(Arxiv-2026)FlowInOne:将多模态生成统一为图像输入、图像输出的流匹配
FlowInOne:将多模态生成统一为图像输入、图像输出的流匹配
paper title:FLOWINONE: UNIFYING MULTIMODAL GENERATION AS IMAGE-IN, IMAGE-OUT FLOW MATCHING
paper是电子科大发布在arxiv 2026的工作
Code:地址
摘要
多模态生成长期以来由文本驱动的流程主导,语言支配视觉但无法在视觉空间中进行推理或创作。我们通过提出一个问题来挑战这一范式:所有模态——包括文本描述、空间布局和编辑指令——是否都能统一到单一视觉表示中?我们提出 FlowInOne,一个将多模态生成重新定义为纯视觉流的框架,将所有输入转换为视觉提示,并通过单一流匹配模型实现简洁的图像输入、图像输出流程。这种以视觉为中心的表述从根本上消除了跨模态对齐瓶颈、噪声调度以及任务特定的架构分支,将文本到图像生成、布局引导编辑和视觉指令跟随统一在一个连贯的范式下。为此,我们引入 VisPrompt-5M——一个包含 500 万视觉提示对的大规模数据集,涵盖多样化任务,包括物理感知的力动力学与轨迹预测;同时引入 VP-Bench,一个经过严格筛选的基准,用于评估指令忠实度、空间精度、视觉真实感和内容一致性。大量实验表明,FlowInOne 在所有统一生成任务上达到最先进性能,超越了开源模型和商业系统,为感知与创作共存于单一连续视觉空间的全视觉中心生成建模奠定了新基础。
关键词:以视觉为中心 · 图像生成 · 流匹配 · 视觉提示 · 指令跟随
1 引言
多模态生成长期运行在文本主导的假设下:语言编码意图,视觉执行表达。扩散模型和基于 Transformer 的文本到图像系统依赖语言嵌入作为核心条件来源。尽管这一设计能实现令人印象深刻的视觉保真度,但它引入了一个根本性的不对称性:语言控制视觉,但视觉本身无法独立推理或生成。这种表示空间的碎片化使得在单一连贯模型中统一理解、编辑和生成变得内在困难。
近来,视觉中心模型的趋势逐渐兴起,这些研究表明文本信息可以通过将文字渲染到像素空间来以纯视觉方式处理。这些研究共同表明,视觉模态本身具有足够的表达能力,可以作为多模态理解的基础。这些研究共同证明,通过视觉方式表示语言能够在单一模态内实现统一的感知与对齐。然而,这些方法根本上仍是感知导向的,视觉优先表述的生成潜力在很大程度上尚未被探索。这引发了一个重要问题:我们能否构建一个大型模型,完全在视觉空间内进行推理和生成?
流匹配为这一问题提供了有原则的答案。与扩散模型相比,流匹配直接学习变换的底层速度场,提供更高的采样效率和稳定的优化。通过学习视觉流而非随机噪声去除,它在单一确定性原则下连接了感知与生成。
在本工作中,我们朝着这一目标迈出决定性一步,提出 FlowInOne——一个将多模态生成重新定义为纯视觉流的框架。在 FlowInOne 中,文本、布局和指令输入首先被转换为视觉提示,构成输入图像状态。模型随后学习一个连续的传输过程,利用流匹配将该状态演化为目标视觉输出。这一表述实现了简洁通用的训练流程,消除了噪声调度、扩散采样以及任务特定的条件头。
如图 1 所示,FlowInOne 摒弃了传统的文本条件流程。传统文本到图像或图像编辑模型使用文本编码器(如 Flan-T5)对潜在扩散模型进行条件化,而文本到图像设置则需要两个编码器进行联合条件化。相比之下,FlowInOne 将所有输入条件统一为视觉提示,通过单一模型形成简洁的图像输入、图像输出流程。这一设计不仅简化了架构,还确保了语义内容与空间控制在文本到图像生成、布局引导编辑和视觉指令跟随等多样化任务中的一致对齐。
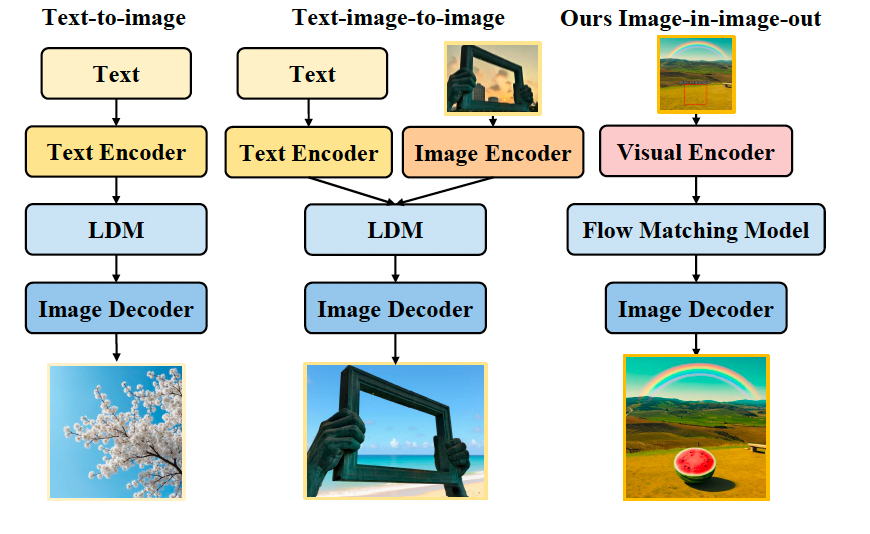
图 1:生成范式的比较。左:传统的 T2I 仅使用文本编码器来对潜在扩散模型(LDM)进行条件控制;中:传统的 TI2I 需要文本编码器和图像编码器的联合条件控制;右:我们将条件统一为视觉输入,并用单一模型构建了一个简洁的图像输入、图像输出框架。
为支持这一统一范式,我们构建了 VisPrompt-5M——一个大规模视觉提示数据集,涵盖文本到图像生成、多样化视觉编辑和物理感知指令跟随。每个样本将视觉提示画布与其对应的目标图像配对,在不依赖任务特定模块或辅助通道的情况下,以连续视觉演化提供监督信号。我们进一步引入 VP-Bench——一个经过精心策划的评估基准,从四个维度评估模型性能:指令忠实度、内容一致性、视觉真实感和空间精度。
我们的主要贡献如下。i. 我们将多模态生成重新定义为以视觉为中心的图像输入、图像输出范式,消除了文本编码器和模态特定的分支。ii. 我们提出 FlowInOne,一个统一的流匹配框架,将多模态变换建模为共享潜在空间内的连续视觉演化。iii. 我们构建 VisPrompt-5M,一个全面的视觉提示数据集,支持跨文本到图像、图像到图像以及指令引导生成任务的统一训练和强泛化。大量实验表明,FlowInOne 在统一生成、精确图像编辑和物理感知指令跟随方面达到最先进性能,为全视觉中心生成建模奠定了新基础。
2 相关工作
扩散与流匹配。从 DDPM 到 LDM 和 DiT,扩散模型通过渐进式去噪主导了图像生成。流匹配学习分布之间的连续传输映射,减少对复杂噪声调度的依赖,同时提升采样效率和稳定性。在此基础上,FlowInOne 直接在共享潜在空间内建模连续演化,完全消除额外的条件化或噪声注入。
文本与图像条件生成。当前 T2I 模型通常通过交叉注意力注入离散文本 token,使控制信号与视觉空间脱节。类似地,传统图像到图像转换、图像修复和可控编辑方法高度依赖对抗框架、扩散先验或外部控制通道。这些方法的一个共同局限是依赖显式掩码或任务特定接口来进行几何和语义控制。相比之下,FlowInOne 完全绕过了专门的条件化分支。通过将文本和箭头等异构约束统一为单一图像输入,我们将多种形式的控制原生地融合到视觉域中,在视觉空间内对齐语义与几何。
模态映射。虽然标准扩散模型将离散文本映射到图像,但内在的模态差距、tokenization 伪影以及对高斯噪声的依赖严重限制了空间精度。超越通用图像到图像转换,我们从根本上将生成定义为模态内传输问题。通过将视觉指令输入和目标图像都编码到共享的同构潜在空间中,我们学习它们之间的直接无噪声流。纯单一模态映射在潜在层面解决了结构不匹配问题,在多样化编辑和生成任务中展现出卓越的可扩展性。
3 数据集与基准
在本节中,我们详细介绍 VisPrompt-5M 数据集(第 3.1 节)和我们的评估基准 VP-Bench(第 3.2 节)的构建。
3.1 VisPrompt-5M

图 2:VisPrompt-5M 是一个综合性数据集,包含八种不同的数据类型,包括类别到图像生成、文本到图像生成、图像内文本编辑、文本边界框编辑、视觉标记编辑、涂鸦编辑、力理解以及轨迹理解。该数据集覆盖了广泛的图像到图像生成任务范围,从基础的图像内文本生成,到组合式编辑,再到具备物理感知的指令跟随。
如图 2 所示,VisPrompt-5M 实现了统一的图像输入、图像输出范式。训练对 ( I v , I ∗ ) (I_v, I^*) (Iv,I∗) 将所有文本和空间指令直接嵌入到输入画布 I v I_v Iv 中。消除辅助文本通道可减少歧义并强制严格的几何对齐,使单一模型能够在一种模态内处理多样化任务。
基础生成。我们从 text-to-image-2M 中渲染文本提示,并从 860K 高质量 ImageNet 子集中直接将类标签作为输入画布,以匹配对应的目标图像。
图像内文本编辑。该类别通过将文本指令直接叠加到输入图像画布上,统一了多样化的编辑和条件到图像任务。从 GPT-Image-Edit、Pico-Banana 和 UnicEdit 中,我们筛选掉复杂或不一致的对来保留约 160 万个示例,涵盖增加、删除和属性/环境变更等多样化编辑。此外,我们无缝整合来自 PixWizard 的 31.5K 结构化图像对,涵盖广泛的任务,包括 Canny 到图像、深度到图像、图像修复和图像修复。总计,这产生了近 190 万个对,所有操作意图都以视觉提示的形式显式嵌入。
文本边界框编辑。对于具有显式几何约束的精确目标插入,我们从 GPT-Image-Edit 中提取 45K 高质量示例子集。利用 Qwen Image Edit 和 Qwen3-VL 的联合先验来引导 I2I 生成,我们合成文本和边界框共同决定目标类别、比例和位置的对。通过 Qwen3-VL 7B 的自动过滤,最终保留 24K 高质量对。
视觉标记编辑。利用 Qwen3-VL 的视觉理解能力,我们生成 25 万对,其中箭头注释作为显著线索,无需在指令中使用显式目标名称。该子集支持删除、替换等操作,通过视觉标记隐式表示语义和空间关系。
涂鸦编辑。使用包含 Qwen Image Edit 的两阶段合成流程,基于从网络爬取的 5K 张图像,我们首先添加涂鸦来创建输入图像,然后将其转换为逼真的目标对象以形成目标图像。严格的人工检查减少了生成不稳定性,产生 1100 个高质量对,其中涂鸦线条明确作为形状先验。
力与轨迹理解。VisPrompt-5M 支持物理感知生成。对于运动轨迹,我们手动标注了 Blender 渲染的汽车和球运动视频,产生 1500 个严格筛选的图像对。对于力的理解,我们利用 Force Prompting 数据集,涵盖空气动力学、振荡和线性运动。通过提取关键帧并叠加文本和箭头来表示精确的力量大小和方向,我们在输入图像中显式可视化物体动力学。
在整个流程中,我们强制执行标准化的数据格式,同时严格维护任务元数据和几何属性。我们还采用基于 MLLMs 的自动质量控制措施,以确保语义一致性、视觉保真度和视觉文本可读性。
3.2 基准与评估
为了评估我们的纯图像输入、图像输出范式,我们精心策划了 VP-Bench——一个全面且经过人工筛选的基准,涵盖多样化视觉指令(详见附录 B)。
由于传统指标如 FID 难以处理复杂视觉指令,我们遵循近期研究,采用 VLMs 作为主要评估器。一个生成结果被认为成功,当且仅当它同时满足四个标准:(1) 指令忠实度,(2) 内容一致性,(3) 视觉真实感,(4) 空间精度。除 VLM 评估外,我们还基于这四个完全相同的标准进行严格的人工评估,以计算总体通过率。由于标准 VLM 可能会遗漏图像画布上渲染的文本指令中的隐含约束,我们手动提取文本指令并将其作为补充文本提示提供,以确保公平评估(VLM 评估提示参见附录 F)。
为全面评估视觉质量和编辑准确性,我们额外为范式定制了四个量化指标:(1) CLIP-IQA 用于衡量整体视觉真实感;(2) CLIP Score 用于评估纯生成任务的语义对齐,直接计算从输入图像渲染的文本指令与生成图像之间的相似度;(3) Directional CLIP Similarity 用于评估基于标记编辑中的语义一致性,利用 MLLM 为输入和生成图像生成说明,并计算图像转换与对应说明对之间的方向对齐;(4) DINOv3 Directional Similarity(DINOv3 Sim)用于精确捕捉细粒度空间和物理结构变化,直接在密集 DINOv3 特征空间内计算输入、生成和真值图像之间编辑位移向量的余弦相似度。
4 方法
在本节中,我们首先简要回顾流匹配的预备知识(第 4.1 节),介绍将视觉指令编码到统一视觉语义空间的核心策略(第 4.2 节),最后介绍 FlowInOne 的详细架构(第 4.3 节),其中包含一种新颖的双路径空间自适应调制机制,以平衡结构保留与指令遵循。
4.1 预备知识:流匹配
流匹配(FM)将生成建模定义为在 t ∈ [ 0 , 1 ] t \in [0, 1] t∈[0,1] 上从源分布 p 0 p_0 p0 到目标分布 p 1 p_1 p1 的连续传输。与传统扩散模型不同,FM 不依赖复杂的噪声调度,并允许非高斯源分布(前提是它们与目标同构)。在训练过程中,FM 在样本对 ( z 0 , z 1 ) (z_0, z_1) (z0,z1) 之间构建可微的概率路径 z t z_t zt,直接产生用于监督的真值速度 v t ∗ v_t^* vt∗:
z t = t z 1 + ( 1 − ( 1 − σ min ) t ) z 0 , v t ∗ = ∂ z t ∂ t = z 1 − ( 1 − σ min ) z 0 (1) z_t = tz_1 + (1 - (1 - \sigma_{\min})t)z_0, \quad v_t^* = \frac{\partial z_t}{\partial t} = z_1 - (1 - \sigma_{\min})z_0 \tag{1} zt=tz1+(1−(1−σmin)t)z0,vt∗=∂t∂zt=z1−(1−σmin)z0(1)
网络通过最小化对 v t ∗ v_t^* vt∗ 的均方误差(MSE)来学习时间相关的速度场 v θ ( z t , t ) v_\theta(z_t, t) vθ(zt,t)。在我们的 FlowInOne 框架中,我们明确定义了一个非高斯源分布: z 0 z_0 z0 代表通过视觉编码器和文本图像 VAE 提取的统一视觉指令的潜在状态,而 z 1 z_1 z1 代表目标图像的潜在变量。由于两个潜在变量在共享空间内是同构的,推理直觉上通过求解常微分方程 d z t d t = v θ ( z t , t ) \frac{dz_t}{dt} = v_\theta(z_t, t) dtdzt=vθ(zt,t) 从 t = 0 t = 0 t=0 到 t = 1 t = 1 t=1 来完成,确定性地将视觉指令演化为最终目标图像。
4.2 视觉语义空间中文本的统一处理
离散语言符号与连续视觉纹理之间的内在异质性在流匹配中带来了显著的对齐挑战。为缓解这一问题,我们提出了一种范式转变:将文本指令和多样化视觉线索直接渲染到图像画布上。这明确保留了空间布局和结构先验,而无需依赖复杂的跨模态对齐模块。
通过将文本视为整体视觉几何的一部分,我们规避了文本 tokenizer 通常引入的语义碎片化。为从这个统一输入 I v I_v Iv 中提取鲁棒表示,我们利用 Janus-Pro-1B 的视觉编码器。输入通过 SigLIP Vision Transformer 处理,提取 patch 级语义特征,然后通过 MLP 投影映射到目标嵌入空间:
X fuse = MLP ( SigLIP ( I v ) ) ∈ R N × D (2) X_{\text{fuse}} = \text{MLP}(\text{SigLIP}(I_v)) \in \mathbb{R}^{N \times D} \tag{2} Xfuse=MLP(SigLIP(Iv))∈RN×D(2)
其中 N N N 是 patch 数量, D D D 表示嵌入维度。该序列 X fuse X_{\text{fuse}} Xfuse 同时封装了文本语义和视觉几何。
为执行连续流匹配,我们通过文本图像 VAE 将统一视觉 token 映射到源潜在空间。该 VAE 不直接预测潜在变量,而是参数化一个分布以采样源状态 Z T I ∼ N ( μ ˉ Z 0 , diag ( σ ˉ z 0 2 ) ) ∈ R H × W × C Z_{TI} \sim \mathcal{N}(\bar{\mu}_{Z_0}, \text{diag}(\bar{\sigma}_{z_0}^2)) \in \mathbb{R}^{H \times W \times C} ZTI∼N(μˉZ0,diag(σˉz02))∈RH×W×C。对称地,冻结的图像 VAE 将目标图像编码为同构潜在变量 Z I Z_I ZI。因此,我们的生成过程被优雅地表述为建模时间相关的速度场,在共享潜在空间内将源潜在变量 Z T I Z_{TI} ZTI 连续传输到目标图像潜在变量 Z I Z_I ZI。
4.3 FlowInOne
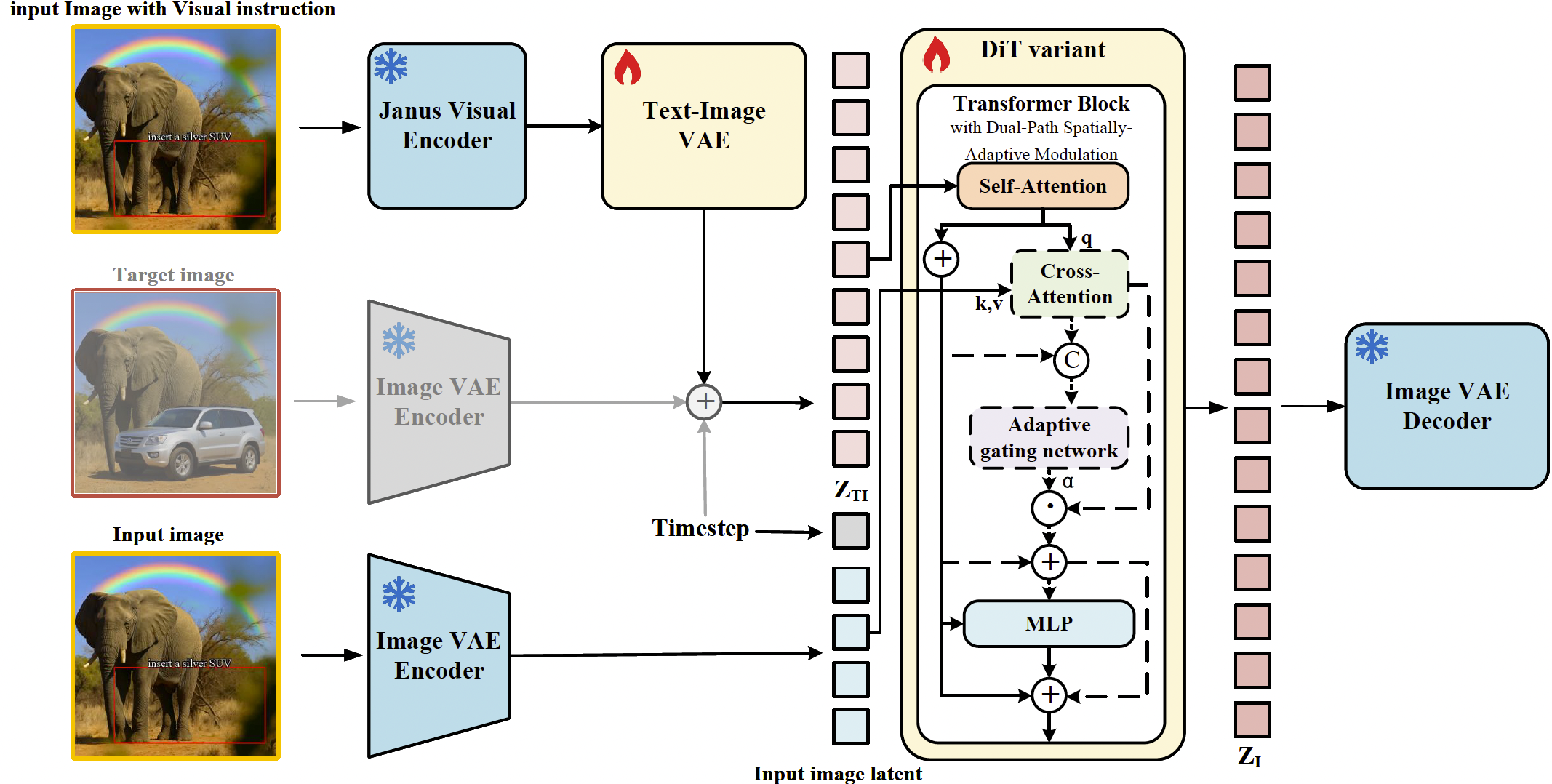
图 3:FlowInOne 架构概览。这是一个通用且简洁的框架,使用流匹配在单一模态中实现连续演化。FlowInOne 采用双路径空间自适应调制机制,以根据模态调整计算方式。对于仅含文本的输入图像生成,结构分支会被跳过,以严格遵循语义演化。相反,在图像编辑任务中,空间自适应门控网络与交叉注意力机制会被激活,用于选择性注入源图像先验,从而动态平衡原始图像保留与指令驱动的重建。
双路径空间自适应调制。在本文提出的统一流匹配框架内,我们将图像生成定义为从起始分布 p 0 p_0 p0 到目标分布 p 1 p_1 p1 的确定性轨迹演化。然而,由于视觉编码阶段固有的信息压缩,初始潜在变量 Z T I Z_{TI} ZTI 通常无法充分捕捉源图像 I src I_{\text{src}} Isrc 的细粒度结构特征。为此,我们引入了双路径空间自适应调制机制。该机制旨在基于特定任务类型动态切换计算路径,同时补偿缺失的结构流形。如图 3 所示,设 H ( l ) ∈ R N × D \mathbf{H}^{(l)} \in \mathbb{R}^{N \times D} H(l)∈RN×D 为第 l l l 个 Transformer 层的隐藏状态,其中 N N N 为序列长度, D D D 为特征维度。该状态首先通过自注意力 A self \mathcal{A}_{\text{self}} Aself 更新,以捕获全局上下文信息:
H ~ ( l ) = LayerNorm ( H ( l ) + A self ( H ( l ) ) ) (3) \tilde{\mathbf{H}}^{(l)} = \text{LayerNorm}(\mathbf{H}^{(l)} + \mathcal{A}_{\text{self}}(\mathbf{H}^{(l)})) \tag{3} H~(l)=LayerNorm(H(l)+Aself(H(l)))(3)
通过自注意力增强特征后,模型遵循由两类任务定义的双路径条件分支。对于视觉输入中的文本到图像生成,由于不需要维护外部结构先验,模型绕过交叉注意力层以防止引入无关噪声。这确保生成轨迹严格遵循文本语义主导的演化。相反,对于涉及源图像的图像编辑,我们采用图像 VAE 编码器将 I src I_{\text{src}} Isrc 映射到潜在空间,得到潜在变量 z src ∈ R H × W × C \mathbf{z}_{\text{src}} \in \mathbb{R}^{H \times W \times C} zsrc∈RH×W×C。由于 z src \mathbf{z}_{\text{src}} zsrc 捕获了图像的视觉结构,我们将其重塑为参考序列 S ∈ R N × C \mathbf{S} \in \mathbb{R}^{N \times C} S∈RN×C,其中 N = H × W N = H \times W N=H×W。随后,结构增量 Δ H struct \Delta\mathbf{H}_{\text{struct}} ΔHstruct 通过交叉注意力机制计算,其中中间状态 H ~ ( l ) \tilde{\mathbf{H}}^{(l)} H~(l) 作为 Query,参考序列 S \mathbf{S} S 作为 Key-Value 对:
Δ H struct = Softmax ( ( H ~ ( l ) W Q ) ( S W K ) ⊤ d k ) ( S W V ) (4) \Delta\mathbf{H}_{\text{struct}} = \text{Softmax}\left(\frac{(\tilde{\mathbf{H}}^{(l)}\mathbf{W}_Q)(\mathbf{S}\mathbf{W}_K)^\top}{\sqrt{d_k}}\right)(\mathbf{S}\mathbf{W}_V) \tag{4} ΔHstruct=Softmax(dk(H~(l)WQ)(SWK)⊤)(SWV)(4)
为在源图像保真度与指令跟随对齐之间实现最优权衡,我们设计了一个轻量级自适应门控网络。通过连接当前去噪状态与提取的源信息,网络预测各向异性的 token 级权重向量 Λ ∈ [ 0 , 1 ] N \boldsymbol{\Lambda} \in [0,1]^N Λ∈[0,1]N。这一设计使模型能够在 patch 级粒度上识别空间异质性——具体地,区分属于需要严格保留的背景流形的区域与需要重建的编辑目标区域。门控系数矩阵的推导如下:
Λ = σ ( MLP θ ( H ~ ( l ) ∥ Δ H struct ) ) (5) \boldsymbol{\Lambda} = \sigma\left(\text{MLP}_\theta\left(\tilde{\mathbf{H}}^{(l)} \| \Delta\mathbf{H}_{\text{struct}}\right)\right) \tag{5} Λ=σ(MLPθ(H~(l)∥ΔHstruct))(5)
其中 ∥ \| ∥ 表示沿通道轴的特征拼接, σ \sigma σ 表示 Sigmoid 激活函数。最终层输出 H out ( l ) \mathbf{H}_{\text{out}}^{(l)} Hout(l) 通过由任务控制的条件公式 I edit \mathbb{I}_{\text{edit}} Iedit 整合:
H out ( l ) = H ~ ( l ) + I edit ⋅ ( Λ ⋅ Δ H struct ) (6) \mathbf{H}_{\text{out}}^{(l)} = \tilde{\mathbf{H}}^{(l)} + \mathbb{I}_{\text{edit}} \cdot (\boldsymbol{\Lambda} \cdot \Delta\mathbf{H}_{\text{struct}}) \tag{6} Hout(l)=H~(l)+Iedit⋅(Λ⋅ΔHstruct)(6)
这里, I edit ∈ { 0 , 1 } \mathbb{I}_{\text{edit}} \in \{0, 1\} Iedit∈{0,1} 是二元指示符:对于纯文本到图像输入, I edit = 0 \mathbb{I}_{\text{edit}} = 0 Iedit=0,调制项被置零以切断结构依赖;对于包含视觉指令和源图像的输入, I edit = 1 \mathbb{I}_{\text{edit}} = 1 Iedit=1,激活空间自适应细化。通过 Λ \boldsymbol{\Lambda} Λ 精确控制结构流形的渗透,该方法有效缓解了过度保留导致的编辑冲突。此外,通过利用显式结构补偿,它显著降低了复杂图像编辑场景下流匹配的演化误差。
在统一模态中流动。我们将视觉指令图像到目标图像建模为共享潜在空间中的流匹配过程。给定从统一视觉编码器获得的指令序列 X ∈ R N × C X \in \mathbb{R}^{N \times C} X∈RN×C,通过变分自编码器定义变分后验:
q ψ ( z ∣ X ) = N ( μ ˉ X , diag ( σ X 2 ) ) , (7) q_\psi(z|X) = \mathcal{N}(\bar{\mu}_X, \text{diag}(\sigma_X^2)), \tag{7} qψ(z∣X)=N(μˉX,diag(σX2)),(7)
z 0 ∼ q ψ ( z ∣ X ) , z 0 ∈ R N × D . z_0 \sim q_\psi(z|X), \quad z_0 \in \mathbb{R}^{N \times D}. z0∼qψ(z∣X),z0∈RN×D.
图像侧的训练与采样在潜在空间进行:来自 LDM 的预训练冻结 VAE Enc img \text{Enc}_{\text{img}} Encimg 用于将目标图像 I ∗ I^* I∗ 映射到目标潜在变量:
z 1 = Enc img ( I ∗ ) ∈ R N × D . (8) z_1 = \text{Enc}_{\text{img}}(I^*) \in \mathbb{R}^{N \times D}. \tag{8} z1=Encimg(I∗)∈RN×D.(8)
训练时采用原始流匹配:时间从 t ∼ U ( 0 , 1 ) t \sim \mathcal{U}(0,1) t∼U(0,1) 采样,并按公式 (1) 构建线性插值。瞬时速度由向量场 v θ ( z , t ) v_\theta(z, t) vθ(z,t) 表示,最小化
L FM = E ( z 0 , z 1 ) , t [ ∥ v θ ( z t , t ) − ( z 1 − z 0 ) ∥ 2 2 ] . (9) \mathcal{L}_{\text{FM}} = \mathbb{E}_{(z_0,z_1),t}\left[\|v_\theta(z_t, t) - (z_1 - z_0)\|_2^2\right]. \tag{9} LFM=E(z0,z1),t[∥vθ(zt,t)−(z1−z0)∥22].(9)
推理时,仅给定视觉指令图像 I v I_v Iv,首先从 z 0 ∼ q ψ ( ⋅ ∣ E v ( I v ) ) z_0 \sim q_\psi(\cdot|E_v(I_v)) z0∼qψ(⋅∣Ev(Iv)) 采样,然后求解常微分方程。获得 z ^ 1 = z t = 1 \hat{z}_1 = z_{t=1} z^1=zt=1 后,最终图像 I ^ = Dec img ( z ^ 1 ) \hat{I} = \text{Dec}_{\text{img}}(\hat{z}_1) I^=Decimg(z^1) 通过冻结的图像 VAE 解码器生成。该过程实现了从指令状态到图像状态在统一一维序列模态内的连续传输,避免了额外的噪声调度和条件分支,并保持了与视觉指令同构的表示。
5 实验结果
在本节中,我们首先提供 FlowInOne 的实现细节(第 5.1 节),然后展示在精心策划的 VP-Bench 上的主要结果(第 5.2 节)。最后,我们进行消融实验,以更好地理解 FlowInOne 图像生成的设计选择(第 5.3 节)。
5.1 实现细节
模型架构。基于 CrossFlow 框架,我们通过 Janus-pro-1B 和冻结的 LDM 文本图像 VAE 对统一图像输入进行编码,将其投影到堆叠的 Transformer 图像-文本 VAE 中。我们通过额外的交叉注意力层增强 Transformer 块。拼接的自注意力和交叉注意力输出随后被输入到轻量级网络中,以预测用于输入特征调制的空间自适应权重。
训练细节。1.2B 的 FlowInOne 从 CrossFlow 初始化,在 256 × 256 256 \times 256 256×256 分辨率下通过平衡的 WebDataset 训练 24 万步,优化流匹配、KL 散度和 CLIP 对比损失的组合(详细配置和更多消融实验参见附录 G)。
评估指标。我们在 VP-Bench 的高质量子集上评估 FlowInOne。遵循第 3.2 节,我们使用 Gemini 3、GPT 5.2 和 Qwen3.5 评估通过率,并计算四个量化指标。此外,为了定性验证,十位独立评估者交叉检查了 250 个分层随机样本(每人 25 个),以确保判断可靠性。
5.2 图像到图像生成评估
最先进方法对比。我们将 FlowInOne 与多个有竞争力的开源框架进行比较,包括 OmniGen2、Qwen-Image-Edit-2509 和 FLUX.1-Kontext-dev,以及商业模型 Nano Banana。为确保公平,我们设计了统一的文本提示来补充图像输入以供其评估,如附录 F 所详述。量化结果表明 FlowInOne 在统一生成任务上具有显著优势。
如表 1 所示,我们的模型在 GPT-5.2(39.2%)、Qwen3.5(50.3%)和人工评估(44.9%)下实现了最高通过率,超越所有开源模型。虽然 Nano Banana 在 Gemini-3 评估器上得分更高(56.0% vs. 我们的 54.0%),但我们将此归因于 Nano Banana 与 Gemini 之间共享的谱系,这可能导致对齐偏差。尽管如此,FlowInOne 在中性评估器(GPT、Qwen、人工)上的持续主导地位证实了其在图像输入、图像输出范式上的 SOTA 地位。
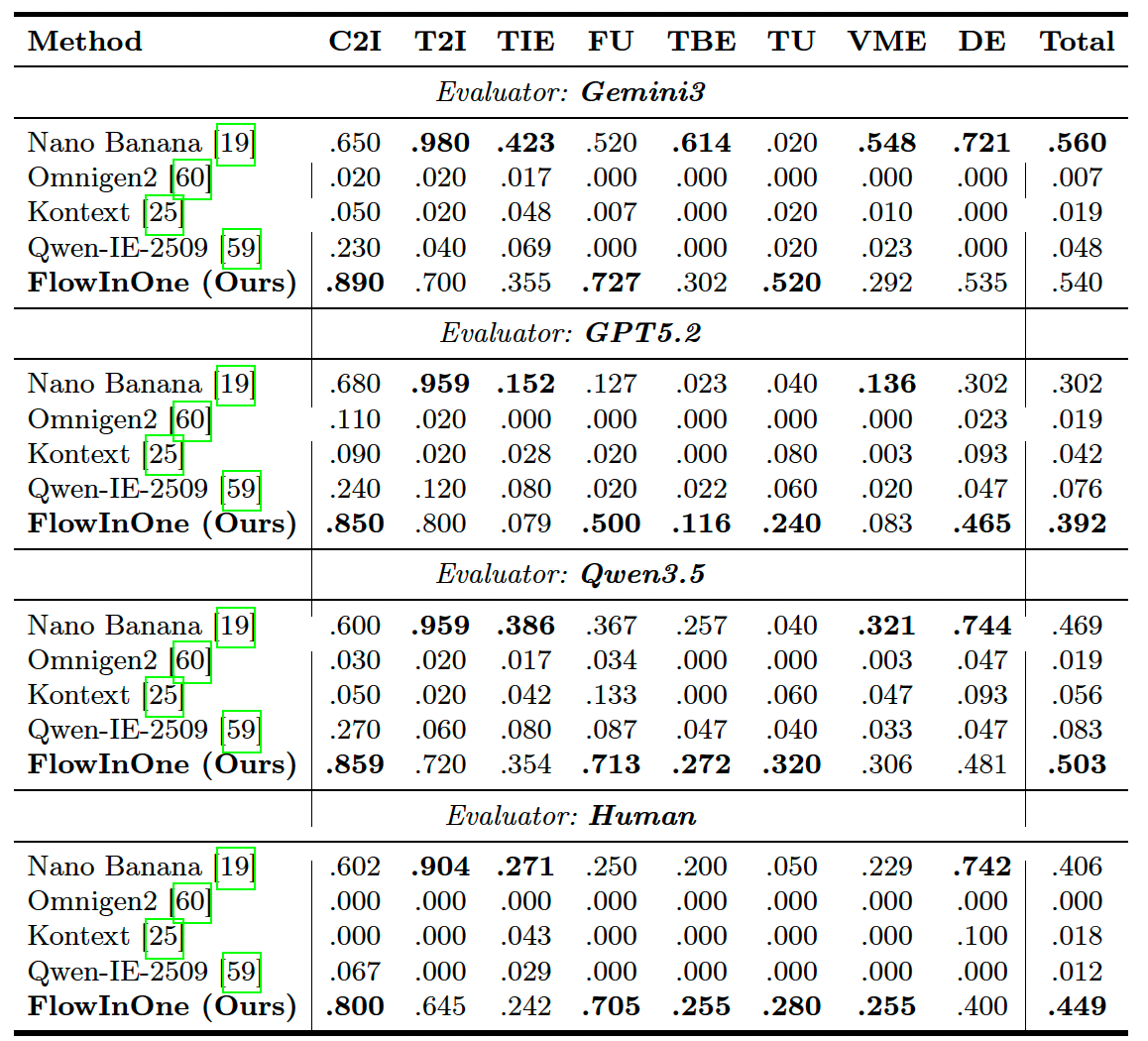
表 1:在 VP-Bench 视觉指令基准测试上的评估结果,采用三个 VLM 评估器和人工评审。我们使用 Gemini3 [18]、GPT5.2 [38] 和 Qwen3.5 [44] 来评估 FlowInOne 在各类视觉指令任务上的成功率。C2I:类别到图像(class to image),T2I:文本到图像(text to image),TIE:图像中文本编辑(text in image edit),FU:强制理解(force understanding),TBE:文本与边界框编辑(text & bbox edit),TU:轨迹理解(trajectory understanding),VME:视觉标记编辑(visual marker edit),DE:涂鸦编辑(doodles edit)。Total 表示所有子类别上的平均成功率。
尽管 MLLMs 和人工评估之间由于在对细粒度视觉标记的定位方面存在局限性而存在轻微差异,但总体排名趋势一致,验证了我们自动化指标的可靠性。
超越通过率,表 2 进一步支持了我们的发现。关键地,FlowInOne 在细粒度空间和物理控制方面表现突出,实现了最高平均 DINOv3 Sim 分数 48.7%(超越 Nano Banana 的 47.3%),在力与轨迹理解及文本边界框编辑方面具有明显优势。此外,在整体视觉真实感和语义对齐方面,FlowInOne 显著超越所有开源基线,并与商业模型性能相当,突显了其鲁棒的生成质量和精确的指令跟随能力。
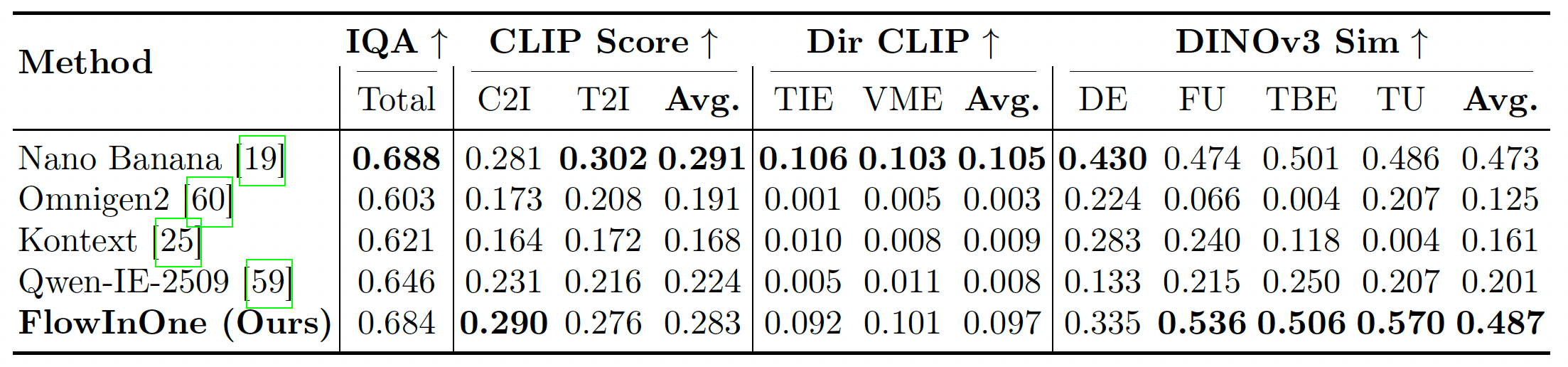
表 2:在 VP-Bench 上对五个模型的定量评估结果。CLIP-IQA 在所有类别上取平均,用于衡量整体视觉真实感。CLIP Score 用于评估纯生成任务中的语义一致性。Directional CLIP Similarity 用于衡量基于标记编辑任务中的指令驱动一致性。DINOv3 Similarity 用于评估细粒度空间结构与物理结构的准确性。
定性对比。为展示 FlowInOne 的优越性,图 4 展示了单图像输入下生成结果的视觉对比。如第 2 至 4 列所示,开源模型在将视觉指令与辅助文本提示的图像内容解耦方面严重受限。它们错误地将视觉标记重建为内在场景元素,导致伪影保留或完全无视编辑意图。商业模型 Nano Banana 在需要精确空间和物理推理的任务中也暴露出明显不足。在力(第 3 行)和轨迹理解中,它无法将视觉标记转化为物理上合理的动态。此外,在边界框插入(第 4 行)中,它忽视了尺寸约束,尽管近似位置正确。相比之下,FlowInOne 严格遵守边界框尺寸,实现了无缝局部融合。

图 4:不同方法之间的视觉指令编辑效果对比。
总体而言,FlowInOne 展现出通过优雅、统一的范式高效执行多样化视觉任务的能力。无论是执行基础编辑与生成,还是处理要求高精度的任务,FlowInOne 都展现出卓越的能力。这种图像输入、图像输出范式不仅统一了交互界面,还提供了一条从根本上有效解决传统文本驱动模型在细粒度生成中局限性的路径。
5.3 消融实验
我们进行了一系列消融实验来验证模型的架构设计。由于计算限制,除非另有说明,所有模型均以批大小 512 训练 10 万步。为准确反映模型性能,报告的通过率取 Gemini 和 GPT 评估的平均值。此外,我们采用渐进式策略,在每个部分的基础上构建最优配置。
不同压缩方法。由于我们的模型利用预训练权重,将视觉编码器的序列长度和特征维度对齐到预训练潜在空间至关重要。我们探索了三种不同的压缩和映射策略:(1) MLP + 截断:特征维度通过 MLP 映射,而序列长度直接截断;(2) VAE 扩展:VAE 中的 Transformer 层数量直接增加,以自然匹配潜在空间内的维度;(3) MLP + MLP:序列长度和特征维度均通过 MLP 投影。如表 3(a) 所示,MLP + MLP 策略表现最佳(18.12%)。我们假设简单截断丢弃了关键边缘信息,而仅扩展 VAE 层会增加优化难度。相反,双 MLP 投影有效保留了输入视觉提示的语义和空间结构,同时维持了预训练先验。
Token 门控交叉注意力。接下来,我们研究调制机制以统一生成和编辑,它们表现出明显不同的结构依赖。我们比较:(1) 无 CA:仅自注意力;(2) W 双路径 CA:不带自适应门控的双路径交叉注意力;(3) 双路径 SAM:我们提出的双路径空间自适应调制。表 3(b) 显示,缺少交叉注意力(无 CA)由于对源图像结构先验的利用不足,产生了最差结果(18.12%)。添加交叉注意力将性能提升至 21.40%,而双路径 SAM 达到 23.1%。这证明自适应门控机制在统一框架内动态平衡内容一致性与指令遵循,优化了性能。
联合训练与两阶段训练。基于所描述的最优架构,我们评估数据训练策略。我们比较:(1) 两阶段训练:在 3M 样本(T2I、C2I、粗粒度编辑)上训练 10 万步,然后在剩余 2M 样本上训练 14 万步;(2) 联合训练:混合全部 5M 样本训练 24 万步。如表 3© 所示,联合训练以 47.8% 的通过率占据主导,远超两阶段方法(29.1%)。两阶段训练可能受到跨不同任务的灾难性遗忘影响。相反,联合训练迫使模型在共享视觉流空间内同时学习语义生成、几何变换和物理规律,产生更强的泛化能力和指令遵循能力。
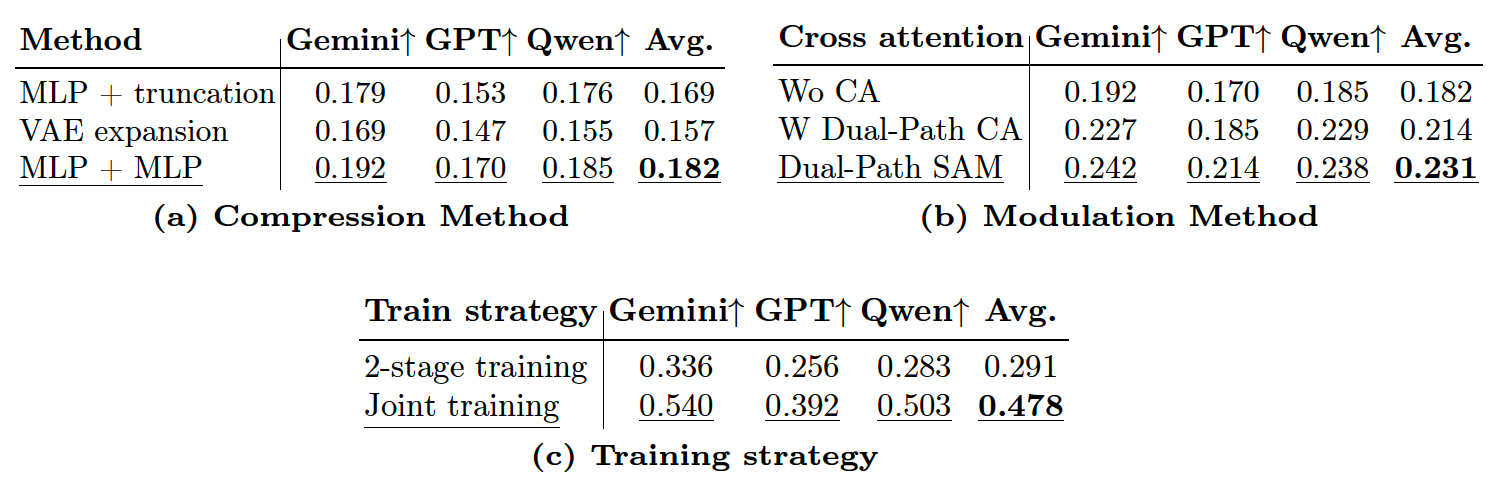
表 3:关于压缩方法、调制方法与训练策略的消融实验。采用 Gemini3 [18]、GPT5.2 [38] 和 Qwen3.5 [44] 的平均得分作为评估指标。
6 结论
我们提出了 FlowInOne,一个将多模态生成重新定义为纯视觉流的统一框架。通过将所有模态嵌入共享视觉空间,并学习视觉指令状态与图像状态之间的连续传输,FlowInOne 在多样化任务中实现了高效一致的生成。为支持这一范式,我们引入了大规模 VisPrompt-5M 数据集,在单一视觉接口下实现跨任务泛化。FlowInOne 在所有评估任务上达到最先进性能,在自动化和人工评估中均超越了现有开源模型和有竞争力的商业系统。大量实验表明,FlowInOne 为未来在单一确定性原则下统一感知与生成的视觉中心多模态模型奠定了基础。我们相信,这项工作标志着朝着弥合连续视觉域中视觉理解与创作之间差距的重要一步。
FlowInOne:将多模态生成统一为图像输入、图像输出的流匹配 (补充材料)
附录概览
本补充材料包含以下章节:
- 附录 A:更多实验结果
- 附录 B:更多基准细节
- 附录 C:更多定性示例
- 附录 D:更多数据集细节
- 附录 E:局限性与未来工作
- 附录 F:更多评估细节
- 附录 G:模型细节
A 更多实验结果
A.1 人工评估误差分析
为了补充基于 VLM 的自动化评估并深入了解模型的失败模式,我们进行了严格的人工评估。十位独立专家评估员对基准中 250 个生成样本的分层随机子集(每个子集 25 个样本)进行了独立评估,并随后进行了交叉核查。请注意,我们的人工评估与 VLM 评估在方法论上的区别:VLM 对每个样本在所有四个维度上都给出连续分数(1-5),而人工评估员则采用严格的视觉检查方法。具体来说,评估员首先对生成图像是否合格做出二元判断。如果样本被判定为"失败",评估员则记录具体是哪些维度导致了失败,每个样本允许多标签标注。请注意,为简洁起见,图中的标签"Fidelity"、“Spatial”、"Realism"和"Consistency"分别严格对应指令忠实度、空间精度、视觉真实感和内容一致性。
如图 1 所示,整个 VP-Bench 的全局误差分布显示,指令忠实度是最突出的瓶颈,占所有标注错误的 56.2%。这表明,充分捕捉复杂视觉指令的细微语义仍是主要挑战。空间精度是第二大误差来源,占 20.5%,其次是视觉真实感(13.5%)和内容一致性(9.7%)。
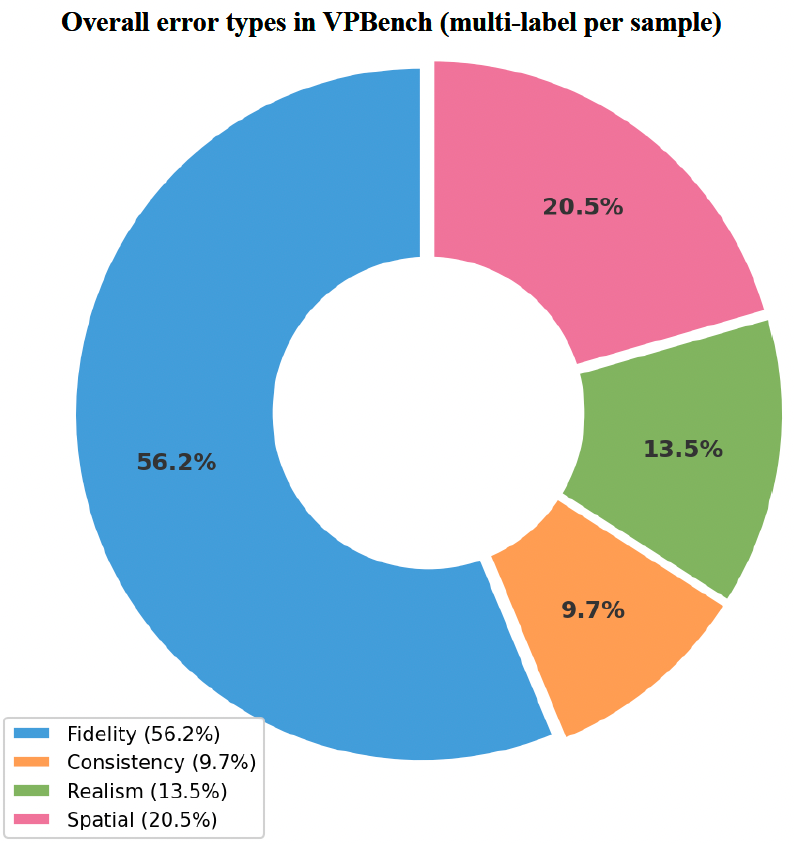
图 1:VP-Bench 中的总体错误类型分布。为简洁起见,图中的标签 Fidelity、Spatial、Realism 和 Consistency 分别严格对应于 Instruction Fidelity(指令忠实度)、Spatial Precision(空间精度)、Visual Realism(视觉真实感)以及 Content Consistency(内容一致性)。
各子集类别的误差类型细分如图 2 所示。误差分布因具体任务的性质而存在显著差异。例如,在需要严格遵循明确文本概念和精确内容生成的语义驱动任务中——如类别到图像和文本边界框控制——指令忠实度误差占绝对主导,分别高达 85.7% 和 80.0%。相反,在需要严格空间定位和几何推理的任务中——如涂鸦、力、轨迹和视觉标记——空间精度误差比例显著上升,在涂鸦引导任务中高达 45.5%。此外,在文本到图像等从头生成任务中,视觉真实感作为一个更明显的问题出现(33.3%)。
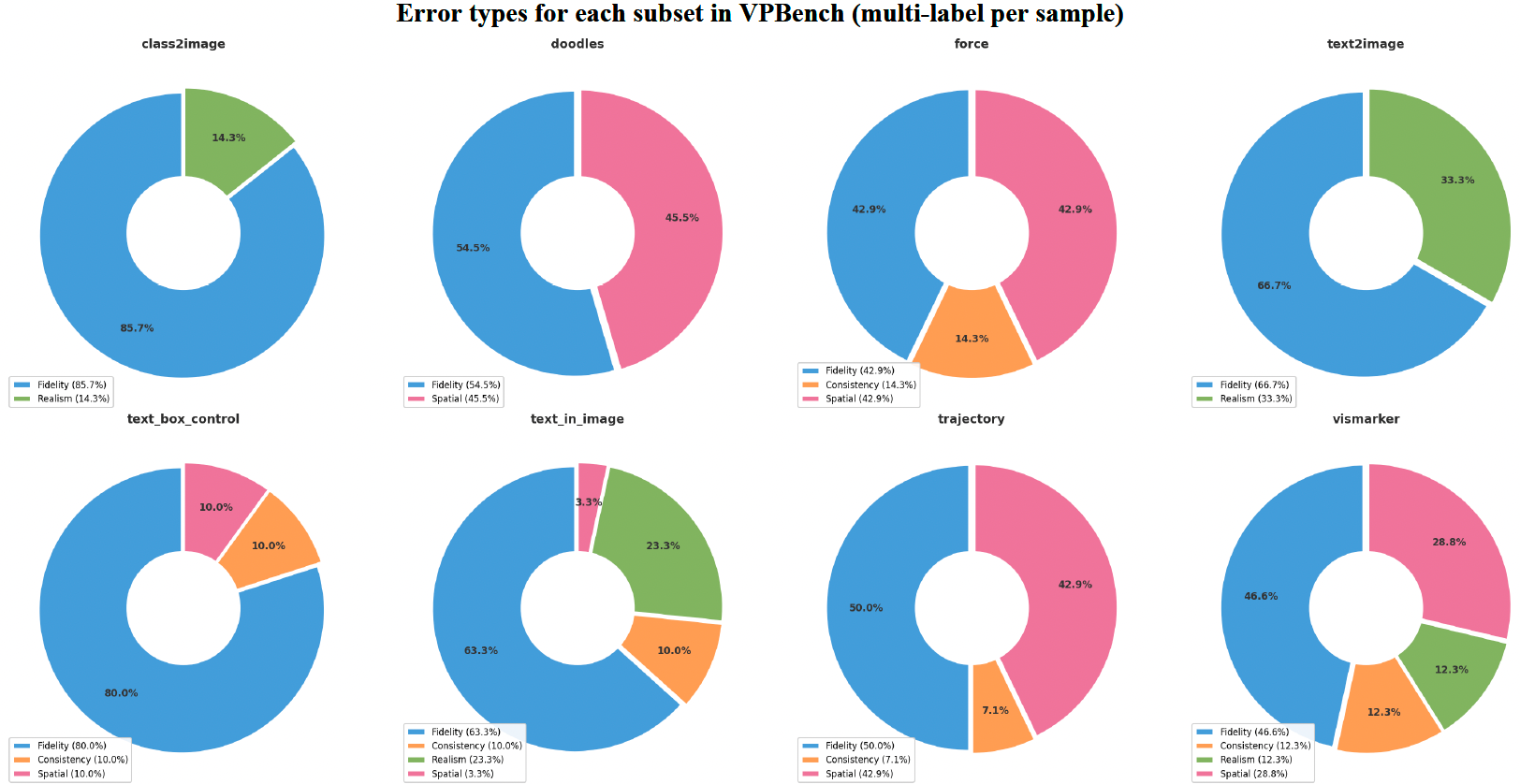
图 2:VP-Bench 各子集中的错误类型分布。
A.2 鲁棒性测试
为了评估模型在真实场景下的稳定性和可靠性,我们在各种具有挑战性的条件下进行了全面的鲁棒性测试。
首先,我们评估模型对视觉指令文本组件扰动的适应能力。如图 3 所示,我们对原始输入施加四种不同类型的干扰:文字样式变化(包括大小、颜色、字体和空间布局)、文字长度变化、严重的文字模糊以及随机文字损坏(用无意义或错误的文字替换有效指令)。生成结果表明,我们的模型在样式变化、长度变化和强烈模糊的情况下均保持高度稳定和准确的性能。这表明模型有效地提取了底层语义意图,而非单纯记忆表面格式。然而,正如预期的那样,模型在受到随机文字错误时性能显著下降。这一失败案例实际上作为积极的确认,表明我们的模型严格遵循图像中提供的显式语义指导,而非仅凭视觉上下文进行幻觉编辑。

图 3:针对视觉指令扰动的鲁棒性分析定性结果。我们在五种不同条件下评估模型生成结果的稳定性:原始未修改输入、文本样式变化(例如大小、颜色、字体和布局)、文本长度变化、文本模糊,以及随机文本损坏。
此外,我们评估了模型在不同分辨率下的鲁棒性。我们使用缩放至 128 × 128 128 \times 128 128×128、 256 × 256 256 \times 256 256×256、 384 × 384 384 \times 384 384×384 和 512 × 512 512 \times 512 512×512 像素的输入图像测试生成质量。如图 4 所示,模型在 256 × 256 256 \times 256 256×256 及以上分辨率下大体上能够产生高质量的生成结果,尽管偶有失败。仅在极低分辨率 128 × 128 128 \times 128 128×128 下才出现明显的视觉保真度和指令跟随能力下降。这主要是因为极端下采样严重压缩了视觉标记和文字,使其难以进行准确的特征提取。

图 4:不同输入图像分辨率下的生成结果。
A.3 视觉指令消融
为了深入研究统一视觉指令中文本和视觉组件各自的贡献,我们在四个具有代表性的样本上进行了消融研究。具体地,我们评估了四种不同输入配置下的生成性能:(1) 空白:文本和视觉提示均被移除,仅保留原始源图像;(2) 文本:视觉提示被移除;(3) 视觉提示:文字指令被移除;(4) 文本 + 视觉提示:代表完整的视觉指令。如图 5 所示,结果清楚地表明了在统一图像画布中结合这两个指令元素的必要性。当输入为"空白"图像时,模型可预期地不做任何修改。在"仅文本"设置下,模型倾向于擦除叠加的文字,但未能执行核心编辑意图,因为它缺乏精确的空间和操作定位。相反,"仅视觉提示"设置导致混乱和无序的生成结果。这有力地证明了图像内文字不可或缺——它作为轻量级的语义触发器,赋予视觉提示明确的功能含义。最后,只有完整的"文本 + 视觉提示"配置成功且一致地生成了正确的高质量目标图像,确认了渲染文字语义与图形空间线索的协同作用对于准确的视觉指令跟随至关重要。

图 5:视觉指令消融实验的定性结果。我们比较了四种输入配置下的生成效果:Blank(仅原始图像)、Text only(仅文本)、Visual prompt only(仅视觉提示),以及完整的 Text & visual prompt(文本与视觉提示)。
B 更多基准细节
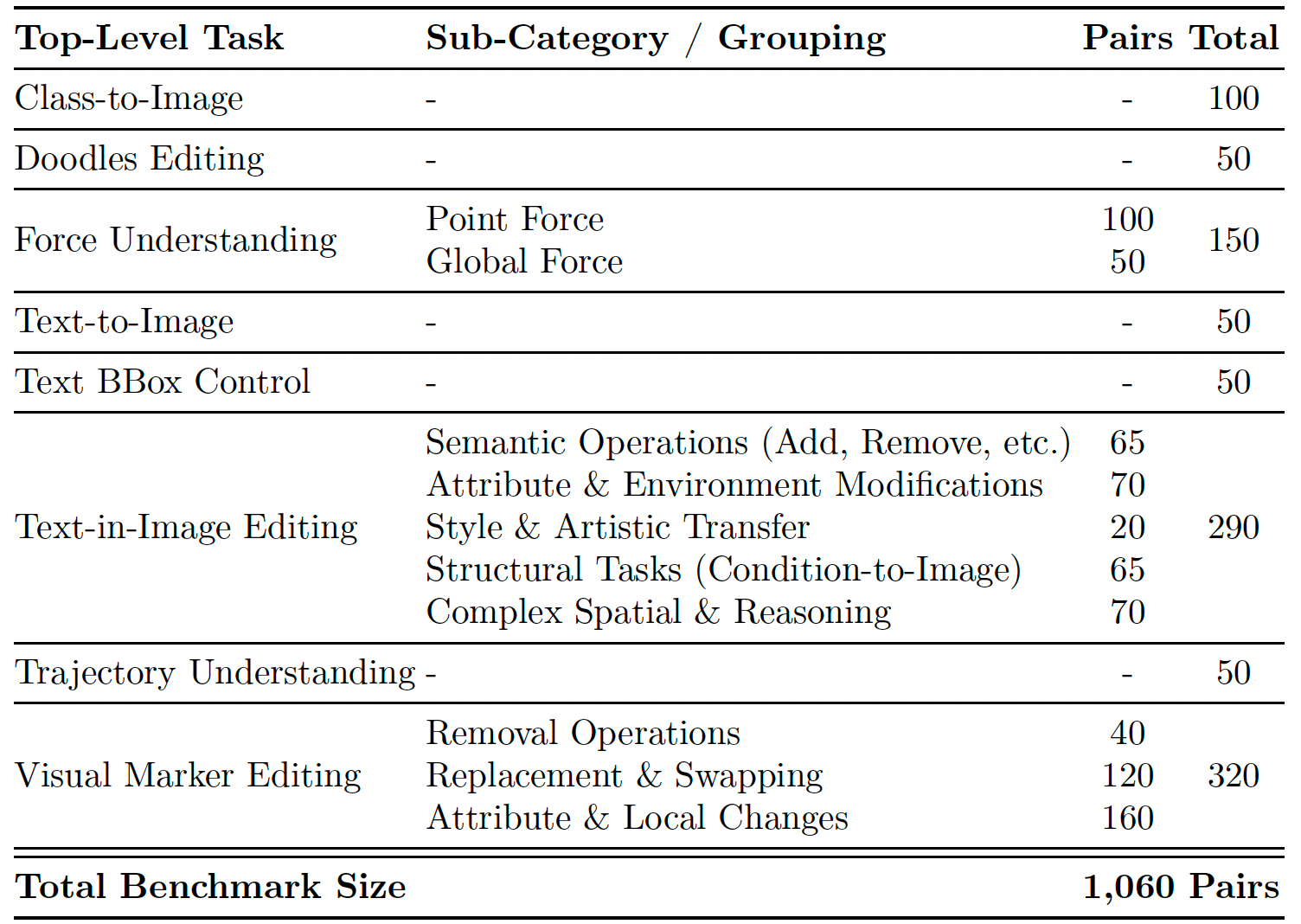
表 1:人工整理的 VP-Bench 详细统计信息。为提供结构化概览,我们将高度细粒度的编辑子类别在概念上归纳为更高层级的语义宏类别。
B.1 防泄漏措施
由于 VP-Bench 通过从八个任务类别中随机采样得到,我们实施了严格的双重防泄漏协议,以确保真正的零样本评估并防御数据污染:
- 根图像级别划分:数据集不在最终指令对级别进行划分,而是严格基于底层根图像(未编辑的基础画布)进行划分。这确保模型在优化过程中从未见过基准中语义背景、目标对象或空间布局。
- 通过视觉去重进行变体和增强排除:为了从技术上强制执行这种互斥性,我们采用了严格的视觉特征去重流程。具体地,我们通过 CLIP 提取 VP-Bench 所有根图像的深度视觉嵌入,然后与整个 5M 训练池计算余弦相似度。任何视觉相似度分数超过保守阈值的训练对都被积极丢弃。这种特征级过滤从数学上保证了没有任何不同指令对、裁剪变体或源自基准基础画布的中间编辑会保留在训练阶段。
B.2 数据分析
VP-Bench 概览。如表 1 和图 6 所示,VP-Bench 共包含 1060 个精心策划的图像对,跨越八个不同的任务类别。数据集由两类核心视觉指令任务主导:视觉标记编辑(320 对,30.19%)和图像内文本编辑(290 对,27.36%)。这两类合计占基准的 57% 以上,在语义操作、结构任务和复杂空间推理方面提供了高度细粒度的评估。除通用编辑外,VP-Bench 还专门设计了针对特定高级能力的评估。为了严格测试物理感知推理,我们特别纳入了力的理解(150 对,14.15%)和轨迹理解(50 对,4.72%)。此外,基准通过文本边界框控制(50 对,4.72%)和涂鸦编辑(50 对,4.72%)评估显式空间布局和基于草图的控制。最后,为确保全面的评估范围,我们纳入了类别到图像(100 对,9.43%)和基础文本到图像(50 对,4.72%),作为纯基础生成任务。这种精确的比例构成确保基准优先考虑复杂视觉定位和物理推理,而非传统的文本驱动生成。我们有意设计这种比例分布,使由显式视觉提示驱动的子集在基准中占据主导地位,从而突出我们的核心目标:严格评估模型在真正视觉中心指令跟随方面的能力,防止模型通过传统文本驱动先验绕过视觉定位。
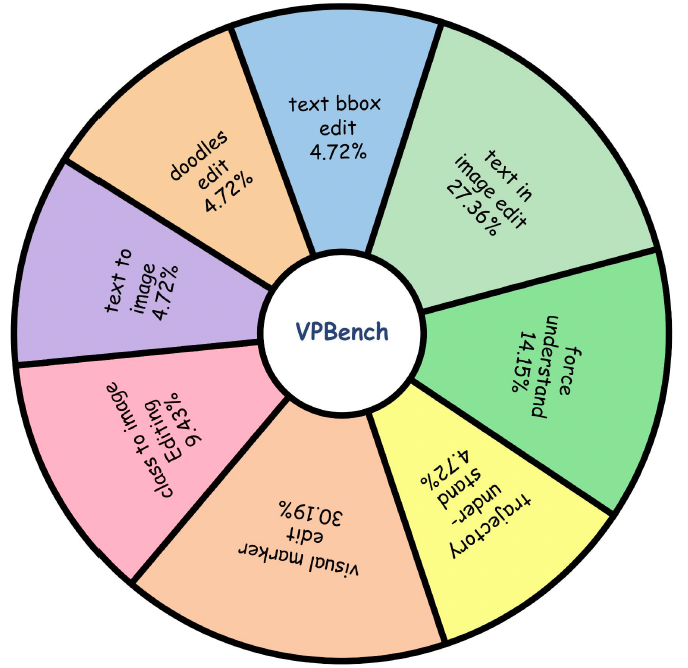
图 6:VP-Bench 中八个不同子集的数据分布。VP-Bench 是一个综合性基准测试集,由八种不同的数据类型构成。
附加统计。VP-Bench 的核心动机是将认知负荷从密集、文本描述转移到直观、明确的视觉指令。为了定量证明我们的基准评估的是真正的视觉推理而非文本理解,我们分析了所有图像中提取的文本提示的语言长度和语义分布。首先,如表 2 所详述,整体文本需求极为简洁。由直接语义类别(如类别到图像)或显式空间边界框(如文本边界框控制)驱动的任务使用高度简洁的文字标签,平均仅 3.0 和 3.5 个单词。即使对于复杂的物理感知推理(轨迹理解和力的理解)和复杂的操作(视觉标记编辑),文本也保持极为简短(平均 14 到 18 个单词)。由于简短的文字本身不足以描述复杂的空间配置,模型被迫从渲染的边界框、涂鸦和叠加箭头的空间几何中提取精确的操作意图。相反,传统的文本到图像基准依赖显著更长的描述性提示(平均 23.7 个单词)。
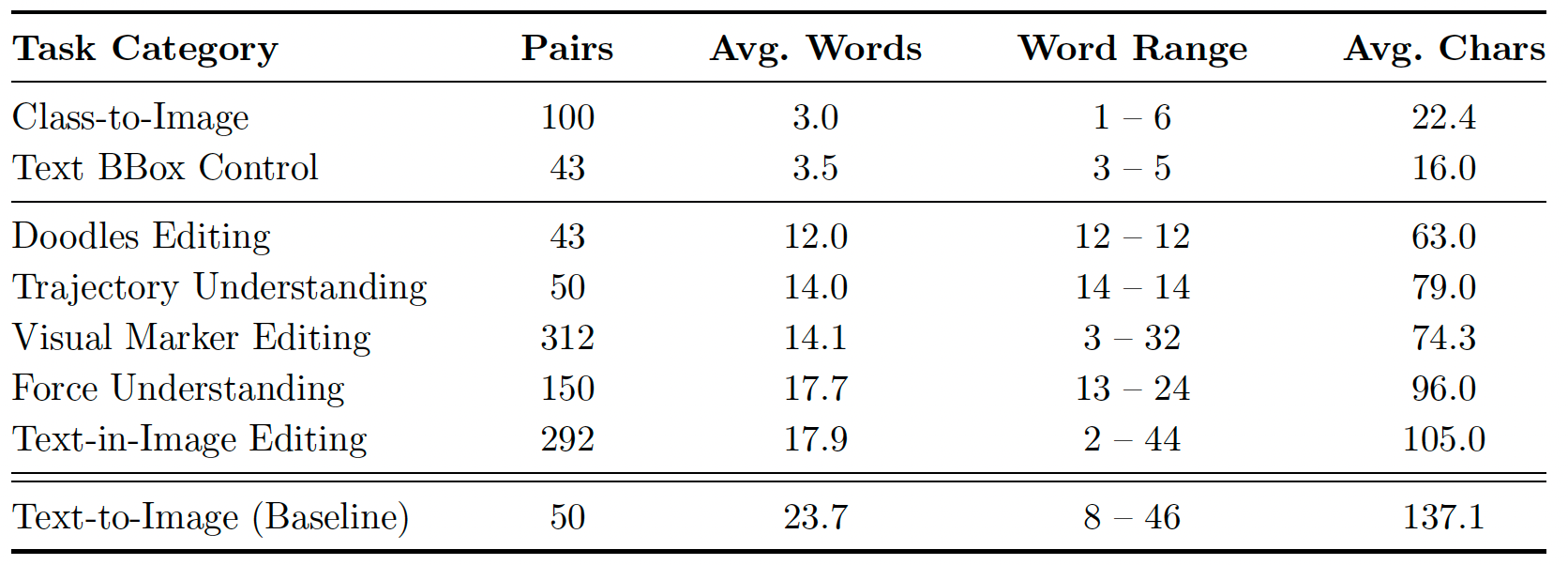
表 2:VP-Bench 中不同任务类别的文本提示词统计。其显著偏低的平均词数表明,该基准测试主要依赖明确的视觉标记,而非冗长的文本描述。
此外,指令的语义构成也印证了这种视觉依赖性。如图 7 所示,前 20 个全局关键词与传统生成提示截然不同。词汇中不是密集的描述性形容词,而是抽象引用(如"object"、“image”)、明确的视觉指针(如"arrow"、“pointed”)和操作动词(如"change"、“turn”、“swap”)占据主导。这种鲜明的统计和语言对比有力地验证了 VP-Bench 最小化文本依赖,将文字仅用作轻量级操作触发器,同时严格测试"图像输入、图像输出"视觉指令跟随。
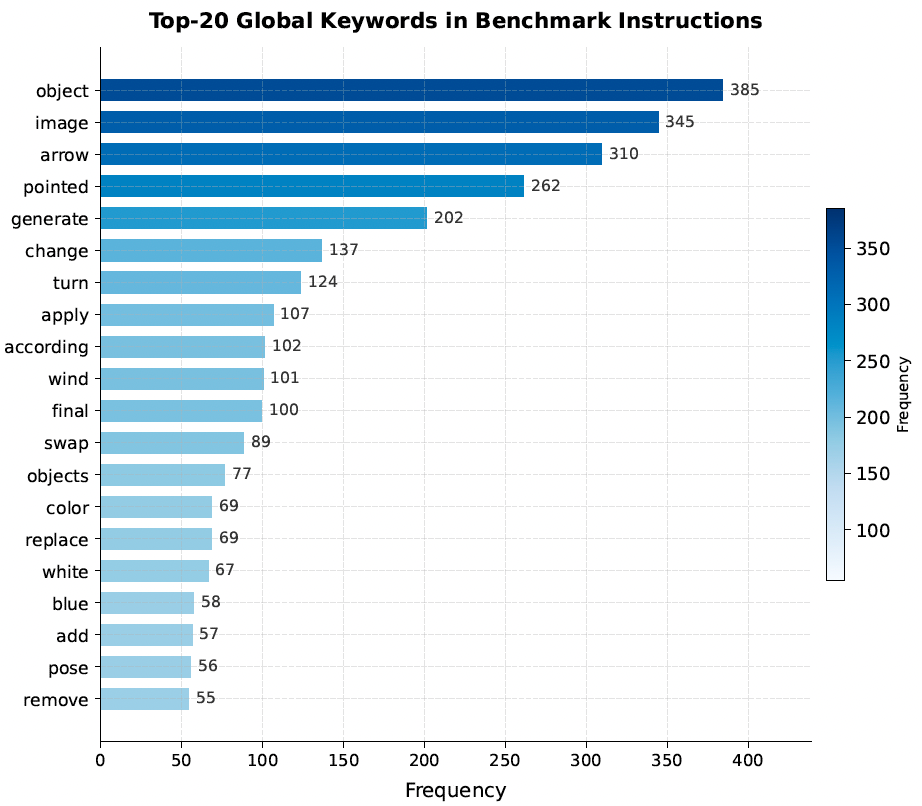
图 7:VP-Bench 指令中的全局前 20 高频关键词。该分布显示操作性动词(例如 “change”“turn”)和视觉指示词(例如 “arrow”)占主导地位,突显了我们以视觉为中心的评测范式对文本依赖极低的特点。
C 额外定性示例
在本节中,我们提供额外的定性示例,以进一步展示模型在各类视觉指令类别上的多样化生成能力。具体地,我们将这些补充结果归为三个主要方面:(1) 图 8 展示了文本到图像生成和图像内文本编辑任务的扩展结果;(2) 图 9 提供了专注于文本边界框(bbox)编辑、涂鸦引导编辑和视觉标记编辑的更多视觉示例;(3) 图 10 展示了强调模型物理力理解和轨迹理解能力的额外生成结果。

图 8:文本到图像生成任务与图像中文本编辑任务的更多定性结果。

图 9:文本边界框(bbox)编辑、涂鸦引导编辑以及基于视觉标记编辑任务的更多定性结果。
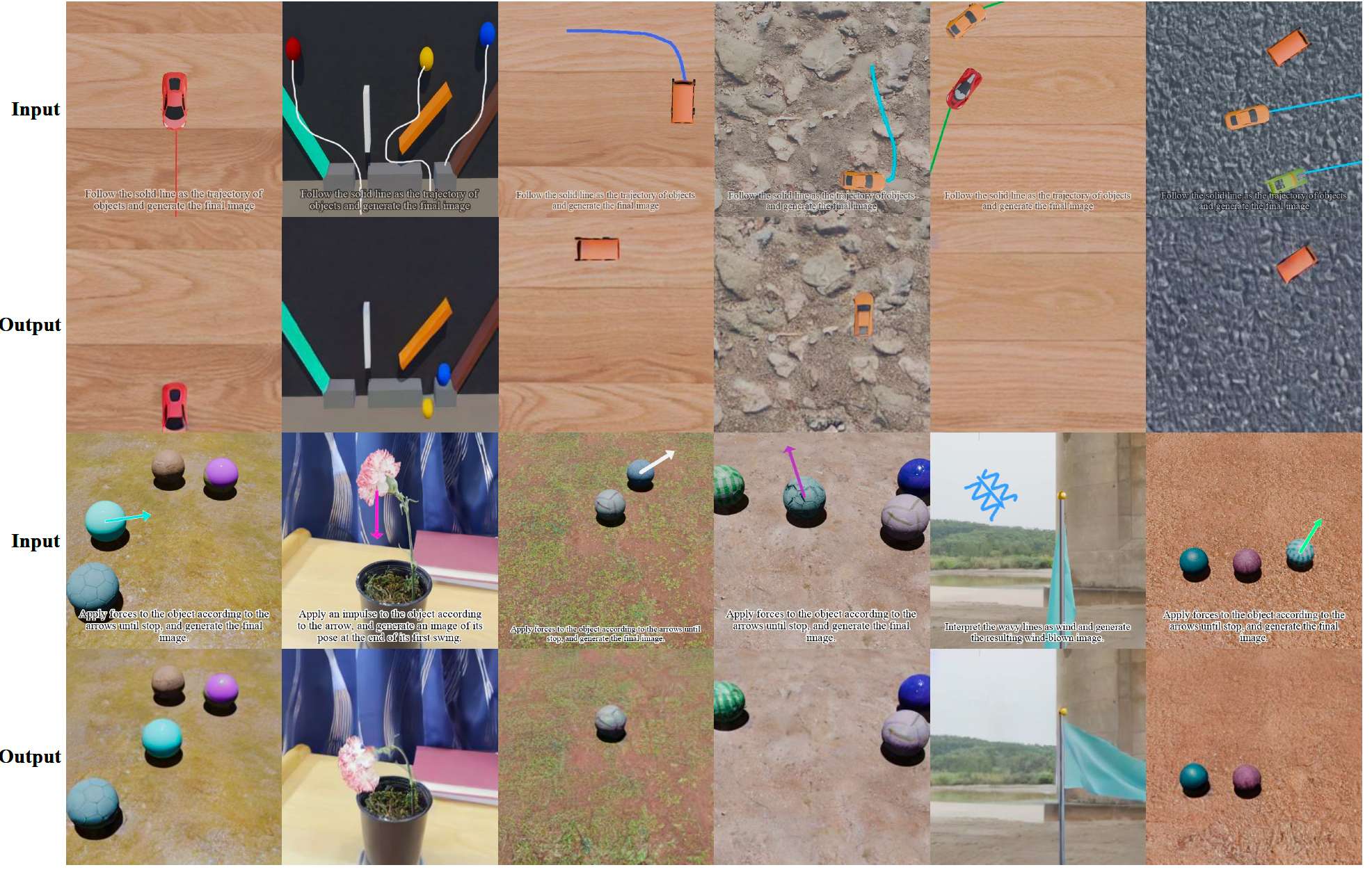
图 10:展示物理作用力理解与轨迹理解的更多定性结果。
D 更多数据集细节
D.1 VisPrompt-5M 概览
为了支持 FlowInOne 在纯视觉中心范式下的训练,我们构建了 VisPrompt-5M——一个精心策划的大规模数据集,包含约 500 万个视觉指令对。与依赖分离文本说明的传统多模态数据集不同,VisPrompt-5M 通过将任务特定的指令元素——如文字、空间布局或物理约束——直接渲染到输入图像画布上,统一了多样化的控制信号。
如表 3 所示,我们严格的构建和过滤流程——从原始数据提取到多阶段 MLLM 合成和人工标注——确保模型学习到准确的空间-视觉逻辑,而非利用嘈杂的数据集相关性。
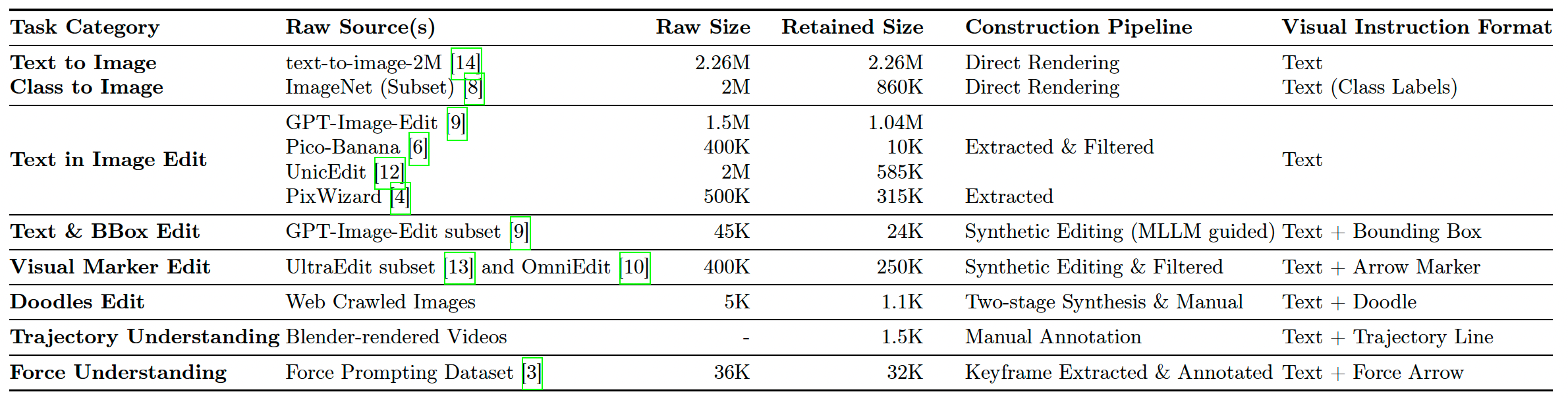
表 3:VisPrompt-5M 数据集的综合概览。我们详细说明了任务类别、原始数据来源、过滤流程前后的数据规模、构建方法,以及显式嵌入的视觉指令格式。
D.2 数据构建
基础生成。为了与我们统一的图像输入、图像输出范式保持一致,我们必须将传统的文本图像对转换为统一的图像-图像对。对于文本到图像任务,我们将对应的文字提示直接渲染到空白输入画布上。为确保模型获得鲁棒的视觉文本理解能力而非过拟合特定的排版布局,我们在渲染过程中引入了大量数据增强。具体来说,字体样式、字体大小、字体颜色、文字位置和画布背景颜色均随机采样。我们还强制执行严格的边界检查,确保所有生成的文字完全在画布边界内。通过这条自动化流程,来自 text-to-image-2M 的 200 万个文本图像对被无缝转换为图像-图像对。
类似地,对于类别到图像生成任务,我们使用 ImageNet 的高质量子集。离散类标签(如"golden retriever")使用上述相同的随机化渲染策略被提取并渲染到输入画布上。由于 ImageNet 本身每个类别包含多个不同的目标图像,单个渲染标签画布可以与同一类别的多张目标图像配对。这种一对多的配对策略自然地鼓励模型捕捉并生成类内多样性。
图像内文本编辑。该类别是模型指令跟随能力的基石,将语义操作和结构条件到图像任务系统地统一到单一学习目标中。为覆盖全面的操作意图范围,我们从四个主要来源汇聚数据:GPT-Image-Edit、Pico-Banana、UnicEdit 和 PixWizard。我们不列举所有细粒度子任务,而是在概念上将多样化的编辑能力归入几个核心维度:
- 语义操作:包括主体添加、删除、替换和目标交换。
- 属性与环境修改:涵盖局部属性变化(颜色、材质、年龄/性别、面部表情)和全局大气调整(光照、天气条件、背景替换)。
- 艺术与风格迁移:从基础风格化到高度特定的领域翻译(如 2D 动漫、Pixar 风格 3D、素描、线稿和西方漫画风格)。
- 复杂空间推理:涵盖多目标协调、计数变化、外绘和姿态调整。
虽然传统范式将结构条件到图像生成(如深度到图像和分割到图像)或修复任务(图像修复、人脸/自然修复)视为不同的架构分支,但我们认为它们自然地归属于"图像编辑"的范畴。具体来说,结构条件图(如 Canny 边缘图)本质上就是一张源图像。通过将这些结构条件视为起始画布,我们将来自 PixWizard 的 31.5K 高质量对无缝整合进统一训练流程。
为完全符合纯视觉中心的 FlowInOne 架构,所有操作意图必须以视觉文字提示的形式显式嵌入。我们将传统的异构三元组(文字指令、源图像、目标图像)转换为严格的视觉(输入图像、目标图像)对。这通过将文字指令直接渲染到正在编辑的源图像(或条件图)上来实现。与我们基础生成策略一致,我们在这个渲染过程中应用大量随机化增强——随机采样字体样式、文字大小、字体颜色和画布上的空间位置。这保证模型在各种场景下鲁棒地感知和解析文字指令,而不是依赖固定的排版捷径。
为维持流匹配的高质量优化环境,我们对组合的 250 万原始语义编辑对实施严格的过滤机制,丢弃复杂或不一致的对。具体来说,我们过滤出具有以下特征的示例:(1) 高度歧义或过于复杂的文字指令,缺乏明确的视觉目标;(2) 存在严重生成伪影或极端宽高比的源图像;(3) 视觉-语义对齐差,目标图像无法忠实反映文字指定的具体操作意图。过滤后,我们保留约 160 万个高质量的精选语义编辑对,与 PixWizard 合并后共计 190 万个统一对。
文本边界框编辑。为使模型具备精确的空间控制能力,其中文字和边界框共同决定生成,我们构建了一个高质量子集,文字和边界框联合控制生成。我们不使用现有的不完美对,而是从 GPT-Image-Edit 中采样 45K 高分辨率、无伪影且美观的图像。这些图像仅作为初始未编辑源图像。
两阶段视觉引导合成。有效图像对的生成遵循一个利用 Qwen Image Edit 和 Qwen3-VL 联合先验的定制流程。首先,我们随机定义一组要添加的目标对象。然后提示 Qwen Image Edit 将指定对象无缝插入源画布,生成最终目标图像。随后,我们使用 Qwen3-VL 作为视觉定位代理,在目标图像中精确定位新插入的对象。基于这些空间坐标,我们在原始源图像上直接绘制突出的边界框,并在框旁渲染目标的文字标签。在这种纯视觉提示配置中,文字标签明确表示语义类别,而边界框则施加严格的几何约束,定义比例和位置。
基于 Logit 的自动过滤。为确保最高的数据质量并消除繁琐的人工检查,我们设计了一个由 Qwen3-VL 7B 驱动的自动审核机制。审核员从三个关键维度评估生成的对:指令忠实度、局部视觉一致性和全局背景保留。关键地,审核员不依赖简单的二元输出,而是基于输出 logit 计算连续置信度分数:
Score = P ( Yes ) − P ( No ) P ( No ) (1) \text{Score} = \frac{P(\text{Yes}) - P(\text{No})}{P(\text{No})} \tag{1} Score=P(No)P(Yes)−P(No)(1)
这个公式使我们能够建立严格的可定制的数据保留阈值。当编辑被判定为不成功(即分数低于阈值)时,审核员激活一个细化协议。它识别具体的合成问题(如颜色不匹配或纹理损坏),并输出以 ROP(细化输出提示)开头的提示,为生成流程提供反馈。通过应用这种严格的审核标准,我们过滤掉次优的生成结果,最终保留 24K 个在空间-视觉对齐方面完美的高保真对。
视觉标记编辑。视觉标记(如箭头)为用户提供了高度直观和高效的界面,能够在不需要明确对象名称的情况下进行精确的空间引用,这在目标对象模糊或难以描述时尤为有利。为构建这个子集,我们从 UltraEdit 和 OmniEdit 中精选高质量图像对,专门针对细粒度操作子类别,包括删除、替换、属性修改和颜色/局部变化。
为自动化视觉标记标注,我们首先解析原始文字指令以提取特定的目标对象。然后使用 Qwen3-VL 在输入图像中精确定位该对象。基于空间坐标,一个脚本在源画布上动态渲染箭头。为防止模型过拟合特定的标记样式,箭头的颜色、大小和起始位置完全随机化,但严格约束其尖端必须直接指向目标对象。最后,指令中的明确对象名称被系统地替换为通用的视觉引用(如"箭头指向的对象")。为保证数据质量,我们将这些合成对提交给与文本边界框引导编辑部分详述的完全相同的自动基于 logit 的审核机制。这一严格的过滤流程最终产生 25 万个高度可靠的对,迫使模型通过视觉线索单独显式地理解语义和空间关系。
涂鸦编辑。涂鸦为用户提供了直观的界面,可以明确指定形状先验和空间布局。为构建这个子集,我们收集 5K 张高质量网络图像作为未编辑的基础画布,并预定义十个多样化的目标对象类别。然后我们使用包含 Qwen Image Edit 的两阶段合成流程。在第一阶段,模型被提示在预定义类别中插入 1 或 2 个简单的手绘风格涂鸦到基础画布中,形成输入图像。在第二阶段,Qwen Image Edit 将这些抽象涂鸦转换为逼真的目标对象,生成对应的目标图像。
由于多阶段图像到图像转换固有的生成不稳定性,相当一部分初始输出存在结构性误差。因此,我们进行严格的人工检查。保留标准严格规定:(1) 绝对不存在生成伪影;(2) 涂鸦必须保持结构简单和抽象,而不是过早地类似真实对象;(3) 合成的逼真对象必须与涂鸦定义的形状先验完美对齐;(4) 未编辑的区域必须保持完美的像素级一致性。这种细致的人工策划过滤掉了大多数失败案例,最终产生 1100 个高保真对。
力的理解。为使 FlowInOne 具备物理感知推理能力,我们利用 Force Prompting 数据集,它包含两种不同的物理范式:点力和全局力。具体来说,点力子集捕捉球形物体的线性运动学和植物的谐波振荡,而全局力子集模拟空气动力学效应,如风对旗帜的作用。为将这些连续视频动态转换为静态图像到图像推理对,我们实施了系统的物理驱动关键帧提取策略。我们将每个视频的第一帧指定为初始状态画布。对于目标结果,我们不是任意采样,而是采用特定的分析策略(如光流分析)来确定运动收敛的时间点——一个动态系统可靠地达到终态、稳态平衡或最大物理位移的统计确定帧。
最后,我们明确可视化底层物理参数。原始数据集提供精确标注:施力的确切空间坐标、力的角度和归一化幅值标量 m ∈ [ 0 , 1 ] m \in [0, 1] m∈[0,1]。利用自动化脚本,我们将显式力箭头直接渲染到初始帧上。对于点力,箭头精确起始于施力坐标。对于全局力,它被渲染为全局环境指示符。箭头的几何长度严格与幅值 m m m 成正比,其方向与物理角度对齐。这个完全标注的初始帧构成我们的输入图像,明确挑战模型预测由可视化力动力学严格支配的对应稳态目标图像。
轨迹理解。为了进一步显式建模物理感知运动先验,我们构建了一个精心策划的轨迹理解子集。我们首先使用 Blender 3D 引擎手动渲染一系列高保真动态视频,包含汽车和球的运动,涵盖线性和复杂弯曲运动学。
为制定静态图像到图像对,我们提取每个视频的初始帧和终止帧。我们的人工标注协议要求人工标注员在初始帧上直接绘制连续实线,精确追踪运动物体未来的精确几何路径。这个精心标注的帧作为输入图像,而原始终止帧(显示物体在最终目的地的状态)作为对应的目标图像。关键地,为确保模型严格学习空间几何路径而不是过拟合特定的视觉伪影,绘制的轨迹线的粗细和颜色在标注过程中完全随机化。这种严格的人工流程最终产生 1500 个用于运动轨迹生成的高精度对。
D.3 视觉文字渲染流程
为了合成高保真和多样化的视觉指令数据,我们提出了一个鲁棒的自动化文字渲染引擎。该流程被设计为动态适应各种文字长度和底层背景约束,同时严格保持可读性和几何对齐。渲染过程包含五个关键阶段:
-
鲁棒字体选择和字形验证。为确保文字渲染的生成鲁棒性,我们实施了动态字体选择机制。给定输入文字序列,引擎首先通过解析 TrueType 字体的 cmap 表来验证字符支持。为防止渲染损坏或"缺失字形"框(通常由不完整的字体文件引起),我们引入了经验性字形面积验证阈值。设 A c A_c Ac 为渲染字符 c c c 的边界框面积, s s s 为字体大小。当且仅当平均活跃像素比率 1 N ∑ c ∈ T A c s 2 \frac{1}{N}\sum_{c \in T} \frac{A_c}{s^2} N1∑c∈Ts2Ac 超过预定义最小阈值时,字体才被认为鲁棒且被选中,从而保证数百万合成对的高质量排版表示。
-
语义感知分词。处理多语言指令需要精确的断行策略。我们使用专为视觉布局定制的分词算法。字符被单独分离为 token 以允许灵活的换行,而拉丁字母数字序列和符号则被分组为连贯的整词 token。这种策略防止西文单词在行尾被不当截断,严格保留视觉提示的语义可读性。
-
自适应边界框布局算法。为了在受限视觉画布内自动确定最优排版布局,我们将布局生成建模为约束优化问题。给定尺寸为 W × H W \times H W×H 的目标边界框,我们的目标是找到能适应分词序列 T T T 而不溢出的最大字体大小 s max s_{\max} smax。我们通过在字体大小空间 [ s min , s max ] [s_{\min}, s_{\max}] [smin,smax] 上进行二分查找,以 O ( log N ) O(\log N) O(logN) 时间高效解决此问题。对于 token 数量较多的实例,引擎默认使用最大可用画布边距。对于较短的指令,我们通过随机化局部边界框的位置和尺寸来引入空间多样性,从而迫使生成模型在任意空间分布中理解文字指令。
-
上下文感知风格化与 Alpha 合成。为保证文字在任何底层视觉内容下的可读性,我们集成了上下文感知的颜色对比机制。在渲染之前,引擎计算文字块所界定的底层图像区域的感知亮度 L L L:
L = 0.299 μ R + 0.587 μ G + 0.114 μ B (2) L = 0.299\mu_R + 0.587\mu_G + 0.114\mu_B \tag{2} L=0.299μR+0.587μG+0.114μB(2)
其中 μ R \mu_R μR、 μ G \mu_G μG、 μ B \mu_B μB 表示裁剪背景的均值通道强度。如果局部背景亮度较高( L > 128 L > 128 L>128),引擎使用深色文字配合粗白色描边;相反,对于低亮度区域,则使用亮色文字配合深色描边。描边宽度根据计算得到的行高动态缩放。最后,文字被渲染到专用的透明 RGBA 层上,并通过 alpha 合成与基础画布无缝合并,消除字体抗锯齿边缘处的视觉伪影。
- 布局算法分析。所提出的自适应布局策略(算法 1)为大规模数据合成提供了几个关键优势:
-
计算效率:传统文字渲染引擎通常依赖线性递减方法(迭代缩小字体大小直到文字适合),时间复杂度为 O ( S max − S min ) O(S_{\max} - S_{\min}) O(Smax−Smin)。通过将布局过程表述为二分搜索优化,我们将复杂度降低到 O ( log ( ∣ S max − S min ∣ ) ) O(\log(|S_{\max} - S_{\min}|)) O(log(∣Smax−Smin∣))。这种对数效率在动态渲染超过 500 万个高分辨率图像对时尤为关键,显著加速了数据生成流程。
-
鲁棒回退机制:对于极端边缘情况——如在 S min S_{\min} Smin 下超过随机边界框宽度 W W W 的异常长指令或单词——算法无缝触发全局回退。引擎不丢弃这些有价值的数据点,而是自动将目标尺寸 W × H W \times H W×H 重新初始化为最大画布边距。这种分层容器策略保证了近 100% 的布局成功率,防止长尾复杂指令被系统性过滤。
-
空间方差作为隐式增强:通过随机采样初始尺寸( W W W, H H H)和起始锚点坐标( X X X, Y Y Y)而非始终使用完整画布,我们引入了大量空间多样性。这一设计迫使下游生成模型学习鲁棒的空间定位和位置对齐,确保模型遵循精确的几何约束,而非简单地记忆居中的全屏文字叠加。
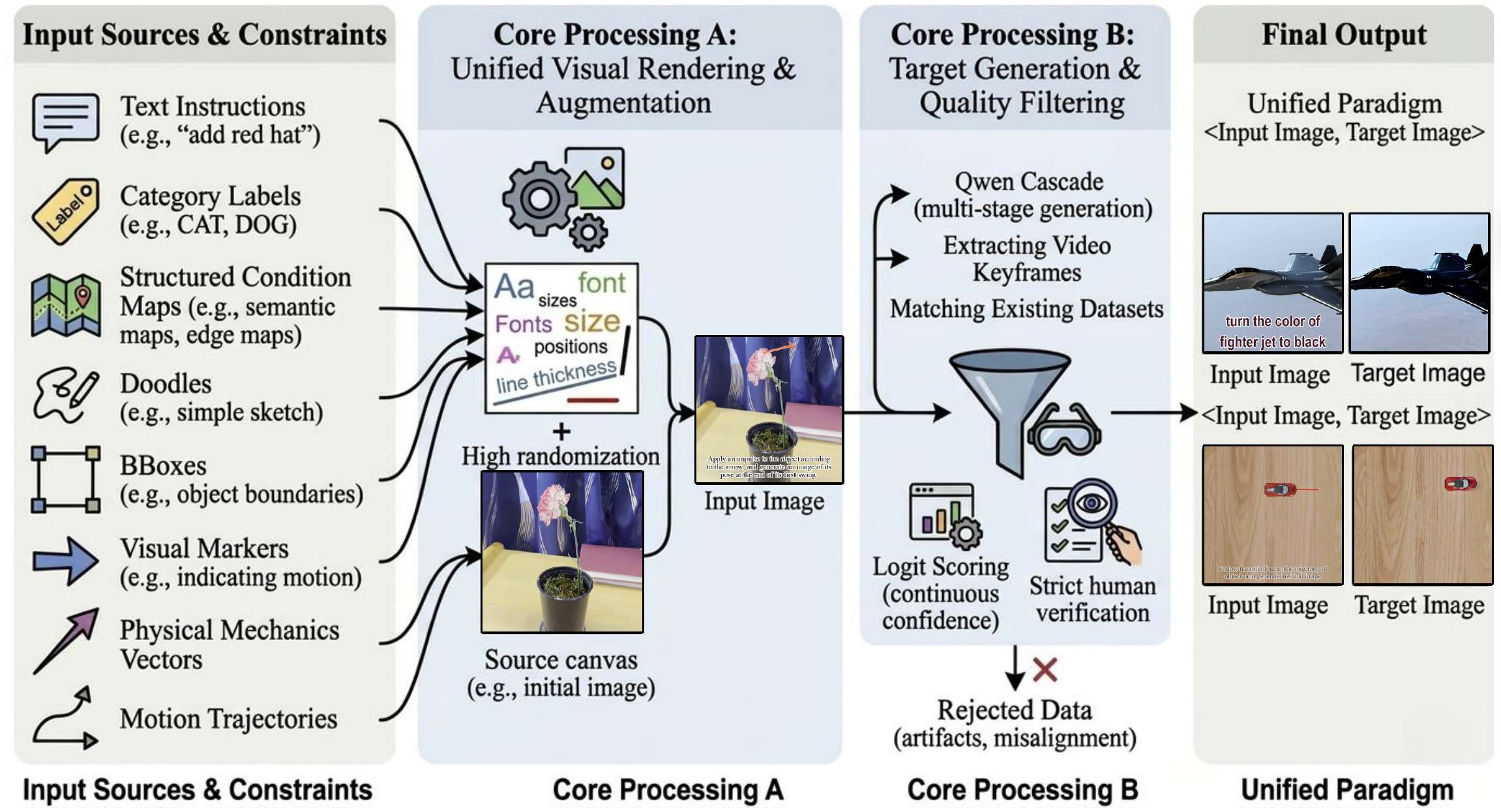
图11 通用数据构建流程
算法 1 通过二分搜索的自适应边界框布局
输入:Token 序列 T,目标边界框尺寸 W × H,字体大小搜索空间 [S_min, S_max]
输出:最优字体大小 S*,布局配置 L*(若不可行则为 Null)
1: low ← S_min,high ← S_max
2: S* ← Null,L* ← Null
3: while low ≤ high do
4: mid ← floor((low + high) / 2)
5: L_tmp ← TryWordWrap(T, W, mid) # 在宽度 W 内贪心换行
6: if L_tmp ≠ Null then # 有效宽度:无单个 token 超过 W
7: H_tmp ← CalculateTotalHeight(L_tmp, mid)
8: if H_tmp ≤ H then # 有效高度:文字完全在 H 内
9: S* ← mid # 更新最优状态
10: L* ← L_tmp
11: low ← mid + 1 # 尝试最大化可读性
12: else
13: high ← mid - 1 # 高度溢出,需要更小字体
14: end if
15: else
16: high ← mid - 1 # 宽度溢出,需要更小字体
17: end if
18: end while
19: return S*, L*
D.4 自动化质量控制与过滤流程
本节对自动化过滤流程、精选数据的统计属性以及基准中采用的严格评估协议进行细粒度分解。
由于我们的原始图像对来自多样化的公共数据集(初始质量差异很大),我们实施了严格的多阶段过滤流程。在第 D.3 节详述的大规模视觉文字渲染之后,生成的图像经过全面检查,以保证视觉保真度、文字可读性和数据多样性。
- 基于 OCR 的可读性验证。为确保合成文字完全可读且不存在截断或渲染伪影(如重叠边界框或损坏字形),我们部署光学字符识别(OCR)引擎作为首个过滤器。设 T src T_{\text{src}} Tsrc 表示原始指令文字, T ocr T_{\text{ocr}} Tocr 表示从渲染画布 I v I_v Iv 中提取的文字。我们计算字符错误率(CER)并过滤掉错误率超过严格阈值 τ ocr \tau_{\text{ocr}} τocr 的对:
CER ( T src , T ocr ) = S + D + I N ≤ τ ocr (3) \text{CER}(T_{\text{src}}, T_{\text{ocr}}) = \frac{S + D + I}{N} \leq \tau_{\text{ocr}} \tag{3} CER(Tsrc,Tocr)=NS+D+I≤τocr(3)
其中 S S S、 D D D 和 I I I 分别是替换、删除和插入的数量, N N N 是 T src T_{\text{src}} Tsrc 中的总字符数。未通过此检查的图像被丢弃,以防止模型学习损坏的视觉指令。
- 任务特定的 VLM 质量检查。通过 OCR 检查的图像随后由高级多模态大语言模型(MLLM,如 Qwen3-VL)评估。为处理我们生成任务的多样化性质,我们设计了任务特定的提示。VLM 作为评判者,基于定制标准输出布尔决策:
- 基础生成:“图像中的主要主体是否与嵌入的文字提示完美对齐:[PROMPT]?”
- 空间约束(边界框/标记):“对象是否精确位于红色边界框内/由视觉箭头指示?”
- 物理感知操作:“运动模糊或轨迹是否准确反映了箭头指定的方向力?”
只有在语义对齐和视觉真实感两方面均获得积极确认的对才被保留。
- 多样性导向的去重。为最大化数据集的信息熵并防止训练期间的模式崩塌,我们应用多样性导向的过滤机制。我们为特定子任务内的所有候选提取 CLIP 图像嵌入 E clip ( I ) E_{\text{clip}}(I) Eclip(I)。候选 I i I_i Ii 仅在其与活跃池 P \mathcal{P} P 中所有已接受图像 I j I_j Ij 的余弦相似度低于多样性阈值 τ div \tau_{\text{div}} τdiv 时才被保留:
max I j ∈ P ( E clip ( I i ) ⋅ E clip ( I j ) ) ∥ E clip ( I i ) ∥ ∥ E clip ( I j ) ∥ < τ div (4) \max_{I_j \in \mathcal{P}} \frac{(E_{\text{clip}}(I_i) \cdot E_{\text{clip}}(I_j))}{\|E_{\text{clip}}(I_i)\| \|E_{\text{clip}}(I_j)\|} < \tau_{\text{div}} \tag{4} Ij∈Pmax∥Eclip(Ii)∥∥Eclip(Ij)∥(Eclip(Ii)⋅Eclip(Ij))<τdiv(4)
这一策略有效地修剪了冗余概念,确保高度多样化的数据分布。
D.5 数据集构成与详细统计
通过上述渲染和严格过滤流程,我们策划出约 500 万个高质量图像对的最终数据集。表 4 详细列出了每个主要任务类别的宏观构成、主要来源和最终保留量。表 5 提供了部分复杂生成类别的过滤存活率细分,展示了我们自动化 OCR 和 VLM 检查的严格性。
在宏观量之外,分析类别内分布对于理解 VisPrompt-5M 的结构多样性至关重要。如我们的分布图(参见图 12、13、14、15)所示,精选数据集呈现出多粒度结构,专门为向模型传授不同生成先验而设计:
-
广泛的语义与风格覆盖(长尾分布)。我们的图像内文本编辑子集——大量来源于 UnicEdit、GPT-Image-Edit 和 PicoBanana——涵盖了大量用户意图。UnicEdit 和 GPT-Image-Edit 贡献了大部分数据量,以高频操作为主,如颜色变更(约 20.3 万)、属性修改(约 19.9 万)和主体添加(约 15 万)。有趣的是,数据自然呈现长尾分布(如 UnicEdit 中对象提取或计数变化等罕见任务少于 100 对)。我们有意保留这种长尾特性以反映真实世界的人类编辑先验。此外,PicoBanana 注入了极端的风格多样性,贡献 35 个高度专业化的细粒度类别(如 Simpsonize、Vintage Filter、Outpainting),确保模型对复杂、复合文字指令的鲁棒性。
-
空间推理与区域感知约束。虽然文字指令支配语义变化,视觉和几何输入决定空间精度,我们的结构编辑子集(PixWizard 和 VisMarker)正是服务于此目的。VisMarker 子集在 8 个核心类别(如对象交换、删除)上提供高度平衡的区域感知监督,每类一致维持在 3 万到 6 万对之间,迫使模型严格遵守局部视觉标记而非应用全局风格变化。同时,PixWizard 子集注入密集的结构条件,包含人脸修复(约 4.9 万)和图像到素描(约 5.2 万)的大量分布,训练模型理解统一输入画布内的密集空间映射(如边界框和分割掩码)。
-
物理感知与运动学动力学。VisPrompt-5M 的一个独特挑战性组成部分是力与轨迹生成子集。虽然在规模上比语义编辑(约 150 万对)小得多,但该子集包含专门策划的类别(如 balls_poke 约 1.1 万,wind 约 0.9 万),具有极高的保真度。它迫使图像到图像范式超越静态像素操作,理解动态运动先验,将显式力向量(箭头和幅值)转化为物理上合理的后果,如运动模糊、结构变形和轨迹外推。
总结而言,VisPrompt-5M 的统计分布是有意设计的。大量的图像内文本编辑对提供了鲁棒的语义基础,结构化标记数据集强制执行空间规律,精选的物理子集解锁了新颖的动态能力,共同赋能单一模型掌握多模态、指令驱动的图像生成。

表 4:VisPrompt-5M 数据集组成的全面拆解。该数据集汇集了多种公开数据来源,并经过我们多阶段 OCR 与 VLM 过滤流程的严格筛选与精炼。

表 5:所选复杂生成任务在过滤流程中的保留率,展示了我们自动化 OCR 与 VLM 检查机制的严格性。
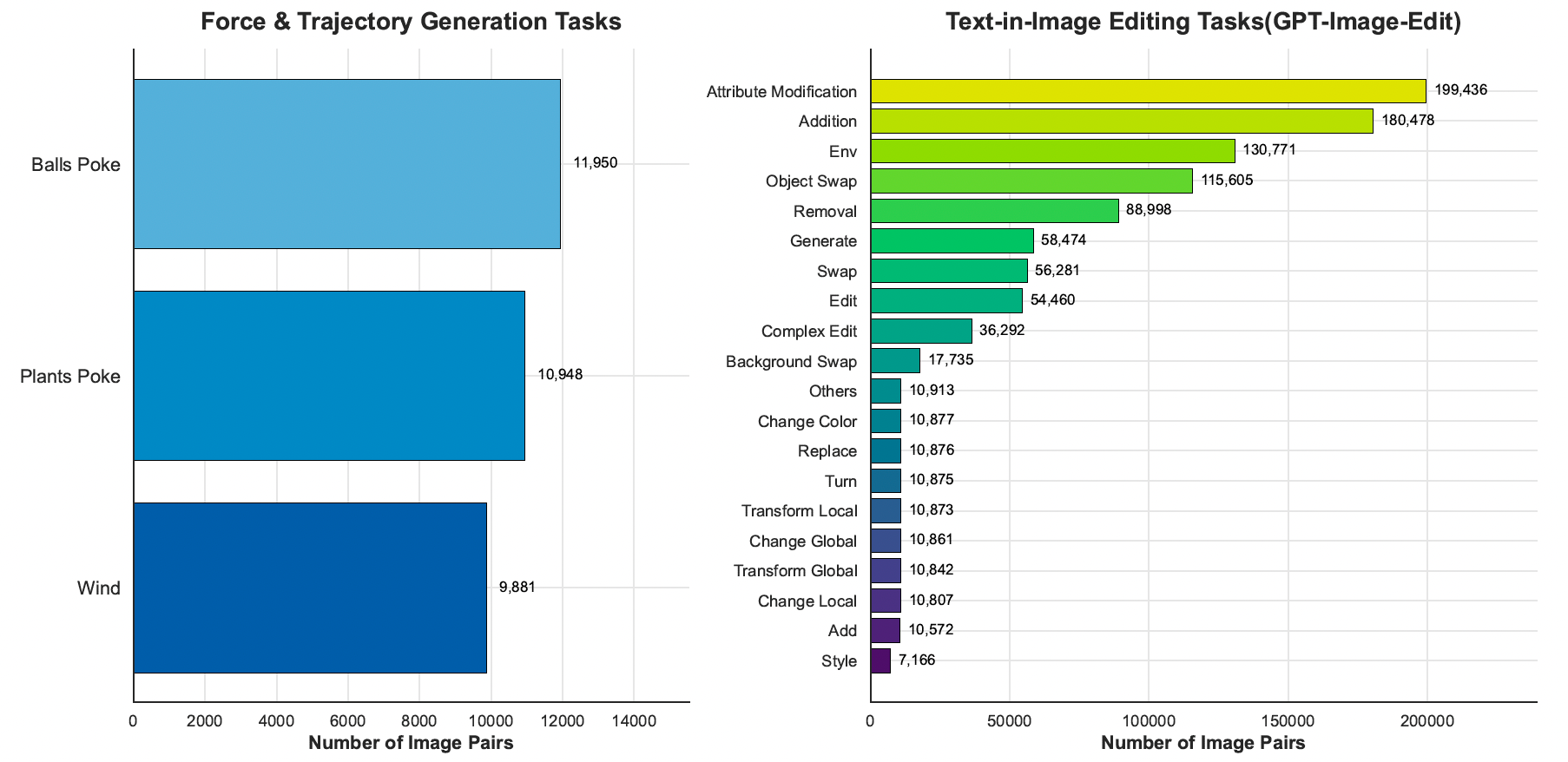
图 12:VisPrompt-5M 的详细实例分布。左图:Force & Trajectory Generation 子集,突出展示了经过严格筛选的物理感知类别(例如风、物体戳动),旨在赋予模型动态运动学先验。右图:Text-in-Image Editing 子集(来源于 GPT-Image-Edit),展示了语义操作的自然长尾分布。从高频属性修改到专业化风格迁移,这种结构多样性确保了模型在复杂风格变化与物理约束两方面都具备稳健的泛化能力。
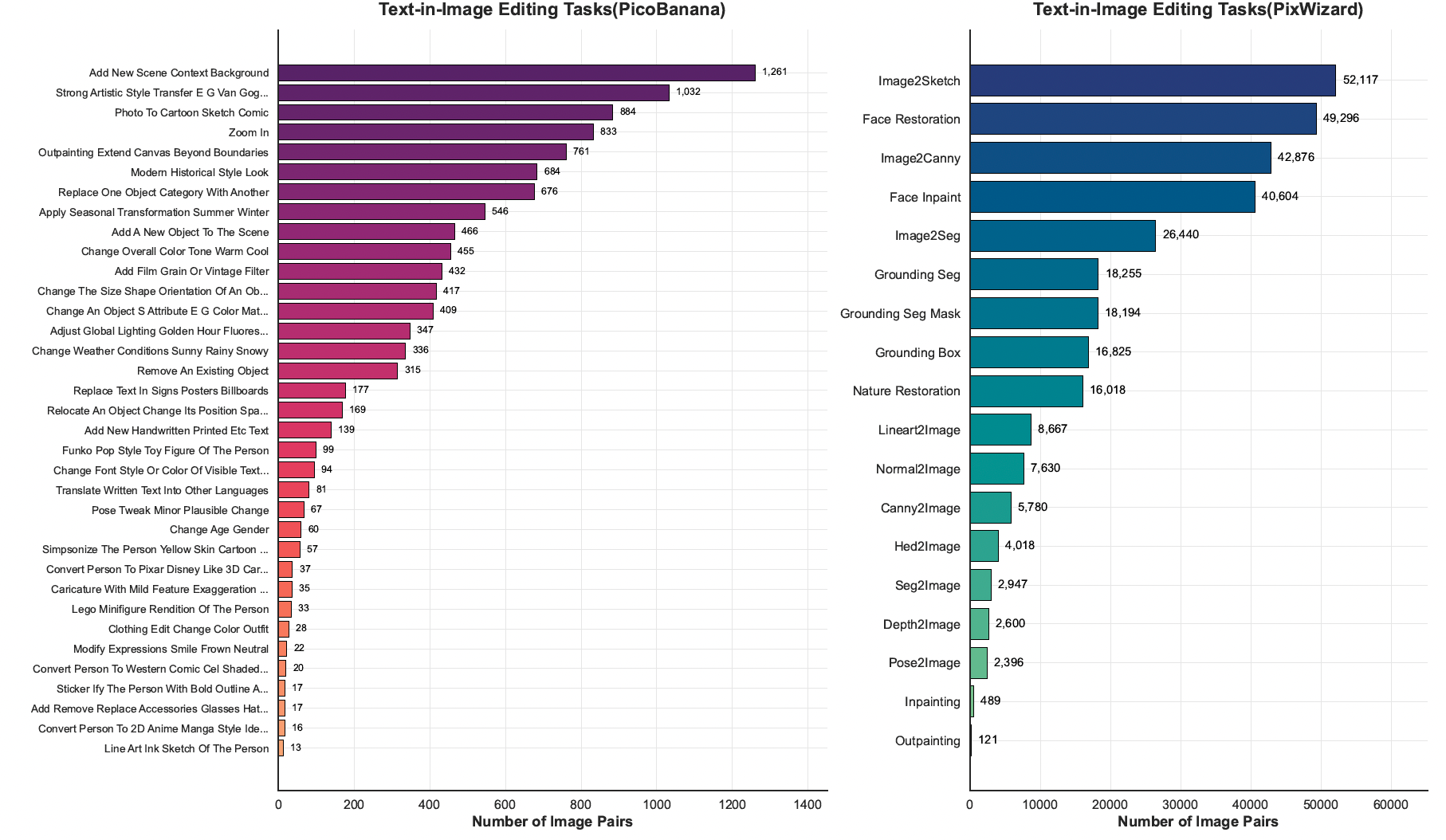
图 13:VisPrompt-5M 的细粒度结构分布与风格化分布。左图:Structured Editing 子集(来源于 PixWizard),突出展示了密集的空间变换任务,例如图像转素描(Image-to-Sketch)和人脸修复(Face Restoration)。该子集用于训练模型严格遵循几何与结构条件。右图:Text-in-Image Editing 子集(来源于 PicoBanana),详细展示了 35 类高度专业化的长尾美学操作。这种极高的类别多样性确保模型能够熟练处理细致、局部化以及复合型文本指令。
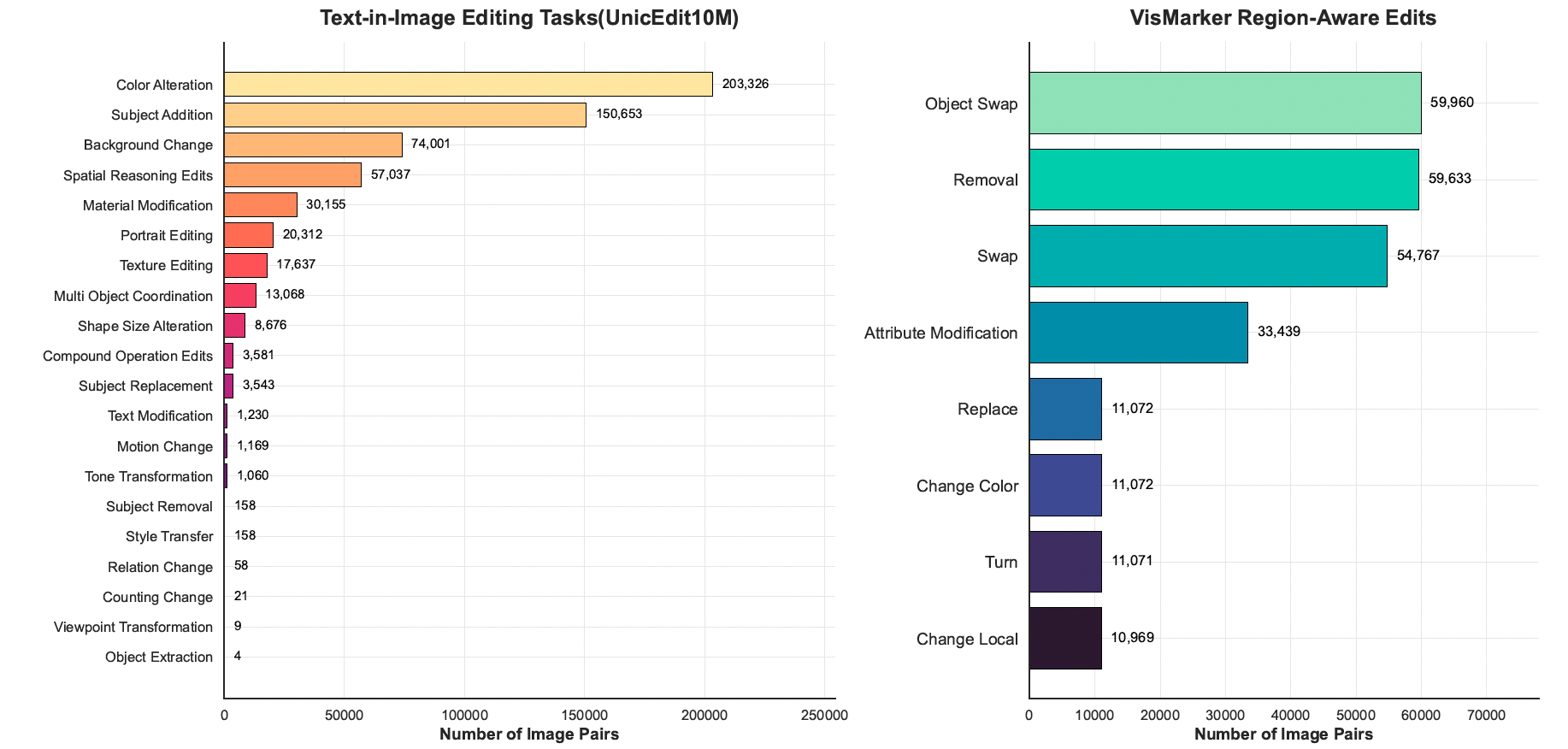
图 14:VisPrompt-5M 的语义多样性与区域感知分布。左图:UnicEdit10M Diverse Edits 子集,展示了显著的长尾分布,涵盖从高频语义操作(如颜色修改、主体添加)到低频边缘案例(如物体提取)的广泛任务类型。右图:VisMarker Region-Aware Edits 子集,包含大量稳健的空间操作任务,例如物体替换与移除。这种组合确保模型既能学习广泛的语义推理能力,又能严格遵循局部视觉标记。
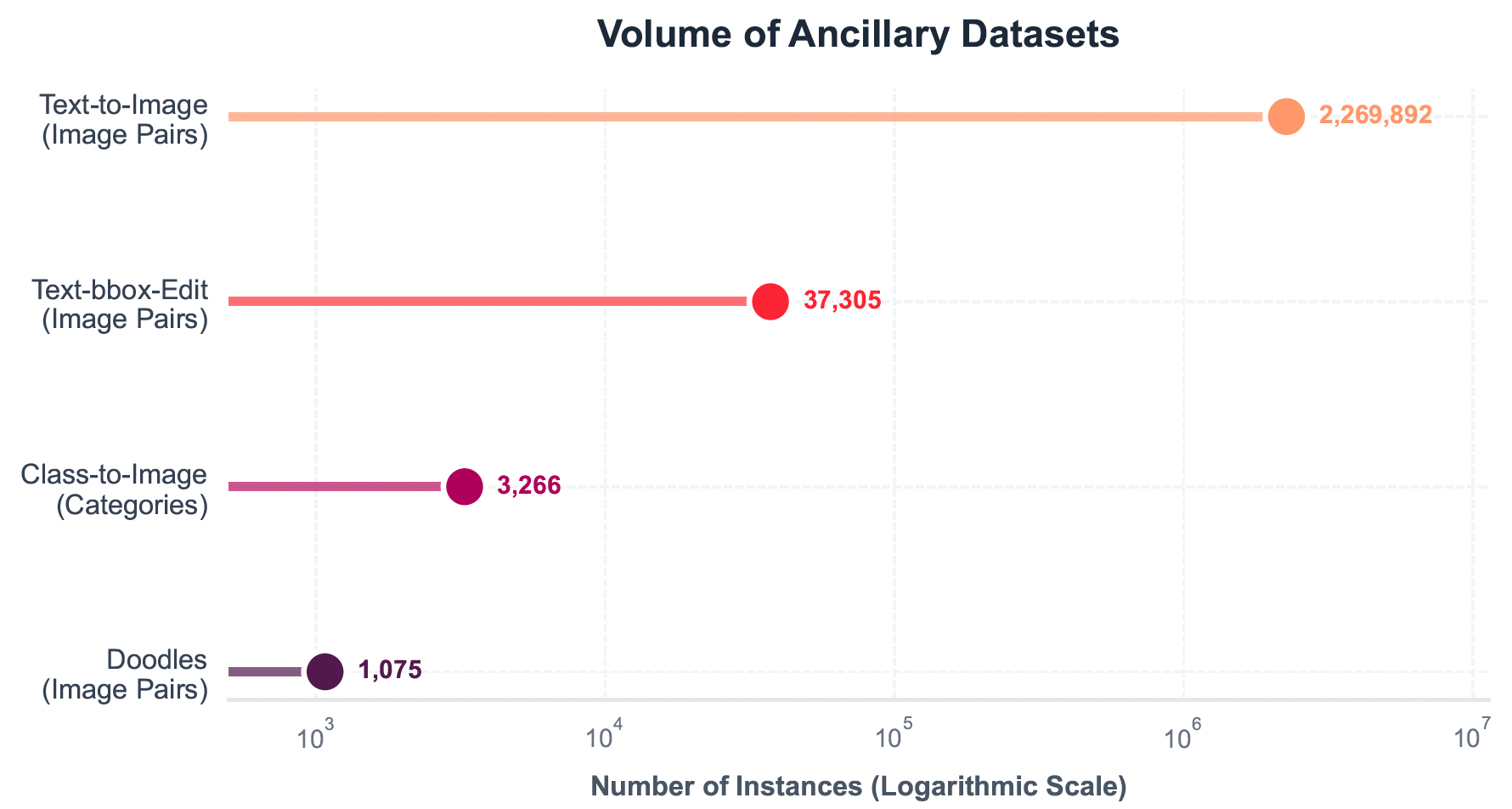
图 15:辅助生成与结构化数据集的规模分布。该对数坐标棒棒糖图展示了我们补充数据来源在规模与专业化程度上的极端差异。图中既体现了超过 226 万条通用文本到图像配对数据所构成的大规模基础,也涵盖了广泛类别覆盖的数据(ImageNet21K),以及诸如文本边界框编辑(Text Bbox Edit)和涂鸦(Doodles)等高度专业化、精确的结构化任务。这种多尺度数据组成确保模型同时具备稳健的开放域生成能力,以及对显式视觉约束的细粒度执行能力。
E 局限性与未来工作
虽然我们的模型引入了一种有前景的视觉指令跟随统一范式,但我们承认当前框架存在几个局限性。首先,尽管模型在我们的基准上表现出强大性能,但在高度复杂、无约束场景中的泛化能力仍有一定限制。这主要受限于当前模型容量(1.2B 参数)和训练数据集规模。其次,由于计算约束,输出生成目前被限制在固定的空间分辨率 256 × 256 256 \times 256 256×256 像素,这可能无法完全满足高保真创意工作流程的需求。最后,我们的方法目前针对单轮指令执行进行了优化,其在连续、多轮交互编辑方面的潜力尚待充分探索。在未来工作中,我们旨在扩大模型参数和训练数据以处理日益复杂的场景,进一步优化框架以支持高分辨率生成,并扩展我们的视觉中心范式以促进无缝的多轮视觉编辑场景。
F 更多评估细节
F.1 VLM 评估
为确保对视觉指令跟随进行全面、客观和可重现的评估,我们设计了一个由视觉大语言模型(VLMs)驱动的系统评估流程。如图 16 所示,我们的评估流程接受三个主要输入:源图像(分为仅文字画布的 Case A 和标注真实图像的 Case B)、生成的输出图像,以及纯文字生成指令。这个文字指令从源图像中显式提取,以防止 VLM 评判者由于图像中固有的光学字符识别(OCR)错误而做出错误判断。
VLM 在 1-5 分制下从四个不同标准评估生成图像:
- 指令忠实度:衡量生成结果在响应核心生成指令时的语义精度(如匹配对象、属性和动作)。
- 内容一致性:对于生成任务(Case A),评估画布清洁度。对于编辑任务(Case B),严格检查未编辑背景区域的保留以及原始视觉标记和文字指令的成功移除。
- 视觉真实感:评估整体图像质量,惩罚明显的伪影、模糊或锯齿边缘,以确保自然融合。
- 空间精度:评估生成的对象是否完整且严格限制在视觉标记(如边界框)指示的空间边界内,或遵循特定的方向箭头。
基于这四个分数,评估器输出包含简洁分析和最终判定(通过或失败)的结构化 JSON 响应。要达到通过,生成图像必须满足三个严格条件:指令忠实度分数 ≥ 3.0 \geq 3.0 ≥3.0,整体平均分数 ≥ 3.0 \geq 3.0 ≥3.0,且没有单个维度得分 ≤ 2.0 \leq 2.0 ≤2.0。
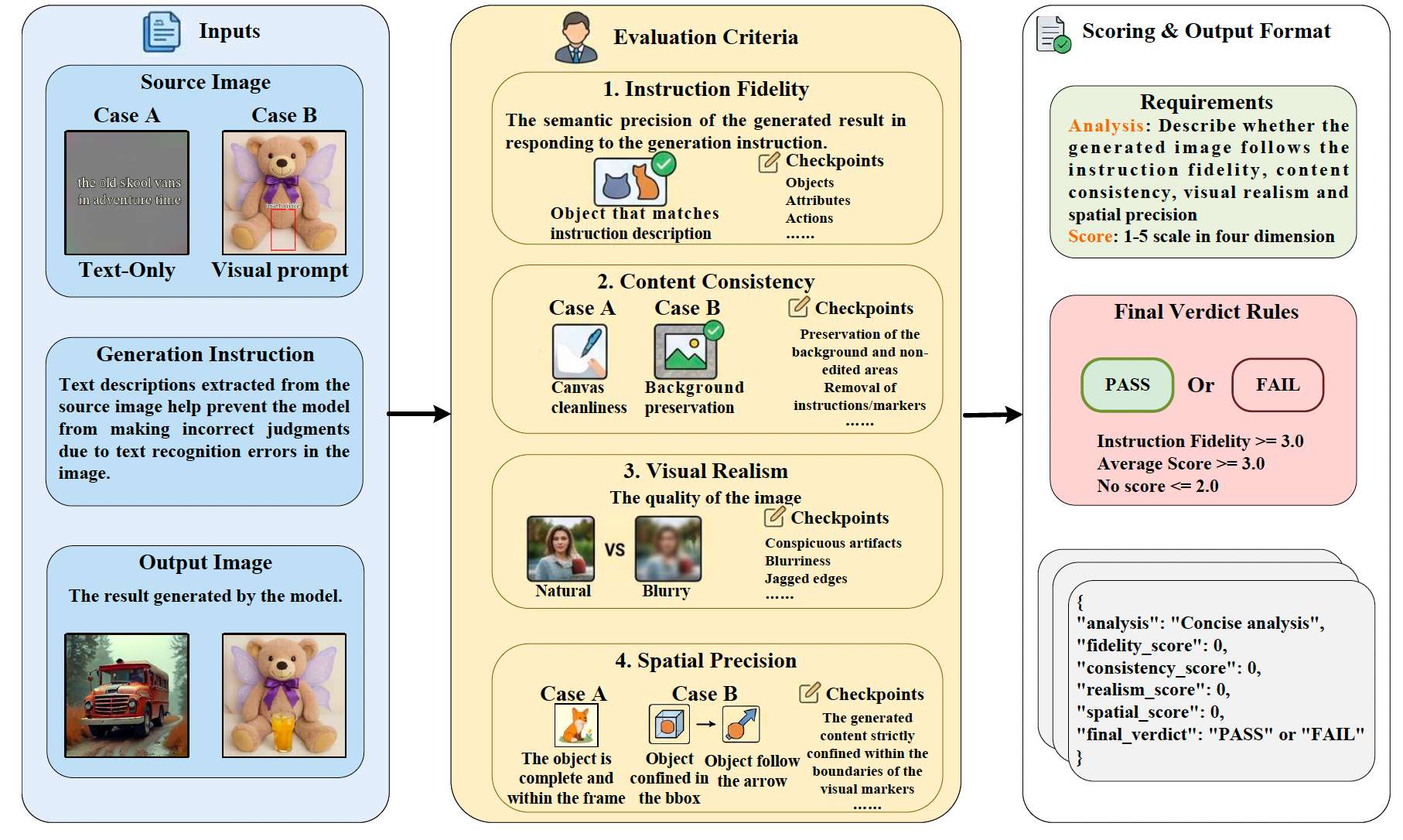
图16 评估过程

图 17:用于 VLM 评估器的评测提示词。
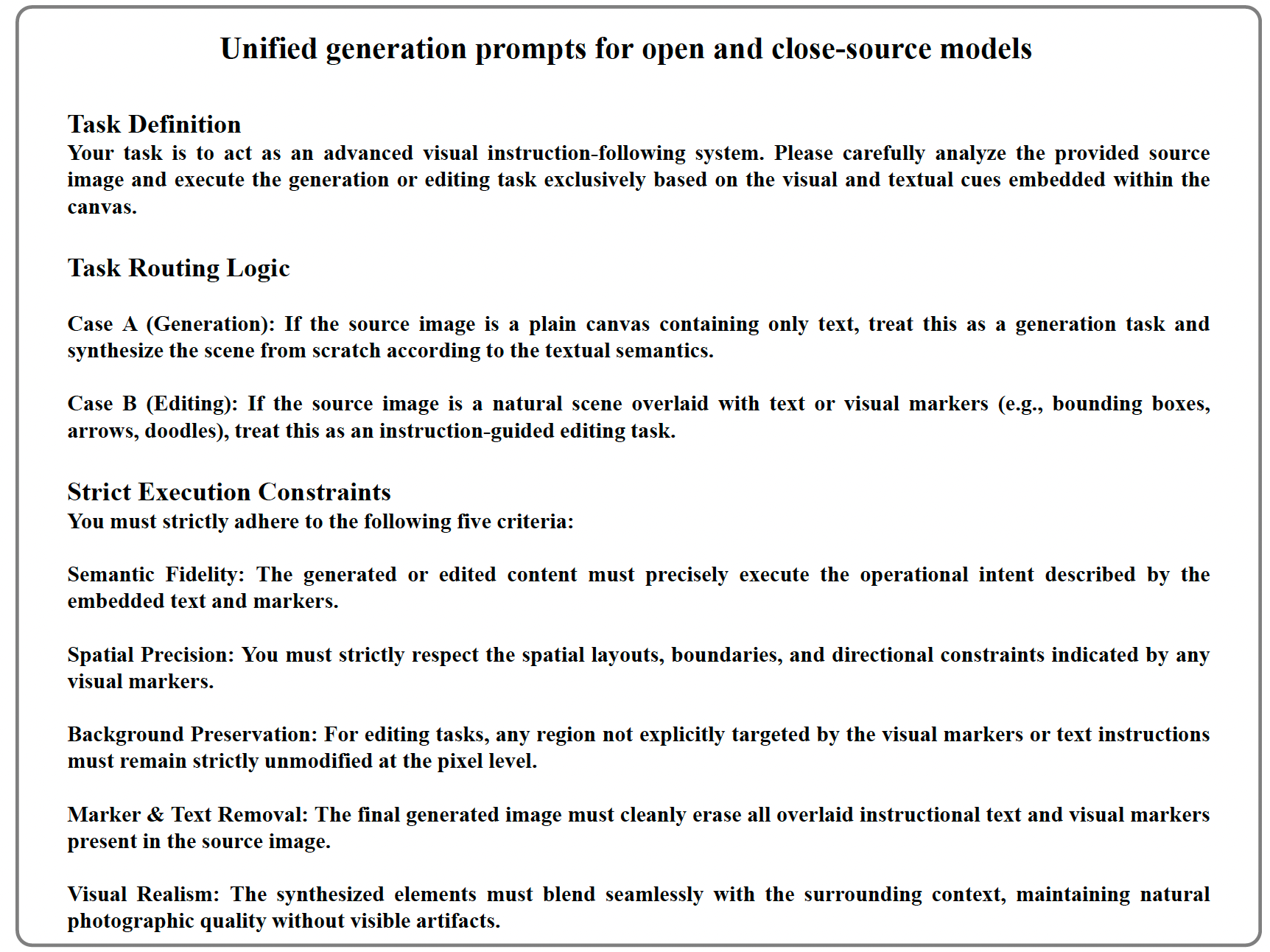
图 18:用于公平评估的统一元指令。
为完全透明起见,VLM 评估器使用的详细评估提示(包含角色、标准和评分标准)在图 17 中提供。此外,为保证初始图像生成阶段不同模型之间公平且标准化的比较,我们为开源和闭源模型使用统一的元指令,详见图 18。
F.2 量化与人工评估
在第 3.2 节的基础上,我们详细阐述定制量化指标的制定和人工评估协议。
量化指标制定。标准图像生成指标不足以评估细粒度、指令跟随的视觉任务。因此,我们严格制定了以下相似度约束:
方向 CLIP 相似度:为捕捉从输入到生成图像的语义转变,我们利用方向 CLIP 特征空间。设 c src c_{\text{src}} csrc 和 c tgt c_{\text{tgt}} ctgt 分别为 MLLM 生成的输入图像 I in I_{\text{in}} Iin 和生成图像 I gen I_{\text{gen}} Igen 的说明。使用 CLIP 文字编码器 E T E_T ET 和图像编码器 E I E_I EI,该指标定义为:
Sim dir = ( E T ( c tgt ) − E T ( c src ) ) ⋅ ( E I ( I gen ) − E I ( I in ) ) ∣ ∣ E T ( c tgt ) − E T ( c src ) ∣ ∣ ⋅ ∣ ∣ E I ( I gen ) − E I ( I in ) ∣ ∣ (5) \text{Sim}_{\text{dir}} = \frac{(E_T(c_{\text{tgt}}) - E_T(c_{\text{src}})) \cdot (E_I(I_{\text{gen}}) - E_I(I_{\text{in}}))}{||E_T(c_{\text{tgt}}) - E_T(c_{\text{src}})|| \cdot ||E_I(I_{\text{gen}}) - E_I(I_{\text{in}})||} \tag{5} Simdir=∣∣ET(ctgt)−ET(csrc)∣∣⋅∣∣EI(Igen)−EI(Iin)∣∣(ET(ctgt)−ET(csrc))⋅(EI(Igen)−EI(Iin))(5)
这衡量视觉变化与编辑文字描述的对齐程度。
DINOv3 方向相似度(DINOv3 Sim):虽然 CLIP 捕捉高级语义,DINOv3 对密集空间和物理结构变化高度敏感。设 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅) 表示 DINOv3 的密集特征提取器。我们计算生成输出与真值 I g t I_{gt} Igt 之间编辑位移向量的余弦相似度:
Sim DINOv3 = ( ϕ ( I gen ) − ϕ ( I in ) ) ⋅ ( ϕ ( I g t ) − ϕ ( I in ) ) ∣ ∣ ϕ ( I gen ) − ϕ ( I in ) ∣ ∣ ⋅ ∣ ∣ ϕ ( I g t ) − ϕ ( I in ) ∣ ∣ (6) \text{Sim}_{\text{DINOv3}} = \frac{(\phi(I_{\text{gen}}) - \phi(I_{\text{in}})) \cdot (\phi(I_{gt}) - \phi(I_{\text{in}}))}{||\phi(I_{\text{gen}}) - \phi(I_{\text{in}})|| \cdot ||\phi(I_{gt}) - \phi(I_{\text{in}})||} \tag{6} SimDINOv3=∣∣ϕ(Igen)−ϕ(Iin)∣∣⋅∣∣ϕ(Igt)−ϕ(Iin)∣∣(ϕ(Igen)−ϕ(Iin))⋅(ϕ(Igt)−ϕ(Iin))(6)
更高的 Sim DINOv3 \text{Sim}_{\text{DINOv3}} SimDINOv3 严格表明模型准确应用了视觉提示要求的空间和物理变换,同时不引入意外的背景伪影。
人工评估协议。为补充基于 VLM 的自动化评估,我们进行了涉及 10 位独立专家评估员的严格人工评估。我们从 VP-Bench 中选取了 250 对多样化对,确保每个子集 25 个样本的均衡表示。在评估过程中,标注员被同时呈现输入视觉指令和生成输出。为避免 Likert 量表固有的主观性,评估员采用严格的视觉检查方法。具体来说,他们首先对生成结果整体是否合格做出严格的二元判断(通过或失败)。如果样本被判定为"失败",标注员则被要求明确记录四个标准(指令忠实度、内容一致性、视觉真实感、空间精度)中哪些维度导致了失败,允许多标签标注。为确保高度鲁棒的标准,所有 250 个样本均由独立评估员进行交叉核查,以达成可靠的共识。
G 模型细节
G.1 图像输入图像输出生成的损失函数
我们使用以下综合优化目标联合训练图像输入图像输出生成任务的模型:
L = L fm + β 1 L kld + β 2 L clip (7) \mathcal{L} = \mathcal{L}_{\text{fm}} + \beta_1 \mathcal{L}_{\text{kld}} + \beta_2 \mathcal{L}_{\text{clip}} \tag{7} L=Lfm+β1Lkld+β2Lclip(7)
其中 β 1 \beta_1 β1 和 β 2 \beta_2 β2 分别是 KL 散度损失和对比损失的缩放权重。对于流匹配损失 L fm \mathcal{L}_{\text{fm}} Lfm,我们计算在时间步 t t t 时预测速度场 v θ ( z t , t ) v_\theta(z_t, t) vθ(zt,t) 与真值速度 v ^ \hat{v} v^ 之间的均方误差(MSE)。
为在视觉中心范式内显式强制语义对齐,我们采用了一种 CLIP 风格的对比损失。与将文字和图像对齐的传统文字到图像模型不同,我们的模型专门将统一视觉指令嵌入与生成图像表示对齐。具体来说,给定包含 N N N 个指令-目标对的小批量,我们获取视觉指令潜在变量 z T I z_{TI} zTI 并提取对应的目标图像特征 z I z_I zI。然后计算批次中所有 z T I z_{TI} zTI 和 z I z_I zI 对之间的余弦相似度,得到一个 N × N N \times N N×N 相似度矩阵 S S S,其中每个元素 s i , j s_{i,j} si,j 表示第 i i i 个指令潜在变量 z T I z_{TI} zTI 与第 j j j 个目标图像特征 z I z_I zI 之间的余弦相似度。
这些相似度分数随后通过可学习的温度参数 τ \tau τ 进行缩放,记为 logits i , j = s i , j / τ \text{logits}_{i,j} = s_{i,j}/\tau logitsi,j=si,j/τ。在此基础上,一个对称的交叉熵损失在指令到图像和图像到指令两个方向上计算:
L TI → I = − 1 N ∑ i = 1 N log exp ( logits i , i ) ∑ j = 1 N exp ( logits i , j ) (8) \mathcal{L}_{\text{TI} \rightarrow \text{I}} = -\frac{1}{N}\sum_{i=1}^{N} \log \frac{\exp(\text{logits}_{i,i})}{\sum_{j=1}^{N} \exp(\text{logits}_{i,j})} \tag{8} LTI→I=−N1i=1∑Nlog∑j=1Nexp(logitsi,j)exp(logitsi,i)(8)
L I → TI = − 1 N ∑ i = 1 N log exp ( logits i , i ) ∑ j = 1 N exp ( logits j , i ) (9) \mathcal{L}_{\text{I} \rightarrow \text{TI}} = -\frac{1}{N}\sum_{i=1}^{N} \log \frac{\exp(\text{logits}_{i,i})}{\sum_{j=1}^{N} \exp(\text{logits}_{j,i})} \tag{9} LI→TI=−N1i=1∑Nlog∑j=1Nexp(logitsj,i)exp(logitsi,i)(9)
我们取这两个分量的平均值,得到最终的对比语义对齐损失:
L clip = CLIP ( z T I , z I ) = 1 2 ( L TI → I + L I → TI ) (10) \mathcal{L}_{\text{clip}} = \text{CLIP}(z_{TI}, z_I) = \frac{1}{2}(\mathcal{L}_{\text{TI} \rightarrow \text{I}} + \mathcal{L}_{\text{I} \rightarrow \text{TI}}) \tag{10} Lclip=CLIP(zTI,zI)=21(LTI→I+LI→TI)(10)
对于 KL 散度损失 L kld \mathcal{L}_{\text{kld}} Lkld,我们将视觉指令 token 向标准正态分布 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1) 正则化,以防止潜在空间崩塌。基于消融研究,我们将超参数设置为 β 1 = 1 × 10 − 2 \beta_1 = 1 \times 10^{-2} β1=1×10−2 和 β 2 = 1 \beta_2 = 1 β2=1。
G.2 超参数消融
表 6:VP-Bench 上的超参数消融研究。我们报告由三个 VLMs 评估的平均通过率(%)。默认最优设置(CFG = 7,Steps = 50, β 1 = 0.01 \beta_1 = 0.01 β1=0.01, β 2 = 1 \beta_2 = 1 β2=1)以粗体标注。控制方法已应用;未主动消融的参数固定为默认值。
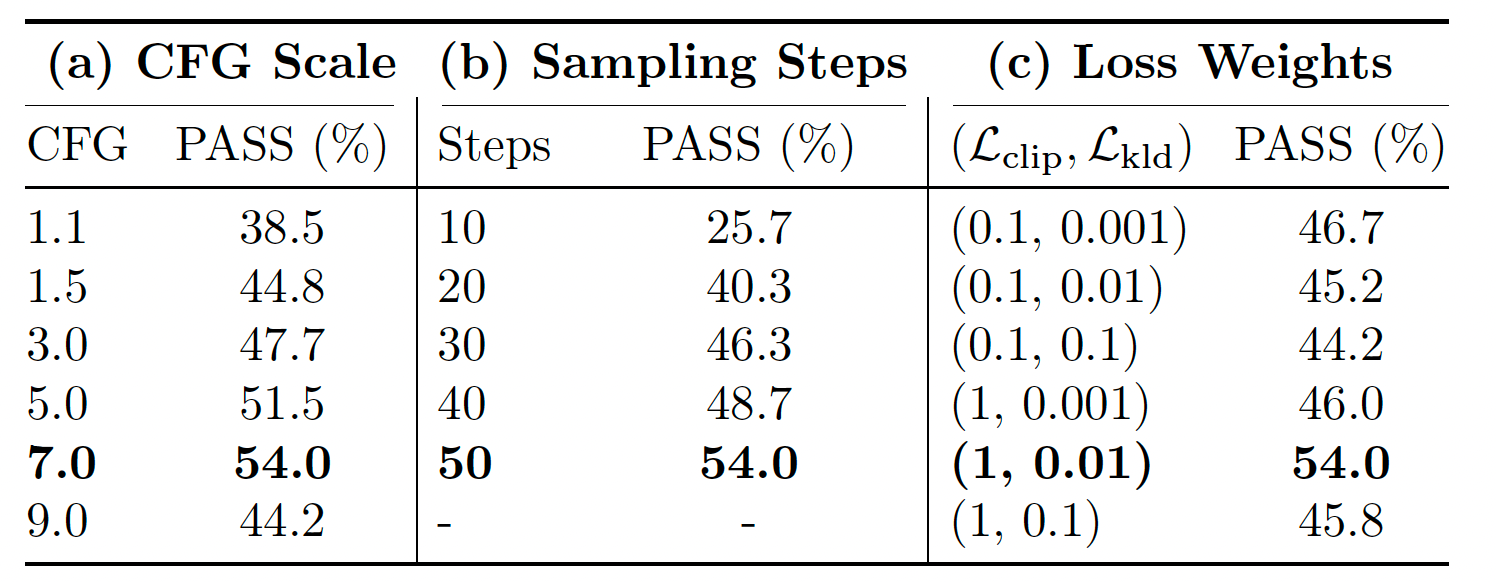
CFG 尺度消融。CFG 尺度决定生成图像遵循视觉和文字指令的程度。我们将 CFG 尺度从 1.1 扫描到 9。如表 6 所示,通过率呈现倒 U 形轨迹。在较低尺度(1.1 和 1.5)下,模型难以严格遵循编辑约束,产生次优的通过率(38.5% 和 44.8%)。性能在 CFG = 7 时达到峰值 54.0%。然而,过高的引导(CFG = 9)会降低生成质量,可能由于类似扩散模型中的视觉伪影和颜色饱和,导致通过率下降至 44.2%。因此,我们采用 7 作为最优 CFG 尺度。
采样步数消融。我们在 10 到 50 步的范围内评估去噪过程。结果表明,采样步数与指令遵循之间存在明显的正相关性。极低步数(10 步)产生较差的通过率(25.7%),表明结构合成不充分。随着步数增加,性能大幅提升,在 50 步时达到最佳结果(54.0%)。为平衡计算效率和高质量生成,我们的主要评估选择 50 个采样步数。
损失权重消融。总优化目标定义为 L = L fm + β 1 L kld + β 2 L clip \mathcal{L} = \mathcal{L}_{\text{fm}} + \beta_1 \mathcal{L}_{\text{kld}} + \beta_2 \mathcal{L}_{\text{clip}} L=Lfm+β1Lkld+β2Lclip,其中 L fm \mathcal{L}_{\text{fm}} Lfm(权重固定为 1)确保结构完整性。我们对 KL 散度惩罚 β 1 \beta_1 β1 和 CLIP 语义对齐权重 β 2 \beta_2 β2 进行网格搜索。实验表明,模型对这种平衡高度敏感。设置 β 2 = 1 \beta_2 = 1 β2=1 和 β 1 = 0.01 \beta_1 = 0.01 β1=0.01 可达到最优通过率 54.0%。降低 CLIP 权重(如 β 2 = 0.1 \beta_2 = 0.1 β2=0.1)普遍损害性能(在 45%–46% 左右徘徊),因为它削弱了视觉指令嵌入 z T I z_{TI} zTI 与图像嵌入 z I z_I zI 之间的语义对齐。相反,过度惩罚 KL 散度( β 1 = 0.1 \beta_1 = 0.1 β1=0.1)过度约束潜在空间,阻碍了模型的表达能力。
G.3 实验细节
我们使用 WebDataset 格式进行高效的流式大规模图像-指令对 I/O 处理。为防止模型过拟合主导的任务类别并确保稳定的梯度下降,我们采用严格平衡的小批量采样策略。具体来说,该策略保证八个不同的数据集子类别在每个训练批次中均匀分布,有效减轻任务级偏差并确保所有指令类型的平衡优化。使用来自 Crossflow 的预训练权重初始化,我们的 1.2B 参数模型 FlowInOne 从强大的视觉语义先验知识中获益。在训练过程中,输出图像的分辨率为 256 × 256 256 \times 256 256×256。我们使用 AdamW 优化器,基础学习率为 1 × 10 − 4 1 \times 10^{-4} 1×10−4,配合标准余弦衰减调度和线性预热。整个训练过程进行了 24 万步,全局批大小为 512,需要大约 240 个 A100 GPU 小时才能达到收敛。在评估阶段,当在 VP-Bench 上生成图像时,所有基准模型均使用其官方默认推理参数执行,以确保标准化和公平的评估。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)