成本降九成,准确率100%!MIT反常识架构挑战硅谷信仰
当顶尖大语言模型智能体(Agent)在模拟企业环境中挣扎,正确率惨淡到0%时,一个叫RUBICON的新架构,靠一套简单直白的查询语言,把正确率拉到了100%。而且用的还是更小更便宜的模型。
AI圈子有个很有意思的现象。
一边是科技公司疯狂给大模型装“手和脚”,让它替人操作各种软件;另一边,真正需要AI的企业客户却在摇头。
慕尼黑工业大学,达姆施塔特工业大学,麻省理工学院等的一群研究者,在他们最新的论文里戳破了这层窗户纸。

企业里的AI落地问题,压根不是模型不够聪明,而是数据太乱。
当顶尖大语言模型智能体(Agent)在模拟企业环境中挣扎,正确率惨淡到0%时,一个叫RUBICON的新架构,靠一套简单直白的查询语言,把正确率拉到了100%。而且用的还是更小更便宜的模型。
企业数据散落在各个孤立系统里。今天的智能体AI总想让LLM当大脑,去理解并操作一切,结果就是混乱、昂贵、不靠谱。
RUBICON走了另一条路。它把操作权交还给用户,让用户通过一种叫AQL的极简查询语言,明确告诉系统去哪个数据源找什么东西,LLM只负责在精确划定的范围内干活。
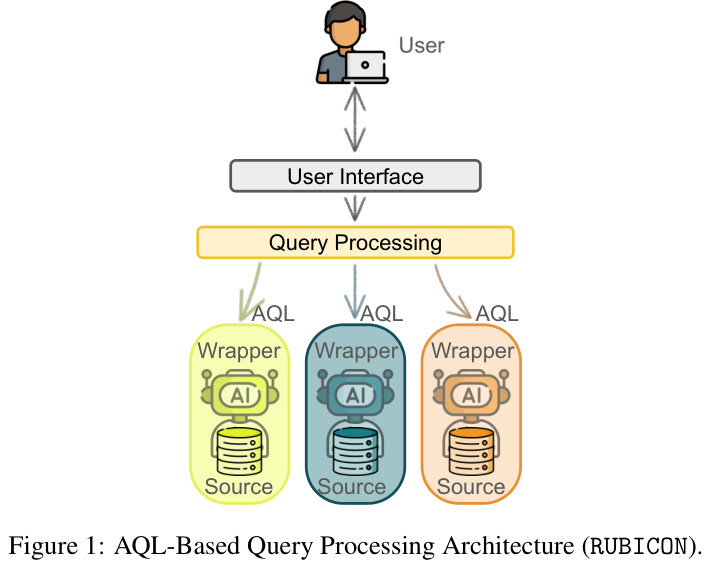
所有中间步骤透明可见,用户随时干预。这套方法用结构化的确定性,替代了端到端推理的概率性。
聪明大脑配不上混乱数据
过去几年,把LLM做成智能体(Agent)成了主流思路。
大家觉得,LLM推理能力强,应该让它做总指挥,自己决定什么时候查什么数据库,什么时候调用什么工具,最后合成一个答案。
这种LLM中心的架构,看起来很美好。
但现实世界里的企业,可不是实验室里那几个干净的测试集。
论文毫不客气地指出,企业在AI上碰的钉子,几乎全是数据整合问题,不是推理赤字。
关键信息分散在数据库、文档系统、邮件服务、外部网页这些完全不同的系统里。
每个系统有自己的查询语言、数据结构、访问权限。
这些系统是架构严谨、对性能苛刻度极高的数据堡垒,而LLM是个玩文字游戏的概率高手。让后者去管前者,就像让一位诗人去调度一支航空母舰编队。
为什么现在流行的Text-to-SQL在企业里玩不转?
论文点出了四个要命的差异。
公开的学术测试集,数据量小,对LLM来说不过是一小撮资料。
但企业的数据仓库动辄存着海量数据,完全不在一个量级。
学术测试集追求干净的单一模式,企业里为了加速访问,到处是冗余视图和物化视图,同一个问题有无数种查法,LLM一看就晕。
企业数据里充满了内部黑话,某个简称可能代表一个复杂项目,某段编码背后是一整套业务流程,靠LLM去猜,完全不现实。
真实的业务查询也比测试集复杂得多。
当这些差异叠加,论文观察到LLM在真实企业数据仓库上的准确率,相比基准测试有超过50%的断崖式下跌。这直接从可用掉到了不可用。
查什么、从哪查,你说了算
既然此路不通,RUBICON的解决之道很淳朴。
它不再死磕让机器理解一切,而是把方向盘还给了人类驾驶员。
架构核心是一套叫AQL(Agentic Query Language,智能体查询语言)的查询代数。
这套语言极其精简,就三个核心指令:FIND(找什么)、FROM(从哪里找)、WHERE(条件是什么)。
条件部分用自然语言写,其他部分用户明确指定。
举个例子,你想知道大学里哪个研究实验室的教授拿过图灵奖或诺贝尔奖。对RUBICON来说,一个可能的AQL指令长这样:

看到了吗,用户必须清楚地说出,要从维基百科和大学数据仓库这两个具体来源取数,并指明字段。
LLM的工作被压缩到了一个极窄的范围:它只负责理解WHERE后面的自然语言条件,把它翻译成各个数据源能执行的指令。
它不用再瞎猜去哪里找数据,不用再操心怎么把数据连起来。这个翻译工作,由连接不同数据源的包装器(Wrapper)完成。
每个包装器负责把一个数据源(哪怕是邮件系统、视频库),转换成一个规范的关系表格视图。
这让所有的数据,看起来都像数据库里的行和列,下游操作变得极其明确。
这种设计直接把LLM那套不透明的链式调用,变成了显式的、可检查的关系操作流水线。
RUBICON有两种运行模式。
交互模式下,用户执行完一条AQL指令,得到一个可视的、类似电子表格的中间结果。
用户可以停下来检查,发现不对立刻纠正,然后把结果存起来,发给下一条指令用。每一步都实实在在,可追溯,可复现。
如果你想重复一个任务,编译模式会把整个指令序列打包,像一个传统数据库查询计划一样,让优化器找到最高效的执行路径,成本比反复调用LLM低得多。
0% 对阵 100%
口说无凭,团队为RUBICON和目前的智能体AI方案做了一个有意思的微型对打。
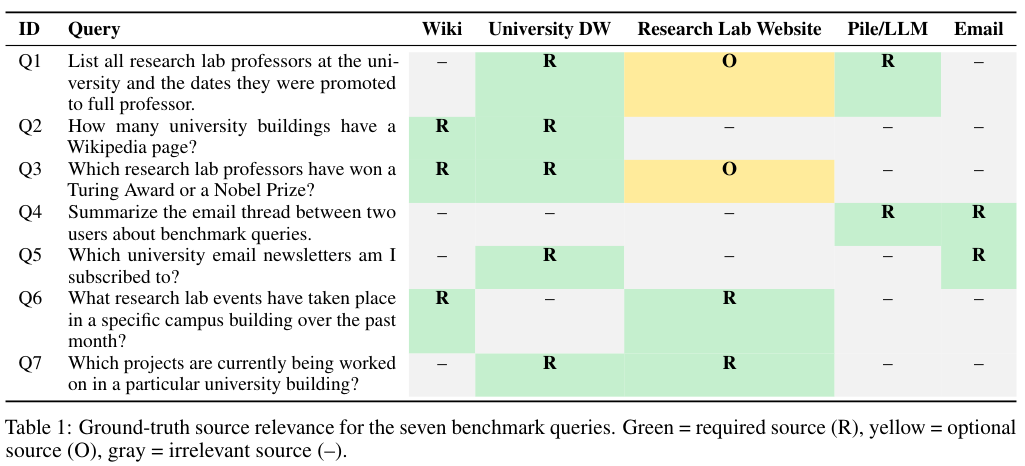
他们模拟了一个典型的企业信息杂乱环境,包括维基百科、一个拥有97张表的匿名化大学数据仓库、一个大学研究实验室网站、Gmail邮箱系统,还有LLM自己的预训练知识库。
他们精心设计了7个问题。每个问题都必须恰恰好跨2个数据源才能回答,其他3个源全是干扰项。
表1:七个基准查询的真实数据源相关性。绿色表示必须的数据源(R),黄色表示可选数据源(O),灰色表示无关数据源(-)。
模型是OpenAI的GPT-5-mini、谷歌的Gemini-3-flash-preview和Anthropic的Claude-Sonnet-4.6。
它们以两种姿态迎战:一种是不带任何工具的普通聊天模式(Vanilla LLM),另一种是配备全套数据源访问权、采用当前最流行的ReAct推理-行动循环的LangChain智能体。
结果是一场令人惊讶的完胜。
所有Vanilla LLM和LangChain智能体配置,准确率全部是0%。一个正确的都没有。
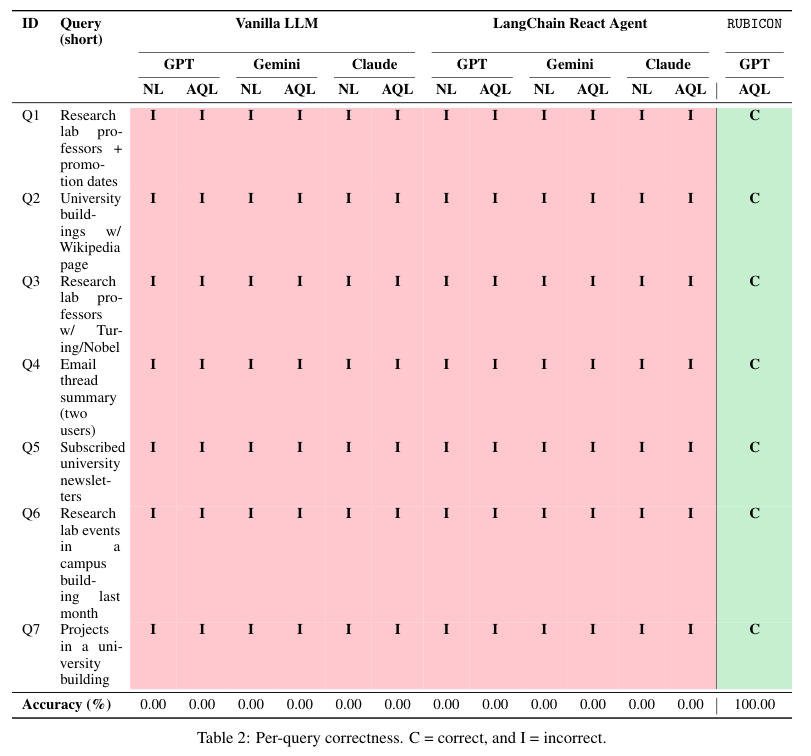
失败的原因不是模型说胡话,而是系统性协调失灵。
模型要么忘记去查某个必要的源头,查到一半就停了,要么没能把不同源的结果正确关联起来。
就拿刚才那个教授获奖的问题来说,LangChain智能体经常只是去维基百科扒了个获奖名单,却没去数据仓库核实这些人是不是学校的教授,最后列出来一堆外人。
给了工具,模型自己却没管住手。论文里形容,给模型更大的自主权和更强的推理设置,得到的是更广的失败面和更高的成本。
反观RUBICON,准确率100%。这7个问题对它来说只是按部就班的AQL指令组合,不存在漏查或忘联的可能。
管住手脚反而更省钱
效率上的对比同样残酷。来看看表3汇总的成本和延迟数据。
表3:所有查询的平均效率指标汇总。k̄是每个查询的平均工具调用次数(Vanilla模式为0)。
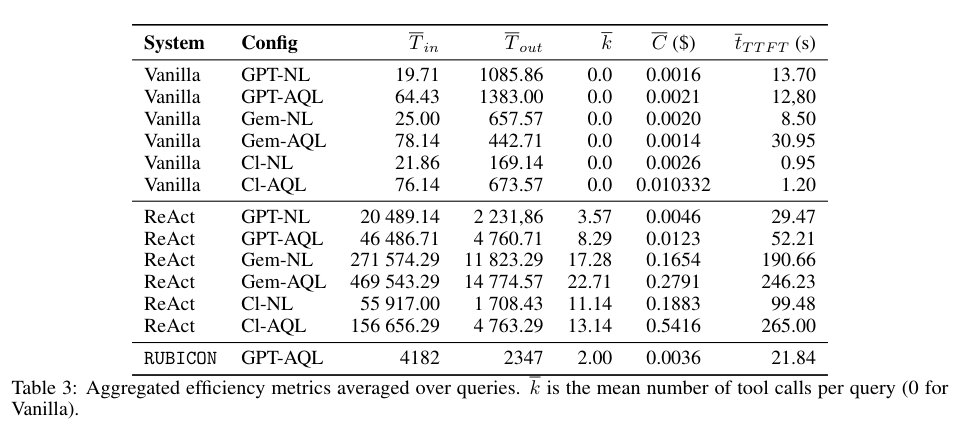
Vanilla模式很安静,不调用任何工具,输入token数不到80,成本极低。
一旦变成ReAct智能体,情况立刻失控。它们为了那可怜的0%正确率,开始疯狂地尝试。
GPT智能体平均每次查询输入token数飙到2万到4.6万。
Gemini智能体更夸张,自然语言模式下输入超过27万token,AQL模式下冲到近47万token,调用了高达22.71次工具,一次查询的金钱成本是0.28美元,首次响应时间要等超过4分钟。
Claude的情况也很类似,昂贵的按token计价,加上大面积探索,导致一次查询可能超过0.5美元。
这些模型用越来越多的推理、越来越长的上下文、越来越频繁的工具调用,换来的却是越来越稳固的0分。
RUBICON用的是GPT-5-mini,成本稳定在极低水平,每次查询正好调用2次工具(对应2个必须的数据源),不瞎逛,不多想。
RUBICON把数据去哪找这类关键的决策权交还给用户,这确保了结果正确,还天然绕开了一个智能体AI自己很难处理的大坑:查询计划的选择。
论文用同一个教授获奖的问题举了个例子。
用户想达到目的,可以写两种不同的AQL指令。
计划A是“先找获奖者,再找人”,先从维基百科找出所有图灵奖和诺奖得主(这个名单不长),然后再去大学数据仓库里,核对哪些人是教授。
计划B是“先找人,再找奖”,先拉出所有教授(可能很多),然后为每一个教授去维基百科翻他的页面,看有没有得奖记录。
这两个计划逻辑上都正确,但成本天差地别。计划B会让系统对每一位教授执行一次维基百科查找操作,开销随教授数量线性增长。计划A则利用了一个高选择性的过滤条件,大幅减少了后续的查找次数。
在智能体AI中,这直接意味着更多或更少的工具调用、Token消耗和等待时间。
LLM自己选择哪条路,有很强的随机性,选的不好,成本能爆掉,速度能慢到无法接受。
RUBICON把选择权交给了用户,也可以用一个经典的基于成本的查询优化器,自动挑出最高效的那条路。这都是当前LLM智能体根本做不到的。
研究结尾引用了MIT一个跟踪了超300个企业AI项目的报告。报告发现,少于5%的自定义AI项目取得了可量化的回报。
模型越来越强,自主能力越开越大,但幻觉和遗漏带来的失败模式,没什么本质改变。
研究者给这股热潮送上了一套古老的软件工程智慧。
先理清数据,管好接口,再说智能的事。这个看似“笨拙”的架构,反而更接近企业真正需要的AI。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献110条内容
已为社区贡献110条内容

所有评论(0)