【GitHub项目推荐--video-use:用自然语言剪辑视频,Claude Code 的“AI 剪辑师”】⭐⭐⭐
GitHub 地址:https://github.com/browser-use/video-use
简介
video-use 是 browser-use 团队开源的一款“对话式视频编辑”技能。它的理念极其简单:把原始素材扔进文件夹,用自然语言告诉 Claude Code(或 Codex、Hermes 等 Agent)你想要什么,直接拿回 final.mp4。
它彻底颠覆了传统的剪辑流程。你不再需要打开 Premiere 或 Final Cut Pro,也无需面对复杂的时间线和菜单。无论是口播、教程、访谈还是 Vlog,只需一句指令,AI 就能自动完成从素材盘点、粗剪、去口癖、调色、加字幕到最终渲染的全流程。它并非让 LLM 暴力“看”视频帧,而是通过巧妙的“文本+按需视觉”架构,实现了极低 Token 消耗下的专业级剪辑。
主要功能
1. 全自动剪辑流水线
-
智能粗剪:自动识别多段素材,根据语义(而非单纯的时间码)进行拼接。
-
精准去“filler”:自动剪掉“嗯”、“啊”、口误、重复句以及镜头间的尴尬空白,保留自然语流。
-
音频美化:在每个剪切点自动添加 30ms 的音频淡入淡出,消除爆音和突兀感。
-
视觉统一:支持对每段素材进行独立的色彩调级(如电影感暖色、中性冲击感),统一画面风格。
2. “读”视频而非“看”视频的架构
这是 video-use 最核心的技术创新。它通过两层结构,将海量的视频数据压缩为 LLM 可高效处理的“轻量化视图”:
-
Layer 1:音频转录(主视图):利用 ElevenLabs Scribe 将视频转为带词级时间戳和说话人分离的文本。所有素材被打包成一个约 12KB 的
takes_packed.md文件,作为 LLM 推理的主要依据。 -
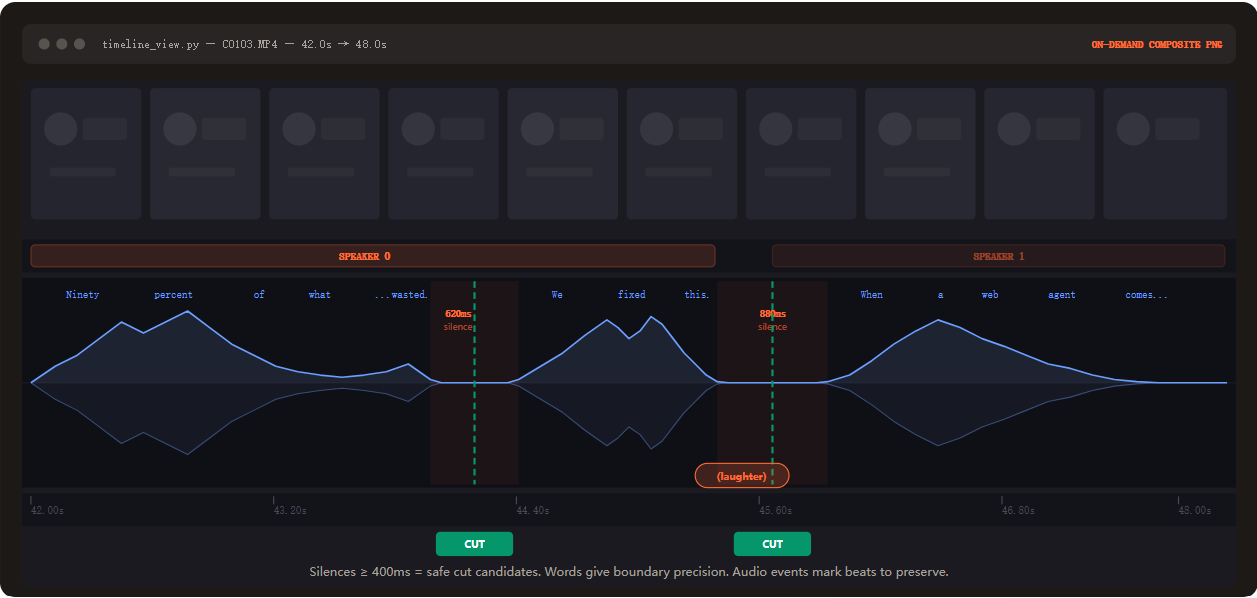
Layer 2:视觉合成(按需):仅在决策模糊时(如判断停顿是否该剪、对比重拍镜头),调用
timeline_view生成一张包含胶片条、波形图和单词标签的 PNG 进行辅助判断。
这种设计使得处理成本从“数千万 Token 的帧噪声”降到了“12KB 文本 + 几张图”,实现了真正的实用化。
3. 质量自闭环
-
自评估机制:渲染完成后,Agent 会在每个剪切点自动检查画面跳变、音频爆音和字幕遮挡。只有通过检查的视频才会呈现给用户,否则会自动修复并重渲染(最多 3 轮)。
-
会话记忆:通过
project.md文件持久化剪辑上下文,支持下次打开 Claude Code 时从上次的进度继续编辑,非常适合长课程或播客的连载剪辑。
安装与配置
前置要求
-
Claude Code / OpenClaw 等 Agent 环境:需支持 Shell 访问和技能加载。
-
FFmpeg:必须安装,用于视频处理。
-
ElevenLabs API Key:用于高精度语音转录(获取地址:https://elevenlabs.io/app/settings/api-keys)。
安装步骤(Agent 自动模式)
推荐方式:直接在 Claude Code 中粘贴以下指令,Agent 会自动完成克隆、依赖安装和技能注册:
“请安装 video-use 技能。这是我的 ElevenLabs API Key:
sk_xxxx。素材目录是~/Videos/my_project。”
安装步骤(手动模式)
如果你倾向于手动控制,或在其他 Agent 中使用:
-
克隆仓库:
git clone https://github.com/browser-use/video-use cd video-use -
安装依赖:
pip install -e . brew install ffmpeg yt-dlp # yt-dlp 用于下载在线素材(可选) -
配置 API Key:
cp .env.example .env # 在 .env 文件中填入:ELEVENLABS_API_KEY=sk_your_key_here -
注册技能(以 Claude Code 为例):
# 创建软链接,将当前目录链接到 Claude 技能目录 ln -s "$(pwd)" ~/.claude/skills/video-use
如何使用
基础工作流
-
准备素材:将所有拍摄的原始视频文件(MP4/MOV)放入一个文件夹(如
raw_footage)。 -
启动 Agent:在终端进入素材目录,启动 Claude Code。
-
下达指令:输入自然语言指令,例如:
“把这些素材剪辑成一个 3 分钟的产品发布视频,去掉所有‘呃’和停顿,加上白色字幕,风格要偏科技感。”
-
确认与交付:
-
Agent 会先扫描素材,生成一份剪辑策略(包括时长预估、片段顺序)并征求你的同意。
-
确认后,Agent 开始全自动转录、剪辑和渲染。
-
成品视频保存在
edit/final.mp4,中间文件(如字幕文件、EDL 剪辑清单)也均在edit/目录下,技能目录本身保持干净。
-
进阶指令示例
-
风格控制:“给这段访谈加一个电影感的暖色滤镜,片头加 5 秒的标题动画。”
-
精细修剪:“保留所有带‘笑’的片段,但剪掉超过 2 秒的沉默。”
-
批量处理:“遍历
videos/下的每个子文件夹,分别把每个文件夹里的素材剪成独立的成品。”
应用场景实例(无代码)
场景一:知识博主的内容量产
痛点:知识博主每周需录制多节课程。手动剪辑(去口癖、加字幕)耗时极长,且重复劳动令人疲惫。
video-use 方案:
-
录制完成后,将视频文件拖入以“课程名”命名的文件夹。
-
在 Claude Code 中输入指令:“按讲课顺序剪辑,去掉所有口头禅,保留知识点连贯性,生成 1080P 带字幕视频。”
-
价值:将数小时的剪辑工作压缩为“一句话+等待渲染”的被动过程,博主可同时处理多个课程文件夹,实现内容量产。
场景二:企业产品更新视频的 CI/CD
痛点:每次 App 迭代,产品团队需要手动录制屏幕、配音、剪辑 Changelog 视频,流程繁琐。
video-use 方案:
-
将 Release Notes(Markdown)、新版 App 截图和配音脚本放入指定目录。
-
在 CI 流水线中集成 video-use,自动触发指令:“用素材生成 45 秒的竖版更新介绍视频,风格与官网一致。”
-
价值:实现了“提交代码即生成宣传视频”的全自动化流程,确保每次发布视频的风格统一且及时。
场景三:播客节目的“精剪”服务
痛点:播客节目通常长达 1-2 小时,包含大量闲聊和停顿,后期剪辑需要人工反复听校,成本极高。
video-use 方案:
-
将录制的多轨音频(或视频)文件放入文件夹。
-
指令:“识别两位主播,剪掉所有非对话的空白和口水词,保留节目核心内容,输出 60 分钟的精剪版。”
-
价值:利用其强大的说话人分离和语义理解能力,将剪辑师从枯燥的“听全片”工作中解放出来,只需做最后的艺术性审核即可。
总结
video-use 不仅仅是一个工具,它代表了一种“Intent-based Editing”(基于意图的剪辑)新范式。它通过将视频抽象为“文本时间线”,让 LLM 能够像处理代码一样处理视频逻辑。对于内容创作者、开发者和企业来说,它是降低视频制作门槛、实现规模化生产的终极利器。
GitHub 地址:https://github.com/browser-use/video-use
核心依赖:ElevenLabs Scribe API(用于高精度转录)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献110条内容
已为社区贡献110条内容

所有评论(0)