模型性能分析GPU工具Profile实践
·
Profile 简介
1️⃣ 什么是 Profile(性能分析)
Profile 是指对程序运行时性能的测量和分析,主要目标是找出程序的瓶颈,例如:
- 哪些函数执行最慢
- 哪些操作占用最多显存或 CPU 时间
- GPU kernel 执行情况
简单来说,就是“测量程序做了多少工作,用了多少时间和资源”。
2️⃣ 为什么要做 Profile
-
发现瓶颈
- 比如在深度学习训练中,卷积层比其他层慢,或者数据加载成为限制因素。
-
优化性能
- 根据 profile 结果调整算法、数据结构、内存布局、并行策略等。
-
资源利用率分析
- CPU/GPU 利用率、内存占用情况。
3️⃣ Profile 的分类
① CPU Profiling
-
测量 CPU 函数执行时间
-
常用工具:
- Python:
cProfile,line_profiler - C/C++:
gprof,perf
- Python:
② GPU Profiling
-
测量 GPU kernel 执行时间、显存占用
-
常用工具:
- CUDA:
nvprof,nsight compute,nvvp - PyTorch:
torch.profiler,torch.cuda.Event
- CUDA:
③ 高级深度学习 Profiling
-
深度学习框架自带 profiler,可以记录每个 layer/operation 时间、内存和 FLOPs
-
例如:
- PyTorch:
torch.profiler - TensorFlow:
tf.profiler
- PyTorch:
4️⃣ Profile 的关键指标
| 指标 | 说明 |
|---|---|
| 执行时间 | CPU/GPU 函数或 kernel 花费时间 |
| 调用次数 | 函数被调用的次数 |
| 内存占用 | RAM 或 GPU 显存使用情况 |
| 吞吐量 | 每秒处理的数据量(samples/sec) |
| FLOPs | 每秒浮点运算次数,衡量算力消耗 |
5️⃣ 在深度学习中的典型应用
-
训练优化:
- 找出训练过程中最慢的 layer
- 优化数据加载或混合精度训练
-
GPU kernel 调优:
- Triton / CUDA kernel 的执行时间
- 使用事件或 profiler 观察 warp/线程利用率
-
模型部署分析:
- 推理延迟分析
- CPU/GPU 并行优化
实践
PyTorch / OpenTriton / CUDA 中做 Profile(性能分析) 的样例代码,涵盖 CPU/GPU 时间、CUDA kernel 以及 PyTorch 内置 profiler。这里用 PyTorch 的 torch.profiler 举例,它适合深度学习模型的 profiling。
1️⃣ PyTorch Profiler 基本示例
import torch
import torch.nn as nn
import torch.optim as optim
import torch.profiler
# 模型
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(1024, 512)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(512, 256)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 输入数据
x = torch.randn(64, 1024, device='cuda')
model = SimpleModel().cuda()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# PyTorch Profiler
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log'),
record_shapes=True,
with_stack=True,
profile_memory=True,
with_flops=True
) as prof:
for step in range(5):
optimizer.zero_grad()
y = model(x)
y.sum().backward()
optimizer.step()
prof.step() # Profiler 轮次推进
print("Profile 完成, TensorBoard 查看 ./log")
说明:
tensorboard_trace_handler('./log')会生成 TensorBoard 可视化日志。schedule可以控制等待、预热和采样阶段。record_shapes=True可以记录输入 tensor 形状。with_stack=True可以查看调用堆栈。profile_memory=True可以分析显存使用情况。
运行后:
tensorboard --logdir=./log
可以看到 GPU kernel 时间分布、CPU 调用情况、内存使用等。
2️⃣ 分析 导出的json文件
https://ui.perfetto.dev/#!/viewer?local_cache_key=0-json
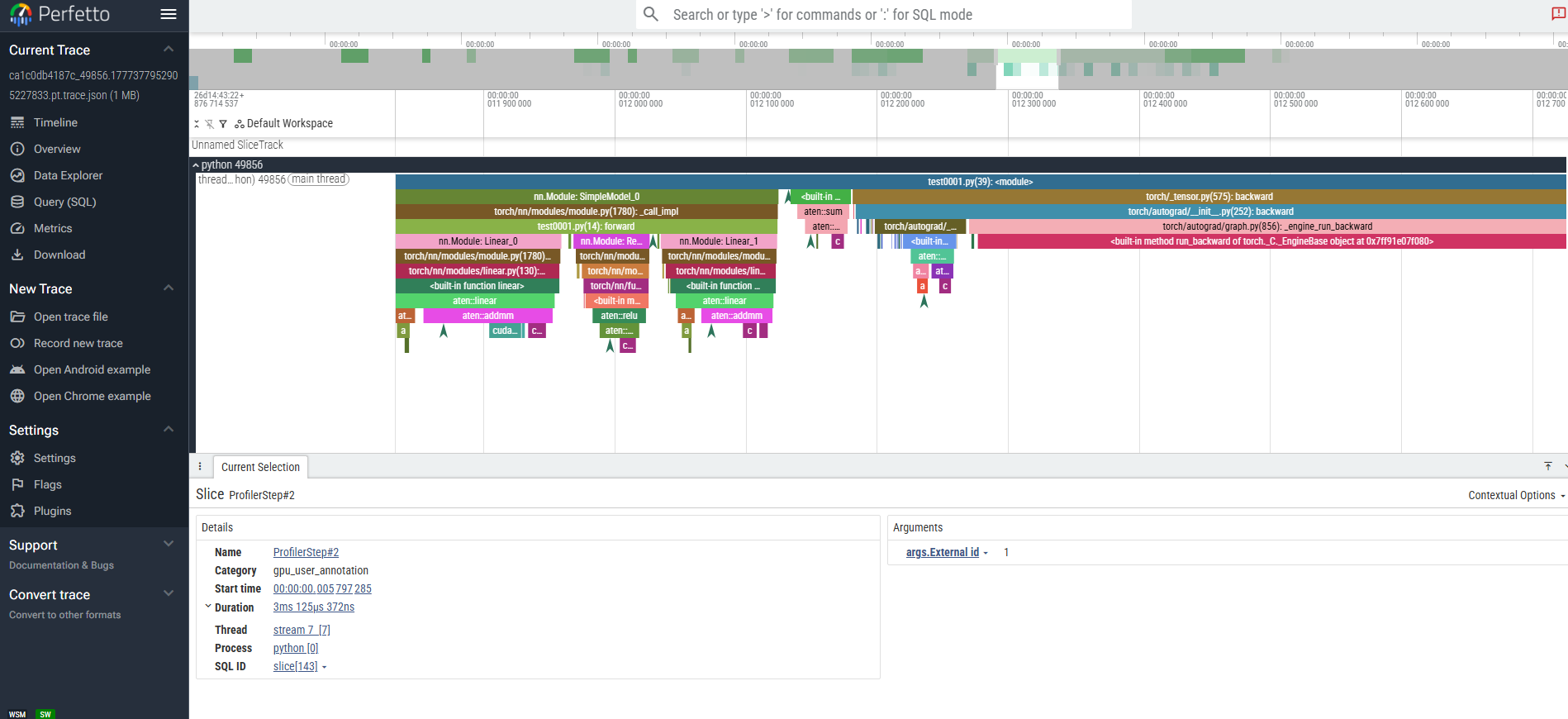
json 文件
https://download.csdn.net/download/liuyunshengsir/92836530


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)