【大模型-世界模型】LingBot-World: Advancing Open-source World Models
Website: https://technology.robbyant.com/lingbot-world
Github: https://github.com/robbyant/lingbot-world
Checkpoints: https://huggingface.co/robbyant/lingbot-world
摘要
我们推出 LingBot-World,一款基于视频生成的开源世界模拟器。作为顶级世界模型,LingBot-World 具备以下特性:(1) 它能够在各种环境中保持高保真度和稳健的动态特性,包括写实风格、科学背景、卡通风格等等。(2) 它能够实现分钟级的时间尺度,同时保持上下文的一致性,也就是所谓的“长期记忆”。(3) 它支持实时交互,在每秒生成 16 帧的情况下,延迟低于 1 秒。我们公开代码和模型,旨在缩小开源和闭源技术之间的差距。我们相信,此次发布将为社区带来丰富的实际应用,涵盖内容创作、游戏和机器人学习等领域。
1 Introduction
长期以来,人工智能理解和模拟物理世界的能力[41, 84]一直被视为计算机视觉和机器学习领域的“圣杯”。我们目前正见证生成模型范式的转变,从静态的“文本到视频”生成[7-9, 64]过渡到更具雄心的“文本到世界”模拟[2, 5, 24, 27, 28, 45, 53, 68, 69, 73, 74]。尽管最先进的视频生成模型[25, 63, 71, 72, 77, 90]在渲染短小精悍、视觉连贯的视频片段方面取得了显著的保真度,但它们本质上仍然是“梦想家”,而非真正的“模拟器”[9, 35]。他们基于统计相关性臆想出像素变化,但往往缺乏对潜在规律的深刻理解,例如因果关系、物体恒存性以及交互的后果。弥合这一差距至关重要,因为必须从生成被动的影像素材过渡到构建能够合成持久、交互式且逻辑一致的环境的世界模型。
(英文写的好好!)
The pursuit of artificial intelligence capable of understanding and simulating the physical world [41, 84] has long been considered a “holy grail” in computer vision and machine learning. We are currently witnessing a paradigm shift in generative models, transitioning from static “text-to-video” generation [7–9, 64] to the more ambitious goal of “text-to-world” simulation [2, 5, 24, 27, 28, 45, 53, 68, 69, 73, 74]. While state-of-the-art video generation models [25, 63, 71, 72, 77, 90] have achieved remarkable fidelity in rendering short, visually coherent clips, they fundamentally remain “dreamers” rather than “simulators” [9, 35]. They hallucinate pixel transitions based on statistical correlations but often lack a grounded understanding of the underlying laws, such as causality, object permanence, and the consequences of interaction. Bridging this gap makes it essential to transition from generating passive footage to building world models capable of synthesizing persistent, interactive, and logically consistent environments.
然而,从视频生成到世界模拟的过渡[1, 27, 78, 80, 89]面临着诸多挑战。
首先,高质量的交互式数据十分稀缺;与被动的网络视频不同,能够捕捉智能体决策与环境反应之间复杂相互作用的数据难以扩展[22, 48]。其次,如何在长达数分钟而非仅仅几秒钟的轨迹中保持叙事和结构的连贯性,对于标准的扩散架构而言仍然是一个尚未解决的难题,因为它们会遭受“灾难性遗忘”[7, 8]的影响。最后,传统扩散采样的计算量巨大,使得实时控制成为不可能,从而限制了大多数现有模型只能进行离线渲染,而无法实现实时交互。此外,该领域最先进的解决方案仍然是专有的,这种壁垒阻碍了更广泛的社区创新。
However, the transition from video generation to world simulation [1, 27, 78, 80, 89] faces significant challenges.
First, high-quality interactive data are scarce; unlike passive web videos, data that captures the complex interplay between an agent’s decisions and the environment’s reaction is notoriously difficult to scale [22, 48]. Second, maintaining narrative and structural coherence over minute-long trajectories rather than mere seconds—remains an unsolved challenge for standard diffusion architectures, which suffer from “catastrophic forgetting” [7, 8]. Finally, the computational prohibitiveness of traditional diffusion sampling makes live control impossible, limiting most existing models to offline rendering rather than real-time interaction. Furthermore, the most advanced solutions in this space remain proprietary, creating a divide that hinders broader community innovation.
在本报告中,我们介绍了 LingBot-World,这是一个全面的开源框架,旨在打破这些壁垒,并使大规模世界模型的研究更加普及。
LingBot-World 不仅仅是一个生成模型;它是一个整体系统,旨在学习虚拟世界的动态并实时渲染它们。LingBot-World 基于三大战略支柱,这些支柱使我们的模型区别于现有解决方案:
In this report, we present LingBot-World, a comprehensive, open-source framework designed to shatter these
barriers and democratize the research of large-scale world models. LingBot-World is not merely a generative model; it is a holistic system engineered to learn the dynamics of virtual worlds and render them in real-time. LingBot-World is founded upon three strategic pillars that distinguish our model from existing solutions:
- 我们构建了一个具有层级语义的可扩展数据引擎。为了解决数据瓶颈问题,我们构建了一个混合引擎,该引擎能够摄取多种数据源,包括真实世界的视频素材、游戏引擎录制的数据以及来自虚幻引擎的合成数据。至关重要的是,为了解决原始数据缺乏细粒度控制的问题,我们引入了一种层级式字幕生成策略[15, 16, 82]。通过生成不同的叙事性字幕、场景静态字幕和密集时间字幕,我们有效地将运动控制与静态场景生成分离,从而使模型能够学习精确的动作相关动态。
A scalable data engine with hierarchical semantics. We address the data bottleneck by constructing a hybrid engine that ingests diverse data sources, including real-world footage, game engine recordings, and synthetic data from Unreal Engine. Crucially, to solve the lack of fine-grained control in raw data, we introduce a hierarchical captioning strategy [15, 16, 82]. By generating distinct narrative, scene-static, and dense temporal captions, we effectively disentangle motion control from static scene generation, allowing the model to learn precise action-contingent dynamics.
- 多阶段进化训练流程。我们提出了一种渐进式训练策略,将基础视频生成器演化为交互式模拟器,该策略包括三个阶段:预训练、中期训练和后训练。在第一阶段,通过预训练建立鲁棒的通用视频先验,以支持高保真纹理生成。在第二阶段,即中期训练中,我们采用混合专家(MoE)架构[17, 19, 36, 77]来融合世界知识并实现动作可控性,重点关注“长期记忆”并在较长的时间范围内保持环境一致性。在第三阶段,我们优化模型以实现实时推理。通过因果注意力自适应和少步蒸馏[44, 59, 65],双向扩散模型被后训练成一个高效的自回归系统[10, 30],延迟低于一秒。
- LingBot-World 为具身人工智能提供了多种应用。除了视觉合成之外,它还可作为下游应用的实用测试平台 [1, 6, 20, 26, 29, 57, 58, 78, 92]。它支持可提示的世界事件,允许用户通过文本提示语义地引导全局条件和局部动态。此外,它还有助于训练动作代理,并能从生成的视频中实现一致的 3D 重建 [34, 50, 83],从而验证其几何完整性。

为了更好地理解我们的贡献,表 1 将 LingBot-World 与近期的一些交互式世界模型进行了比较。虽然像 Genie 3 [5] 和 Mirage 2 [73] 这样的系统已经取得了长足的进步,但它们往往在动态程度上有所妥协,或者仍然是闭源的。LingBot-World 的独特之处在于,它提供了通用的领域能力、较长的生成周期以及实时的高动态程度,并且完全开源。通过发布代码和模型权重,我们旨在激发新一轮的创新浪潮,赋能社区构建下一代虚拟世界。
通过开源 LingBot-World,包括我们的模型权重和推理代码库,我们旨在掀起新一轮创新浪潮。我们诚邀社区成员超越被动观看视频的模式,加入我们,共同构建下一代无限、可玩、交互式的虚拟世界。
2 Data Engine
构建一个能够稳健处理新颖视角、复杂动态和长远规划的世界模型,需要严谨的数据策略。我们通过将数据引擎构建成一个包含三个协同组件的统一管道来解决这个问题:
(i)数据采集,(ii)数据分析,以及(iii)数据描述。
(i) data acquisition, (ii) data profiling, and (iii) data captioning.
数据采集
为了构建该系统的基础,我们的数据采集阶段采用了一种混合采集策略,旨在确保获得丰富、高质量且交互式的训练语料库。首先,我们精心整理了一个大规模的高质量、多样化视频数据集,其中包含第一人称视角[17, 22]和第三人称视角[4, 66]的人类、动物和车辆视频。其次,为了捕捉精确的动作相关动态,我们收集了游戏数据,其中RGB帧与用户控制输入(例如W、A、S、D)和相机参数严格配对。最后,我们使用虚幻引擎(UE)[18]开发了一个合成渲染管线。通过将授权资源与自定义环境集成,我们设计了一个自动化渲染工作流程,该流程可以生成无碰撞、随机但合理的相机轨迹,从而生成与真实相机内参和外参一致的RGB数据流。其总体思路如图2所示。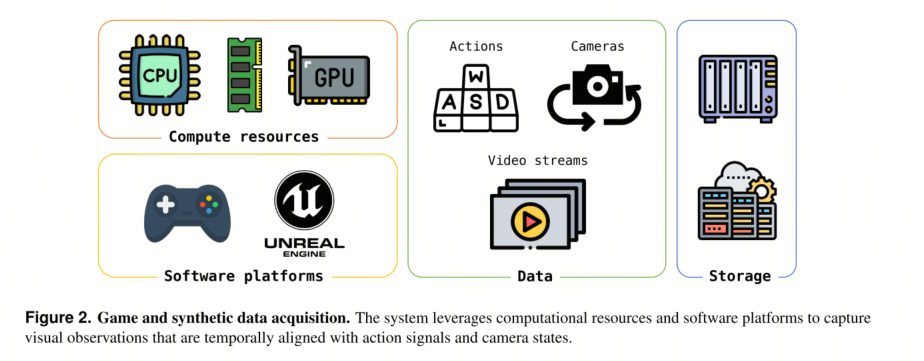
为了确保我们的游戏数据涵盖各种行为和环境复杂性,我们建立了一套标准化的数据采集策略,分为四个主要类别:
• 导航:涵盖虚拟世界中的一般移动。– 自由导航:允许玩家沿随机轨迹进行随机探索;– 循环漫游:记录闭环路径或多点往返;– 过渡导航:针对高变化性的场景变化,例如离开建筑物或在不同的室内环境之间切换。
• 观光:侧重于精细观察。这包括仔细检查静态和动态环境中的场景细节,以及围绕地标物体旋转以捕捉多视角的一致性。
• 长尾场景:针对标准场景中通常缺失的罕见但关键的数据分布。
– 静止观察:从固定位置采集数据,不进行平移运动,包括 360 度旋转以绘制静态环境地图,以及固定角度凝视以记录随时间变化的动态元素(例如人群或交通)。
– 后退导航:在保持对周围环境感知的同时进行撤退。
• 世界交互:捕捉因果性的智能体-环境关系,从局部动作(例如,拾取物品、开门)到引发重大状态变化的重大事件(例如,战斗、破坏)。
为了使工作流程包含多样化且逼真的运动,轨迹生成阶段采用两种不同的模式,旨在平衡随机多样性与行为真实性。
• 程序化路径生成:此模式自主合成复杂的摄像机运动,以最大程度地探索环境,主要采用两种算法策略:– 几何图案合成:系统生成结构化轨迹,包括不同尺度的随机矩形路径以及以不同角速度进行的多圈 360° 旋转。这些图案提供全面的全景上下文,并通过重复的环境覆盖增强长期的空间一致性。
– 多点插值:此策略使用互惠回望过渡对随机空间路径点进行采样,从而增强关系空间记忆。
• 真实世界轨迹导入:此模式将从物理设备捕获的路径直接映射到虚幻引擎中。它融入了真实的人类浏览行为,例如反复扫描房间或重新访问感兴趣的对象,同时保留了手持运动的微妙差别(例如,自然的抖动和有机的速度变化),以反映实际用户交互的随机性和时间复杂性。
数据分析
数据采集完成后,数据分析组件充当关键的标准化层。为了统一各种输入数据(例如,与游戏或UE数据相比,普通视频缺乏摄像头信息),我们首先利用最先进的姿态估计模型[33, 61, 62]为摄像头内参和外参生成伪标签。然后,系统执行基本滤波,根据分辨率和时长剔除不合格的样本,同时采用现成的算法将视频片段分割成便于训练的片段[11, 67]。最后,我们利用视觉语言模型(VLM)[54, 56, 70]进行语义分析,评估视觉质量、运动幅度、场景透视等属性,从而对滤波后的数据集进行优化。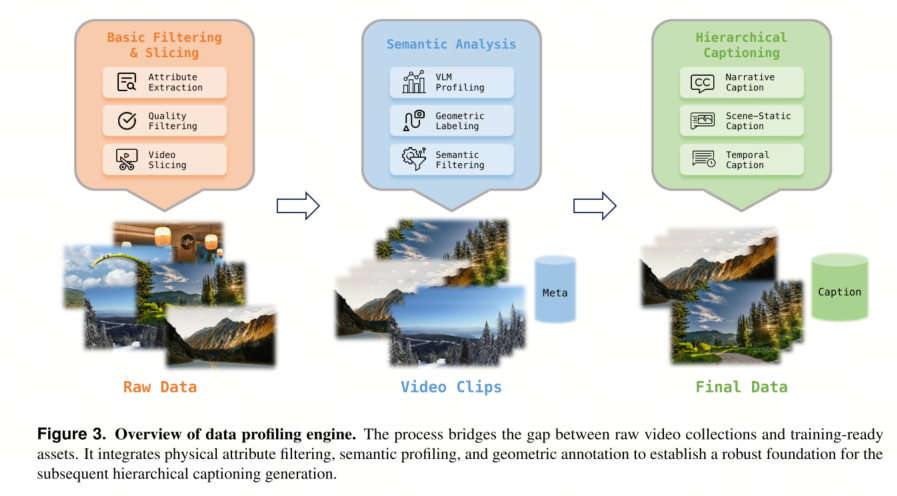
基本过滤与时间分割 在基础层面,我们提取视频时长、分辨率和文件大小等基本文件属性,以建立数据集的基本索引。基于这些元数据,我们剔除不合格的样本,特别是分辨率不足或时长不够的视频。随后,我们利用 Koala [82] 提供的切片算法以及 TransNet v2 [67] 将视频分割成便于训练的片段。这种方法保留了每个片段的语义连贯性和一致性,确保为下游处理提供高质量的视频源。
语义分析
接下来进行语义分析,我们采用内部视觉语言模型 (VLM) 提取一套全面的过滤属性。具体来说,该模型评估视觉质量(包括亮度、清晰度),量化运动幅度,并识别场景类型和视角(例如,第一人称视角与第三人称视角)。这些语义描述符为下游处理中的精确数据选择提供了可靠的基础。
为了解决原始视频中几何信息缺失的问题,我们进一步利用 MegaSAM [37] 为缺乏几何信息的视频生成相机姿态标注。这确保所有选定的样本都具备训练所需的必要 3D 结构先验信息。
最终,这种两阶段分析策略弥合了原始视频集和可用于训练的资源之间的差距。
通过将基本物理属性与高级语义描述符和固有几何数据相结合,我们为后续的训练阶段奠定了坚实的基础。
数据标注
在数据采集和过滤之后,数据标注模块最终使用视觉语言模型(VLM)[42, 75]为语料库添加语义元数据。我们采用分层标注策略,生成三个不同的描述层,以确保对视频内容进行多粒度的理解。这包括:将环境和镜头运动融入整体故事的综合叙事性描述;专注于环境的场景静态描述;以及提供特定事件的精细时间序列描述的密集时间性描述。
-
全面叙述性字幕:这种类型的字幕提供对整个视频的全面、详细的描述,将视觉环境与摄像机的轨迹和时间演变交织在一起,起到全局语义提示的作用。

-
场景静态描述(动作解耦):此描述仅关注静态环境和美学细节,刻意省略了对镜头运动或角色动作的描述。这种设计对于在世界模型中将运动控制与场景生成解耦至关重要。

-
密集时间字幕:这种类型通过将视频分割成区间并详细描述每个区间内的事件,提供精细的、时间对齐的描述,以支持时间对齐训练。

这种层级式字幕框架确保每个视频片段都配有丰富且结构化的文本注释。这些注释不仅捕捉静态的视觉细节,还编码了动态演变和拍摄意图。
3 LingBot-World
3.1 Formulation
我们将世界模型构建为一个条件生成过程,该过程模拟由智能体动作驱动的视觉状态的演化。令 V = {x1, x2, . . . , xT} 表示视频帧序列,其中 xt ∈ RH×W×C 表示时间步 t 的状态。令 A = {a1, a2, . . . , aT} 表示相应的控制信号(动作)序列。
LingBot-World 的目标是学习一个参数模型 θ,该模型能够近似描述环境的转换动态。
我们并没有将模型严格限制为单步预测,而是将目标函数概括为:在给定历史帧和当前控制信号的情况下,最大化未来状态的似然性:
其中 L ≥ 1 表示预测范围。为了弥合标准视频生成器与高效交互式世界模拟器之间的差距,我们提出了一种多阶段演化策略,将学习过程分解为三个渐进阶段:基础阶段、知识注入阶段和交互准备阶段。
3.1.1 Stage I: Pre-Training — Establishing the General Video Prior
在初始阶段,我们专注于对自然视频序列的无条件分布进行建模,并建立视觉动态的通用先验。为此,我们利用了一个在大规模开放域视频数据上预训练的基础视频生成器,这赋予了 LingBot-World 强大的时空连贯性和开放域语义理解能力。该预训练模型能够合成高保真度的物体纹理和连贯的场景结构,作为后续交互动态的通用视觉“画布”,而非编码特定任务的物理规则。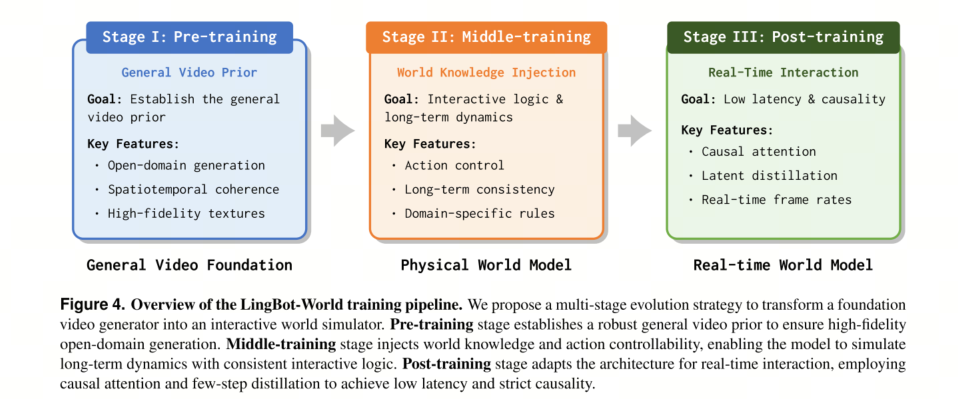
3.1.2 Stage II: Middle-Training — Injecting World Knowledge & Long-Term Dynamics
在中间阶段,我们将初始生成器升级为双向世界模型。根据我们的一般公式(1),
设置 t = 0 符合双向范式,使模型能够首先捕捉全局时间依赖关系,而不受因果历史的约束。虽然预训练模型在生成高保真视频方面展现出巨大潜力,但它仅限于短视频片段,且缺乏交互逻辑。因此,我们使用专门的数据引擎进一步训练 LingBot-World,以融入动作控制、时间一致性和领域特定规则。此阶段引入的关键改进如下:
长期一致性:为了增强记忆容量,该模型使用扩展视频序列进行训练。通过观察长期的上下文帧,LingBot-World 能够学习如何缓解视频生成过程中的“遗忘”问题,从而确保生成的视觉世界在数分钟的游戏过程中保持连贯性,而不仅仅是几秒钟。
• 动作可控性:为了引入交互能力,我们通过自适应归一化[77, 84]将用户定义的动作信号融入模型。基于这些显式的动作输入,LingBot-World 生成一个不再受随机噪声驱动,而是遵循用户指定指令的视觉世界。备注:在此阶段,该模型作为一个整体世界模拟器运行,能够根据动作生成高保真度的未来轨迹,但它依赖于双向注意力机制,这对于实时部署而言计算量较大。
3.1.3 Stage III: Post-Training — Causal Architecture Adaptation & Few-Step Distillation
最后阶段将我们的双向世界模型转化为一个高效的自回归系统,能够实现实时交互式生成。通过将公式 (1) 推广到 t ≥ 0 并以过去的上下文 x<t 为条件,我们的模型无缝过渡到因果范式,从而实现了交互所需的逐步推理。虽然第二阶段模型能够准确地捕捉世界动态,但由于需要完整的时序关注和多步迭代去噪,标准的双向扩散模型在计算上过于庞大,难以部署。我们通过以下方式解决这些限制:
• 因果架构自适应:我们用块因果注意力机制取代了完整的时序注意力机制,结合了块内局部双向依赖关系和块间全局因果关系。该模型从高噪声专家(第二阶段)初始化,并采用混合时间步长协议进行训练,以弥合专家专业化差异。这使得我们能够在保持时间一致性的同时,通过键值缓存实现高效的自回归生成。
少步蒸馏:我们采用分布匹配蒸馏(DMD),并结合自展开训练和对抗优化[39, 86, 87]。这种双重方法蒸馏出一个少步生成器,该生成器能够在较长的展开过程中保持动作条件动态和视觉保真度,而不会出现明显的漂移。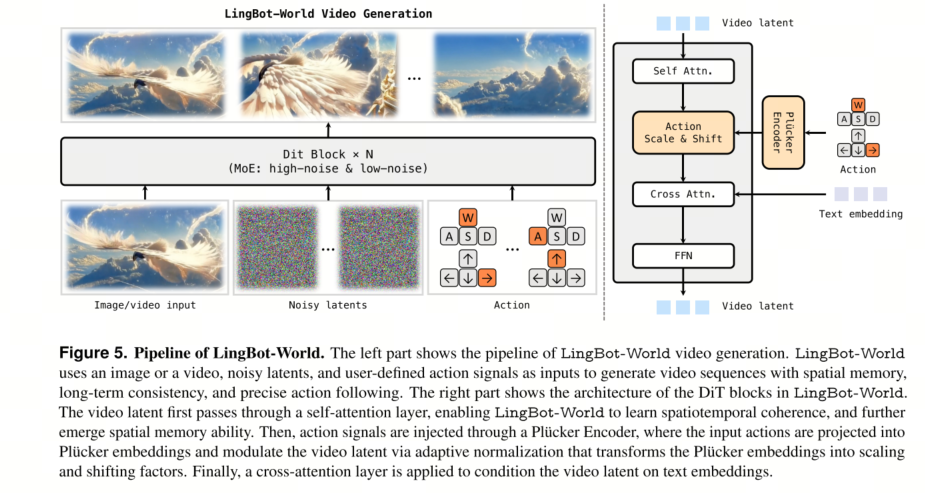
3.2 Pre-Training
预训练阶段的目标是找到一个预训练模型,为后续阶段提供强大的视频先验信息,从而使 LingBot-World 能够生成多样化、连贯且高保真的视频。近年来,世界模型(例如 Genie 3 [5])的进步[6, 13, 26]证明了利用强大的视频基础模型初始化交互式世界模型的有效性。这些视频基础模型[25, 52, 60, 69, 76]可以提供强大的内部先验信息(例如视觉真实感、物体恒存性和时间动态性),从而显著加速交互式物理和可控视觉世界生成的学习。为此,我们采用 14B 参数的 Wan2.2 图像到视频扩散模型[77]作为预训练模型,该模型特别适合捕捉复杂的时空一致性并生成高保真视频内容。
3.3 Middle-Training
在中间训练阶段,预训练的视频扩散模型被转换为双向世界模型,以生成连贯且交互式的视觉世界。虽然预训练模型在高保真视频合成方面表现出色,但它本质上仅限于短视频片段,并且缺乏与用户自定义动作信号交互的能力。为了克服这些局限性,我们利用所提出的数据引擎(第2节)生成动作相关的、时间上扩展的视频序列,用于中间训练阶段。该阶段包含三个主要部分。首先,训练一个基础世界模型,使其获得长期时间一致性和涌现的空间记忆,从而确保生成世界的稳定性(第3.3.1节)。其次,我们通过将用户自定义的动作信号注入到DiT模块中,对该基础世界模型进行微调,以支持动作相关的生成,从而实现可控的动态特性(第3.3.2节)。第三,由于训练基础世界模型需要大量的计算资源,我们实现了一个并行架构,能够在保证GPU内存消耗在合理范围内的同时,实现高效训练(第3.3.3节)。通过这一中间训练阶段,LingBot-World逐步学习长期时间一致性、空间记忆和精确的动作条件动力学,从而弥合了随机视频生成与交互式、可控世界建模之间的差距。
3.3.1 Fundamental World Model
如图 5 所示,LingBot-World 以图像或视频、带噪声的潜在变量以及用户自定义动作作为输入,生成可控的视觉世界,而非随机合成视频。我们首先训练一个基础世界模型,该模型在给定任意初始状态(即单张图像或视频)的情况下,能够生成兼具长期视频一致性和空间记忆的视觉世界。训练策略如下:
Mixture-of-experts (MoE) architecture.LingBot-World 借鉴了 Wan2.2 图像到视频扩散模型 [77] 的 MoE [51] 架构,该模型已验证了 MoE 架构的有效性,LingBot-World 也采用了 MoE 设计,在保持推理成本基本不变的情况下提升了模型性能。由于不同的去噪阶段各司其职,LingBot-World 采用了一种针对扩散过程定制的双专家设计:在早期时间步激活的高噪声专家专注于建模全局结构和粗略布局,而在后期时间步激活的低噪声专家则负责精细化空间和时间细节。每个专家包含约 140 亿个参数,因此模型总参数量为 280 亿,但每个去噪时间步仅激活一个专家。这种设计使得推理时间和 GPU 内存消耗与密集的 140 亿模型相当。
Progressive curriculum training. 为了使 LingBot-World 能够实现长期视频一致性和空间记忆,我们采用了一种渐进式课程训练策略。在第一轮训练中,我们使用 5 秒的视频序列来训练基础世界模型,并拓宽其内部生成域,因为预训练模型受限于较窄的分布。然后,我们将训练时长从 5 秒逐步延长至 60 秒,使基础世界模型能够学习长期时间一致性并促进空间记忆的出现。此外,我们根据视频时长的增加逐步调整流偏移量。这种设计的动机源于以下观察:长视频生成需要更加重视高噪声时间步,这些时间步负责对全局场景结构进行建模。增加高噪声时间步的比例有助于在更长的时间范围内稳定场景级结构,从而减少漂移并提高长视频生成性能。
Multi-task training. 为了使 LingBot-World 能够从任意初始条件预测未来世界状态,我们采用了一种多任务训练范式,该范式融合了图像到视频和视频到视频(即视频连续性)两个目标。这些任务对应于不同形式的初始状态:图像到视频任务使基础世界模型能够从单个静态帧推断未来的动态变化,而视频到视频任务则通过从历史序列预测未来帧,从而实现对已观测运动的外推。通过联合优化这些互补的任务,模型学习到一个统一的世界转移函数,该函数能够泛化到各种不同的初始条件,从而实现从任意时间点出发对未来世界状态的稳健预测。
3.3.2 Action-Conditioned World Model
在训练基础世界模型以建立长期时间一致性和空间记忆之后,我们进一步微调模型以支持交互式控制。此阶段通过注入用户自定义的动作信号,将视频生成器转换为响应式世界模拟器。
动作表示。为了实现对生成环境的精确控制,我们采用了一种混合动作表示策略,该策略结合了连续的相机旋转和离散的键盘输入(例如 W、A、S、D)。具体来说,我们使用 Plücker 嵌入来表示相机旋转,它提供了一种适用于连续 3D 变换的几何表示。同时,离散的交互被编码为多热向量。这两种模态通过沿通道维度的拼接进行融合。这种混合表示确保模型既能处理平滑的视角变化,也能处理清晰的逻辑状态转换。
动作注入机制。为了在不破坏预训练视觉先验的情况下将这些动作信号融入扩散过程,我们采用了一种自适应层归一化(AdaLN)机制[84]。融合后的动作嵌入被投影并注入到DiT模块中。这使得动作信号能够动态地调节归一化特征,从而引导去噪过程生成与指定动作一致的视频帧。
微调范式。我们采用一种参数高效的微调策略来保持基础模型的生成质量。具体来说,我们冻结了预训练基础世界模型的主要DiT模块,仅对新添加的动作适配器层(包括动作嵌入投影和AdaLN参数)进行微调。这种设计主要基于两个动机:(1)它有效地将固有的视频生成能力与动作控制能力解耦。(2)由于高质量的动作标注数据通常稀少或为合成数据(通过第2.1.2节中提到的数据引擎生成),对密集模型进行完全微调存在灾难性遗忘或基础视觉质量下降的风险。冻结骨干网络可以确保模型在学习跟踪控制信号的同时,保持其高保真视频合成能力。
3.3.3 Parallelism Infrastructure
在时长一分钟的视频序列上训练拥有 280 亿参数的基础世界模型 LingBot-World,对 GPU 内存的要求极高。这是由于模型规模庞大、词元长度较长,以及梯度计算、优化器状态管理和激活检查点等内存密集型操作共同造成的。为了克服这些挑战,我们实现了一个并行架构,能够高效地将计算和内存分配到多个 GPU 上。
为了高效训练拥有 280 亿参数的 LingBot-World 模型,我们采用了完全分片数据并行 2 (FSDP2) [91] 来实现可扩展的数据并行。FSDP2 采用完全分片方案,每个 GPU 仅存储模型参数、梯度和优化器状态的一部分,从而能够训练原本会超出单 GPU 内存限制的大规模模型。此外,通过通信与计算的重叠以及利用其他系统级优化,FSDP2 能够实现高训练效率,并且随着模型规模和 GPU 数量的增加,吞吐量也能保持近乎线性的增长。
上下文并行(CP)。为了缓解长标记带来的内存瓶颈,我们采用了 Ulysses [32] 作为上下文并行策略。Ulysses 通过沿时间(序列)维度对输入张量进行分区,并将这些分区分布到多个 GPU 上,从而引入了序列并行。在注意力计算过程中,一种高效的全对全集体通信模式会重新分配必要的激活值,使得每个设备都能在其序列分片上本地计算注意力。通过这种方式对序列维度进行分片,每个 GPU 用于激活值和注意力相关中间数据的内存占用显著降低,从而使 LingBot-World 能够并行处理长序列。
3.4 Post-Training
在训练后阶段,我们将双向世界模型转换为能够实时生成交互式内容的高效自回归模型。这种转换解决了在实时应用中部署双向注意力机制的计算限制,同时保留了中期训练阶段学习到的丰富动态特性。我们的训练后方法包含两个关键阶段。首先,我们通过扩散强制机制(第3.4.1节)[12]将双向架构适配到因果框架中。其次,我们采用结合长时域训练的少步蒸馏方法,将教师模型的能力迁移到学生模型(第3.4.2节)[30, 39]。在整个过程中,我们优先考虑保留两个关键能力:保持精确的动作条件动态建模,并确保在长时间序列中保持视觉保真度,避免累积漂移。
3.4.1 Causal Architecture Adaptation
模型初始化。回顾一下,我们中间训练的模型是一个混合专家图像到视频扩散模型,由两个顺序专家组成:一个高噪声专家和一个低噪声专家。每个专家都专注于对扩散过程中的特定时间步长范围进行去噪。为了简化和高效地进行训练和推理,我们使用高噪声专家初始化因果学生模型,因为它具有更优异的动态建模能力。从我们中间训练的模型进行初始化,通过渐进式课程学习,具有固有的优势。该模型已经能够处理可变长度的标记序列,这使得我们的因果自适应更加稳定,并且能够泛化到不同长度的展开。实验评估证实,与低噪声专家相比,从高噪声专家进行自适应能够产生更优异的动作条件动态建模。
架构调整。我们根据近期自回归视频蒸馏框架[14, 60]将双向教师模型调整为因果世界模型。具体而言,我们用块因果注意力取代了完整的双向时间注意力,块因果注意力结合了局部双向注意力和全局因果约束,以平衡建模能力和自回归要求[30, 88]。在每个时间块内,词元进行双向关注,以捕捉短程时间依赖性并保持相邻帧之间的局部一致性。在时间块之间,注意力受到因果限制,使得当前时间块中的词元只能关注同一时间块或前一个时间块中的词元,从而消除了对未来帧的依赖性。这种混合注意力模式能够在保持长程时间连贯性的同时,实现无限制的自回归生成。在推理过程中,因果结构通过键值缓存促进了高效的流式生成。我们重用先前时间块的缓存表示,并且仅对新生成的词元计算注意力,从而显著降低了每个生成步骤的计算开销。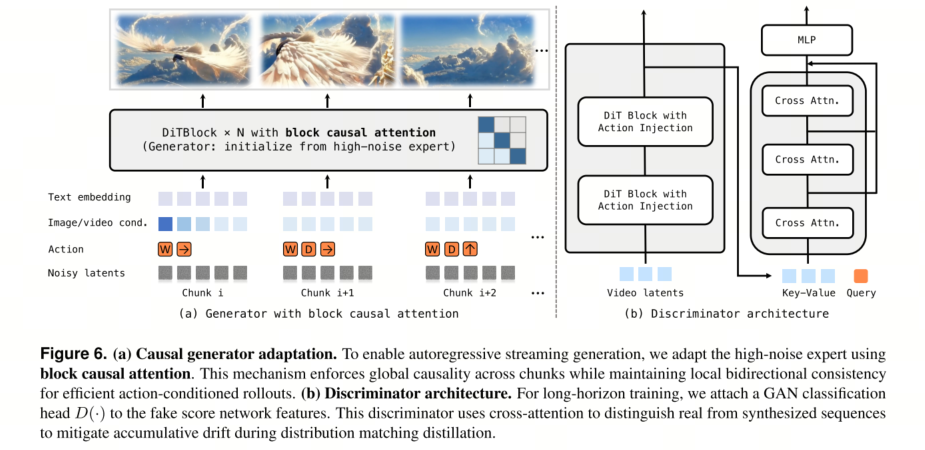
训练协议。在训练过程中,我们处理 N 个带噪声的视频帧序列,这些帧被分割成 L 个片段,每个片段都根据扩散强制范式分配一个独立的噪声时间步 [12, 88]。为了在保持模型表达能力的同时优化训练效率,我们将训练限制在一组精心选择的目标时间步 {t1, …, tm} 内,这些时间步在后续阶段用作蒸馏目标。选择这些时间步是为了覆盖去噪轨迹,同时保持计算的可处理性。由于我们的初始化使用了专门在高噪声条件下训练的高噪声专家模型,我们通过引入时间步 0 的采样 [28, 69] 来增强训练,从而引入干净帧的监督。这使得模型能够学习干净的潜在编码能力,有效地弥合了我们教师模型中高噪声专家和低噪声专家之间的专业化差距。训练损失的公式如下:

3.4.2 Few-Step Distillation with Long-Horizon Training
虽然我们的因果自适应模型能够根据用户输入操作生成视觉上合理的视频帧,但由于训练条件和推理条件之间的分布不匹配,训练周期结束后仍会累积显著的偏差。为了解决这一根本性挑战,我们采用了一种综合的蒸馏框架,该框架结合了自强制训练和先进的分布匹配技术。
自展开扩展训练。遵循自强制范式[30, 40, 43, 85],我们使用学生模型自身生成的序列对其进行训练,以弥合训练集与测试集之间的差距。在训练过程中,模型会根据其先前生成的帧进行条件化,这些帧通过高效的滚动键值缓存存储,从而迫使模型发展出从自身生成伪影和累积误差中恢复的稳健机制。这种方法确保模型能够学会处理自回归生成过程中自然发生的分布偏移。为了控制长时域展开带来的巨大计算开销,我们采用了随机梯度截断策略。具体而言,我们仅通过最近的K个生成步骤进行梯度反向传播,同时保持前向计算的完整上下文,从而在训练效率和长期依赖性学习之间取得平衡。
分布匹配和对抗优化。我们应用分布匹配蒸馏(DMD)结合对抗优化[86, 87]来提高样本质量和时间一致性。我们使用经过中间训练的MoE教师模型作为真实得分函数,并使用相同的MoE教师模型初始化虚假得分模型,以实现全步得分匹配。对于动作条件生成,关于学生参数θ的梯度为:
根据 [86],我们采用双时间尺度更新规则:对每个学生更新执行多次 µϕ fake 更新,以便 µϕ fake 紧密跟踪学生不断变化的输出分布,从而提高训练稳定性和蒸馏质量。
然而,经过DMD训练后,蒸馏生成器和教师模型之间仍然存在性能差距;
例如,学生模型生成的视频质量通常较差。造成这种差距的原因可能有以下几点。
- 首先,学生模型是从高噪声模型初始化的,因此无法继承低噪声模型学习到的知识(即负责精细细节和高频合成的组件)。
- 其次,我们将注意力掩码替换为因果变体,并在推理阶段仅采用少量采样步骤,这进一步限制了生成质量。
- 更重要的是,在DMD训练下,生成器和教师模型均未直接接受真实数据的监督,这可能导致学生模型继承教师模型的偏差和误差。
为了缓解这些问题,我们引入了一个基于对抗训练的附加目标[21]。具体来说,生成器的目标是欺骗判别器,而判别器则学习区分真实视频和合成视频。通过引入真实数据的监督,蒸馏生成器不再严格受限于教师的限制,这有可能提高样本的真实性和感知质量。
具体而言,我们在DMD中将分类头D(·)附加到伪分数网络中。该分类头的架构
遵循APT[39]中的设计。对抗目标如下: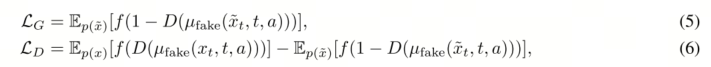
其中 p(x) 和 p(˜x) 分别表示真实视频和合成视频的分布。µfake 是伪造评分网络,t 表示自强制去噪算法 [30] 中的当前去噪时间步,f(·) 是 softplus 函数。值得注意的是,对抗损失仅用于更新判别器头 D,而伪造评分网络 µfake 仅使用 DMD 损失进行更新。此外,我们没有应用 R1 或 R2 [47] 等正则化项,因为在我们的设置中,DMD 目标函数已经足够稳定。通过这种增强的对抗目标函数,我们显著提高了视觉质量,同时保持了动作跟踪能力,并在较长的时间范围内保持了时间一致性。
4 Evaluation
4.1 Qualitative Analysis
4.1.1 Diverse Results
我们通过分析中间训练模型 LingBot-World-Base 和后训练模型 LingBot-World-Fast 在各种场景下的定性结果,来评估我们框架的泛化能力。图 7 至图 9 可视化了 LingBot-World-Base 的结果,其中每一行显示了随时间采样的关键帧。首先,对于高保真度的 LingBot-World-Base,序列表明它能够有效地处理不同的物体属性和复杂的空间配置。帧之间的过渡保持平滑且逻辑一致,突显了该模型捕捉精细环境动态的能力。
在此基础上,我们进一步分析了实时变体 LingBot-World-Fast,它在配备一个 GPU 节点的系统上处理 480p 视频时实现了 16 fps 的吞吐量。
尽管加速过程必然会降低理论质量上限,但视觉上的劣化在感知上微乎其微。如图所示。在第 10 和 11 题中,LingBot-World-Fast 成功地保留了教师模型的结构完整性和物理逻辑。它能够适应动态交互,而不会出现明显的视觉瑕疵或模式崩溃,这表明它在推理速度和生成质量之间实现了最佳平衡。
4.1.2 Emergent Memory Capability
LingBot-World 的一个关键特性是它能够自发地保持全局一致性,而无需依赖显式的 3D 表示方法,例如高斯散射 [34]。如图 12 的前三行所示,即使地标(包括雕像和巨石阵)长时间(长达 60 秒)不在视野中,该模型也能保持其结构完整性。这与先前的观察结果 [5, 46] 相符,即视频模型具有对物体重新出现的隐式记忆。至关重要的是,与通常仅限于静态场景重建的显式 3D 方法不同,我们基于视频的方法更具动态性。它能够自然地模拟复杂的非刚性动力学,例如流动的水或移动的行人,而这些动力学是传统静态 3D 表示方法难以捕捉的。
除了能够呈现可见的动态效果外,该模型甚至还具备推理未观测状态演化的能力。
例如,当摄像机向前移动后返回正面视角时,远处的桥梁被渲染得明显更近,准确地反映了摄像机随时间推移的向前运动。类似地,在第 5 行中,车辆离开画面后,在未被观测到的情况下继续其运动轨迹,并在一个符合物理规律的位置重新出现,而不是消失或静止不动。这些行为表明,该模型模拟的是真实世界潜在的时空一致性,而不仅仅是记忆像素。
4.1.3 探索生成边界
我们拓展了视频合成中时间一致性的边界。我们的模型能够
在超长时间(长达十分钟)内维持稳定、高保真的环境,而不会显著降低视觉质量或叙事一致性。这一结果凸显了我们方法在处理长期时间依赖性方面的鲁棒性。
4.2 Quantitative Analysis
为了进行定量评估,考虑到世界模型的评估协议仍处于起步阶段,且本文提出的方法基于视频生成模型,我们使用 VBench [31] 对一个包含 100 个生成视频(每个视频时长超过 30 秒)的精选测试集进行了全面分析。我们将 LingBot-World 与两个最先进的视频世界模型 Yume-1.5 [45] 和 HY-World 1.5 [68] 进行了比较。如表 2 所示,我们的方法在大多数评估指标上都表现出更优的性能。具体而言,在视觉保真度方面,我们的模型在图像质量和美学质量方面均取得了最高分,超越了两个基线模型。这表明我们的模型生成的场景具有更高的真实感和更好的视觉吸引力,这对于交互式世界漫游中的沉浸式用户体验至关重要。
对于交互式世界模型而言,至关重要的是,我们的模型在动态度方面展现出显著优势,
其得分达到 0.8857,而 Yume-1.5 为 0.7612,HY-World 1.5 为 0.7217。这一显著优势表明,我们的模型能够根据用户控制生成更丰富的场景过渡和更复杂的运动,避免视频生成中常见的静态模式。此外,尽管动态度很高,我们的方法仍保持了最佳的整体一致性,证实了我们的模型在长期生成过程中能够保持对输入提示的高度语义保真度。
在时间特性方面,我们的模型在运动平滑度和时间闪烁方面取得了具有竞争力的结果,
与领先的基线模型 HY-World 1.5 相当。这确保了生成的视频流保持流畅,避免出现突兀的瑕疵。总之,定量结果验证了我们的模型不仅提供了更具动态性和交互性的环境,而且与现有方法相比,还保持了更优异的视觉质量和一致性。
5 Applications
我们的自回归框架通过将合成过程与自然语言提示和离散动作相结合,将视频生成转化为交互式模拟。这种多模态可控性使得该模型能够作为下游任务的多功能平台。在本节中,我们将展示我们设计实现的三个关键应用:(1)可提示的世界事件,用户可以通过文本语义控制全局和局部动态;(2)动作代理,利用模拟器学习自主探索策略;以及(3)3D重建,验证我们生成的环境所展现的几何一致性和长期空间记忆。
5.1 Promptable World Events
我们提倡一种响应式世界模型,而非将用户限制在静态环境中被动导航,在这种模型中,模拟会根据交互方式呈现不同的结果。为此,我们展示了可提示世界事件[5, 79],这是一种允许用户通过自然语言主动引导未来轨迹的机制。如图14所示,这种能力将生成过程从单一的确定性路径转变为一个包含多种可能性的树状结构。给定一个初始上下文,我们的模型可以根据语义提示分支出截然不同的未来。这种可控性带来了两项关键能力。
5.1.1 Global Events
全局事件指的是对模拟环境的整体性修改,包括天气状况、光照和风格渲染。利用我们基础模型的文本条件特性以及 Ditto [3] 的变体,我们可以在推理过程中通过调整提示来操控全局状态。如图 14 所示,引入环境描述符(例如“冬季”或“夜晚”)可以将场景无缝过渡到目标域。该模型能够始终如一地渲染出连贯的物理效果,例如城堡的冰封或夜晚的光照变化,同时保持与先前历史的时间一致性。此外,该模型还支持风格域的转换。通过提示艺术风格(例如“像素艺术”或“蒸汽朋克”),我们可以在保持底层几何形状和运动动力学不变的情况下转换视觉渲染。
5.1.2 Local Events
局部事件是指将特定物体或动态主体精确地注入场景。如图 14 所示,用户可以引入目标元素,例如在城堡上方触发“烟花”,或在喷泉处生成“鸟”和“鱼”。我们的模型能够将注入的元素无缝地融入到不断演变的场景中,确保物理行为的一致性和时间上的稳定性。这种精细的控制对于具身人工智能和自动驾驶至关重要。它能够构建多样化的交互式训练环境,使智能体能够在其中推理因果关系和动态变化。通过定义特定事件,我们可以严格评估智能体感知、预测和响应细粒度物理交互的能力,从而弥合静态数据集学习与现实世界适应性之间的差距。
5.2 Action Agent
除了学习动作条件世界模型之外,我们还利用相同的数据来训练一个动作智能体,该智能体可以从单个视觉观察中推断运动动态,并激励环境探索,从而更有效地利用数据集。
形式上,我们对 Qwen3-VL-2B [75] 骨干网络在图像-动作对上进行微调。每个训练样本包含一个视觉观察,随后是一系列动作块 (a0, a1, …),其中每个动作块 (ai) 指定了驱动智能体探索环境的后续动作。基于这些视觉观察,模型被训练来预测未来的动作。
在我们的设置中,智能体输出接下来 10 秒的动作,包括用于移动的离散键盘控制 (W, A,S, D) 和用于旋转相机的离散鼠标方向 (I, J, K, L)。然后,预测的动作被转换为运动轨迹,并传递给世界模型以生成相应的视频展开。
5.3 3D Reconstruction
得益于高质量的大规模长时域训练,LingBot-World展现出涌现的三维空间一致性和长期空间记忆能力。如图16所示,通过利用大规模三维重建基础模型[38, 81],我们可以将生成的视频序列进一步转换为高质量的场景点云。这些点云在帧间表现出很强的空间一致性,为下游具身智能训练提供了丰富的数据来源。这种涌现的三维一致性有效地缓解了传统视频生成模型中常见的跨视角不一致性,从而实现了更高的场景保真度和几何精度。
6 Conclusion and Discussion
本报告提出了一个全面的框架,为世界模型开辟了开源领域的新天地,有效弥合了视频生成与可操作模拟之间的鸿沟。我们的贡献涵盖了整个流程,首先是一个强大的数据引擎,它配备了可扩展的自动化采集系统,确保了高质量且多样化的训练数据。在建模方面,我们开发了一种针对精确动作控制进行优化的因果变换器架构,并采用实时蒸馏技术来实现高效推理。这些进展最终应用于各种场景,展示了该模型在执行智能体动作、进行一致的世界编辑以及支持3D环境重建方面的能力。
尽管取得了这些进展,但在实现完全沉浸式和持久的虚拟世界方面仍然存在一些挑战。
• 内存稳定性:目前,该模型的内存是一种从上下文窗口涌现出来的能力,而不是显式的存储模块。因此,它缺乏稳定性,导致在长期模拟过程中出现不一致的情况。
• 计算成本:推理成本仍然很高。运行该模型需要企业级GPU,这使得消费级硬件无法使用。
• 动作空间有限:目前可控动作的范围有限。该模型主要处理导航和基本移动,缺乏多样化的复杂交互。
• 交互精度:精细控制仍然很困难。具体来说,由于缺乏精确的物体级定位,与特定目标物体进行交互(例如,在杂乱的桌子上拿起特定的杯子)具有挑战性。
• 生成长度和漂移:连贯的生成长度不足以支持长时间的游戏体验。随着视频时长的增加,场景会出现“漂移”问题,即环境逐渐失去其原有结构。
• 单智能体仿真:当前框架仅支持单智能体视角,尚未考虑多智能体交互。
展望未来,我们计划通过有针对性的路线图来解决这些局限性。我们的首要目标是显著扩展动作空间并增强物理引擎,从而实现更多样化、更逼真的环境交互。为了解决长期模拟中固有的稳定性问题,我们计划设计一个更完善、更明确的内存模块,而不是仅仅依赖于涌现特性。此外,我们将着重解决漂移问题,以实现更长时间的视频生成,为无限时游戏和更稳健的模拟铺平道路。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)