无问芯穹李秀红:Cache命中率越高越亏钱?藏在“浴盆模型”里的反直觉真相
近日,在 QCon 全球软件开发大会上,无问芯穹技术副总裁李秀红发表了题为《高效 AgenticMaaS 推理系统:KV Cache 压缩技术在大模型推理系统中的应用实践》的专题演讲。该演讲基于无问芯穹长期的推理优化工程实践,分享了技术背后的设计思路与实战经验。以下内容根据演讲中关于 Cache 命中率带来的反直觉发现及核心思考整理而成。

01 Agent 推理阶段新特征:长文本、短输出与高达90%的 Cache 命中率
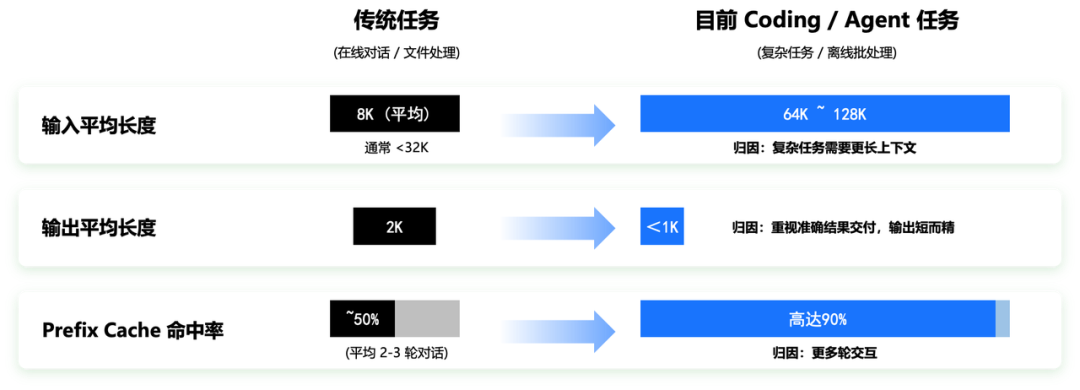
2025年以来,大模型推理应用场景已从传统对话交互,逐步拓展至代码生成、智能执行等多元化 Agent 场景。从大模型推理的工作负载角度来看,长文本、高 Prefix Cache 命中率和短输出已成为了 Agent 推理阶段的新特征。
传统任务以在线对话、文件处理为主,输入平均8K,通常不超过32K,输出平均2K,Cache 命中率50%(平均2-3轮对话)。而当前的 Agent 任务,输入长度普遍提升至64K~128K,输出长度多控制在1K以内,Cache 命中率可高达90%。这一差异源于复杂任务对更长上下文支撑、更多轮次交互迭代、更精准的结果交付的需求,因此呈现出输入更长、缓存复用率更高、输出更精简准确的特征。
下图是某个服务在3月份某一天,请求 Cache 命中率的分布情况,我们发现在流量较低的时间段,比如凌晨2点,甚至有高达50%的请求,Cache 命中率超过了99%,而平均命中率也可以达到80%-90%。
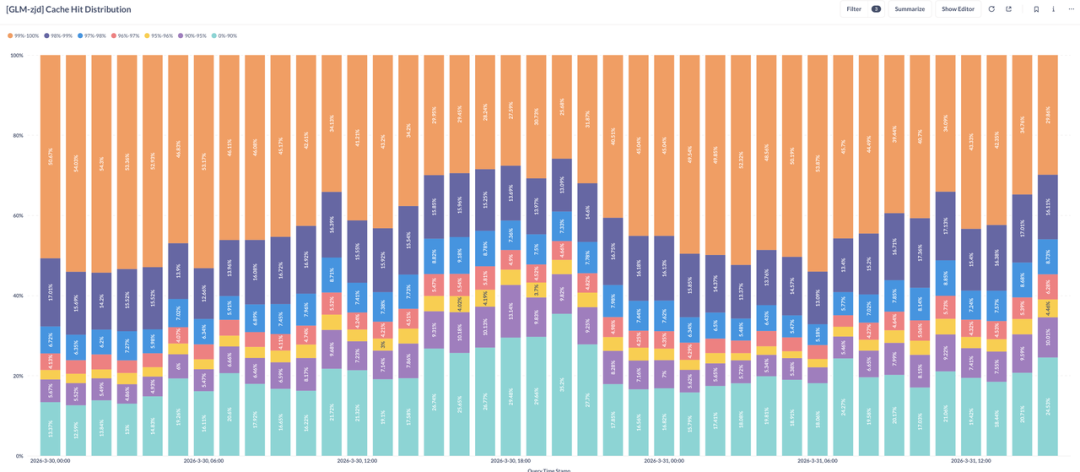
如此高的 Cache 命中率意味着请求中大量的 Token 不需要计算,只需要计算很小一部分,那么对于大模型推理厂商而言,钱也赚得太容易了吧,那么真实情况是这样么?
02 一个“反直觉”的发现:Cache 命中率越高越亏钱
然而我们分析了历史业务中的命中率变化在开源框架上的表现,发现了一个非常“反直觉”的发现,如下图所示,随着 Cache 命中率提升,反而更亏钱了。
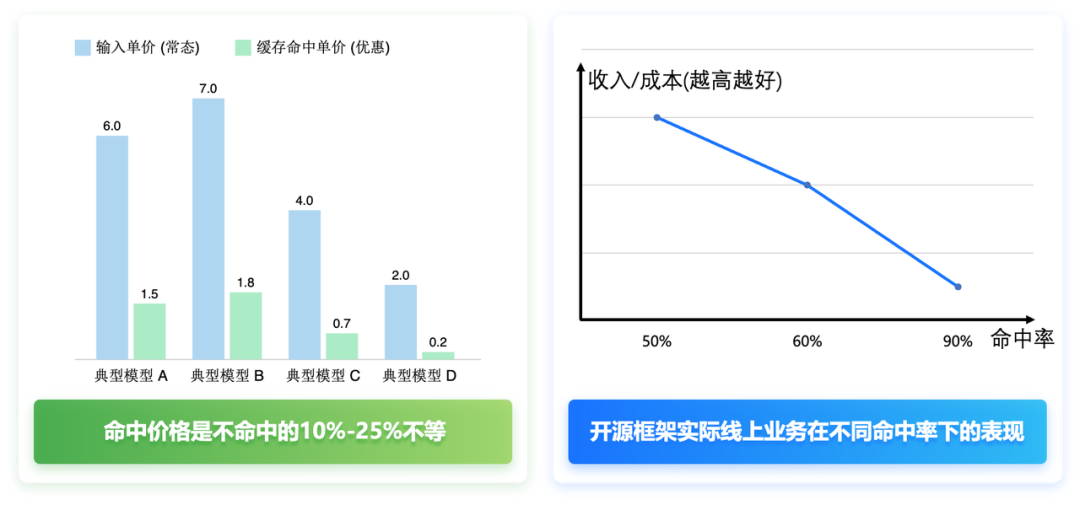
因为目前大模型的输入部分 Cache 命中和未命中部分的价格不一致,大概命中部分的价格是未命中部分的10%-25%不等。那么,命中率越高越亏钱,是否就说明命中带来的吞吐收益,抵不过 Cache 命中部分的极低折扣?
03 背后玄机揭秘:Cache 命中率的浴盆模型
接下来让我们对 Cache 命中率作为核心变量的收入模型展开量化分析。首先,给定一组机器的服务,每秒的收入由以下公式算得,其中 TPD 代表该服务每天支持的 Token 总数即 Token per Day,其中分为 hit 和 miss 两部分,分别代表命中 Cache 的 Token per Day 和未命中部分的 Token per Day 。考虑到每秒的成本属于固定机器成本,不随 Cache 命中率变化。因此,收入/成本主要受下述公式影响。
(TPDhit∗Pricehit+TPDmiss∗Pricemiss)/(3600∗24)(TPD^{hit} ∗Price^{hit}+TPD^{miss}∗Price^{miss})/(3600∗24)(TPDhit∗Pricehit+TPDmiss∗Pricemiss)/(3600∗24)
上述公式可以简化为推理服务Cache命中部分和未命中部分的吞吐率,因此这两部分TPS随着Cache命中率的变化成为性价比的关键。
TPShit∗Pricehit+TPSmiss∗PricemissTPS^{hit} ∗Price^{hit}+TPS^{miss}∗Price^{miss}TPShit∗Pricehit+TPSmiss∗Pricemiss
(1)大胆假设
我们不妨大胆假设,TPSmissTPS^{miss}TPSmiss不受命中率影响,而TPShitTPS^{hit}TPShit随着命中率提升而提升,如下图所示:
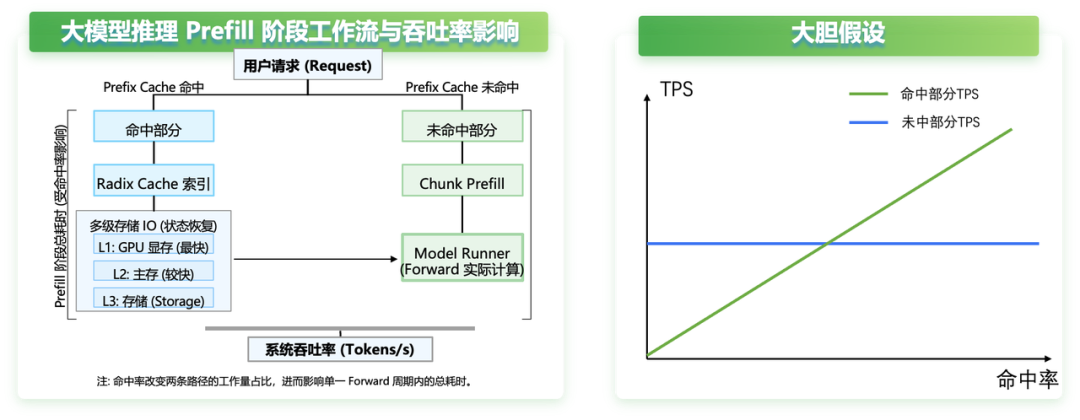
(2)小心求证
接下来,让我们开始小心求证。首先,我们使用某个真实模型,人造出不同Cache命中率的数据,然后实测了不同Cache命中率下,TPSmissTPS^{miss}TPSmiss的变化过程:
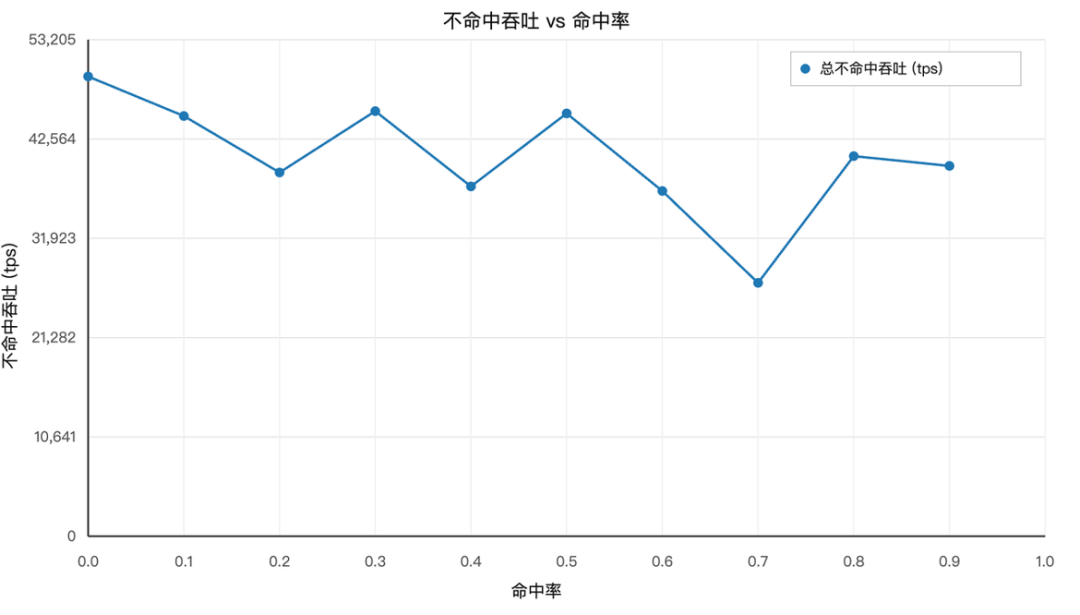
我们发现随着 Cache 命中率提升,TPS存在几个奇异点,即20%、40%、70%命中率下 TPS 很低。我们分析代码发现是这几个命中率下,框架在调度过程中会出现一些很小的需要计算的Chunk,即末尾残块(Tail Chunk),其大小会随命中率变化。若不满 Chunk Size 又无法拼接,需独立计算。末尾残块越小,TPS越差。我们可以通过工程优化进行优化处理。除掉奇异点之后,我们小心求证得到,未命中部分的吞吐随着Cache命中率提升,呈近似线性下降,我们使用公式表达TPSmiss=TPS0∗(1−a∗x)TPS^{miss}=TPS^{0}*(1-a*x)TPSmiss=TPS0∗(1−a∗x),其中TPS0TPS^{0}TPS0代表命中率为0时的吞吐率,0<a<10<a<10<a<1。
搞定TPSmissTPS^{miss}TPSmiss,我们再分析TPShitTPS^{hit}TPShit随着Cache命中率提升的变化,我们首先做一个数学建模,如下图所示,我们发现TPShitTPS^{hit}TPShit随着Cache命中率公式为xt1−x\frac{xt}{1-x}1−xxt,而我们知道未命中部分吞吐率t=1−a∗xt=1-a*xt=1−a∗x,因此TPShit=x−a∗x21−xTPS^{hit}=\frac{x - a*x^{2}}{1-x}TPShit=1−xx−a∗x2,因为当Cache命中率为100%的时候,未命中部分的TPS不会为0,因此容易得出0<a<10<a <10<a<1,对上述函数求导容易得到该函数在命中率[0,1)区间单调递增,而且逼近1的时候取值为正无穷。
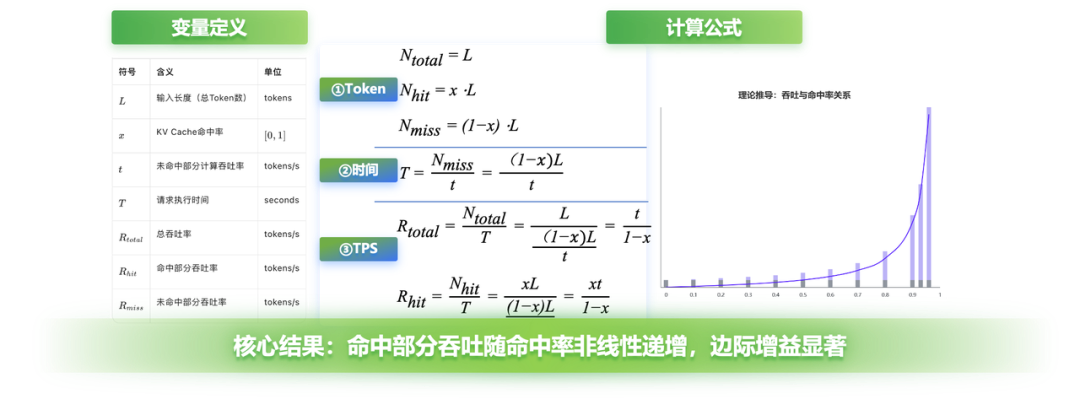
理论分析之后,我们同样通过实验进行验证,我们使用某个真实模型,人造出不同Cache命中率的数据,然后实测了不同Cache命中率下,TPShitTPS^{hit}TPShit的变化过程基本吻合。
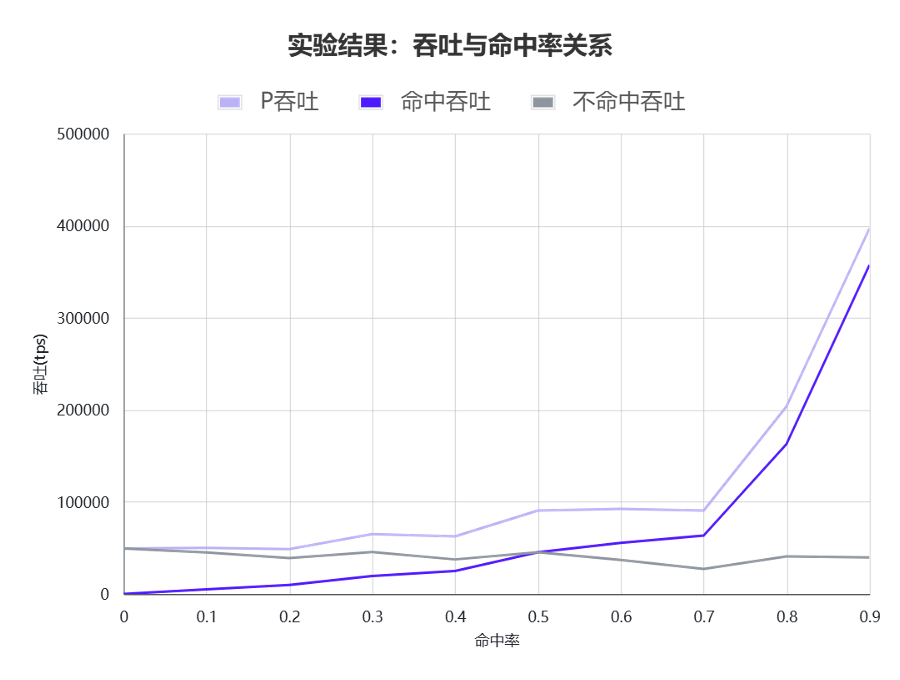
(3)浴盆模型
我们发现以上图来看,当命中率从40%提高到70%时,未命中部分 TPS 下降了接近20%,而命中部分的吞吐率提升不超过 3 倍。考虑到命中部分的价格只有未命中部分的10%-25%,显然命中率提升之后,更亏钱了。我们通过建模和实测给出了命中越高越亏钱这个反直觉发现的背后玄机,即随着命中率变化,收益呈现出一个浴盆曲线的变化。当我们落入在偶然失效区间时,就会出现命中率越高越亏钱。
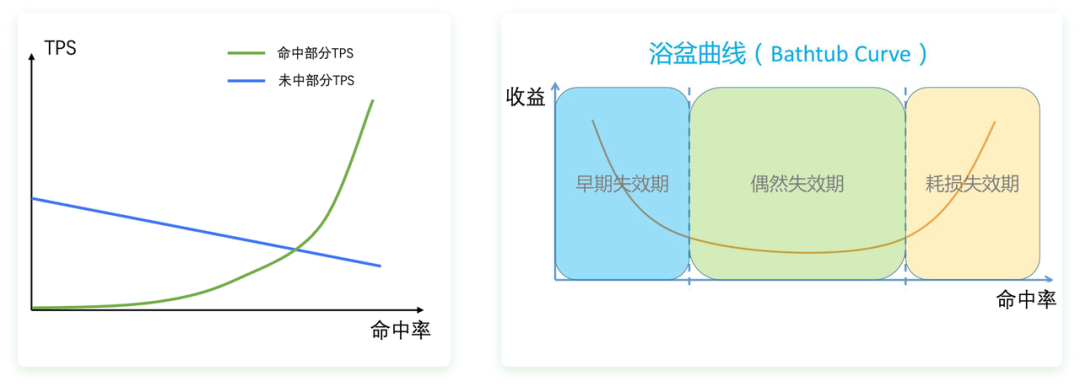
04 未来的核心优化方向:Stay Away From The Valley
体系结构领域有一篇著名的论文比较 SIMT 和 SIMD 架构,Many-Core vs. Many-Thread Machines: Stay Away From the Valley,和这里有异曲同工之妙,我们也借用 Stay Away From The Valley 的描述,来给出一些我们认为的优化方向:
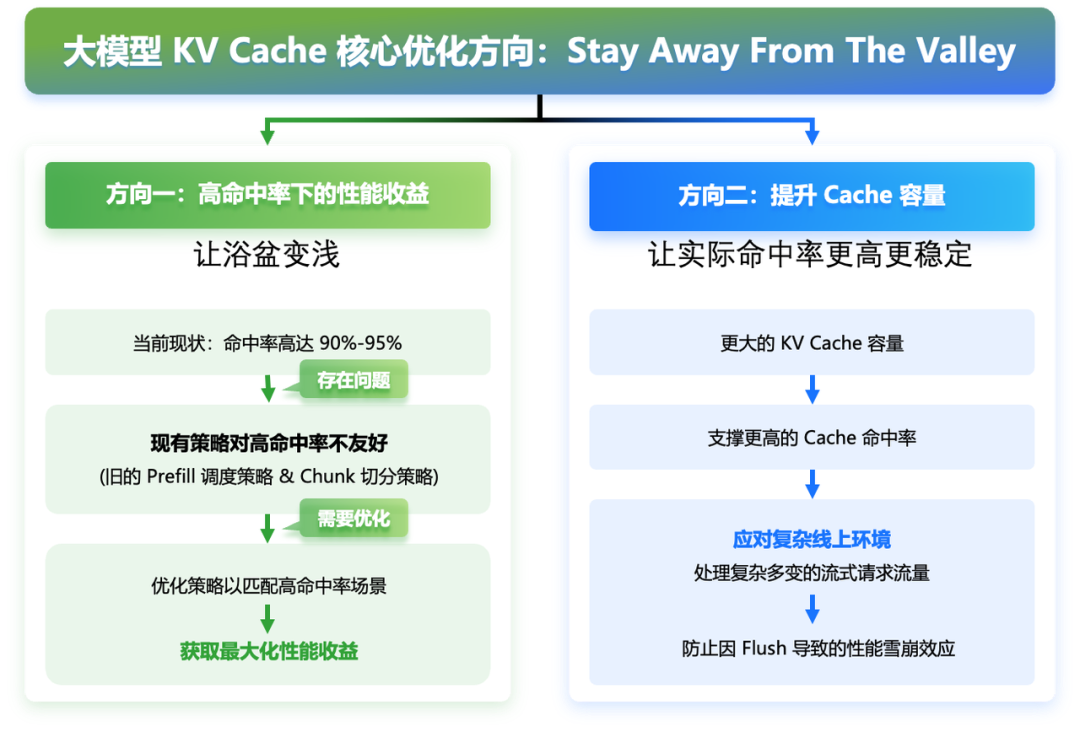
1)通过系统优化,把浴盆变浅,一是降低上图中未命中部分下降的斜率,二是提升命中部分上升的斜率。
2)提高 Cache 容量,逃离盆底,让实际命中率更高更稳定。
随着 Agent 场景持续深化,大模型推理需求呈现爆发式增长,其背后涌现出的一系列反直觉现实也让我们意识到,比起埋头解题,或许穿透表象发现真问题、定义真命题更为关键。Prefix Caching 作为 Agent 推理时代的一等公民,穿透其本质之后的优化才能真正落地到实际业务。针对 Prefix Cache,无问芯穹 MaaS 大模型推理团队从 KV Cache 无损压缩、Cache-aware 负载均衡策略到高命中率下的请求 Chunk 和 Batch 策略方面开展了系统级协同优化。
作为国际领先的大模型推理服务团队,无问芯穹长期为智谱和月之暗面等行业头部大模型企业的最新旗舰模型(如GLM-5.1、Kimi K2.6)提供高质量服务,在服务质量(模型精度、P99 TTFT 和 TPS)和服务稳定性方面持续领先行业。
后续,我们也将围绕 KV Cache 无损压缩、Cache-aware 负载均衡等核心优化方向,推出系列技术文章,深度拆解技术实现细节,分享真实业务落地经验。也希望通过此次抛砖引玉,能引发大家更多的思考和更好的优化工作,共同推动大模型推理效率持续升级。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)