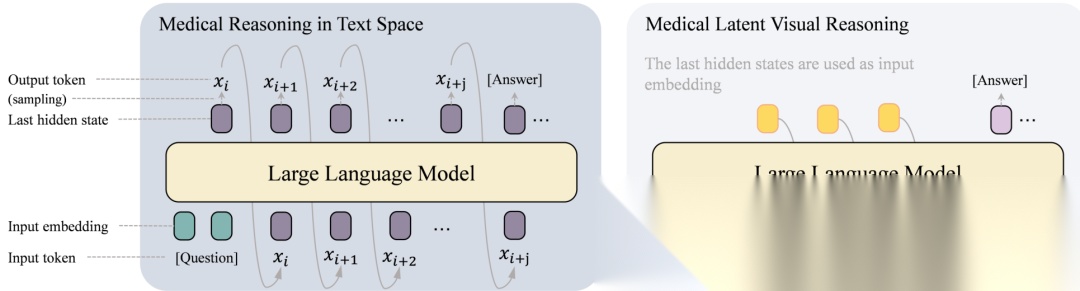 图 1:传统文本空间推理与医疗潜在视觉推理的对比。在 MedLVR 中,最后的隐藏状态被直接复用为输入嵌入以形成潜在推理步骤,从而在生成答案前在隐藏空间进行隐式推理。
图 1:传统文本空间推理与医疗潜在视觉推理的对比。在 MedLVR 中,最后的隐藏状态被直接复用为输入嵌入以形成潜在推理步骤,从而在生成答案前在隐藏空间进行隐式推理。
II. 相关工作 (RELATED WORKS)
- 医疗 VLMs:早期模型(如 LLaVA-Med)通过 SFT 使通用 VLMs 适应临床环境;近期模型强调医疗原生预训练或通过强化学习后训练对齐。但大多对中间线索获取缺乏强约束。
- 使用文本和工具推理:包括多模态 CoT 监督、引入视觉草稿本、以及规划显式的感知动作(如区域重访、工具调用)。这些方法让推理步骤显式化,但也引入了较高的复杂度和计算开销。
- 潜在空间推理:将中间推理从离散的文本 token 转移到连续的潜在嵌入中。这提供了一种扩展测试时计算量的新方法:模型可以分配额外的潜在步骤来细化内部状态,同时保持外部文本输出简洁。
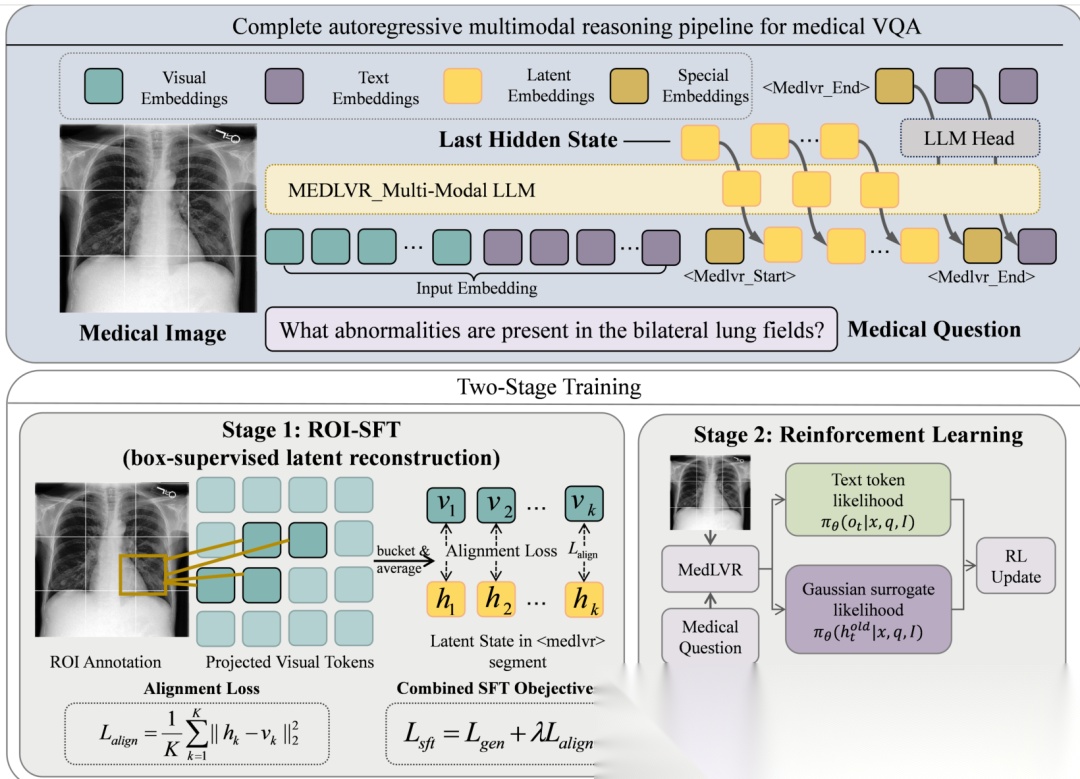 图 2:MedLVR 框架概述。顶部展示了自回归多模态推理管道,在
图 2:MedLVR 框架概述。顶部展示了自回归多模态推理管道,在 <Medlvr_Start> 和 <Medlvr_End> 之间,隐藏状态作为潜在推理步骤被复用。底部展示了两阶段训练策略:ROI 监督潜在对齐(阶段1)和视觉潜在策略优化 VLPO(阶段2)。
III. 方法 (METHOD)
A. 方法概述
MedLVR 遵循标准的多模态 LLM 管道:视觉编码器将图像 映射为视觉 token ,投影器将其对齐到语言潜在空间生成 ,与文本 token 拼接为统一上下文 。 为了打破传统 MLLM 以文本为中心的推理解码,MedLVR 插入了一段潜在推理片段。当模型输出控制 token <Medlvr_Start> 时,解码器暂停 token 发射,转为潜在状态展开(将上一步的隐藏状态直接作为下一步的输入嵌入反馈),在与 相同的潜在空间中迭代优化内部证据表示。完成 步后,模型输出 <Medlvr_End> 并恢复正常的文本答案生成。
B. 两阶段训练管道
**第一阶段:带 ROI 证据对齐的监督微调 (SFT)**在仅使用带有 ROI 注释的数据上微调模型,使潜在片段编码查询相关的视觉证据。 当模型进入 MedLVR 模式时,展开固定长度为 的潜在轨迹 ,其中 。我们将 ROI 对应的视觉 token 提取为 ,并将其划分为 个连续的桶 。第 个潜在位置的监督目标定义为桶内 token 的平均值:
通过最小化均方误差将潜在轨迹锚定到 ROI 证据:
结合标准答案序列 的下一词预测损失:
整体 SFT 目标为:
第二阶段:视觉-潜在策略优化 (VLPO) 的强化学习SFT 后,应用结果级 RL 联合优化潜在展开和答案生成。给定轨迹的标量奖励 ,计算组归一化优势:
-
**文本比率 (Text ratio)**:将记录的潜在状态补丁入上下文中,评估 token 级重要性比率:
-
**潜在比率 (Latent ratio)**:使用高斯代理策略,定义当前策略的潜在状态 与记录状态的偏差:
潜在重要性比率为:
- 联合裁剪目标:
整体 VLPO 目标包含文本损失、潜在损失及 KL 散度惩罚:
C. 解码与优化细节
- 潜在片段解码:推理时,模型进入固定预算 的潜在展开阶段,避免了脆弱的终止决策。
- 轨迹重放:RL 中要求重要性比率在相同的上下文中评估,因此将历史潜在轨迹强制作为共享前缀(重放)。
- 奖励与优势广播:稀疏的序列级奖励转化为优势后,广播给轨迹内的所有文本和潜在位置。
IV. 实验 (EXPERIMENTS)
A. 实验设置
- 数据集:第一阶段使用内部构建的包含 8 个模态、近 80万对数据的医疗定位语料库;第二阶段在 OmniMedVQA 的训练集上进行 RL。
- 外部评估基准:SLAKE, VQA-RAD, PMC-VQA, MMMU (Health & Medicine), 以及 MedXpertQA。
- 实现细节:基于 Qwen2.5-VL-7B-Instruct 初始化,固定视觉塔进行全参数优化;推断时设置潜在步骤预算 。
B. OmniMedVQA 上的主要结果
MedLVR 在 8 种医疗成像模态上取得了最高的平均准确率 (),显著超越了最强零样本通用模型 Qwen2-VL-72B () 和近期推理模型 Med-R1 ()。特别是对 CT () 和 MRI () 表现出极强的性能,且在多模态间表现出更均衡、更稳健的特征。
C. 外部医疗 VQA 基准的泛化能力
在未见过的 5 个外部基准上,MedLVR 较其基础模型 Qwen2.5-VL-7B 有了全面提升(平均得分从 提升至 )。特别是在 MMMU (Health & Medicine) 上提升了 10.2 个绝对百分点。由于未采用外部工具或检索增强,这些纯内部推理的改进验证了潜在视觉推理机制的有效性。
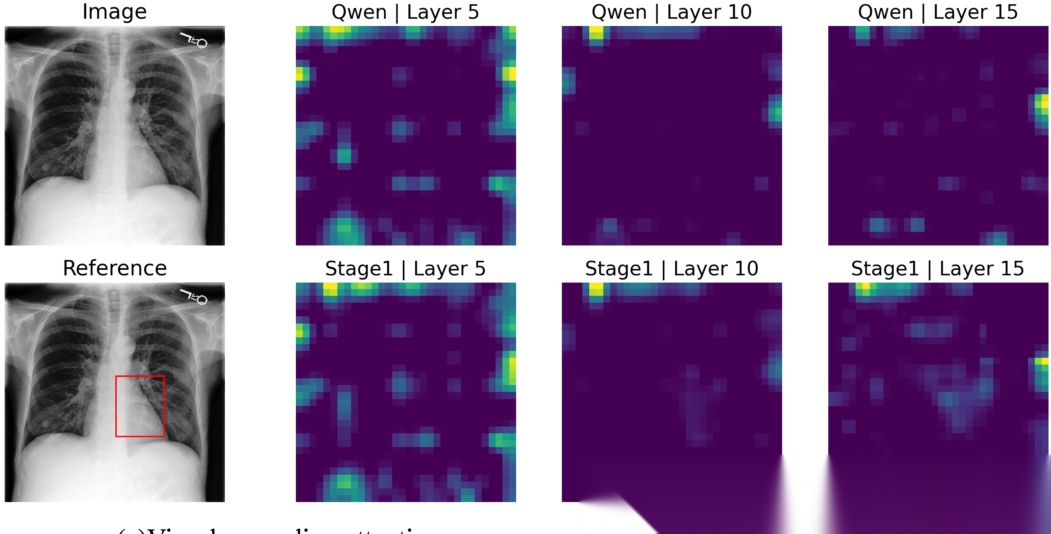
D. 视觉定位行为分析
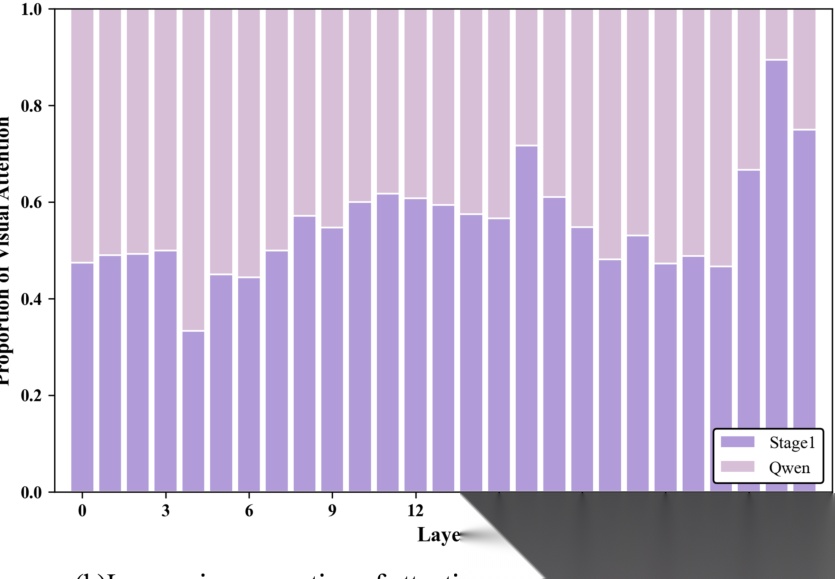 (b) 分配给视觉 token 的注意力层级比例。
(b) 分配给视觉 token 的注意力层级比例。
图 3(a) 可视化表明,与基线模型宽泛且分散的注意力不同,MedLVR 在深层能产生针对临床相关病变区域高度局部的结构化响应。图 3(b) 的层级统计显示,MedLVR 在大多数层级(特别是深层)中为视觉 token 分配了更高比例的注意力,证明了视觉证据在整个解码过程中的持续活跃。
E. 对潜在展开预算的敏感性
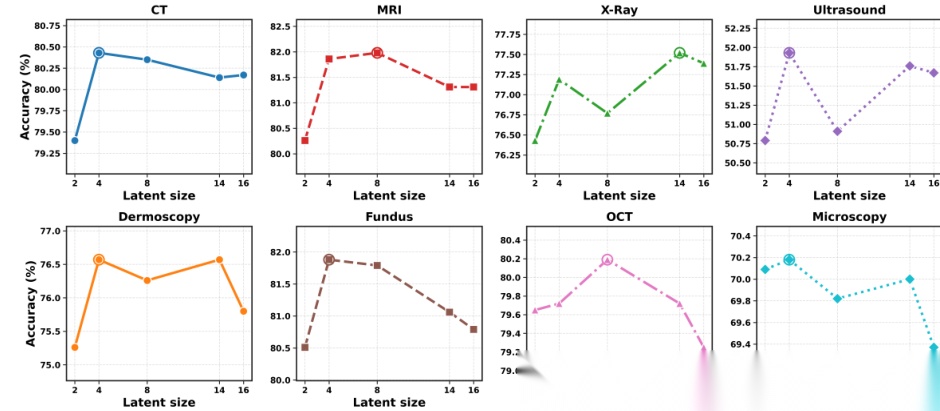 图 5:推理期间不同潜在步数对 8 种医疗成像模态测试准确率的影响。
图 5:推理期间不同潜在步数对 8 种医疗成像模态测试准确率的影响。
研究表明(图5),将潜在大小从 2 增加到适中预算(如 4、8 或 14)可带来一致的性能提升;但进一步增加至 16 并不会带来持续收益,甚至会导致轻微的性能下降。这表明 MedLVR 虽对预算有一定敏感度,但在合理设定的中等潜在步骤下依然稳定。
F. 训练变体比较
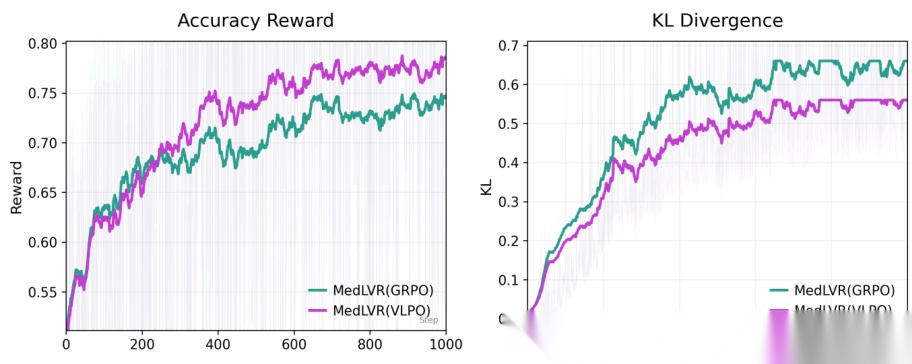 图 4:使用 GRPO 和 VLPO 优化的 MedLVR 训练动态。左:准确率奖励;右:KL散度。VLPO 在保持高准确率奖励的同时呈现出较低的 KL 散度,优化稳定性更好。
图 4:使用 GRPO 和 VLPO 优化的 MedLVR 训练动态。左:准确率奖励;右:KL散度。VLPO 在保持高准确率奖励的同时呈现出较低的 KL 散度,优化稳定性更好。
消融实验(表 IV)显示:单纯引入潜在架构(无 ROI 监督)已能提供有用的中间推理能力;加入 ROI 引导监督进一步增强了效果;而使用 VLPO 进行潜在推理优化取得了最佳结果(在 MMMU-HM 上较普通基线提升了 8.5 分),证明随着推理任务难度增加,显式优化的潜在推理大有裨益。
G. 效率-准确率权衡
评估结果(表 III)表明,生成过长的文本 token 与最终诊断准确率并不正相关。如 MedGemma-1.5 平均生成 102.1 个 token,准确率仅为 ;而 MedLVR 平均仅生成 7.8 个 token,耗时短且达到了最高的 准确率。这表明紧密锚定在视觉证据上的紧凑输出比冗长的文本响应更具优势。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献171条内容
已为社区贡献171条内容

所有评论(0)