MPDA:多视角数据增强,给深度学习漏洞检测补上“样本短板”
“ 深度学习在软件漏洞检测上已有不少成功尝试,但现实问题依然明显:漏洞样本少、类别极度不平衡,导致模型易漏报、误报。MPDA(multiperspective data augmentation)提出通过三种互补的增强策略(oversampling、GAN、fuzzy sampling)与两套策略选择算法(OSS / FSS),按漏洞类型与下游模型自动选择最优增强组合,从而系统性地提高训练数据的质量与多样性。”
论文:MPDA: a data augmentation approach to improve deep learning for software vulnerability detection
作者:Feiqiao Mao, Yingxiang Yuan, Xingyang Du, Li Gao, Zhihua Du
单位:深圳大学软件与计算机学院
期刊:Empirical Software Engineering (2025)开源代码:https://github.com/Yfeix/MPDA.
01
—
方法简介
MPDA 的流程分三步:
-
→方法级代码预处理(基于 Word2Vec 将方法/行转换成向量)
-
多视角增强(OSS:智能选过采样、GAN:生成正/负样本、FSS:模糊采样策略选择)
-
用增强后的训练集训练下游模型(LSTM/GRU/BiLSTM/BiGRU/ Transformer)。
关键在于两个自动选择算法:OSS(为每类漏洞挑选最合适的oversampling)与 FSS(为每类漏洞 & 下游模型挑选最合适的 fuzzy 策略),从而实现“因类制宜”的增强。
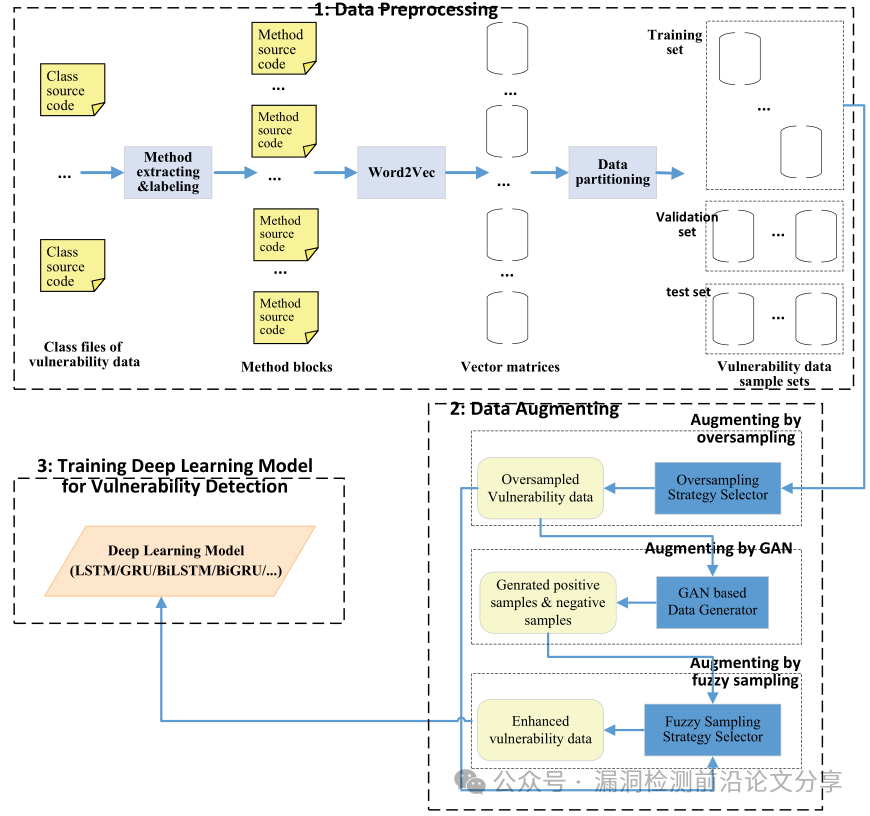
图:MPDA 三大组件与策略选择流程
小结:MPDA不是把所有增强堆在一起,而是通过策略选择把最合适的增强“配给”每一类漏洞与模型,从而既增加数量又保留可学特征。
02
—
关键机制
|
机制 |
核心实现 |
目标与作用 |
|---|---|---|
|
OSS(Oversampling Strategy Selection) |
候选:SMOTE / Borderline-SMOTE / ADASYN。基于漏洞类型的嵌入分布自动选择最合适方法。 |
针对不同分布选择最佳过采样,减少噪声/过拟合风险。 |
|
GAN-based 生成 |
正/负样本分别训练 pGAN / nGAN,生成语义上更真实的合成样本。 |
扩充稀缺类别样本数量并提升多样性,缓解样本不足。 |
|
FSS(Fuzzy Sampling Strategy Selection) |
设计四种 fuzzy 策略,按漏洞类型与下游模型复杂度自动匹配(basic vs variant NN)。 |
通过受控扰动提升泛化能力并在不同模型间找到最优增强组合。 |
|
策略组合(MPDA) |
OSS + GAN + FSS 的协同组合(OSS+GAN+FSS 被定义为 MPDA 的默认组合)。 |
综合三类增强的优点,对多数模型在 F1 / Recall 上带来显著提升。 |
小结:三类增强互补、两套策略自动化选择,是 MPDA 在多模型、多漏洞类型上稳定提升的核心设计理念。
03
—
实验结果
主要实验基准为 Juliet 1.2 Java Test Suite(选取 29 类常用 CWE 做主测试)。论文还评估了51类小样本子集以验证对小样本场景的效果。训练/验证/测试划分采用 8:1:1。关键比较结果如下:
表12 应用不同过采样方法改进LSTM和GRU的结果
|
方法 |
LSTM |
|||
|---|---|---|---|---|
|
A |
P |
R |
F1 |
|
|
Baseline |
80.7 |
66.8 |
46.5 |
50.7 |
|
SMOTE |
79.5 |
65.1 |
78.9 |
67.6 |
|
GAN |
81.2 |
75.8 |
48.4 |
52.9 |
|
Fuzzy |
80.2 |
63.9 |
51.7 |
53.3 |
| MPDA | 91.2 | 80.9 | 96.7 | 87.4 |
|
方法 |
GRU |
|||
|---|---|---|---|---|
|
A |
P |
R |
F1 |
|
|
Baseline |
80.2 |
69.3 |
39.5 |
46.0 |
|
SMOTE |
76.7 |
66.2 |
70.0 |
61.2 |
|
GAN |
80.4 |
69.0 |
48.2 |
49.2 |
|
Fuzzy |
78.0 |
65.8 |
42.3 |
46.4 |
| MPDA | 85.7 | 69.1 | 79.9 | 72.3 |
表19 利用FSS优化数据增强以改进BiLSTM和BiGRU的结果
|
方法 |
BiLSTM |
|||
|---|---|---|---|---|
|
A |
P |
R |
F1 |
|
|
SMOTE+GAN+Fuzzy |
91.8 |
81.9 |
94.5 |
86.3 |
|
SMOTE+GAN+FSS |
92.9 |
84.3 |
95.3 |
88.5 |
|
OSS+GAN+Fuzzy |
92.3 |
82.7 |
95.7 |
86.8 |
| MPDA | 95.5 | 88.1 | 98.9 | 93.1 |
|
方法 |
BiGRU |
|||
|---|---|---|---|---|
|
A |
P |
R |
F1 |
|
|
SMOTE+GAN+Fuzzy |
92.2 |
83.1 |
95.1 |
86.2 |
|
SMOTE+GAN+FSS |
92.2 |
82.8 |
95.5 |
87.7 |
|
OSS+GAN+Fuzzy |
93.5 |
84.5 |
96.0 |
88.8 |
| MPDA | 95.4 | 88.7 | 98.2 | 93.2 |
小结:MPDA 在各类模型上均显著提升 Recall 与 F1 —— 对简单模型(LSTM/GRU)提升尤为明显;对较强模型(BiLSTM/BiGRU)仍能带来10%+的F1增益,Transformer 的 F1 也有小幅正向提升(≈3.9%)。统计检验显示多数指标差异显著。
📌 总结
MPDA 通过“三管齐下”的增强策略与“按类选择”的调度算法,有效解决了漏洞数据的稀缺与不平衡问题。在 Juliet Java Suite 的大量实验证明:MPDA 能在多数深度学习模型上把 Recall 与 F1 明显拉升(在多数情形下 F1 提升 ≥12%,简单模型的相对增益更高),同时对小样本类也能带来可观改善。
📣 欢迎留言讨论
-
你认为在漏洞检测中,数据增强是否比模型架构改进更能短期内提高可用性?
-
在工业落地时,MPDA 这种自动策略选择的成本是否值得(计算/人工/验证)?
📌 点赞 · 收藏 · 分享 —— 你的支持,是我们持续解读前沿论文的最大动力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 34
34 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)