DeepSeek V4 1M上下文实战解析(附本地部署思路)
在实际开发和数据处理场景中,长文本处理一直是大模型应用的关键难点。DeepSeek V4最新版本引入1M上下文窗口能力,大幅提升了单次输入处理上限,使其可以支持完整代码库分析、长文档解析以及多文件知识整合任务。

这对于开发者而言,意味着Prompt工程正在从“分段控制”进入“整体输入”阶段。
一、百万Token上下文到底意味着什么?
“上下文窗口”本质上代表AI一次能够“记住并理解”的信息上限。DeepSeek V4的1M Token能力,换算下来大约是75万汉字输入容量。

举个更直观的例子,你可以直接把以下内容“一次性丢给AI”:
-
一整本《三国演义》
-
300页上市公司年报
-
一个完整GitHub代码仓库
-
数十页法律合同合集
AI不再需要“分段阅读”,而是:
-
一次性理解全局
-
自动建立上下文关联
-
支持跨章节推理
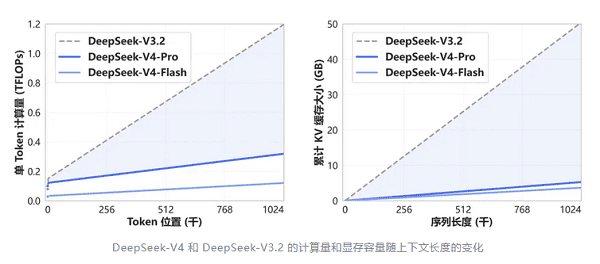
这意味着传统“切片+拼接”的Prompt工程正在被淘汰。
二、百万上下文典型应用场景
|
场景类型 |
具体用途 |
AI能力要求 |
|
长文档分析 |
财报/白皮书/研究报告 |
全文理解 |
|
代码工程分析 |
多文件项目结构 |
跨文件推理 |
|
合同审查 |
条款一致性比对 |
全局语义理解 |
|
学术研究 |
多文献整合总结 |
长文本归纳 |
|
企业知识库 |
多文档问答系统 |
跨文档关联 |
在实际测试中,有用户直接让V4分析300+页财报,并精准定位隐藏在附录中的关键数据,这在旧模型时代几乎是不可能的。
三、DeepSeek V4为什么能做到1M上下文?
这并不是简单“扩大窗口”,而是架构级优化。核心在于三点技术升级:
1. CSA压缩稀疏注意力
减少无效Token计算,让模型只关注关键片段。
2. HCA分层压缩机制
对长文本进行结构化压缩,降低计算冗余。
3. KV Cache极致优化
显著降低显存占用,使长上下文推理可落地。
四、关键性能变化(相对V3)
|
模块 |
优化幅度 |
|
推理计算量 |
↓约70% |
|
KV Cache占用 |
↓90%以上 |
|
长文本效率 |
显著提升 |
这意味着:DeepSeek V4已经从“模型能力提升”进入“工程可用阶段”。
五、云端API的隐形成本问题正在放大
很多用户在尝试长文本AI时,忽略了一个关键问题:Token成本是指数级增长的。尤其在V4 Pro版本中:
-
输入缓存命中:约1元/百万Token
-
未命中:约12元/百万Token
-
输出:约24元/百万Token
如果每天处理多个长文档,成本会迅速累积。
六、云端 vs 本地对比
|
维度 |
云端API |
本地部署 |
|
成本 |
持续计费 |
一次投入 |
|
数据安全 |
上传服务器 |
完全本地 |
|
网络依赖 |
必须联网 |
可离线运行 |
|
长文本能力 |
受限成本 |
完整释放 |
|
使用频率 |
低频适用 |
高频适用 |
七、本地部署才是V4真正的打开方式
如果你希望将V4的超长上下文能力握在自己电脑里,无论是出于数据隐私的考量,还是为了规避按Token计费的后顾之忧,DeepSeek本地部署大师都能帮你一键完成设置——无需在终端输入一团看不懂的命令,也不用自己处理复杂的环境依赖,一个软件就能搞定DeepSeek系列大模型的本地部署体验。
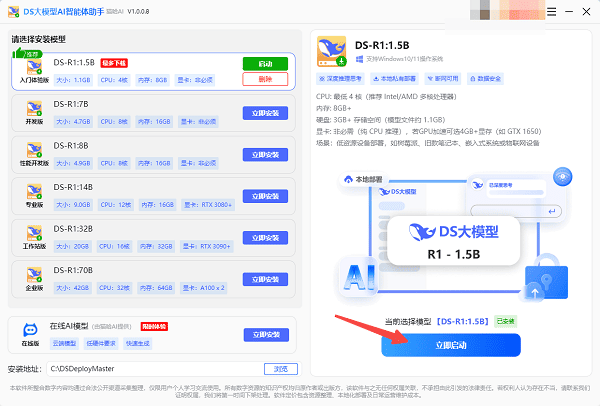
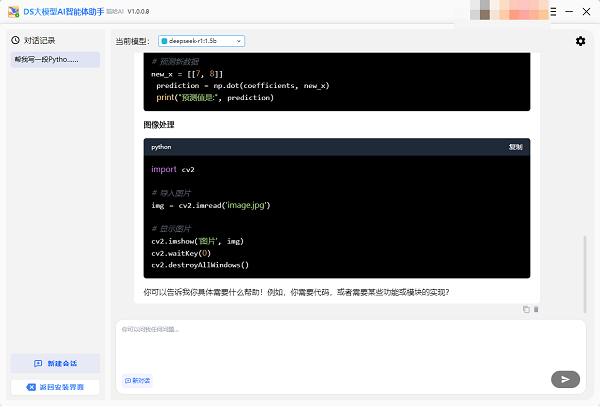
除了让V4的超长上下文能力在您的硬件上充分发挥,用DeepSeek本地部署大师还有一个长期的附加价值:后续任何新模型的发布,您都可以在软件中一键完成更新和部署,不用担心平台封号和API涨价,真正实现AI能力的私有化和长期可用。
八、未来趋势已经非常清晰
AI的发展正在发生一个关键转变:从“回答问题” → “处理完整任务”。而DeepSeek V4 + 本地部署方案,正在把这一趋势变成现实。未来竞争不再是模型参数大小,而是:
-
谁能处理更长的上下文
-
谁能真正落地执行任务
-
谁能在本地稳定运行
总体来看,DeepSeek V4的长上下文能力已经具备较强的工程可用性。但在实际落地中,仍需结合部署方式与运行环境进行优化。尤其是在高频长文本场景下,本地化部署与资源调度,将成为影响体验的关键因素。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)