【人工智能】从零搭建AI问答助手项目(五):本地知识库向量化
引言
上一篇中,我们完成了云模型与本地模型的统一 API 调用封装,打通了大模型基础对话能力。但单纯的大模型原生对话,普遍存在知识滞后、信息受限、容易产生幻觉等问题,没办法满足专属场景的精准问答需求。
想要打造一个专属、精准、可控的AI 问答助手,核心关键就是引入私有本地知识库,结合 RAG 检索增强技术,让模型只依托我们自定义的资料进行作答。
而整个 RAG 流程里,本地文档处理 + 文本切块 + 内容向量化入库,是最核心、最基础的前置环节。本篇就聚焦项目落地,完整讲解本地知识库的处理逻辑、文本分片原则,以及文档向量化与向量库存储的完整实现思路,为后续智能检索、精准问答做好全部铺垫。
版本目标
升级为“真正RAG”,即升级为向量数据库RAG(FAISS + embedding):
• 引入 embedding
• 使用 FAISS / Chroma
• 语义检索(不是关键词)
第一版的存在的问题
RAG部分使用的是关键词匹配,而非语义匹配。所以当用户输入“Java特点”,会去找包含“Java”的句子,但本地知识库里包含“Java”的句子并不是跟“Java特点”语义相近的句子,所以检索存在“不理解语义、同义词失效”的问题。
升级后的效果(向量检索)
当用户输入“Java特点”,会把问题转换成向量,再根据语义找最接近的内容。
升级的内容
1、将本地知识库的文档进行切分,然后使用embedding模型生成本地向量库:
文档 → 切分 → embedding → 向量库(FAISS)
2、将用户的问题通过embeding模型转换成向量,通过相似度检索拿到TopK文档,将TopK文档与原有Prompt拼装成最终的提示词发送给LLM。
用户问题 → embedding → 相似度搜索 → TopK文档 → LLM
实现步骤
第一步,安装环境依赖
依然是在PyCharm的命令行工具页面输入以下命令并执行,将faiss-cpu和sentence-transformers的相关依赖安装到本项目:
pip install faiss-cpu sentence-transformers

执行效果
第二步,改造 vector_db.py(核心代码)
# 向量检索(先做简化版)
import os
import pickle
from pathlib import Path
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
# ===== 1. 初始化模型 =====
print("开始加载embedding模型...")
# 本地模型路径获取
BASE_DIR = Path(__file__).resolve().parent.parent
model_path = BASE_DIR / "models" / "all-MiniLM-L6-v2"
model = SentenceTransformer(str(model_path))
print("模型加载完成")
INDEX_PATH = BASE_DIR / "data" / "faiss.index"
DOCS_PATH = BASE_DIR / "data" / "docs.pkl"
# ===== 2. 文档切分 =====
def load_knowledge():
print("加载知识库...")
BASE_DIR = Path(__file__).resolve().parent.parent
file_path = BASE_DIR / 'data' / 'knowledge.txt'
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
# 简单按行切分(后面可升级)
docs = text.split("\n")
return [d for d in docs if d.strip()]
# ===== 3. 构建向量库 =====
class VectorDB:
def __init__(self, docs):
self.docs = docs
# ===== 如果已有索引,直接加载 =====
if os.path.exists(str(INDEX_PATH)) and os.path.exists(str(DOCS_PATH)):
print("加载已有向量库...")
self.index = faiss.read_index(str(INDEX_PATH))
with open(DOCS_PATH, "rb") as f:
self.docs = pickle.load(f)
else:
print("首次构建向量库(可能较慢)...")
# 向量化
embeddings = model.encode(docs, show_progress_bar=True)
print("首次向量化完成")
# FAISS索引
dim = embeddings.shape[1]
self.index = faiss.IndexFlatL2(dim)
self.index.add(np.array(embeddings).astype("float32"))
# 保存
faiss.write_index(self.index, str(INDEX_PATH))
with open(DOCS_PATH, "wb") as f:
pickle.dump(self.docs, f)
print("向量库构建完成并已保存")
# ===== 4. 搜索 =====
def search(self, query, top_k=3):
query_vec = model.encode([query])
distances, indices = self.index.search(
np.array(query_vec).astype("float32"),
top_k
)
return [self.docs[i] for i in indices[0]]
第三步,改造RAG流程
# RAG主流程
from core.vector_db import load_knowledge, VectorDB
from core.llm_manager import LLMManager
print("开始加载知识库")
docs = load_knowledge()
print("开始初始化向量数据库")
vector_db = VectorDB(docs)
print("开始初始化模型管理器")
# llm = get_llm()
llm_manager = LLMManager()
print("初始化完成")
def ask(question: str) -> str:
# 用向量检索代替关键词匹配
related_docs = vector_db.search(question)
context = "\n".join(related_docs)
prompt = f"""
你是一个严格的问答助手。
【规则】:
1. 只能根据“提供的知识”回答问题
2. 如果知识中没有相关内容,必须回答:“我不知道”
3. 不允许使用你自己的知识
4. 不允许进行推测或补充
【知识】:
{context}
【问题】:
{question}
"""
return llm_manager.generate(prompt)
第四步,运行测试
1、如果运行测试通过,则表示成功了。
2、如果没有运行测试通过,则极大概率是模型下载有问题,具体方案详见“踩过的坑”中的“模型下载失败”。
第五步,验证模型是否下载成功,是否能正常输出向量
注意:单独在项目中新建一个python文件执行进行检验!
为什么要单独写文件?因为需要排除CLI逻辑干扰、RAG逻辑干扰、本地路径混乱、离线模式影响。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"..\\models\\all-MiniLM-L6-v2",
local_files_only=True
)
print("模型加载成功")
vec = model.encode("Java是什么")
print(vec[:5])
如果控制台输出以下内容,则说明模型正常,输出向量也正常.
第六步,将本地知识库转化为向量库
在模型确定下载成功且位置放对后,第一次运行项目,日志会打印首次构建向量库。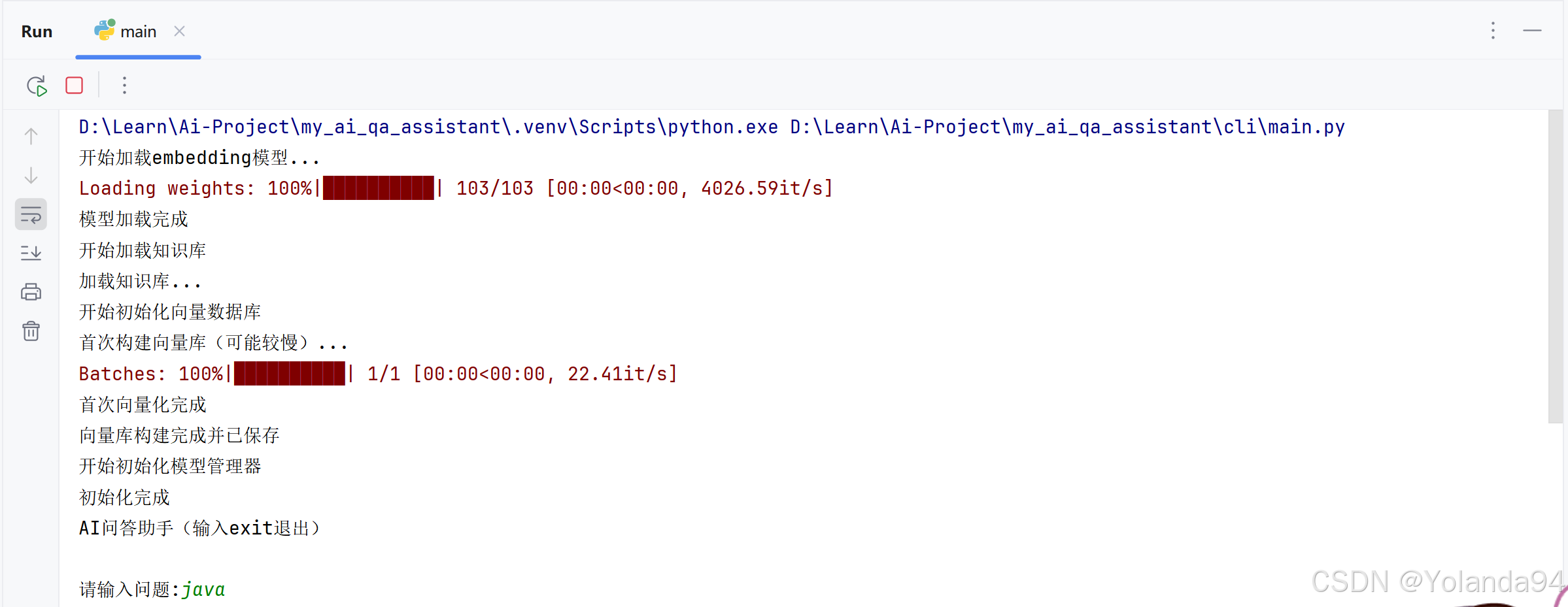
构建成功后再次进行提问题测试↓
第二次或更多次运行程序时会打印日志“加载已有向量库”。
踩过的坑
模型下载是否成功不清楚怎么确认
直接看文件夹
模型默认会下载到 HuggingFace 缓存目录:
Windows:
C:\Users\你的用户名\.cache\huggingface\
C:\Users\你的用户名\.cache\huggingface\hub\
Linux / Mac:
~/.cache/huggingface/hub/
实际查看以下目录,检查权重(.bin)、配置(config.json)、tokenizer、sentence-transformers结构文件文件是否存在,如果有缺失,那么说明模型下载失败了;如果没有缺失,则说明模型下载成功。
模型目录文件自检清单:
models/all-MiniLM-L6-v2/
config.json
pytorch_model.bin
tokenizer.json
modules.json
sentence_bert_config.json
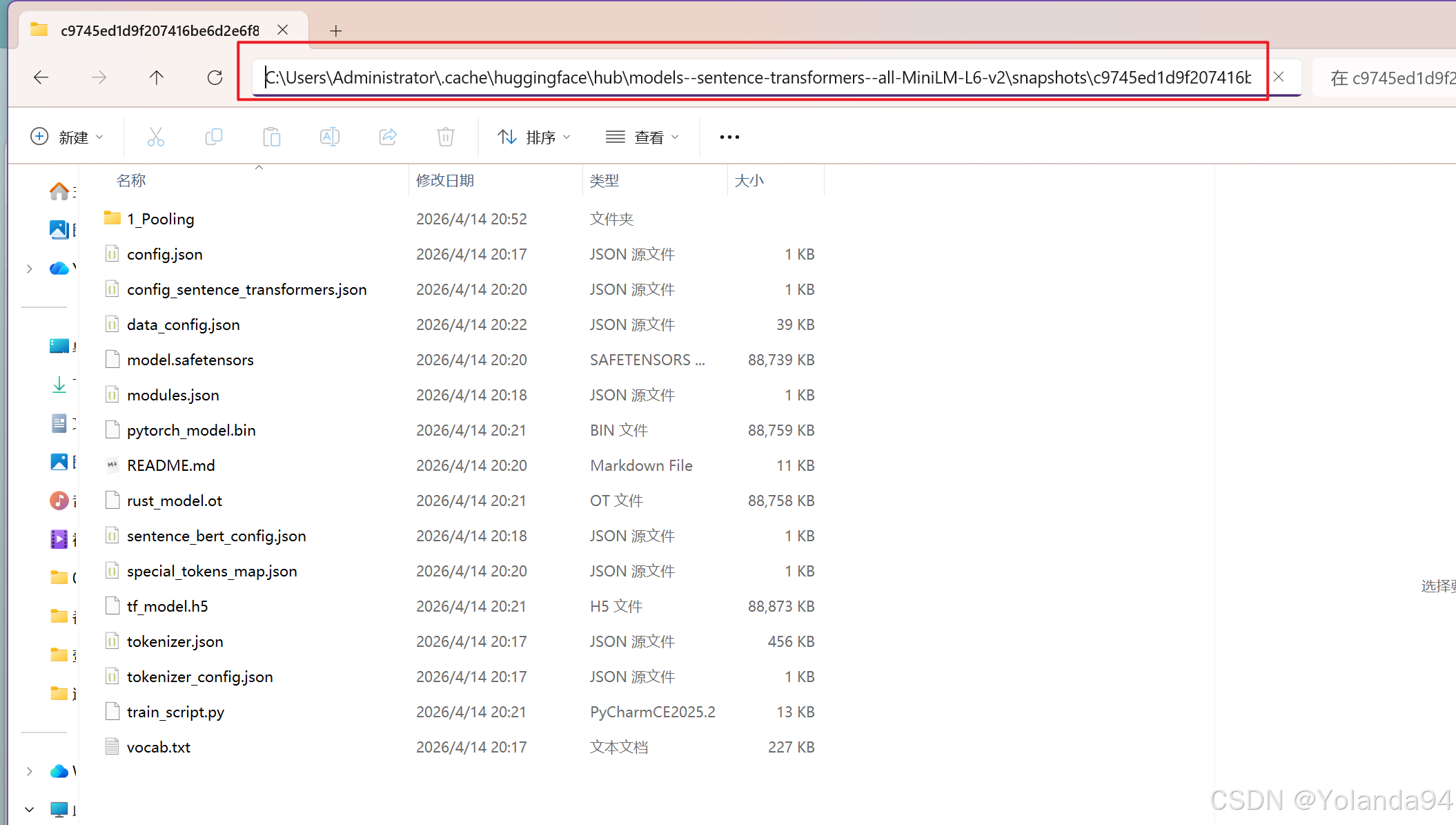
项目里的模型下载失败
具体表现为测试运行时卡住,很长时间控制台既不输出内容也不报错提示。然后进行了以下步骤分析并解决问题:
(1)原因分析
原因1:初始化阶段卡住(最高概率)
回忆这段代码:
docs = load_knowledge()
vector_db = VectorDB(docs) # ❗这里
llm_manager = LLMManager()
关键点: VectorDB(docs) 会执行:
model = SentenceTransformer("all-MiniLM-L6-v2")
这个操作会下载模型(第一次运行)、连接 HuggingFace,可能很慢 / 被墙 / 卡住。典型表现:程序不报错、控制台没输出、CPU占用低或偶尔高。
原因2:模型加载太慢
即使不下载,也可能初始化耗时10~30秒
原因3:网络问题(尤其你在国外/国内混合环境)
网络问题导致连接huggingface被限制或者下载失败但不抛异常。
(2)排查定位
为了定位具体是哪个原因造成的程序运行卡住,可以在代码中加入日志打印:
print("开始加载知识库")
docs = load_knowledge()
print("开始初始化向量数据库")
vector_db = VectorDB(docs)
print("开始初始化模型管理器")
llm_manager = LLMManager()
print("初始化完成")
(3)解决方案
提前下载embedding模型
1)命令行方式
python -c "from sentence_transformers import SentenceTransformer; SentenceTransformer('all-MiniLM-L6-v2')"
2)手动到huggingface”官网下载**,然后将下载后的模型放到“\my_ai_qa_assistant\models\all-MiniLM-L6-v2”项目目录下。
本人测试结果是第一种方式即使科学上网也不行,模型下载不完全,文件会有缺失,建议直接科学上网到huggingface官网手动下载。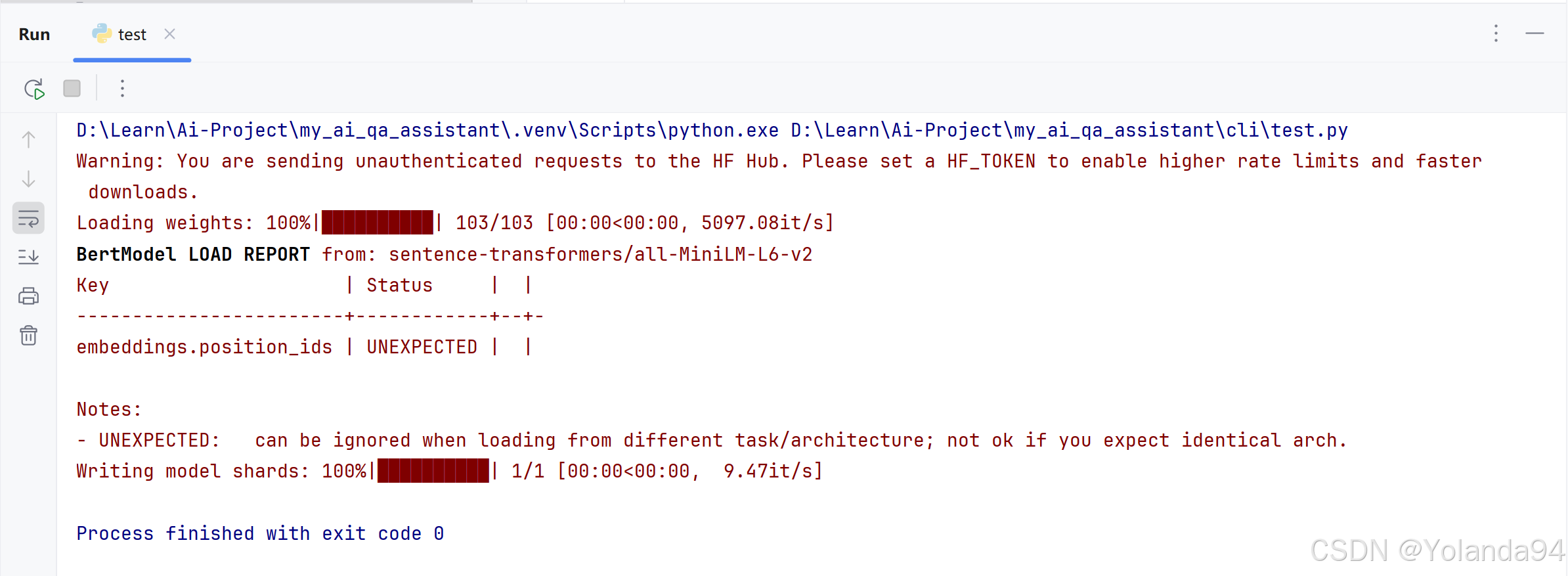
加载embedding模型时报链接尝试失败
手动下载模型并放在相应目录后,运行报以下错误:
开始加载embedding模型…
‘[WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。’ thrown while requesting HEAD https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/main/adapter_config.json
Retrying in 1s [Retry 1/5].
‘[WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。’ thrown while requesting HEAD https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2/resolve/main/adapter_config.json
Retrying in 2s [Retry 2/5].
问题原因:程序在尝试访问 HuggingFace(外网),但连接失败 → 一直重试 → 卡住。
简单来说,就是虽然把模型下载到本地了,但是程序仍然仍然尝试访问 HuggingFace 校验文件(HEAD请求),然后就出现了网络不通 → 重试 → 卡住 的问题。
这个问题的关键愿意在于项目的默认设置是即使模型在本地,它也会默认去“联网检查更新” 所以需要我们在系统中设置强制“离线模型”,以下有几种解决方案:
解决方案
1、强制“离线模式”
环境变量
通过设置环境变量来完全禁止联网,只使用本地模型。
Windows:
set TRANSFORMERS_OFFLINE=1
set HF_HUB_OFFLINE=1
Mac/Linux:
export TRANSFORMERS_OFFLINE=1
export HF_HUB_OFFLINE=1
在代码中写
在代码最前面(下面这行)
from sentence_transformers import SentenceTransformer
加:
import os
os.environ["TRANSFORMERS_OFFLINE"] = "1"
os.environ["HF_HUB_OFFLINE"] = "1"
2、指定“本地路径”
把下面这行代码↓
model = SentenceTransformer("all-MiniLM-L6-v2")
改成
# 本地模型路径获取
BASE_DIR = Path(__file__).resolve().parent.parent
model_path = BASE_DIR / "models" / "all-MiniLM-L6-v2"
model = SentenceTransformer(str(model_path))
print("模型加载完成")
3、禁用更新检查
慎用此方案!!! 如果上面的设置还不行,再尝试做以下的禁用更新设置。
model = SentenceTransformer(
"models/all-MiniLM-L6-v2",
local_files_only=True
)
第一次运行程序进行本地知识库向量化时未联网
因为前面本地下载模型成功后在代码中禁止联网了(local_files_only=True),但是本地模型的路径当时没写对,所以第一次运行时报以下错误:
开始加载embedding模型… Traceback (most recent call last): File “D:\Learn\Ai-Project\my_ai_qa_assistant.venv\Lib\site-packages\transformers\utils\hub.py”, line 422, in cached_files hf_hub_download( ~~~~~~~~~~~~~~~^ path_or_repo_id, ^^^^^^^^^^^^^^^^ …<10 lines>… tqdm_class=tqdm_class, ^^^^^^^^^^^^^^^^^^^^^^ ) ^ File “D:\Learn\Ai-Project\my_ai_qa_assistant.venv\Lib\site-packages\huggingface_hub\utils_validators.py”, line 88, in _inner_fn return fn(*args, **kwargs) File “D:\Learn\Ai-Project\my_ai_qa_assistant.venv\Lib\site-packages\huggingface_hub\file_download.py”, line 997, in hf_hub_download return _hf_hub_download_to_cache_dir( # Destination …<15 lines>… dry_run=dry_run, ) File “D:\Learn\Ai-Project\my_ai_qa_assistant.venv\Lib\site-packages\huggingface_hub\file_download.py”, line 1148, in _hf_hub_download_to_cache_dir _raise_on_head_call_error(head_call_error, force_download, local_files_only) ~~~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File “D:\Learn\Ai-Project\my_ai_qa_assistant.venv\Lib\site-packages\huggingface_hub\file_download.py”, line 1773, in _raise_on_head_call_error raise LocalEntryNotFoundError( …<2 lines>… ) huggingface_hub.errors.LocalEntryNotFoundError: Cannot find the requested files in the disk cache and outgoing traffic has been disabled. To enable hf.co look-ups and downloads online, set ‘local_files_only’ to False.
关键错误原因:本地没找到模型,但是代码里又设置了禁止联网,所以无法进行本地知识库向量化。
当时本地模型下载了在缓存目录:
C:\Users\你的用户名\.cache\huggingface\hub\models--sentence-transformers--all-MiniLM-L6-v2\snapshots\c9745ed1d9f207416be6d2e6f8de32d1f16199bf
项目实际运行时检查的目录是项目目录:
D:\你的项目目录\my_ai_qa_assistant\models\all-MiniLM-L6-v2
所以报本地模型找不到,解决方案很简单,就是把本地模型的snapshot里面的内容复制到项目目录的 \models\all-MiniLM-L6-v2 文件夹目录下。
首次构建向量库完成后写入本地文件时报错:
RuntimeError: Error in __cdecl faiss::FileIOWriter::FileIOWriter(const char *) at D:\a\faiss-wheels\faiss-wheels\third-party\faiss\faiss\impl\io.cpp:104: Error: ‘f’ failed: could not open data/faiss.index for writing: No such file or directory
要写入的目录 data/ 不存在,Python / FAISS 的行为是可以创建文件,但不会自动创建目录 。
解决方案
但这里出现的根本原因还是前面路径写的不对,所以这里修正了一下写入文件的路径:
INDEX_PATH = BASE_DIR / "data" / "faiss.index"
DOCS_PATH = BASE_DIR / "data" / "docs.pkl"
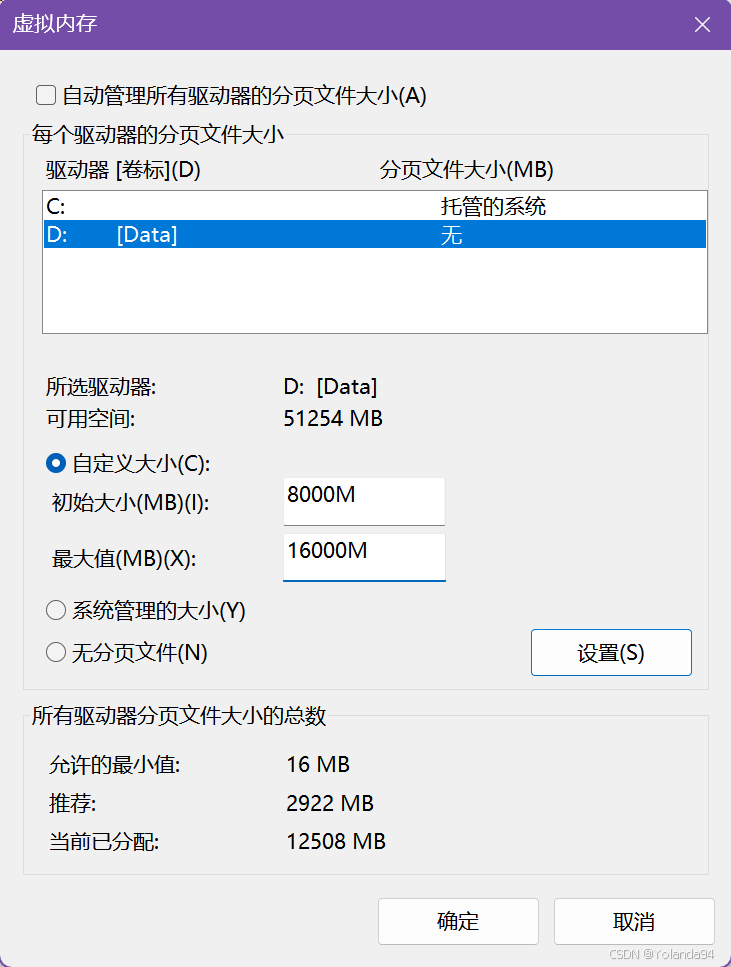
OSError: 页面文件太小,无法完成操作。 (os error 1455)
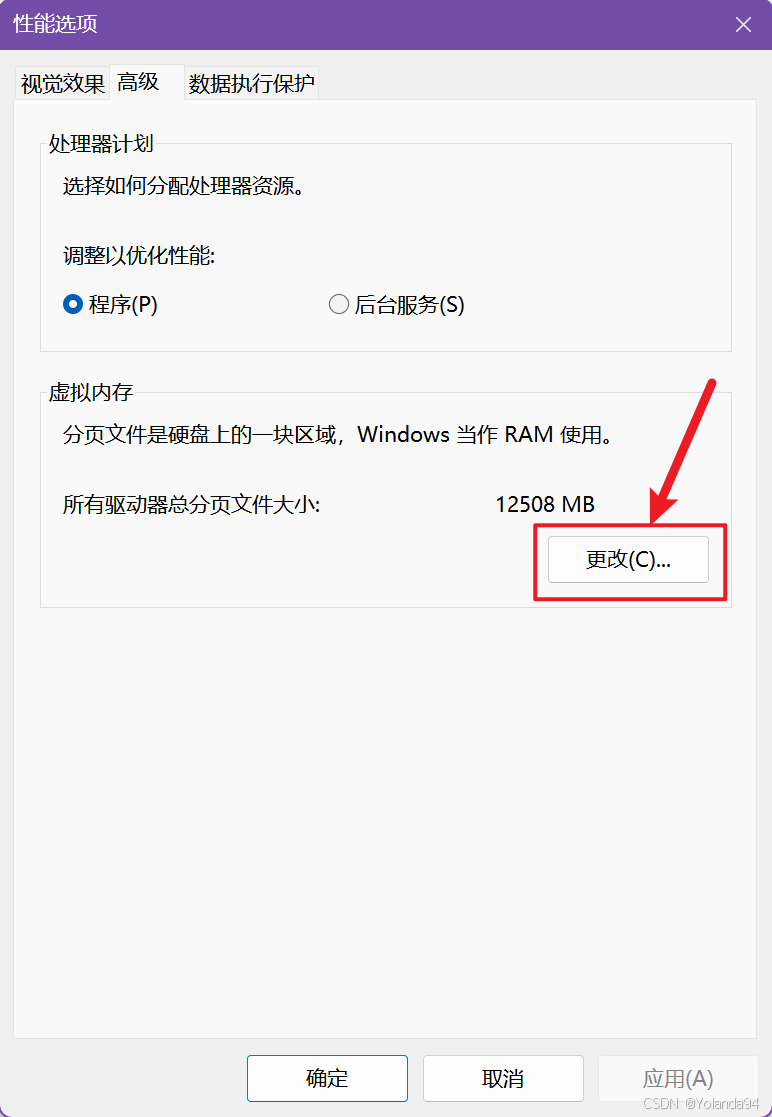
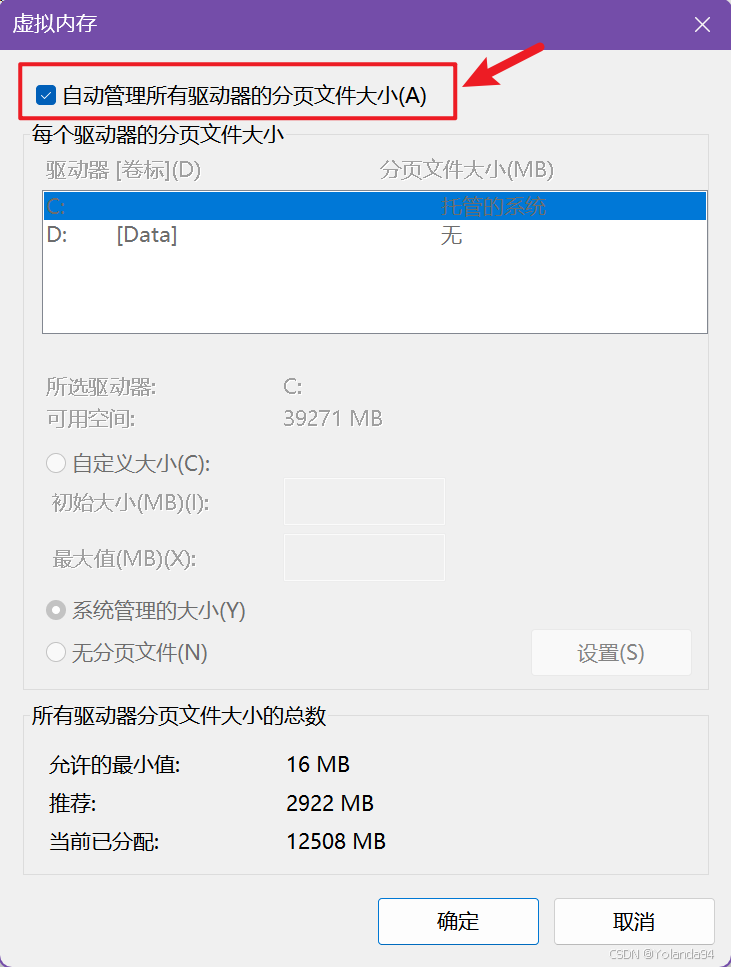
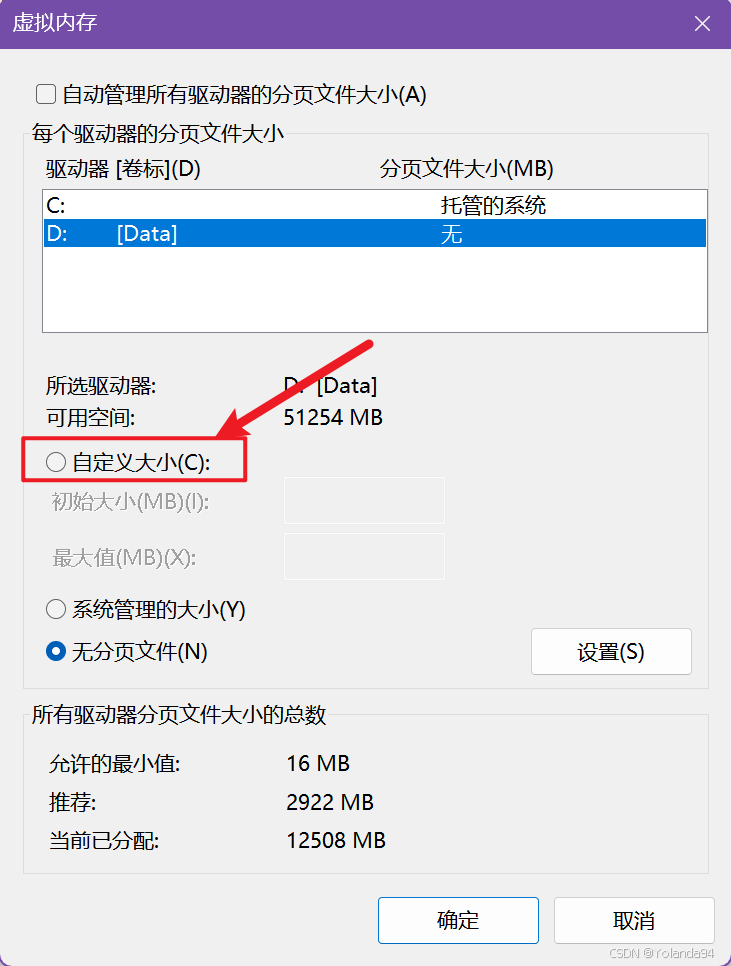
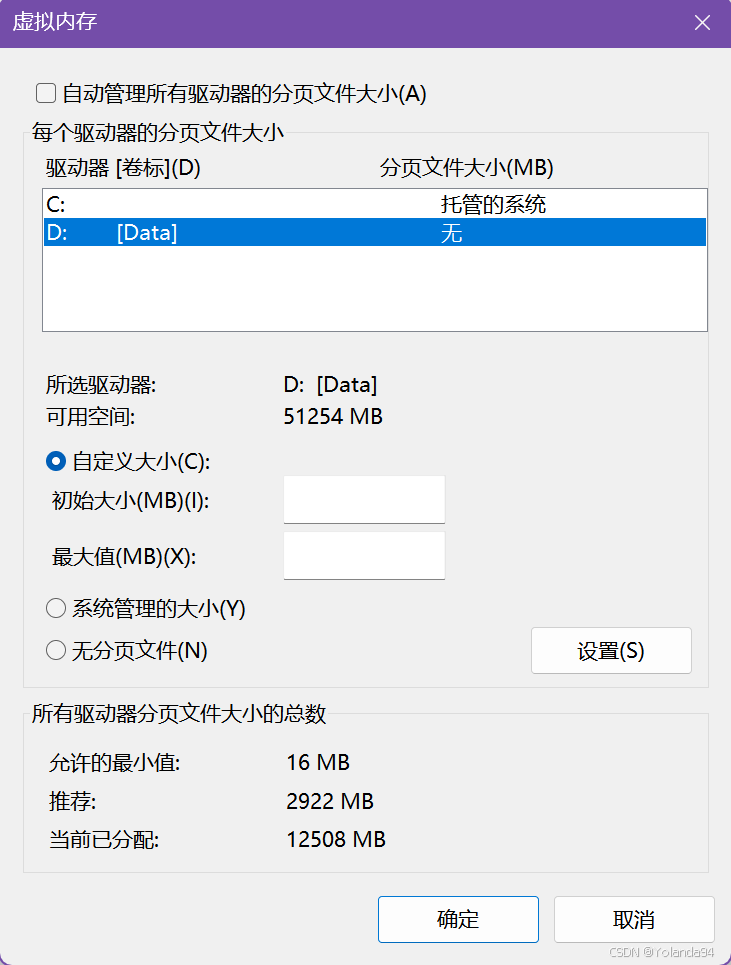
这个报错是系统申请内存失败(物理内存 + 虚拟内存都不够),需要改Windows系统设置的页面文件大小,即修改页面文件(虚拟内存)可以解决当前报错。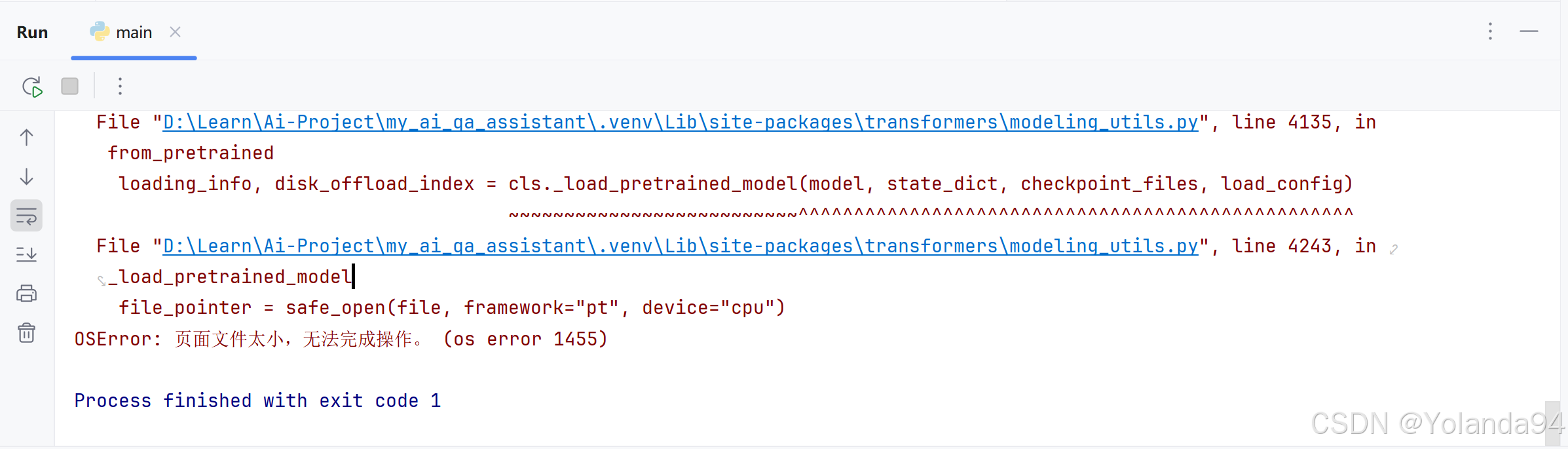
解决方案
修改电脑的分页大小初始值为8G,最大值为16G。
请谨慎修改这个分页大小设置!!!,根据下面的情况预警自行选择:
情况1:电脑内存 ≥ 8GB
基本不会崩,可能表现:稍慢,但能跑
情况2:电脑内存 ≤ 4GB
可能会:非常慢(卡顿),偶尔卡死,但通常不会直接报错
情况3:内存非常紧张(同时开很多软件)
可能:再次报错,或系统卡死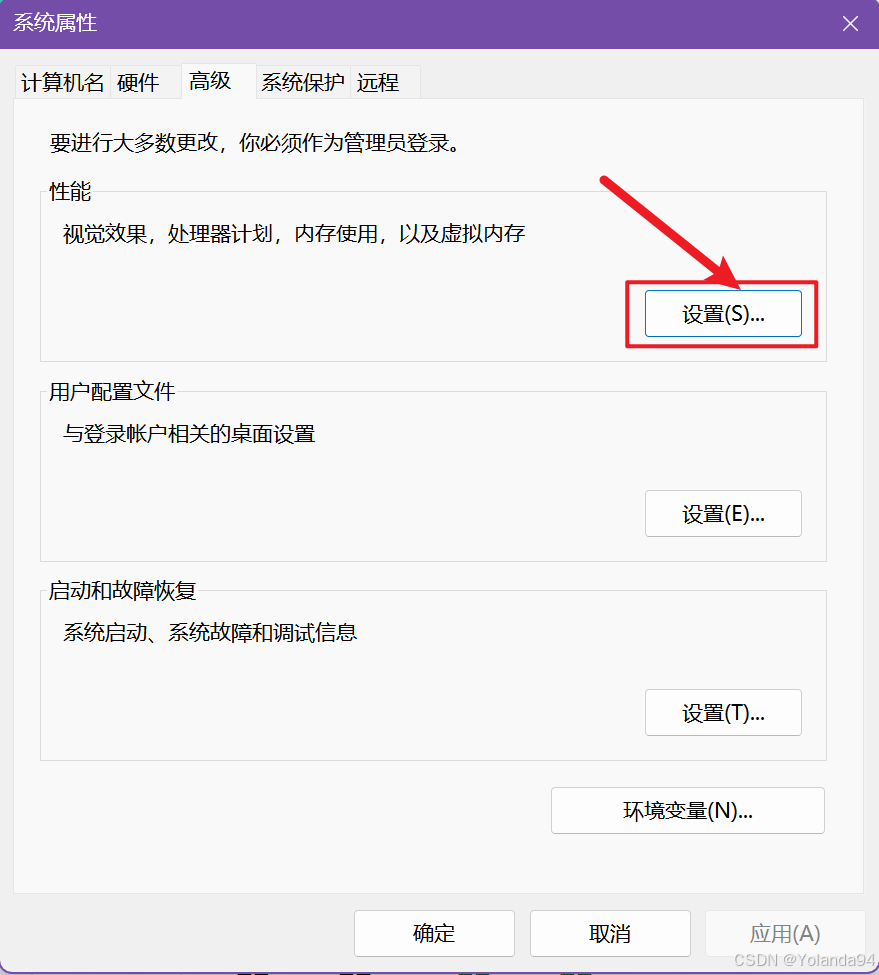
关于向量化的知识
SentenceTransformer 目录结构
旧的架构0_Transformer是必须的,但是新的架构没有0_Transformer。
all-MiniLM-L6-v2/
│
├── modules.json
├── sentence_bert_config.json
├── config.json
│
├── 0_Transformer/
│ ├── config.json
│ ├── pytorch_model.bin
│
├── 1_Pooling/
│ ├── config.json
导出SentenceTransformer目录
# export_model.py
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2")
model.save("my_sentence_model")
print("导出完成")
HuggingFace原始模型和SentenceTransformer封装模型区别
| 层级 | 内容 |
|---|---|
| 原始模型 | pytorch_model.bin |
| SentenceTransformer封装 | modules.json + pooling结构 |
| 类型 | 内容 |
|---|---|
| HuggingFace原始模型 | ✔ pytorch_model.bin |
| SentenceTransformer封装模型 | ❗包含 pooling + transformer 结构 |
embedding
是一次性计算任务(吃内存),但是运行阶段的查询query很轻量,所以只要“构建向量库能跑完”,后面基本稳定。
“禁止联网”设置的工程级排查流程
1:查环境变量
echo $env:HF_HUB_OFFLINE
2、查代码污染
offline
HF_HUB
TRANSFORMERS
3、查缓存
~/.cache/huggingface
4、重启 IDE + 终端(很关键)
embedding模型的缓存目录和项目目录作用
缓存目录
.cache 是“下载仓库”,作用:自动下载用,不适合直接工程使用,结构复杂(有 snapshots 层)。
C:\Users\你\.cache\huggingface\hub\models--sentence-transformers--all-MiniLM-L6-v2\
snapshots\
xxxx/
项目目录
models/ 是“工程使用仓库”,作用:可控、可部署、可离线、工程标准做法。
D:\Learn\Ai-Project\my_ai_qa_assistant\
models\
all-MiniLM-L6-v2\
下一步

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)