从 Transformer 结构到 DeepSeek-R1:揭秘 AI 进化背后的“作弊”与“顿悟”
引言: AI 的“大脑”是如何分工的?
每一个初次接触大模型的人,在打开那篇划时代的论文《Attention Is All You Need》时,多半会被那张经典的
Transformer
架构图搞晕:密密麻麻的连线、左右对称的层级、莫名其妙的“Masked”字样。初学者往往会陷入困惑:为什么一个处理文字的算法,要设计得如此百转千回?
事实上,这种结构并非为了复杂而复杂,它背后隐藏着 AI 处理信息的“思维物理学”。从 2017 年的原始架构到 2025 年席卷全球的DeepSeek,技术演进的逻辑始终如一。
本文将为你拆解五个最颠覆认知的技术真相,带你直抵大模型的底层逻辑。
Transformer架构最早是Google研发出来用于机器翻译的算法,因此我们可以基于机器翻译场景来理解该算法。
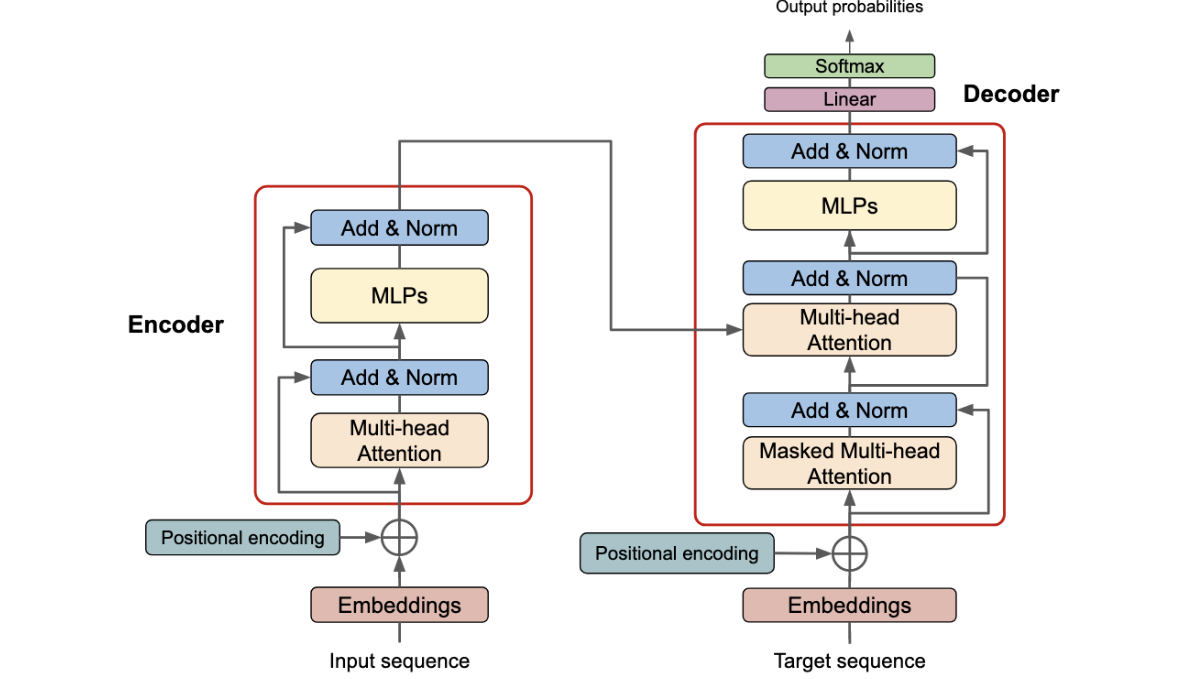
真相一:左手理解,右手生成——Encoder 和 Decoder 的“分家”真相
为什么 Transformer 架构要一分为二?这并非美学追求,而是由机器翻译这类序列到序列(Seq2Seq)任务的物理规律决定的。
1. 左半部分:Encoder(编码器 / 全局理解者):
Encoder的任务是一次性读取所有的输入信息,并将其转化为一个富含上下文语义的特征矩阵。
- 处理方式:并行处理。 它不需要像传统RNN那样按顺序一个词一个词地读。
- QKV的来源: 在Encoder的自注意力(Self-Attention)中,QQQ、KKK、VVV 全部来自于输入序列本身。每个词都会和输入序列中的所有其他词计算注意力分数。
- 最终产出: 经过多层Encoder后,左边会输出一个极其精炼的“记忆矩阵”。这个矩阵包含了源语言的所有语义和结构信息。它将作为后续的 KKK 和 VVV 传递给右边的Decoder。
2. 右半部分:Decoder(解码器 / 自回归生成者):
Decoder的任务是根据Encoder提取的“记忆”,加上目前已经生成的内容,来预测下一个词。这里有一个核心矛盾:理解可以一次性完成,但生成必须是逐步的(Autoregressive)。 就像在处理时序信号预测时,你只能利用过去的历史数据来推断未来的走向,当前时刻绝对不能提前“偷看”到未来的数据点。
因此,Decoder内部有两个不同的注意力机制:
- Masked Self-Attention(带掩码的自注意力):
- 位置: Decoder的最底层。
- 作用: 让Decoder在生成当前词时,只能结合已经生成的词的信息,把未来的词“遮蔽(Mask)”掉。此时的 QQQ、KKK、VVV 全部来自于已经生成的目标序列。
- Cross-Attention(交叉注意力 / 编解码器注意力):
- 位置: Decoder的中间层。
- 核心桥梁: 这就是架构图上左右两部分连线的地方
- QKV的来源: 此时的 QQQ 来自于Decoder(代表“我现在正在生成的这个词需要什么信息”),而 KKK 和 VVV 来自于左侧Encoder的最终输出(代表“源输入里有哪些信息可以回答这个查询”)。
总结:左右两部分的交互
- Encoder自己跟自己玩(Self-Attention),充分理解原文,提炼出完美的 KKK 和 VVV。
- Decoder也是先自己跟自己玩(Masked Self-Attention),搞清楚当前已经生成了什么语境,提炼出 QQQ。然后,拿着这个 QQQ 去左侧的 KKK 和 VVV 里去查(Cross-Attention),寻找下一个词的线索。
真相二:防作弊机制——Masked Attention 遮住的到底是什么?
在 Decoder 的架构图中,“Masked Attention(带掩码的注意力)”常被误读。最常见的误区是认为它遮蔽了 Encoder 传来的信息。事实上,Decoder 必须看到 Encoder 的全句信息才能准确翻译。
Decoder 它遮蔽的是自己将要生成的“未来词”,我们可以用“开卷考试”来比喻:
- Encoder 的输出: 就像印在卷子上的原题。这是一场开卷考试,你随时可以翻看原题的任何一个词,无需任何遮掩。
- Masked Attention: 就像是一块挡板,盖在你的答题纸上。你只能看到自己已经写下的答案,绝不能“偷看”尚未写出的部分。
Masked Self-Attention 的真实战场在目标序列(Target)。 在训练阶段,为了实现 GPU 的并行化,我们会一次性把正确答案塞给模型(教师强制Teacher Forcing),但是Decoder 的自注意力机制(Self-Attention)天生就是“全局互联”的,它习惯于让序列中的每一个词都去和其他所有词发生联系。如果把完整的答案一次性喂进去,当模型在位置 1 试图预测下一个词时,它的注意力机制会直接扫到位置 2 甚至位置 3 的词。这就像考试时答案直接印在了卷子上,模型不需要学习任何推理逻辑,直接把后面的词“抄”过来就行了。Loss 会迅速降为 0,但模型什么都没学到(严重的数据泄露)。因此为了既能一次性输入所有数据实现并行计算,又能防止模型偷看未来,我们就加了一个遮罩(Causal Mask)。
而实际推理阶段时,则采用串行自回归,此时模型已经训练完毕,且真实预测场景中未来词都还没生成,Mask只是顺带保持了网络计算结构的统一。
这是一种数学上的强制约束:在计算注意力分值前,模型会将未来位置的权重设为负无穷大,使得 Softmax 之后的分数为零。在数学实现上,这表现为 下三角矩阵(Lower Triangular Matrix):
[ 1, -∞, -∞ ] <-- 处理第一个词时,未来词权重为负无穷
[ 1, 1, -∞ ] <-- 处理第二个词时,只能看到前两个
[ 1, 1, 1 ] <-- 处理第三个词时,全可见
这种时间维度的约束,迫使模型在计算当前 Token 时,通过 Softmax 自动将未来的注意力权重归零,从而学会在有限的已知信息下进行预测。
Decoder 中的 Mask 机制,本质上是为了妥协于 GPU 的并行训练需求。
这里用一个机器翻译的例子来说明:
比如我正在训练翻译 “ 我爱人工智能 ” 这句话,
- 首先Encoder通过自注意力机制对这句话所有token进行并行处理,最终输出包含这句话所有语义的K和V
- 接着Decoder的训练分为下面几步:(此时假设已经翻译出 “ 我爱 ” 两个字)
第一步:矩阵化输入(一次性提取特征): 在训练时,GPU 不会先处理 < S >(起始符),再处理“ 我 ”。而是将整个输入序列 [< S >, 我, 爱] 作为一个整体矩阵 XXX 送入模型。通过三个不同的权重矩阵(WQW_QWQ, WKW_KWK, WVW_VWV),模型同时计算出包含所有词信息的查询矩阵 QQQ、键矩阵 KKK 和值矩阵 VVV Q=XWQ,K=XWK,V=XWVQ = XW_Q, \quad K = XW_K, \quad V = XW_VQ=XWQ,K=XWK,V=XWV此时,QQQ 和 KKK 矩阵里,每一行都代表一个词的特征向量。
第二步:计算全连接注意力得分(此时存在作弊): 接下来,计算序列中每个词与所有词的关联度得分,即 Q×KTQ \times K^TQ×KT。此时计算出的得分矩阵是一个 3x3 的矩阵(这里用 sss 代表原始得分): 原始得分矩阵=(s11(<S>→<S>)s12(<S>→我)s13(<S>→爱)s21(我→<S>)s22(我→我)s23(我→爱)s31(爱→<S>)s32(爱→我)s33(爱→爱))\text{原始得分矩阵} = \begin{pmatrix} s_{11}(<S>\rightarrow<S>) & s_{12}(<S>\rightarrow我) & s_{13}(<S>\rightarrow爱) \\ s_{21}(我\rightarrow<S>) & s_{22}(我\rightarrow我) & s_{23}(我\rightarrow爱) \\ s_{31}(爱\rightarrow<S>) & s_{32}(爱\rightarrow我) & s_{33}(爱\rightarrow爱) \end{pmatrix}原始得分矩阵= s11(<S>→<S>)s21(我→<S>)s31(爱→<S>)s12(<S>→我)s22(我→我)s32(爱→我)s13(<S>→爱)s23(我→爱)s33(爱→爱) 注意看第一行: < S >试图预测下一个词(应该是 “ 我 ” ),但它现在的得分里包含了 s12s_{12}s12 和s13s_{13}s13,这意味着它提前“偷看”了未来的词 “ 我 ” 和 “ 爱 ”。如果不处理,这就构成了严重的数据泄露。

第三步:盖上 Mask 遮罩(物理隔绝): 为了防作弊,我们构建一个“下三角矩阵”作为 Causal Mask。这个矩阵的右上角全部是负无穷大 (−∞-\infty−∞),左下角全部是 0。将原始得分矩阵与 Mask
矩阵相加:加Mask后的得分=(s11s12s13s21s22s23s31s32s33)+(0−∞−∞00−∞000)=(s11−∞−∞s21s22−∞s31s32s33)\text{加Mask后的得分} = \begin{pmatrix} s_{11} & s_{12} & s_{13} \\ s_{21} & s_{22} & s_{23} \\ s_{31} & s_{32} & s_{33} \end{pmatrix} + \begin{pmatrix} 0 & -\infty & -\infty \\ 0 & 0 & -\infty \\ 0 & 0 & 0 \end{pmatrix} = \begin{pmatrix} s_{11} & -\infty & -\infty \\ s_{21} & s_{22} & -\infty \\ s_{31} & s_{32} & s_{33} \end{pmatrix}加Mask后的得分= s11s21s31s12s22s32s13s23s33 + 000−∞00−∞−∞0 = s11s21s31−∞s22s32−∞−∞s33

第四步:Softmax 转换: 接着,对上面这个矩阵的每一行进行 Softmax 操作,将其转化为概率权重(相加为1)。数学魔法在这里生效: 任何数 e−∞e^{-\infty}e−∞ 都等于 0。注意力权重矩阵=(w1100w21w220w31w32w33)\text{注意力权重矩阵} = \begin{pmatrix} w_{11} & 0 & 0 \\ w_{21} & w_{22} & 0 \\ w_{31} & w_{32} & w_{33} \end{pmatrix}注意力权重矩阵= w11w21w310w22w3200w33 你看这个最终的权重矩阵:
第 1 行(预测“我”): < S > 只能看到自己(权重 w11w_{11}w11),未来的权重全是 0。
第 2 行(预测“爱”): 我 只能看到 < S > 和 我,未来的“爱”权重是 0。
第 3 行(预测“AI”): 爱 可以看到前面的所有历史信息 < S >、我、爱。
它的物理含义是分配给各个词的注意力百分比。右上角的 0 意味着“对未来的关注度为绝对的 0%”。

第五步:并行输出计算结果:
最后,将这个下三角权重矩阵去乘以包含实际词汇信息的特征矩阵 VVV。矩阵乘法本质上是一种加权求和。因为权重矩阵的巧妙设计,奇迹在这里发生了。最终输出的是一个新的 4x4 中间特征矩阵,让我们逐行看看里面到底装了什么:
第 1 行(对应 < S >): 因为它的权重向量是 [100%, 0, 0, 0],所以它乘出来的特征向量,完完全全只包含 < S > 自己的信息。
第 2 行(对应 I): 假设它的权重向量是 [30%, 70%, 0, 0],它乘出来的特征向量,融合了 < S > 和 I 的信息,但绝对没有掺杂未来的信息。
第 3 行(对应 love): 它的特征向量里,完美融合了 < S >、I 和 love 三者的信息。

由于整个过程全都是大型矩阵乘法,GPU 可以在一个计算步内(并行地)同时得出三个词位的输出向量,这个输出向量就是 Decoder 提炼出来的完美的 QQQ 矩阵,作为下一步跟Encoder得到的K、V做Cross-Attention(交叉注意力匹配)。
位置 1 输出了一个向量,去和真实标签 “ 我 ” 计算误差(Loss)。位置 2 输出了一个向量,去和真实标签“ 爱 ” 计算误差。位置 3 输出了一个向量,去和真实标签 “ 人工智能 ” 计算误差。
从这个步骤中也可以看到,Decoder的计算量比也Encoder大出很多倍,主要体现在2个方面:
- 结构层面:Decoder 天生就比 Encoder 多了一个交叉注意力机制,为了接收 Encoder 传来的全局记忆,Decoder 每走一层,都要额外进行一次极其昂贵的 Q×KT×VQ \times K^T \times VQ×KT×V 的矩阵乘法操作。
- 运行机制层面:推理阶段的“时间惩罚”与显存灾难:
- Encoder 是并行计算: 当你输入一段提示词(Prompt)时,Encoder 瞬间把整个句子并行处理完毕,提炼出特征矩阵。它的时间复杂度是常数级的。
- Decoder 是串行计算: Decoder 必须一个词一个词地生成(自回归)。假设你要让模型写一篇 1000 字的文章:
- 生成第 1 个字,它要计算 1 次。
- 生成第 2 个字,它要把前 1 个字当输入,再计算 1 次。
- ……
- 生成第 1000 个字,它要把前 999 个字当输入,再计算 1 次。
这种串行生成带来了巨大的内存读写瓶颈(Memory Bound)。
为了避免每次都重新计算前面的词浪费时间,工程上采用 “用显存空间换取计算时间” 的技术,引入了 KV Cache(键值缓存) 技术,把前面算过的特征存进显存。但是代价就是,随着生成长度的增加,显存占用量呈线性甚至指数级暴涨。
( 其实对于有Encoder的架构,训练阶段的Cross-Attention也会缓存Encoder传来的K和V,但因为Encoder全局只计算一次,缓存是静态的。真正的显存杀手是 Decoder 内部动态增长的 Self-Attention 缓存。)
引入 KV Cache 后,Decoder 面对第 100 次计算时,只需要计算最新这 1 个词的特征,然后去显存里调取前 99 个词的特征进行匹配即可。
我们以上一句话生成 [‘< S >’, ‘I’, ‘love’, ‘AI’] 为例,看看加入缓存后的微观步骤:
-
生成 I 时(输入 < S >):模型计算 < S > 的 QQQ、KKK、VVV。计算完毕后,将 < S > 的 KKK 和 VVV 存入显存(KV Cache 建立)。利用 QQQ 与缓存的 K,VK, VK,V 计算得出 I。
-
生成 love 时(输入 < S >, I): 模型不再去管 < S > 了。它只针对刚生成的 I 计算它自己的 QnewQ_{new}Qnew、KnewK_{new}Knew、VnewV_{new}Vnew。
然后,它把 KnewK_{new}Knew 和 VnewV_{new}Vnew 追加进显存的 KV Cache 里。
接着,拿着 I 的 QnewQ_{new}Qnew,去跟此时显存里完整的 Cache(包含 < S > 和 I 的 K,VK, VK,V)进行匹配打分,输出 love。 -
生成 AI 时(输入 < S >, I, love):模型只计算 love 自身的 Q,K,VQ, K, VQ,K,V。把 K,VK, VK,V 存入 Cache,然后用 QQQ 去查询库里存好的前三个词的 K,VK, VK,V,得出 AI。
但是凡事皆有代价。算力确实省下来了,但显存遭殃了。那个不断变大的 KV Cache 会疯狂吃掉 GPU
的内存。这就是为什么当生成极长的文本时,模型算力可能够用,但显存会最先爆掉(Out of Memory)。
为了缓解这个“显存灾难”,现代大模型(如 GPT-4)在结构上做出了妥协,由传统的多头注意力机制(Multi-Head Attention,MHA)换成了 MQA(多查询注意力)或GQA(分组查询注意力) 技术,让多个查询头( QQQ )去共享同一组键( KKK )和值( VVV ),从而极大地压缩 KV Cache 的体积。
- MHA(多头注意力):所谓“多头”,就是为了让模型能从多个不同的角度去理解同一句话(比如有的头关注语法,有的头关注情感),模型会把特征切分成多个平行的计算通道(Head)。假设一个模型有 8 个注意力头,则会分别计算出8组 QQQ、 KKK、 VVV,推理时也需要将8份 KKK、 VVV都塞进显存里存起来。
- MQA(多查询注意力):既然各个注意力头主要是提问的角度( QQQ )不同,那么可以共用同一组KKK、 VVV。这样 8 个不同的 QQQ 头,全部去查询唯一的一份 K、VK、 VK、V,显存占用直接暴降到原来的 1/8。但因为所有头都共享同一份记忆,模型在处理极度复杂的逻辑时,能力会出现明显的下降(变笨了)。
- GQA(分组查询注意力):属于一个“既要又要”的折中方案,也是目前大模型普遍采用的方案。我们把这 8 个 QQQ 头分成 4 组(每组包含 2 个头);再为这 4 个小组,分别生成 4 份不同的 KKK 和 VVV; 第 1 组的 2 个 QQQ 头共享第 1 份 K,VK, VK,V;第 2 组共享第 2 份……以此类推。
这样相比于传统的 MHA,它的 KV Cache 显存占用砍掉了一半(从 8 份变成了 4 份),极大地缓解了显存压力;同时,相比于极端的 MQA,它保留了 4 份不同视角的记忆特征,尽可能的保持了模型原本的推理能力。



真相三:避免“Apple Car”灾难——为什么模型训练时需要用教师机制“强行喂饭”?
传统的深度学习算法,像CNN训练时都采用“自回归训练”或者自由运行(Free-running),但是像RNN、Transformer这些Seq2seq结构的算法之所以没有采用该方式,而是选择Teacher Forcing(教师强制)策略,核心是为了解决一个极其现实的工程与数学灾难:错误级联(Error Accumulation):
- CNN的空间独立性 VS Transformer的时间依赖性:
在 CNN 的图像任务中,像素预测在空间上是相对独立的;但在 Transformer 中,生成具有极强的时间依赖性。如果不使用 Teacher Forcing(教师强制),模型会陷入“错误级联”:
- 假设正确答案是 I love AI。
- 如果模型第一步错把 I 猜成了 Apple。
- 若不干预,第二步输入就成了 Apple,模型紧接着会猜出 Car。
- 这种“一步错步步错”导致的**暴露偏差(Exposure Bias)**会让梯度计算彻底失效,模型根本不知道自己错在哪。
通过 Teacher Forcing,我们在训练时强行切断错误传播,告诉模型:“别管你刚才猜了什么,强行把正确的历史答案喂给它,现在来猜下一个词。
-
训练 Step 1: 告诉模型:“输入是 < S >,预测下一个词。” (模型猜 Apple,算 Loss 扣分)。
-
训练 Step 2: 告诉模型:“别管你刚才预测了什么,现在假设历史是完全正确的,输入是 [‘< S >’, ‘I’],结合原文预测下一个词” (模型如果在正确的语境下猜对了 love,就能得到正确的梯度更新)。
这样做的好处是巨大的:
- 切断错误传播: 每一步的预测都被隔离开来,模型可以专注学习“在完美的上下文下,下一个词应该是什么”。
- 极度契合 GPU 并行: 因为所有的输入(正确的历史前缀)我们提前都知道,所以我们可以像上面说的那样,用 Masked Attention 把它们打包成一个大矩阵,一次性扔给 GPU 并行计算出所有位置的 Loss。
如果让模型自己生成,就只能写 for 循环一步步等,GPU 利用率极低。
这样不仅让模型在“温室”中快速收敛,更关键的是,它利用 Masking 机制让模型在 GPU 上实现了极其高效的矩阵并行训练。
Teacher Forcing 虽然训练快、容易收敛,但它会留下一个被称为 暴露偏差(Exposure Bias) 的后遗症:
模型在训练时就像温室里的花朵,永远都有老师提供最正确的上下文;但真正到了推理时,没有老师了,一旦它自己生成错了一个词,它就很容易因为没见过这种“偏离正轨”的情况而彻底崩溃(也就是俗称的“胡言乱语”或“幻觉”)。
那么现在最顶级的 AI(比如 ChatGPT / Gemini)是怎么解决这个问题的呢?
- 第一阶段(预训练 / SFT): 先用 Teacher Forcing 搭配 Masked Attention,快速、高效地让模型掌握基础的语言规律和注意力机制(把模型从不及格教到 80 分)。
- 第二阶段(RLHF 强化学习): 此时模型已经有一定能力了。这时候就完全采用你提议的逻辑——给模型一个 Prompt,让它自己根据当前的权重完整地生成一整段话(不加 Teacher Forcing),然后由一个奖励模型(Reward Model)对这整段生成的结果进行“比对打分”,再利用 PPO 等强化学习算法去微调参数(把模型从 80 分逼到 95 分)。
这套“预训练 + 监督微调(SFT)+ 强化学习(RLHF)”就是当年OpenAI的第一代ChatGPT所采用的方式。
真相四:DeepSeek-R1 的降维打击——逻辑是“算”出来的,不是“教”出来的
刚刚提到经典的ChatGPT采用的是“ 预训练 + 监督微调(SFT)+ 强化学习(RLHF)”,而DeepSeek-R1(以及它的前身 R1-Zero)之所以在2025年初被称为“掀起行业地震的全新算法”,并且大幅降低了训练成本,正是因为它把 ChatGPT 的这套经典流程给“颠覆”了。
DeepSeek-R1 的出现,是对 OpenAI 传统路线的一次范式转移。此前,业界高度依赖监督微调(SFT),即雇佣大量人类写标准答案让模型模仿。
- 经典 ChatGPT 路线:人类手把手教 (SFT + RLHF)
在 DeepSeek-R1 之前,业界公认的训练范式是这样的:
- 预训练 (Pre-training): 让模型看海量网页,学会说话(此时模型像个满腹经纶但口无遮拦的野人)。
- 监督微调 (SFT - Supervised Fine-Tuning): 极其耗时耗钱的一步。雇佣大量高学历人类,写下成千上万的高质量问答对。强迫模型去模仿(Teacher Forcing)这些人类的回答格式和逻辑。
- 人类反馈强化学习 (RLHF): 训练一个“奖励模型(Reward Model)”来模仿人类的审美,给模型的输出打分(比如语句通不通顺、是否有礼貌),然后用 PPO 算法微调。
痛点: 这种方法极度依赖高质量的 SFT 数据。而且,用来打分的奖励模型往往是很主观的,很难教导模型进行极其严密的数学或代码逻辑推理。
- DeepSeek-R1 路线:给个规则,自己悟 (纯粹的强化学习驱动)
DeepSeek 团队问了一个极其大胆的问题:如果我们不雇人写答案(跳过昂贵的 SFT),直接把预训练好的“野人”模型扔进强化学习的试炼场,它能自己学会推理吗?
答案是:能,而且极其强大!这就是 DeepSeek-R1-Zero 的核心突破。
它的做法彻底改变了“打分”的逻辑:
-
抛弃主观的奖励模型,拥抱“基于规则的客观奖励 (Rule-based Reward)”。
- 当模型做一道数学题或写一段代码时,不需要另一个 AI 甚至人类来给它打分。
- 打分标准非常冷酷且精确: 代码能跑通吗?数学题最后的答案是不是等于 42?
- 如果对,就给巨大的正向 Loss 奖励;如果错,就给惩罚。
-
GRPO 算法:大幅砍掉显存和计算量的秘密武器
- 传统的强化学习(比如 PPO)在更新参数时,不仅需要运行生成模型(Actor),还需要在显存里常驻一个差不多一样大的“评论家模型(Critic)”来评估当前的动作好不好。这导致训练对显存的要求翻倍。
- DeepSeek 提出了 GRPO (Group Relative Policy Optimization)。它扔掉了那个庞大的 Critic 模型。
- 它的逻辑是“组内矮子里拔将军”: 针对同一个问题,让模型自己生成一批(比如 8 个)不同的答案。然后根据客观规则给这 8 个答案打分。得分高于这 8 个答案平均值的,就强化其生成路径;低于平均值的,就抑制。
- 这样一来,不需要额外的评论家模型,极大节省了计算资源。DeepSeek-R1 证明了:推理能力可以纯粹由强化学习(RL)驱动。
-
ChatGPT 路线: 侧重于“模仿人类”,教模型如何说话才得体,逻辑往往源于人类数据的投喂。
-
DeepSeek 路线: 给予客观规则(如数学对错、代码运行结果),让模型在无数次试错中自我博弈。
核心结论: “逻辑是算出来的,不是教出来的!”
DeepSeek-R1-Zero 证明了,只要有冷酷的规则裁判,模型能自发产生“顿悟(Aha moment)”和自我纠错能力。逻辑不再是昂贵人工标注的产物,而是算力在规则碰撞下溢出的智慧。
真相五:GRPO 算法——如何通过“组内内卷”省下巨额算力?
DeepSeek 能够实现性能与成本的降维打击,核心武器是 GRPO(组相对策略优化)。
在传统的强化学习(比如 PPO 算法)中,有一个庞大的 Critic 模型。而DeepSeek-R1-Zero不仅扔掉了基于神经网络的“打分器(Reward Model)”,还顺手把“评估基线(Critic Model)”也给丢掉了。
- “客观规则”到底是什么?(扔掉神经网络 Reward Model)
在 ChatGPT 的 RLHF 里,给答案打分的 “ Reward Model ” 是一个真正的深度学习神经网络。它需要被训练,才能具备人类的审美,告诉你这篇作文能打 8 分还是 9 分。
但在 DeepSeek-R1 面对的数学和代码任务中,“客观规则”根本不是神经网络,它就是几行极其简单的 Python 代码(脚本)。- 对于数学题: Python 脚本会用正则表达式提取模型输出的最后一个 \boxed{} 里的内容。如果提取出的内容和标准答案完全一致(比如都是 42),Python 函数直接 return 1.0;如果不一致,return 0.0。
- 对于代码题: Python 脚本会把模型生成的代码丢进一个沙箱环境里编译运行。如果所有测试用例(Test cases)都跑通了,return 1.0;报错了或者超时了,return 0.0 或给予负分惩罚。
结论: 这一步只是冷酷的程序逻辑判定,不需要任何 AI 算法(Critic 或 Reward 模型)的介入。
- 为什么不再需要 Critic?(GRPO 的核心魔法)
得到了 Python 脚本给的 1.0 或 0.0 之后,还没完。在强化学习中,我们要更新模型,需要计算的是优势(Advantage)。
- 优势 = 实际得分 - 预期基线(Baseline)
- 如果优势是正的,说明表现超出预期,大力鼓励这种生成方式;
- 如果优势是负的,说明表现低于预期,狠狠惩罚。
- 传统 PPO 的痛点: 每次生成一个答案,为了知道“这个分数到底算好还是算坏”,必须引入一个 Critic 神经网络。Critic 的唯一工作就是预测“在当前状态下,模型大概能拿多少分”(也就是预估这个基线 Baseline)。维护和计算这个 Critic 会消耗一倍的显存!
- DeepSeek GRPO 的破局:用“组内内卷”代替“专家评估”
- GRPO (Group Relative Policy Optimization) 算法极其巧妙地利用了统计学,彻底废掉了 Critic。它的具体做法是这样的:面对同一个问题(比如一道复杂的微积分题),模型不只生成 1 个答案,而是同时生成 NNN 个答案(通常 N=4N=4N=4 到 N=8N=8N=8 之间)。
- 批量生成: 模型给出了 8 个不同的解题过程和结果。
- 规则打分: 把这 8 个答案扔进 Python 脚本。假设有 3 个算对了,5 个算错了。脚本返回了一组分数:[1, 0, 0, 1, 0, 1, 0, 0]。
- 计算基线(替代 Critic): 根本不去预测什么期望值!直接算这 8 个分数的平均值(Mean)和标准差(Std)。在这组数据里,平均值 μ=0.375\mu = 0.375μ=0.375。这个平均值就是天然的“基线”!
- 计算优势(Advantage): 把每个分数减去平均值,再除以标准差(也就是做一个简单的标准化处理)。
- 算对的那些,优势值是正数(因为 1>0.3751 > 0.3751>0.375),梯度会鼓励模型记住它们生成时的思考路径。
- 算错的那些,优势值是负数(因为 0<0.3750 < 0.3750<0.375),梯度会惩罚并抑制那些错误的思考路径。
缺点:
但是在处理非标准答案(比如文本对话、写诗、摘要)时,“客观规则”不仅不能简单理解为二分类问题,而且纯靠客观规则根本走不通。这也是 DeepSeek-R1-Zero 和最终发布的 DeepSeek-R1 之间最大的区别。
注意: 虽然在逻辑任务上完全去中心化,但在处理日常对话等主观任务或者没有标准答案的问题(比如文本对话、写诗、摘要)时,DeepSeek
依然采用混合奖励机制(Hybrid Reward),结合神经网络打分与格式规则约束,以确保模型在变聪明的同时依然“会说话”:
- 对于数学/代码等“有标准答案”的任务:
依然坚持使用 客观规则(Rule-based Reward)。这确实是一个简单的二分类问题(或者离散的分数,比如跑通了一半测试用例给 0.5 分)。- 对于文本对话、创意写作等“无标准答案”的任务:
团队不得不请回了传统的“神经网络奖励模型(Neural Reward Model)”,就像 ChatGPT 那样,用一个专门训练过的人类偏好模型来给生成的文本打分。此时的得分是一个连续的浮点数(比如 0.85 分表示非常符合人类喜好,0.2 分表示答非所问)。
总结:GRPO 引擎 + 多元化的裁判
需要把 “算法引擎 (GRPO)” 和 “裁判打分 (Reward)” 分开看:
- 引擎(GRPO)是不变的: 无论面对什么任务,它依然是让模型生成一批答案,算出平均分,然后“组内内卷”计算优势(Advantage),全程不需要 Critic 模型。
- 裁判(Reward)是可变的:
- 做数学题:裁判是冷酷无情的 Python 规则(0 或 1)。
- 做日常对话:裁判是“神经网络打分器(看重质量)” + “格式规则校验器(看重规范)”的结合体。
在日常讨论中,大家往往把 “RLHF(基于人类反馈的强化学习)” 简化成了一个黑盒,统称为“奖励模型”。事实上,在任何强化学习(RL)系统中,“打分系统(Reward)” 和 “参数更新算法(Engine)” 是两个完全独立的物理组件。
我们可以把强化学习训练模型的过程,想象成“教练训练运动员”:
-
裁判 / 奖励机制(Reward)—— 负责“打分”
这部分解决的问题是:“模型这次生成的答案到底好不好?”- 在传统的 RLHF 中: 这个裁判确实是一个完整的深度学习神经网络(即 Reward Model),它被训练出来模仿人类的喜好。它给出的分数是一个连续的浮点数(比如 0.85 分)。
- 在 DeepSeek 处理数学/代码时: 裁判被换成了一段没有人工智能成分的 Python 脚本(客观规则)。答案对就是 1,错就是 0。
- 在 DeepSeek 处理日常对话时: 裁判变成了混合体(Hybrid)。它既需要传统的神经网络 Reward Model 来评判语气是否通顺,又需要客观规则来检查是否输出了 < think > 标签(1),还是输出< \think >(0)。
-
引擎 / 优化算法(Engine)—— 负责“涨经验(更新权重)”
这部分解决的问题是:“拿到裁判的分数后,模型该如何调整大脑(更新参数),确保下次表现更好?” 仅仅知道分数是不够的,你必须有一套复杂的数学公式去计算梯度。- 在传统的 RLHF 中: 充当引擎的通常是 PPO 算法。PPO 引擎极其臃肿,它不仅需要生成答案的模型(Actor),还需要在显存里额外挂载一个庞大的“评论家模型(Critic)”来预估基线分数,从而计算优势值(Advantage)。
- 在 DeepSeek-R1 中: 充当引擎的换成了 GRPO 算法。这个引擎极其轻量,它彻底扔掉了 Critic 模型。它的工作方式是让模型同时生成 8 个答案,把裁判(不管是 Python 脚本还是神经网络)给这 8 个答案打的分数拿过来,自己算一个平均分作为基线。高于平均分就奖励,低于平均分就惩罚。
结语:从“情商”到“智商”的范式转移
当前 AI 的进化正呈现出“两条腿走路”的态势:
- SFT(监督微调): 负责对话的得体与礼貌,这是 AI 的“情商”。
- RL(强化学习): 负责推理的严密与准确,这是 AI 的“智商”。
目前 ChatGPT(以 GPT-4o 为代表)和 Gemini(以 1.5 Pro/Ultra 为代表)的基础对话版本,其核心的对齐基石依然是“SFT + RLHF”的思路,但整个行业实际上已经分裂成了“两条不同的科技树”:
- 通用对话模型(GPT-4o, Gemini 1.5):依然是 SFT + RLHF 的拥趸
- 深度推理模型(OpenAI o1):转向“重度 RL”的先驱
DeepSeek 的成功预示着,未来 AI 的核心竞争力将不再是人类喂了多少数据,而是模型在规则框架下进行了多少次自我进化的博弈。
思考:
如果未来的 AI逻辑完全通过这种“自我博弈”进化,甚至推演出人类无法理解的证明过程,那么人类在数据链条中的最终位置,将会在哪里?人类最终的壁垒是否仅剩下定义那套决定进化方向的“奖惩函数”?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)